简介
BAGEL 模型原生支持统一的多模态理解和生成,是一个 decoder-only 的模型,BAGEL 在包含文本、图像、视频和网络数据的大量多模态数据上进行了预训练,包括数万亿 tokens。尽管有一些研究尝试扩展其统一模型,但它们主要仍然依赖于标准图像生成和理解任务中的图像-文本配对数据进行训练。
然而,最近的研究发现,学术模型与 GPT-4o 和 Gemini 2.0 等专有系统在统一多模态理解和生成方面存在显著差距,而这些专有系统的底层技术并未公开。作者认为,弥合这一差距的关键在于使用精心构建的多模态交错数据进行规模化训练。这种多模态交错数据整合了文本、图像、视频和网络来源。通过使用这种多样化的多模态交错数据进行扩展时,模型展现出复杂的、新兴的多模态推理能力。这种规模化不仅增强了核心的多模态理解和生成能力,还促进了复杂的组合能力,例如自由形式的视觉操作和需要长上下文推理的多模态生成。
论文主要贡献:
- 数据策略创新,融合多源数据。包含:
- 架构设计理念,采用 Mixture-of-Transformer-Experts (MoT) 架构:选择性激活模态特定参数,不同于以往方法的bottlenect连接器设计, bagel通过共享自注意力操作实现长上下文交互
- BAGEL模型特性, Bagel模型共有7B 激活参数(总计 14B 参数),并且开源了多模态基础模型, 模型同时俱有非常有竞争力的图像理解,图像生成以及图像编辑能力
- 能力涌现模式,随着交错多模态预训练的扩展,观察到清晰的能力涌现模式:
Model
BAGEL 采用了MoT 架构,包括两个 Transformer experts,一个负责理解,一个负责多模态生成。两个 experts 通过每层共享的 self-attn 处理相同的 token序列。对于预测不同模态的 token,模型采用了不同的方法:
- 预测文本 token 时,遵循了自回归语言模型的 Next-Token-Prediction 范式。
- 预测视觉 token 时,采用了 Rectified Flow ,这也是图像生成中常用的方案。

模型设计
讨论了用于统一多模态理解和生成模型的典型架构设计选择,有几种主要的模型设计方案可供选择:
- Quantized AR :这类方法利用了文本和视觉 token 生成的 Next-Token-Prediction 范式。它的实现相对直接,可以直接利用现有的 LLM 预训练模型。然而,这种方法的视觉生成质量在实践中通常不如基于 diffusion 的模型,并且由于自回归方法的顺序性,推理延迟较高。
- External Diffuser :这种设计将预训练的 LLM 或 VLM 通过轻量级、可训练的适配器连接到 diffusion 模型。通常,LLM Backbone自回归地生成一组latent token 作为“语义条件”信号,然后由 diffusion 模块使用这些信号来生成图像。这种方法通常收敛速度快,数据消耗少,并且在既有多模态生成和理解基准测试上也能产生有竞争力的性能。但它的主要缺点是将 LLM 上下文压缩到相对少量的潜在 token 中,这在理解和生成模块之间引入了明显的瓶颈,可能导致大量信息丢失,特别是在长上下文多模态推理中。作者认为这种约束可能与大型基础模型的扩展理念相悖。
- Integrated Transformer :这种方法在单个 Transformer 中统一集成 LLM 和 diffusion 模型。它利用自回归 Transformer(强大的理解/推理能力)和 diffusion Transformer(强大的视觉生成能力)的互补优势,使用共同的模型架构实现两种范式之间的无缝切换。与 External Diffuser 方案相比,它需要显更高的训练计算量。这种架构还有一个重要的优势,即在所有 Transformer 块中保持完整的上下文,从而实现生成和理解模块之间的无损交互,并且更适合于 scaling。
在本工作中,作者认为统一模型有能力从大规模交织的多模式数据中学习更丰富的多模式功能,最终选择了Integrated Transformer,并认为它在大规模训练环境中具有更大的潜力,可以更好地充当长 context 多模态推理以及强化学习的基础模型。
模型架构
BAGEL 的Backbone 基于一个decoder-only 的 transformer 架构,并使用 Qwen2.5 LLM 作为初始化。
- Qwen2.5采用了 RMSNorm 进行归一化,SwiGLU 作为激活函数,RoPE 进行位置编码,以及 GQA 来减少 KV cache
-
模型在每个注意力块中又添加了 QK-Norm,这在图像/视频生成模型中是常见做法,有助于稳定训练过程。
视觉信息有两个不同 Encoder : -
对于视觉理解,使用一个 ViT 编码器 (SigLIP2-so400m/14) 将原始像素转换为 token。该编码器经过修改以支持最大 980x980 的输入尺寸(通过插值位置嵌入)和处理任意宽高比(集成 NaViT)。一个两层的 MLP 连接器用于匹配 ViT token 和 LLM 隐藏状态的特征维度。
- 对于图像生成,使用一个预训练的 VAE (来自 FLUX) 在像素空间和潜在间之间转换。这个 VAE 模型在训练期间是冻住的。
在将 ViT 和 VAE token 集成到 LLM Backbone 前,应用 2D 位置编码。
其他细节:
- timestep编码:模型直接将timestep embedding 添加到 VAE token 的初始hidden states。
- token 排布:在 LLM 内部,来自理解和生成任务的文本、ViT 和 VAE token 根据输入的模态结构进行交错排列。
- 因果注意力:对于同一样本内的 token,模型采用了一种广义的因果注意力机制。这些 token 首先被分割成多个连续的部分,每个部分包含来自单一模态(文本、ViT 或 VAE)的 token。
Generalized Causal Attention
在训练期间,对于包含多幅图像的交错多模态生成样本,需要为每幅图像准备三组不同的视觉 token:
- 加噪的 VAE token:这是加入了扩散噪声的 VAE 潜在表示,专门用于 Rectified-Flow 训练,计算 MSE 损失时使用这组 token。
- 干净的 VAE token:这是原始(无噪声)的 VAE 潜在表示,用于作为生成后续图像或文本 token 的条件。
-
ViT token:来自 SigLIP2 编码器,用于统一理解和生成数据的输入格式,并提升交错生成质量。
在交错图像或文本生成中: -
后续的图像或文本 token 可以关注之前图像的干净 VAE token 和 ViT token,但不能关注其加噪的 VAE token。
- 对于交错的多图像或视频片段生成,模型采用了 diffusion forcing 策略,将每一幅图像的状态建立在之前图像的加噪表示之上。为了增强生成的一致性,还会随机将连续的图像分组并在组内应用全注意力。
- 广义因果注意力机制的实现使用了 PyTorch FlexAttention
- 可以在推理过程中缓存已生成的干净 VAE token 和 ViT token 的 kv cache,从而加速多模态解码。当一幅图像完全生成后,上下文中的相应加噪 VAE token 会被其去噪(干净)块替换。
- 为了在交错推理中实现无分类器指导 (classifier-free guidance),模型会随机丢弃文本、ViT 和干净 VAE token,概率分别为 0.1、0.5 和 0.1。

Transformer Design
遵循 Integrated Transformer 解决方案的前提下,比较了几种不同的 Transformer 变体:标准 Dense Transformer、Mixture-of-Experts (MoE) transformer 和 Mixture-of-Transformers (MoT) 架构。
- MoE 变体是复制 Qwen2.5 LLM 每个块中的前馈网络(FFN)作为生成专家
-
MoT 变体是复制 Qwen2.5 LLM 所有可训练参数来创建一个完整大小的生成专家。
BAGEL 模型采用了 MoT 架构。 -
MoE 和 MoT 在模型中都使用硬路由(hard routing):新复制的生成专家专门处理 VAE token,而原始参数(理解专家)处理文本和 ViT token。这种策略遵循了 Qwen-VL 系列的做法。MoE 和 MoT 架构虽然增加了总参数数量(大约是 Dense 基线的两倍),但在训练和推理期间的 FLOPs 是相同的。
作者在一个 1.5B Qwen-2.5 LLM 上进行实验,以比较这几种架构变体。
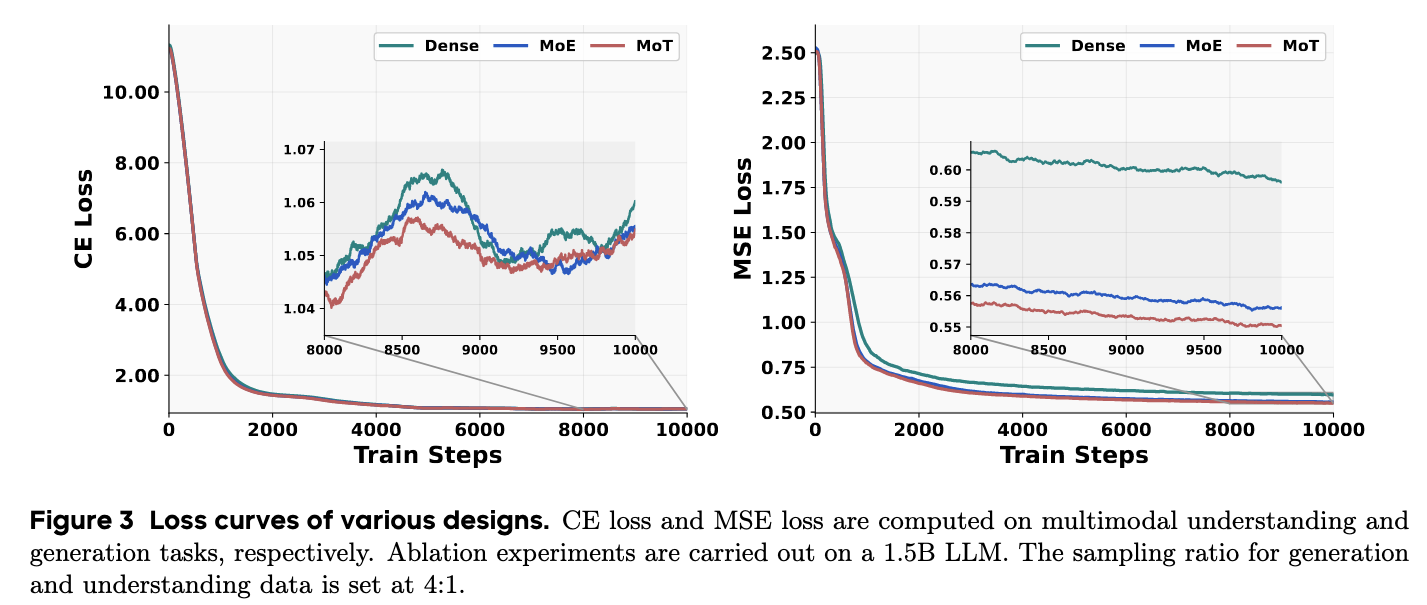
- MoT 变体始终优于 Dense 和 MoE 设计。
- 将用于生成的参数与用于理解的参数解耦具有明显的优势。这两个目标可能引导模型走向参数空间中不同的区域,分配单独的容量可以缓解由相互竞争的模态特定学习目标带来的优化挑战。
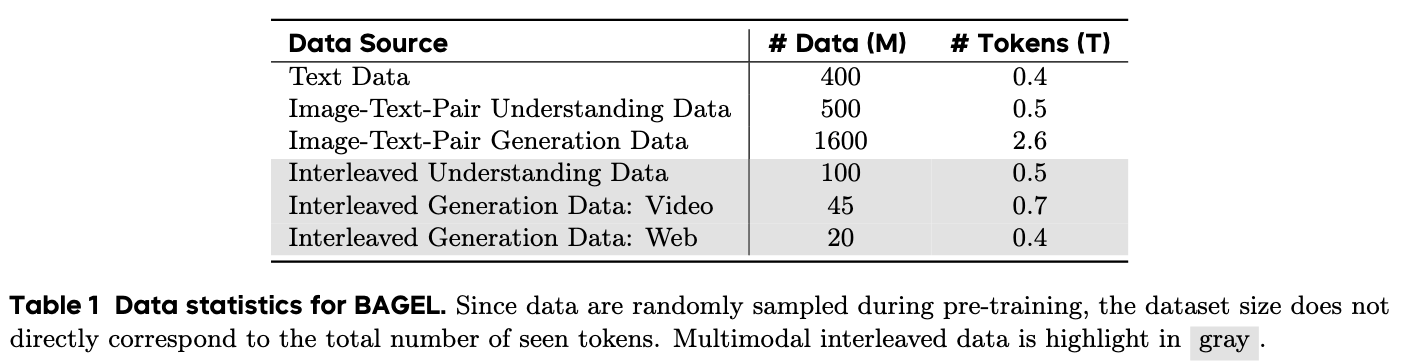
Data
除了标准视觉语言(VLM),文本对图像(T2I)和大规模语言建模(LLM)数据集外,还构建了从Web和视频源构建新的视觉文本交织的数据集,以进一步增强模型的序列多模式推理的能力
Text Only Data
为了维持底层大型语言模型 (LLM) 的语言建模能力,BAGEL 在训练语料库中加入了高质量的纯文本数据,旨在支持广泛的语言覆盖。
它们能够增强模型在通用文本任务上的推理和生成能力
Vision-Text Paired Data
文本-图像配对数据为视觉语言模型 (VLM) 和文本到图像 (T2I) 生成任务提供了大规模的视觉监督。在 BAGEL 的训练设置中,这类数据根据其下游用途被组织成两个子集:
- VLM Image-Text Pairs
- T2I Image-Text Pairs
Vision-Text Interleaved Data
虽然视觉-文本配对数据(如图像-文本对)提供了重要的视觉监督,但它不足以支持涉及多幅图像和中间文本的复杂上下文推理。仅使用配对数据训练的模型往往难以捕捉跨模态的视觉和语义关系,导致生成内容连贯性较差。为了解决这些限制,BAGEL 在训练中整合了大规模的视觉-文本交错数据。
- 交错数据的目的: 交错数据用于提高 BAGEL 的顺序多模态推理能力。它支持更丰富的多模态交互。对于多模态理解,使用 VLM 交错数据集。对于视觉生成,引入了一个统一的协议来构建视觉-文本交错数据,以支持更丰富的多模态交互。
- 数据来源: 为了覆盖多样化的真实世界场景并实现可扩展的数据供应,BAGEL 的训练语料库集成了两个主要的交错数据来源:视频数据和网页数据。
- 数据处理与构建: 对这些交错数据源进行了处理和构建:
- 推理增强数据: 材料还介绍了构建推理增强数据以促进多模态推理。这包括利用长上下文的 Chain-of-Thoughts (CoT) 数据进行多模态理解。此外,假设在图像生成之前引入基于语言的推理步骤有助于澄清视觉目标和改进规划。构建了 50 万个推理增强示例,涵盖四种结构关系:文本到图像生成、自由形式图像操纵和概念编辑。
Training
BAGEL 采用了包含多个阶段的训练方法,每个阶段都有特定的目标和配置。这些阶段分别是:
- Alignment 阶段:
- Pre-training (PT) 阶段:
- Continued Training (CT) 阶段:
- Supervised Fine-tuning (SFT) 阶段:
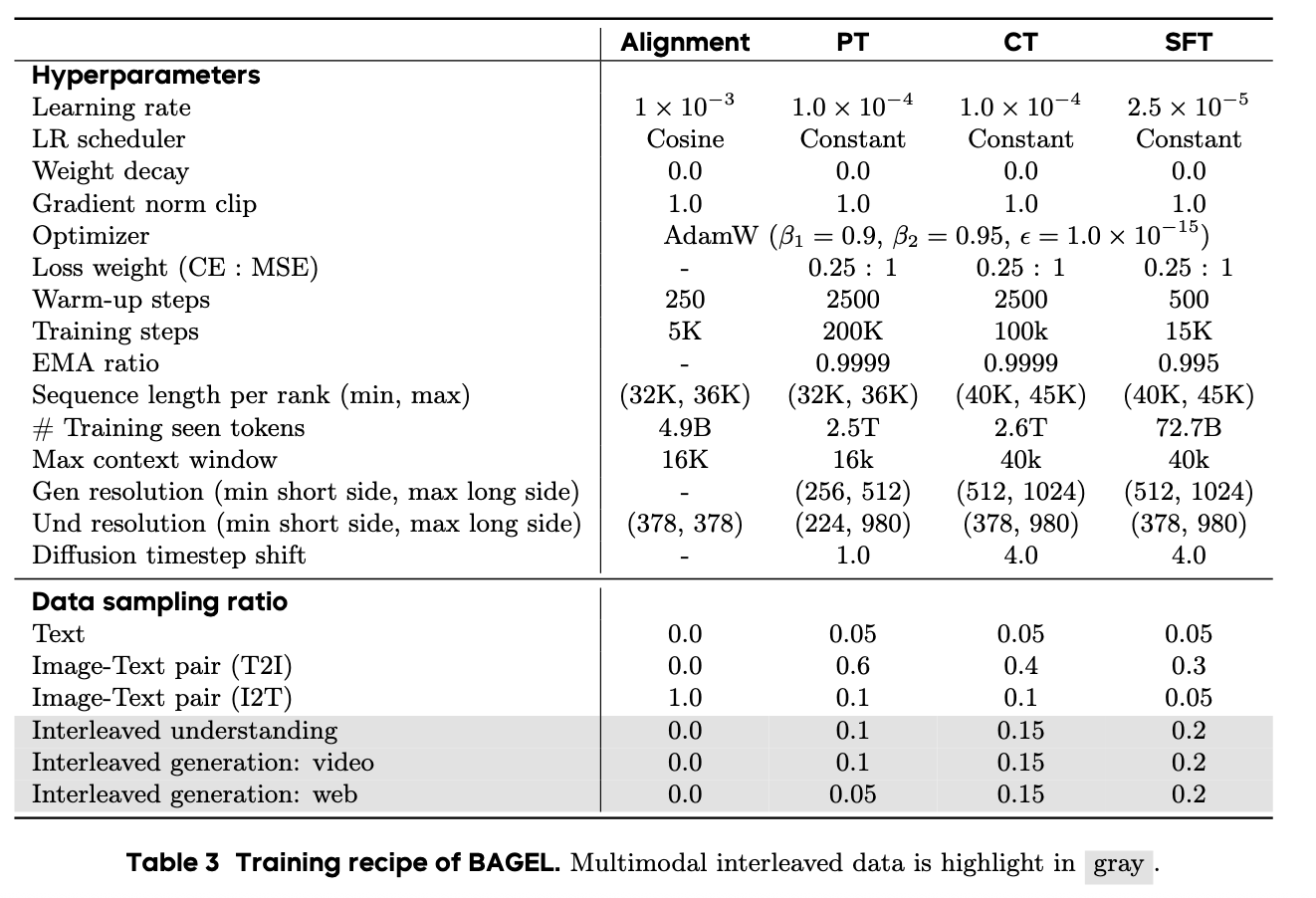
训练配置:
- 所有训练阶段均使用 AdamW 优化器。
- 设置了特定的 epsilon 值 (1.0×10−15) 以抑制损失尖峰。
- 在增加生成分辨率时,扩散 timestep 从 1.0 增加到 4.0。
- PT、CT 和 SFT 阶段使用恒定学习率。
-
通过打包序列以确保不同 rank 之间的负载均衡。
统一多模态预训练需要仔细调整数据采样比例和学习率,以平衡理解和生成任务的信号。 -
数据采样比例 (Data Sampling Ratio):
- 学习率 (Learning Rate):
Emerging Properties
涌现能力特指那些在早期训练阶段不存在,但在后期预训练阶段出现的能力。这是一种定性转变,难以通过训练损失曲线的简单外推来预测。为了研究这些涌现能力,作者通过对不同checkpoint在各种任务上的模型表现来进行考察。使用了多种基准作为代理指标,包括:
- 多模态理解的平均 VLM 基准分数。
- 文本到图像生成 (T2I) 的 GenEval 分数。
- 经典图像编辑的 GEdit 分数。
-
复杂多模态推理和任务组合所需的智能图像编辑 (Intelligent Editing) 的 IntelligentBench 分数。
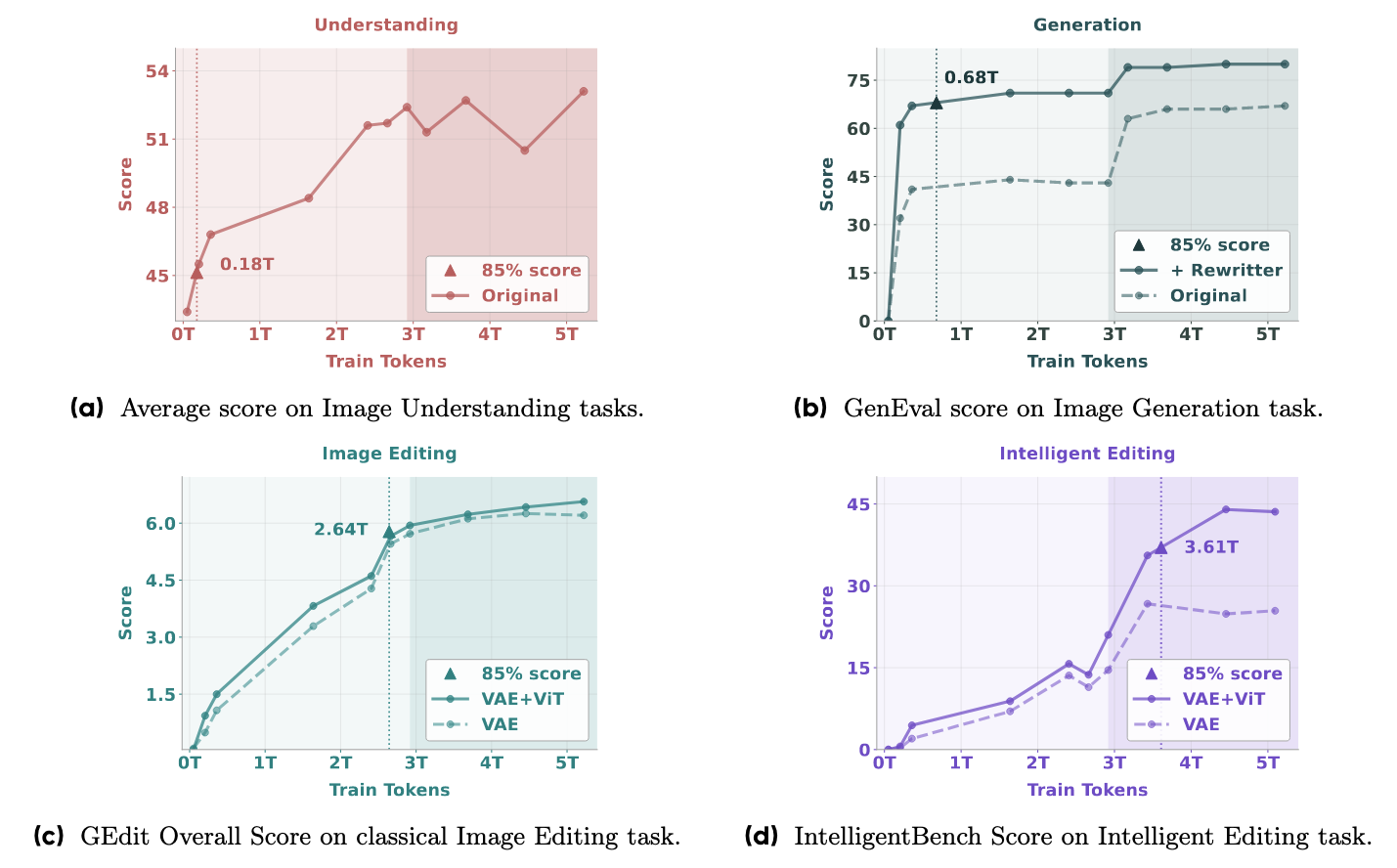
作者观察到了不同的涌现模式 : -
不同能力涌现的时间不同:理解和生成等基本多模态能力首先出现并相对较早饱和。
- 编辑能力涌现较晚:需要理解和生成能力的编辑任务收敛速度较慢,达到 85% 峰值性能所需训练 tokens 更多 (2.64T tokens)。
- 智能编辑(复杂推理)最后涌现:专门设计用于评估复杂多模态推理的 Intelligent Editing 任务需要最多的训练 tokens (3.61T) 才能达到 85% 性能,展现出类似于大型语言模型中描述的涌现行为。在后期训练阶段,智能编辑的性能显著提高。
- 理解能力,特别是视觉输入,在多模态推理中起着关键作用。移除 ViT tokens 对 GEdit-Bench 影响很小,但导致 Intelligent Editing 性能显著下降了 16%。
除了定量指标,通过检查不同训练检查点生成的图像,也观察到了与性能曲线一致的趋势。