💡 GRPO相比PPO主要优势:
1. 训练更稳定
引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性
GRPO用组内相对优势替代value model,消除了value估计误差
通过组内归一化,自动消除reward scale和bias的影响
实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低
2. 工程更简单
只需要1-2个模型(policy + reference),而PPO需要4个
显存占用减少50%以上,训练速度提升2-3倍
超参数更少,更容易调优
3. 相对奖励机制
通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差
背景
GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略:
- 强化学习(RL)在提升模型数学推理能力方面被证明是有效的
- 传统PPO算法需要较大训练资源
- GRPO作为PPO的变体被提出,可以更高效地优化模型

PPO回顾
PPO的目标函数为:
其中:
- \(\pi_\theta\) 和 \(\pi_{\theta_{old}}\) 分别是当前和旧策略模型
- \(A_t\) 是优势函数
- \(\epsilon\) 是裁剪相关的超参数
模型训练
如图1上所示,PPO需要同时训练一个Value Model \(V_\psi\) 和策略模型, 同时需要reference model(通常从SFT model初始化)来限制策略模型训练保持和reference model的行为接近,而 Reward model用来计算reward:
- Value Model 用于基于奖励序列 \({r_{\geq t}}\) 进行优势估计,这增加了额外的计算和内存开销
- 在每个token位置 \(t\),奖励计算公式为:
其中:
- \(r_\phi(q, o_{\leq t})\) 是奖励模型给出的原始奖励
- \(\beta\) 是KL惩罚项的系数
- \(\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{ref}(o_t|q,o_{<t})}\) 表示当前策略与参考策略的比值的对数
PPO局限性
- 计算资源问题:PPO需要训练一个与策略模型相当规模的值函数模型,这带来了巨大的内存和计算负担
- 值函数训练的困难: 在LLM环境中,奖励模型通常只给最后一个token分配奖励分数, 这使得在每个token位置训练准确的值函数变得复杂,影响了优势估计的准确性
GRPO的具体实现
GRPO核心思想
- 完全避免使用额外的值函数近似
- 采用组内相对奖励作为baseline
- 通过分组采样的方式计算优势
GRPO的目标函数为:
其中:
- \(\epsilon\) 和 \(\beta\) 是超参数
- \(\hat{A}_{i,t}\) 是基于组内相对奖励计算的优势值
GRPO没有像在(2) 中一样 奖励中添加KL惩罚,而是通过直接添加训练的策略与参考策略之间的KL差异来正则化损失,从而避免使 \(\hat{A}_{i,t}\) 的计算复杂化。并且KL散度计算也有一些不同,用了一个无偏估计的KL散度计算:
GRPO的结果监督(Outcome Supervision)
基本流程
- 采样阶段:对每个问题 q 从旧策略模型 \(\pi_{\theta_{old}}\) 采样G个输出: \({o_1, o_2, ..., o_G}\)
- 奖励计算:使用奖励模型对每个输出进行评分得到G个奖励值: \(r = {r_1, r_2, ..., r_G}\)
- 奖励归一化:对原始奖励进行标准化处理:
其中:
- \(mean(r)\) 是组内奖励的平均值
- \(std(r)\) 是组内奖励的标准差
- 对输出序列中的 \(o_i\) 中的所有token t 使用相同的优势值,优势值等于归一化后的奖励值
这样做的好处是:
- 相对比较:通过组内归一化实现输出间的相对比较,减少了不同问题间奖励尺度的差异
- 方差减少:标准化处理有助于稳定训练,控制了优势值的分布范围
- 简化优势分配: 统一分配所有token获得相同的优势值,简化了优势估计过程
- 端到端反馈:基于最终结果对整个序列进行优化,适合于结果导向的任务
这种结果监督机制的设计体现了GRPO算法在实用性和效率之间的权衡,通过简化优势计算来提高训练效率,同时保持了足够的效果。这对于大规模语言模型的强化学习优化特别有价值。
- 去除了critic模型
- 使用组内得分作为baseline估计
GRPO的过程监督(Process Supervision)
结果监督只在输出结束时提供奖励,对复杂数学任务的监督可能不够充分,需要对推理过程中的每个步骤进行评估。
基本流程
- 对问题q采样G个输出:\({o_1, o_2, ..., o_G}\)
- 使用过程奖励模型对每个推理步骤进行评分,得到对应的奖励:
- 计算归一化奖励
- 基于后续步骤的奖励计算token优势值
这样实现的优势是
- 更细粒度的监督:
- 可以评估每个推理步骤的质量
- 提供更及时的反馈信号
- 更好的奖励分配:
- 能够区分不同推理阶段的贡献
- 有助于学习更好的推理策略
- 适合多步推理问题,需要清晰推理过程的任务比如数学问题求解和复杂逻辑的推理
具体示例
这里再对比一下GRPO和PPO在计算优势函数上的差异:
假设我们有一个数学问题:
Q: "计算 13 × 17 的结果"
模型生成了多个答案:
- 输出1: "让我们一步步计算:
- 13 × 10 = 130
- 13 × 7 = 91
- 130 + 91 = 221 所以 13 × 17 = 221"
- 输出2: "13 × 17 = 220"
- 输出3: "13 × 17 = 221"
PPO的计算方式
- 需要训练一个值函数模型 \(V_\psi(s_t)\)
- 对每个token位置都要计算值函数预测
- 使用 \(TD(λ)\) 或 \(GAE(λ)\) 计算优势值
- 更新策略
以输出1为例:
Token序列: ["让", "我们", "一步", "步", "计算", ":", "1", ".", " ", "13", "×", "10", "=", "130", ...]
值函数预测: [0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.6, 0.65, 0.7, 0.75, 0.8, ...]
实际奖励: \(r = 1\) (正确答案)
优势值计算(使用GAE):
\(A_t = r_t + γV(s_{t+1}) - V(s_t)\)
GRPO Outcome Supervision 的计算方式
- 采样一组输出(G个)
- 计算组内奖励统计量
- 归一化奖励
- 将归一化奖励作为整个序列的优势
- 更新策略
对同一问题采样G个输出(例如G=3):
组内采样结果:
输出1: 完整推导过程,答案221 → \(r₁ = 1.0\)
输出2: 直接答案220 → \(r₂ = 0.0\)
输出3: 直接答案221 → \(r₃ = 1.0\)奖励归一化:
\(rewards = [1.0, 0.0, 1.0]\)
\(mean(R) = (1.0 + 0.0 + 1.0) / 3 = 0.667\)
\(std(R) = sqrt(((1.0-0.667)² + (0.0-0.667)² + (1.0-0.667)²) / 3) = 0.471\)归一化奖励: \(r̃₁ = (1.0 - 0.667) / 0.471 = 0.707\) \(r̃₂ = (0.0 - 0.667) / 0.471 = -1.414\) \(r̃₃ = (1.0 - 0.667) / 0.471 = 0.707\)
优势值分配:
对于输出1中的每个token:\(Â_{1,t} = r̃₁ = 0.707\) (对所有\(t\))
GRPO Process Supervision 的计算方式
- 采样一组输出(G个)
- 计算组内奖励统计量
- 归一化奖励
- 基于后续步骤的奖励计算token优势值(每个步骤的优势值相同)
- 更新策略
对同一问题采样G个输出(例如G=3):
组内采样结果:
输出1 (完整推导):
Step 1: "让我们分解计算:" → \(r₁₁ = 0.5\)
Step 2: "13 × 10 = 130" →\( r₁₂ = 1.0\)
Step 3: "13 × 7 = 91" → \(r₁₃ = 1.0\)
Step 4: "最后 130 + 91 = 221" →\( r₁₄ = 1.0\)输出2 (部分推导):
Step 1: "可以这样计算:" →\( r₂₁ = 0.5\)
Step 2: "13 × 17 = 220" → \(r₂₂ = 0.0\)输出3 (直接答案): Step 1: "13 × 17 = 221" → \(r₃₁ = 1.0\)
奖励归一化:
奖励矩阵
R = [0.5, 1.0, 1.0, 1.0, # 输出1的所有步骤
0.5, 0.0, # 输出2的所有步骤
1.0] # 输出3的所有步骤\(mean(R) = (0.5 + 1.0 + 1.0 + 1.0 + 0.5 + 0.0 + 1.0) / 7 = 0.714\)
\(std(R) = sqrt(((0.5-0.714)² + (1.0-0.714)² + ...) / 7) = 0.39\)归一化奖励:
输出1: \(r̃₁₁ = (0.5 - 0.714) / 0.39 = -0.549\) \(r̃₁₂ = (1.0 - 0.714) / 0.39 = 0.733\) \(r̃₁₃ = (1.0 - 0.714) / 0.39 = 0.733\) \(r̃₁₄ = (1.0 - 0.714) / 0.39 = 0.733\)
输出2: \(r̃₂₁ = (0.5 - 0.714) / 0.39 = -0.549\) \(r̃₂₂ = (0.0 - 0.714) / 0.39 = -1.831\)
输出3: \(r̃₃₁ = (1.0 - 0.714) / 0.39 = 0.733\)
优势值计算:
对于输出1中的token t
如果 t 在Step 1开始到结束: \(Â_{1,t} = r̃₁₁ + r̃₁₂ + r̃₁₃ + r̃₁₄ = -0.549 + 0.733 + 0.733 + 0.733 = 1.650\)
如果 t 在Step 2开始到结束: Â₁,t = r̃₁₂ + r̃₁₃ + r̃₁₄ = 0.733 + 0.733 + 0.733 = 2.199
如果 t 在Step 3开始到结束: \(Â_{1,t} = r̃₁₃ + r̃₁₄ = 0.733 + 0.733 = 1.466\)
如果 t 在Step 4: \(Â_{1,t} = r̃₁₄ = 0.733\)
对于输出2,3的token t计算方式类似
关键区别对比
特性 | PPO | GRPO过程监督 | GRPO结果监督 |
|---|---|---|---|
奖励频率 | 每个Token | 每个推理步骤结束 | 仅在序列末尾 |
优势计算 | 用值函数预测 | 基于后续步骤累积 | 所有token使用相同值 |
反馈精度 | 细粒度 | 中等粒度 | 粗粒度 |
计算复杂度 | 高 | 中等 | 低 |
迭代式GRPO
随着策略模型的改进,旧的奖励模型可能变得不够competent, 奖励模型需要与策略模型同步更新, 并且需要保持历史经验的连续性
所以迭代式的GRPO核心思想是:
- 动态更新奖励模型(使用新生成的数据)
- 使用replay机制保留历史经验(保留10%的历史数据)
- 策略模型和奖励模型交替优化
具体的GRPO算法伪代码如下:

统一范式理论
这篇文章还将之前的RL方法整理成了一个统一的范式,对于训练方法的参数 \(θ\)的梯度可以统一表示为:
其中包含三个关键组成部分:
- 数据源(Data Source) D: 决定训练数据
- 奖励函数(Reward Function) \(\pi_{rf}\): 训练奖励信号的来源
- 算法(Algorithm) A: 处理训练数据和奖励信号,生成梯度系数GC
我们基于这种统一范式分析了几种代表性方法
监督微调(SFT)
- 目标函数
- 对应的梯度
- 数据源: SFT数据集
- 奖励函数: 可视为人工选择
- 梯度系数: 恒为1
拒绝采样微调(RFT)
- 目标函数:
- 对应的梯度:
- 数据源: SFT数据集中的问题,输出从SFT模型中采样
- 奖励函数: 根据答案是否正确的规则
- 梯度系数:
在线拒绝采样微调(Online RFT)
与RFT的主要区别是在线RFT使用SFT模型初始化策略模型, 输出从实时策略模型 \(\pi_\theta\)采样, 而不是从SFT模型 \({\pi }_{{\theta }_{sft}}\)采样
- 目标函数的梯度:
直接偏好优化(DPO)
- 目标函数:
- 对应的梯度:
- 数据源: SFT数据集中的问题,输出从SFT模型中采样正负样本对
- 使用规则型奖励函数
- 梯度系数:
PPO
- 目标函数:
为了简化分析,假定该模型在每个探索阶段之后只更新一次,从而确保\(π_{θ_{old}}=π_θ\)。在这种情况下,我们可以删除最小值和clip操作:
- 对应的梯度:
- 使用实时策略模型采样数据
- 使用模型作为奖励函数
- 梯度系数:
其中, \(A_t\)是通过应用广义优势估计(GAE)基于奖励\(\{r_{≥t}\}\)和学习的值函数\(v_ψ\) 计算得出的优势函数。
GRPO
- 目标函数(为了简化分析,这里假设 \(π_{θ_{old}}=π_θ\)):
- 对应的梯度为:
- 使用实时策略模型采样数据
- 使用模型作为奖励函数
- 梯度系数:
总结了这些方法的组成部分总结如下:
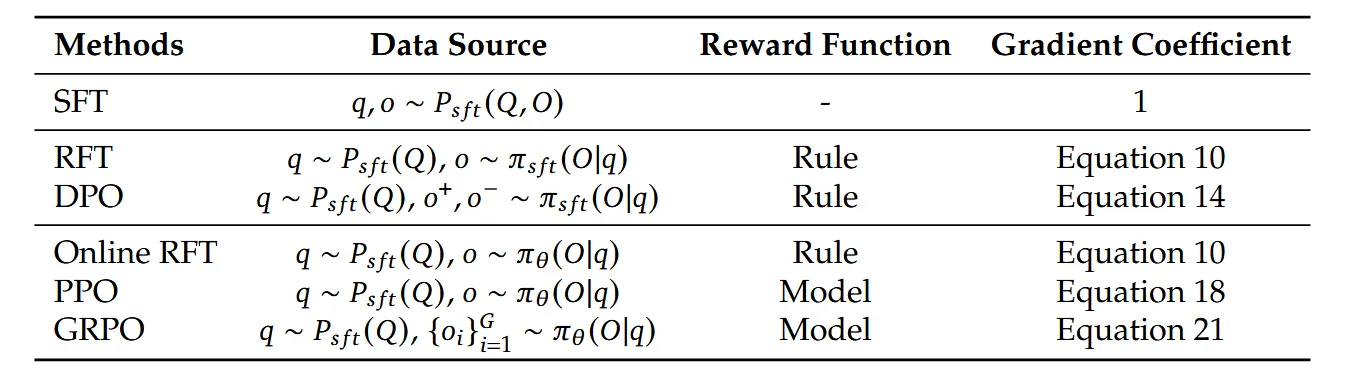
实验观察与发现
数据源
- 分为在线采样和离线采样两类:
- 在线采样: 使用实时训练的策略模型
- 离线采样: 使用初始SFT模型
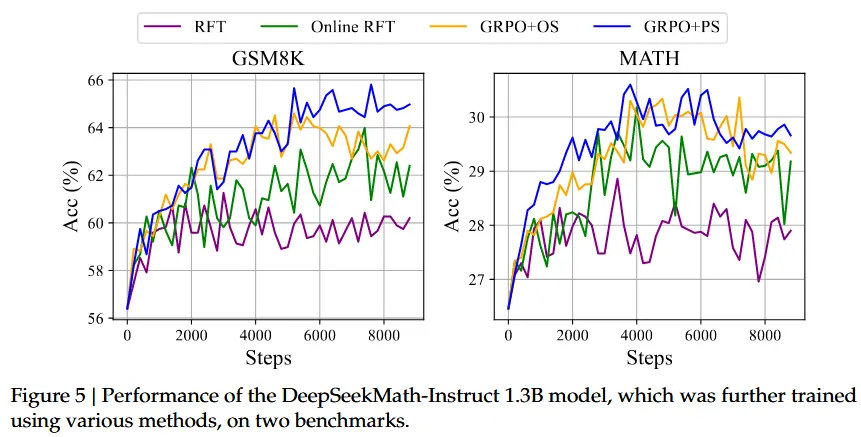
- 如下图所示,实验结果显示:
- Online RFT显著优于RFT
- 在训练后期,实时采样优势更明显: 这个观察很直观,在初始阶段一样,策略模型和SFT模型表现出非常相似,而采样数据仅显示出较小的差异。但是,在后期,从策略模型中采样的数据将显示出更大的差异,实时数据采样将提供更大的优势。
梯度系数
- 奖励函数分类:
- 规则型(Rule): 基于答案正确性判断
- 模型型(Model): 训练奖励模型打分
- GRPO vs Online RFT:
- GRPO可根据奖励值大小调整梯度系数
- Online RFT对正确答案使用统一强度增强
- GRPO+PS vs GRPO+OS
- GRPO+PS的性能更好,表明使用细粒度,渐变的梯度系数的好处。
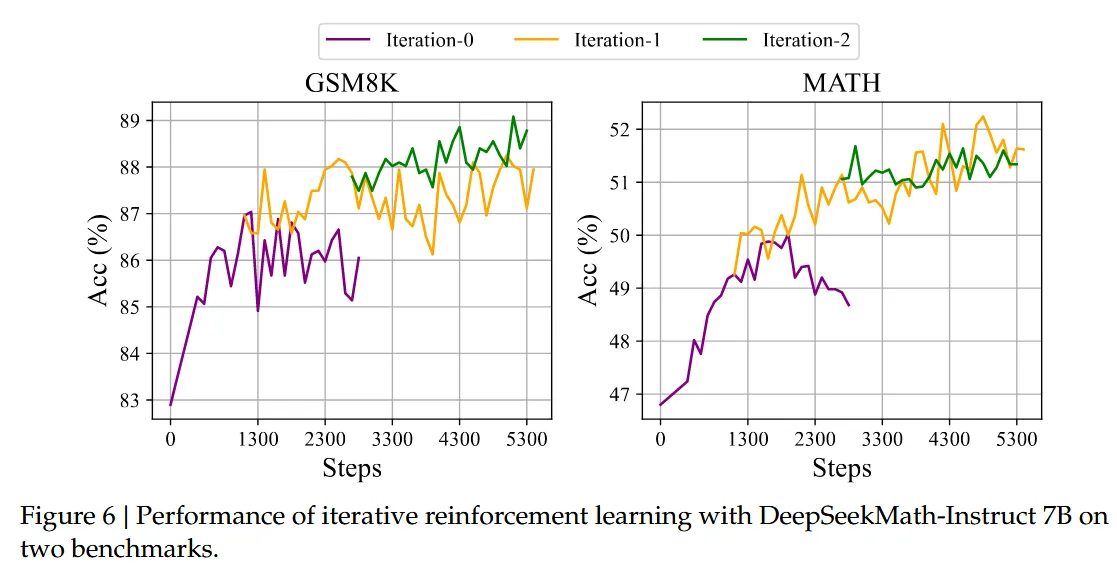
- 此外,我们探索了迭代RL,在我们的实验中,我们进行了两轮迭代。如下图所示,我们注意到迭代RL显着提高了性能,尤其是在第一次迭代时。
为什么强化学习有效?
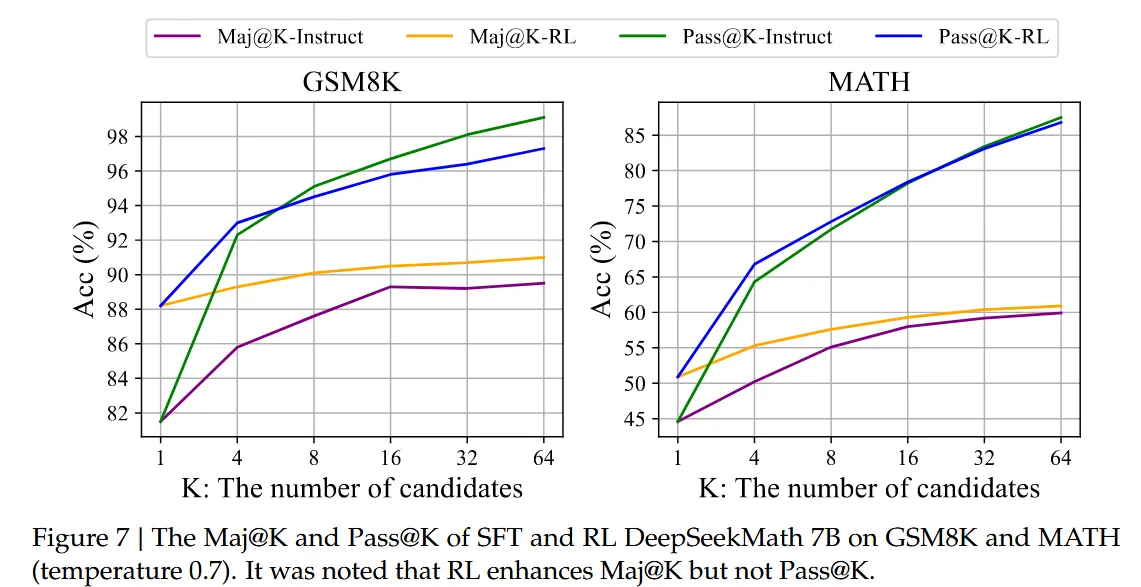
作者使用两个关键指标对Instruct模型和RL模型在两个基准测试上进行评估:
- Pass@K:模型生成K次回答中是否至少有一次正确
- Maj@K:模型生成K次回答中多数是否正确(投票机制)
实验发现: RL提高了Maj@K的性能, 但没有提升Pass@K的性能,如下图所示:
解释说明:
- RL通过使输出分布更加稳健来提升模型的整体性能
- 改进主要来自于提升TopK中正确答案的比例
- 而不是模型基础能力的提升
- 其他研究者也发现了类似现象:
启示意义
- RL的作用机制:RL主要是通过改善模型输出的分布特性,使模型更倾向于产生正确答案,而不是从根本上提升模型的推理能力
- 实践指导:
- 在应用RL时应该注意其实际改进的方面, 可能需要结合其他方法来真正提升模型的基础能力
- 偏好对齐策略可能是一个重要的补充方向
这个发现对于理解强化学习在语言模型中的作用机制,以及如何更好地改进模型性能提供了重要的见解。
如何实现更有效的强化学习?
- 数据源改进
- 探索分布外问题提示
- 使用基于树搜索的高级采样策略
- 提升策略模型的探索效率
- 算法改进
- 开发对噪声奖励信号更鲁棒的算法
- 探索WEAK-TO-STRONG对齐方法
- 奖励函数改进
- 提升奖励模型的泛化能力
- 反映奖励模型的不确定性
- 构建高质量的过程奖励模型
代码理解
数据处理
首先,这里有几个关键的参数
generation_batch_size:每次生成的总样本量,默认为:per_device_train_batch_size * num_processes * steps_per_generationsteps_per_generation:生成一次后,训练的steps数量,默认为:gradient_accumulation_stepsnum_generation:每个prompt生成的答案数量,也就是G,一组的输出数量
举例来说:
────────────────────────────────────────────────────────────────────
• per_device_train_batch_size = 3 (每个GPU每step处理3个样本)
• num_gpus = 2 (2个GPU) • num_generations = 2 (每个prompt生成2个响应)
• steps_per_generation = 4 (生成一次后训练4个steps)
• gradient_accumulation_steps = 2 (梯度累积2步) ────────────────────────────────────────────────────────────────────
-
train_batch_size(每个training step处理多少个样本):train_batch_size = per_device_train_batch_size × num_gpus = 3 × 2 = 6 generation_batch_size(一次生成需要多少个样本):generation_batch_size = train_batch_size × steps_per_generation = 6 × 4 = 24num_prompts_per_generation(需要多少个不同的prompts):num_prompts_per_generation = generation_batch_size / num_generations = 24 / 2 = 12
在trl官方代码这里也给了注释:(数字代表prompt的index)
#
# | GPU 0 | GPU 1 |
#
# global_step step <-───> num_generations=2
# <-───────> per_device_train_batch_size=3
# grad_accum ▲ ▲ 0 0 0 0 1 1 2 2 <- Generate for the first `steps_per_generation` (prompts 0 to 11); store the completions; use the first slice to compute the loss
# =2 ▼ | 0 1 3 3 4 4 5 5 <- Take the stored generations and use the second slice to compute the loss
# |
# | 1 2 6 6 7 7 8 8 <- Take the stored generations and use the third slice to compute the loss
# steps_per_gen=4 ▼ 1 3 9 9 10 10 11 11 <- Take the stored generations and use the fourth slice to compute the loss
#
# 2 4 12 12 13 13 14 14 <- Generate for the second `steps_per_generation` (prompts 12 to 23); store the completions; use the first slice to compute the loss
# 2 5 15 15 16 16 17 17 <- Take the stored generations and use the second slice to compute the loss