NLP
2026-03-23
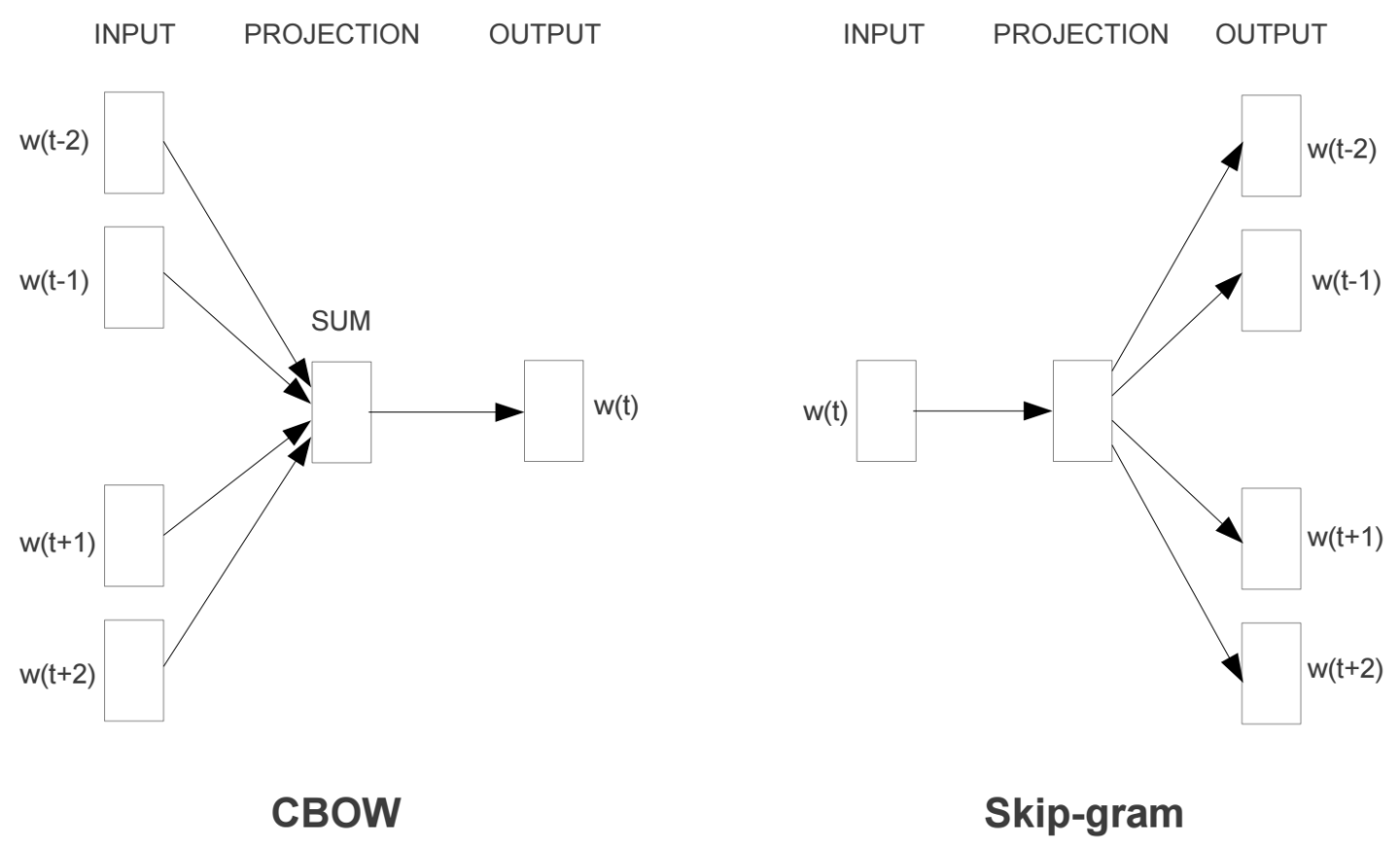
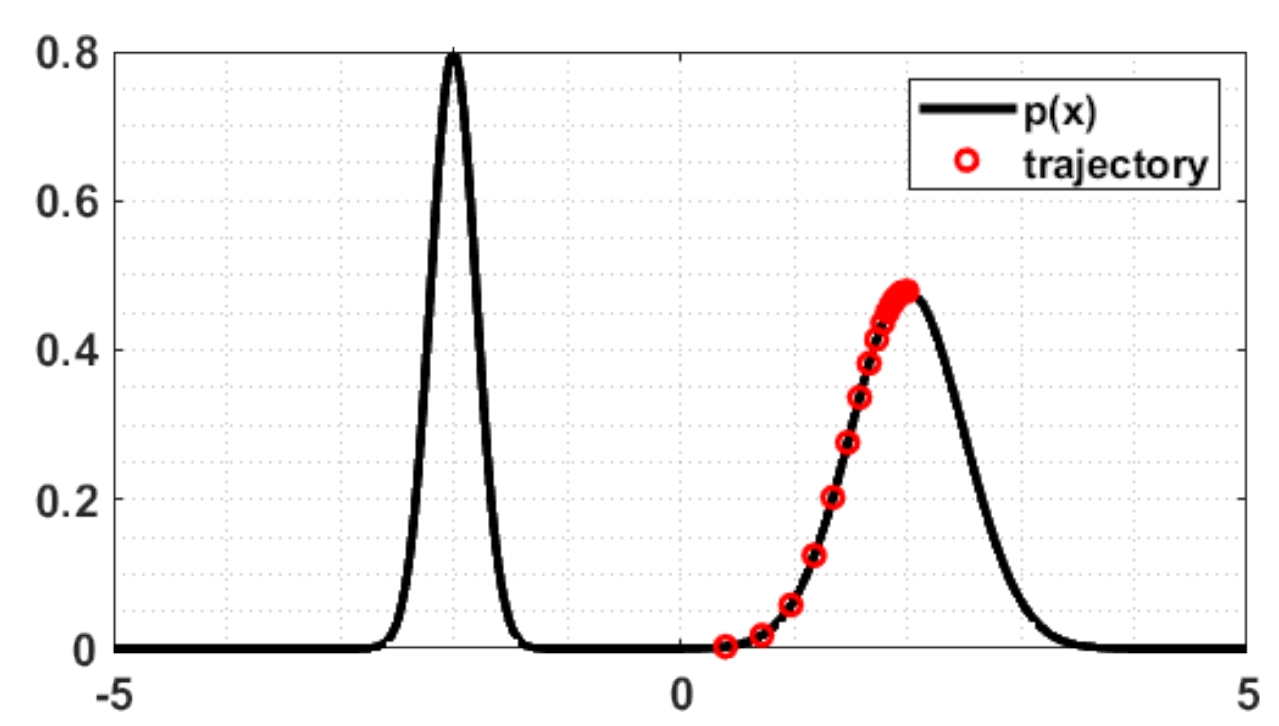
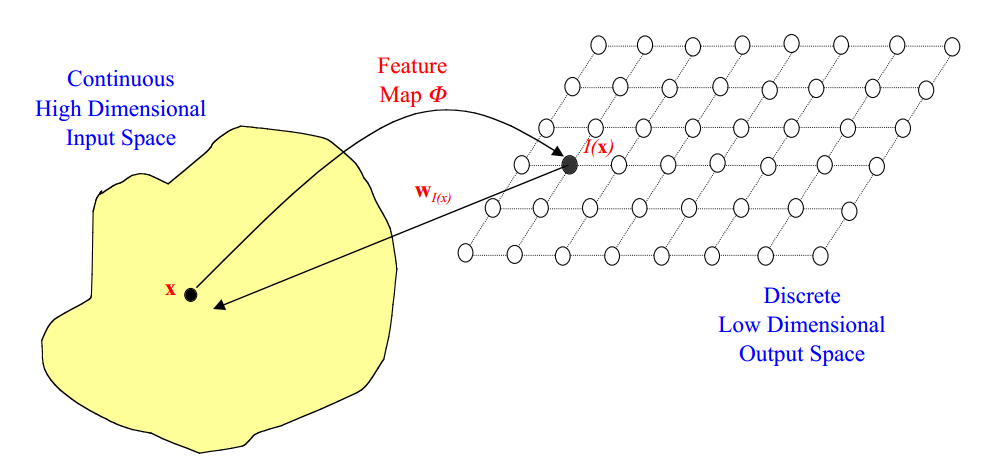
什么是Word2Vec和Embeddings? Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即 通过一个嵌入空间使得语义上相似的单词在该空间内距离很近 。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。 我们从直观角度上来理解一下,cat这个单词和kitten属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。通过对词汇表中单词进行这种数值表示方式的学习(也就是将单词转换为词向量),能够让我们基于这样的数值进行向量化的操作从而得到一些有趣的结论。比如说,如果我们对词向量kitten、cat以及dog执行这样的操作:kitten - cat + dog,那么最终得到的嵌入向量(embedded vector)将与puppy这个词向量十分相近。 第一部分 模型...