引言与背景
策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(value-based),而策略梯度方法则直接优化策略函数(policy-based),这是一个重要的进步。
当策略用函数表示时,策略梯度方法的核心思想是通过优化某些标量指标来获得最优策略。与传统的表格表示策略不同,策略梯度方法使用参数化函数 \(\pi(a|s, \theta)\) 来表示策略,其中 \(\theta \in \mathbb{R}^m\) 是参数向量。这种表示方法也可以写成其他形式,如 \(\pi_\theta(a|s)\)、\(\pi_\theta(a, s)\) 或 \(\pi(a, s, \theta)\)。
策略梯度方法具有多种优势:
- 更高效地处理大型状态/动作空间
- 具有更强的泛化能力
- 样本使用效率更高
策略表示:从表格到函数
当策略的表示从表格转变为函数时,存在以下几个关键区别:
- 最优策略的定义:
- 表格表示:最优策略是使每个状态值最大化的策略
- 函数表示:最优策略是使某些标量指标最大化的策略
- 策略更新方式:
- 表格表示:可以直接更改表格中的条目
- 函数表示:只能通过改变参数 \(\theta\) 来更新策略
- 获取动作概率:
- 表格表示:直接查表获取动作概率
- 函数表示:需要将 \((s,a)\) 输入函数计算其概率,或者输入状态 \(s\) 获取所有动作的概率
下面两张图展示了表格和函数表示策略的区别

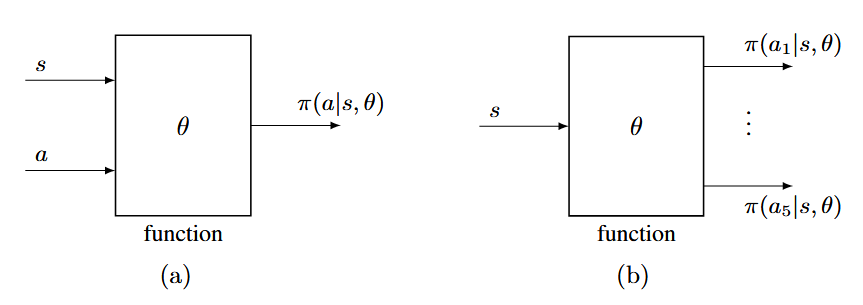
策略函数可以有不同的结构形式(如上图所示):
- 输入状态和动作 \((s,a)\),输出选择该动作的概率 \(\pi(a|s, \theta)\)
- 输入状态 \(s\),输出所有动作的概率分布 \([\pi(a_1|s, \theta), \pi(a_2|s, \theta), ..., \pi(a_n|s, \theta)]\)
策略梯度法的基本思想总结如下。假设\( J(\theta)\) 是一个标量度量。可以通过基于梯度的算法优化此指标来获得最佳策略:
定义最优策略的指标
策略梯度方法使用两类主要指标来定义最优策略
平均状态值
平均状态值定义为:
其中 \(d(s)\) 是状态 \(s\) 的权重,满足 \(d(s) \geq 0\) 且 \(\sum_{s \in S} d(s) = 1\),因此可以将 \(d(s)\) 解释为状态 \(s\) 的概率分布。
状态分布 \(d\) 的选择有两种情况:
- 独立于策略 \(\pi\) 的分布:
- 记为 \(d_0\) 和 \(\bar{v}_\pi^0\)
- 可以选择 \(d_0(s) = 1/|S|\) 使所有状态同等重要
- 或者当只关注特定状态 \(s_0\) 时,设置 \(d_0(s_0) = 1\) 且 \(d_0(s \neq s_0) = 0\)
- 依赖于策略 \(\pi\) 的分布:
- 通常选择为策略 \(\pi\) 下的稳态分布 \(d_\pi\)
- 满足 \(d_\pi^T P_\pi = d_\pi^T\),其中 \(P_\pi\) 是状态转移概率矩阵
- 稳态分布反映了马尔可夫决策过程在给定策略下的长期行为
我们的最终目标是找到一个最优策略(或等效的最优 \(θ\))来最大化 \(\bar{v}_\pi\)。
平均状态值有两个重要的等价表达式:
- 收集奖励的期望:
这个式子可以稍微推导一下就可以看出是和 \(\bar{v}_\pi\)相等的,
- 向量内积形式:
其中,
在对其分析梯度时, 这个式子非常有用。
平均奖励
第二个指标称为 average one-step reward 或者简单称为 平均奖励(average reward),定义为:
其中 \(d_\pi(s) \) 是稳定态分布,
是即时奖励的期望, \(r\left( {s,a}\right) \doteq \mathbb{E}\left\lbrack {R | s,a}\right\rbrack = \mathop{\sum }\limits_{r}{rp}(r|s,a)\)
平均奖励也有两个等价表达式:
- 单步奖励的长期平均:假设agent根据策略 \(\pi(\theta)\) 收集了奖励 \(\{R_{t+1}\}_{t=0}^\infty\),一种在论文中很常见的指标是:
这个表达式其实是和 \(\bar{r}_\pi\) 相等的:
证明 (6)
首先,我们证明对于任何起始状态 \(s_0 \in S\),以下等式成立:
证明过程如下:
我们可以将上式重写为:
最后一个等式是由于切萨罗平均(Cesaro mean)的性质:如果 \(\{a_k\}{k=1}^{\infty}\) *是一个收敛序列,使得 \(\lim{k \to \infty} a_k\)* 存在,那么 \(\{\frac{1}{n} \sum_{k=1}^{n} a_k\}{n=1}^{\infty}\) 也是一个收敛序列,且 \(\lim{n \to \infty} \frac{1}{n} \sum_{k=1}^{n} a_k = \lim_{k \to \infty} a_k\)。
接下来,我们更仔细地分析 \(\mathbb{E}[R_{t+1} | S_0 = s_0]\)。根据全期望定律:
其中 \(p^{(t)}(s|s_0)\) 表示从 \(s_0\) 恰好经过 \(t\) 步转移到 \(s\) 的概率。由于马尔可夫无记忆性质(下一步获得的奖励仅依赖于当前状态而非之前的状态),上式可简化为:
注意到,当 \(t \to \infty\) 时,\(p^{(t)}(s|s_0) \to d_\pi(s)\),这是由稳态分布的定义决定的。因此:
这表明起始状态 \(s_0\) 不再重要,系统最终会收敛到稳态分布,使得长期平均收益等于平均奖励 \(\bar{r}_\pi\)。
现在考虑任意状态分布
现在,我们考虑一个任意的状态分布 \(d\)。根据全期望定律:
由于已经证明了结果对任何起始状态都成立,我们有:
这完成了证明。
这个证明表明,无论系统从哪个状态开始,长期平均收益都会收敛到平均奖励 \(\bar{r}_\pi\)。这一结果非常重要,因为:
- 它证明了平均奖励 \(\bar{r}_\pi\) 是一个合理的优化目标,因为它代表了策略 \(\pi\) 下系统的长期性能。
- 它表明在无折扣设置下(\(\gamma = 1\)),我们可以使用平均奖励作为优化目标,而不必担心初始状态分布。
- 这个结果为策略梯度方法提供了理论基础,使我们能够使用梯度上升算法来优化平均奖励。
- 切萨罗平均的使用表明,即使在短期内系统行为可能变化很大,但长期平均行为会收敛到一个稳定值。
- 向量内积形式:
其中,
两个指标之间的关系
指标的等价性
在折扣情况下(\(\gamma < 1\)),两个主要指标 \(\bar{v}_\pi\)和 \(\bar{r}_\pi\) 是等价的,它们之间存在以下关系:
这个等式表明这两个指标可以同时最大化。也就是说,最大化平均状态值 \(\bar{v}_\pi\)的策略也会最大化平均奖励\(\bar{r}_\pi\),反之亦然。这个等式的证明在后面的引理给出。
指标的不同表达式
下表总结了 \(\bar{v}_\pi\) 和 \(\bar{r}_\pi\) 这两个指标的不同但等价的表达式:
指标 | 表达式1 | 表达式2 | 表达式3 |
|---|---|---|---|
\(\bar{v}_\pi\) | \(\sum_{s \in S} d(s)v_\pi(s)\) | \(\mathbb{E}_{S \sim d}[v_\pi(S)]\) | \(\lim_{n \to \infty} \mathbb{E}[\sum_{t=0}^n \gamma^t R_{t+1}]\) |
\(\bar{r}_\pi\) | \(\sum_{s \in S} d_\pi(s)r_\pi(s)\) | \(\mathbb{E}_{S \sim d_\pi}[r_\pi(S)]\) | \(\lim_{n \to \infty} \frac{1}{n} \mathbb{E}[\sum_{t=0}^{n-1} R_{t+1}]\) |
这些不同的表达式提供了对这些指标的不同理解视角:
- 表达式1展示了指标作为状态值或即时奖励的加权平均
- 表达式2将指标表示为期望形式
- 表达式3将指标与长期累积奖励联系起来
这里还有几点值得说明的是:
- 我们有时使用 \(\bar{v}_\pi\) 特指状态分布为稳态分布 \(d\pi\) 的情况,而使用 \(\bar{v}_\pi^0\) 指代状态分布 \(d_0\) 独立于策略 \(\pi\) 的情况。这种区分在推导梯度时很重要,因为不同的状态分布会导致不同的梯度表达式。
- 所有这些指标都是策略 \(\pi\) 的函数。由于策略 \(\pi\) 由参数 \(\theta\) 参数化,因此这些指标都是 \(\theta\) 的函数。换句话说,不同的 \(\theta\) 值会生成不同的指标值。因此,我们可以搜索最优的 \(\theta\) 值来最大化这些指标。这就是策略梯度方法的基本思想。
- 策略梯度方法的核心是将策略性能指标表示为参数 \(\theta\) 的函数,然后通过优化 \(\theta\) 来最大化这些指标。这些指标虽然表达形式不同,但在本质上是等价的,都衡量了策略的长期性能。
策略梯度定理
策略梯度定理是本文最重要的理论结果,它给出了目标函数 \(J(\theta)\) 的梯度:
策略梯度定理:\(J(\theta)\) 的梯度为\[\begin{equation}\nabla_\theta J(\theta) = \sum_{s \in S} \eta(s) \sum_{a \in A} \nabla_\theta \pi(a|s, \theta) q_\pi(s, a)\tag{8}\end{equation}\]
其中 \(\eta\) 是状态分布,其紧凑形式为:\[\begin{equation}\nabla_\theta J(\theta) = \mathbb{E}_{S \sim \eta, A \sim \pi(S,\theta)}[\nabla_\theta \ln \pi(A|S, \theta) q_\pi(S, A)]\tag{9}\end{equation}\]
关于策略梯度定理的几点重要说明:
- 策略 \(\pi(a|s,\theta)\) 必须对所有 \((s,a)\) 为正,以确保 \(\ln \pi(a|s,\theta)\) 有效。这可以通过使用 softmax 函数实现:
- 由于 \(\pi(a|s,\theta) > 0\),策略是随机的,因此具有探索性。策略不直接告诉采取哪个动作,而是根据策略的概率分布生成动作。
这个技巧被称为"对数梯度技巧"(log-derivative trick)或"得分函数梯度"(score function gradient),它是策略梯度方法的核心技术之一。
最后一步是将内层求和转换为关于策略 \(\pi(S,\theta)\) 的期望。这是因为当我们从分布 \(\pi(a|S,\theta)\) 中采样动作 \(A\) 时,期望 \(\mathbb{E}_{A \sim \pi(S,\theta)}[f(A)]\) 可以写为 \(\sum_{a \in A} \pi(a|S,\theta) f(a)\)
- 策略 \(\pi(a|s,\theta)\) 必须对所有 \((s,a)\) 为正,以确保 \(\ln \pi(a|s,\theta)\) 有效。这可以通过使用 softmax 函数实现:
其中 \(h(s,a,\theta)\) 是表示在状态 \(s\) 选择动作 \(a\) 的偏好的函数。该策略可以由神经网络实现。网络的输入为\(s\)。输出层是一个softmax,因此网络对于所有 \(a\) 的输出\(\pi(a|s,\theta)\),输出的总和等于1。
- 由于 \(\pi(a|s,\theta) > 0\),策略是随机的,因此具有探索性。策略不直接告诉采取哪个动作,而是根据策略的概率分布生成动作。
蒙特卡罗策略梯度(REINFORCE)
有了策略梯度定理,我们可以使用梯度上升算法来最大化目标函数 \(J(\theta)\):
其中 \(\alpha > 0\) 是学习率。
由于真实梯度未知,我们可以用随机梯度替代:
其中 \(q_t(s_t, a_t)\) 是 \(q_\pi(s_t, a_t)\) 的近似值。如果 \(q_t(s_t, a_t)\) 通过蒙特卡罗估计获得,该算法称为REINFORCE或蒙特卡罗策略梯度。

这个算法非常重要,因为许多其他策略梯度算法都可以通过扩展它来获得。接下来,我们更仔细地解释这个算法。
由于 \(\nabla_\theta \ln \pi(a_t|s_t, \theta_t) = \frac{\nabla_\theta \pi(a_t|s_t,\theta_t)}{\pi(a_t|s_t,\theta_t)}\),我们可以将(13)重写为:
令 \(\beta_t = \frac{q_t(s_t, a_t)}{\pi(a_t|s_t, \theta_t)}\),上式可以简洁地写为:
从这个重写的形式中,可以得出两个重要解释:
- 策略概率的调整
由于(14)是一个简单的梯度上升算法,我们可以得到以下观察结果:
- 如果 \(\beta_t \geq 0\),选择 \((s_t, a_t)\) 的概率会增强,即:
\(\beta_t\) 越大,增强效果越强。
- 如果 \(\beta_t < 0\),选择 \((s_t, a_t)\) 的概率会减少,即:
这些观察可以通过泰勒展开来证明。当 $\theta_{t+1} - \theta_t$ 足够小时,有:
代入 (14)得:
显然,当 \(\beta_t \geq 0\) 时,\(\pi(a_t|s_t, \theta_{t+1}) \geq \pi(a_t|s_t, \theta_t)\);当 \(\beta_t < 0\) 时,\(\pi(a_t|s_t, \theta_{t+1}) < \pi(a_t|s_t, \theta_t)\)。
- 探索与利用的平衡
算法可以在一定程度上平衡探索和利用,这是由于 \(\beta_t\) 的表达式:
从这个表达式可以看出:
- 利用方面:\(\beta_t\) 与 \(q_t(s_t, a_t)\) 成正比。因此,如果动作 \(q(s_t, a_t)\) 的值较大,则 \(\pi(a_t|s_t, \theta_t)\) 会增强,从而增加选择该动作的概率。这表明算法倾向于利用价值更高的动作。
- 探索方面:当 \(q_t(s_t, a_t) > 0\) 时,\(\beta_t\) 与 \(\pi(a_t|s_t, \theta_t)\) 成反比。因此,如果选择动作 \(a_t\) 的概率较小,则 \(\pi(a_t|s_t, \theta_t)\) 会增强,从而增加选择该动作的概率。这表明算法倾向于探索低概率的动作。
采样问题
由于(13)使用样本来近似(12)中的真实梯度,理解样本应该如何获取非常重要:
- 状态\(S\)的采样
真实梯度 \(\mathbb{E}[\nabla_\theta \ln \pi(A|S, \theta_t)q_\pi(S, A)]\) 中的 \(S\) 应该遵循分布 \(\eta\),这可能是稳态分布 \(d_\pi\) 或折扣总概率分布 \(\rho_\pi\)。这些分布代表了策略 \(\pi\) 下的长期行为。 - 动作\(A\)的采样
\(\mathbb{E}[\nabla_\theta \ln \pi(A|S, \theta_t)q_\pi(S, A)]\) 中的 \(A\) 应该遵循分布 \(\pi(A|S, \theta)\)。理想的采样方式是按照 \(\pi(a|s_t, \theta_t)\) 选择 \(a_t\)。因此,策略梯度算法是在策略(on-policy)的。
然而,在实践中,由于样本使用效率低,这些理想的采样方式通常不被严格遵循。算法9.1提供了一种更高效的实现方式,先生成一个完整episode,然后使用episode中的每个样本多次更新 \(\theta\)。