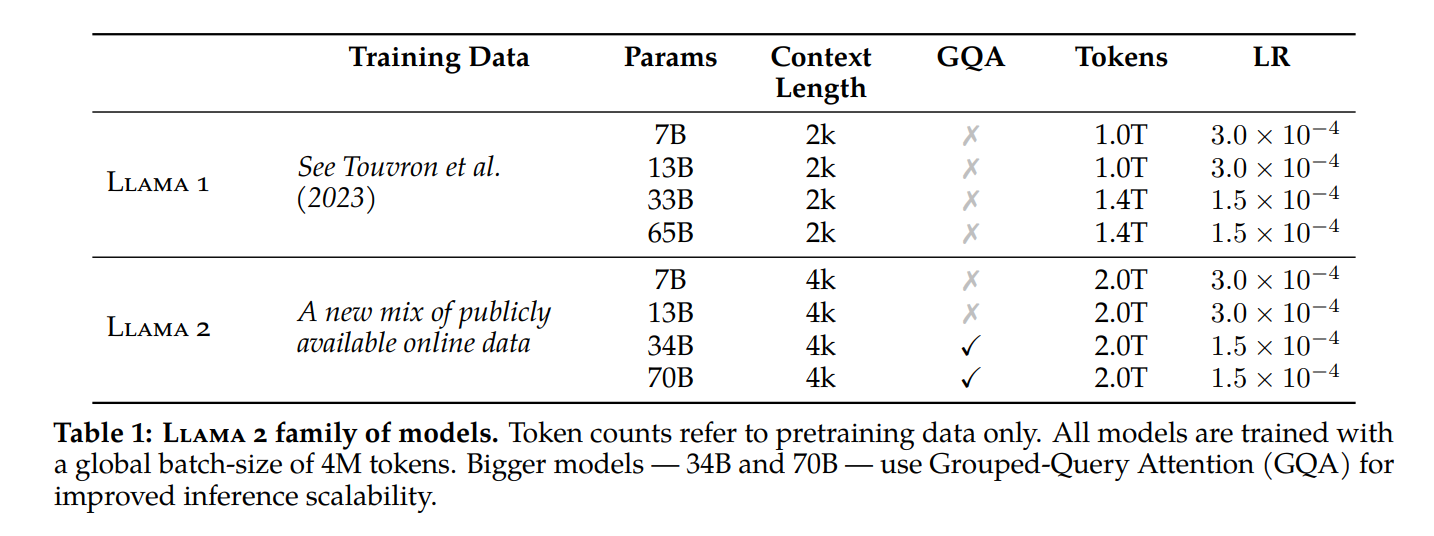
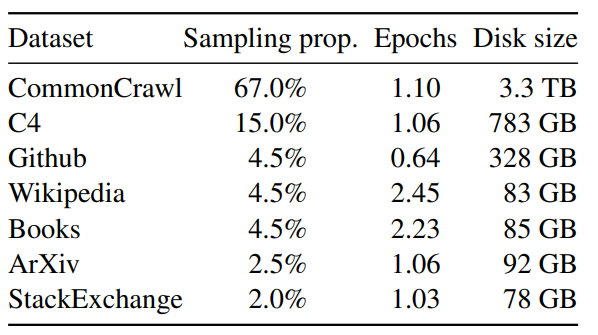
Large Model
2025-01-02

简介 该工作建立了一个GCG(Grounded Conversation Generation )的数据集和对应多模态大模型,与之前的工作主要的区别在于针对输入图像,可以生成grounding pixellevel理解的语言对话,如下图示例所示: Model Automated Dataset Annotation Pipeline level 1: Object locatlization and attributes 1. Landmark Categorization 基于LLaVA模型对图像做场景的分类, 包含主要场景和细粒度场景。就是对数据集整体做一个大的类别标签和子类别标签,做场景的划分 [代码] 2. Depth Map Estimation 通过MiDaS v3.1 一个单目...