随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
算法初探
Muon全称是“MomentUm Orthogonalized by Newton-schulz”,它适用于矩阵参数\(\boldsymbol{W}\in\mathbb{R}^{n\times m}\),其更新规则是
\(\boldsymbol{G}_t\)(Gradient)
- 含义:当前时间步 \(t\) 的梯度矩阵。
- 数学定义:\(\boldsymbol{G}_t = \nabla_{\boldsymbol{W}} \mathcal{L}(\boldsymbol{W}_{t-1})\)
- 形状:与权重矩阵 \(\boldsymbol{W}\) 相同(例如 \(d_{in} \times d_{out}\))。
- 作用:它告诉优化器当前参数应该往哪个方向移动以减少 Loss。
\(\boldsymbol{M}_t\) (Momentum)
- 含义:动量矩阵(一阶矩估计)。
- 数学定义:\(\boldsymbol{M}_t = \beta \boldsymbol{M}_{t-1} + \boldsymbol{G}_t\)
- 这里 \(\beta\) 是动量系数(通常取 0.9 或 0.95)。
- 注意:有些实现(如 PyTorch 的 SGD)可能会写成 \(\boldsymbol{M}_t = \beta \boldsymbol{M}_{t-1} + (1-\beta)\boldsymbol{G}_t\),本质是一样的,只是缩放比例不同。
- 作用:它平滑了梯度的波动,累积了历史梯度的方向,帮助优化器冲过鞍点(Saddle Points)并加速收敛。
- 关键点:Muon 的核心操作
msign是直接作用在这个动量矩阵 \(\boldsymbol{M}_t\) 上的,而不是像 Adam 那样作用在梯度平方和上。
\(\boldsymbol{W}_t\)(Weight)
- 含义:权重矩阵(模型参数)。
- 数学定义:\(\boldsymbol{W}_t\) 是第 \(t\) 步更新后的参数值。
- 形状:例如 \(d_{in} \times d_{out}\) 的二维矩阵。
- 作用:这是神经网络实际存储和使用的参数。
- 更新逻辑:
- \(\text{msign}(\boldsymbol{M}_t)\):提供了经过正交化处理后的更新方向(矩阵级归一化)。
- \(\lambda \boldsymbol{W}_{t-1}\):权重衰减项(Weight Decay),用于正则化。
- \(\eta_t\):学习率(Learning Rate)。
Muon 的精髓在于:它不直接用 \(\boldsymbol{M}_t\) 更新 \(\boldsymbol{W}\),而是先对 \(\boldsymbol{M}_t\) 做了一个 msign(矩阵符号函数)变换,强制让更新量的能量在各个方向上均匀分布(正交化),然后再去更新 \(\boldsymbol{W}\)。
这里\(\text{msign}\)是矩阵符号函数,它并不是简单地对矩阵每个分量取\(\text{sign}\)操作,而是\(\text{sign}\)函数的矩阵化推广,它跟SVD的关系是:
其中\(\boldsymbol{U}\in\mathbb{R}^{n\times n},\boldsymbol{\Sigma}\in\mathbb{R}^{n\times m},\boldsymbol{V}\in\mathbb{R}^{m\times m}\),\(r\)是\(\boldsymbol{M}\)的秩。更多的理论细节我们稍后再展开,这里我们先来尝试直观感知如下事实:
Muon是一个类似于Adam的自适应学习率优化器。
像Adagrad、RMSprop、Adam等自适应学习率优化器的特点是通过除以梯度平方的滑动平均的平方根来调整每个参数的更新量,这达到了两个效果:
- 损失函数的常数缩放不影响优化轨迹;
- 每个参数分量的更新幅度尽可能一致。
Muon正好满足这两个特性:
- 损失函数乘以\(\lambda\),\(\boldsymbol{M}\)也会乘以\(\lambda\),结果是\(\boldsymbol{\Sigma}\)被乘以\(\lambda\),但Muon最后的更新量是将\(\boldsymbol{\Sigma}\)变为单位阵,所以不影响优化结果;
- 当\(\boldsymbol{M}\)被SVD为\(\boldsymbol{U}\boldsymbol{\Sigma}\boldsymbol{V}^{\top}\)时,\(\boldsymbol{\Sigma}\)的不同奇异值体现了\(\boldsymbol{M}\)的“各向异性”,而将它们都置一则更加各向同性,也起到同步更新幅度的作用。
对了,关于第2点,有没有读者想起了BERT-whitening?另外要指出的是,Muon还有个Nesterov版,它只是将更新规则中的\(\text{msign}(\boldsymbol{M}_t)\)换成\(\text{msign}(\beta\boldsymbol{M}_t + \boldsymbol{G}_t)\),其余部份完全一致,简单起见就不展开介绍了。
符号函数
利用SVD,我们还可以证明恒等式
其中\({}^{-1/2}\)是矩阵的\(1/2\)次幂的逆矩阵,如果不可逆的话则取伪逆。这个恒等式能让我们更好理解为什么\(\text{msign}\)是\(\text{sign}\)的矩阵推广:对于标量\(x\)我们有\(\text{sign}(x)=x(x^2)^{-1/2}\),正是上式的一个特殊情形(当\(\boldsymbol{M}\)是\(1\times 1\)矩阵时)。这个特殊例子还可以推广到对角阵\(\boldsymbol{M}=\text{diag}(\boldsymbol{m})\):
其中\(\text{sign}(\boldsymbol{m})\)、\(\text{sign}(\boldsymbol{M})\)是指向量/矩阵的每个分量都取\(\text{sign}\)。上式意味着,当\(\boldsymbol{M}\)是对角阵时,Muon就退化为带动量的SignSGD(Signum)或笔者所提的Tiger,它们都是Adam的经典近似。反过来说,Muon与Signum、Tiger的区别就是Element-wise的\(\text{sign}(\boldsymbol{M})\)替换成了矩阵版\(\text{msign}(\boldsymbol{M})\)。
对于\(n\)维向量来说,我们还可以视为\(n\times 1\)的矩阵,此时\(\text{msign}(\boldsymbol{m}) = \boldsymbol{m}/\Vert\boldsymbol{m}\Vert_2\)正好是l_2归一化。所以,在Muon框架下对向量我们有两种视角:一是对角矩阵,如LayerNorm的gamma参数,结果是对动量取\(\text{sign}\);二是\(n\times 1\)的矩阵,结果是对动量做l_2归一化。此外,输入和输出的Embedding虽然也是矩阵,但它们使用上是稀疏的,所以更合理的方式也是将它们当成多个向量独立处理。
当\(m=n=r\)时,\(\text{msign}(\boldsymbol{M})\)还有一个意义是“最优正交近似”:
类似地,对于\(\text{sign}(\boldsymbol{M})\)我们可以写出(假设\(\boldsymbol{M}\)没有零元素):
不论是\(\boldsymbol{O}^{\top}\boldsymbol{O} = \boldsymbol{I}\)还是\(\boldsymbol{O}\in\{-1,1\}^{n\times m}\),我们都可以视为对更新量的一种规整化约束,所以Muon和Signum、Tiger可以视作是同一思路下的优化器,它们都以动量\(\boldsymbol{M}\)为出发点来构建更新量,只是为更新量选择了不同的规整化方法。
(2)的证明:对于正交矩阵\(\boldsymbol{O}\),我们有\[\begin{aligned} \Vert \boldsymbol{M} - \boldsymbol{O}\Vert_F^2 =&\, \Vert \boldsymbol{M}\Vert_F^2 + \Vert \boldsymbol{O}\Vert_F^2 - 2\langle\boldsymbol{M},\boldsymbol{O}\rangle_F \\[5pt] =&\, \Vert \boldsymbol{M}\Vert_F^2 + n - 2\text{Tr}(\boldsymbol{M}\boldsymbol{O}^{\top})\\[5pt] =&\, \Vert \boldsymbol{M}\Vert_F^2 + n - 2\text{Tr}(\boldsymbol{U}\boldsymbol{\Sigma}\boldsymbol{V}^{\top}\boldsymbol{O}^{\top})\\[5pt] =&\, \Vert \boldsymbol{M}\Vert_F^2 + n - 2\text{Tr}(\boldsymbol{\Sigma}\boldsymbol{V}^{\top}\boldsymbol{O}^{\top}\boldsymbol{U})\\ =&\, \Vert \boldsymbol{M}\Vert_F^2 + n - 2\sum_{i=1}^n \boldsymbol{\Sigma}_{i,i}(\boldsymbol{V}^{\top}\boldsymbol{O}^{\top}\boldsymbol{U})_{i,i} \end{aligned}\]
其中涉及到的运算规则我们在伪逆中已经介绍过。由于\(\boldsymbol{U},\boldsymbol{V},\boldsymbol{O}\)都是正交矩阵,所以\(\boldsymbol{V}^{\top}\boldsymbol{O}^{\top}\boldsymbol{U}\)也是正交矩阵,正交矩阵的每个分量必然不超过1,又因为\(\boldsymbol{\Sigma}_{i,i} > 0\),所以上式取最小值对应于每个(\(\boldsymbol{V}^{\top}\boldsymbol{O}^{\top}\boldsymbol{U})_{i,i}\)取最大值,即\((\boldsymbol{V}^{\top}\boldsymbol{O}^{\top}\boldsymbol{U})_{i,i}=1\),这意味着\(\boldsymbol{V}^{\top}\boldsymbol{O}^{\top}\boldsymbol{U}=\boldsymbol{I},即\boldsymbol{O}=\boldsymbol{U}\boldsymbol{V}^{\top}\)。
该结论还可以仔细地推广到\(m,n,r\)不相等的情形,但这里不作进一步展开。
迭代求解
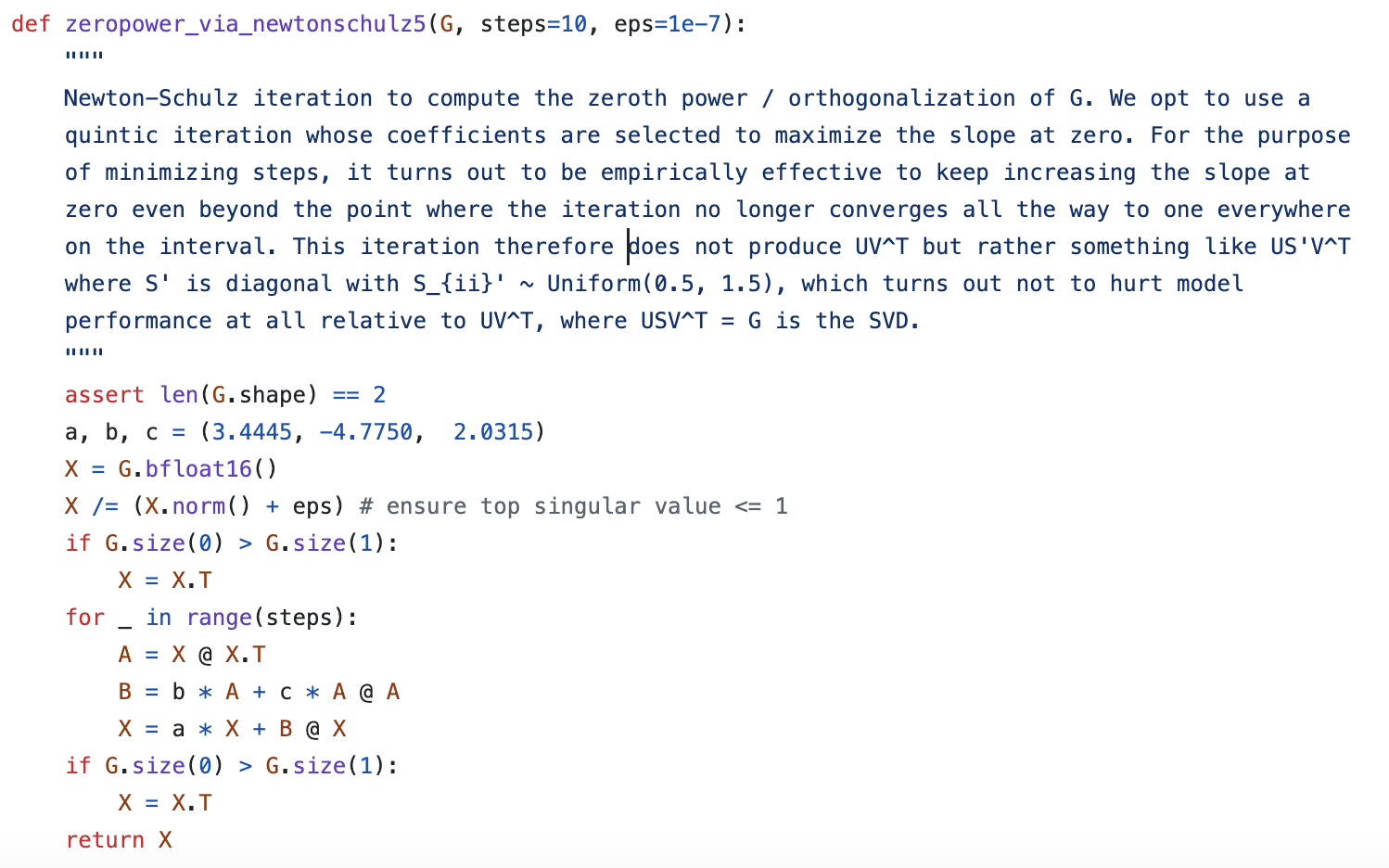
实践中,如果每一步都对\(\boldsymbol{M}\)做SVD来求解\(\text{msign}(\boldsymbol{M})\)的话,那么计算成本还是比较大的,因此作者提出了用Newton-schulz迭代来近似计算\(\text{msign}\)\((\boldsymbol{M})\)。
迭代的出发点是恒等式(1),不失一般性,我们假设\(n\geq m\),然后考虑在\(\boldsymbol{M}^{\top}\boldsymbol{M}=\boldsymbol{I}\)处泰勒展开\((\boldsymbol{M}^{\top}\boldsymbol{M})^{-1/2}\),展开的方式是直接将标量函数\(t^{-1/2}\)的结果用到矩阵中:
保留到二阶,结果是\((15 - 10t + 3t^2)/8\),那么我们有
假如\(\boldsymbol{X}_t\)是\(\text{msign}(\boldsymbol{M})\)的某个近似,我们认为将它代入上式后,会得到\(\text{msign}(\boldsymbol{M})\)的一个更好的近似,于是我们得到一个可用的迭代格式
然而,查看Muon的官方代码我们就会发现,它里边的Newton-schulz迭代确实是这个形式,但三个系数却是(3.4445, -4.7750, 2.0315),而且作者没有给出数学推导,只有一段语焉不详的注释:
收敛加速
为了猜测官方迭代算法的来源,我们考虑一般的迭代过程
其中\(a,b,c\)是三个待求解的系数,如果想要更高阶的迭代算法,我们也可以逐次补充\(\boldsymbol{X}_t(\boldsymbol{X}_t^{\top}\boldsymbol{X}_t)^3\)、\(\boldsymbol{X}_t(\boldsymbol{X}_t^{\top}\boldsymbol{X}_t)^4\)等项,下面的分析过程是通用的。
我们选择的初始值是\(\boldsymbol{X}_0=\boldsymbol{M}/\Vert\boldsymbol{M}\Vert_F\),\(\Vert\cdot\Vert_F\)是矩阵的\(F\)范数,选择的依据是除以\(\Vert\boldsymbol{M}\Vert_F\)不改变SVD的\(\boldsymbol{U},\boldsymbol{V}\),但可以让\(\boldsymbol{X}_0\)的所有奇异值都在[0,1]之间,让迭代的初始奇异值更标准一些。现在假设\(\boldsymbol{X}_t\)可以SVD为\(\boldsymbol{U}\boldsymbol{\Sigma}_t\boldsymbol{V}^{\top}\),那么代入上式我们可以得到
因此,(3)实际上在迭代奇异值组成的对角阵\(\boldsymbol{\Sigma}_{[:r,:r]}\),如果记\(\boldsymbol{X}_t=\boldsymbol{U}_{[:,:r]}\boldsymbol{\Sigma}_{t,[:r,:r]}\boldsymbol{V}_{[:,:r]}^{\top}\),那么有\(\boldsymbol{\Sigma}_{t+1,[:r,:r]} = g(\boldsymbol{\Sigma}_{t,[:r,:r]})\),其中\(g(x) = ax + bx^3 + cx^5\)。又因为对角阵的幂等于对角线元素各自取幂,所以问题简化成单个奇异值\(\sigma\)的迭代。我们的目标是计算\(\boldsymbol{U}_{[:,:r]}\boldsymbol{V}_{[:,:r]}^{\top}\),换言之希望通过迭代将\(\boldsymbol{\Sigma}_{[:r,:r]}\)变为单位阵,这又可以简化为迭代\(\sigma_{t+1} = g(\sigma_t)\)将单个奇异值变为\(1\)。
受@leloykun启发,我们将\(a,b,c\)的选择视为一个最优化问题,目标是让迭代过程对于任意初始奇异值都收敛得尽可能快。首先我们将\(g(x)\)重新参数化为
其中\(x_1 \leq x_2\)。该参数化的好处是直观表示出了迭代的5个不动点0,\(\pm x_1,\pm x_2\)。由于我们的目标是收敛到1,因此初始化我们选择\(x_1 < 1,x_2 > 1\),想法是不管迭代过程往\(x_1\)走还是往\(x_2\)走,结果都是1附近。
接下来,我们确定迭代步数\(T\),这样迭代过程就称为一个确定性函数,然后我们将矩阵的形状(即\(n,m\))确定好,就可以采样一批矩阵,并通过SVD来算奇异值。最后,我们将这些奇异值当成输入,而目标输出则是1,损失函数是平方误差,整个模型完全可导,可以用梯度下降解决(@leloykun则假设了\(x_1 + x_2 = 2\),然后用网格搜索来求解)。
一些计算结果:
这里的\(\text{mse}_{\text{o}}\)是有Muon作者的\(a,b,c\)算出来的结果。从表格可以看出,结果跟矩阵大小、迭代步数都有明显关系;从损失函数来看,非方阵比方阵更容易收敛;Muon作者给出的\(a,b,c\),大概是迭代步数为5时方阵的最优解。当迭代步数给定时,结果依赖于矩阵大小,这本质上是依赖于奇异值的分布,关于这个分布有个值得一提的结果是当\(n,m\to\infty\)时为Marchenko–Pastur分布。
参考代码:
import jax
import jax.numpy as jnp
from tqdm import tqdm
n, m, T = 1024, 1024, 5
key, data = jax.random.key(42), jnp.array([])
for _ in tqdm(range(1000), ncols=0, desc='SVD'):
key, subkey = jax.random.split(key)
M = jax.random.normal(subkey, shape=(n, m))
S = jnp.linalg.svd(M, full_matrices=False)[1]
data = jnp.concatenate([data, S / (S**2).sum()**0.5])
@jax.jit
def f(w, x):
k, x1, x2 = w
for _ in range(T):
x = x + k * x * (x**2 - x1**2) * (x**2 - x2**2)
return ((x - 1)**2).mean()
f_grad = jax.grad(f)
w, u = jnp.array([1, 0.9, 1.1]), jnp.zeros(3)
for _ in tqdm(range(100000), ncols=0, desc='SGD'):
u = 0.9 * u + f_grad(w, data) # 动量加速
w = w - 0.01 * u
k, x1, x2 = w
a, b, c = 1 + k * x1**2 * x2**2, -k * (x1**2 + x2**2), k
print(f'{n} & {m} & {T} & {k:.3f} & {x1:.3f} & {x2:.3f} & {a:.3f} & {b:.3f} & {c:.3f} & {f(w, data):.5f}')一些思考
如果按照默认选择\(T=5\),那么对于一个\(n\times n\)的矩阵参数,Muon的每一步更新至少需要算15次\(n\times n与n\times n\)的矩阵乘法,这计算量毋庸置疑是比Adam明显大的,由此可能有读者担心Muon实践上是否可行。
事实上,这种担心是多余的,Muon计算虽然比Adam复杂,但每一步增加的时间不多,笔者的结论是5%内,Muon作者则声称能做到2%。这是因为Muon的矩阵乘法发生在当前梯度计算完后、下一梯度计算前,这期间几乎所有的算力都是空闲的,而这些矩阵乘法是静态大小且可以并行,因此不会明显增加时间成本,反而是Muon比Adam少一组缓存变量,显存成本更低。
Muon最值得深思的地方,其实是向量与矩阵的内在区别,以及它对优化的影响。SGD、Adam、Tiger等常见优化器的更新规则是Element-wise的,即不论向量、矩阵参数,实际都视为一个大向量,分量按照相同的规则独立地更新。具备这个特性的优化器往往理论分析起来更加简化,也方便张量并行,因为一个大矩阵切成两个小矩阵独立处理,并不改变优化轨迹。
但Muon不一样,它以矩阵为基本单位,考虑了矩阵的一些独有特性。可能有些读者会奇怪:矩阵和向量不都只是一堆数字的排列吗,能有什么区别?举个例子,矩阵我们有“迹(trace)”这个概念,它是对角线元素之和,这个概念不是瞎定义的,它有一个重要特性是在相似变换下保持不变,它还等于矩阵的所有特征值之和。从这个例子就可以看出,矩阵的对角线元素跟非对角线元素,地位其实是不完全对等的。而Muon正是因为考虑了这种不对等性,才有着更好的效果。
当然,这也会导致一些负面影响。如果一个矩阵被划分到不同设备上,那么用Muon时就需要将它们的梯度就需要汇聚起来再计算更新量了,而不能每个设备独立更新,这增加了通信成本。即便我们不考虑并行方面,这个问题也存在,比如Multi-Head Attention一般是通过单个大矩阵投影到\(Q\)(\(K,V\)同理),然后用reshape的方式得到多个Head,这样在模型参数中就只有单个矩阵,但它本质上是多个小矩阵,所以按道理我们需要将大矩阵拆开成多个小矩阵独立更新。
总之,Muon这种非Element-wise的更新规则,在捕捉向量与矩阵的本质差异的同时,也会引入一些小问题,这可能会不满足一些读者的审美。
(补充:几乎在本博客发布的同时,Muon的作者Keller Jordan也发布了自己的一篇博客《Muon: An optimizer for hidden layers in neural networks》。)
范数视角
从理论上看,Muon捕捉了矩阵的什么关键特性呢?也许接下来的范数视角可以回答我们的问题。
这一节的讨论主要参考了论文《Stochastic Spectral Descent for Discrete Graphical Models》和《Old Optimizer, New Norm: An Anthology》,特别是后一篇。对于向量参数\(\boldsymbol{w}\in\mathbb{R}^n\),我们将下一步的更新规则定义为
其中\(\Vert\Vert\)是某个向量范数,这称为在某个范数约束下的“最速梯度下降”。接着假设\(\eta_t\)足够小,那么第一项占主导,这意味着\(\boldsymbol{w}_{t+1}与\boldsymbol{w}_t\)会很接近,于是我们假设\(\mathcal{L}(\boldsymbol{w})\)的一阶近似够用了,于是问题简化成
记\(\Delta\boldsymbol{w}_{t+1} = \boldsymbol{w}_{t+1}-\boldsymbol{w}_t, \boldsymbol{g}_t = \nabla_{\boldsymbol{w}_t}\mathcal{L}(\boldsymbol{w}_t)\),那么可以简写成
计算\(\Delta\boldsymbol{w}_{t+1}\)的一般思路是求导,但《Old Optimizer, New Norm: An Anthology》提供了一个不用求导的统一方案:将\(\Delta\boldsymbol{w}\)分解为范数\(\gamma = \Vert\Delta\boldsymbol{w}\Vert\)和方向向量\(\boldsymbol{\varphi} = -\Delta\boldsymbol{w}/\Vert\Delta\boldsymbol{w}\Vert\),于是
\(\gamma\)只是一个标量,跟学习率类似,容易求得最优值是\(\eta_t\Vert \boldsymbol{g}_t\Vert^{\dagger}\),而更新方向则是最大化\(\boldsymbol{g}_t^{\top}\boldsymbol{\varphi}(\Vert\boldsymbol{\varphi}\Vert=1)\)的\(\boldsymbol{\varphi}^*\)。现在代入欧氏范数即\(\Vert\boldsymbol{\varphi}\Vert_2 = \sqrt{\boldsymbol{\varphi}^{\top}\boldsymbol{\varphi}}\),我们就有\(\Vert \boldsymbol{g}_t\Vert^{\dagger}=\Vert \boldsymbol{g}_t\Vert_2\)和\(\boldsymbol{\varphi}^* = \boldsymbol{g}_t/\Vert\boldsymbol{g}_t\Vert_2\),这样一来\(\Delta\boldsymbol{w}_{t+1}=-\eta_t \boldsymbol{g}_t\),即梯度下降(SGD)。一般地,对于p范数
Hölder不等式给出\(\boldsymbol{g}^{\top}\boldsymbol{\varphi} \leq \Vert \boldsymbol{g}\Vert_q \Vert \boldsymbol{\varphi}\Vert_p\),其中\(1/p + 1/q = 1\),利用它我们得到
等号成立的条件是
以它为方向向量的优化器叫做pbSGD,可参考《pbSGD: Powered Stochastic Gradient Descent Methods for Accelerated Non-Convex Optimization》。特别地,当\(p\to\infty\)时有\(q\to 1\)和\(|g_i|^{q/p}\to 1\),此时退化为SignSGD,即SignSGD实际上是\(\Vert\Vert_{\infty}\)范数下的最速梯度下降。
矩阵范数
现在让我们将目光切换到矩阵参数\(\boldsymbol{W}\in\mathbb{R}^{n\times m}\)。类似地,我们将它的更新规则定义为
此时\(\Vert\Vert\)是某种矩阵范数。同样使用一阶近似,我们得到
这里\(\Delta\boldsymbol{W}_{t+1} = \boldsymbol{W}_{t+1}-\boldsymbol{W}_t, \boldsymbol{G}_t = \nabla_{\boldsymbol{W}_t}\mathcal{L}(\boldsymbol{W}_t)\)。还是使用“范数-方向”解耦,即设\(\gamma = \Vert\Delta\boldsymbol{w}\Vert和\boldsymbol{\Phi} = -\Delta\boldsymbol{W}/\Vert\Delta\boldsymbol{W}\Vert\),我们得到
然后就是具体范数具体分析了。矩阵常用的范数有两种,一种是F范数,它实际上就是将矩阵展平成向量后算的欧氏范数,这种情况下结论跟向量是一样的,答案就是SGD,这里不再展开;另一种则是由向量范数诱导出来的2范数,也称谱范数:
注意右端出现的\(\Vert\Vert_2\)的对象都是向量,所以定义是明确的。由于2范数是由“矩阵-向量”乘法诱导出来的,因此它更贴合矩阵乘法,并且还恒成立\(\Vert\boldsymbol{\Phi}\Vert_2\leq \Vert\boldsymbol{\Phi}\Vert_F\),即2范数相比\(F\)范数更紧凑。
所以,接下来我们就针对2范数进行计算。设\(\boldsymbol{G}\)的SVD为\(\boldsymbol{U}\boldsymbol{\Sigma}\boldsymbol{V}^{\top} = \sum\limits_{i=1}^r \sigma_i \boldsymbol{u}_i \boldsymbol{v}_i^{\top}\),我们有
根据定义,当\(\Vert\boldsymbol{\Phi}\Vert_2=1\)时\(\Vert\boldsymbol{\Phi}\boldsymbol{v}_i\Vert_2\leq \Vert\boldsymbol{v}_i\Vert_2=1\),于是\(\boldsymbol{u}_i^{\top}\boldsymbol{\Phi}\boldsymbol{v}_i\leq 1\),因此
等号在所有\(\boldsymbol{u}_i^{\top}\boldsymbol{\Phi}\boldsymbol{v}_i\)都等于1时取到,此时
至此,我们证明了\(2\)范数惩罚下的梯度下降正是\(\beta=0\)时的Muon优化器!当\(\beta > 0\)时,滑动平均生效,我们可以将它视为梯度的一种更精准的估计,所以改为对动量取\(\text{msign}\)。总的来说,Muon相当于2范数约束下的梯度下降,2范数更好地度量了矩阵之间的本质差异,从而使每一步都走得更精准、更本质。
追根溯源
Muon还有一个更久远的相关工作《Shampoo: Preconditioned Stochastic Tensor Optimization》,这是2018年的论文,提出了名为Shampoo的优化器,跟Muon有异曲同工之处。
Adam通过梯度平方的平均来自适应学习率的策略,最早提出自Adagrad的论文《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》,里边提出的是直接将梯度平方累加的策略,这相当于全局等权平均,后来的RMSProp、Adam则类比动量的设计,改为滑动平均,发现在实践中表现更好。
不仅如此,Adagrad最开始提出的实际是累加外积\(\boldsymbol{g}\boldsymbol{g}^{\top}\),只不过缓存外积空间成本太大,所以实践中改为Hadamard积\(\boldsymbol{g}\odot\boldsymbol{g}\)。那累加外积的理论依据是什么呢?这我们在《从Hessian近似看自适应学习率优化器》推导过,答案是“梯度外积的长期平均\(\mathbb{E}[\boldsymbol{g}\boldsymbol{g}^{\top}]\)近似了Hessian矩阵的平方\(\sigma^2\boldsymbol{\mathcal{H}}_{\boldsymbol{\theta}^*}^2\)”,所以这实际上在近似二阶的Newton法。
Shampoo传承了Adagrad缓存外积的思想,但考虑到成本问题,取了个折中。跟Muon一样,它同样是针对矩阵(以及高阶张量)进行优化,策略是缓存梯度的矩阵乘积\(\boldsymbol{G}\boldsymbol{G}^{\top}和\boldsymbol{G}^{\top}\boldsymbol{G}\),而不是外积,这样空间成本是\(\mathcal{O}(n^2 + m^2)\)而不是\(\mathcal{O}(n^2 m^2)\):
这里的\(\beta\)是笔者自己加的,Shampoo默认了\(\beta=1\),\({}^{-1/4}\)同样是矩阵的幂运算,可以用SVD来完成。由于Shampoo没有提出Newton-schulz迭代之类的近似方案,是直接用SVD算的,所以为了节省计算成本,它并没有每一步都计算\(\boldsymbol{L}_t^{-1/4}\)和\(\boldsymbol{R}_t^{-1/4}\),而是间隔一定步数才更新它们的结果。
特别地,当\(\beta=0\)时,Shampoo的更新向量为\((\boldsymbol{G}\boldsymbol{G}^{\top})^{-1/4}\boldsymbol{G}(\boldsymbol{G}^{\top}\boldsymbol{G})^{-1/4}\),通过对\(\boldsymbol{G}\)进行SVD我们可以证明
这表明\(\beta=0\)时Shampoo和Muon在理论上是等价的!因此,Shampoo与Muon在更新量的设计方面有着相通之处。
算法再探
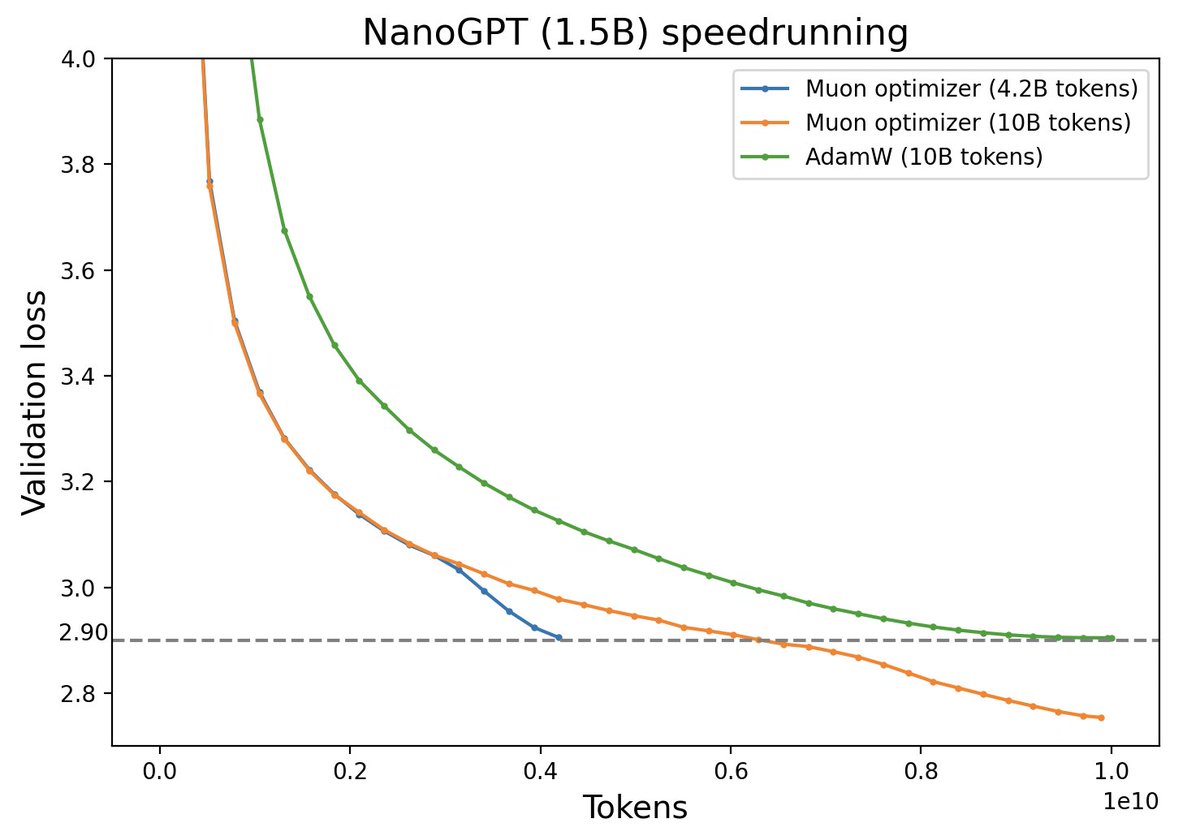
这里解读一下最新的技术报告《Muon is Scalable for LLM Training》,里边分享了我们上面介绍过的Muon优化器的一次较大规模的实践,并开源了相应的模型(我们称之为“Moonlight”,目前是一个3B/16B的MoE模型)。我们发现了一个比较惊人的结论:在我们的实验设置下,Muon相比Adam能够达到将近2倍的训练效率。
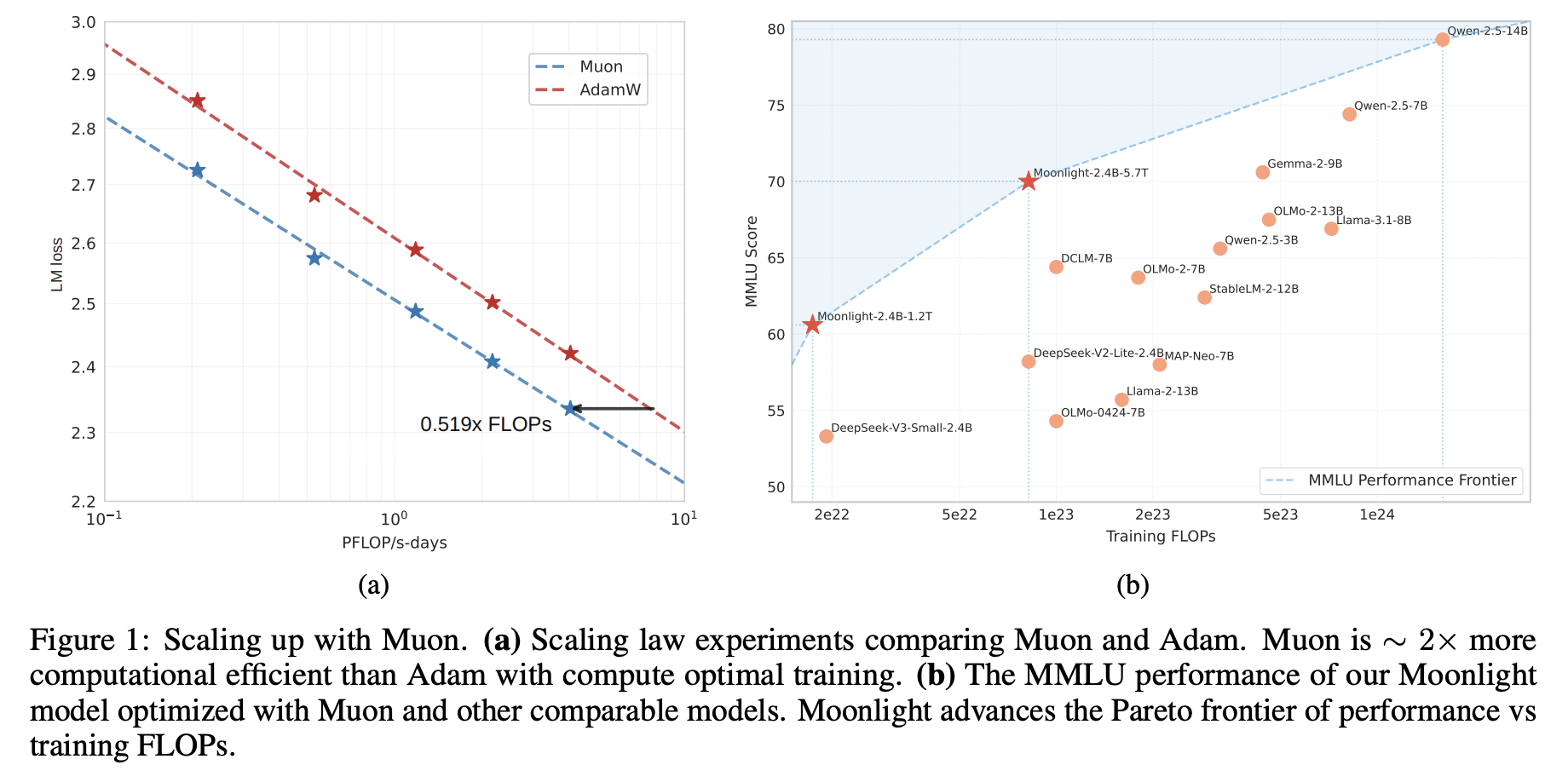
优化器的工作说多不多,但说少也不少,为什么我们会选择Muon来作为新的尝试方向呢?已经调好超参的Adam优化器,怎么快速切换到Muon上进行尝试呢?模型Scale上去之后,Muon与Adam的性能效果差异如何?接下来将分享我们的思考过程。
优化原理
多数优化器改进实际上都只是一些小补丁,不能说毫无价值,但终究没能给人一种深刻和惊艳的感觉。
我们需要从更贴近本质的原理出发,来思考什么才是好的优化器。直观来想,理想的优化器应当有两个特性:稳和快。具体来说,理想的优化器每一步的更新应该满足两点:
- 对模型扰动尽可能小;
- 对Loss贡献尽可能大。
说更直接点,就是我们不希望大改模型(稳),但希望大降Loss(快),典型的“既要...又要...”。
怎么将这两个特性转化为数学语言呢?稳我们可以理解为对更新量的一个约束,而快则可以理解为寻找让损失函数下降最快的更新量,所以这可以转化为一个约束优化问题。用回前文的记号,对于矩阵参数\(\boldsymbol{W}\in\mathbb{R}^{n\times m}\),其梯度为\(\boldsymbol{G}\in\mathbb{R}^{n\times m}\),当参数由\(\boldsymbol{W}\)变成\(\boldsymbol{W}+\Delta\boldsymbol{W}\)时,损失函数的变化量为
那么在稳的前提下寻找快的更新量,那么就可以表示为
这里\(\rho(\Delta\boldsymbol{W})\geq 0\)是稳的某个指标,越小表示越稳,而\(\eta\)是某个小于1的常数,表示我们对稳的要求,后面我们会看到它实际上就是优化器的学习率。如果读者不介意,我们可以模仿理论物理的概念,称上述原理为优化器的“最小作用量原理(Least Action Principle)”。
矩阵范数
式(4)唯一不确定的就是稳的度量\(\rho(\Delta\boldsymbol{W})\),选定\(\rho(\Delta\boldsymbol{W})\)后就可以把\(\Delta\boldsymbol{W}\)明确求解出来(至少理论上没问题)。某种程度上来说,我们可以认为不同优化器的本质差异就是它们对稳的定义不一样。
很多读者在刚学习SGD时想必都看到过类似“梯度反方向是函数值局部下降最快的方向”的说法,放到这里的框架来看,它其实就是把稳的度量选择为矩阵的\(F\)范数\(\Vert\Delta\boldsymbol{W}\Vert_F\),也就是说,“下降最快的方向”并不是一成不变的,选定度量后才能把它确定下来,换一个范数就不一定是梯度反方向了。
接下来的问题自然是什么范数才能最恰当地度量稳?如果我们加了强约束,那么稳则稳矣,但优化器举步维艰,只能收敛到次优解;相反如果减弱约束,那么优化器放飞自我,那么训练进程将会极度不可控。所以,最理想的情况就能找到稳的最精准指标。考虑到神经网络以矩阵乘法为主,我们以\(\boldsymbol{y}=\boldsymbol{x}\boldsymbol{W}\)为例,有
上式的意思是,当参数由\(\boldsymbol{W}\)变成\(\boldsymbol{W}+\Delta\boldsymbol{W}\)时,模型输出变化量为\(\Delta\boldsymbol{y}\),我们寄望于这个变化量的模长能够被\(\Vert\boldsymbol{x}\Vert\)以及\(\Delta\boldsymbol{W}\)相关的一个函数\(\rho(\Delta\boldsymbol{W})\)控制,我们就用这个函数作为稳的指标。从线性代数我们知道,\(\rho(\Delta\boldsymbol{W})\)的最准确值就是\(\Delta\boldsymbol{W}\)的谱范数\(\Vert\Delta\boldsymbol{W}\Vert_2\),代入式(4)得到
这个优化问题求解出来就是\(\beta=0\)的Muon:
当\(\beta > 0\)时,\(\boldsymbol{G}\)换成动量\(\boldsymbol{M}\),\(\boldsymbol{M}\)可以看作是对梯度更平滑的估计,所以依然可以理解为上式的结论,因此我们可以得出“Muon就是谱范数下的最速下降”的说法,至于Newton-schulz迭代之类的,则是计算上的近似,这里就不细说。
权重衰减
至此,我们可以回答第一个问题:为什么选择尝试Muon?因为跟SGD一样,Muon给出的同样是下降最快的方向,但它的谱范数约束比SGD的\(F\)范数更为精准,所以有更佳的潜力。另一方面,从“为不同的参数选择最恰当的约束”角度来改进优化器,看起来也比各种补丁式修改更为本质。
当然,潜力不意味着实力,在更大尺寸的模型上验证Muon存在一些“陷阱”。首先登场的是Weight Decay问题,尽管我们在上面介绍Muon的时候带上了Weight Decay,但实际上作者提出Muon时是没有的,而我们一开始也按照官方版本来实现,结果发现Muon前期收敛是快,但很快就被Adam追上了,而且各种“内科”还有崩溃的苗头。
我们很快意识到这可能是Weight Decay的问题,于是补上Weight Decay:
继续实验,果不其然,这时候Muon一直保持领先于Adam,如论文Figure 2所示:
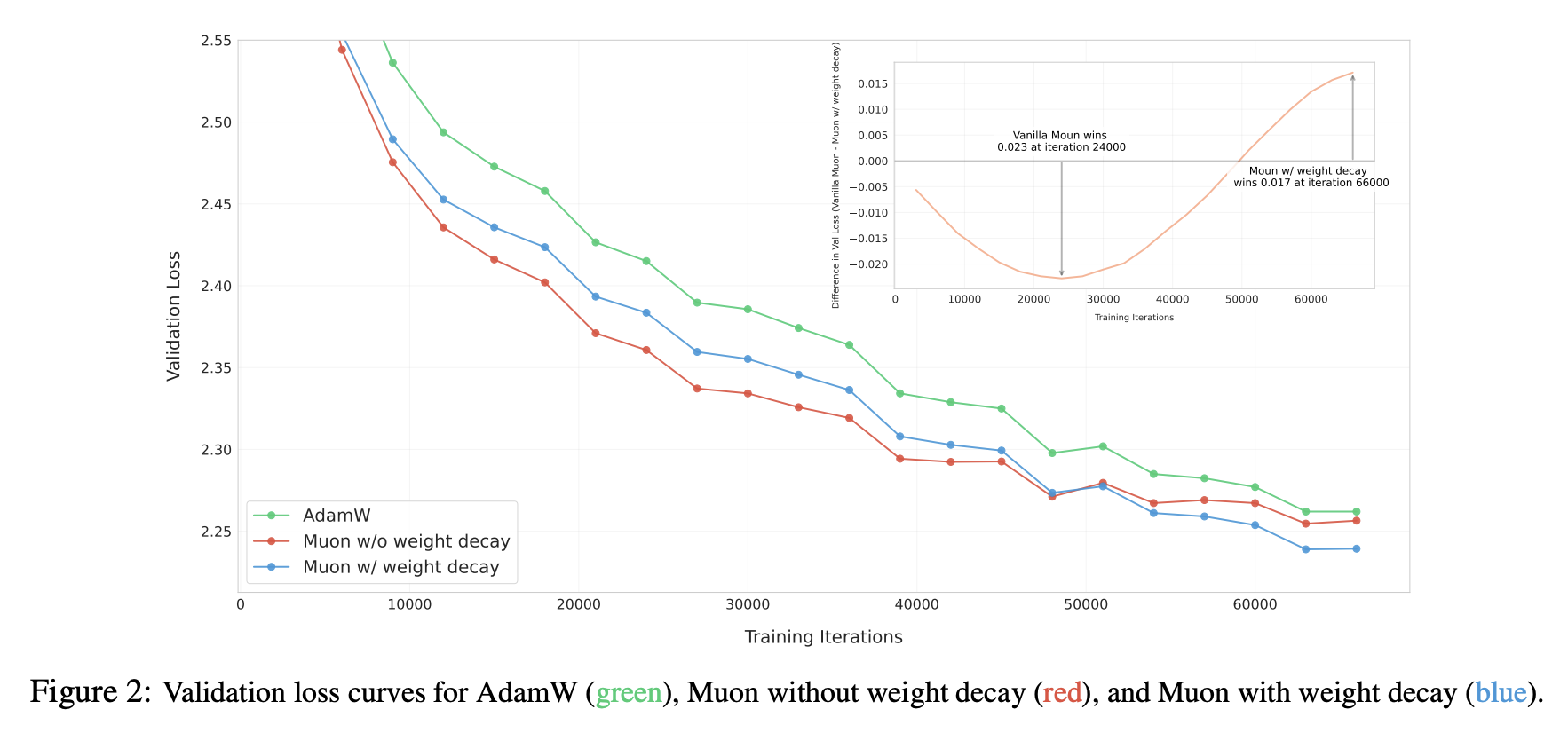
Weight Decay起到什么作用呢?事后分析来看,可能比较关键的地方是能够让参数范数保持有界:
这里的\(\Vert\cdot\Vert\)是任意一种矩阵范数,即上述不等式对于任意矩阵范数都是成立的,\(\boldsymbol{\Phi}_t\)是优化器给出的更新向量,对Muon来说是\(\text{msign}(\boldsymbol{M})\),当我们取谱范数时,有\(\Vert\text{msign}(\boldsymbol{M})\Vert_2 = 1\),所以对于Muon来说有
这保证了模型“内科”的健康,因为\(\Vert\boldsymbol{x}\boldsymbol{W}\Vert\leq \Vert\boldsymbol{x}\Vert\Vert\boldsymbol{W}\Vert_2\),\(\Vert\boldsymbol{W}\Vert_2\)被控制住了,意味着\(\Vert\boldsymbol{x}\boldsymbol{W}\Vert\)也被控制住了,就不会有爆炸的风险,这对于Attention Logits爆炸等问题也尤其重要。当然这个上界在多数情况下还是相当宽松的,实际中参数的谱范数多数会明显小于这个上界,这个不等关系只是简单显示Weight Decay有控制范数的性质存在。
RMS对齐
当我们决定去尝试新的优化器时,一个比较头疼的问题是如何快速找到接近最优的超参数,比如Muon至少有学习率\(\eta_t\)和衰减率\(\lambda\)两个超参数。网格搜索自然是可以,但比较费时费力,这里我们提出Update RMS对齐的超参迁移思路,可以将Adam调好的超参数用到其他优化器上。
首先,对于一个矩阵\(\boldsymbol{W}\in\mathbb{R}^{n\times m}\),它的RMS(Root Mean Square)定义为
简单来说,RMS度量了矩阵每个元素的平均大小。我们观察到Adam更新量的RMS是比较稳定的,通常在0.2~0.4之间,这也是为什么理论分析 常用SignSGD作为Adam近似。基于此,我们建议通过RMS Norm将新优化器的Update RMS对齐到0.2:
这样一来,我们就可以复用Adam的\(\eta_t\)和\(\lambda\),以达到每步对参数的更新幅度大致相同的效果。实践表明,通过这个简单策略从Adam迁移到Muon,就能训出明显优于Adam的效果,接近进一步对Muon超参进行精搜索的结果。特别地,Muon的\(\text{RMS}(\boldsymbol{\Phi}_t)=\text{RMS}(\boldsymbol{U}_{[:,:r]}\boldsymbol{V}_{[:,:r]}^{\top})\)还可以解析地算出来:
即\(\text{RMS}(\boldsymbol{\Phi}_t) = \sqrt{r/nm}\),实践中一个矩阵严格低秩的概率比较小,因此可以认为\(r = \min(n,m)\),从而有\(\text{RMS}(\boldsymbol{\Phi}_t) = \sqrt{1/\max(n,m)}\)。所以我们最终没有用RMS Norm而是用等价的解析版本:
最后的这个式子,表明了在Muon中不适宜所有参数使用同一个学习率。比如Moonlight是一个MoE模型,有不少矩阵参数的形状都偏离方阵,\(\max(n,m)\)跨度比较大,如果用单一学习率,必然会导致某些参数学习过快/过慢的不同步问题,从而影响最终效果。
实验分析
我们在2.4B/16B这个尺寸的MoE上,对Adam和Muon做了比较充分的对比,发现Muon在收敛速度和最终效果上都有明显的优势。详细的比较结果建议大家去看原论文,这里仅截取部分分享。
Github: https://github.com/MoonshotAI/Moonlight
首先是一个相对客观的对照表格,包括我们自己控制变量训练的Muon和Adam的对比,以及与外界(DeepSeek)用Adam训练的同样架构的模型对比(为了便于对比,Moonlight的架构跟DSV3-Small完全一致),显示出Muon的独特优势:
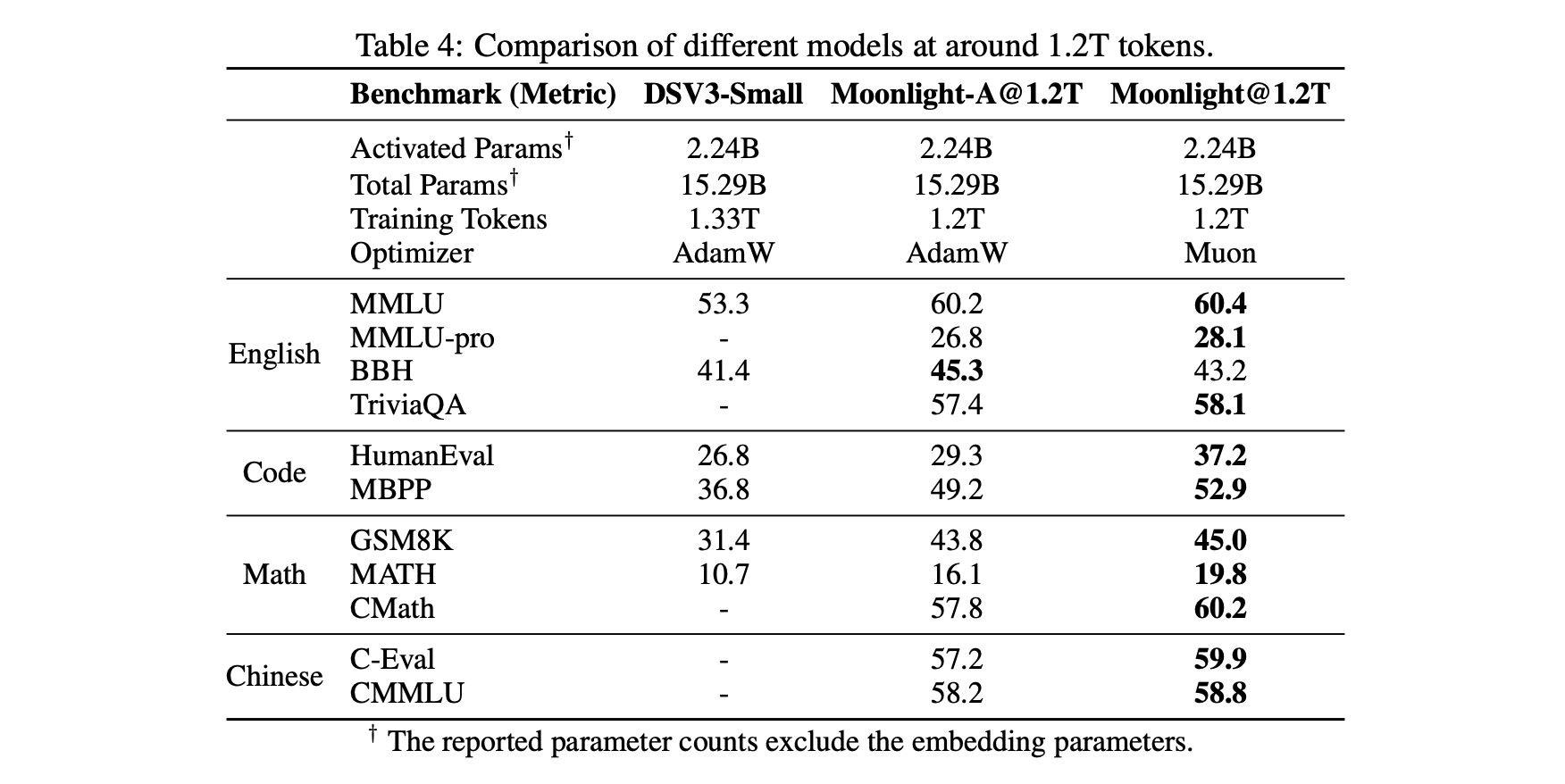
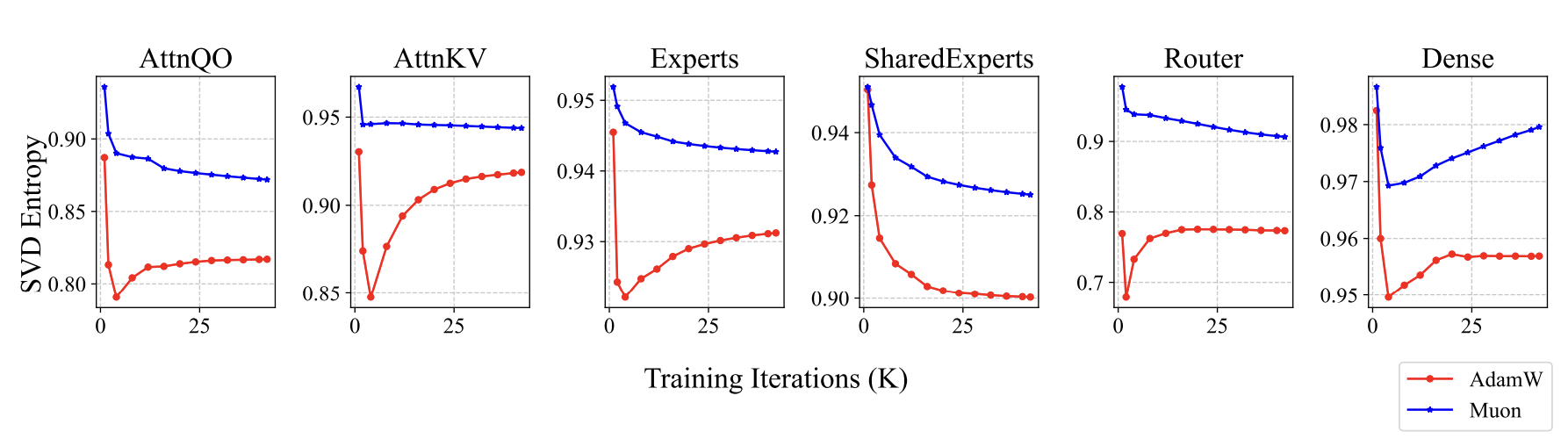
Muon训练出来的模型有什么不同呢?既然前面我们说Muon是谱范数下的最速下降,谱范数是最大的奇异值,所以我们想到了监控和分析奇异值。果然,我们发现了一些有趣的信号,Muon训出来的参数,奇异值分布相对更均匀一些,我们使用奇异值熵来定量描述这个现象:
这里\(\boldsymbol{\sigma}=(\sigma_1,\sigma_2,\cdots,\sigma_n)\)是某个参数的全体奇异值。Muon训出来的参数熵更大,即奇异值分布更均匀,意味着这个参数越不容易压缩,这说明Muon更充分发挥了参数的潜能:
还有一个有趣的发现是当我们将Muon用于微调(SFT)时,可能会因为预训练没用Muon而得到次优解。具体来说,如果预训练和微调都用Muon,那么表现是最好的,但如果是另外三种组合(Adam+Muon、Muon+Adam、Adam+Adam),其效果优劣没有呈现于明显的规律。
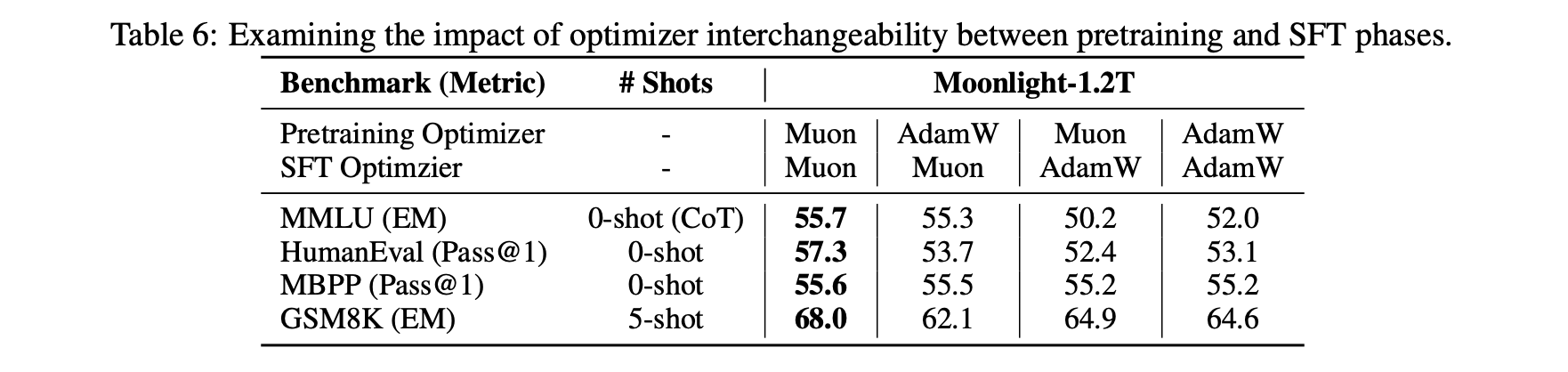
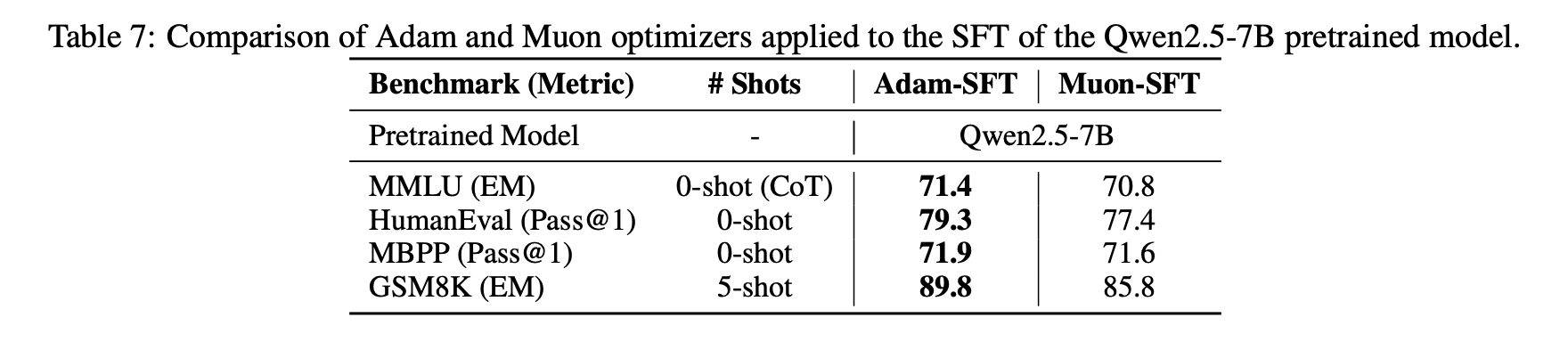
这个现象表明存在一些特殊的初始化对Muon不利,当然反过来也可能存在一些初始化对Muon更有利,更底层的原理我们还在探索中。
拓展思考
总的来说,在我们的实验里,Muon的表现跟Adam相比显得非常有竞争力。作为一个形式上跟Adam差异较大的新优化器,Muon的这个表现其实不单单是“可圈可点”了,还表明它可能捕捉到了一些本质的特性。
此前,社区流传着一个观点:Adam之所以表现好,是因为主流的模型架构改进都在“过拟合”Adam。这个观点最早应该出自《Neural Networks (Maybe) Evolved to Make Adam The Best Optimizer》,看上去有点荒谬,但实际上意蕴深长。试想一下,当我们尝试改进模型后,就会拿Adam训一遍看效果,效果好就保留,否则放弃。可这个效果好,究竟是因为它本质更佳,还是因为它更匹配Adam了呢?
这就有点耐人寻味了。当然不说全部,肯定至少有一部份工作,是因为它跟Adam更配而表现出更好的效果,所以久而久之,模型架构就会朝着一个有利于Adam的方向演进。在这个背景下,一个跟Adam显著不同的优化器还能“出圈”,就尤其值得关注和思考了。注意笔者和所在公司都不属Muon提出者,所以这番言论纯属“肺腑之言”,并不存在自卖自夸的意思。
接下来Muon还有什么工作可做呢?其实应该还有不少。比如上面提到的“Adam预训练+Muon微调”效果不佳问题,进一步分析还是有必要和有价值的,毕竟现在大家开源的模型权重基本都是Adam训的,如果Muon微调不行,必然也影响它的普及。当然了,我们还可以借着这个契机进一步深化对Muon理解(面向Bug学习)。
还有一个推广的思考,就是Muon基于谱范数,谱范数是最大奇异值,事实上基于奇异值我们还可以构造一系列范数,如Schatten范数,将它推广到这种更广义的范数然后进行调参,理论上还有机会取得更好的效果。此外,Moonlight发布后,还有一些读者问到Muon下µP(maximal update parametrization)如何设计,这也是一个亟待解决的问题。