项目:https://llava-vl.github.io/
github: https://github.com/haotian-liu/LLaVA
一句话优点:
- 极大简化了VLM的训练方式:Pre-training + Instruction Tuning
- 训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练
LLaVA
LLaVA是2023的连续工作,包含了LLaVA 1.0, 1.5, 1.6几个版本(后续会有更多),也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。
LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。
非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。
简介
LLaVA通过使用机器生成的指令遵循数据对大型语言模型(LLMs)进行指令调优,已经在新任务上提高了零样本能力,但在多模态领域,这一想法还没有被充分探讨。在本文中,首次尝试使用GPT-4生成多模态语言-图像指令遵循数据。通过对这些生成数据进行指令调优,作者引入了LLaVA:一个大型语言和视觉助手。LLavA是一个端到端训练的大型多模态模型,将视觉Encoder和LLM连接起来,用于通用视觉和语言理解。实验表明,LLaVA展示了很强的多模型聊天能力,有时会展示出在未见过的图像/指令上的类似于GPT-4v的表现,并在一个合成的多模态指令遵循数据集上获得了与相比于GPT-4 85.1%的相对分数。在Science QA上进行微调时,LLaVA和GPT-4的协同作用实现了新的SOTA准确率92.53%。
LLaVA的贡献包括以下几个方面:
- 多模态指令跟随数据。由于缺乏视觉-语言指令跟随数据,作者利用ChatGPT/GPT-4提出了一种将图像文本对转换成适当的指令跟随格式的数据重新构造方法。
- 大型多模态模型。作者开发了一个大型多模态模型(LMM),通过将CLIP的开放集视觉编码器与语言解码器Vicuna相连接,并在我们生成的指令视觉语言数据上进行端到端微调。证明了使用生成数据进行LMM指令调优的有效性,并为构建通用的指令跟随视觉代理提供了实用建议。当与GPT-4集成时,我们的方法在Science QA多模态推理数据集上实现了最佳性能。
- 多模态指令跟随基准测试。作者提出了LLaVA-Bench,包括两个具有挑战性的基准测试,其中包含多样化的配对图像、指令和详细注释。
- 开源。包括生成的多模态指令数据、代码库、模型文件等。
数据
GPT-assisted Visual Instruction Data Generation
作者利用gpt4,给定图像的caption,或者boundingbox坐标信息 生成三种形式(conversation, detailed description, complex reasoning)的response作为最终的visual instruction

下面是作者使用的生成response的prompts

网络架构
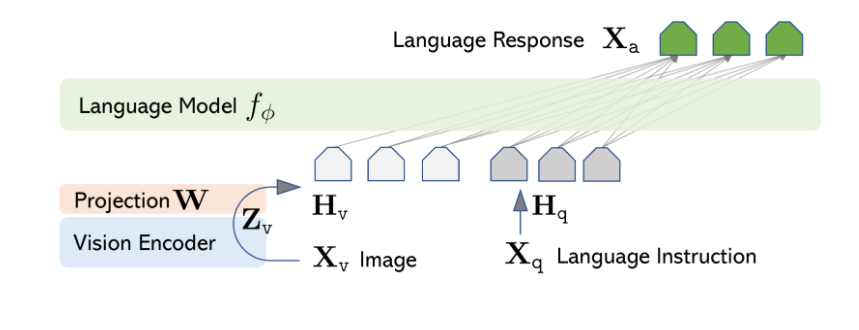
ViT:CLIP ViT-L/14224px(LLaVA 1.5用的是CLIP ViT-L/14-336px)Text:Vicuna 13B(推理)- Projection:
MLP * 2(Linear → GELU → Linear) 类似翻译官(编译器)的角色
架构设计时,主要考虑要复用已有的LLM和Visual预训练模型。Projection scheme选择非常轻量的MLP是为了能够快速的实验迭代。
训练方法
- 冻结视觉编码器和LLM,只训练Projection层。
- 从CC3M中过滤了595K的图文对。这些图文对被改造为指令跟随数据(instruction-following data)
- 每个样本是一个单轮对话。
- 预测结果是图像的原始描述文本。
- 通过这一步,视觉编码器输出的图像特征可以和预训练的LLM的词向量对齐。这个阶段可以理解为为冻结的LLM训练一个兼容的visual tokenizer。
- 在CC-595K过滤后的子数据集上训练,epoch数量为1,学习率2e-3,batch_size为128。
- 阶段二:端到端微调(Fine-tuning End-to-End)。
- 冻结视觉编码器,训练Projection层和LLM。
- 两个实验设置
- 多模态对话机器人:利用158K语言-图像指令跟随数据对Chatbot进行了微调开发。在这三种类型的回答中,对话型是多轮交互式的,而其他两种则是单轮交互式。在训练过程中,这些样本被均匀地采样使用。
- ScienceQA数据集:ScienceQA 包含了21,000个多模态多项选择题,这些问题涵盖了广泛的领域多样性,涉及3个学科、26个主题、127个类别和379项技能。这个基准数据集被划分为训练、验证和测试三个部分,分别包含12,726个、4,241个和4,241个样本。
- 在提出的LLaVA-Instruct-158K数据集上训练,epoch数量为3,学习率2e-5,batch_size为32。
文章同时做了一些ablation study,一些值得关注的结论:
1、视觉特征提取:使用ViT倒数第二层的Features更有利
2、思维链CoT:发现“先生成reason再生成answer” 相比“先生成answer再生成reason” 仅对模型快速收敛有帮助,对最终的性能 上限的提升没帮助。
3、Pre-train:证明了pre-train的有效性,pre-train+scienceQA finetune 相对比 直接在ScienceQA train from scratch 会提升5.11%。
4、模型大小:7B比13B的低1.08%,印证了越大的LLM对整体的性能越有利。
5、涌现能力:LLaVA 的一个有趣的涌现行为是它能够理解训练中未涵盖的视觉内容。此外LLaVA 还展示了令人印象深刻的 OCR能力。
LLaVA 1.5
作者在LLaVA 1.0发布后半年左右,推出了LLaVA 1.5。
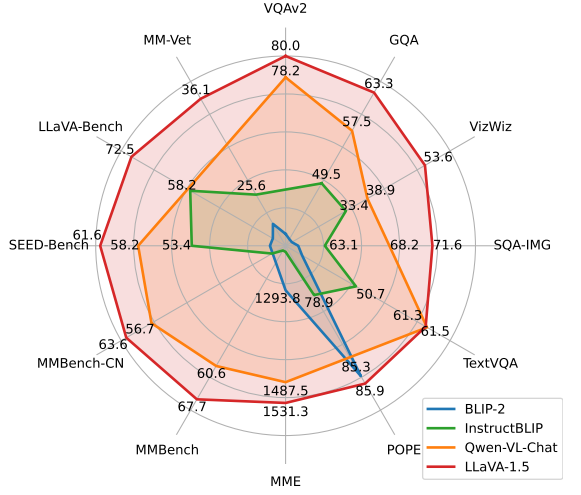
LLaVA-1.5在11个基准测试中达到了SoTA水平,仅通过对原始LLaVA进行简单修改,利用约一百万量级的数据,超越了使用十亿规模数据的方法。
搬上超强直观的雷达图,各项指标超越BLIP-2、InstructBLILP、Qwen-VL-Chat。
基于LLaVA的改动点
- 明确指定输出格式的提示:为了解决短文本 VQA 和长文本 VQA 之间的兼容问题,在短文本回答中明确指定了输出格式的提示。例如,通过在问题文本的末尾添加特定的短语,如想要短回答时加上“Answer the question using a single word or phrase”,模型能够基于用户的指示适当地调整输出格式。
- 使用 MLP 作为视觉-语言连接器:使用了两层 MLP 作为视觉-语言连接器,以增强连接器的表达能力。相比LLaVA的单个线性投影层,显著提升了多模态能力。
- 添加特定任务的数据集:为了强化模型在不同能力上的表现,研究者不仅添加了 VQA 数据集,还专注于 OCR 和区域级别识别的四个数据集。这些数据集包括需要广泛知识的 VQA(如 OKVQA 和 A-OKVQA)、需要 OCR 的 VQA(如 OCRVQA 和 TextCaps)等。
- 规模扩大。
- 图片分辨率提升到336。
- 新增GQA数据集作为额外的图片知识。
- 加入ShareGPT数据。
- LLM增大到13B。MM-Vet上的结果显示,当LLM模型扩展至130亿参数规模时,改进最为显著,这表明基础LLM的能力对于视觉对话至关重要。
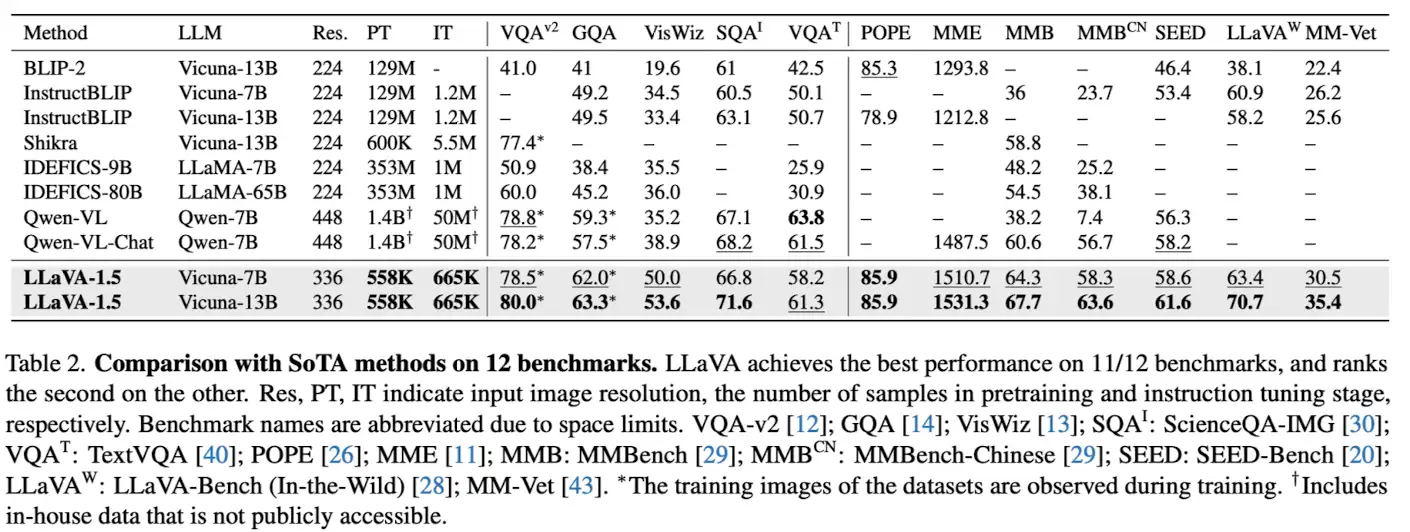
和其他模型的对比结果
- 12个任务中有11个都是第一,另一个是第二。
- 该方法在单一8块A100节点上大约1天内完成训练,并超越了那些使用十亿级别数据的方法(指的Qwen-VL)。
计算成本
对于LLaVA-1.5,我们使用与LCS-558K1相同的预训练数据集,并在进行指令微调时保持与LLaVA [28]大致相同的训练迭代次数和批次大小。由于将图像输入分辨率提高到了336像素,因此LLaVA-1.5的训练时间约为LLaVA的两倍:预训练阶段大约需要6小时,视觉指令微调阶段大约需要20小时,使用的是8块A100显卡。
几点不足
- 首先,LLaVA利用完整的图像patch,可能会延长每个训练迭代。而视觉重采样器减少了LLM中的视觉patch数量,但目前它们不能像LLaVA那样有相当数量的训练数据时有效收敛,可能是因为重采样器中的更多可训练参数。开发一个样本效率高的视觉重采样器可以为未来扩展指令遵循多模态模型铺平道路。
- 其次,由于缺乏这样的指令遵循数据和上下文长度的限制,LLaVA-1.5还无法处理多个图像。
- 第三,尽管LLaVA-1.5展示了遵循复杂指令的熟练程度,但其问题解决能力在某些领域仍可能受到限制,这可以通过更强大的语言模型和高质量的针对性视觉指令调谐数据来改进。
- 最后,尽管其幻觉的倾向显著减少,但LLaVA不免偶尔产生幻觉和传播错误信息,在关键应用中(例如医疗)仍应谨慎使用。
LLaVA 1.6(LLaVA-NEXT-240130)
https://llava-vl.github.io/blog/2024-01-30-llava-next/
概述
LLaVA-NeXT,它在推理、OCR和世界知识方面实现了显著提升,甚至在多个基准测试上超过了Gemini Pro的表现。
相较于LLaVA-1.5,LLaVA-NeXT有如下改进:
- 将输入图像分辨率提高了4倍,使得它可以捕捉到更多视觉细节。它支持三种不同的宽高比,最高可达672x672、336x1344、1344x336的分辨率。
- 通过改进视觉指令微调数据混合,提升了视觉推理和OCR能力。
- 对更多场景下的视觉对话功能进行了优化,覆盖了不同应用领域,并增强了世界知识和逻辑推理能力。
- 采用SGLang实现高效的部署和推理。
伴随着性能的提升,LLaVA-NeXT继续保持了LLaVA-1.5的极简主义设计和数据效率。它重用了LLaVA-1.5预先训练的连接器,并且仍然使用少于100万的视觉指令微调样本。最大的340亿参数版本在配备32块A100显卡的情况下,约1天即可完成训练。代码、数据和模型将会公开提供。
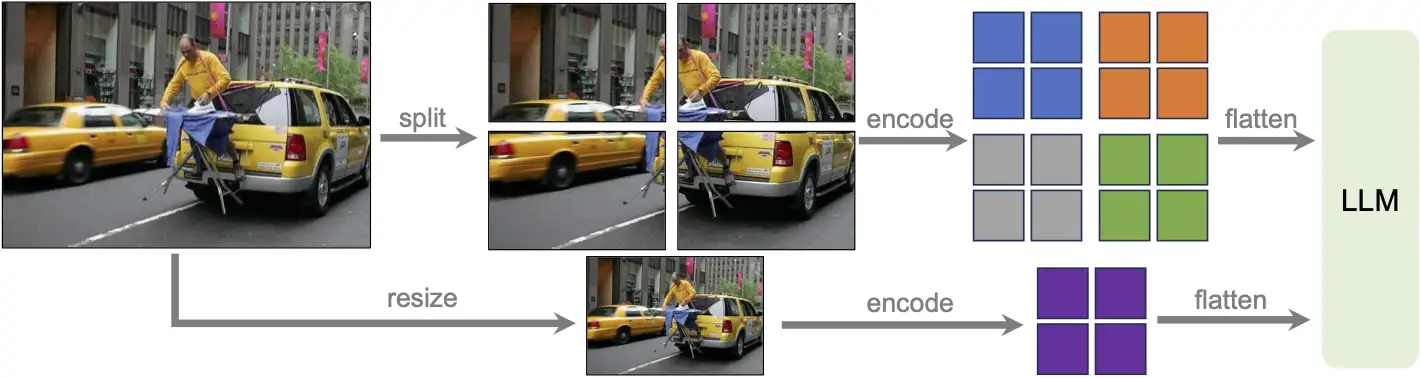
动态高分辨率
在高分辨率下设计模型,旨在保持其数据效率。当提供高分辨率图像和保留这些细节的表示时,模型感知图像中复杂细节的能力得到显著提高。它减少了模型在面对低分辨率图像时产生的视觉内容幻觉。作者提出的“AnyRes”技术旨在适应各种高分辨率图像。作者采用 {2×2,1×{2,3,4},{2,3,4}×1}{2×2,1×{2,3,4},{2,3,4}×1} 的网格配置,平衡性能效率与运行成本。
亮点:
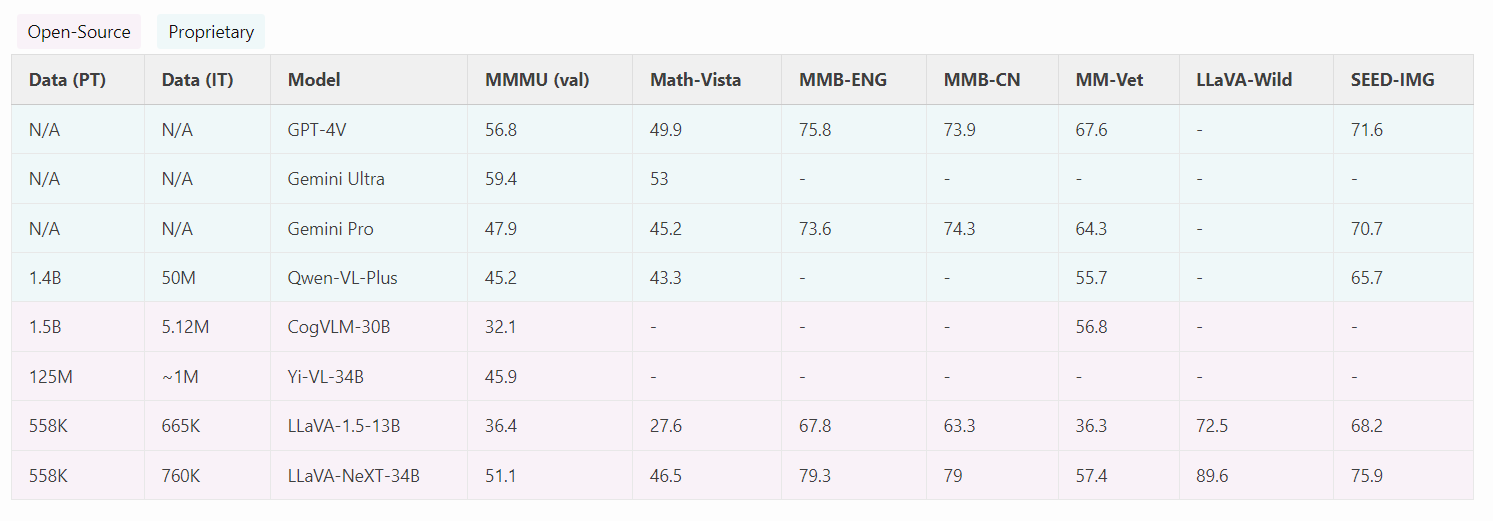
- 表现卓越!LLaVA-NeXT相比开源的大型多模态模型(如CogVLM或Yi-VL)取得了最佳性能表现。相较于商业模型,它在部分基准测试中已达到与Gemini Pro相当的水平,并超越了Qwen-VL-Plus。
- 零样本中文能力。LLaVA-NeXT具备新兴的零样本中文能力(即仅考虑英文多模态数据训练)。其在中文多模态场景中的表现令人惊讶,例如在MMBench-CN上取得最优结果。
- 训练成本低。LLaVA-NeXT使用32块GPU进行约1天的训练,总共使用了130万个数据样本。其计算量和训练数据成本仅为其他模型的1/100至1/1000,展现出极低的训练成本优势。
评估
下面是和其他多模态大模型的对比结果。
Llava-onevision
论文地址:https://arxiv.org/pdf/2408.03326
公开时间:2024年9月14日
项目地址:https://llava-vl.github.io/blog/llava-onevision
论文的核心是分享了一个OneVision的架构设计,以统一对单图、多图及视频任务的训练框架(token编码规则),将单图训练的能力迁移到多图与视频中。同时分享了一种动态分辨率设计规则,以提供更好的视觉表示(兼容图像视频);最后介绍了训练数据的收集步骤与训练步骤,其中重点表明高质量知识是lmm中最为重要的环境。
模型
该模型架构继承了LLaVA系列的极简主义设计,其主要目标是
- 有效地利用LLM和视觉模型的预训练能力
- 在数据和模型方面促进了强大的缩放行为。
网络的原始结构如图所示:
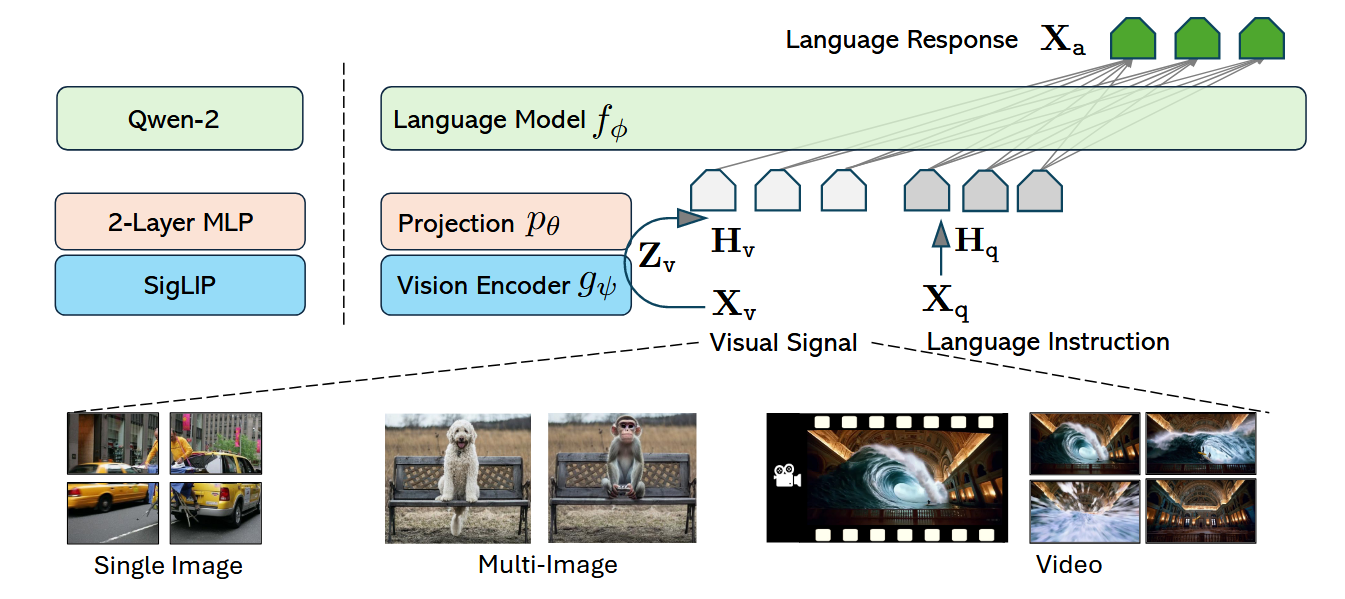
- LLM(大语言模型):选择Qwen-2 ,记作 \(f_\phi(\cdot)\) ,其中 \(\phi\) 是 LLM 参数。
- Vision Encoder(视觉编码器):选择SigLIP,记作\(g_\psi(\cdot)\) 输入图像 \(\mathbf{X}_v\),输出视觉特征: \(\mathbf{Z}v = g\psi(\mathbf{X}_v)\)
- Projector(投影器):结构为 2-layer MLP, 记作 \(p_\theta(\cdot)\) 将视觉特征 \(\mathbf{Z}_v\) 映射到“词向量/嵌入空间”,得到视觉 token 序列 \(\mathbf{H}v = p\theta(\mathbf{Z}_v)\)
- 作用:解决“视觉特征维度/分布”与“LLM 词嵌入空间”不匹配的问题。
他们对答案序列进行自回归建模。设答案 token 序列长度为 \(L\),则:
视觉输入 \(\mathbf{X}_v\)是一个泛化概念(适配多场景)
- 单图序列(single-image sequence):输入可能是 单张图的 crop(某种裁剪后的局部)。
- 多图序列(multi-image sequence):输入是 序列中的单张图(逐张编码)。
- 视频序列(video sequence):输入是 序列中的单帧(逐帧编码)。
这为后续统一建模“图像/多图/视频”提供接口:都当成某种 \(\mathbf{X}_v\) 流喂给视觉编码器即可。
视觉表征
视觉信号表征的成败,关键取决于两件事:
- 原始像素空间的分辨率(resolution)
- 特征空间中的 token 数量()
因此,视觉输入配置可以抽象成二元组:(resolution, )
经验观察:提升分辨率与提升 token 数 都会提升效果,尤其对需要视觉细节的任务。但在性能/成本权衡下,他们观察到:提升分辨率(resolution scaling)通常比提升 token 数更有效。
直觉:更多像素让小目标/文字/细纹理可见;而 token 数增加若来自更密的 patch 切分或更长序列,会显著增加计算与 KV cache/attention 成本。
AnyRes + pooling
为了在性能与成本之间平衡,Llava1.5 使用的是AnyRes strategy with pooling
可理解为:
- AnyRes:允许输入图像是“任意/多尺度分辨率”(不是固定单一分辨率)。
- pooling:对视觉特征做池化(或某种下采样/聚合),把 token 数控制住,避免序列过长带来计算爆炸
下图(b)展示了anyres策略的具体做法,先把图像 resize(通常到某个较小/统一尺度),再切成 crops。
Original AnyRes 主要靠“像素空间 resize”来控制 token(以及可能配合 pooling),因此 token 控制更“硬”、更离散;并且因为先 resize,再 split,细节在进入 encoder 之前就可能丢失。
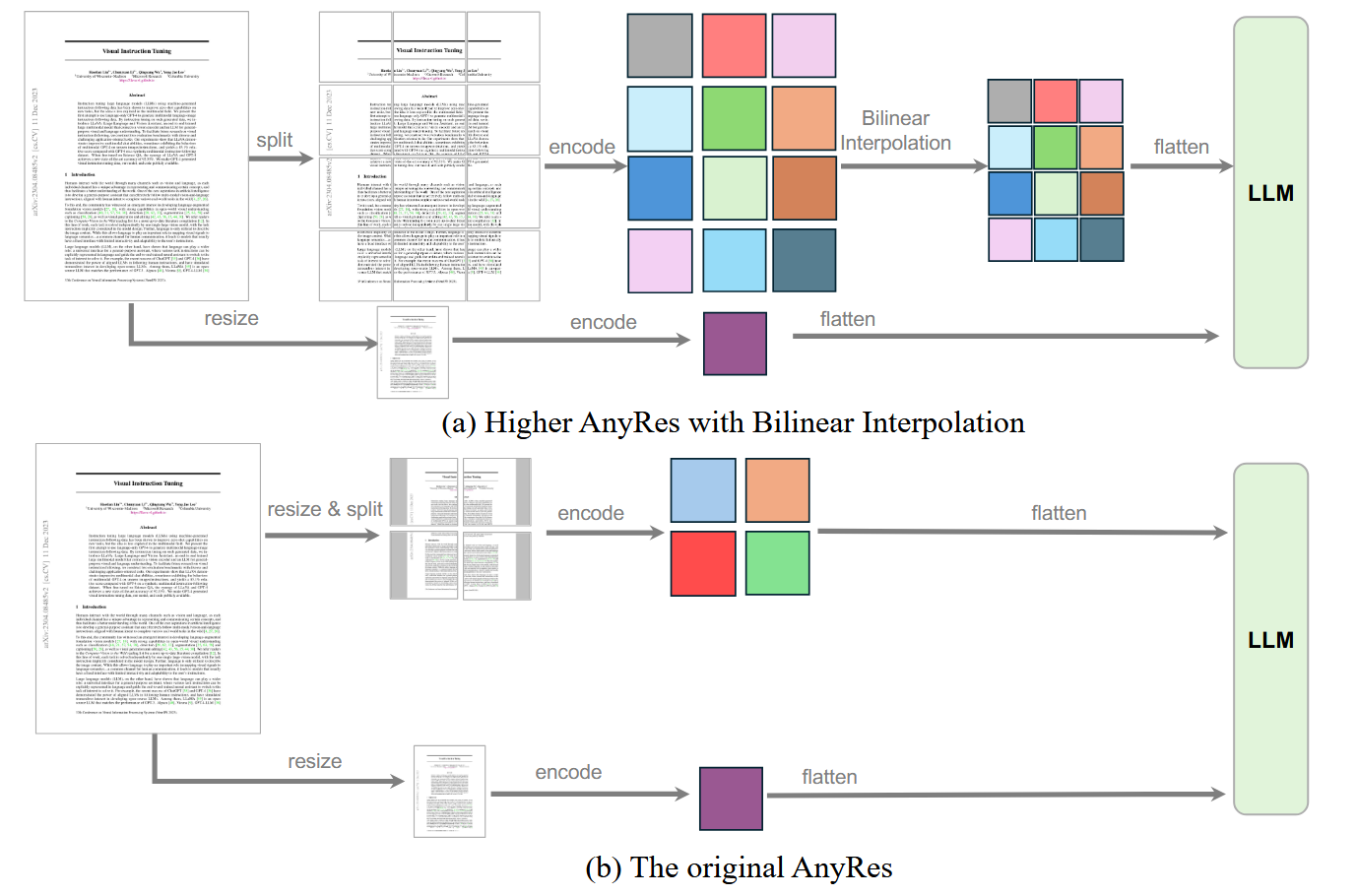
Higher AnyRes
最终作者提出了 Higher AnyRes:如上图(b)所示,把“一张任意分辨率图”变成“base + 多crop”的统一表示
对任意分辨率图片,Higher AnyRes 选一个空间配置(宽方向 \(a\)、高方向 \(b\)),把图像划分为 \(a\times b\)个 crops。
- crops 数:\(a\times b\)
- 额外还有一个 base image(先 resize 到视觉编码器适配的分辨率再编码)
- 因此,总的“图像视角”数量是:\((a\times b + 1)\)
base 提供全局语义;crops 提供局部细节(高分辨率信息被拆到多个局部视野中)。
假设视觉编码器对每个视角(base 或 crop)产生同样数量的 token:\(T\)。
则该张图总视觉 token 数:
- \(T\):每个视角的 token 数(例如 ViT 的 patch tokens 数,或 feature map flatten 后的长度)
- \(L\):整张图(base + crops)拼起来后喂给 LLM 的视觉 token 总长度
论文引入一个 token 的总预算阈值 \(\tau\)。当 \(L>\tau\)时,降低每个视角的 token 数,使得总 token 约束在预算内:
并且在需要降采样 token 的情况下,使用双线性插值实现(通常对应:对 feature map 在空间维度做插值/下采样,再 flatten 成更短 token 序列)。这其实就是“token pooling”的一种实现路径:不是减少 crop 数,而是让每个 crop/base 的特征更“稀疏/更粗”,从而把总 token 控制在 \(\tau\) 内。
配置集合与选择准则:适配不同长宽比
定义一组空间配置 \(\{(a,b)\}\),用于适配不同分辨率与长宽比的图片。并且在这些候选中:
- 选择一个“需要最少 crops”的配置(在满足某种覆盖/适配规则的前提下)。
- crops 越多,局部细节越充分但计算越贵;在“够用”的情况下取最少 crops,是一种成本优先的策略。
最终作者利用Higher Anyres策略定义了三种输入场景的高层编码策略
- Single-image(单图):尽量保留原始分辨率 + 给足 token(长序列)
选一个较大的最大空间配置 \((a,b)\),尽量 不resize原图,通过多crop保留细节。给单张图分配较多视觉 token,形成“长序列”。
动机:高质量单图指令数据通常比视频更多、更丰富;让单图也用类似“视频那样的长视觉序列”去表示,有助于从 image → video 的能力迁移更平滑。
- Multi-image(多图):只用 base 分辨率,避免高分辨率多crop,省算力
- Video(视频):每帧 base 分辨率 + 用插值降 token,以换取更多帧
- 视频每一帧 resize 到 base 分辨率;
- 逐帧过视觉编码器得到 feature maps;
- 用双线性插值 减少每帧 token 数,从而在固定预算下可以“放进更多帧”。
数据
在多模态从 LLM 出发的训练里,“quality over quantity”尤其关键,原因是:
- 预训练的 LLM 与 ViT 本身已有大量知识;
- 与其用海量低质 web-scale 图文数据硬 scale,不如在有限算力下用精心筛选/构造的高质量数据去“精炼与增强”已有知识;
- 还强调一个容易忽略点:在训练生命周期后期,持续暴露给模型新的高质量数据,能带来持续知识获取。
High-Quality Knowledge
- Re-Captioned Detailed Description Data
- 使用:LLaVA-NeXT-34B 生成更细的 captions
- 来源数据集:COCO118K、BLIP558K、CC3M
- 合并后规模:3.5M samples
- 观点:这可以看作一种“自我改进”式的数据构造(用较早版本模型生成训练数据)。
- Document / OCR Data(文档/OCR数据)
- 使用:UReader 的 Text Reading 子集(100K,PDF 渲染即可获得)
- 加上:SynDOG EN/CN
- 合计:1.1M samples
- Chinese and Language Data(中文与语言相关数据)
- 使用 ShareGPT4V 的原始图片
- 调用 Azure API 的 GPT-4V 生成 92K 详细中文 caption
- 目标:增强中文能力
一个很重要的观察:几乎所有(99.8%)高质量知识数据是合成的,原因是真实世界收集大规模高质量数据成本高,并且还存在版权限制你可以把这一段理解成:OneVision 的“高质量知识学习”更像 用强模型生成/改写数据来精炼知识,而不是依赖 web-scale 弱标注图文。
视觉指令微调数据
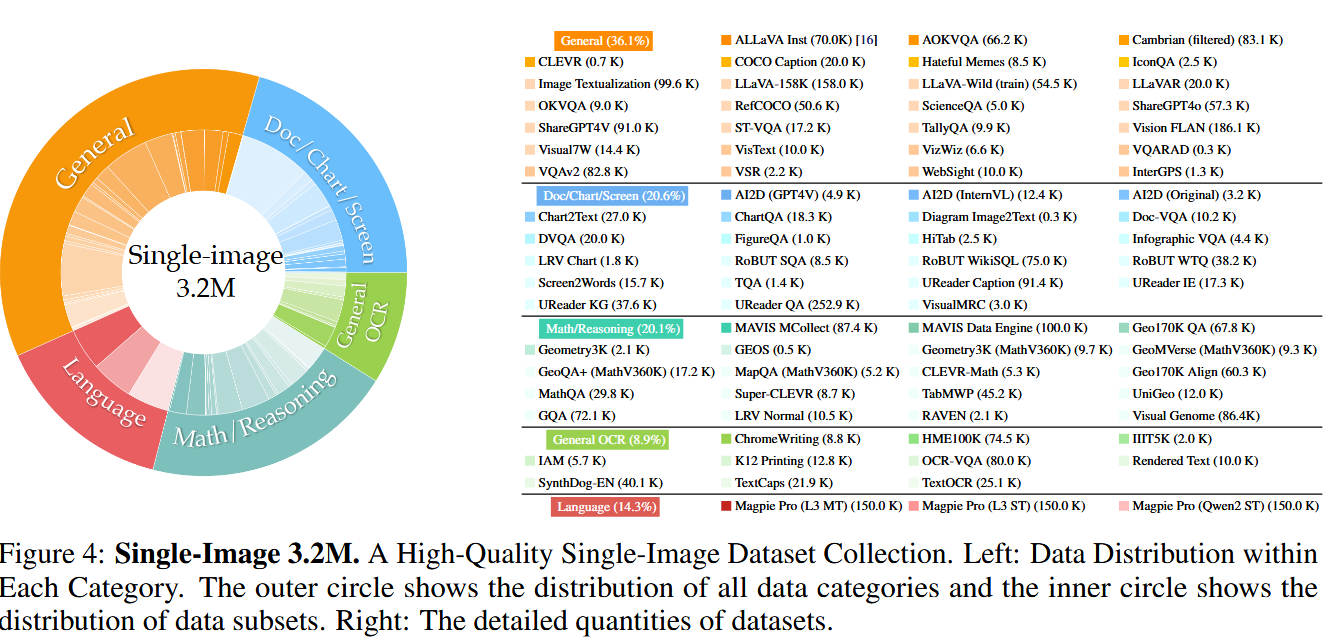
阶段 1:Single-Image Data(单图阶段)
- 明确构建一个“平衡的单图数据集合”
- 总量:3.2M samples
- 用途:先把“单图视觉理解 + 指令跟随”的基本盘做强。
阶段 2:OneVision Data(混合场景微调阶段)
在单图阶段之后,进一步用 video + image + multi-image 的混合数据微调:
- 总量:1.6M mixed samples
- 构成:
- 560K multi-image(来自 [68])
- 350K videos(项目内收集)
- 800K single-image samples
- 关键点:这一阶段不再引入新的单图数据,而是从上一阶段的单图集合里抽取“高质量且平衡”的部分进行采样(截图后半句被截断,但逻辑已很明确)

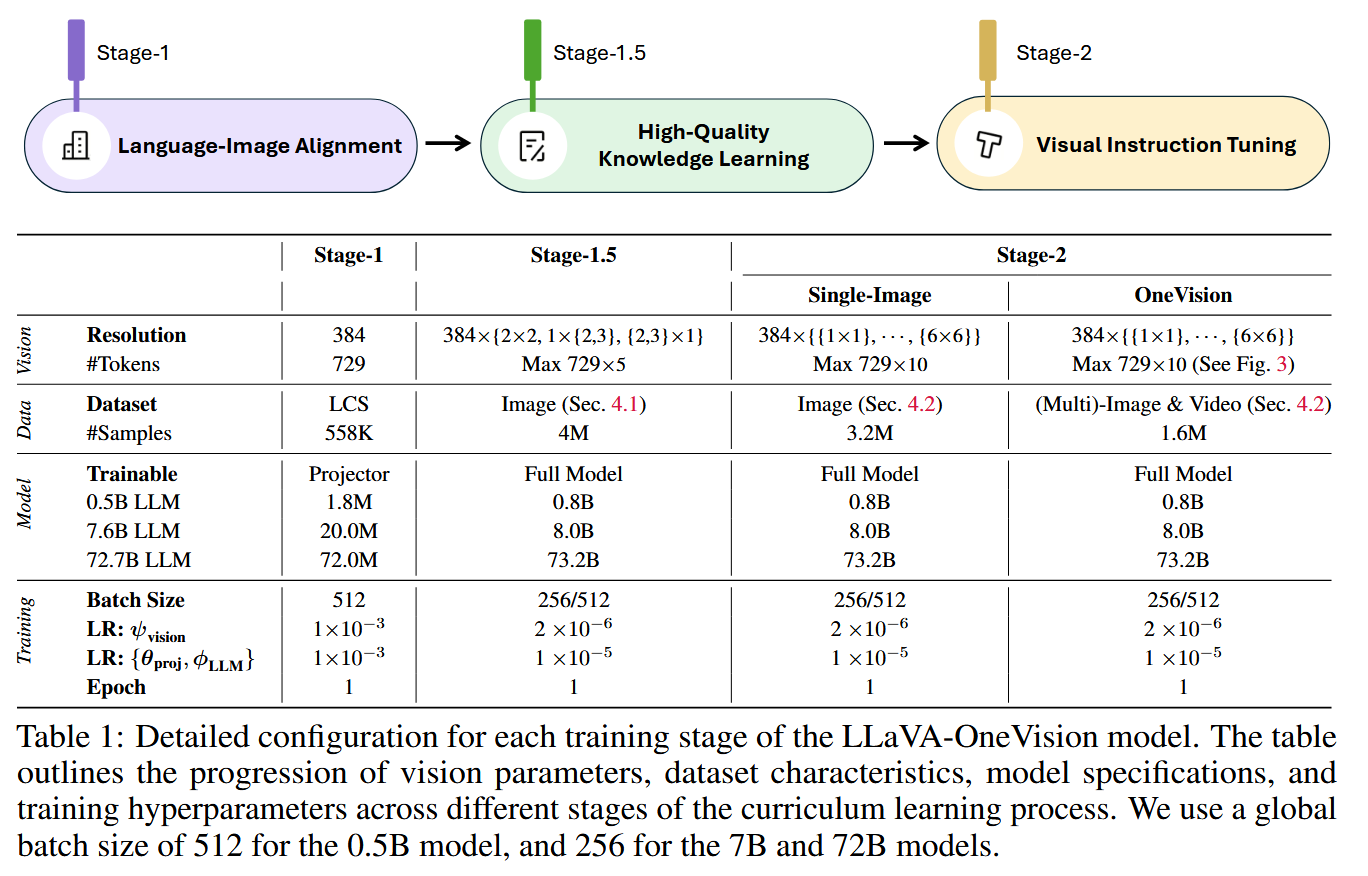
训练流程
- Stage-1:视觉和文本特征对齐
- Stage-1.5: 高质量知识学习
- Stage-2:视觉指令微调
LLaVA-Onevision-1.5
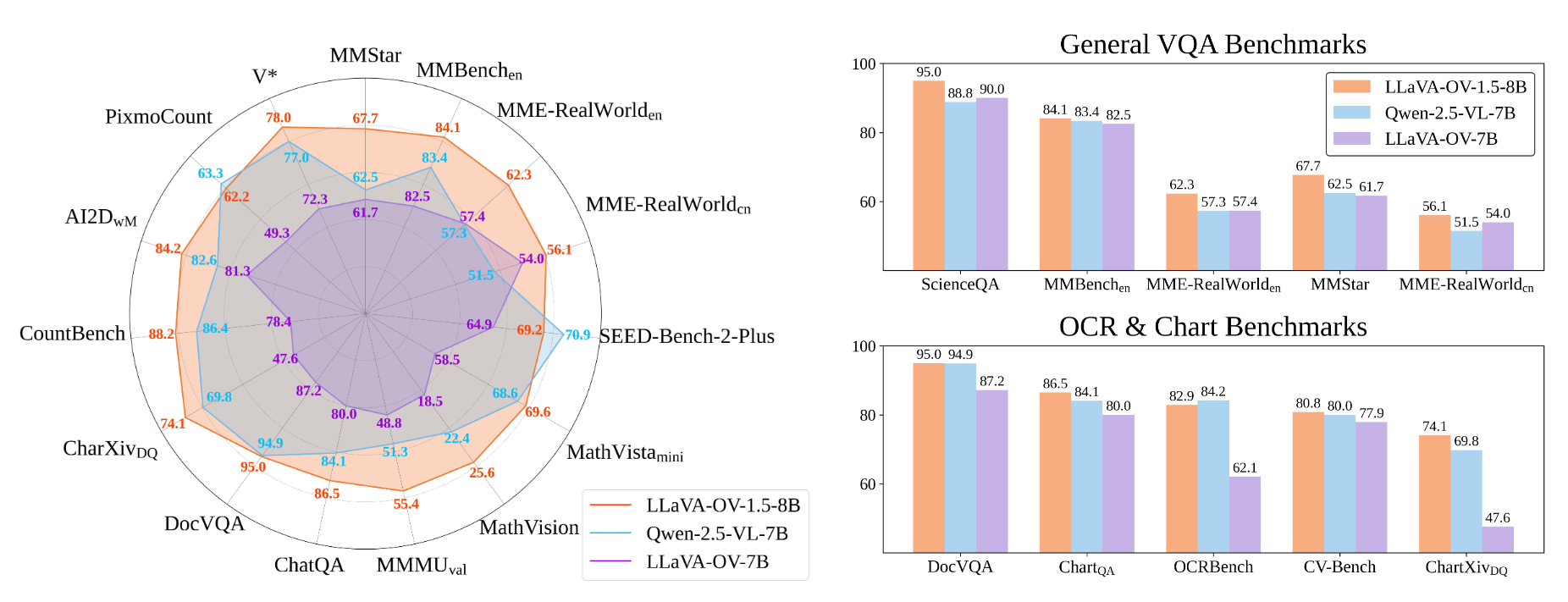
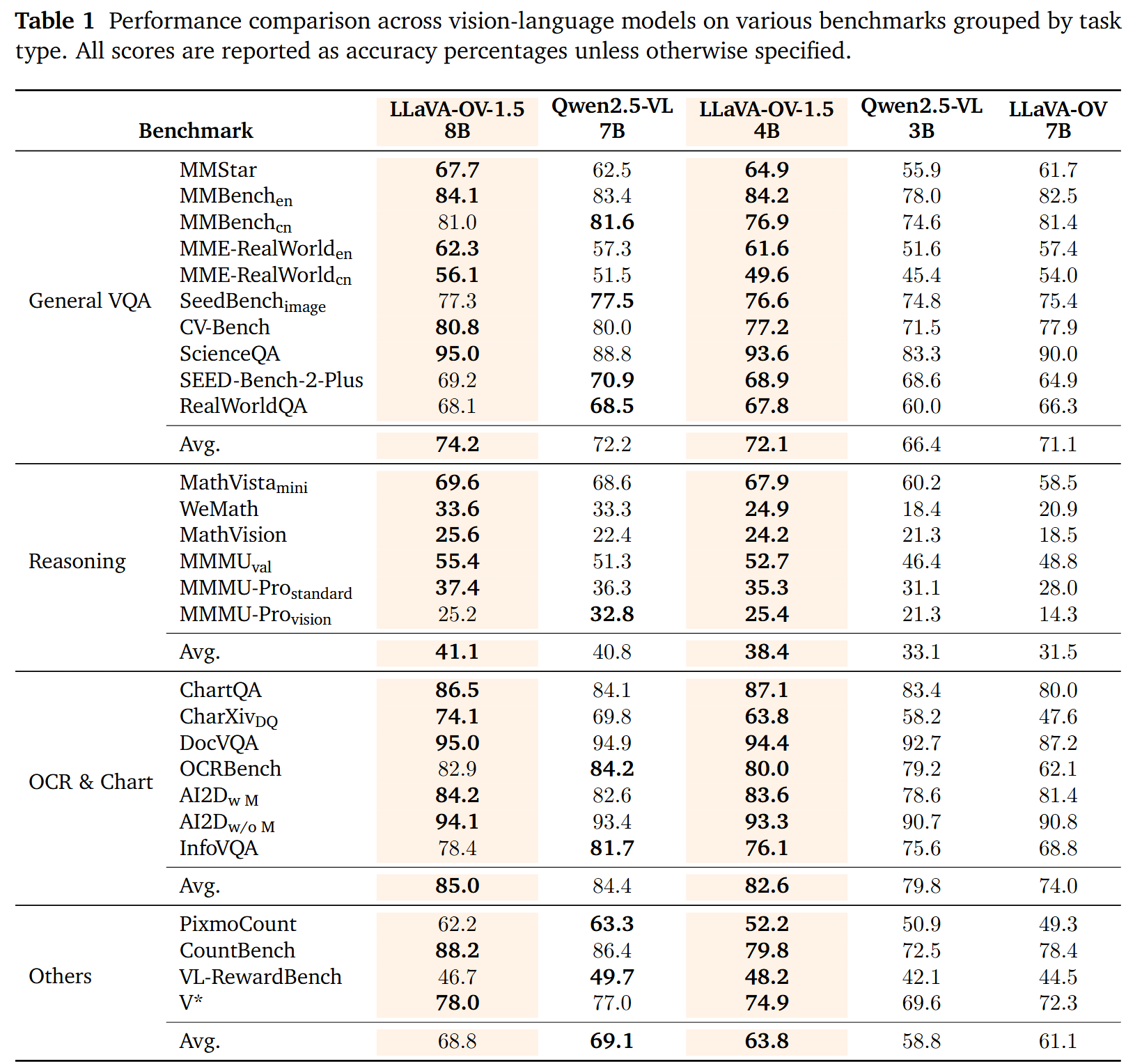
LLaVA-OneVision-1.5,一个旨在以显著降低的计算和财务成本实现最先进性能的新型大视听多模态模型(LMMs)系列。它提供了一个完全开放、高效且可复现的框架,用于从零开始构建高质量的视觉-语言模型,从而推动多模态AI的民主化。
其核心贡献体现在三个主要方面:
- 大规模精选数据集: 研究者构建了85M的LLaVA-OneVision-1.5-Mid-Traning概念平衡预训练数据集,以及22M的LLaVA-OneVision-1.5-Instruct精心策划的指令数据集。
- 对于LLaVA-OneVision-1.5-Mid-Traning,通过引入一种概念平衡采样策略来丰富预训练数据的多样性。与依赖原始字幕进行概念匹配的MetaCLIP不同,该方法采用基于特征的匹配方法
- LLaVA-OneVision-1.5-Instruct数据集则聚合了来自广泛来源的指令调优数据,精心策划了7个类别的平衡覆盖,包括Caption、Chart & Table、Code & Math、Domain-specific、General VQA、Grounding & Counting、OCR和Science。
- 高效训练框架: 开发了一套完整的端到端高效训练框架,通过利用离线并行数据打包策略(offline parallel data packing strategy)优化成本效益。该策略在预处理阶段将多个较短的样本合并为打包序列,利用哈希桶处理大规模数据,并通过多线程、策略感知批处理来控制打包成功率和批次构成。相较于在线打包,这种离线方法能确保统一的输出长度,并对85M预训练样本实现高达11倍的压缩比,显著提升了训练效率和GPU利用率。训练LLaVA-OneVision-1.5的预算仅为$16,000。
- 最先进性能: 实验结果表明,LLaVA-OneVision-1.5在广泛的下游任务中表现出极具竞争力的性能。具体而言,LLaVA-OneVision-1.5-8B在27个基准测试中的18个上超越了Qwen2.5-VL-7B,而LLaVA-OneVision-1.5-4B则在全部27个基准测试中超越了Qwen2.5-VL-3B。
模型结构
LLaVA-OneVision-1.5沿袭了LLaVA系列经典的“ViT–MLP–LLM”范式。
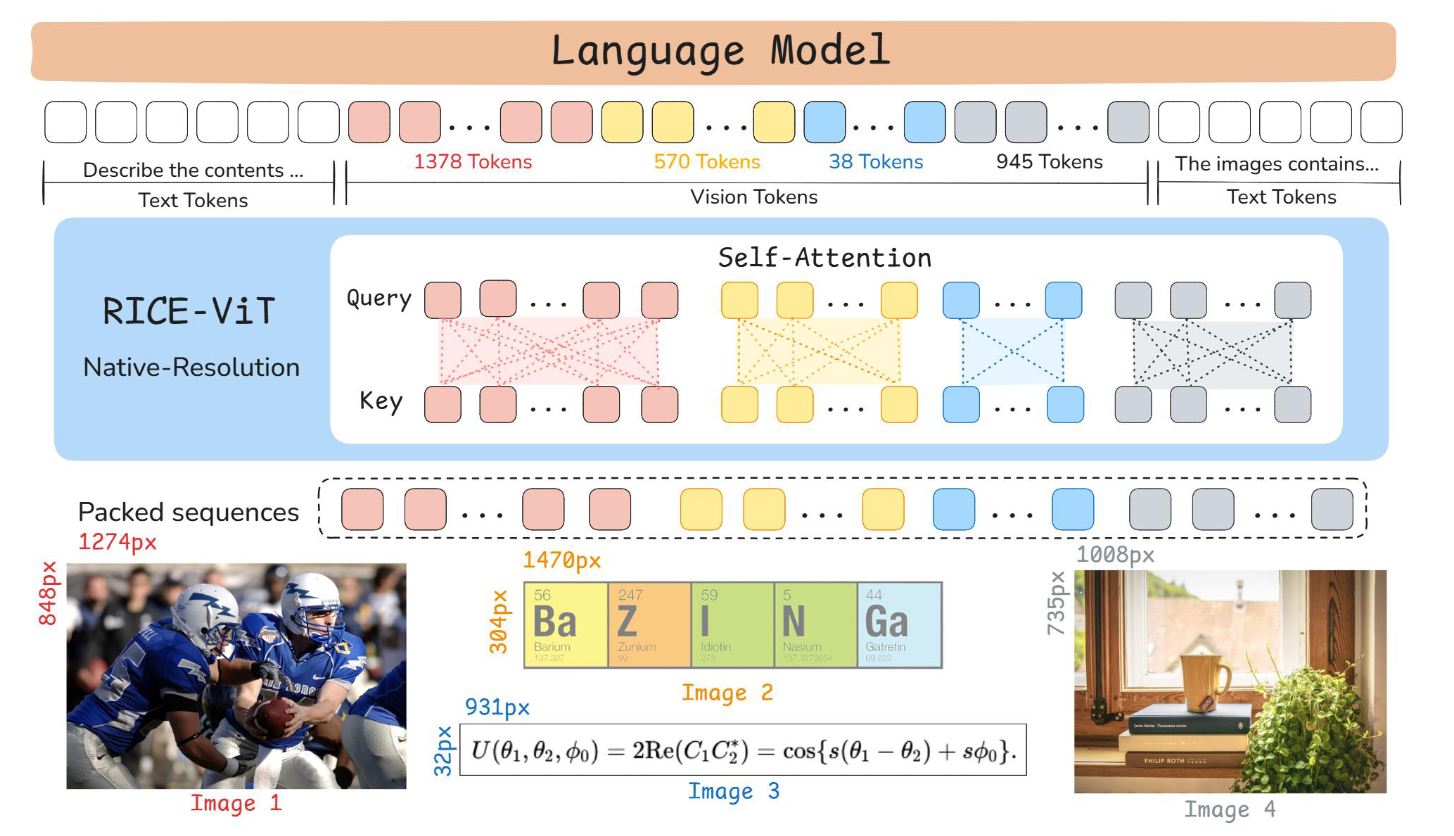
Vision Encoder: 不同于以往采用SigLIP或DFN的工作,尽管像CLIP和SigLIP这样的大规模视觉-语言对比模型通过全局视觉-语言对齐展现出强大的性能,但它们未能捕捉训练数据的相似结构或图像中的局部区域语义。这种不足源于实例级对比学习,它无论实例的语义相似性如何,都将所有实例视为负样本,并且仅用一个全局嵌入来表示每个实例。LLaVA-OneVision-1.5集成了RICE-ViT(Region-aware Cluster Discrimination Vision Transformer)作为视觉编码器。RICE-ViT通过引入统一的区域簇判别损失(unified region cluster discrimination loss),并结合区域感知注意力机制(region-aware attention mechanism)进行局部语义建模,以及2D旋转位置编码(2D Rotary Positional Encoding),自然支持可变输入分辨率,无需特定的分辨率微调。这使其能增强对象和OCR能力,捕获图像中的局部区域级语义,并简化了训练复杂性(相比SigLIP2的多种专门损失)。
Projector: 遵循Qwen2.5-VL的方法,首先将空间上相邻的四组Patch特征进行分组,然后通过一个两层多层感知机(MLP)将其映射到LLM的文本嵌入空间。
Large Language Model: LLaVA-OneVision-1.5系列采用Qwen3作为语言骨干(language backbone),以显著提升下游任务性能。
训练数据
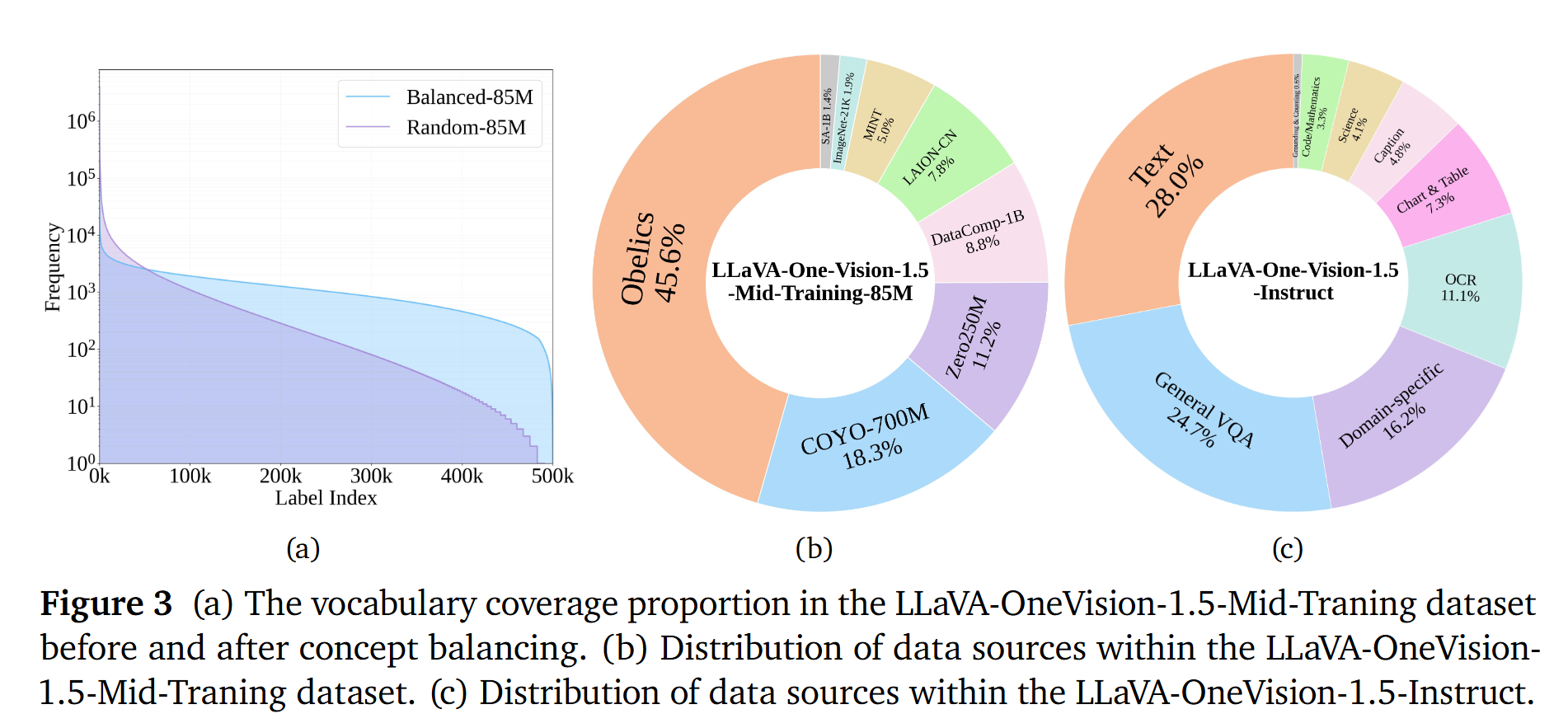
- 对齐数据:LLaVA-1.5 558K:先使用 LLaVA-1.5 558K将视觉特征对齐到 LLM 的词向量/嵌入空间,作为后续训练的基础对齐步骤。
- Mid-Training 预训练数据:LLaVA-OneVision-1.5-Mid-Training(85M),包含 COYO-700M、Obelics、DataComp-1B、LAION-CN、ImageNet-21K、SAM-1B、MINT、Zero250M
- 指令微调数据:LLaVA-OneVision-1.5-Instruct(22M)
- 构建了 LLaVA-OneVision-1.5-Instruct 指令数据集:总规模2200 万(22M)样本,覆盖 7 大类
概念均衡采样(Concept-balanced Sampling)
作者为提升预训练数据的多样性与概念覆盖,引入受 MetaCLIP启发的 概念均衡采样策略,但与 MetaCLIP 不同点在于:
MetaCLIP 依赖原始 caption做概念匹配,因此对以下数据不友好:
- 无 caption 或 交错式数据(如 SAM-1B、ImageNet-21K、Obelics)
- caption 过短/不完整(如 COYO-700M 常见)
本文方法改为基于特征的匹配,降低对 caption 质量的依赖。具体来说
- 使用预训练的 MetaCLIP-H/14-Full-CC2.5B 编码器:
- 将 图像与 MetaCLIP 的 50 万(500K)概念词条投影到同一嵌入空间
- 对每张图像:
- 计算与概念嵌入的相似度(余弦相似度,且嵌入做 L2 归一化)
- 检索 Top-K 最近概念,作为该图像的概念“标签/归纳”
- 按照这些概念的逆频率为图像赋权,并按权重进行采样 → 目的:让采样后的数据在“概念分布”上更均衡
- 产出:得到 85M 概念均衡的 mid-training 图像集合。
- 随后:
- 用强 captioner 为这些图像生成英文+中文 caption
- 用有效性过滤(validity filter)去除重复与过长输出
文中还提到:由于 MetaCLIP 概念嵌入本身已“概念均衡”,因此用它做相似度检索有利于进行基于相似度的概念归纳(concept induction);Top-K 概念还可用于构造更“语义对齐”的伪 caption(pseudo-captions)。
模型训练
模型采用三阶段训练流水线:
Stage-1:Language-Image Alignment(语言-图像对齐): 使用LLaVA-1.5 558K数据集预训练投影层,将视觉特征与LLM的词嵌入空间对齐。
Stage-1.5:High-Quality Knowledge Learning(高质量知识学习): 在语言-图像对齐的基础上,使用LLaVA-OneVision-1.5-Mid-Traning数据集对所有模块进行全参数训练(full-parameter training),以平衡计算效率和新知识注入。
Stage-2:Visual Instruction Tuning(视觉指令调优): 使用LLaVA-OneVision-1.5-Instruct和FineVision数据集继续进行全参数训练,使LMM能够理解并遵循各种视觉指令。
评估
消融研究进一步证实了其设计的有效性:视觉编码器对比显示,RICE-ViT在OCR和文档理解方面表现出显著优势,并且在LMM训练后,其性能优于Qwen-ViT。Mid-Training数据规模扩展证明,在高质量知识学习阶段扩展数据量能持续提升模型在所有基准上的性能。概念平衡的有效性研究表明,概念平衡的数据集在绝大多数下游任务中优于随机采样数据。指令数据质量和规模的评估强调,融合LLaVA-OneVision-1.5-Inst-Data和FineVision的Merged46M数据集在SFT阶段取得了最佳效果。
综上,LLaVA-OneVision-1.5为构建高效、可复现的高性能视觉-语言系统树立了新范式,证明了在资源有限条件下从零训练竞争性多模态模型的可行性,并有望成为社区进一步开发专业应用和更强大LMM的基础资源。