研究对象与基本设定
我们希望学习一个能够“生成数据”的概率模型。假设我们有一个数据集 \(D\),每个样本是 \(n\) 维二值向量:\(x \in \{0,1\}^n\)
我们的目标是用一个参数化分布 \(p_\theta(x)\) 去逼近真实数据分布 \(p_{\text{data}}(x)\),并最终能够:
- 密度估计:给定 \(x\) 计算 \(p_\theta(x)\) 或 \(\log p_\theta(x)\)
- 采样生成:从 \(p_\theta(x)\) 采样得到新的 \(x\)
给定一个具体的任务,如MNIST中的手写数字二值图分类,从Generative的角度进行Represent,并在Inference中Learning.

下面先介绍:
描述如何对这个MINST任务建模 \(p(X,Y)\)(Representation)
对MNIST任务建模
对于一张pixel为 \(28\times28\) 大小的图片,令 \(x_1\) 表示第一个pixel的随机变量, \(x_1\in\{0,1\}\),需明确:
- 任务目标:学习一个模型分布\(p(x_1,...,x_{784}),x\in\{0,1\}\),使采样时 \(x\sim p_\theta(X)\),\(x\) 是一个logits数字的概率高
- 模型假设:
conditional probability tables (CPT)
- 先利用参数\(\alpha_1\) 参数化 \(p_{CPT}(x_1;\alpha^1)\),如 \(p_{CPT}(X_1=1;\alpha^1)=\alpha^1\), \(p_{CPT}(X_1=0;\alpha^1)=1-\alpha^1\)
- 基于前面的变量 \(x_1\),利用参数 \(\alpha_2\) 参数化 \(p_{logit}(x_2|x_1;\alpha^2)\),如 \(p_{logit}(X_2=1|x_1;\alpha^2)=\sigma(\alpha^2_0+\alpha_1^2x_1)\)
- 基于前面的变量 \(x_1,x_2\),利用参数 \(\alpha_3\) 参数化 \(p_{logit}(x_3|x_1,x_2;\alpha^3)\),如 \(p_{logit}(X_3=1|x_1,x_2;\alpha^3)=\sigma(\alpha^3_0+\alpha^3_1x_1+\alpha^3_2x_2)\)
以此类推,第\(i\)个pixel取决于前 \(i-1\) 个pixel,这种特性称作AutoRegressive,自回归即
这样建模的参数量有 \(1+2+\cdots+n\approx \frac{n^2}{2}\)
根据概率的链式法则,我们可以将 n 维上的联合分布分解为:
其中:\(x_{<i} = [x_1, x_2, \dots, x_{i-1}]\),这意味着:只要我们能为每个维度 \(i\) 学好一个条件分布 \(p(x_i \mid x_{<i})\),就能得到完整的 \(p(x)\)。
- 模型固定一个变量顺序 \(x_1, x_2, \dots, x_n\)
- 每个 \(x_i\) 的分布依赖于所有“之前”的变量 \(x_{<i}\)
- 不做额外条件独立假设(即“全连接依赖”)
这一结构也可理解为一个贝叶斯网络:每个节点 \(x_i\) 指向未来所有节点,或至少依赖所有过去节点。可以图形化地表示为贝叶斯网络

这种不做条件独立假设的贝叶斯网络被称为服从自回归性质。 术语自回归源自关于时间序列模型的文献,其中使用来自先前时间步长的观测值来预测当前时间步长的值。 在这里,我们固定变量 \(x_1, x_2,..., x_n\) 的顺序,第 \(i\) 个随机变量的分布取决于所选顺序中所有前面随机变量的值 \(x_1, x_2,..., x_{i-1}\).
用参数化函数表示条件分布
核心思想:不查表,而是用一个带固定参数量的函数去预测条件分布参数。
如果我们允许以表格形式指定每个条件概率 \(p (x_i | x _{<i})\),那么这样的表示是完全通用并且可以表示在 \(n\) 个随机变量上的任何可能分布。 然而,这种表示的空间复杂度随着 \(n\) 呈指数增长。
在自回归生成模型中,条件被指定为具有固定数量参数的参数化函数。 也就是说,我们假设条件分布 \(p (x_i | x_{ <i})\) 对应于伯努利随机变量,并学习将前面的随机变量 \(x_1, x_2,..., x_{i − 1 }\)映射到该分布的均值的函数。 因此,我们有
其中:
- \(f_i:\{0,1\}^{i-1}\to [0,1]\) 输出伯努利均值(即 \(p(x_i=1\mid x_{<i})\))
- \(\theta_i\) 是第 \(i\) 个条件分布对应的参数
- 总参数量为 \(\sum_{i=1}^{n} |\theta_i|\),通常远小于指数级
自回归生成模型的参数数量由 \(∑^n_{i = 1} | θ_i | \)给出。 正如我们将在下面的示例中看到的,参数的数量比之前考虑的表格设置少得多。 然而,与表格设置不同,自回归生成模型不能表示所有可能的分布。 它的表达能力受到以下事实的限制:表达能力受限于我们限制条件分布对应于均值为通过受限类参数化函数指定的伯努利随机变量
FVSBN
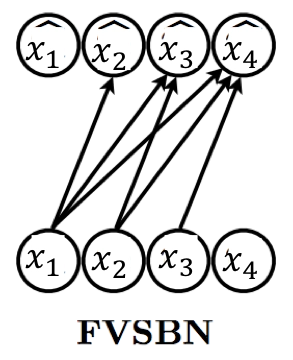
在最简单的情况下,我们可以将函数指定为输入元素的线性组合,然后是 sigmoid 非线性输出。 这为我们提供了fully-visible sigmoid belief network (FVSBN)的公式
即最简单的 \(f_i\):线性 + sigmoid:
其中:
- \(\sigma(\cdot)\) 为 sigmoid 函数,把实数映射到 \([0,1]\)
- \(\theta_i = \{\alpha_0^{(i)},\alpha_1^{(i)},\dots,\alpha_{i-1}^{(i)}\}\), 表示均值函数的参数
第 \(i\) 个条件分布需要 \(i\) 个参数,因此总参数量:\(\sum_{i=1}^{n} i = \mathcal{O}(n^2)\)。相比查表的指数复杂度已经大幅下降,但表达能力也较有限(本质是逐维 logistic 回归)。
用 MLP 增强表达力
用一个一层隐藏层的网络定义 \(f_i\):变量 \(i\) 的均值函数可以表示为
参数包括:\(\theta_i = \{A_i \in \mathbb{R}^{d\times (i-1)},\ c_i\in \mathbb{R}^d,\ \alpha^{(i)}\in \mathbb{R}^d,\ b_i\in \mathbb{R}\}\). 参数量主要由 \(A_i\) 决定,总体约为:\(\mathcal{O}(n^2 d)\)
问题:对每个 \(i\) 都有单独的网络(尤其是 \(A_i\) 尺寸不断增长),既费参数也费计算。
NADE:Neural Autoregressive Density Estimator
NADE 的核心是让不同维度的条件分布共享一套“输入到隐层”的权重。
NADE 定义:
其中:
- \(W \in \mathbb{R}^{d \times n}\) 为共享矩阵
- \(W_{\cdot,<i}\) 表示取前 \(i-1\) 列(对应 \(x_{<i}\))
- \(c \in \mathbb{R}^d\) 为共享偏置
整体参数集合:\(\theta = \{W\in \mathbb{R}^{d\times n},\ c\in \mathbb{R}^d,\ \{\alpha^{(i)}\}_{i=1}^n,\ \{b_i\}_{i=1}^n\}\)为均值函数 \(f_1(\cdot), f_2(\cdot), \ldots, f_n(\cdot) \)的完整参数集。权重矩阵 \(W\) 和偏置向量 \(c\) 在条件之间共享。
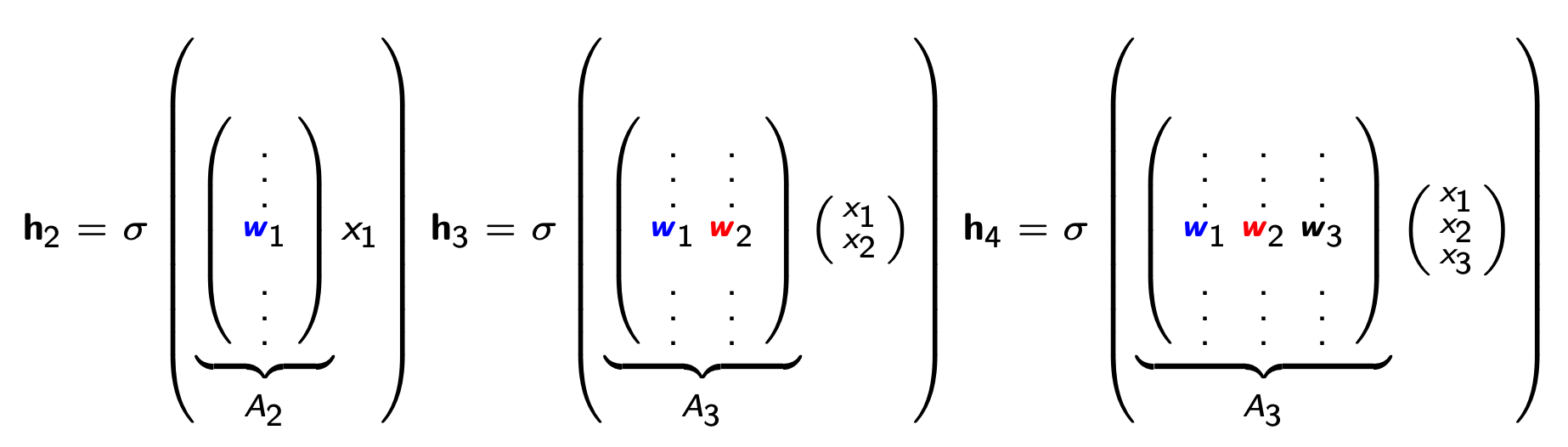
共享参数提供了两大收益
- 参数量显著降低:从朴素 MLP 的 \(\mathcal{O}(n^2 d)\) 降到:\(\mathcal{O}(nd)\)
- 计算可递推,整体 \(\mathcal{O}(nd)\) :NADE 可用递推方式更新隐藏层的“预激活”,避免每次从头计算(原文提到 base case 为 \(a_1=c\),后续可逐步加入第 \(i-1\) 个输入贡献)。直观上:
- 从 \(i\) 到 \(i+1\) 只多了一项与 \(x_i\) 相关的增量
- 因此可做到线性时间遍历所有条件
任务复杂度扩展RNADE(Random NADE)
上述NADE的任务背景是每个pixel均为二值变量 \(x_i\in\{0,1\}\)x, 现在先扩展到256个值的变量\(x_i\in\{0,1,...,255\}\),再扩展到连续变量如 \(x_i \sim N(u_i,\sigma_i)\).
多项式分布
先看看256个值的变量\(x_i\),自然想到用多项式分布categorical distribution,即 \(x_i\sim Cat(p_i^1,...,p_i^{256})\),对于第\(i\)个随机变量服从一个多项分布\(Cat\),其参数为\(p_i^k,k=1,...,256\)
在NADE中有:
因此RNADE有:
解释一下:
- (1):利用Autoregressive来建模联合分布,第\(i\)个随机变量的分布condition on前\(i − 1\)个随机变量的值,并服从一个多项式分布\(C a t\)(离散情况下的数量)
- (2):一个观测值\(\hat{x} _ i\)的多项式分布参数 \(p_i^1,...,p_i^{256}\) 来自隐层输出\(X_ih_i+b_i\)的softmax
- (3):一个隐层的输入\(h_i\) 与前面 \(i-1\)个随机变量有关
该建模过程,通过假设分布,模型最后的输出拟合的是分布参数,采样观测值的分布,而并不是观测值本身
高斯分布
连续变量的情况下,最容易想到的就是高斯分布了。根据上面的流程,看看建模过程是怎样的representation
- (4):利用Autoregressive来建模联合分布,第 \(i\) 个随机变量的分布condition on前 \(i-1\)个随机变量的值,并服从由\(K\)个高斯分布组成的混合高斯分布
- (5) :一个观测值\(\hat x_i\) 的混合高斯分布参数\((u_i^1...,u_i^K,\sigma_i^1,...,\sigma_i^K)\)来自经过函数\(f\)映射的隐层输出\(X_ih_i+b_i\)
- (6) :一个隐层的输入 \(h_i\)与前面 \(i-1\)个随机变量有关
以Autoregressive看Autoencoder与RNN
Autoregressive 的Autoencoder
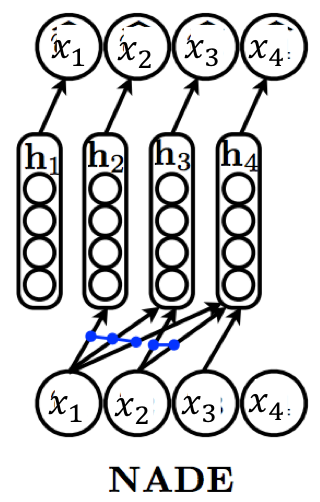
上述提到的FVSBN、NADE、RNADE在建模联合分布时,都假设了第 \(i\) 个随机变量的分布condition on前\(i-1\)个随机变量的值,并服从一个假设分布。 实际上自回归Autoregressive的意思,是指这堆随机变量之间组成一个DAG图,即随机变量之间存在条件独立性的约束,并不存在环。 我们看看Autoencoder的图,与RNADE想比,随机变量\(x_1,x_2,x_3\)之间并无条件独立性假设,而且值输入一次,1个pass,就可以得到三个观测值 \(\hat x_1,\hat x_2,\hat x_3\),但是RNADE的 \(n\) 个观测值 \(\hat x_1,\hat x_2...\hat x_n\),需要值输入\(n\)次,\(n\)个pass,因为第 \(i\) 个观测值取决于前 \(i-1\) 个随机变量 \(x_1,x_2,...,x_{i-1}\)的值。
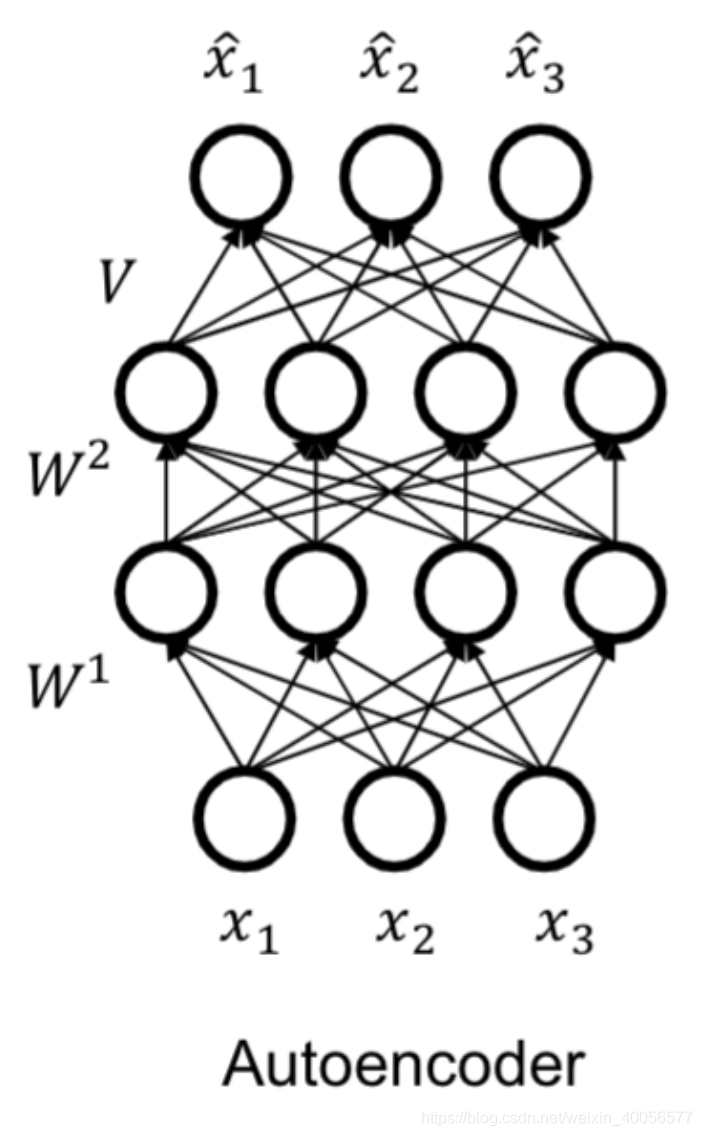
下面简要介绍一下Autoregressive的AutoEncoder,最主要的就是在随机变量之间施加条件独立性假设,具体做法就是通过Masks,如下图:
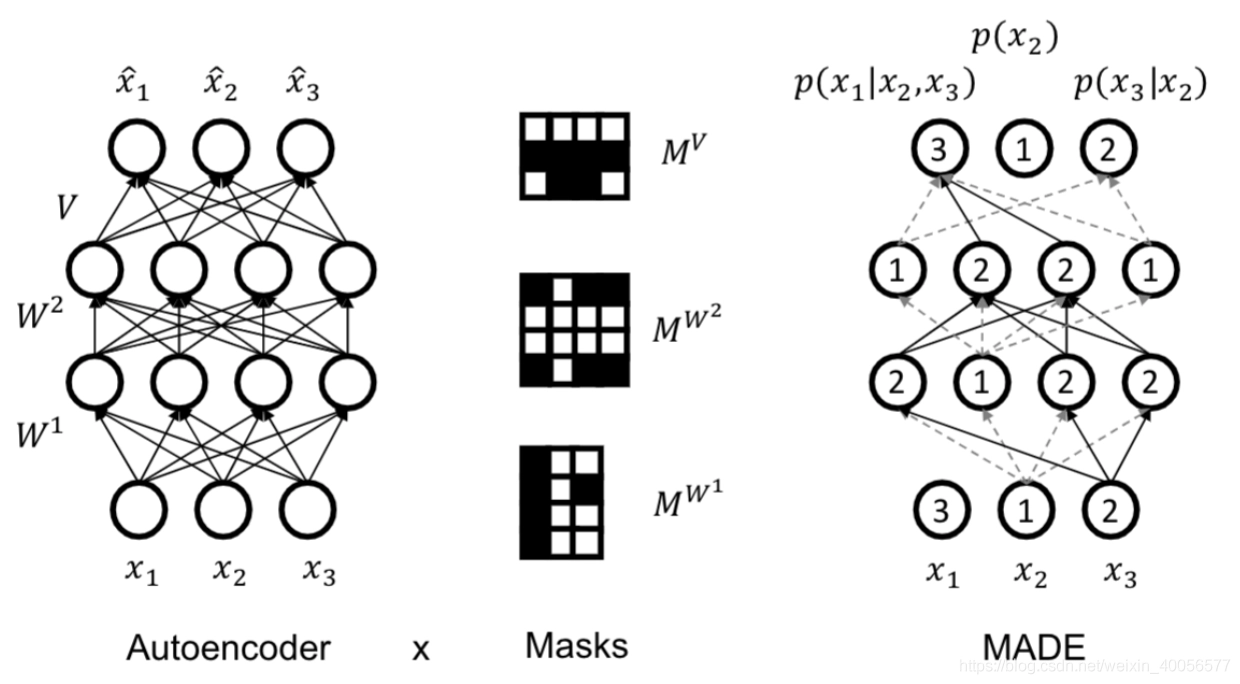
通过固定一个Mask来实现输入层随机变量与隐层之间的条件独立性假设,从而使得输出层的分布参数形成的分布如 \(p(x_3|x_2)\) 带有了Autoregressive的特性。具体可参见这篇文章。 MADE: Masked Autoencoder for Distribution Estimation 2015 jmlr
带有Autoregressive特性的RNN
在上面的模型FVSBN,NADE,RNADE中,建模时有一个问题,即 \(p(x_t|x_{1:t-1};\alpha^t)\) 随着变量个数或者序列长度t的增多,Hitory即 \(x_{1:t-1}\) 一直在变长,造成计算量剧增。
Idea:解决这个histroy随序列变长的问题,就是从一开始就存储一个对History信息进行浓缩的Summary,并且每一次变长都更新这个Summary,就不需要每次都计算一遍历史信息了。
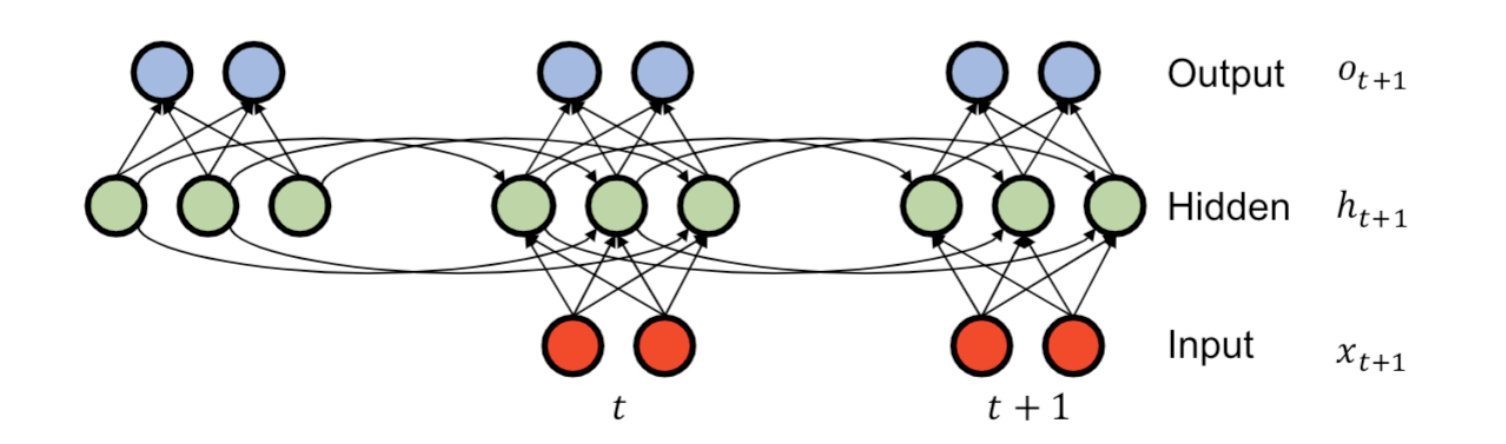
- Summary update:\(h_{t+1}=tanh(W_{hh}h_t+W_{xh}x_{t+1})\)
- Prediction:\(o_{t+1}=W_{hy}h_{t+1}\)
- Summary Initalization:\(h_0=b_0\)
解释一下:
- 第\(t+1\)时刻的Summary = tanh(第\(t\)时刻的Summary+第\(t+1\)时刻的输入)
- 第\(t+1\)时刻的观测值observation = 第\(t+1\)时刻的Summary的变换
- 初始化Summary
一个为什么RNN自带Autoregressive的例子:
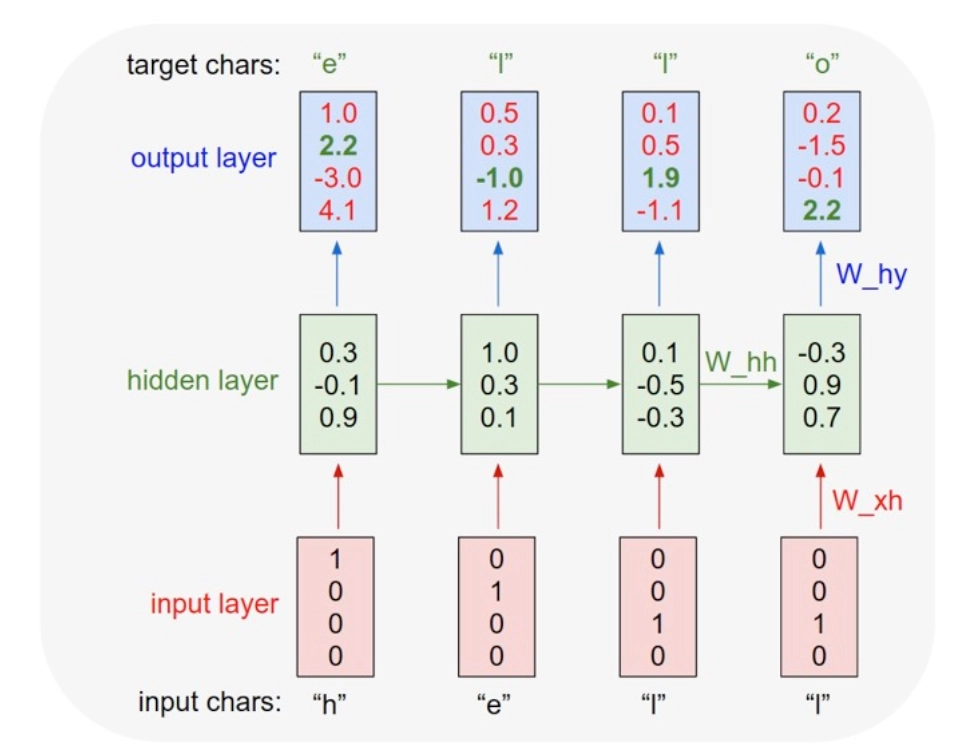
假设随机变量 \(x_i\in\{h,e,l,o\}\), 使用one-hot编码 Autoregressive:
当然除此以外,随机变量 \(x_i\) 的取值可以是word,bi word,也是character,在图像中则为pixel,于是有Pixel RNN,Pixel CNN这样的模型,采用AutoRegressive建模的方式与上述差异不大。
Pixel RNN与Pixel CNN
主要对Image的pixel进行Autoregressive的角度,看看Pixel RNN与Pixel CNN的大致原理,顺便回顾下Autoregressive的Generative Model对一个问题的建模过程。
Pixel RNN
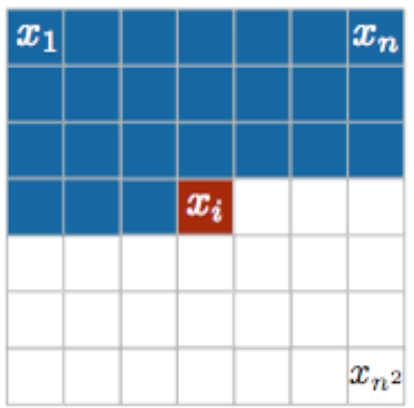
对于一张彩色的图片,假设随机变量条件独立性的顺序ordering,如 \(x_1,x_2,...x_{n^2}\)。Autoregressive总有一个ordering,毕竟是条件独立性
- 先研究变量 \(x_i\) 的取值,因为是彩色图片,所以一个pixel的 \(x_i\) 除了离散的256个灰度值,还有三个通道(R,G,B),所以 \(x_i\in \{0,1,...,255,R,G,B\}\)
- 联合分布有
- 对其建模
其中,\(p(x_t^R|x_{1:t-1}),p(x_t^G|x_{1:t-1},x_t^R),p(x_t^B|x_{1:t-1},x_t^R,x_t^G)\) 均服从一个多项式分布,即\(Cat(p_{R,G,B}^1,...,p_{R,G,B}^{256})\)
- 对于历史信息 \(x_{1:t-1}\) 的处理采用RNN的形式,大致原理如下图所示
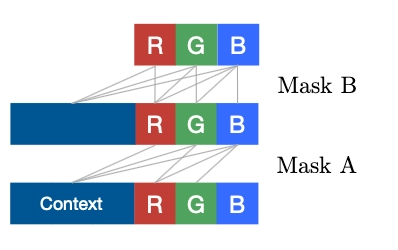
解释一下大意:
- 最底层的context即 \(x_{1:t-1}\) 的历史信息值,作为conditon
- 中间层的R condition on \(x_{1:t-1}\),即 \(p(x_t^R|x_{1:t-1})\)
- 中间层与顶层的G condition on \(x_{1:t-1},x_t^R\) 即 \(p(x_t^G|x_{1:t-1},x_t^R)\)
这三层的意思,是因为使用RNN来避免重复计算历史信息,即进行Summray的update。而Mask的作用在于,限制层间信息传输是服从条件独立性的,区别于Fully Connected。
Pixel CNN
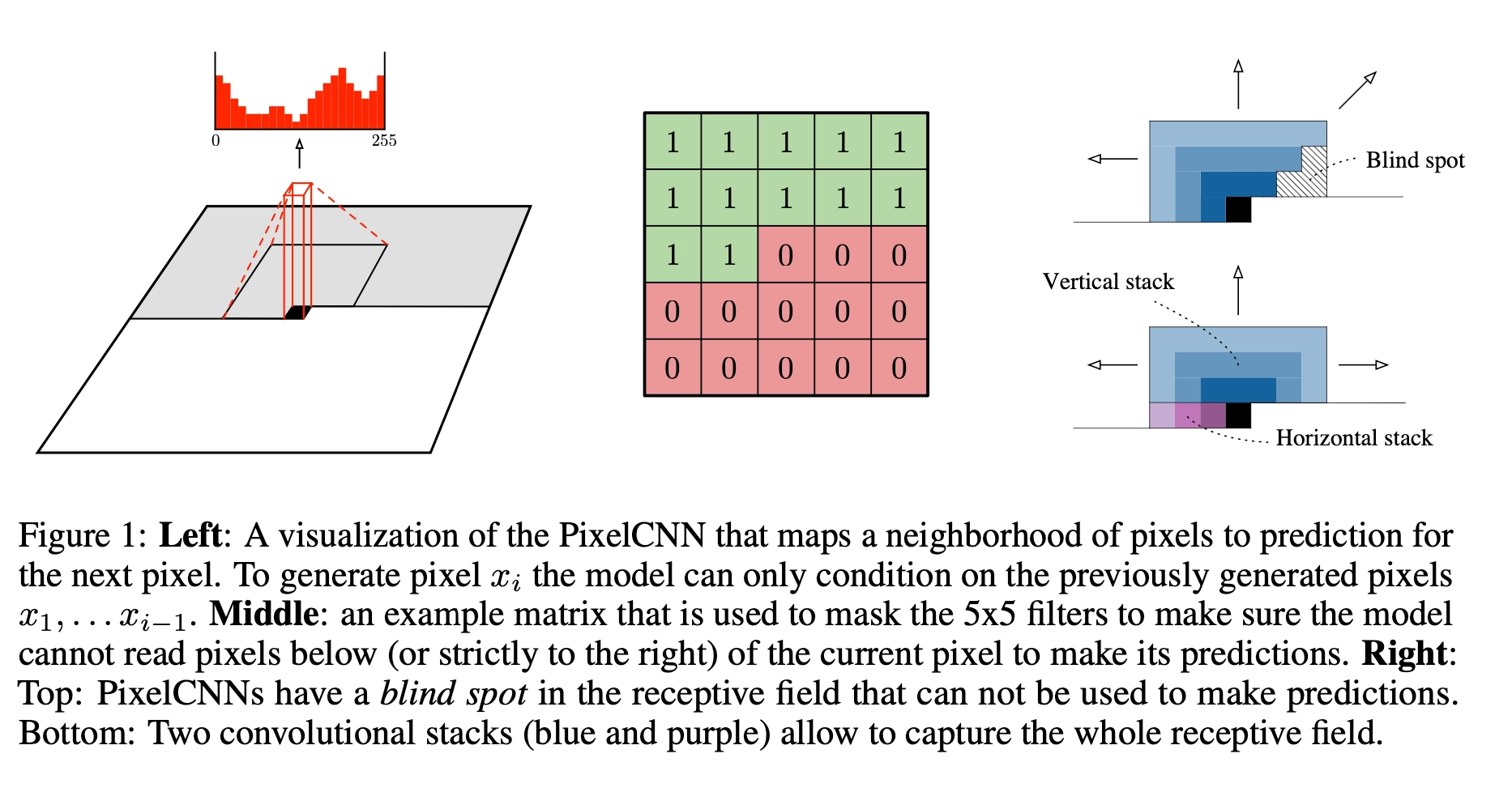
pytorch代码如下
class MaskedCNN(nn.Conv2d):
"""
Implementation of Masked CNN Class as explained in A Oord et. al.
Taken from https://github.com/jzbontar/pixelcnn-pytorch
"""
def __init__(self, mask_type, *args, **kwargs):
self.mask_type = mask_type
assert mask_type in ['A', 'B'], "Unknown Mask Type"
super(MaskedCNN, self).__init__(*args, **kwargs)
self.register_buffer('mask', self.weight.data.clone())
_, depth, height, width = self.weight.size()
self.mask.fill_(1)
if mask_type =='A':
self.mask[:,:,height//2,width//2:] = 0
self.mask[:,:,height//2+1:,:] = 0
else:
self.mask[:,:,height//2,width//2+1:] = 0
self.mask[:,:,height//2+1:,:] = 0
def forward(self, x):
self.weight.data*=self.mask
return super(MaskedCNN, self).forward(x)Pixel CNN与Pixel RNN的区别
- Pixel RNN对联合分布的条件独立性假设是 \(p(x_t|x_1,...,x_{t-1};\alpha^t)\);
Pixel CNN对联合分布的条件独立性假设是 \(p(x_t|x_{neighborhood};\alpha^t)\)
- 如上图所示,对第\(i\) 个pixel的预测,condition on 邻居pixel时,是Pixel CNN;condition on 历史信息 \(x_{1:i-1}\) 的pixels时,是Pixel RNN;
- Pixel CNN与Pixel RNN比效果相当,但计算速度更快。
两者共同点
- 共同的地方就是把随机变量的取值 \(\{0,1,...,255,R,G,B\}\) 分为 \(\{0,1,...,255\}\)与 \(\{R,G,B\}\)两个部分进行处理
- 对conditon on通道\(\{R,G,B\}\)的 \(\{0,1,...,255\}\)采用的都是多项式分布建模,对通道建模处理相同,即
- 实现条件独立性的顺序即condition on的做法,都是采用固定的mask进行,对于Pixel CNN选neighborhood的操作.
Learning and inference
回想一下,学习生成模型涉及优化数据和模型分布之间的接近度。 KL散度是描述数据和模型分布之间接近度的一种常用概念。
KL散度,也就是相对熵。如果我们把熵看成是编码的期望代价的话(近似于最优符号码的期望表示长度),相对熵就是如果我用一个分布来近似另一个分布,那么额外会产生的期望代价。它是不对称的,上面的例子说明了一个比较有意思的现象,这种不对称往往表示了一些蕴含的关系(如果两个值都足够小,而某一个更甚)
由于 \(p_{data }\)不依赖于 \(θ\),我们可以通过最大化似然估计等效地恢复最优参数:
为了近似对未知 \(p_{data}\) 的期望,我们做出一个假设:数据集\(D\)中的点是从\(p_{data}\)中 i.i.d 采样的。 这使我们能够获得目标的无偏蒙特卡罗估计:
最大似然估计 (MLE) 有一个直观的解释:选择模型参数 \(θ∈M\) 使 \(D\) 中观察到的数据点的对数概率最大化。
在实践中,我们使用小批量梯度上升来优化 MLE 目标:
其中,\(r_t\)是第t轮迭代的学习率。通常,我们只指定初始学习率 \(r_1\) 并根据迭代步数更新学习率。
现在我们有了明确定义的目标和优化程序,剩下的唯一任务就是在自回归生成模型的上下文中评估目标。为此,我们在 MLE 目标中替换自回归模型的联合分布以获得
其中 \(θ=\{θ_1,θ_2,…,θ_n\}\) 现在表示条件参数的集合集合。
自回归模型中的推理很简单。对于任意点 \(x\) 的密度估计,我们简单地评估每个 \(i\) 的对数条件概率 \(log\ p_{θ_i}(x_i|x_{<i})\) 并将它们相加以获得模型分配给 x 的对数似然。由于我们知道条件向量 \(x\),因此可以并行评估每个条件。因此,密度估计在现代硬件上是有效的。
从自回归模型中采样是一个顺序过程。在这里,我们首先对 \(x_1\) 进行采样,然后以采样的 \(x_1\) 为条件采样 \(x_2\),然后以 \(x_1\) 和 \(x_2\) 为条件对 \(x_3\) 进行采样,依此类推,直到我们以先前采样的 \(x_{<n}\) 为条件对 \(x_n\) 进行采样。对于需要实时生成高维数据(例如音频合成)的应用程序,顺序采样可能是一个昂贵的过程。
从 KL 到最大似然(MLE)
生成模型涉及优化数据和模型分布之间的接近程度。常用的接近程度概念是数据与模型分布之间的 KL 散度:
两点重要提醒:
- KL 不对称: \( D_{\text{KL}}(p,q) \neq D_{\text{KL}}(q,p)\) ,优化反向 KL 可能带来不同的行为。、
- 强烈惩罚漏覆盖(zero-prob): 若存在 \(x\sim p_{\text{data}}\) 但 \(p_\theta(x)=0\),则目标变为 \(+\infty\)。
因为 \(p_{\text{data}}\) 不依赖 \(\theta\),上述最小化等价于最大化:
数据集 \(D\) 视为 i.i.d. 采样,可用 Monte Carlo 估计:
在实践中,我们使用小批量梯度上升来优化 MLE 目标。该算法以迭代方式运行。每次迭代 \(t\) 取一个 mini-batch \(B_t\),更新:
其中 \(r_t\) 为学习率(可调度)。实践中常用 Adam、RMSProp 等变体。
现在我们已经有了明确的优化目标和优化过程,剩下的唯一任务就是在自回归生成模型的上下文中评估目标。为此,我们把自回归分解代入似然:
因此训练目标变为:
这点非常重要:训练时每个样本的 log-likelihood 可以拆成逐维的条件对数概率之和,实现和优化都很直接。
模型生成和推理
在自回归模型中的推理非常直接。对于任意点 \(x\) 的密度估计,我们只需评估每个 \(i\) 的 log-conditionals \(p(x_i\mid x_{<i})\) ,并将这些值相加,以获得模型分配给 \(x\) 的对数似然。由于我们知道条件向量 \(x\) ,每个条件都可以并行评估。因此,在现代硬件上密度估计是高效的。
但是对于自回归模型的采样生成是串行的
采样必须按顺序进行:
- 先采 \(x_1 \sim p(x_1)\)
- 再采 \(x_2 \sim p(x_2\mid x_1)\)
- …
- 最后采 \(x_n \sim p(x_n\mid x_{<n})\)
因此生成复杂高维数据(如音频)时会很慢。