引言
Structured Generation with LLM,是指让LLM按照预先定义的schema,输出符合schema的结构化结果。
常见的应用场景有:
- 数据处理。主要功能为a -> b,即从源文本中抽取/生成符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等;
- Agent。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。
将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。
Kor
Kor,一个基于prompt的技术方案;Kor比较适合数据处理场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。


使用Kor进行structured generation的流程如下:
- 定义schema,包括结构、注释还有例子;
- Kor用特定的prompt template,将用户提供的schema和待处理的raw text,组装成prompt;
- 将prompt发送给LLM,借助其通用的In Context Learning能力,尽量生成符合schema的内容;
- Kor对LLM的输出进行parse,返回符合schema的结构化结果,但也有概率没有返回(当LLM的输出不符合schema时)。
Kor的工作是其中的第2步、第4步。由此可见,Kor是对LLM的一层包装。
Kor的优点是:使用方便。Kor无需介入decode过程,只要有一个text to text的LLM API即可使用,既可以用闭源模型,也可以用开源模型。
但Kor的缺点也很明显:无法保证抽取结果一定满足schema,这是因为:
- 本质上Kor只是帮你“组装”了一下prompt而已,输出是否符合schema还取决于模型自身的instruction-following能力。
Example
介绍了Kor的原理之后,可以通过两个实例来查看Kor的具体过程
Example 1
- 中文翻译器效果:输入任意文本,返回{"translate_result": {"chinese": 翻译结果}}
- 在结构化输出中,一般只需两步即可:
Kor支持两种设置schema的模式,Kor schema和Pydantic Model,在这个例子中,我们使用Kor schema。
# kor schema,我们想要的输出格式
schema = Object(
id="translate_result",
description=(
"任意文本的翻译结果。"
),
attributes=[
Text(
id="chinese",
description="中文翻译结果",
examples=[], # Kor支持few-shot examples,但本例子比较简单,故不需要
many=False,
),
],
many=False,
)
*# 运行结果*chain = create_extraction_chain(llm, schema, encoder_or_encoder_class='json')
text="We've trained a model, based on GPT-4, called CriticGPT to catch errors in ChatGPT's code output. We found that when people get help from CriticGPT to review ChatGPT code they outperform those without help 60% of the time. We are beginning the work to integrate CriticGPT-like models into our RLHF labeling pipeline, providing our trainers with explicit AI assistance. This is a step towards being able to evaluate outputs from advanced AI systems that can be difficult for people to rate without better tools."
print(chain.run(text)['data'])
{'translate_result': {'chinese': '我们训练了一个基于GPT-4的模型,称为CriticGPT,用于捕捉ChatGPT代码输出的错误。我们发现,当人们从CriticGPT那里获得帮助来审查ChatGPT代码时,他们比没有帮助的人高出60%的效率。我们正在开始将类似CriticGPT的模型集成到我们的RLHF标记流程中,为我们的训练师提供明确的AI辅助。这是朝着能够评估来自高级AI系统的输出迈出的一步,这些输出在没有更好的工具的情况下很难被人类评估。'}}
示例1成功运行:
我们打印kor的prompt来看看。
print(chain.prompt.format_prompt(text="[user input]").to_string())
Your goal is to extract structured information from the user's input that matches the form described below. When extracting information please make sure it matches the type information exactly. Do not add any attributes that do not appear in the schema shown below.
```TypeScript
translate_result: { // 任意文本的翻译结果。
chinese: string // 中文翻译结果
}
Please output the extracted information in JSON format. Do not output anything except for the extracted information. Do not add any clarifying information. Do not add any fields that are not in the schema. If the text contains attributes that do not appear in the schema, please ignore them. All output must be in JSON format and follow the schema specified above. Wrap the JSON in
Input: [user input]
Output:
### Example2
- 评价解析预期效果:输入一段用户评价,得到评价属性(口味、价格等)、评价极性(正向、负向、中立)、评价词(好吃、贵等)、参考片段。
- 结构化输出,第一步是定义schema,我们可以设置成这样的schema
- 在这个例子中,我们使用Pydantic Model来定义schema,Pydantic Model也能够支持few-shot examples,其额外好处是可以Validate
```python
# 评价解析的pydantic model
class Sentiment(enum.Enum):
positive = "positive"
negative = "negative"
neural = "neural"
class Dianpin(BaseModel):
aspect: str = Field(
description="评价属性"
)
sentiment_word: str = Field(
description='对评价属性的评价词,从原文中抽取',
)
sentiment: Optional[Sentiment] = Field(
description='对评价属性的情感,positive\negative\neural中的一个',
)
reference: str = Field(
description='评价的原文'
)
# 运行kor
schema, validator = from_pydantic(
Dianpin,
description='对评价的解析结果',
examples=[],
many=True #支持list of aspect
)
chain = create_extraction_chain(
llm, schema, encoder_or_encoder_class="json", validator=validator
)
pprint(chain.run("整体来说,环境可以,味道的话也还不错,但价格有一点小贵。"))
{'data': {},
'errors': [ParseError('The LLM has returned structured data which does not match the expected schema. Providing additional examples may help improve the parse.')],
'raw': '\n'
'<json>\n'
'[\n'
' {\n'
' "aspect": "环境",\n'
' "sentiment_word": "可以",\n'
' "sentiment": "positive"\n'
' },\n'
' {\n'
' "aspect": "味道",\n'
' "sentiment_word": "还不错",\n'
' "sentiment": "positive"\n'
' },\n'
' {\n'
' "aspect": "价格",\n'
' "sentiment_word": "小贵",\n'
' "sentiment": "negative"\n'
' }\n'
']\n'
'</json>',
'validated_data': {}}
注意,此时data字段数据为空,因为LLM的返回不符合预期的schema,kor建议加入examples
于是我们加入一个简单的example
# 运行kor
schema, validator = from_pydantic(
Dianpin,
description='对评价的解析结果',
examples=[
('味道真不错,下次还来!', [{"aspect":"味道", "sentiment_word": "真不错", "sentiment": "positive", "reference": "味道真不错"}])
],
many=True #支持list of aspect
)
chain = create_extraction_chain(
llm, schema, encoder_or_encoder_class="json", validator=validator
)
pprint(chain.run("整体来说,环境可以,味道的话也还不错,但价格有一点小贵。"))
{'data': {'dianpin': [{'aspect': '环境',
'reference': '整体来说,环境可以',
'sentiment': 'positive',
'sentiment_word': '可以'},
{'aspect': '味道',
'reference': '味道的话也还不错',
'sentiment': 'positive',
'sentiment_word': '还不错'},
{'aspect': '价格',
'reference': '但价格有一点小贵',
'sentiment': 'negative',
'sentiment_word': '小贵'}]},
'errors': [],
'raw': '\n'
'<json>\n'
'{\n'
' "dianpin": [\n'
' {\n'
' "aspect": "环境",\n'
' "sentiment_word": "可以",\n'
' "sentiment": "positive",\n'
' "reference": "整体来说,环境可以"\n'
' },\n'
' {\n'
' "aspect": "味道",\n'
' "sentiment_word": "还不错",\n'
' "sentiment": "positive",\n'
' "reference": "味道的话也还不错"\n'
' },\n'
' {\n'
' "aspect": "价格",\n'
' "sentiment_word": "小贵",\n'
' "sentiment": "negative",\n'
' "reference": "但价格有一点小贵"\n'
' }\n'
' ]\n'
'}\n'
'</json>',
'validated_data': [Dianpin(aspect='环境', sentiment_word='可以', sentiment=<Sentiment.positive: 'positive'>, reference='整体来说,环境可以'),
Dianpin(aspect='味道', sentiment_word='还不错', sentiment=<Sentiment.positive: 'positive'>, reference='味道的话也还不错'),
Dianpin(aspect='价格', sentiment_word='小贵', sentiment=<Sentiment.negative: 'negative'>, reference='但价格有一点小贵')]}
加入example之后,示例2成功运行。
我们也打印kor的prompt,看看长什么样,以及few-shot examples是如何使用的。
print(chain.prompt.format_prompt(text="[user input]").to_string())
Your goal is to extract structured information from the user's input that matches the form described below. When extracting information please make sure it matches the type information exactly. Do not add any attributes that do not appear in the schema shown below.
```TypeScript
dianpin: Array<{ // 对评价的解析结果
aspect: string // 评价属性
sentiment_word: string // 对评价属性的评价词,从原文中抽取
sentiment: "positive" | "negative" | "neural" // 对评价属性的情感,positive
egative
eural中的一个
reference: string // 评价的原文
}>
Please output the extracted information in JSON format. Do not output anything except for the extracted information. Do not add any clarifying information. Do not add any fields that are not in the schema. If the text contains attributes that do not appear in the schema, please ignore them. All output must be in JSON format and follow the schema specified above. Wrap the JSON in
Input: 味道真不错,下次还来!
Output:
Input: [user input]
Output:
## **小结**
Kor主要基于prompt,是对LLM的一层封装;Kor的设计理念使其便于进行数据处理(raw data -> schema),但Kor的最大限制是,**并不能保证所抽取内容的结构稳定性**,而这点将会被guided decoding类技术解决。
# Function Calling
这里以mistral发布的12B模型 -- **Mistral-Nemo-Instruct-2407**为例,初步研究其实现方式。
从一个简单的FC例子入手:
- tool是经典的`get_current_weather`,schema如下
```python
Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location."},
},
"required": ["location", "format"],
})
- 用户query:What's the weather like today in Paris and Beijing? I prefer Celsius format.
打印出来prompt如下:

在input侧,mistral-nemo的做法是直接将用户提供的tool schema转为string,并包裹在特殊的tag(AVAILABLE_TOOLS)之中,然后插入到user query之前。
既然都是组装Prompt,我们拿它和Kor的Prompt做个对比:

可以发现,mistral-nemo的prompt更精简(不包含Your goal is .... 、All output must be in JSON format.... 等内容)。
这就是微调模型与通用模型的用法差异:
- mistral-nemo在fine-tuning时,按照这样的格式进行训练,FC的“要求”已经被encode到模型的参数中去了;
- Kor是第三方实现,无从得知模型的训练细节,只能依靠模型的通用In Context Learning能力,因此需要把“要求”写清楚,于是prompt细节较多。
接着,我们来看output侧。
mistral-nemo的输出结果如下:

看起来,这是一个普通的text generation过程,通过特殊标记(TOOL_CALLS)来表明,这是一个tool_call message,而非常见的text message;同时nemo支持同时call多个tools,每个call为一个字典,其中包含function name和arguments参数(json格式)。
小结
总结一下,mistral-nemo这样实现FC:
- 将tools按照特定的template,组装到prompt中去;
- LLM输出时,也遵循特定的template,call tool时加入特殊标记(TOOL_CALLS),并返回name和arguments。
需要提到的是,FC虽然经过了fine-tuning,输出结构的稳定性有一定保证,但若未使用constrain decoding技术,那么仍然不是100%鲁棒的
Constrained Decoding
Structured generation 使得输出结构的稳定性,尤其便于应用复杂的prompt技巧和搭建workflow。在扣子中,大模型的默认输出格式便是json;openai也开始支持structured output。
之前介绍的Kor,其本质仍是基于Prompt,依赖模型的通用instruction following能力,而使用LLM厂商提供的function calling,用一种“曲线救国”的方式,间接实现structured generation。但这两种方法本质上都不是100%鲁棒的,模型仍有一定概率失败(即输出不符合schema的内容;结构越复杂则失败概率越大)。
可以预想,各大厂会快速跟进openai的更新,加入structured output能力;而实际上,早有许多开源项目(例如outlines, guidance, sglang, llama.cpp, LMQL, jsonformer),能基于本地模型实现类似效果,其背后的核心技术是constrained decoding。
constrained decoding的基本思想

如何实现constrained decoding?这里有两个基本的思想:
- 一个直觉是:定义好schema之后,我们就知道了各个字段的输出范围。
-
schema中有些部分不需模型生成,因为已经提前定义好了。
从这2个基本思想,可以得到constrained decoding的基本特性: -
对于新的schema,有初始的时间和空间花销。因为需提前把各步的输出token范围计算出来、存储下来,所以有一定的时间花销和空间花销;但对于同一个schema,理论上只需计算一次即可,以后再生成的话,速度几乎没有影响;
- 可能比unconstrained decoding更快。因为可以跳过一些固定内容的生成;
- 模型效果可能有提升。模型只需关注每个字段内容的生成,而不用管结构的事,因为生成难度降低了,所以效果可能有提升,例如outlines团队的这篇博客
- 更好的微调模型仍然是必要的。structured generation只管结构的事,生成效果的好坏,还得看模型能否理解各种类型、各种难度的schema,因此仍需要针对性的微调模型(例如有Function/Tool Calling能力的模型)。
下面介绍一些常见的实现思路
outlines:基于FSM的方法
🔖 http://github.com/dottxt-ai/outlines
基本使用
假设我们希望语言模型生成一个代表故事中角色的 JSON 对象。我们的角色需要有一个名字和一个年龄,分别包含在 JSON 的“name”和“age”字段中。为了简化本文中的问题,我们将限制可能的名字和年龄的数量。以下是使用 Pydantic 定义此角色的方法:
from enum import Enum
from pydantic import BaseModel
class Name(str, Enum):
john = "John"
paul = "Paul"
class Age(int, Enum):
twenty = 20
thirty = 30
class Character(BaseModel):
name: Name
age: Age
可以使用 Outlines 来使用任何开源语言模型生成故事角色,这里是一个使用 Mistral-7B-v0.1 的示例:
from outlines import models, generate
model = models.transformers("mistralai/Mistral-7B-v0.1")
generator = generate.json(model, Character)
char = generator("Generate a young character named Paul.")
print(char)
# Character(name:"Paul", age:20)
使用 generate.json 与让模型和自由生成文本一样快,只是输出结构得到了保证。为了理解其如何使这种生成显著更快,我们需要深入了解 Outlines 的内部机制。
具体原理
对于一个json schema,outlines首先将其转为正则表达式,然后再转为token-level的Finite State Machine(FSM)。
随后,模型的生成过程就变成在state之间的跳转:首先从初始state出发,随后在有限的输出路径中选一条,到达下一个state,直到到达最后一个state,完成生成。
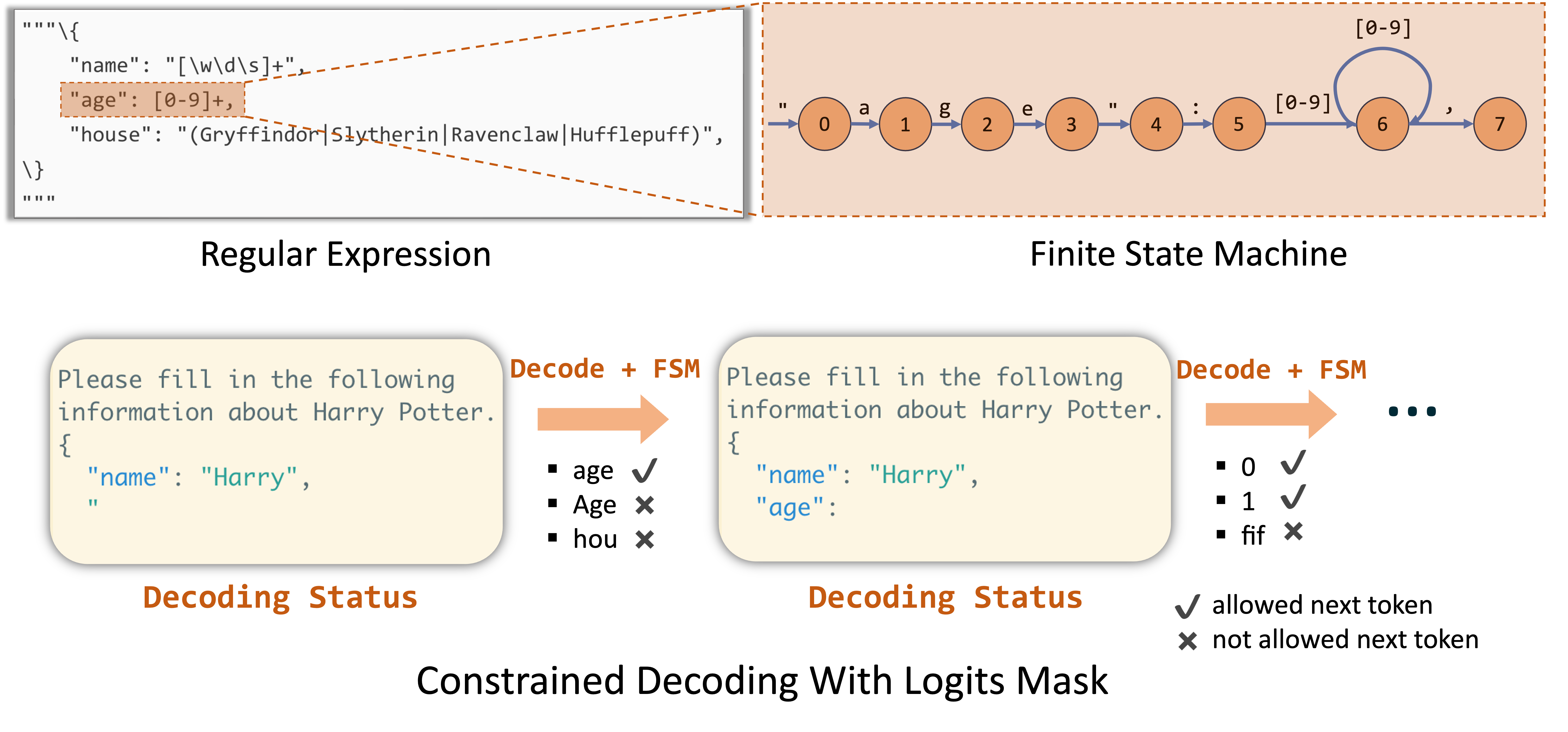
将 JSON 转换为正则表达式
Outlines的第一步是将我们的 JSON 模式转换为正则表达式。正如稍后将看到的,正则表达式是使结构化生成快速的关键部分。当你将一个 Pydantic 对象传递给 Outlines 时,它首先将其转换为 JSON 模式规范: