SigLIP
概述
CLIP自提出以来在zero-shot分类、跨模态搜索、多模态对齐等多个领域得到广泛应用。得益于其令人惊叹的能力,激起了研究者广泛的关注和优化。
目前对CLIP的优化主要可以分为两大类:
- 其一是如何降低CLIP的训练成本;
- 其二是如何提升CLIP的performance。
对于第一类优化任务的常见思路有3种。
- 优化训练架构,如 LiT 通过freezen image encoder,单独训练text encoder来进行text 和image的对齐来加速训练;
- 减少训练token,如 FLIP 通过引入视觉mask,通过只计算非mask区域的视觉表征来实现加速(MAE中的思路)
- 优化目标函数,如 CatLIP 将caption转为class label,用分类任务来代替对比学习任务来实现加速。
对于第二类提升CLIP的performance最常用和有效的手段就是数据治理,即构建高质量、大规模、高多样性的图文数据,典型的工作如:DFN。
SigLIP这篇paper提出用sigmoid loss来做图文对比训练。这个方案既能降低训练成本,在小batch下(低于32k)performance也优于传统方法。
方法
对于经典的softmax-based优化目标InfoNCE,其核心思路是让positive的图文对的距离越近越好,让negative图文对的距离越远越好,计算公式如下:
其中: \(\mathbf { x } _ { i } = \frac { f ( I _ { i } ) } { \| f ( I _ { i } ) \| _ { 2 } }\) \(\mathbf { y } _ { i } = \frac { g ( T _ { i } ) } { \| g ( T _ { i } ) \| _ { 2 } }\), \(f(\cdot)\)和\(g(\cdot)\)分别为视觉和文本的编码器
InfoNCE的缺点
- softmax的计算存在数值不稳定的问题,需要引入额外的trick保证softmax的计算稳定性。
- 计算量大。softmax loss的非对称(asymmetry),需要做了两次normalization,即\(\sum _ { j = 1 } ^ { | \mathcal { B } | } e ^ { t \mathbf { x } _ { j } \cdot \mathbf { y } _ { i } } \neq \sum _ { j = 1 } ^ { | \mathcal { B } | } e ^ { t \mathbf { x } _ { i } \cdot \mathbf { y } _ { j } } \)。并且计算稳定性的trick也需要引入额外的计算量。
- 显存占用大,由于要计算normalize,需要维护一个很大的概率分布矩阵。假定batch size为32k,那么这个概率分布矩阵的大小为\(32k \times 32k\)
下面来看文本提出的sigmoid loss 。其定义如下:
从上式可见,Sigmoild loss将每对图文对独立看待。即分别将每对图文对做二分类。
- \((I_i, T_i)\)为正例。
- \((I_i, T_{j, j\neq i})\)为负例。
(2)中,\(z _ { i j }\)为图文对的标签,1表示是正例,-1表示是负例。直观来看,上式明显存在正负样本不均衡的问题,batch size为\(\mathcal{B}\) 时,正例数为\(\mathcal{B}\),负例数为 \(|\mathcal{B}|^ 2 - |\mathcal{B}|\)。为了缓解正负样本不均衡,作者引入两个learnable parameter \(t,b\) 来调节正负例的梯度,\(t\) 调节梯度敏感度, \(b\) 补偿样本数量差异,初始时 \(t=\log 10, b=−10\).

多卡场景下,可以用(3)的通信策略实现高效训练。

实验
The influence of batch size
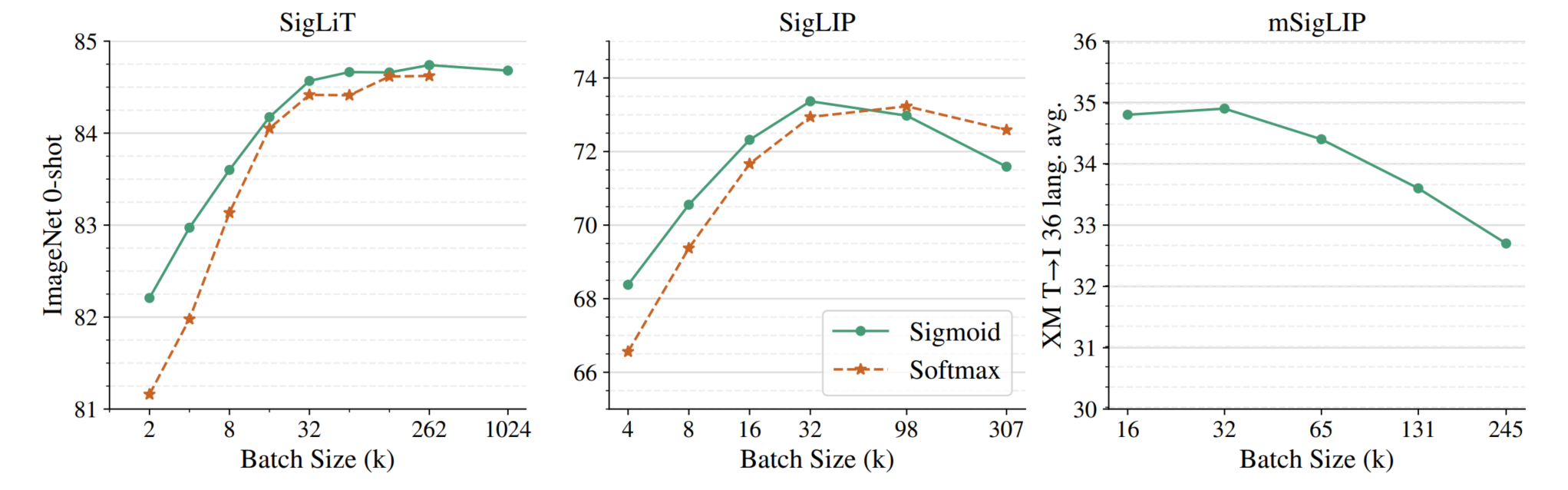
在之前的研究表明:对比学习的batch size越大,效果越好。但之前的研究受限成本,最大只研究到64k。这篇paper将batch size扩大到1M。结果表明,当batch size达到32k,继续扩大的收益就很低了,达到256k后,收益达到顶峰。随后根据上述经验,作者对比了sigmoid和softmax的scale up batch size的能力,有以下几点核心结论:
- sigmoid loss相比softmax loss更节约显存。用sigmoid loss时,4张TPU-v4能够容纳4096个batch size,但若用softmax,batch size只能容纳2048。
- 在小batch下(batch size低于32k)sigmoid-based明显优于softmax-based loss,随着batch size进一步增加,二者差距逐渐减少。
The influence of positive and negative pairs ratio
对于sigmoid来说,它的loss是以pair为粒度计算的,positive和negative非常不平衡。以batch size
\(|\mathcal{B}| = 16k\)为例(有16k个图文对),只有\(16k\)个positive samples,但有 \(16k * 16k - 16k = 16k(16k-1)\) 个negative samples,其positive和negative的比率约为\(1:16k\)。
因此,有必要深入探究positive和negative的不平衡对模型的影响。得益于sigmoid loss以pair为粒度的计算方式,我们可以很方便的人为控制正负样本的比例。作者尝试了4种方式调控positive和negative的比例
- Random: 通过随机mask掉negative sample,来保证positive和negative的占比
- Hard:通过mask掉loss较低的negative sample ,来保证positive和negative的占比
- Hard, matched pair:通过mask掉loss较低的negative的sample,来保证positive和negative的占比。由于上述mask的操作,模型的可见的pair 少,此实验通过增加iteration来保证”pair seen”和原始一致。(相当于常用的resample方法)
- Easy:通过mask掉loss较高的negative sample,来保证positive和negative的占比。
作者在SigLIT上用进行以上四种mask out机制的实验。\(|\mathcal{B}| = 16k\),迭代\(\mathrm{Iter}=900M\)
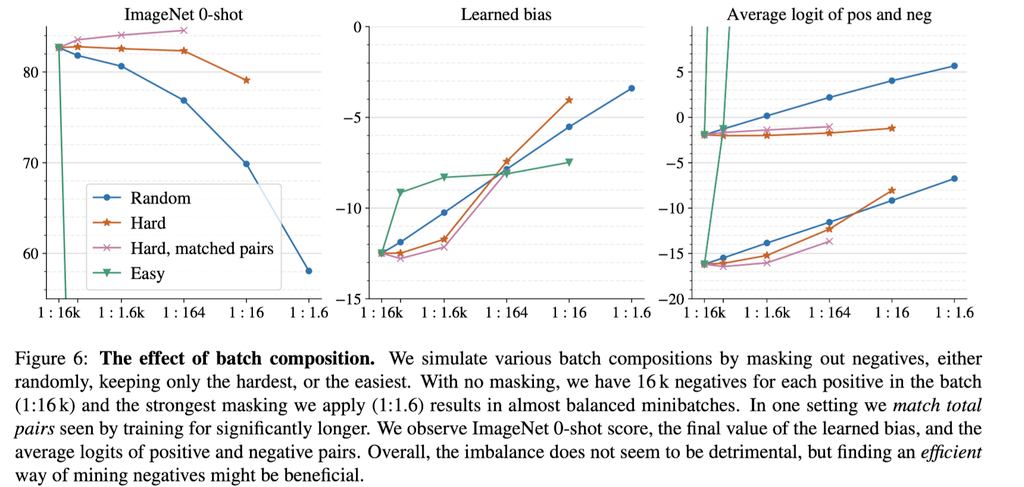
结果表明:
- 不做matched pair的情况下,用3种mask方式均会造成精度下降。影响程度:easy>random>hard。
- Hard sample mining + matched pair有助于进一步提升模型性能。
- 当正负样本的imbalance减弱时,learnable bias和pair的logit都在上升,说明了预设的learnable bias起到了积极的作用。
总体来看,得益于learnable temperature和learnable bias,sigmoid loss的正负样本不均衡基本不会导致模型性能下降。
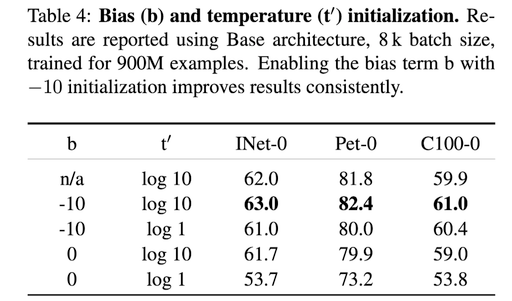
文中对这两个超参数的初始值进行了进一步实验,结果如下。(可见引入合适的prior knowledge对提升模型performance非常有效)
SigLIP2
概述
SigLIP 2基于原始SigLIP的成功进行了扩展和改进。这个新版本整合了多种独立开发的技术,形成了一个统一的训练方案,包括:
- 基于图像描述的预训练
- 自监督损失(自蒸馏、掩码预测)
- 在线数据筛选
SigLIP 2模型在所有模型规模上都优于原始SigLIP,包括零样本分类、图像-文本检索和作为视觉语言模型(VLMs)的视觉表示提取器的迁移性能。此外,新的训练方案在定位和密集预测任务上也带来了显著改进。
SigLIP 2提供以下关键优势:
- 强大的多语言视觉-语言编码器:在英语为中心的视觉-语言任务上表现出色,同时在多语言基准测试上提供强大的结果。
- 密集特征:通过自监督损失和基于解码器的损失,提供更好的密集特征(如用于分割和深度估计)并改进定位任务(如指代表达理解)。
- 向后兼容性:与SigLIP保持相同的架构,使现有用户只需简单地更换模型权重和分词器(现在是多语言的)即可在广泛任务上获得改进。
- 原生宽高比和可变分辨率:包括NaFlex变体,支持多种分辨率并保留原始图像宽高比。
- 强大的小型模型:通过主动数据筛选的蒸馏技术进一步优化了较小模型(B/16和B/32)的性能。
训练方案
基础架构、训练数据和优化器
- 架构:遵循SigLIP的架构,使用标准ViT架构和学习位置嵌入。图像和文本塔使用相同的架构,g尺寸的视觉编码器与So400m尺寸的文本编码器配对。使用MAP头(注意力池化)进行视觉和文本表示的池化。
- 文本处理:文本长度设为64,使用多语言Gemma分词器(词汇量256k),在分词前将文本转为小写。
- 训练数据:使用WebLI数据集,包含100亿图像和120亿alt文本,覆盖109种语言。混合比例为90%来自英语网页,10%来自非英语网页。应用 M4(Google 自家ICLR2024的论文) 的过滤技术,以减轻数据在敏感属性方面的表示和关联偏差。
- 优化器:使用Adam优化器,学习率\(10^{-3}\),解耦权重衰减 \(10^{-4}\),梯度裁剪至范数 1。批量大小为32k,使用余弦调度,预热步骤20k,总共训练40B样本。
使用Sigmoid损失和解码器训练
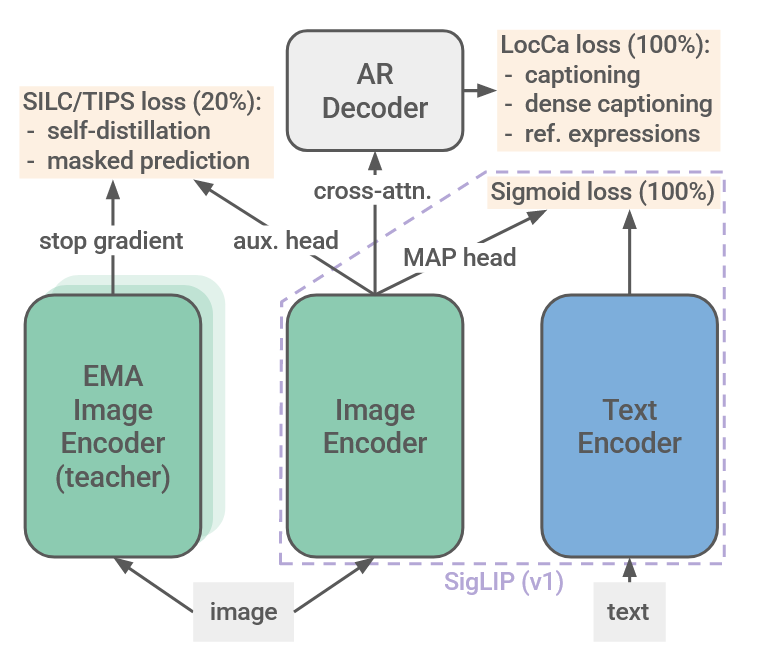
在预训练的第一步中,SigLIP 2将SigLIP与LocCa结合,简单地将两个损失函数以相等的权重组合。
目的是在siglip基础中,增加视觉(位置敏感)特征的表达能力。结构如图中右半边所示
- SigLIP损失:通过将每个图像嵌入与mini-batch中的每个文本嵌入组合,创建二元分类问题,并通过sigmoid损失训练嵌入来分类匹配和不匹配的对。
- LocCa损失:通过交叉注意力将标准transformer decoder 附加到未池化的视觉编码器表示上。解码器遵循文本编码器的形状,但添加了交叉注意力层,并将层数减少了一半。
- LocCa除了训练一个预测图像caption外,还额外增加了两个任务
- Automatic referring expression prediction:给定特定区域的caption预测bbox
- Grounded captioning:给定bbox预测区域caption
- 和传统的任务区别是,这两个额外的loss是通过 transformer decoder 自回归的方式,加入任务前缀
“ARef : {c} : {b}” for automatic referring expression and “GCap: {b} : {c}” for grounded captioning, each prefixed with “ARef :” and “GCap:” respectively.
对于所有模型大小,视觉编码器的patch大小设为16,图像分辨率为256(图像表示序列长度为256)。
使用自蒸馏和掩码预测训练
遵循SILC和TIPS的方法,在上面描述的训练设置基础上,增加了局部到全局对应学习,包括自蒸馏和掩码预测损失,以改进(未池化的)特征表示的局部语义。结构如图中左半边所示,具体添加了两个损失项:
- 局部到全局一致性损失(SILC ):视觉编码器成为学生网络,接收训练图像的部分(局部)视图,并训练以匹配教师的表示(来自完整图像)。教师参数是学生参数在之前迭代中的指数移动平均(EMA)。使用1个全局(教师)视图和8个局部(学生)视图。
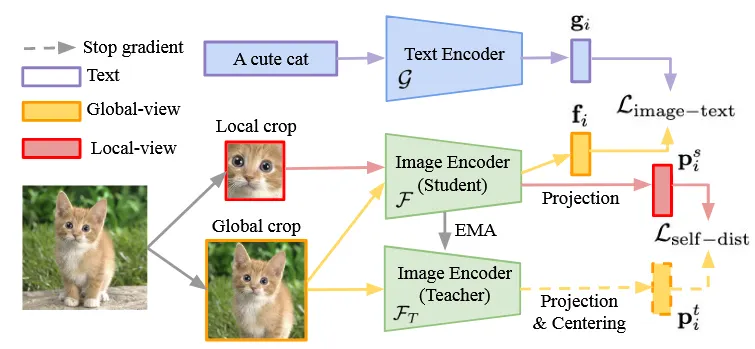
- 图像-文本对比损失(\(L_{image-text}\)):对齐图像和文本表示
- 在图像编码器顶部添加一个projector作为可学习的 MLP,以从维度 \(J\) 的原始共享嵌入空间映射到\(K\),其中\(K > J\)。
- 教师模型的参数基于动量编码器(momentum encoder),通过EMA更新: \[\mathcal{F}_T\leftarrow\lambda\mathcal{F}_T+(1-\lambda)\mathcal{F}_S\]
- 自蒸馏损失(\(L_{self-dist}\)):利用教师模型指导学生模型学习更好的视觉表示, 以知识蒸馏损失的形式实现:
其中学生和教师的特征向量首先通过应用 softmax 转换为概率分布, \({P}_t(I_i^{gl})=\text{softmax}((p_i^t-c)/\tau_t)\),\({P}_s(I_i^{gc})=\text{softmax}((p_i^s)/\tau_s)\)
- 掩码预测目标(TIPS):在学生网络中将50%的嵌入图像块替换为掩码标记,并训练学生以匹配教师在掩码位置的特征。
这些损失在训练完成80%时添加,使用原始图像计算SigLIP和LocCa损失,在额外的增强视图上应用额外的损失。第一和第二损失项的权重分别设为1和0.25,并根据模型大小进一步重新加权。
适应不同分辨率
- 固定分辨率
为了获得多个分辨率固定的checkpoint,在训练的95%时的checkpoint恢复(序列长度256,patch大小16),将位置嵌入调整为目标序列长度(在某些情况下,使用伪逆(pseudoinverse)调整策略将patch嵌入从patch大小16调整为14),然后在目标分辨率下使用所有损失恢复训练。
- 可变宽高比和分辨率(NaFlex)
NaFlex结合了FlexiViT(支持单个ViT模型的多种预定义序列长度)和NaViT(以原生宽高比处理图像)的思想。这使得能够以适当的分辨率处理不同类型的图像,同时最小化宽高比失真对某些推理任务的影响。
给定patch大小和目标序列长度,NaFlex预处理数据的步骤:
- 调整输入图像大小,使得调整后的高度和宽度是patch大小的倍数
- 同时保持宽高比失真尽可能小
- 并保证产生的序列长度最多为所需的目标序列长度
调整大小后,图像被分割成一系列patch,并添加patch坐标和带有填充信息的掩码。
为了处理不同的序列长度(和宽高比),对学习的位置嵌入进行双线性调整大小(带抗锯齿),以适应调整大小后的输入图像的目标非方形patch网格。
对于 NaViT和FlexiViT的具体细节可以参考:ViT系列
通过主动数据筛选进行蒸馏
为了最大化最小的固定分辨率模型(ViT-B/16和ViT-B/32)的性能,在简短的微调阶段从教师(参考)模型中蒸馏知识。降低学习率至\(10^-5\),移除权重衰减,仅使用sigmoid图像-文本损失继续训练这些模型额外4B样本。
在这个阶段,使用ACID方法通过"数据蒸馏"进行隐式蒸馏。在每个训练步骤中,教师模型和当前学习者模型用于根据样本的"可学习性"(ACID)对样本进行评分。然后使用这些分数从更大的btach中联合选择最佳的32k大小的批次。
实验
SigLIP 2发布了四种大小的模型检查点:
- ViT-B (86M参数)
- ViT-L (303M参数)
- ViT-So400m (400M参数)
- ViT-g (1B参数)
在ImageNet-1k验证集上的零样本分类准确率:
- B/16 (256px): 79.1%
- L/16 (256px): 82.5%
- So/16 (256px): 83.4%
- g/16 (256px): 84.5%
在COCO图像→文本检索上的Recall@1:
- B/16 (256px): 69.7%
- L/16 (256px): 71.5%
- So/16 (256px): 71.5%
- g/16 (256px): 72.5%
SigLIP2 in VLM
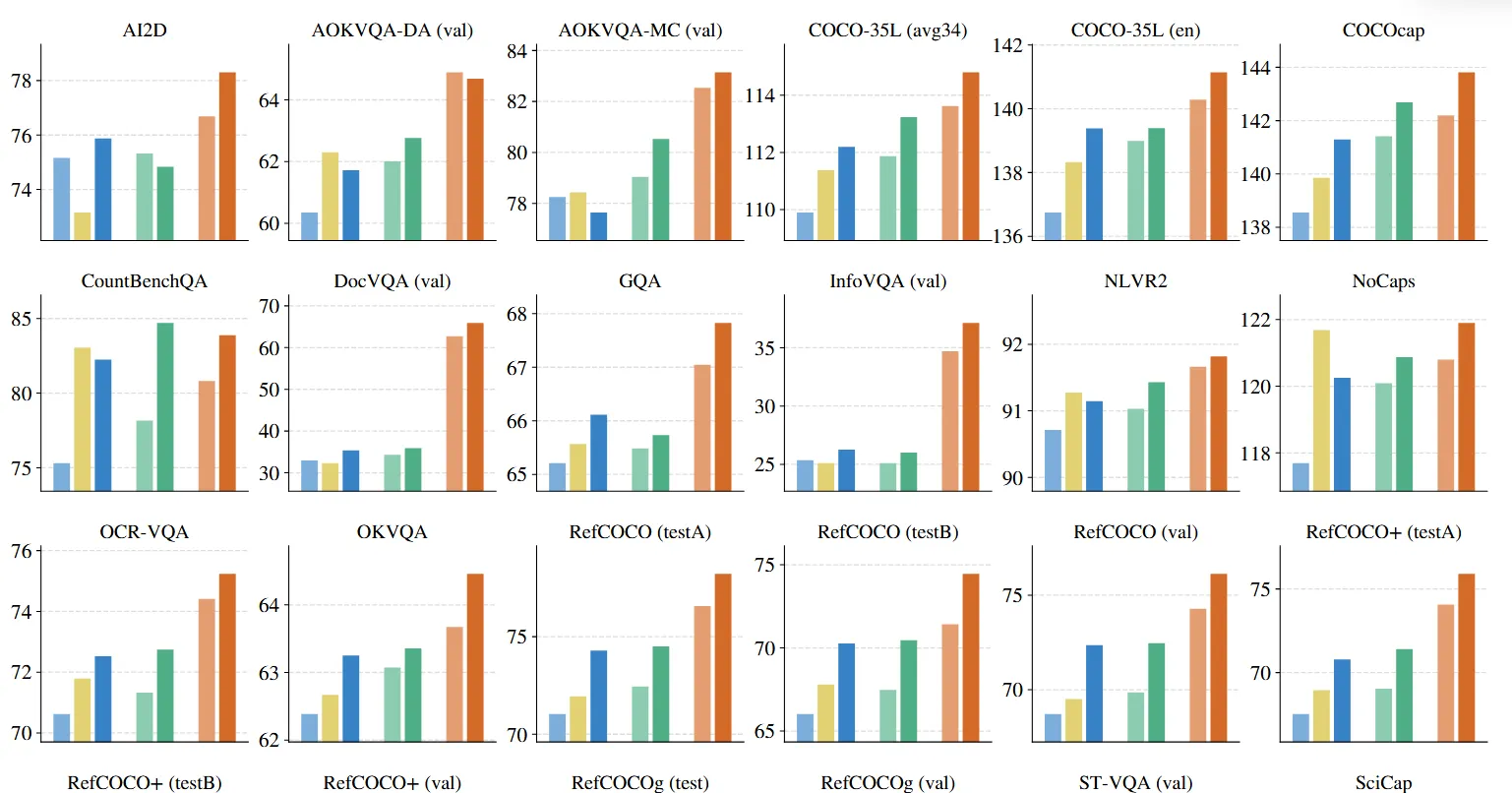
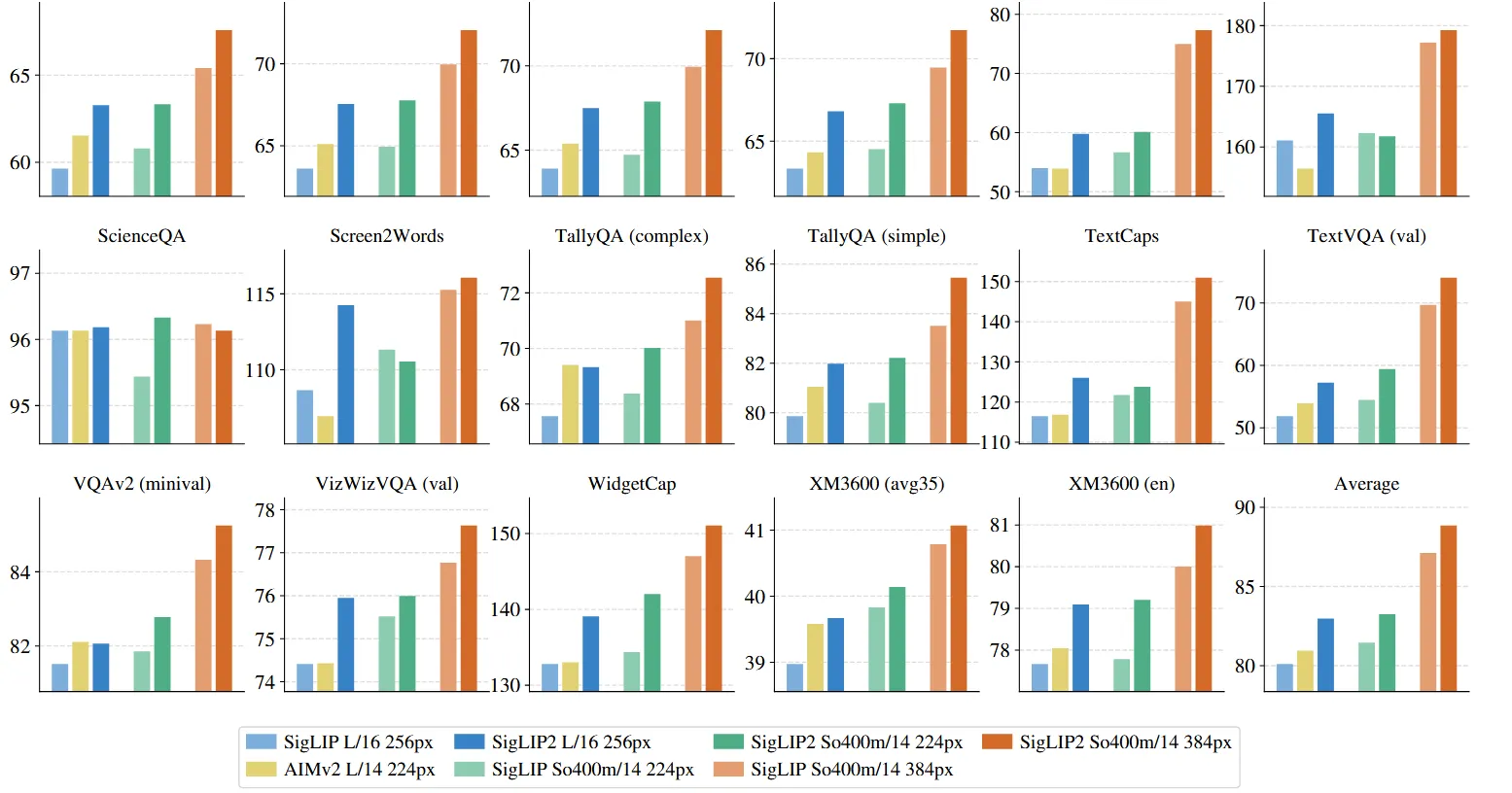
CLIP 和 SigLIP 等视觉编码器的一个常见用例是提取 VLM 的视觉表示。通用范式将预训练的视觉编码器与预训练的 LLM 相结合,并对丰富的视觉语言任务组合进行多模态训练。为了评估 SigLIP 2 在该应用中的性能,作者开发了一种类似于 PaliGemma 2 的配方。具体来说,我们将使用 Gemma 2 2B 和SigLIP 2 视觉编码器训练,并在第 1 阶段训练组合的 50M 示例上训练 LLM,包括 Caption、OCR、Grounded Caption、视觉问答、检测和实例分割。保持视觉编码器处于冻结状态(这基本上对质量没有影响 ,参考PaliGemma)并缩短训练持续时间。生成的 VLM 在下游任务中进行微调,为了了解输入分辨率的效果,我们在分辨率 224 或 256(对于补丁大小分别为 14 和 16 的模型,以提取 256 个图像token)和 384px 下进行实验,但与 PaliGemma 不同的是,在 384px 处重复阶段 1,而不是从 224px 变体开始。 下图 显示了每个数据集微调后的结果。总体而言,SigLIP 2 在分辨率和模型大小方面明显优于 SigLIP。对于 L 型视觉编码器,SigLIP 2 的性能也优于最近发布的 AIMv2 。
结论
SigLIP 2通过整合多种技术,包括基于解码器的预训练、自监督损失和主动数据筛选,在零样本分类、作为VLM视觉编码器的迁移性能以及定位和密集预测任务方面取得了显著改进。此外,由于在多语言数据上训练并应用去偏滤波器,SigLIP 2在文化多样性数据上实现了更平衡的质量。最后,NaFlex变体使模型能够支持单个模型检查点的多种分辨率,同时保留原始图像宽高比。