InternVL Blog:https://internvl.github.io/blog/
Github: https://github.com/OpenGVLab/InternVL
InternVL 1.0
对齐策略
语言模型和视觉模型各自发展,各有突破,但如何让语言模型会看图,或者让视觉模型会说话?为了将视觉模型与语言模型进行连接,对齐如同“胶水”,将两种模型链接在一起,如使用QFormer或线性投影这样的轻量级“胶水”层,来形成视觉-语言模型,如InstructBLIP和LLaVA,但均存在局限性。
现有对齐策略的局限性
- 参数规模的不一致:LLM的参数规模已经达到1000亿,而广泛使用的VLLM的视觉编码器仍在10亿参数左右。这种差距可能导致LLM的能力无法被充分利用。
- 特征表示的不一致:在纯视觉数据上训练的视觉模型或与BERT系列对齐的模型往往与LLM存在表示上的不一致。
- 连接效率低下:“胶水”层通常是轻量的、随机初始化的,可能无法捕捉到多模态理解和生成所需的丰富的跨模态交互和依赖关系。
InternVL引入全新的对齐策略
渐进式的对齐训练策略,从海量噪声数据上的对比学习开始,逐渐过渡到高质量数据上的生成式学习。通过这种方式,我们充分利用了互联网上各种来源的海量图像-文本对数据,得到了经过良好对齐的视觉编码器和语言中间件。 细节将在下文详解。
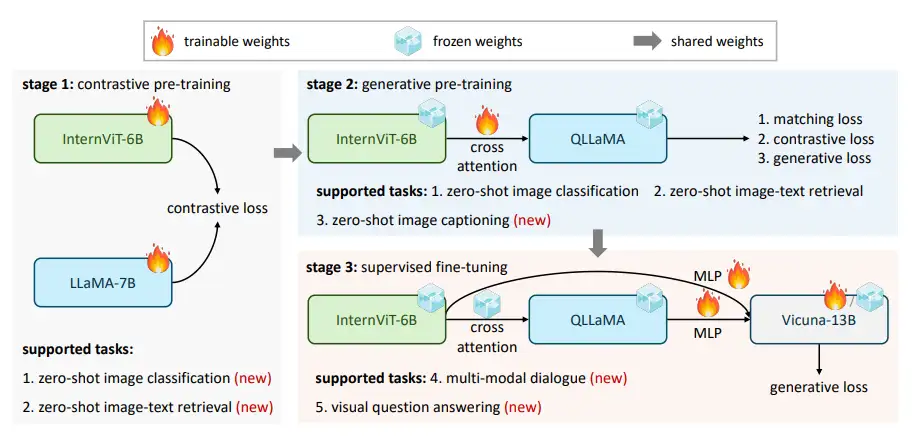
InternVL方法与模型详解
如图所示,与传统的仅使用视觉骨干网络的方法以及双编码器的模型不同,我们提出的InternVL包含了一个视觉编码器InternViT-6B和一个语言中间件QLLaMA。
- InternViT-6B:60亿参数的ViT模型,通过自定义结构超参数,实现了性能、效率和稳定性之间的良好平衡。
- QLLaMA: 80亿参数的语言中间件,使用多语言增强的LLaMA-7B进行初始化。它可以为图像-文本对的对比学习提供鲁棒的多语言表示,或者作为连接视觉编码器和现有的LLM解码器的桥梁。
配合全新的渐进式对齐策略,形成了InternVL强大的的视觉-语言多模态能力。
Part1. 模型设计
大规模视觉编码器: InternViT-6B
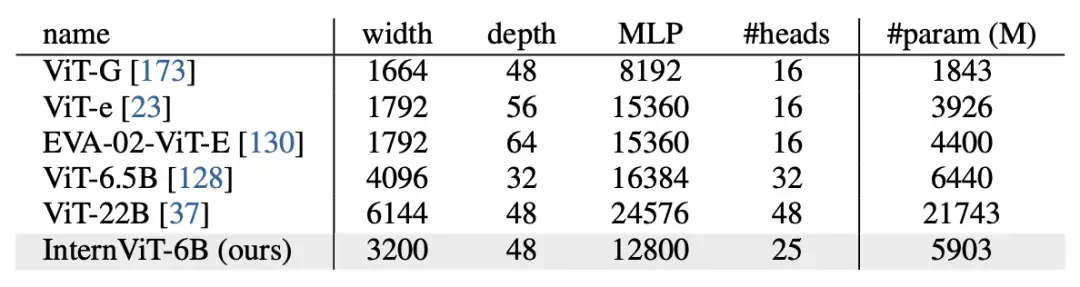
我们基于原始ViT结构来构建InternVL的视觉编码器。为了与LLM的规模相匹配,我们将视觉编码器扩大到了60亿参数,从而得到了InternViT-6B模型。为了在准确性、速度和训练稳定性之间取得较好的权衡,我们对InternViT-6B进行了超参数搜索,主要包括模型深度(32,48,64,80)、注意力头的维度(64,128),以及MLP的比率(4,8)。我们在LAION-en数据集的一个100M子集上,使用对比学习来对比各种6B模型变体的准确性、速度和稳定性,通过实验最终确定了现在的模型结构。
语言中间件: QLLaMA
语言中间件QLLaMA旨在进一步对齐视觉和语言特征。QLLaMA在上一阶段LLaMA权重的基础之上,额外添加了随机初始化的96个可学习Query以及交叉注意力层(共有10亿参数)。通过这种方式,QLLaMA可以将视觉特征平滑地整合到语言模型中,从而进一步增强了视觉特征与语言特征的对齐程度。**这里是BLIP2的做法 **
Part2. 渐进式对齐策略
InternVL的对齐分为三个渐进式阶段,包括视觉-语言对比训练、视觉-语言生成训练和有监督微调(SFT)。这些阶段有效地利用了互联网上不同来源的开源数据。通过这种策略,我们的训练从带有噪声的图像-文本对逐渐过渡到高质量的标题、视觉问答和多模态对话数据集。
第一阶段,我们通过对比学习将InternViT-6B与多语言的LLaMA-7B对齐,使用海量的公开多语言图文对数据集,包括LAION-en、LAION-multi、LAION-COCO、COYO、Wukong等。我们对这些数据集进行轻微的过滤来剔除极端异常数据。原始数据集总共包含60.3亿图文对,经过清理后(包括剔除下载失败的样本)剩下49.8亿图文对。
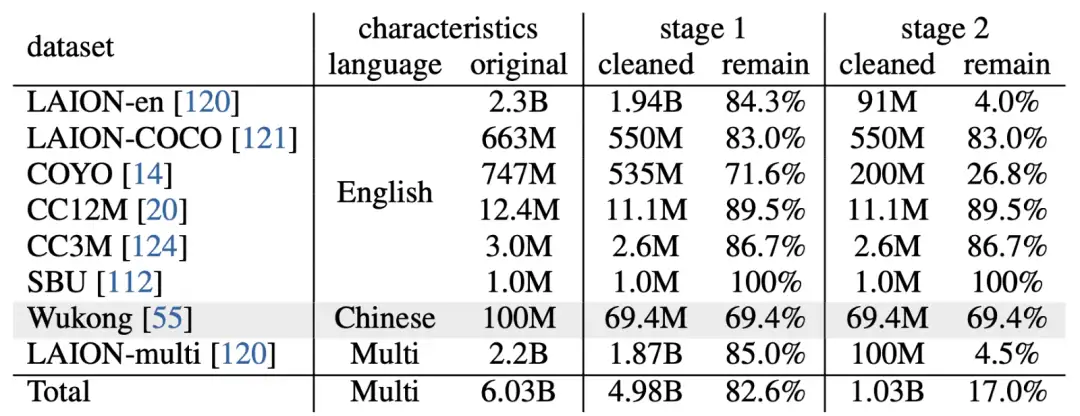
第二阶段,我们通过交叉注意力来连接InternViT-6B和QLLaMA,并采用生成式的训练策略。具体来说,QLLaMA 继承了第一阶段的LLaMA-7B的权重。我们保持 InternViT-6B 和 QLLaMA 的权重不变,只训练添加的可学习Query和交叉注意力层。在这一阶段,我们根据文本的质量进一步过滤了低质量的数据,将其从第一阶段的49.8亿个图文对减少到10.3亿个图文对。 这一阶段的损失函数由图文对比损失(ITC)、图文匹配损失(ITM)和图像引导的文本生成损失(ITG)组成。这使得Query能够提取鲁棒的视觉表示,并与以LLM为初始化的QLLaMA进一步对齐特征空间。
有监督微调(SFT)
为了展示InternVL在创建多模态对话系统方面的有效性,我们将其与现有的LLM解码器(例如,Vicuna或InternLM)通过一个MLP层连接,并进行有监督微调(SFT)。我们在互联网上收集了一系列高质量的指令数据,总共包含约为400万个样本。对于非对话数据集,我们参考LLaVA-1.5的方法进行格式转换。由于QLLaMA和LLM解码器具有相似的特征空间,即使冻结LLM解码器,选择仅训练MLP层,我们仍然可以实现不错的性能。这种方法不仅加快了SFT的速度,还保持了LLM的原始语言能力。
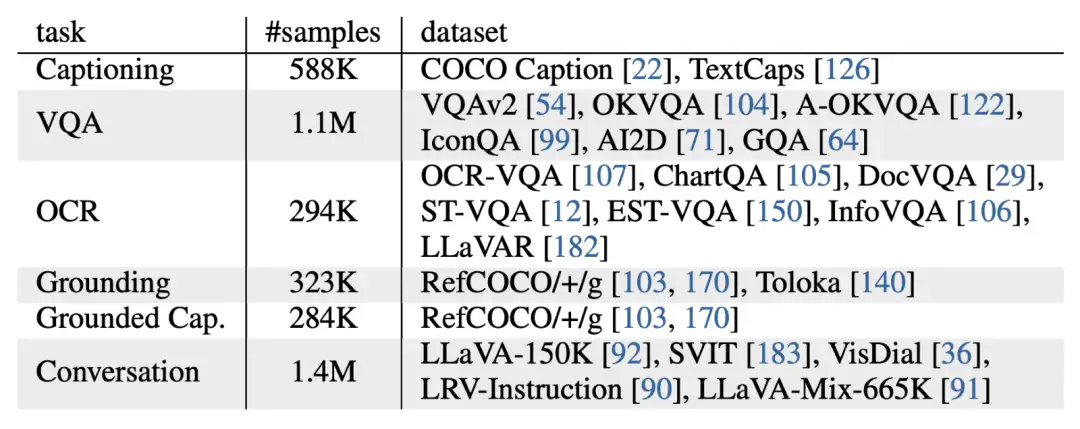
模型使用
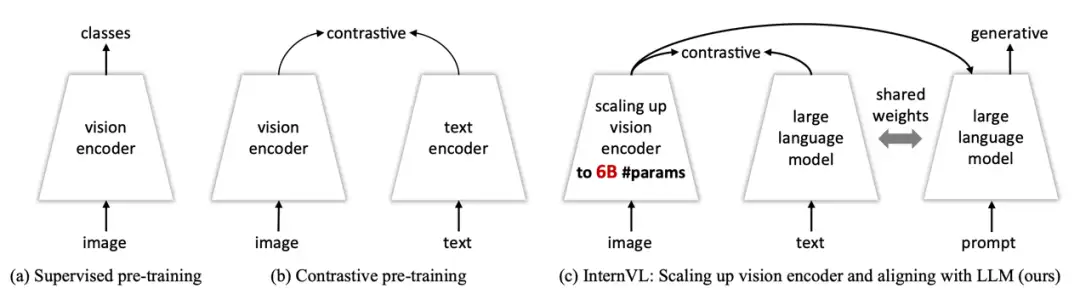
InternVL的不同使用方式通过灵活组合视觉编码器和语言中间件,InternVL可以支持各种视觉或视觉-语言任务,堪称“瑞士军刀”版基础模型 ,你可以用它:
1.做纯视觉任务的主干网络:InternViT-6B可以替代ViT、ResNet,直接作为骨干网络;
2.替代CLIP:对于对比式任务,我们有两种使用方式,分别是InternVL-C(ontrastive)和InternVL-G(enerative),如图4(a)(b)所示。我们对InternViT-6B的输出特征或者QLLaMA的Query特征做attention pooling得到视觉特征,将QLLaMA的EOS token对应的特征作为文本特征,从而可以支持图文检索等任务;
3.用在LLaVA等视觉对话模型上:对于多模态对话,我们将InternVL作为视觉特征提取器:既可以单独使用InternViT-6B,也可以上图(c)(d)所示,将InternViT-6B与QLLaMA作为整体。
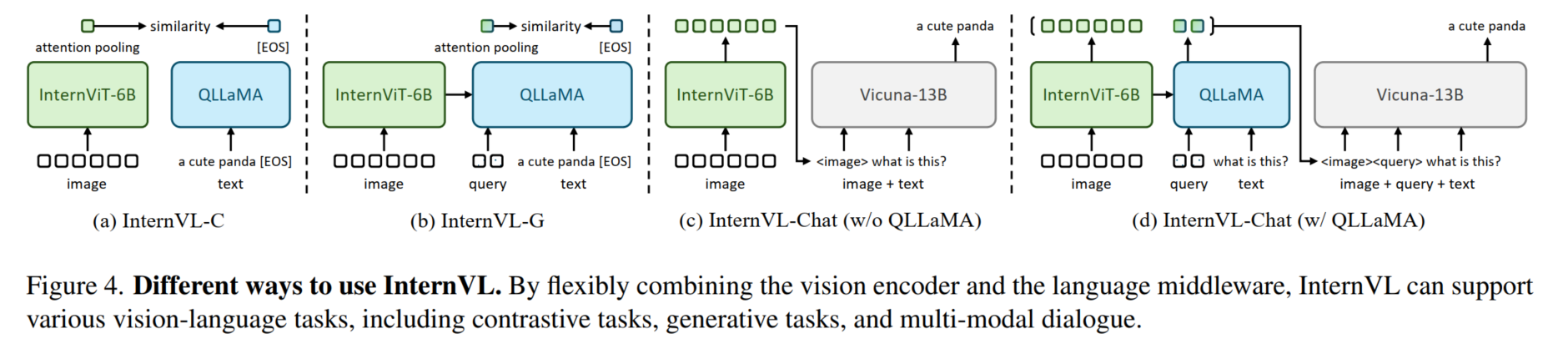
InternVL 1.1
InternVL-Chat-V1-1,其结构类似于 LLaVA,包括 ViT、MLP 投影器和LLM。如图所示,将 InternViT-6B 通过简单的 MLP 投影器连接到 LLaMA2-13B。请注意,这里使用的 LLaMA2-13B 不是原始模型,而是通过逐步预训练和微调 LLaMA2-13B 基础模型以适应中文任务而获得的内部聊天版本。总体而言,模型总共有 19B参数。

InternVL 1.5
模型结构
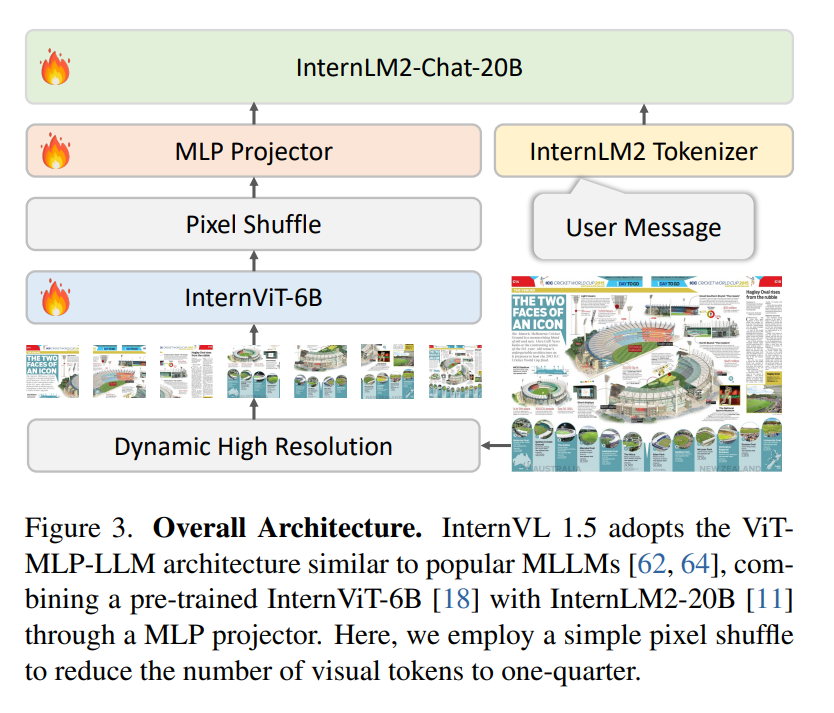
InternVL 1.5整体结构包括3个部分:ViT、MLP Projector和LLM。
- ViT模型选择的是一个6B的模型InternViT-6B-448px-V1.5 ,作为强视觉特征提取器;
- MLP Projector则是负责将视觉特征和语言模型的特征空间进行对齐,InternLM2-Chat-20B的embedding维度是6144,MLP Projector会将视觉特征转换到相同的维度;
- LLM选择的是自家的InternLM2-Chat-20B。
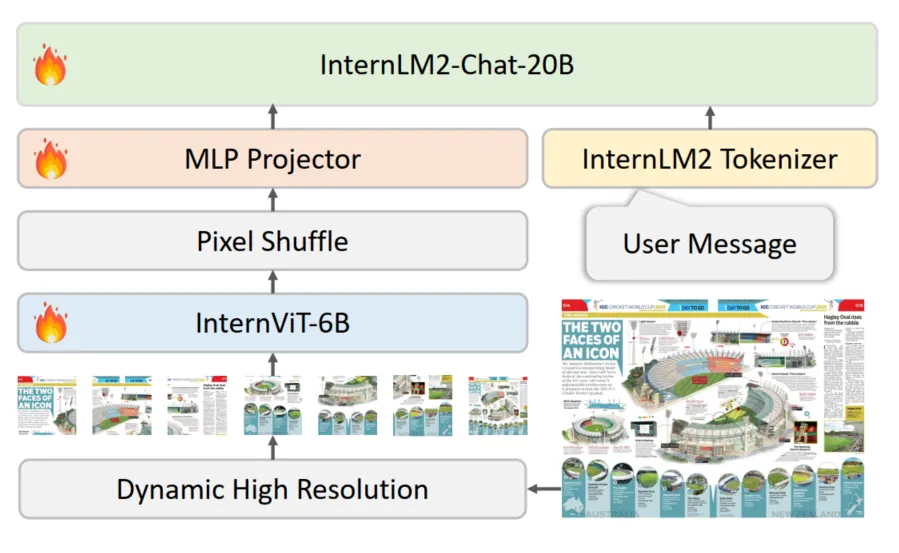
InternVL 1.5的总体参数量是26B。并且,在整体框架中我们还看到另外两个技术手段,分别是Pixel Shuffle和Dynamic High Resolution;Pixel Shuffle主要是用来重排ViT提取到的pixel feature,目的是减少visual token的数量并保持特征信息不丢失,而Dynamic High Resolution,即动态高分辨率,则是为了让ViT模型能够尽可能获取到更细节的图像信息,提高视觉特征的表达能力。接下来,本文会对这个两个技术做详细的解析。
Dynamic High-Resolution
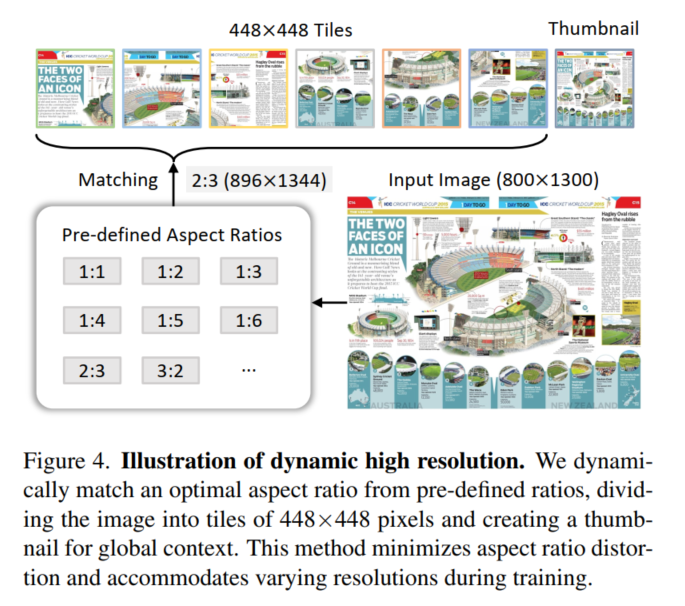
Dynamic High Resolution具体的做法为:
- 预设纵横比集合:例如{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:3, 3:2 …,2:6}多种可能的组合(这取决于自定义min和max两个变量,后面代码会说到)
- 最优匹配:对于每个输入图像,系统会计算其纵横比,并与预定义的集合进行比较,找出差异最小的纵横比。那么如果有多个匹配的纵横比(即并列最小差异)怎么办?比较原始图像面积与特定纵横比下的图像面积来实现的。如果特定纵横比下的图像面积大于原始图像面积的一半,那么这个纵横比会被选为最优纵横比。
- patch 分割:输入图像被动态分割成\(448\times 448\)的patch ,patch的数量是根据图像匹配的纵横比和分辨率 (在1到12之间变化)。
- 图像分割与缩略图(Image Division & Thumbnail)
调整图像分辨率:一旦确定了合适的纵横比,图像将被调整到相应的分辨率。例如,一个\(800\times 1300\)的图像将被调整到\(896\times 1344\)。
分割图像:调整后的图像被分割成\(448\times 448\)像素的patch。在训练阶段,根据图像的纵横比和分辨率,patch的数量可以在1到12,推理时候是1到40
全局上下文缩略图:同时会resize 原始图像到448x448,帮助模型理解整体场景。
核心代码如下,比较简单不做注释了:
from transformers import AutoTokenizer, AutoModel
import torch
import torchvision.transforms as T
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
#动态分辨率预处理
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
# {(1, 2), (2, 1), (4, 1), (3, 1), (1, 5), (1, 1), (6, 1), (5, 1), (1, 4), (2, 3), (2, 2), (1, 6), (3, 2), (1, 3)}
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=6):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values额外的实验结果是,训练在1-12 块Patch的范围内,但是推理时候泛化到了40个,(开始说过VIT模型输出是256个token,所以\(256*(40+1)=10496\)),实验证明24块为最优效果。
Pixel Shuffle
为了增强模型对大分辨率图像的支持,作者引入了pixel shuffle的操作降低visual token数量
Pixel Shuffle在超分任务中是一个常见的操作,PyTorch中有官方实现,即nn.PixelShuffle(upscale_factor) 该类的作用就是将一个tensor中的元素值进行重排列,假设tensor维度为\([B, C, H, W]\), PixelShuffle操作不仅可以改变tensor的通道数,也会改变特征图的大小,先看官方文档:
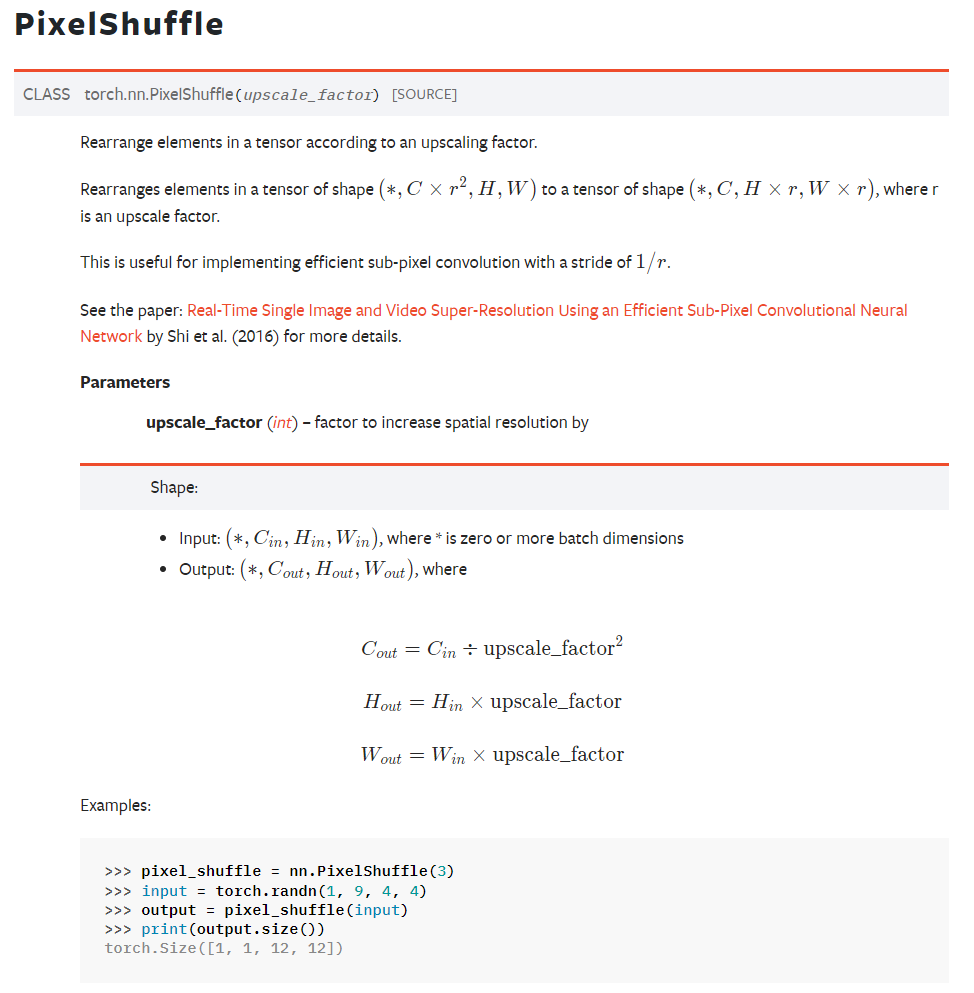
InternVL 1.5中是自己写了一个pixel shuffle的操作,他的这个操作刚好相反,是一个下采样操作,实际使用的scale_factor为0.5,其实就相当于把更多的像素保存在channel维度上,所以pixel shuffle后,\(H\), \(W\)变小了,channel数变多了。对于scale_factor,比如0.5,pixel shuffle将输入\([N, W, H, C]\)转换成shape为\([N, H *\text{scale}, W * \text{scale}, C//(\text{scale}^2)]\)的Tensor。

可见,对于一个\(448\times 448\)的image来说,经过ViT + pixel shuffle后,visual token数由原来的\(32\times 32\)下降到了\(16\times 16\),token数下降到了原来的\(1/4\),既保留了原始的feature信息,又达到了减少上下文长度的效果。
模型训练
InternVL 1.5训练分为2个阶段。
阶段一(pre-training):对MLP Projector和InternViT-6B模型做预训练,LLM底座权重冻结,这个阶段主要是针对视觉特征提取器进行优化;
阶段二(finetuning):InternViT-6B + MLP Projector + InternLM2-20B总共26B的参数全部参与训练,上下文长度设置为4096,并且采用和LLaVA一样的prompt格式。
值得一提的是在finetuning的数据中, 由于之前的模型对非英语的支持不是非常好, 作者加入了 translation的pipeline ,

InternVL2
2024年7月份,InternVL团队发布了InternVL 2.0,效果比InternVL 1.5更好。InternVL 2.0整体的网络结构和InternVL 1.5是一样的,Pixel Shuffle和Dynamic High Resolution的技术从InternVL 1.5继承了下来。但是InternVL 2.0进一步支持了医疗图像和视频作为输入,在功能上是比较大的变化。
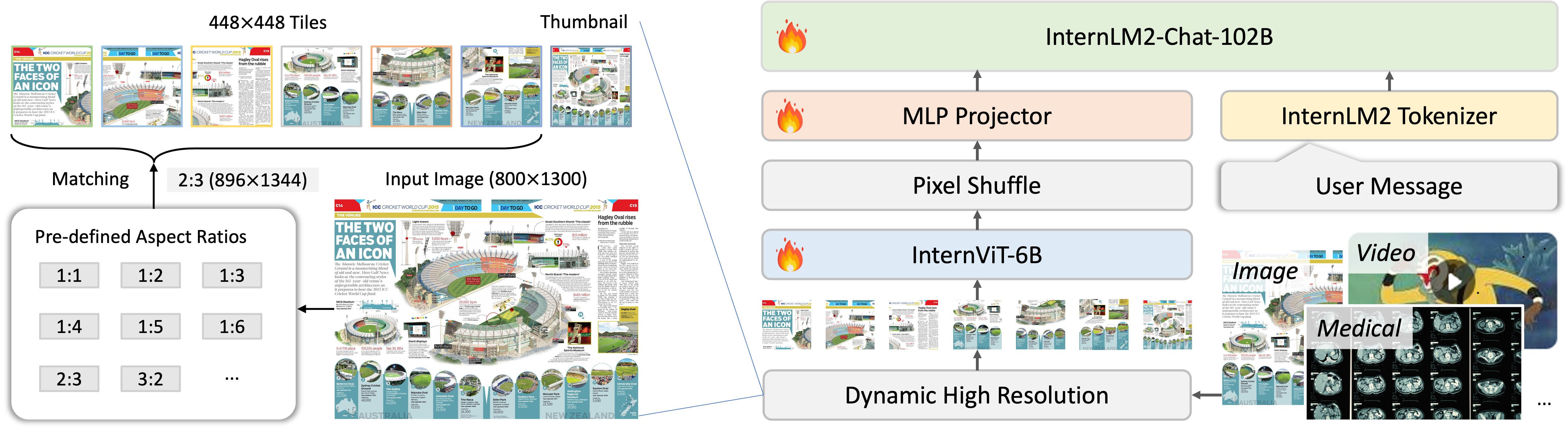
相对于InternVL 1.5,这次更新的InternVL 2.0主要的创新有:
- 提出了渐进式对齐的训练策略:实现了与LLM原生对齐的视觉基座模型,渐进式训练策略使得模型从小到大,数据从粗到细训练。InternVL2.0以相对较低的成本完成了大模型的训练。这种方法在有限的资源下表现出了出色的性能。
- 多模态输入:通过一组统一的参数,InternVL2.0模型支持多种输入模态,包括文本、图像、视频和医疗数据。
- 多任务输出:基于VisionLLMv2,InternVL2.0模型支持各种输出格式,例如图像、边界框和掩模,具有广泛的多功能性。并且,通过将 MLLM 与多个下游任务解码器连接,InternVL2 可以推广到数百个视觉语言任务,同时实现与专家模型相当的性能。
- InternVL2 系列包括从 1B 模型,适用于边缘设备,到 108B 模型,后者功能显著更强大。随着更大规模的语言模型,InternVL2-Pro 展示了卓越的多模态理解能力,在各种基准测试中与商业闭源模型的性能相匹配。
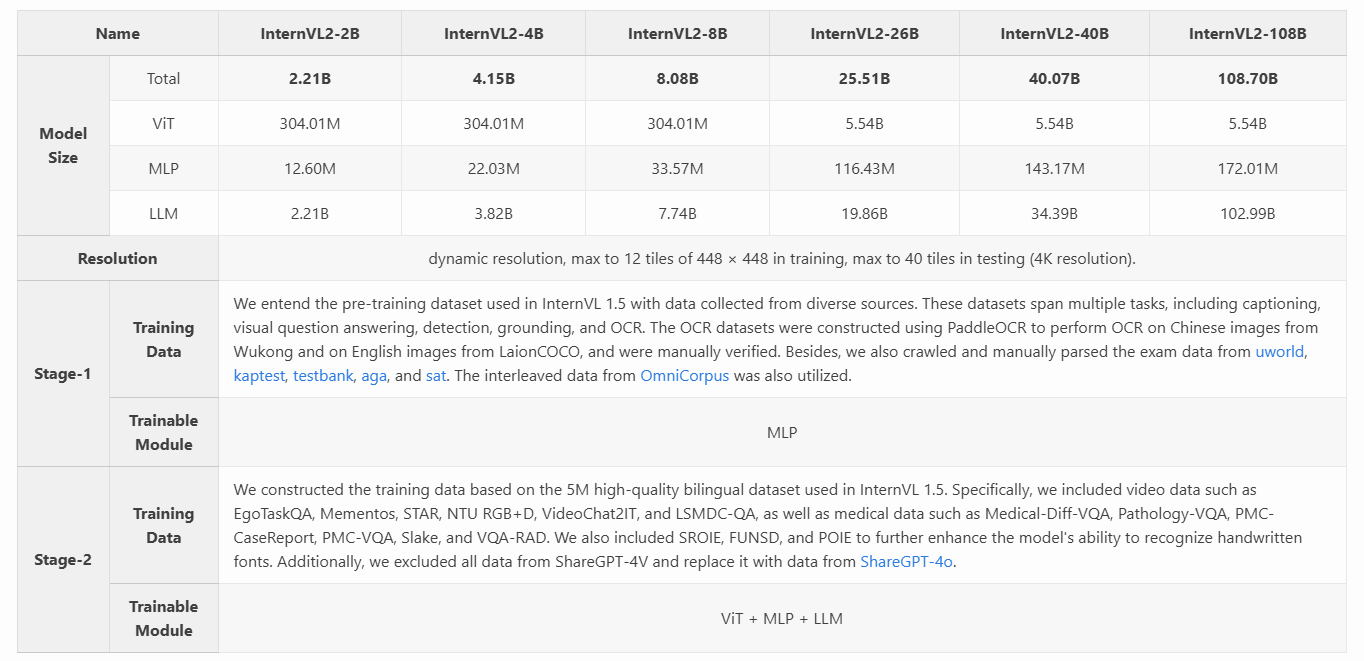
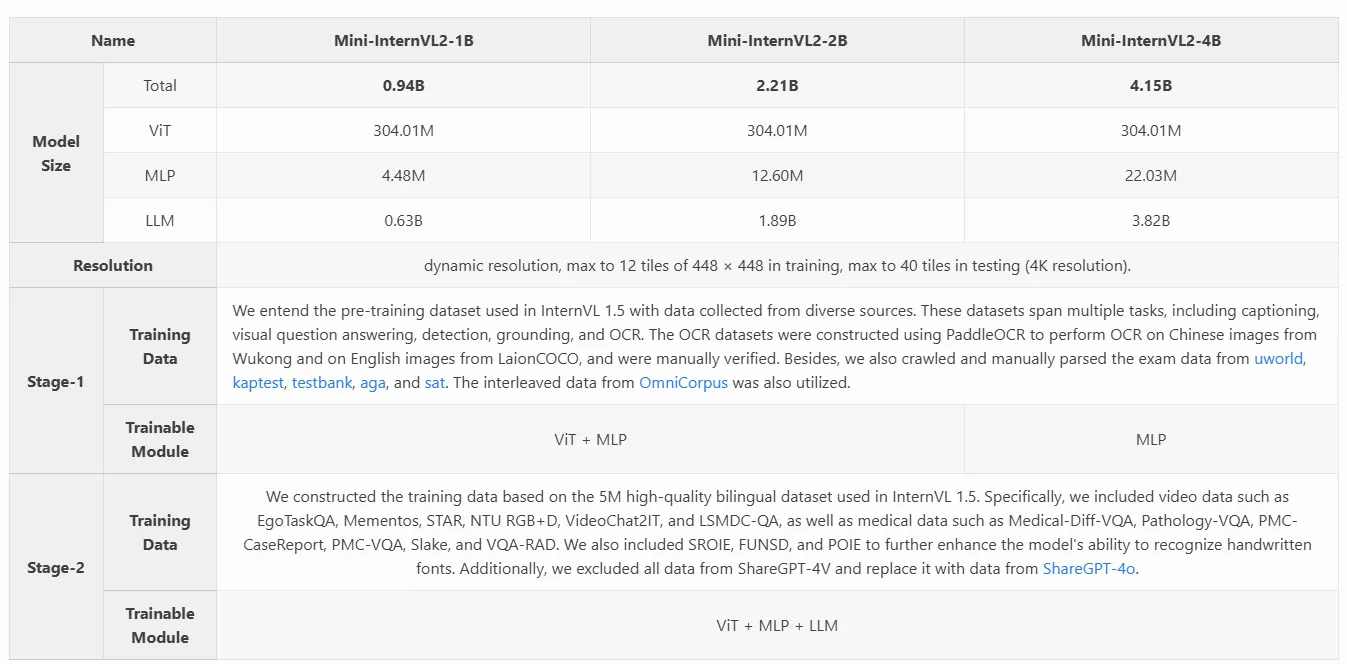
训练数据
pretrain(stage-1)
InternVL 1.5中使用的预训练数据集来自不同来源的数据进行整合。这些数据集涵盖多个任务,包括字幕、视觉问答、检测、Grounding和OCR。OCR数据集使用PaddleOCR构建,对悟空的中文图像和LaionCOCO的英文图像进行OCR处理,并进行了人工验证。此外,还爬取并手动解析了uworld、kaptest、testbank、aga和SAT的考试数据。还利用了OmniCorpus的交错数据。
Instruction Fine-Tuning (stage-2)
基于InternVL 1.5中使用的500万高质量双语数据集构建训练数据。具体来说,包括了视频数据,如EgoTaskQA、Mementos、STAR、NTU RGB+D、VideoChat2IT和LSMDC-QA,以及医学数据如Medical-Diff-VQA、Pathology-VQA、PMC-CaseReport、PMC-VQA、Slake和VQA-RAD。还加入了SROIE、FUNSD和POIE,以进一步增强模型识别手写字体的能力。此外,排除了 ShareGPT-4V 的所有数据,并用 ShareGPT-4o 的数据替换。
模型结构
Vision model: InternVisionModel整体结构如下, 输入就是经过Dynamic High-Resolution 的 pixel values 14是patch size
InternVisionModel(
(embeddings): InternVisionEmbeddings(
(patch_embedding): Conv2d(3, 3200, kernel_size=(14, 14), stride=(14, 14))
)
(encoder): InternVisionEncoder(
(layers): ModuleList(
(0-44): 45 x InternVisionEncoderLayer(
(attn): InternAttention(
(qkv): Linear(in_features=3200, out_features=9600, bias=False)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj_drop): Dropout(p=0.0, inplace=False)
(q_norm): InternRMSNorm()
(k_norm): InternRMSNorm()
(inner_attn): FlashAttention()
(proj): Linear(in_features=3200, out_features=3200, bias=True)
)
(mlp): InternMLP(
(act): GELUActivation()
(fc1): Linear(in_features=3200, out_features=12800, bias=True)
(fc2): Linear(in_features=12800, out_features=3200, bias=True)
)
(norm1): InternRMSNorm()
(norm2): InternRMSNorm()
(drop_path1): Identity()
(drop_path2): Identity()
)
)
)
)可以看到这里先是经过InternVisionEmbeddings层, 就是类似VIT一样对图像切patch然后组成sequence embedings, 只不过这里用了个卷积来做, 再加入class token 和position embeding,还是比较简单的
class InternVisionEmbeddings(nn.Module):
def __init__(self, config: InternVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.class_embedding = nn.Parameter(
torch.randn(1, 1, self.embed_dim),
)
self.patch_embedding = nn.Conv2d(
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
)
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches + 1
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim))
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
batch_size = pixel_values.shape[0]
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
embeddings = embeddings + self.position_embedding.to(target_dtype)
return embeddings后面就是跟着多层的Self-Attention 再接着做Pixel-Shuffle
- MLP-Projector: 将视觉和语言特征align
- LLM Model:将合并后的特征送入LLM model, 整体InternLM2结构类似LLaMA,这里不细说了
Mini-InternVL 2.0
Mini-InternVL 2.0,这是一系列参数从 10 亿到 40 亿的 MLLM,仅用 5%的参数就实现了 90%的性能。这种在效率和有效性方面的显著提升,使得模型在各个实际应用场景中更加易于访问和应用
模型的整体结构和InternVL1.5 保持了一致, 只是visual backbone用了更小的模型InternViT-300M
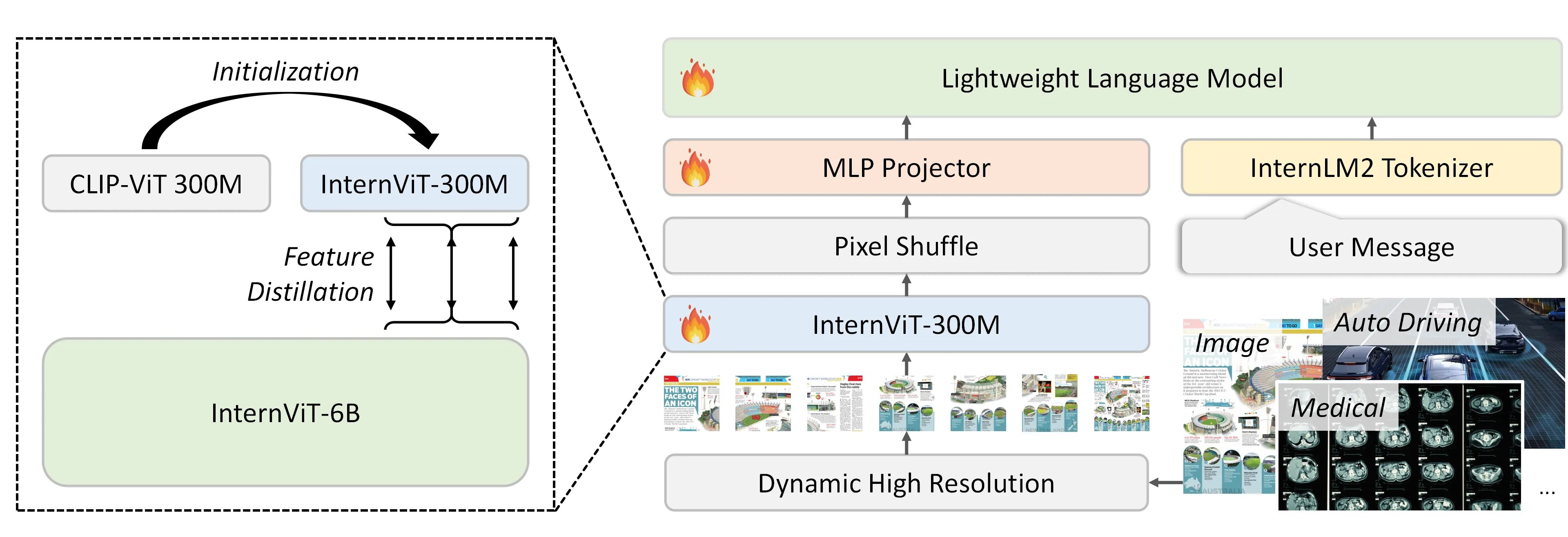
其中, InternViT-300M 具体来说是使用 InternViT-6B 作为教师模型,并初始化学生模型的权重为CLIP-ViT-L-336px 。通过计算最后 \(K\) 个变压器层的隐藏状态之间的负余弦相似性损失,将学生模型的表示与教师模型的表示保持一致。生成的模型名为 InternViT-300M,特别的是,所有图像的大小都调整为 448 ×448 的分辨率,并且为了提高训练效率,动态分辨率也被禁用。
模型训练也基本和InternVL1.5 一致,具体可以参考他们的模型主页面
InternVL 2.5
模型结构
模型结构还是继承自InternVL1.5 没什么大的改动。
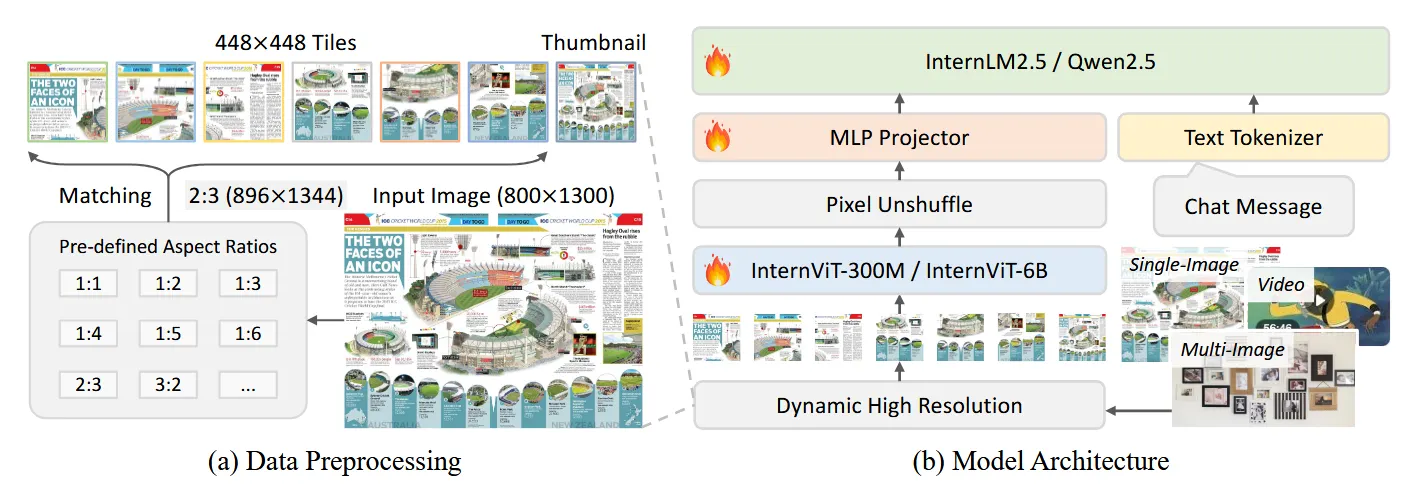
整个模型包含几个部分
- 较大的视觉encoder:InternViT-300M/InternViT-6B
- MLP projector
- LLM
训练策略
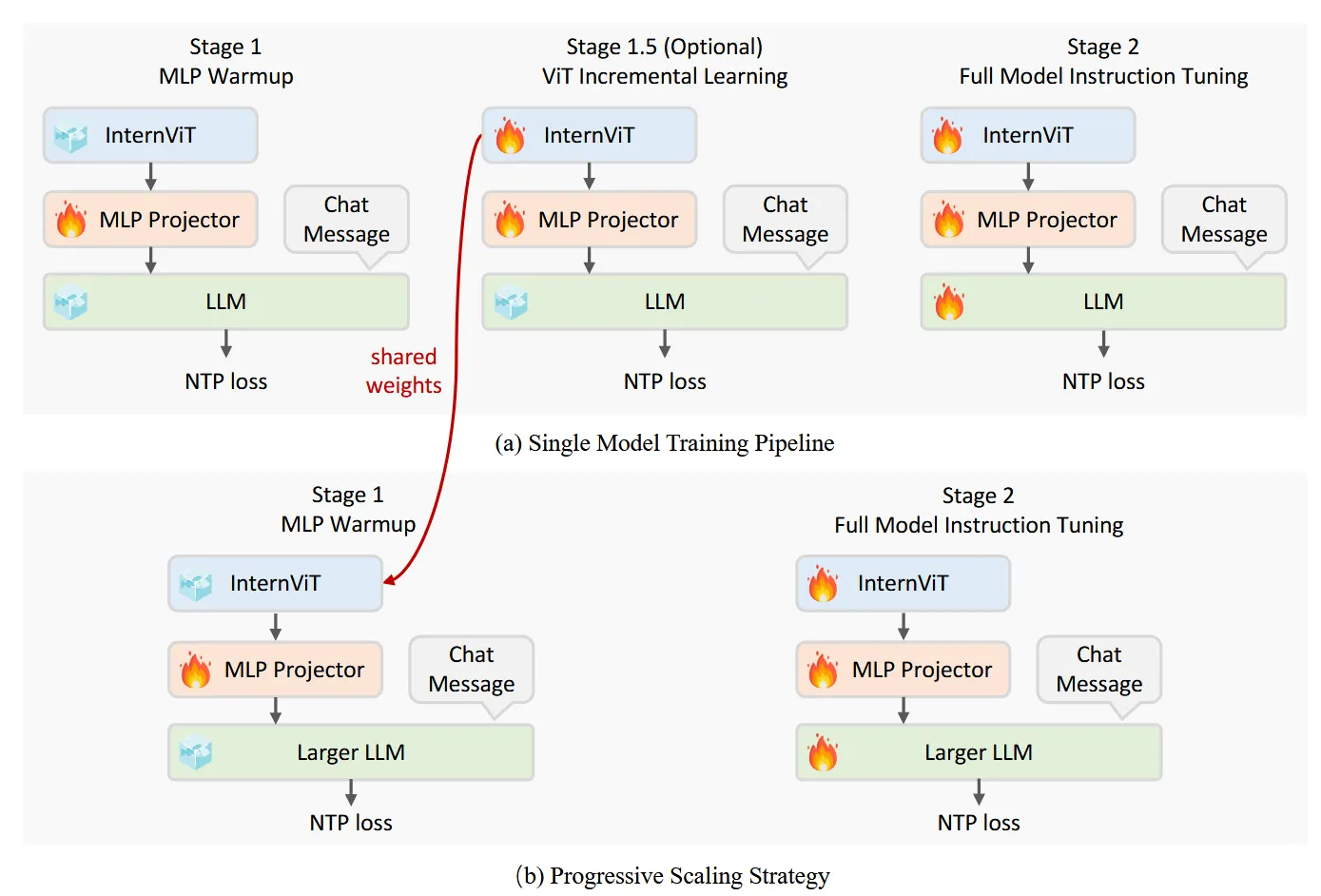
训练分为3个stage:
- Stage 1: MLP Warmup: 只训练MLP Projector,对齐语言和视觉特征。采用NTP Loss(Next Token Prediction Loss), 并采用了一个相对较大的学习率来加速模型对齐;
- Stage 1.5: ViT Incremental Learning (Optional):此阶段的目的是增强视觉编码器提取视觉特征的能力,使其能够捕获更全面的信息,特别是对于在 Web 规模数据中相对较少的领域,比如OCR和数学等,并使用较低的学习率以防止灾难性遗忘,确保编码器不会丢失以前学习的功能;
- Stage 2: Full Model Instruction Tuning:全参训练
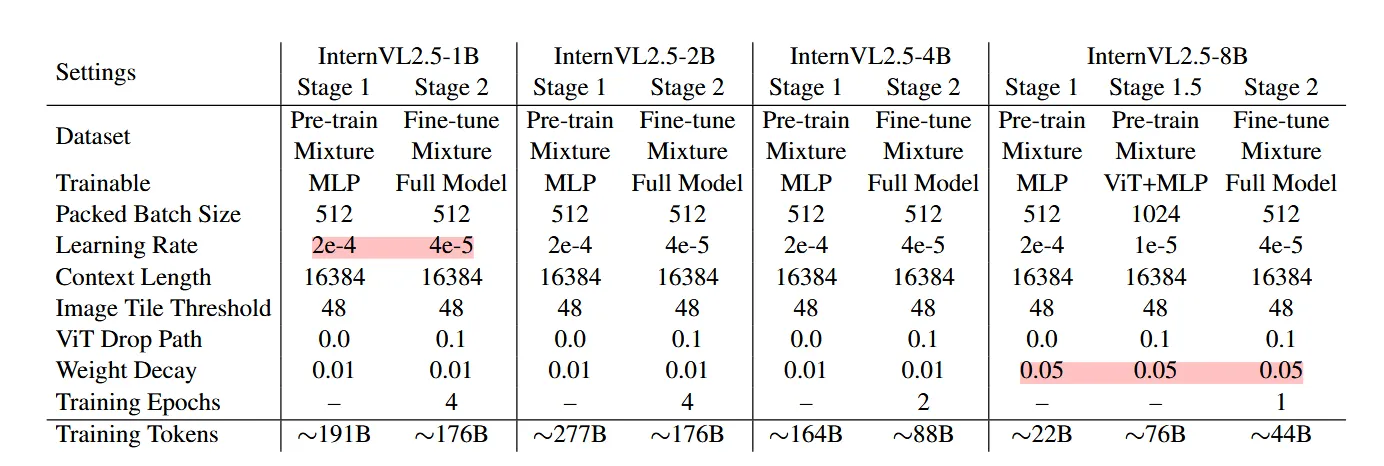
Progressive Scaling Strategy
如上面模型训练图 ,作者提出了一种渐进式缩放策略,以有效地将视觉编码器(例如 InternViT)与 LLM 对齐。之前在 InternVL 1.5 和 2.0 的训练中采用了类似的策略,但这次将该方法正式化为明确定义的方法。
该策略采用分阶段训练方法,从较小、资源高效的 LLM 开始,然后逐步扩展到更大的 LLM。这种方法源于我们的观察,即使 ViT 和 LLM 使用 NTP 损失进行联合训练,由此产生的视觉特征也是其他 LLM 可以轻松理解的可泛化表示。
具体来说,在阶段 1.5 中,InternViT 与较小的 LLM(例如 20B)一起训练,专注于优化基本视觉能力和跨模态对齐。此阶段避免了与直接使用大型 LLM 进行训练相关的高计算成本。使用共享权重机制,经过训练的 InternViT 可以很容易地转移到更大的 LLM(例如 72B),而无需重新训练。因此,在训练更大的模型时,可以跳过阶段 1.5,因为早期阶段优化的 InternViT 模块被重用。这不仅加快了训练速度,还确保了视觉编码器的学习表示得到保留并有效地集成到更大的模型中。 通过采用这种渐进式扩展策略,我们实现了可扩展的模型更新,而成本通常只是大规模 MLLM 训练成本的一小部分。例如,Qwen2-VL [246] 累计处理 1.4 万亿个代币,而 InternVL2.5-78B 仅接受约 1200 亿个代币的训练,不到 Qwen2-VL 的十分之一。这种方法在资源受限的环境中被证明特别有利,因为它可以最大限度地重用预先训练的组件,最大限度地减少冗余计算,并能够有效地训练能够解决复杂视觉语言任务的模型。
Training Enhancements
这里主要是采用了两个特别的data augmentation
- Random JPEG Compression. 为了避免在训练过程中过度拟合并提高模型的实际性能,作者应用了一种保留空间信息的数据增强技术:JPEG 压缩。具体来说,应用质量级别在 75 到 100 之间的随机 JPEG 压缩来模拟 Internet 来源图像中常见的退化。这种增强提高了模型对噪点、压缩图像的鲁棒性,并通过确保在各种图像质量下实现更一致的性能来增强用户体验。
- Loss Reweighting.Token Averaging 和 Sample Averaging 是两种广泛应用的 NTP 损失加权策略。Token Averaging计算所有token的平均 NTP 损失,这可能导致梯度偏向于具有更多token的response; 而 Sample Averaging 首先在样本内部平均,这样可以防止长序列样本在整体损失中占据过大权重, 再对所有样本求平均, 但是会使得模型偏向于选择更短的response。这些策略可以用统一的格式表示:
其中 \(\mathcal{L}_i\)和 \(w_i\)分别表示token \(i\)的损失和权重,\(x\)表示token \(i\) 所属样本的长度(token 数)
为了平衡模型不偏向于任何模式,所以作者就在这两种策略中做了个trade-off,取 \(w_i=1/x^{0.5}\)
数据
Multimodal Data Packing
为了提高训练效率,减少padding数量, 作者将训练数据重新整合,整合策略可以氛围四个阶段:
- 选择阶段 (Select)
类似标准数据集采样,直接采样独立数据,将过长的样本截断成多个小样本,确保每个样本满足两个阈值限制:
- LLM序列长度 ≤ \(l_{max}\)(上下文长度限制)
- 图像块数量 ≤ \(t_{max}\)(图像块数量限制)
- 搜索阶段 (Search)
为当前样本在缓冲区列表中寻找可打包的配对样本,打包后需满足条件:
- 总序列长度 < \(l_{max}\)
- 总图像块数量 < \(t_{max}\)
如果多个缓冲区样本满足条件, 选择序列最长且图像块最多的样本
缓冲区列表按降序维护,并使用二分查找加速搜索
- 打包阶段 (Pack)
将采样数据和选中的缓冲区数据打包为单个序列, 如果未找到合适的配对样本,则保持原样,
重要限制:
- 注意力机制仅在各自样本内部有效
- 不同打包样本间的token不能相互注意
- 每个样本独立维护位置索引
- 维护阶段 (Maintain)
如果打包样本超出限制(\(l_{max}\)或 \(t_{max}\)),直接用于训练, 否则将打包样本插入缓冲区列表
缓冲区容量管理:
- 超出容量时,输出序列最长且图像块最多的样本
- 保持缓冲区效率
Data Filtering Pipeline
作者认为,虽然传统观点认为大规模数据集中的微小噪声可以忽略不计,但研究结果表明并非如此:即使是极小一部分噪声样本也会降低 MLLM 的性能和用户体验。所以作者构建了一系列的过滤和清洗数据的pipeline,具体来说
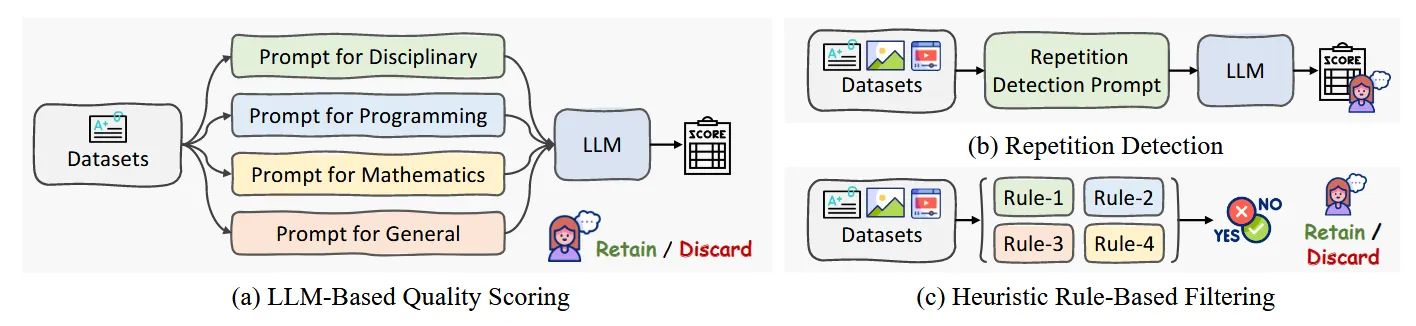
- Pure Text data: 对于纯文本数据,作者设计了三种过滤方式
- 基于LLM的质量评分:首先按领域分类数据集(学科、编程、数学、通用等),然后使用预训练LLM(Qwen2.5)对每个样本评分(0-10分),使用特定领域的prompt进行评分,删除低于阈值(如7分)的样本。
- 重复模式检测:结合LLM和专门prompt识别重复模式,对可疑样本进行人工审核,删除低于阈值(如3分)的样本。
- 基于启发式规则的过滤
- 过滤异常长度的句子
- 过滤过长的零序列
- 过滤重复行过多的文本
- 所有标记样本在最终删除前需人工审核
- multimodal data:多模态也用了类似的策略,具体来说:
- 重复模式检测:高质量学术数据集豁免检查,其余数据集使用特定prompt识别重复模式类似纯文本数据集
- 基于启发式规则的过滤: 与纯文本数据类似
InternVL 2.5-MPO
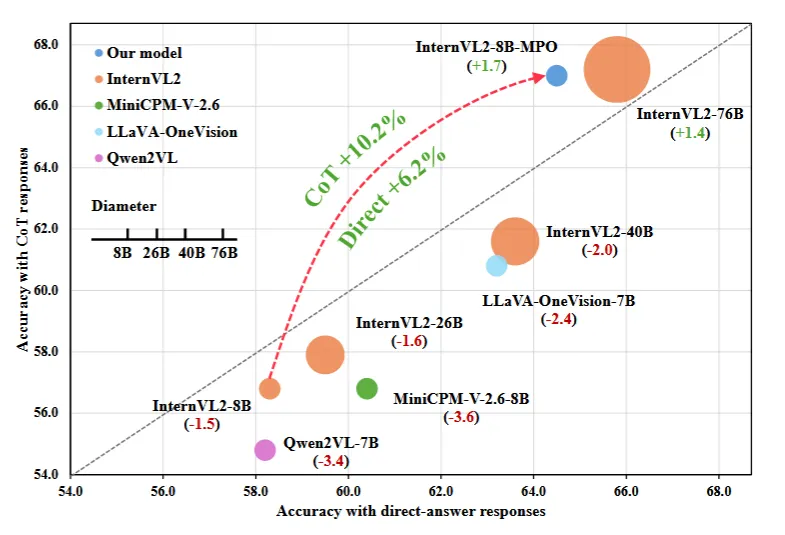
作者发现,现阶段的开源VLM中CoT相比Direct的prompt中CoT表现一般较差,作者给出的理由是SFT训练数据和用户输入prompt的分布偏差(distribution shift) 导致性能降低
所以作者构建了一个偏好数据集 MultiModal PReference dataset (MMPR), 并提出了一个MPO(mixed preference optimization)方案去训练模型。
MMPR
- 针对有明确标准答案的指令
对于有明确正确答案(即标准答案)的指令,采用以下方法:- 正样本集 (\(\mathcal{Y}_p\)):模型生成的响应与标准答案匹配。响应必须符合要求的格式,例如先提供推理过程,最后以“Final Answer: ”的形式明确给出最终答案。
- 负样本集 (\(\mathcal{Y}_n\)):模型生成的响应未与标准答案匹配或者响应没有提供明确的最终答案(例如,响应不完整或含糊不清)。
构建训练模型的偏好对:
- 从正样本集 (\(\mathcal{Y}_p\)) 中选择一个被选中的响应 (\(y_c\))。
- 从负样本集 (\(\mathcal{Y}_n\)) 中选择一个被拒绝的响应 (\(y_r\))。
使用这些偏好对,通过排序损失函数(例如对比损失或成对排序损失)训练模型,让模型学会优先生成正样本而非负样本。
- 针对没有明确标准答案的指令
对于没有单一正确答案的指令,采用另一种方法:
Dropout Next-Token Prediction (Dropout NTP)
- 正样本集 (\(\mathcal{Y}_p\)):模型生成的所有响应。因为没有明确的标准答案,所以所有生成的响应都被视为有效的正样本。
- 负样本集 (\(\mathcal{Y}_n\)):通过从正样本集中随机选择一个响应,并截断响应的后半部分来生成负样本。这些截断后的响应是没有图像输入的响应,作为负样本:
其中 \(y_{<j} \)和 \(y_{≥j}\) 分别是 \(y \)的剩余部分和截断部分。\(\tilde{y}_{≥j} \)是 \(y_{<j} \)的补全,没有图像输入。原始响应 \(y = [y_{<j}, y_{≥j}] \)用作所选响应 \(y_c\),补全的响应 \(\tilde{y}_{≥j} = [y_{<j}\), \(\tilde{y}_{≥j}]\) 用作被拒绝的响应 \(y_r\)。值得注意的是,虽然 \(M_0\) 生成的响应可能并不完美,但与使用图像输入生成的响应相比,没有图像输入生成的响应会引入更多的幻觉。因此,\(y \)和\( \tilde{y} \)之间的偏序关系成立。
MPO
一个有效的 PO 过程应该使模型能够学习到成对响应之间的相对偏好、单个响应的绝对质量以及生成偏好响应的过程。所以MPO将训练目标定义为偏好损失\(\mathcal{L}_\mathrm{p}\)、质量损失\(\mathcal{L}_{\mathrm{q}}\) 和生成损失\(\mathcal{L}_\mathrm{g}\)的组合,称为混合偏好优化:
\(w_*\) 代表分配给每个损失组件的权重。在本工作中,作者经验性地比较了不同变体的偏好损失。基于实验结果,最终使用 DPO 作为偏好损失,BCO 作为质量损失。
具体来说,DPO 充当偏好损失,以使模型能够学习所选和被拒绝的响应之间的相对偏好。此算法优化以下损失函数:
其中 \(\beta\) 是 KL 惩罚系数,\(x\)、\(y_c\)和\(y_r\)分别是用户query、选择的响应和拒绝的响应。策略模型 \(\pi_\theta\) 从模型 \(\pi_0\) 初始化。
此外,BCO 损失被用作质量损失,这有助于模型理解单个响应的绝对质量。损失函数定义为:
\(\mathcal{L}_{\mathrm{q}}^+\)和\(\mathcal{L}_{\mathrm{q}}^-\)分别代表所选和被拒绝的响应的损失。每种响应类型的损失是独立计算的,需要模型区分单个响应的绝对质量。损失项由以下给出:
\(\delta\) 代表奖励偏移,计算为之前奖励的移动平均以稳定训练。
BCO Loss可以认为是对比学习的思想:公式的核心思想是通过对比当前策略 \(\pi_\theta\)和参考策略 \(\pi_0\) 的预测概率,来优化模型的输出。
- 如果当前策略对正样本的预测概率 \(\pi_\theta(y_c \mid x)\)比参考策略 \(\pi_0(y_c \mid x)\)更高,损失会更小。
- 对于负样本,损失函数会鼓励当前策略对负样本的预测概率 \(\pi_\theta(y_r \mid x)\)更低。
最终,将SFT 损失用作生成损失,以帮助模型学习首选响应的生成过程。损失函数定义为:
InternVL3
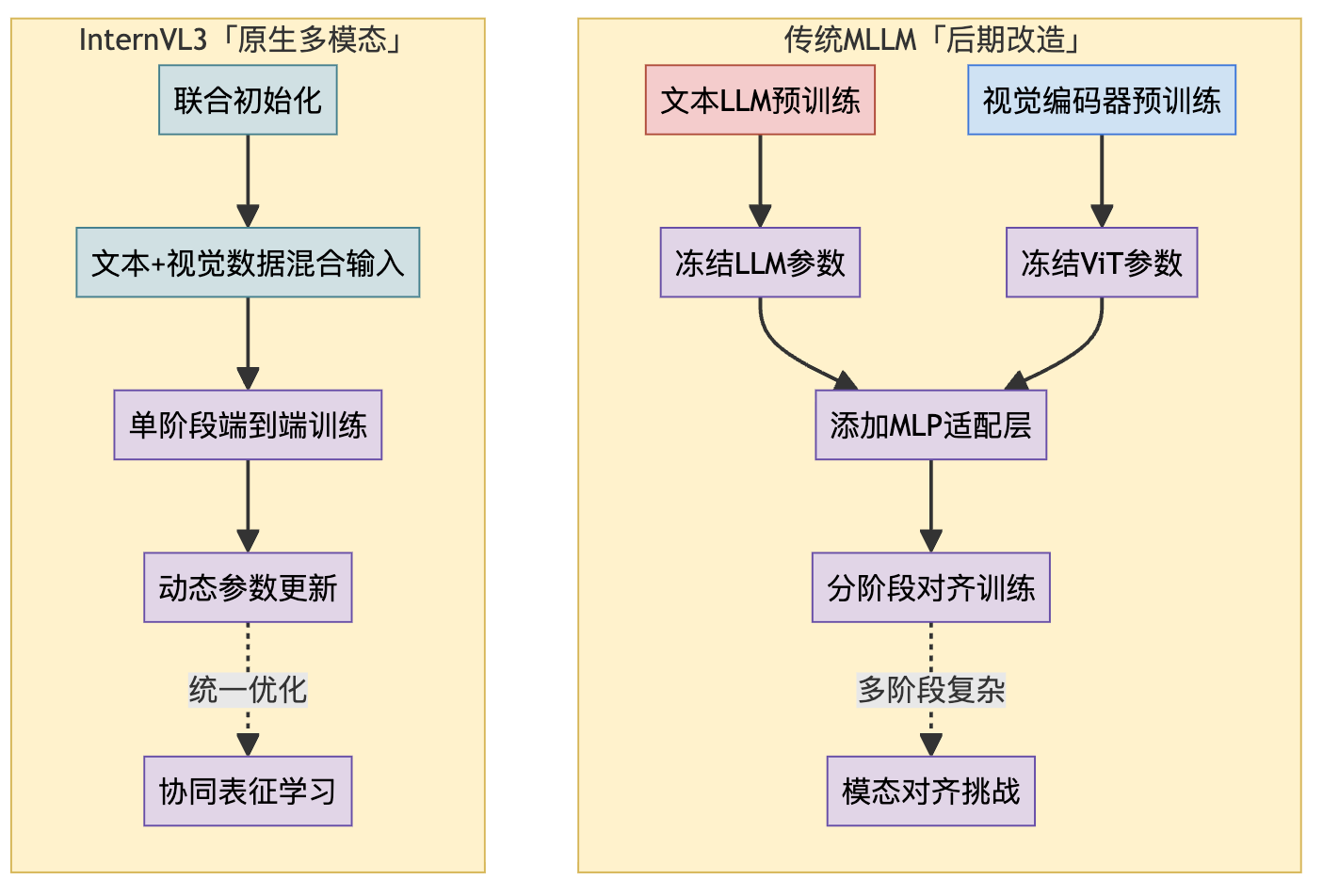
InternVL3 的想法其实也很直白,架构其实仍然是 ViT-MLP-LLM这一套,只是选用了 原生多模态预训练 (Native Multimodal Pre-training):
- 统一的训练阶段 (Unified Pre-training Stage) :取消了传统方法中独立的特征对齐预训练阶段。在一个统一的、大规模的预训练阶段中,模型同时接触纯文本语料库和多模态数据。
- 共同优化所有参数 (Joint Parameter Optimization) :在这个统一的预训练阶段,模型的所有核心组件——视觉编码器 (ViT)、接口模块 (MLP) 和语言模型 (LLM)——的参数都同时参与优化。没有谁是「旁观者」或「被冻结者」。大家一起学习,一起调整。
- 以文本为中心的预测目标 (Text-centric Predictive Objective) :尽管输入包含了视觉信息,但训练的目标仍然是经典的自回归预测 (Autoregressive Prediction),即预测序列中的下一个 token。但关键在于,损失函数 (\(\mathcal{L}\)) 只计算文本 token 的预测损失。
用公式表达就是:对于一个包含文本和视觉 token 的序列 \(\mathbf{x} = (x_1, x_2, \ldots, x_L)\),其损失为:
其中,\(x_i \in \mathrm{Text}\) 表示只对序列中是文本 token 的 \(x_i\) 计算损失,\(p_{\theta}(x_i \mid \dots)\) 是模型预测第 \(i\) 个 token 的概率,\(w_i\) 是该 token 的损失权重(InternVL3 采用了 \(\frac{1}{l^{0.5}}\) 的平方平均权重,l 为计算损失的文本 token 总数)。
对比一下「原生训练」和「后期改造」:
这样有什么好处呢?
- 深度协同,消除鸿沟 :视觉和语言表示从一开始就在统一的模型内部共同学习、相互塑造。这有助于模型学习到更深层次、更本质的跨模态关联,而不是后期「强行」对齐。模态之间的「鸿沟」在学习过程中就被自然地填平了。
- 简化流程,提升效率 :将多个分离的训练阶段整合为一个统一的预训练阶段,大大简化了 MLLM 的构建流程,减少了中间环节的调优复杂性。虽然这个统一阶段可能很长,但整体上可能更高效。
- 释放潜力,减少妥协 :所有参数共同优化,使得视觉和语言能力可以同步发展,减少了因冻结参数而导致的能力瓶颈,模型可以更充分地学习如何结合多模态信息。
- 更强的泛化能力 :在混合数据上进行联合训练,可能促使模型学习到更通用、更鲁棒的表示,从而在未见过的任务或数据上表现更好。
核心技术
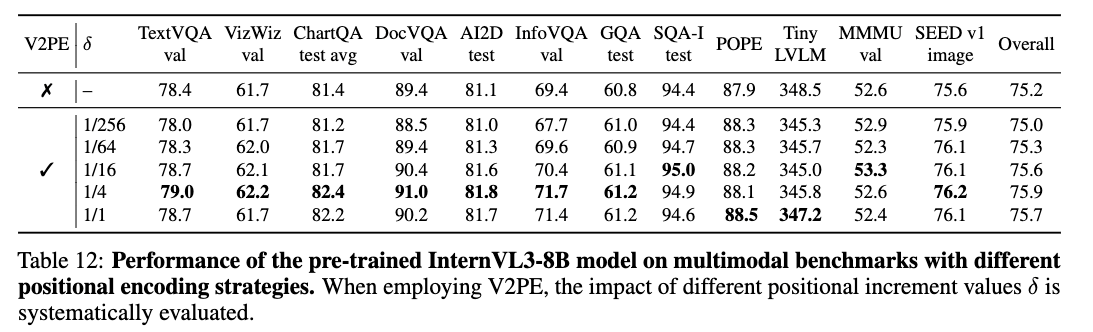
可变视觉位置编码 (V2PE)
当 MLLM 需要处理包含大量图像(比如一个相册)或高分辨率图像(拆分成很多小块)或长视频时,输入的视觉 token 数量会急剧增加。传统的 Transformer 位置编码是给每个 token (无论文本还是视觉) 分配一个递增的整数索引 (0, 1, 2, 3…)。视觉 token 一多,序列长度可能轻松超过 LLM 的处理上限,导致无法处理或信息丢失。
InternVL3 的解决方案是:给视觉 token 分配更小的位置增量。称之为V2PE (Variable Visual Position Encoding)。
文本 token 的位置索引仍然是 \(p_i = p_{i-1} + 1\)。但视觉 token 的位置索引则变为 \(p_i = p_{i-1} + \delta\),其中 \(\delta\) 是一个小于 1 的分数 (例如 1/4, 1/16, …, 1/256):
关键点在于,对于同一张图像(或同一个视频片段)内的所有视觉 token,\(\delta\) 的值是相同的,这样保证了图像内部的相对空间关系得以保留。
在训练时,\(\delta\) 的值从一个预定义的集合(如 \(\{1, 1/2, 1/4, \dots, 1/256\}\))中随机为每张图片选择。这使得模型学会适应不同「压缩程度」的位置编码。
而在推理时,可以根据输入序列的实际长度灵活地选择一个合适的 \(\delta\) 值,以在性能和不超过上下文窗口之间取得平衡。
有趣的是,这种设计还有意外收获:论文的消融实验表明,V2PE 不仅在处理长序列时有用,即使在处理普通长度序列的标准基准测试上,使用较小的 \(\delta\) (如 1/4, 1/16) 相比于 \(\delta=1\)(即传统编码)也能带来性能提升。这似乎暗示,V2PE 可能不仅仅是解决了长度问题,或许还对模型学习视觉-语言对齐有更深层次的好处,值得进一步研究。
数据策略
InternVL3 采用了纯文本数据和多模态数据的混合喂养。
- 多模态数据 (约 1500 亿 tokens):不仅包含了 InternVL 2.5 使用的覆盖广泛领域(图像描述、问答、数学、图表、OCR、文档、对话、医疗等)的数据,还新增了更多真实世界应用场景的数据,如图形用户界面 (GUI) 操作、工具使用、3D 场景理解、视频理解等。这大大扩展了模型的应用范围。
- 纯文本数据 (约 500 亿 tokens):主要基于 InternLM 2.5 的预训练数据,并加入了其他开源文本数据集,特别强化了知识密集型任务、数学和推理方面的语料。这是为了确保模型在进行多模态学习的同时,保持甚至增强其核心的语言理解和生成能力。
通过实验确定了 语言数据 : 多模态数据 ≈ 1 : 3 的比例效果最佳。这个比例是在总训练量约 2000 亿 (200B) tokens 的预算下找到的平衡点。太少的语言数据可能削弱基础能力,太多的语言数据则可能冲淡多模态学习的效果。
除了数量和比例,InternVL3 团队也非常注重数据的质量。在后续的 SFT 和 MPO 阶段,都使用了更高质量、更多样化的数据集。
后训练策略 (SFT & MPO)
原生多模态预训练打下了一个坚实的基础,但要让模型成为能理解复杂指令、进行流畅对话、做出可靠推理的「全能选手」,还需要进一步的后训练 (Post-Training)。InternVL3 采用了两阶段策略:
- 阶段一:监督微调 (SFT)
使用大量高质量的「指令-回答」数据对进行训练,模型学习模仿这些「标准答案」。 沿用了 InternVL 2.5 的一些有效技术(如随机 JPEG 压缩增加鲁棒性、平方损失加权、多模态数据打包提高效率)。
关键在于数据升级:SFT 数据集从 16.3M 样本扩展到 21.7M 样本,并且显著增加了新领域的数据,如工具使用、3D 场景理解、GUI 操作、长上下文任务、视频理解、科学图表、创意写作和多模态推理。这使得模型的能力更加全面。
- 阶段二:混合偏好优化 (MPO)
如果说 SFT 是教模型「模仿」标准答案,那么 MPO 就是教模型「分辨好坏」并朝着「更好」的方向优化,尤其是在需要复杂推理和判断的场景下,MPO 的作用更加突出。
SFT 时模型是基于「标准答案」预测下一个词,而推理时模型是基于「自己之前生成的词」来预测。这种差异被称作训练与推理的偏差 (Train-Test Discrepancy),在高难度的、需要一步步推理的任务(如数学题、复杂逻辑)中尤其明显,可能导致模型「一步错、步步错」,即链式思考 (CoT) 能力下降。MPO 的目标是让模型的输出更符合人类的偏好,提升推理的可靠性。
MPO 不仅仅依赖「标准答案」,还利用了「偏好数据」,即告诉模型对于同一个问题,哪个回答更好 (chosen),哪个回答更差 (rejected)。它结合了多种损失函数:
- 偏好损失 \(\mathcal{L}_p\) (Preference Loss) :使用类似 DPO 的损失,让模型学习最大化「好答案」的概率,同时最小化「坏答案」的概率。
- 质量损失 \(\mathcal{L}_q\) (Quality Loss) :使用类似 BCO 的损失,让模型学习判断单个答案的绝对质量(是好是坏),而不仅仅是相对好坏。
- 生成损失 \(\mathcal{L}_g\) (Generation Loss) :标准的语言模型损失,用在「好答案」上,保持模型的生成能力和流畅性。
- 总损失是这三者的加权和:\(\mathcal{L} = w_p\mathcal{L}_p + w_q\mathcal{L}_q + w_g\mathcal{L}_g\)。
- InternVL3 的实践:
在数据方面,InternVL3 使用了基于 MMPR v1.2 构建的约 300K 偏好样本对,覆盖问答、科学、图表、数学、OCR、文档等多个领域。用 SFT 后的 InternVL3 模型(不同尺寸)生成候选回答,再进行偏好标注。
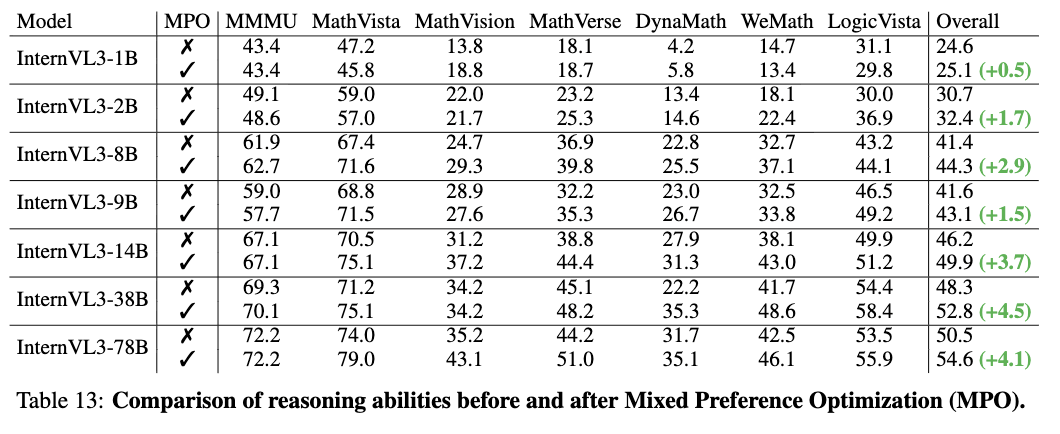
实验表明,经过 MPO 训练后,模型的推理能力(尤其在数学和逻辑基准上)得到了显著提升。重要的是,这些提升主要来自于 MPO 算法本身,而不是仅仅增加了数据量(MPO 数据是 SFT 数据的一个子集)。
InternVL 3.5
InternVL 3.5 是上海AI实验室(OpenGVLab)在2025年8月推出的一个开源多模态大模型家族。它在推理能力、通用性和效率方面相比前代(InternVL 3.0)有显著提升,并进一步缩小了与顶级闭源模型(如GPT-5)的性能差距。
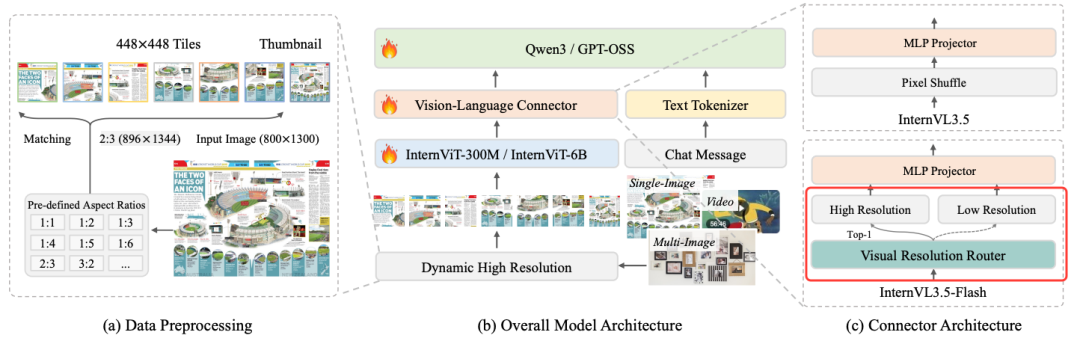
依然是ViT+MLP+LLM的结构,相比于之前 InternVL 系列增加了MoE的模型。
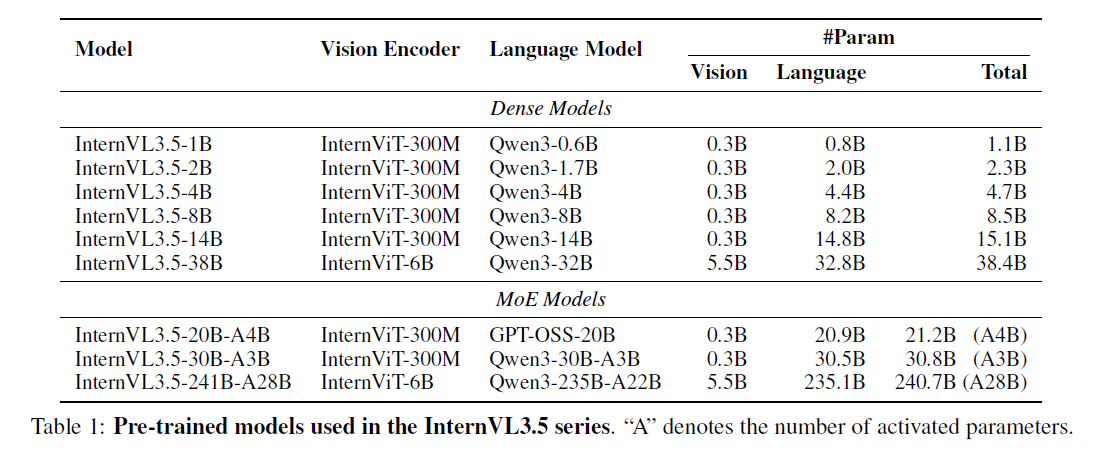
主要创新点
训练方法创新:
- 级联强化学习(Cascade RL)
- 结合离线RL(保证稳定收敛)和在线RL(进行精细化对齐)的两阶段训练策略。显著提升模型在复杂推理任务(如MMMU、MathVista)上的表现
- 推理效率创新
- 视觉分辨率路由器(ViR):一个能动态调整图像token压缩率的模块。通过视觉一致性学习(ViCO)训练,确保压缩后输出与高质量输出一致。在几乎不损失性能的前提下,将视觉token数量减少约50%,大幅提升处理高分辨率图像的效率
- 部署方式创新
- 解耦视觉-语言部署(DvD):将视觉编码器(ViT)和语言模型(LLM)分离到不同的GPU服务器上,并行异步执行
- 模型规模与能力
- 提供从1B到241B等多种参数规模的版本6。最大模型InternVL3.5-241B-A28B在多项任务中表现优异。支持GUI交互和具身智能等新型智能体任务,模型通用性极强
详细介绍
级联强化学习(Cascade RL):让推理更强大
InternVL 3.5 引入了级联强化学习(Cascade RL)框架,旨在提升模型的推理和对齐能力。该框架包含两个阶段:
- 离线RL(离线强化学习):使用混合偏好优化(MPO)算法,在预收集的高质量数据上进行训练,结合了偏好损失、质量损失和生成损失,确保模型初期的稳定收敛和强化学习训练的安全性。
- 在线RL(在线强化学习):在离线RL的基础上,使用GSPO算法进行在线优化。该阶段会对模型生成的多个回应进行采样,并通过一个奖励模型进行评分和标准化,最终利用这些评分通过重要性加权来优化模型策略,进一步提升模型输出的质量和对齐精度。
这种“由粗到细”的训练策略,使得 InternVL 3.5 在 MMMU(多学科专家级推理)、MathVista(数学视觉推理)等需要复杂推理的基准测试中取得了显著进步。
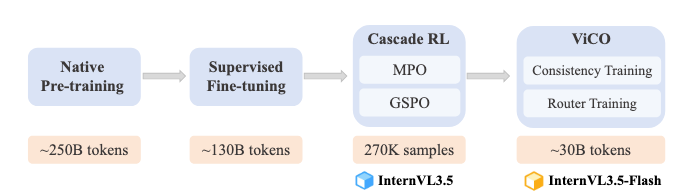
视觉分辨率路由器(ViR):动态平衡效率与精度
处理高分辨率图像会产生大量视觉token,严重拖慢推理速度。InternVL 3.5 引入了视觉分辨率路由器(Visual Resolution Router, ViR)来智能地解决这个问题。
动态路由:ViR 是一个轻量的神经网络(如小CNN),它能对输入图像的每个小块(patch)进行快速评估,判断其内容的复杂程度。
- 对于背景、纯色区域等简单内容,采用高压缩率(如1/16,保留64个token),减少计算量。
- 对于文字、图表、人物面部等细节丰富的关键区域,采用低压缩率(如1/4,保留256个token),保留更多信息。
视觉一致性学习(ViCO):为了训练ViR而不导致模型性能下降,团队设计了ViCO方法。其核心是迫使采用不同压缩率处理同一图像得到的输出,都与原始高分辨率模型的输出保持高度一致。通过最小化KL散度损失,模型学会了“即使看得模糊些,也能说得一样准”,从而保证了ViR压缩后的效果。
这项创新使得 InternVL 3.5 在几乎不牺牲任何性能的前提下,平均减少了50%的视觉token,为后续的加速奠定了坚实基础。
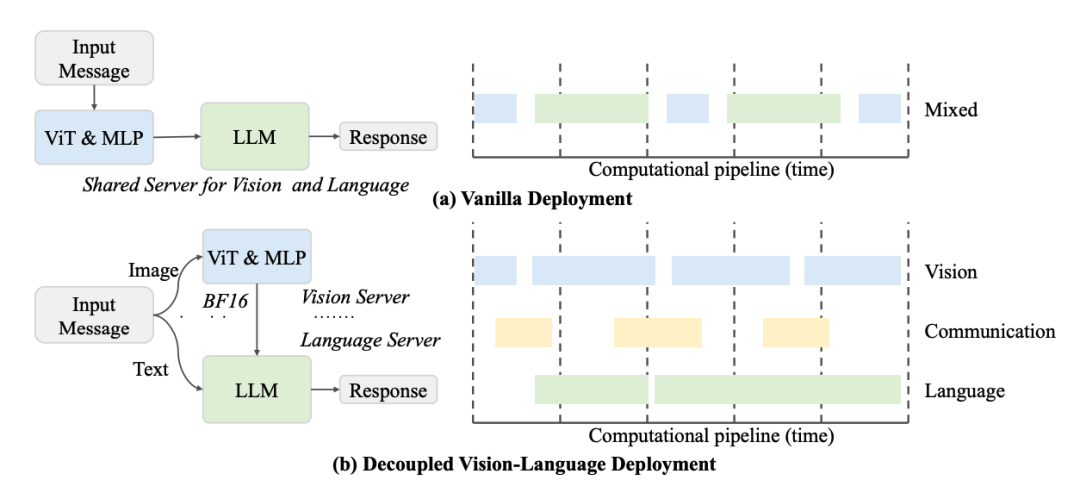
解耦视觉-语言部署(DvD):解锁推理速度飞跃
传统的多模态模型将视觉编码器(ViT)和语言模型(LLM)串联在同一个GPU上运行,导致两者相互等待,效率低下。InternVL 3.5 提出了解耦视觉-语言部署(Decoupled Vision-Language Deployment, DvD)策略。
- 物理分离:将ViT(和ViR)与LLM部署在不同的GPU服务器上。前者作为“视觉服务器”,后者作为“语言服务器”。
- 并行异步处理:视觉服务器可以并行处理大批量的图像,生成嵌入向量后,再压缩传输给语言服务器。语言服务器则无需等待,可以异步地进行自回归解码生成文本。
- 效果:这种方式极大地利用了计算资源,避免了视觉和语言计算相互等待的资源冲突。仅DvD策略本身就能带来近2倍的吞吐量提升,与ViR结合后,实现了最高4.05倍的端到端推理加速。
总结
总的来说,InternVL 3.5 的核心创新在于:
- 通过CascadeRL(算法创新) 大幅提升模型能力,尤其在复杂推理方面。
- 通过ViR(算法创新) 智能压缩视觉信息,在保真度的前提下优化计算效率。
- 通过DvD(工程创新) 改变部署方式,最大化硬件利用率,实现推理速度的极致提升。
Reference
InternVL-1.5:开源社区最强的多模态大模型成长记录
17、InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
超速解读多模态InternVL-Chat1.5 ,如何做到开源SOTA——非官方首发核心技巧版(待修订)
InternLM2/InternLM2.5/InternViT/InternVL1.5/InternVL2.0笔记: 核心点解析