简介
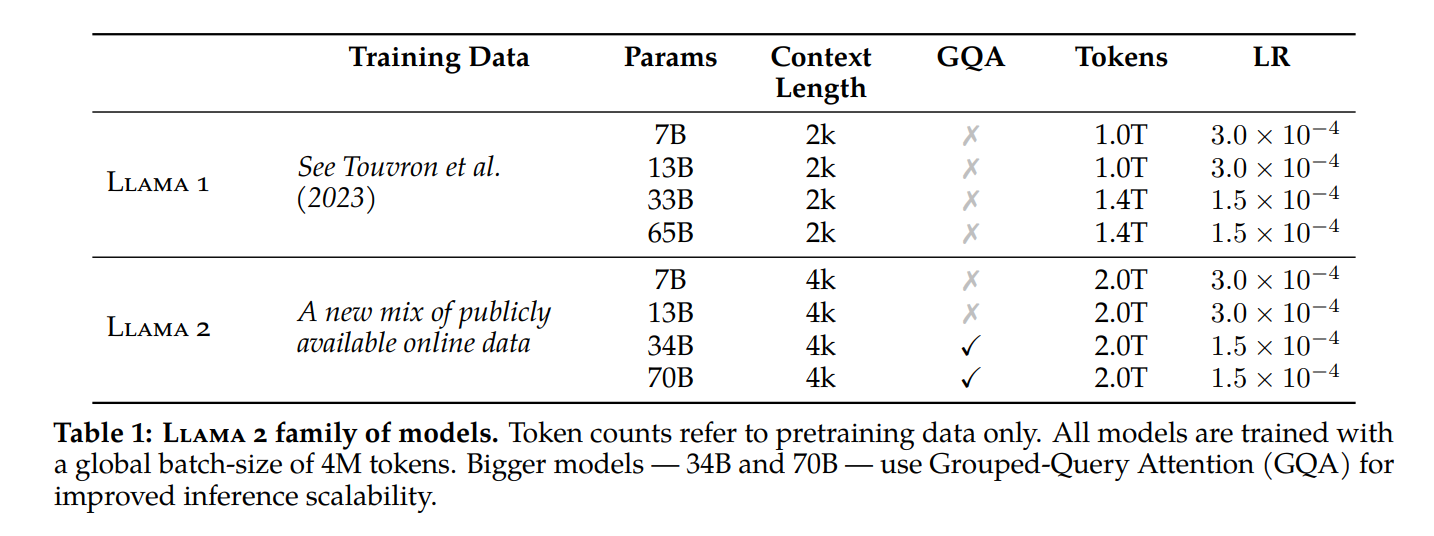
- 模型结构
- 32K词表大小
- 2T训练数据
- 4K上下文长度
- 模型种类:7B、13B、70B(用了GQA)
LLaMA 2-Chat:三个版本——7B 13B 70B
同时 Meta 还发布了 LLaMA 2-CHAT,其是基于 LLAMA 2 针对对话场景微调的版本,同样 7B、13B 和 70B 参数三个版本,具体的训练方法与ChatGPT类似
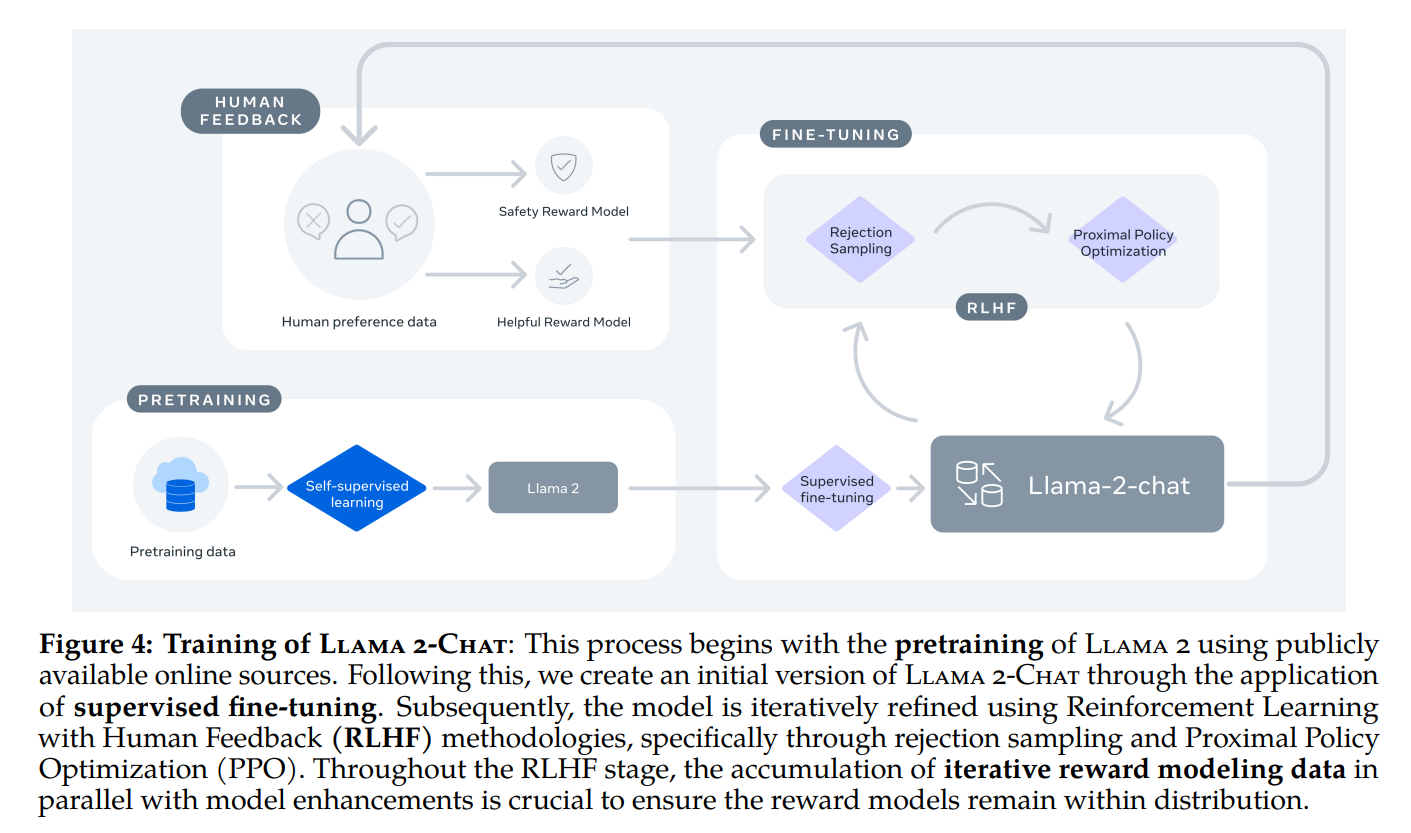
- 先是监督微调LLaMA2得到SFT版本 (接受了成千上万个人类标注数据的训练,本质是问题-答案对 )
- 然后使用人类反馈强化学习(RLHF)进行迭代优化
先训练一个奖励模型
然后在奖励模型/优势函数的指引下,通过拒绝抽样(rejection sampling)和近端策略优化(PPO)的方法迭代模型的生成策略
LLAMA 2 的性能表现更加接近 GPT-3.5,Meta 也承认距离 GPT-4 和 PaLM 2 等领先非开源模型还有差距

Meta 在技术报告中详细列出了 LLAMA 2 的性能、测评数据,以及分享了重要的训练方法,具体详见原论文
Grouped-Query Attention(GQA)
自回归解码的标准做法是缓存序列中先前标记的键 (K) 和值 (V) 对,从而加快注意力计算速度
然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显着增长
对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能,可以使用
- 具有单个 KV 投影的原始多查询格式(MQA)
ChatGLM2-6B即用的这个,详见此文《ChatGLM两代的部署/微调/实现:从基座GLM、ChatGLM的LoRA/P-Tuning微调、6B源码解读到ChatGLM2的微调与实现》的3.1.2节
不过,多查询注意(Multi-query attention,简称MQA)只使用一个键值头,虽大大加快了解码器推断的速度,但MQA可能导致质量下降,而且仅仅为了更快的推理而训练一个单独的模型可能是不可取的 - 或具有多个 KV 投影的分组查询注意力(grouped-query attention,简称GQA),速度快 质量高
23年,还是Google的研究者们提出了一种新的方法,即分组查询注意(GQA,论文地址为:

Llama 2-Chat中的RLHF:依然是三阶段训练方式
监督微调(SFT)
在SFT的数据上
- 他们先是重点收集了几千个高质量 SFT 数据示例 (注意:很多新闻稿会说SFT的数据达到百万以上,这就是没仔细看论文的结果,论文之意是胜过百万低质量的数据,
- 之后发现几万次的SFT标注就足以获得高质量的结果,最终总共收集了27540条用于SFT的标注数据
在微调过程中
- 每个样本都包括一个prompt和一个response(说白了,就是问题-答案对,和instructGPT/ChatGPT本身的监督微调是一个本质),且为确保模型序列长度得到正确填充,Meta 将训练集中的所有prompt和response连接起来。他们使用一个特殊的 token 来分隔prompt和response片段,利用自回归目标,将来自用户提示的 token 损失归零,因此只对答案 token 进行反向传播,最后对模型进行了 2 次微调
- 微调过程中的参数则如此设置:we use a cosine learning rate schedule with an initiallearning rate of 2 ×10−5 , a weight decay of 0.1, a batch size of 64, and a sequence length of 4096 token

训练两个奖励模型:一个偏实用 一个偏安全
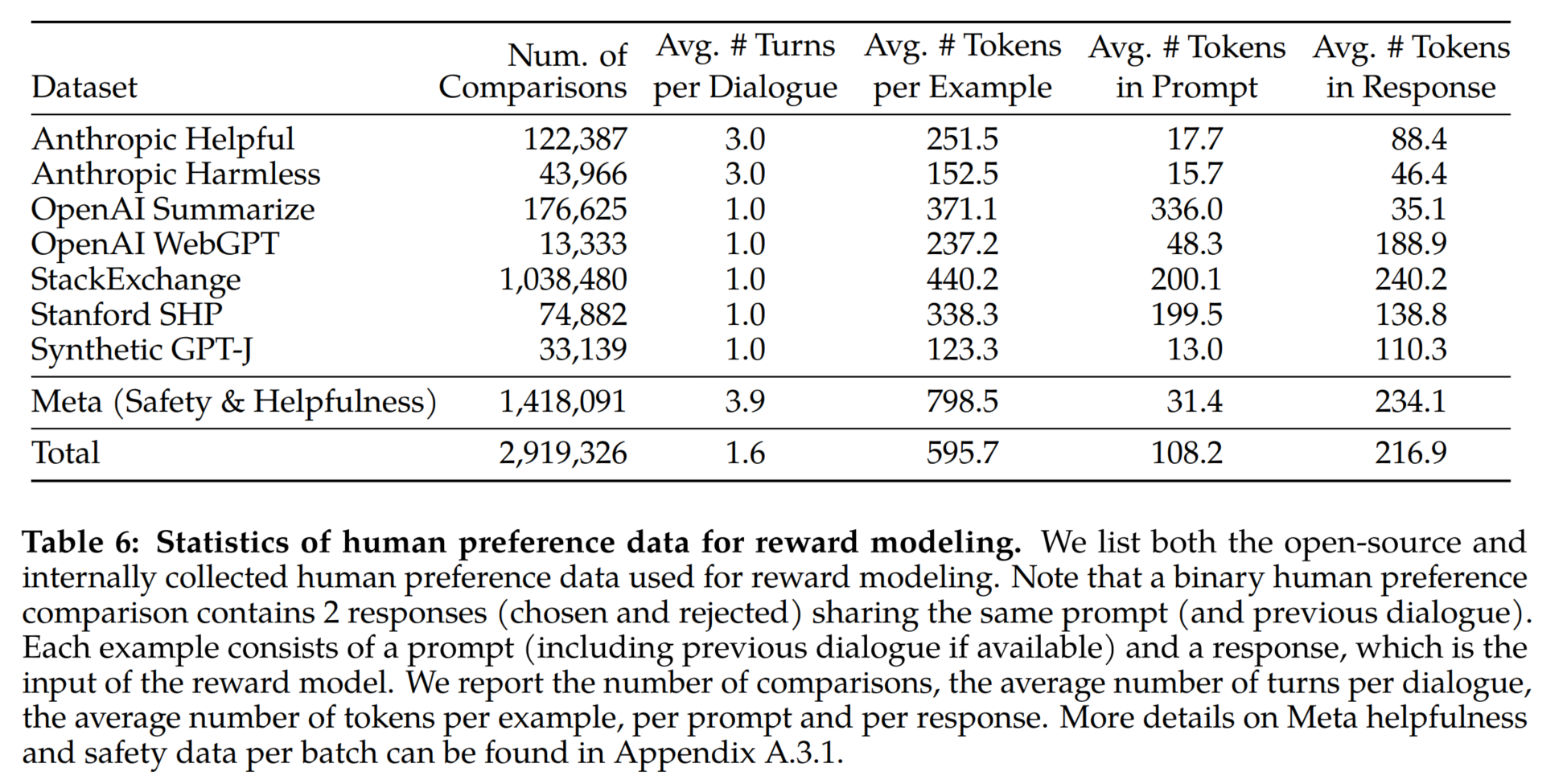
下表 6 报告了 Meta 长期以来收集到的奖励建模数据的统计结果,并将其与多个开源偏好数据集进行了对比。他们收集了超过 100 万个基于人类应用指定准则的二元比较的大型数据集,也就是奖励建模数据.
关于奖励数据
- prompt和response中的标记数因文本领域而异,比如摘要和在线论坛数据的prompt通常较长,而对话式的prompt通常较短。与现有的开源数据集相比,本文的偏好数据具有更多的对话回合,平均长度也更长
- 奖励模型将模型响应及其相应的提示(包括前一轮的上下文)作为输入,并输出一个标量分数来表示模型生成的质量(例如有用性和安全性),利用这种作为奖励的响应得分,Meta 在 RLHF 期间优化了 Llama 2-Chat,以更好地与人类偏好保持一致,并提高有用性和安全性
在每一批用于奖励建模的人类偏好标注中,Meta 都拿出 1000 个样本作为测试集来评估模型,并将相应测试集的所有prompt的集合分别称为实用性和安全性 (很多新闻稿会翻译成元实用、元安全,其实没必要加个“元”字,你理解为是Meta内部定义的“实用”与“安全”两个概念即可)
故为了兼顾和平衡模型的实用性和安全性,LLaMA 2团队训练了两个独立的奖励模型
- 一个针对实用性(称为实用性RM)进行了优化,在内部所有偏实用的奖励数据集上进行训练,并结合从内部偏安全的奖励数据集和开源安全性数据集中统一采样的同等部分剩余数据
- 另一个针对安全性(安全性RM)进行了优化,在内部所有偏安全的奖励数据和人类无害数据上进行训练,并以90/10的比例混合内部偏实用的奖励数据和开源实用性数据
并通过预训练的LLaMA 2初始化奖励模型(意味着奖励模型的架构与参数与预训练模型一致,只是用于下一个token预测的分类头被替换为用于输出标量奖励的回归头),因为它确保了两个模型都能从预训练中获得的知识中受益
「虽然论文中的原文是:We initialize our reward models from pretrained chat model checkpoints, as it ensures that both modelsbenefit from knowledge acquired in pretraining,以及The model architecture and hyper-parameters are identical to thoseof the pretrained language models, except that the classification head for next-token prediction is replacedwith a regression head for outputting a scalar reward,但为何没有类似ChatGPT那样,通过微调过的SFT初始化RM模型,该点存疑 」
为了使模型行为与人类偏好相一致,Meta 收集了代表了人类偏好经验采样的数据,通过针对同一个prompt模型给出的两个不同的response,人类标注者选择他们更喜欢的模型输出。这种人类偏好被用于训练奖励模型
奖励模型的训练目标使用了一个binary ranking loss 保证chosen response的分数高于rejected
其中,\(y_c\) 是标注者选择的首选response,\(y_r\) 是被拒绝的对应response, \(r_\theta(x, y)\)即为奖励模型输出的score
且为了让模型可以更好的体会到不同response质量之间的差异,作者团队将偏好评级被分为4层评级,且考虑到根据这些评级信息使得奖励模型对有更多差异的生成,有着不同分数且这些分数上彼此之间的差距尽可能拉开是有用的「Given that our preference ratings is decomposed as a scale of four points (e.g.,significantly better), it can be useful to leverage this information to explicitlyteach the reward model to assign more discrepant scores to the generations that have more differences」,为此,我们在损失中进一步添加一个边际成分
其中边际 \(m(r)\) 是偏好评级的离散函数,他们发现这个边际成分可以提高帮助性奖励模型的准确性,特别是在两个response更好区分的的样本上「where the margin m(r) is a discrete function of the preference rating. We found this margin component can improve Helpfulness reward model accuracy especially on sampleswhere two responses are more separable」
具体而言,为了衡量不同response好坏的程度,划分为4个等级(比如很好、好、较好、一般好或不确定),那这4个等级是需要有一定的间隔的,彼此之间不能模棱两可(模棱两可就容易把模型搞糊涂),而这个间隔大小是个超参数,可以人为设定,比如为小点的间隔1/3或大点的间隔1,如下图所示

具体的策略迭代:PPO与拒绝采样
此处使用两种主要算法对 RLHF 进行了微调:
- 近端策略优化(PPO)
PPO在之前的《ChatGPT技术原理解析》或《强化学习极简入门》等文章中讲的很详细了,可以参见 - 拒绝采样(Rejection Sampling)
即在模型生成多个回复后,选择最佳的回复作为模型的输出,过程中,如果生成的回复不符合预期,就会被拒绝,直到找到最佳回复
从而帮助提高模型的生成质量,使其更符合人类的期望