概述
MTP(Multi-token Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。
在DeepSeek之前也有几个MTP方案,其侧重点各自不同。
- 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个token,实现成倍的加速来提升推理性能。
- 侧重训练时提高效率。比如论文“Better & Faster Large Language Models via Multi-token Prediction]”。具体而言,该方案通过一次生成多个后续token,可以一次学习多个位置的label,这样在训练时可以提供更丰富、更密集的训练信号,进而有效提升样本的利用效率,提升训练速度,同时也可以提升模型性能。Deep Seek MTP 也属于此类。
EAGLE
论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”提出了一种投机采样框架 EAGLE,该框架在特征层进行自回归,并引入了提前一个时间步的 token 序列来解决特征预测的不确定性。EAGLE的核心创新点在于它为了提高小模型能力,把大模型的最后一个hidden state(或者说feature)也添加到了小模型里面。具体来说,就是小模型在训练时,需要把大模型t-1位置输出的 [feature, token] 都送进去,预测的时候也要求小模型和大模型 [feature, token]进行对齐。
研究背景
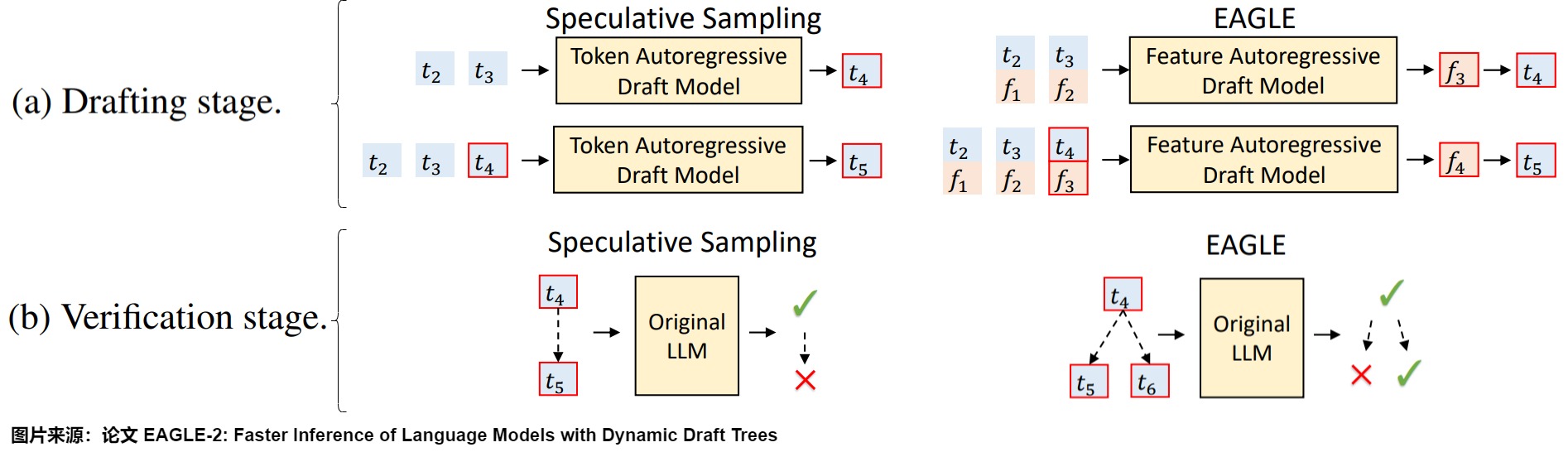
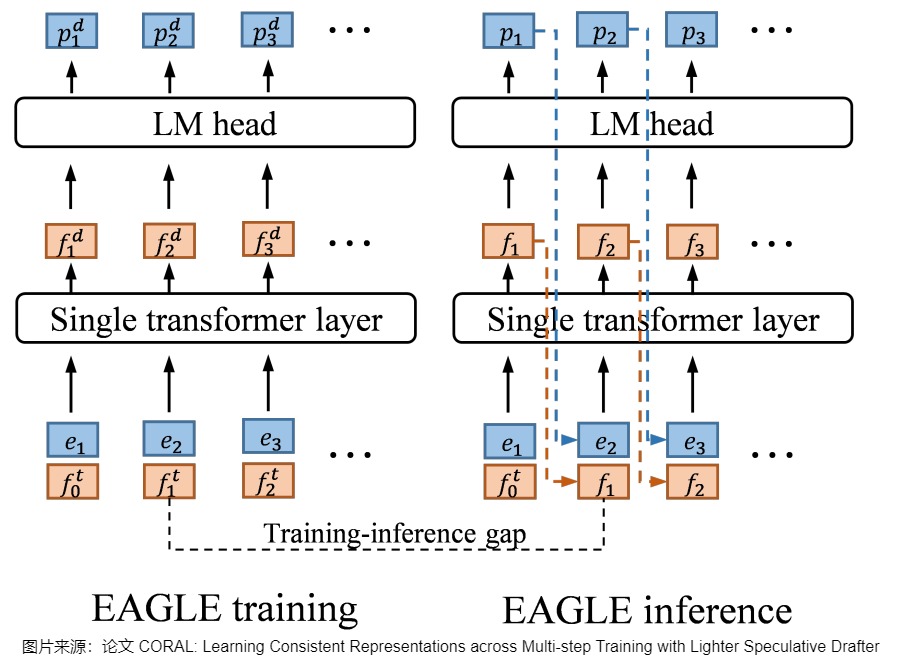
LLM 是逐个 token 生成文本的,即生成下一个 token 需要依赖前面已经生成的 token。这种串行的模式导致自回归编码过程计算量大、耗时,是LLM应用的主要瓶颈,因此有众多方案对其进行改进。EAGLE 论文中用下图把 EAGLE 和其它一些投机方案做了对比,\(t_i\) 表示第 \(𝑖\) 次输入的 token, \(f_i\) 表示 \(t_i\) 经过 LLM 后在倒数第二层的输出(即 LM Head 之前的输出)。我们就由此入手,看看其研究背景。

- 投机采样(Speculative Sampling)使用一个较小的草稿模型快速生成多个 token,然后使用原始的目标 LLM 并行验证这些 token。其缺点是需要合适的草稿模型,并且草稿模型的质量直接影响加速效果。
- Lookahead使用 n-gram 和 Jacobi 迭代来预测 token。其缺点是草稿质量较低,加速效果有限,并且只适用于贪婪解码。
- Medusa使用多个 MLP 基于目标 LLM 的倒数第二层特征 (second-to-top-layer feature) 来预测 token,图上就是使用f2来预测t4和t5。缺点是草稿质量仍然不高,加速效果有限,并且在非贪婪解码 (non-greedy decoding) 下不能保证输出分布与目标LLM一致。
- EAGLE 作者认为通过目标模型本身的特征向量预测下一个 token 更准确,所以草稿模型使用与目标模型基本相同的结构,利用了目标模型输出的特征向量作为草稿模型输入。即,EAGLE 创新性地选择对 \(𝑓\) 做 Autoregressive Decoding,将 Speculative Decoding 前移至了特征层(即倒数第二层)。对应图上就是使用\((f_1,f_2)\)来预测 \(f_3\),同时把token序列 \((t_2,t_3)\) 再前进一步,利用\(p_4=\text{LM Head}(f_3)\) 得到 \(t_4\)。
EAGLE 作者提出了两个核心观点:
- 在特征层(feature level)进行自回归预测,然后通过 LM Head 得到 token,比直接预测 token 更简单,效果更好。特征指的是 LLM 倒数第二层的输出的embedding,也就是在进入 LM Head 之前的隐状态。隐状态相较于 token 层更有规律性,而且会拥有比最终结果更多的隐知识(dark knowledge)。只采样 token 的方法显然就直接忽略了这些知识。
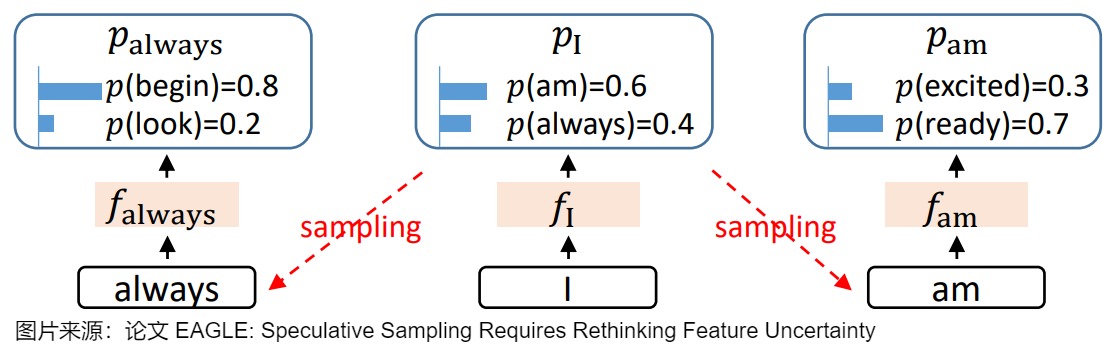
- 采样过程中的不确定性限制了特征预测的性能。因为 LLM 会对 token 的概率分布进行采样,所以LLM 的输出是带有随机性的。这种随机性会导致特征序列的预测变得不确定。例如,给定相同的输入「I」,接下来可能按概率采样输出「always」或者「am」,在这一步不同的选择会造就两个完全不同的意思、两个完全不同的逻辑,这就导致了特征预测的不确定性。
因此,EAGLE 的核心思想如下:
- 在特征层进行自回归。使用一个轻量级的自回归模型来预测目标 LLM 的特征序列,而不是直接预测 token。
- 保留特征层可以更好的克服采样过程中的不确定性。通过引入前一个时间步的 token 序列来解决特征预测中的不确定性,这使得模型能够以最小的额外计算成本精确预测倒数第二层的特征。即,在预测当前特征时,不仅考虑之前的特征序列,还考虑之前已经采样的 token 序列。如上图,在输出 I 之后,会按概率采样输出 am 或是 always。在进一步寻找 always 的后续输出时,如果能保留 I 的特征层输出,就能保留住采样过程中丢掉的关于 am 的信息。
架构
Eagle 需要训练一个小的 draft 模型,这是自己设计的模型,主要包括嵌入层(Embedding layer)、语言模型头(LM Head)和由全连接层和 Decoder 层组成的自回归头(Autoregression Head)。论文作者将 embedding 和 特征 𝑓 拼接在一起作为 Draft Model 的输入。全连接层将拼接后的向量降维至特征维度,Decoder 层负责预测下一个特征。这样可以保留最终输出 token 中遗失的其它信息。为了一次验证多个 sequence,论文采用了 Tree Attention 来生成树状结构的草稿,这样可以在一个前向传播过程中生成多个 token。草稿模型中需要训练的部分是自回归头,嵌入层和语言模型头使用目标 LLM 的参数,不需要额外的训练。
技术细节大致如下图所示。EAGLE使用一层transformer layer+冻结的LM head(大模型的输出头)。绿色块表示token embedding,橙色块表示特征,红色框表示草稿模型的预测,带有雪花状图标的蓝色模块表示使用目标LLM参数,这些参数不受训练。下图三次前向传播使用的是同一个模型,可以共享一份KV Cache。
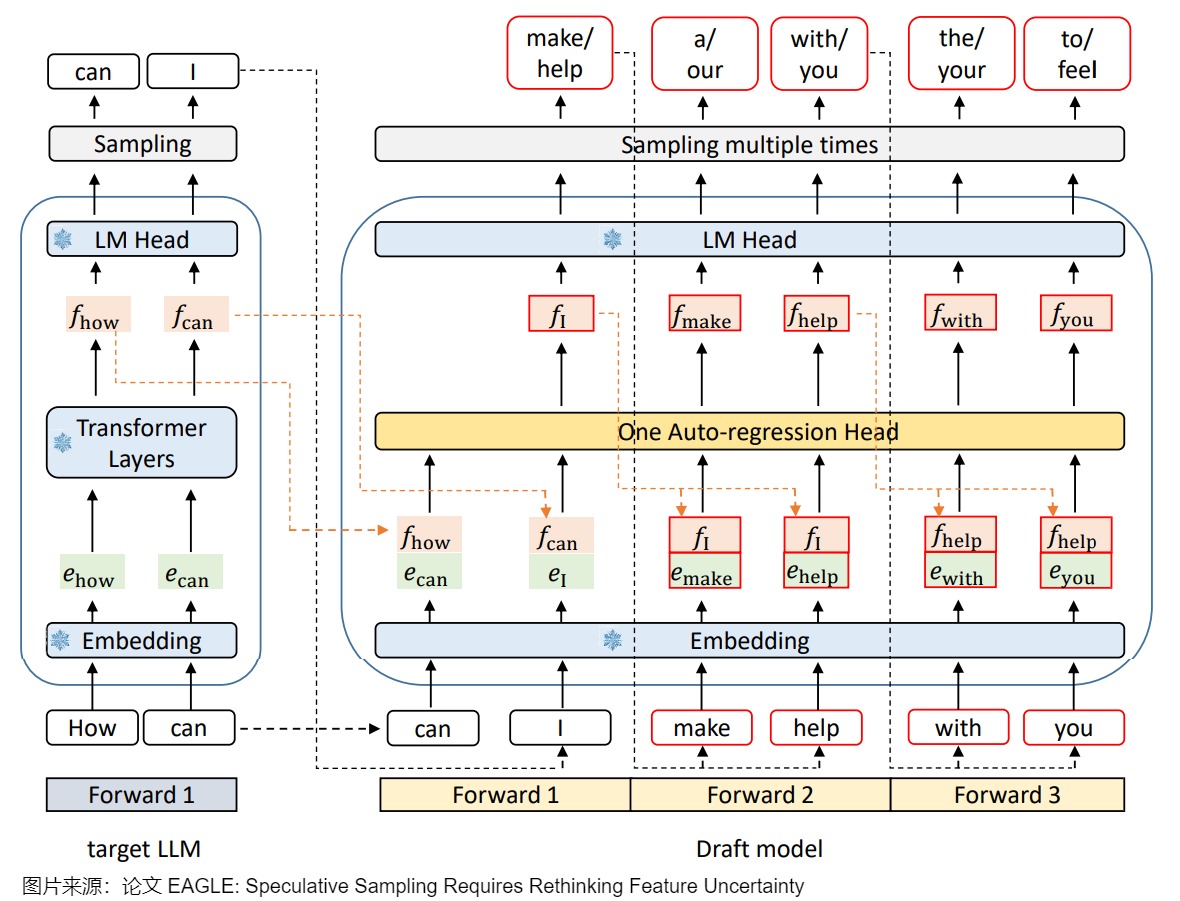
因为第一次前向传播无法加速,所以需要通过一次前向传播才能得到后续 EAGLE 所需要的特征。这里也就能看出上面对比图中,EAGLE 为何要从 \(t_2\) 画起。
下图给出了每一步的预测结果。
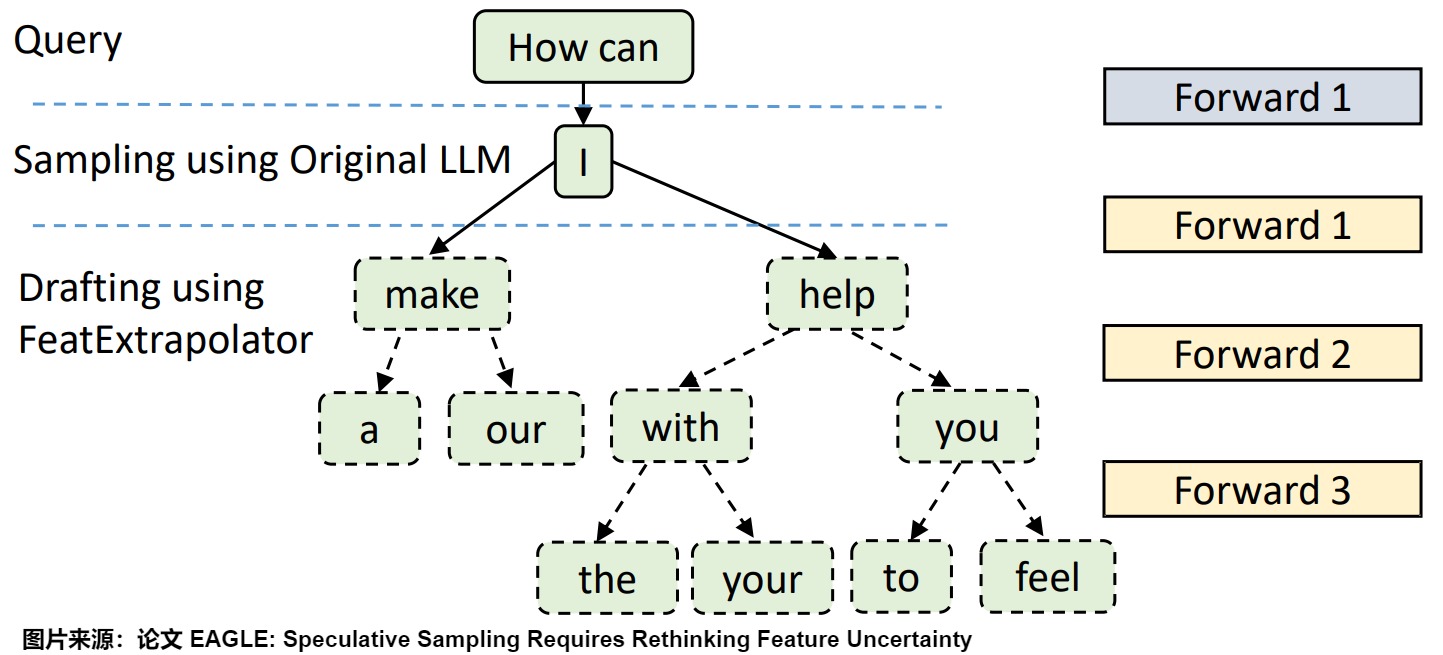
整体流程如下:
EAGLE也是draft-and-verify 的基本范式,其基本流程如下。
草稿阶段(Drafting Phase)的输入是之前的特征序列和提前一个时间步的 token 序列,输出是一个由多个 token 组成的草稿树 (draft tree)。该阶段的处理过程如下:
- 将 token 序列转换为 embedding 序列。
- 将 embedding 序列和特征序列拼接在一起。
- 使用一个自回归头 (Autoregression Head) 来预测下一个特征。
- 使用 LM Head 将预测的特征转换为 token 的概率分布,并从中采样得到下一个 token。
- 将预测的特征和采样的 token 添加到输入序列中,继续进行自回归预测。
验证阶段(Verification Phase)的输入是草稿树,输出被接受的 token 序列。EAGLE在验证阶段采用了与投机采样相同的策略。在草稿阶段生成的词元需要通过目标LLM的验证,只有在接受概率下才被采纳,否则会被拒绝并重新采样。这种机制保证了最终生成的词元分布与目标LLM一致。该阶段的处理过程如下:
- 前向传播:使用目标 LLM 对草稿树进行一次前向传播,得到每个 token 的概率分布。
- 验证:从根节点开始,逐层递归地对草稿树中的 token 进行验证。对于每个 token 计算其接受概率,接受概率取决于草稿模型对该词元的概率预测和目标 LLM 对该词元的概率预测。接受概率通常是
min(1, p_target(t) / p_draft(t))。 这个公式的含义是,当目标模型的预测概率大于草稿模型时,该词元被接受;当目标模型的预测概率小于草稿模型时,该词元以一定概率被接受,接受概率等于两个概率之比。 - 接受:如果一个词元以其接受概率被接受,那么这个词元会被添加到最终的输出序列中。
- 拒绝/重采样:如果一个词元被拒绝,那么这个词元会被丢弃,并且会基于目标 LLM 的概率分布
p_target(t)重新采样一个新的词元。 - 合并:最终,被接受的 token 会被合并成一个序列,作为最终的输出。
具体也可以参考下图的对比。
因为小模型除了transformer层数和大模型不同,其他完全一致,包括自回归生成的流程也完全一致。所以EAGLE最大的优势就是对部署极度友好。
模型训练
训练中,用了两个 loss。
- Classification Loss(分类损失)使用交叉熵损失 (Cross Entropy Loss) 来衡量预测 token 分布(自回归头输出的特征)和真实 token 分布(原模型特征在经过 LM Head 之后的分类)之间的差异。这是要求两个模型的概率分布对齐。
- Regression Loss(回归损失)使用 Smooth L1 Loss 来衡量预测特征和真实特征之间的差异。这是要求两个模型的feature对齐。由于小模型在推理阶段是自回归的,约束feature能够让小模型的输入更加稳定,从而在一定程度上避免测试时出现OOD(out of distribution)的情况,这样小模型在长距离自回归生成中会拥有更高的准确率。
如果只约束输出token一致而不约束feature,在训练时只使用大模型的feature,但是推理时,小模型用的是自己上一个时间步的feature,该feature和大模型feature是有偏差的,在测试时很可能出现“虽然token预测对了,但是feature和大模型不一样”的情况,从而导致长距离的推理精度受到影响。具体可以参见下图:
EAGLE使用目标模型的特征进行训练,而在推理中,草稿模型使用自己的特征。图上的 \(f\) 表示特征,\(e\) 表示嵌入。上标表示变量的来源,\(t\) 和 \(d\) 表示目标模型和草稿模型。下标用来索引特征或嵌入的位置。例如,\(f^t_2\) 表示位置 2 中来自目标模型的特征。 因此,后续其它研究人员都对此做出了改进,比如HASS和CORAL。HASS使用了Multi-step training让模型见过推理阶段的数据分布+增大数据量。
另外,EAGLE作者在论文中也提到,MoE 模型和 Speculative Decoding 配合不好。因为在 Vanilla Inference 阶段,每个 token 只会需要两个 experts 的权重。但 Speculative Decoding 的 verification 阶段需要同时验证多个 token,可能导致激活更多的专家模型,读取更多专家的权重,这就会削弱 MoE 的优势,从而导致加速比的下降。而且,MoE 模型的专家选择过程会引入额外的依赖关系,也可能使得并行计算变得更加困难。
EAGLE-2
作者还对EAGLE进行升级,得到了EAGLE-2。论文是“EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees”。EAGLE-2提出了动态草稿树投机采样:依据草稿模型的置信度动态调整草稿树的结构,最高可以将大语言模型的推理速度提高5倍,同时不改变大语言模型的输出分布,确保无损。
思路
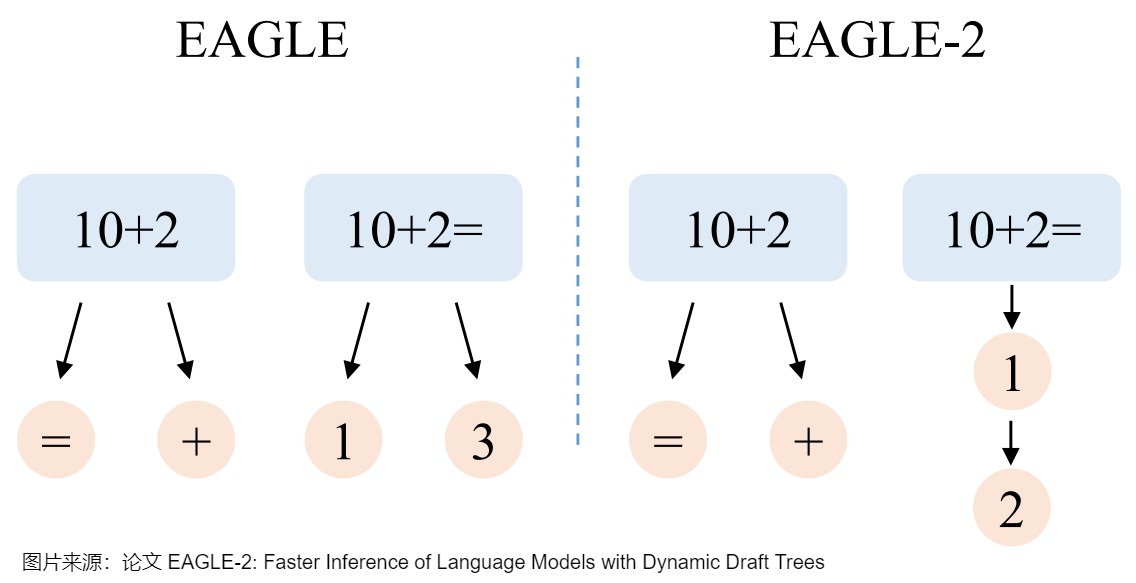
EAGLE和Medusa等方法使用静态的草稿树,隐式地假设草稿token的接受率和上下文无关。
- 当上文是“10+2”时,下一个token难以预测。于是,EAGLE在这个位置添加两个候选token以增加草稿命中率,“10+2=”和“10+2+”有一个正确即可。
- 当上文是“10+2=”时,下一个token明显是“1”,但是EAGLE使用静态的草稿结构,仍然添加两个候选“1”和“3”,“10+2=3”不可能通过大语言模型的检查,存在浪费。EAGLE-2旨在解决这一问题,如下图右侧所示,当上文是“10+2=”时,EAGLE-2只增加一个候选token“1”,将节约出的token用于让草稿树更深,这样“10+2=12”可以通过大语言模型的检查,进而可以一次生成更多的token。
改进方案
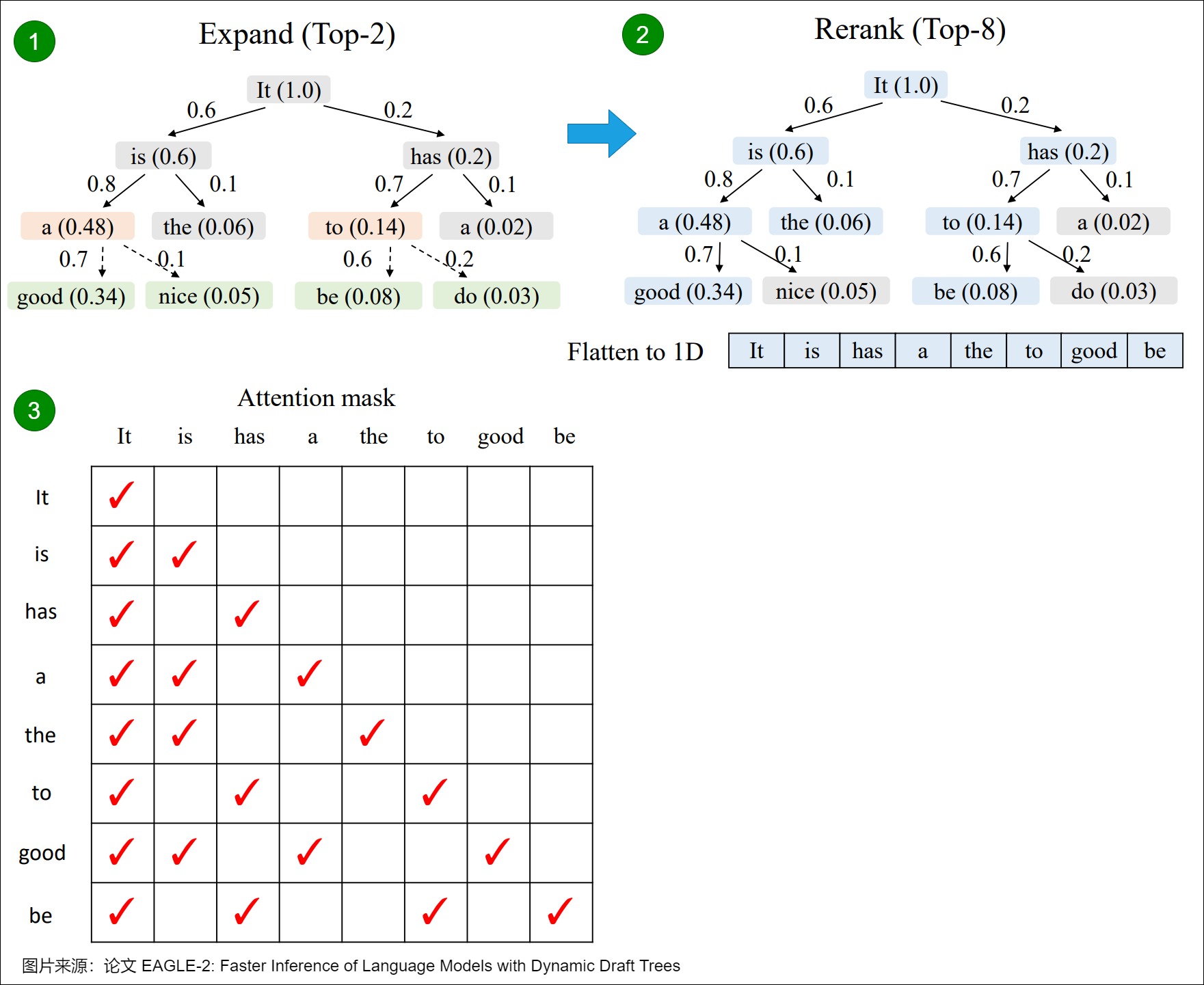
为了保证无损,一个草稿token被接受的前提是它的祖先节点都被接受,所以EAGLE-2将一个节点的价值定义为它和它祖先的接受率的乘积,用置信度的乘积来近似。EAGLE-2包括两个阶段,扩展和重排:
- 扩展阶段加深加大草稿树。在扩展阶段,EAGLE-2选择草稿树最后一层价值最高的m个节点(token)进行扩展。这些token被送入草稿模型,然后将草稿模型的输出作为子节点连接到输入节点,加深加大草稿树。
- 重排阶段修剪草稿树,丢弃部分节点(token)。在重排阶段,EAGLE-2按照价值对整棵草稿树进行重排序,保留前n个节点(token)。草稿token的置信度在0-1之间,两个节点价值相同时,优先保留浅层节点,因此重排后保留的草稿树一定是连通的,这保证了语义上的连贯性。而且,重排后草稿树变小,也降低了原始大语言模型验证的计算量。
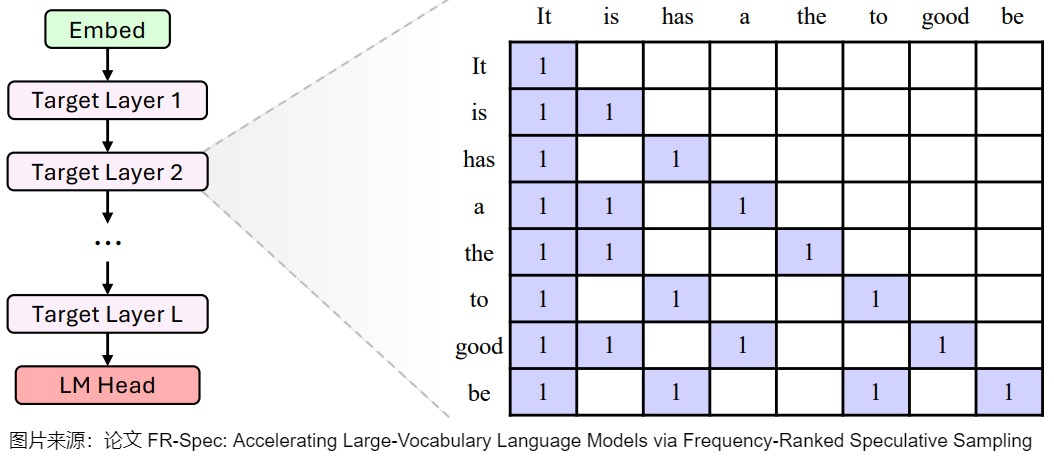
下面是一个简单的例子。图中,扩展(Expand)阶段的黄色框表示被选中进行扩展的节点,绿色框为以这些节点为输入时草稿模型的预测。重排(Rerank)阶段的蓝色框表示被保留的节点,之后它们被展平成一维作为原始大语言模型的输入。为了保证计算结果的正确性,EAGLE-2 也会根据树的结构调整attention mask,确保每一个token只能看到它的祖先节点,不受其他分支的影响。比如,”a”只能看到它的祖先“It”和“is”,看不到另一个分支的“has”。EAGLE-2也同时调整位置编码,确保和标准自回归解码的一致性。
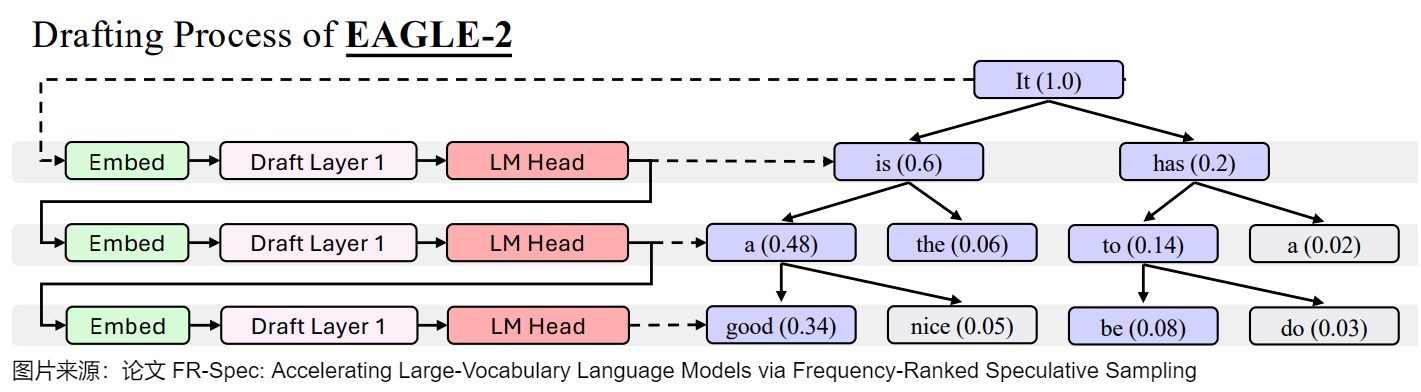
下图是草稿流程。当prompt P=“It”时,波束宽度=2,搜索深度=3。EAGLE-2挑选出顶部K=8个概率标记(紫色)作为草稿树。
下图是验证流程。
EAGLE-3
EAGLE的作者后来又对方案做了进一步升级,得到了EAGLE-3。EAGLE、Medusa 等投机采样方法都重用目标模型的最后一层特征作为草稿模型的提示,但 EAGLE-3 的作者们发现这存在缺陷。大语言模型的最后一层特征经过线性变换可以得到下一个 token 的分布。最后一层特征只有下一个 token 的信息,失去了目标模型的全局性质。因此,EAGLE-3 不再使用目标模型的最后一层特征作为辅助信息,而是混合目标模型的低层、中层、高层信息来作为草稿模型的输入。