Reinforcement Learning
从GRPO到GSPO、DAPO
回顾 PPO \[\begin{equation}\begin{aligned}\mathcal{J}_{\text{PPO}}(\theta) &= \mathbb{E}_{(q,a)\sim\mathcal{D}, o_{<t}\sim\pi_{\theta_{\text{old}}}(\cdot|q)} \\
&\left[ \min \left( \frac{\pi_\theta(o_t \mid q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{<t})} \hat{A}_t, \text{clip}\left(\frac{\pi_\theta(o_t \mid q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{<t})}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_t \right) \right]\end{aligned}\tag{1}\end{equation}\] 其中 \((q, a)\) 是 数据集...
#Reinforcement Learning
#Large Model
Reinforcement Learning
Policy Gradient 优化:TRPO,PPO
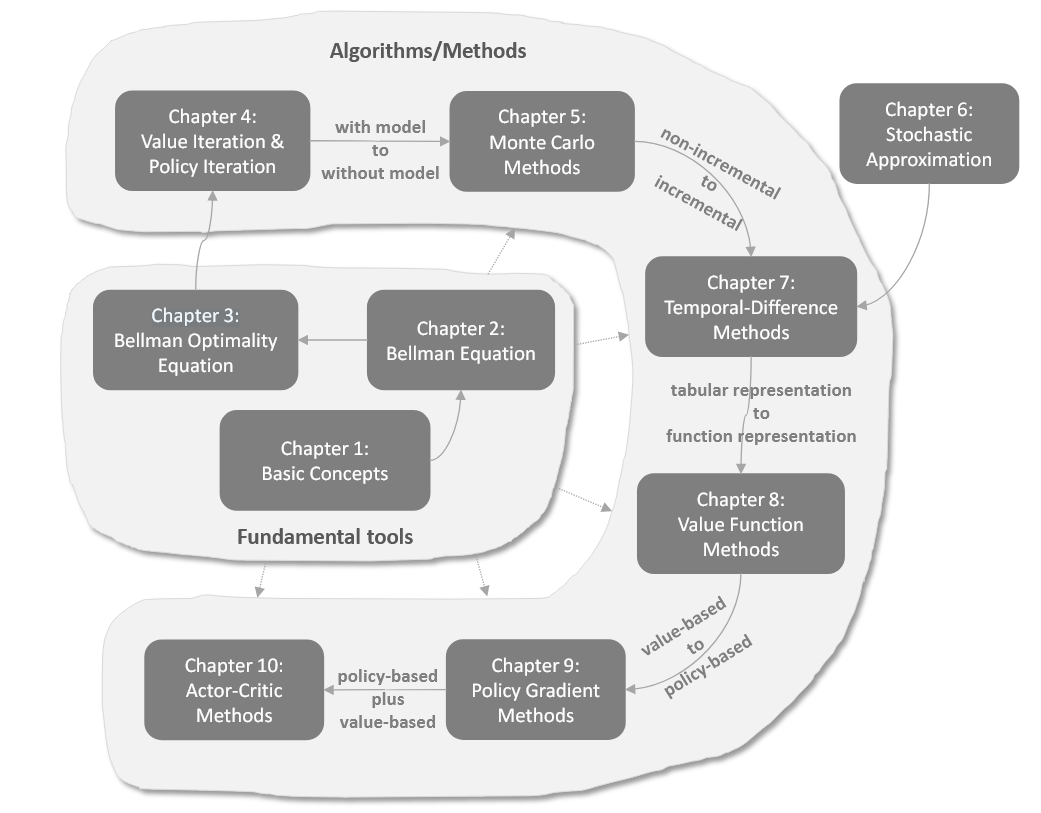
概念 符号 定义 来源 用途 特点 Reward \(r_t\) 即时奖励 环境 基础信号 局部、即时 Return \(G_t\) \(Σ γ^k·r_{t+k}\) 计算 Value训练目标 实际、高方差 Value \(V(s)\) \(E[G_t|s_t=s]\) 模型 状态评估 预测、期望 Q-Value \(Q(s,a)\) \(E[G_t|s_t=s,a_t=a]\) 模型 动作评估 更细粒度 Advantage \(A(s,a)\) \(Q(s,a) - V(s)\) 计算 Policy更新 相对、低方差 GAE \(GAE(λ)\) 加权Advantage 算法 优势估计 平衡bias-variance 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础...
#Reinforcement Learning
#Policy Gradient
Reinforcement Learning
策略梯度方法(Policy Gradient Methods)
引言与背景 策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(value-based),而策略梯度方法则直接优化策略函数(policy-based),这是一个重要的进步。 当策略用函数表示时,策略梯度方法的核心思想是 通过优化某些标量指标来获得最优策略 。与传统的表格表示策略不同,策略梯度方法使用参数化函数 \(\pi(a|s, \theta)\) 来表示策略,其中 \(\theta \in \mathbb{R}^m\) 是参数向量。这种表示方法也可以写成其他形式,如 \(\pi_\theta(a|s)\) 、 \(\pi_\theta(a, s)\) 或 \(\pi(a, s, \theta)\) 。 策略梯度方法具有多种优势: 更高效地处理大型状态/动作空间 具有更强的泛化能力 样本使用效率更高 策略表示:从表格到函数 当策略的表示从表格转变为函数时,存在以下几个关键区别: 最优策略的定义 : 表格表示:最优策略是使每个状态值最大化的策略 函数表示:最优策略是使某些标量指标最大化的策略 策略更新方式 :...
#Reinforcement Learning
#Policy Gradient