SD模型原理
SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。
SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。

基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。文生图模型往往参数量比较大,基于pixel的方法往往限于算力只生成64x64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256x256和1024x1024;而基于latent的SD是在latent空间操作的,它可以直接生成256x256和512x512甚至更高分辨率的图像。
SD模型的主体结构如下图所示,主要包括三个模型:
- autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像;
- CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;
- UNet:扩散模型的主体,用来实现文本引导下的latent生成。
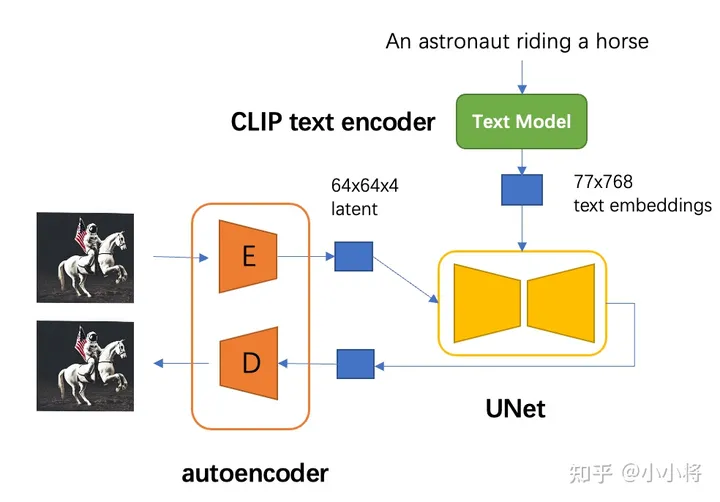
对于SD模型,其autoencoder模型参数大小为84M,CLIP text encoder模型大小为123M,而UNet参数大小为860M,所以SD模型的总参数量约为1B。
autoencoder
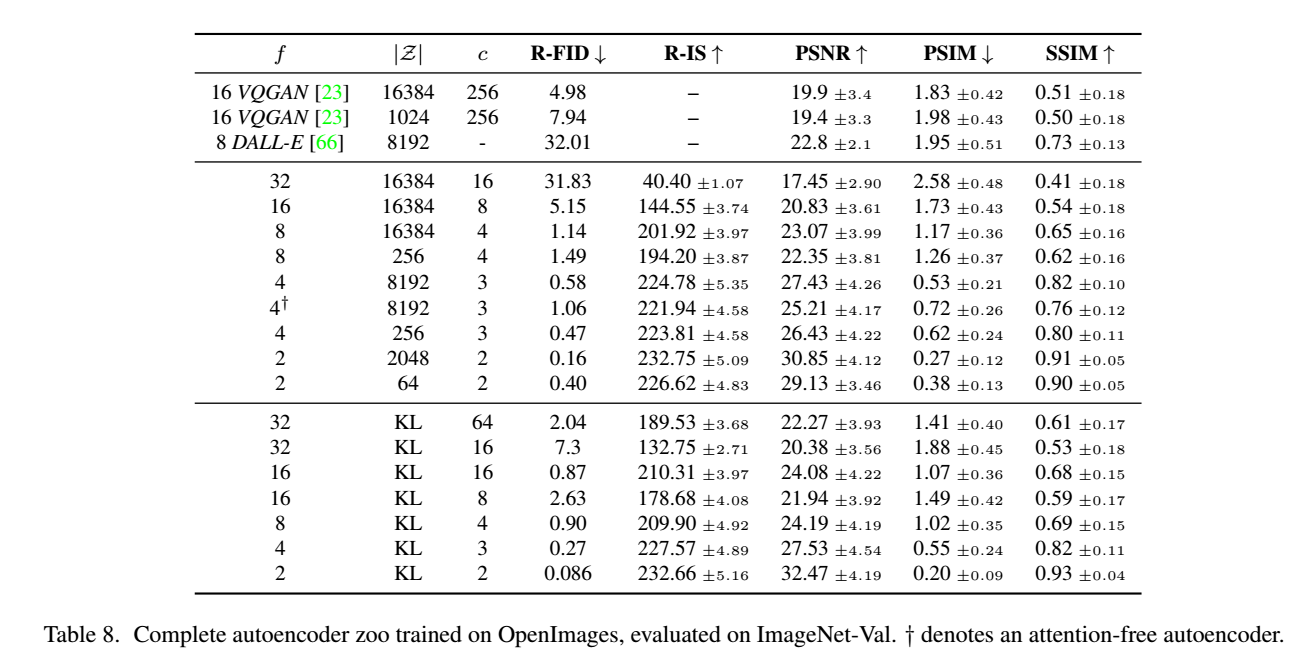
autoencoder是一个基于encoder-decoder架构的图像压缩模型,对于一个大小为\(H\times W \times 3\) 的输入图像,encoder模块将其编码为一个大小为 \(h\times w \times c\) 的latent,其中 \(f=H/h=W/w\) 为下采样率(downsampling factor)。在训练autoencoder过程中,除了采用L1 重建损失外,还增加了感知损失(perceptual loss,即LPIPS,具体见论文The Unreasonable Effectiveness of Deep Features as a Perceptual Metric)以及基于patch的对抗训练。辅助loss主要是为了确保重建的图像局部真实性以及避免模糊,具体损失函数见latent diffusion的loss部分。同时为了防止得到的latent的标准差过大,采用了两种正则化方法:第一种是KL-reg,类似VAE增加一个latent和标准正态分布的KL loss,不过这里为了保证重建效果,采用比较小的权重(~10e-6);第二种是VQ-reg,引入一个VQ (vector quantization)layer,此时的模型可以看成是一个VQ-GAN,不过VQ层是在decoder模块中,这里VQ的codebook采样较高的维度(8192)来降低正则化对重建效果的影响。 latent diffusion论文中实验了不同参数下的autoencoder模型,如下表所示,可以看到当$ f$ 较小和 \(c\) 较大时,重建效果越好(PSNR越大),这也比较符合预期,毕竟此时压缩率小。
论文进一步将不同\(f\) 的autoencoder在扩散模型上进行实验,在ImageNet数据集上训练同样的步数(2M steps),其训练过程的生成质量如下所示,可以看到过小的 \(f\)(比如1和2)下收敛速度慢,此时图像的感知压缩率较小,扩散模型需要较长的学习;而过大的 \(f\) 其生成质量较差,此时压缩损失过大。
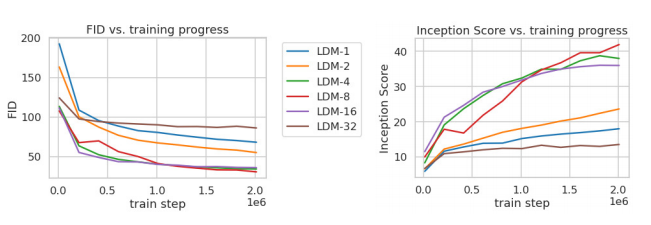
当 \(f\) 在4~16时,可以取得相对好的效果。SD采用基于KL-reg的autoencoder,其中下采样率 \(f=8\)
,特征维度为\(c=4\),当输入图像为512x512大小时将得到64x64x4大小的latent。 autoencoder模型时在OpenImages数据集上基于256x256大小训练的,但是由于autoencoder的模型是全卷积结构的(基于ResnetBlock,只有模型的中间存在两个self attention层),所以它可以扩展应用在尺寸>256的图像上。下面我们给出使用diffusers库来加载autoencoder模型,并使用autoencoder来实现图像的压缩和重建,代码如下所示:
import torch
from diffusers import AutoencoderKL
import numpy as np
from PIL import Image
#加载模型: autoencoder可以通过SD权重指定subfolder来单独加载
autoencoder = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
autoencoder.to("cuda", dtype=torch.float16)
# 读取图像并预处理
raw_image = Image.open("boy.png").convert("RGB").resize((256, 256))
image = np.array(raw_image).astype(np.float32) / 127.5 - 1.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
# 压缩图像为latent并重建
with torch.inference_mode():
latent = autoencoder.encode(image.to("cuda", dtype=torch.float16)).latent_dist.sample()
rec_image = autoencoder.decode(latent).sample
rec_image = (rec_image / 2 + 0.5).clamp(0, 1)
rec_image = rec_image.cpu().permute(0, 2, 3, 1).numpy()
rec_image = (rec_image * 255).round().astype("uint8")
rec_image = Image.fromarray(rec_image[0])
这种有损压缩肯定是对SD的生成图像质量是有一定影响的,不过好在SD模型基本上是在512x512以上分辨率下使用的。为了改善这种畸变,stabilityai在发布SD 2.0时同时发布了两个在LAION子数据集上精调的autoencoder,注意这里只精调autoencoder的decoder部分,SD的UNet在训练过程只需要encoder部分,所以这样精调后的autoencoder可以直接用在先前训练好的UNet上(这种技巧还是比较通用的,比如谷歌的Parti也是在训练好后自回归生成模型后,扩大并精调ViT-VQGAN的decoder模块来提升生成质量)。我们也可以直接在diffusers中使用这些autoencoder,比如mse版本(采用mse损失来finetune的模型):
autoencoder ``**=**`` AutoencoderKL``**.**``from_pretrained("stabilityai/sd-vae-ft-mse/")
由于SD采用的autoencoder是基于KL-reg的,所以这个autoencoder在编码图像时其实得到的是一个高斯分布DiagonalGaussianDistribution(分布的均值和标准差),然后通过调用sample方法来采样一个具体的latent(调用mode方法可以得到均值)。由于KL-reg的权重系数非常小,实际得到latent的标准差还是比较大的,latent diffusion论文中提出了一种rescaling方法:首先计算出第一个batch数据中的latent的标准差 \(\hat \sigma\),然后采用 \(1/\hat \sigma\) 的系数来rescale latent,这样就尽量保证latent的标准差接近1(防止扩散过程的SNR较高,影响生成效果,具体见latent diffusion论文的D1部分讨论),然后扩散模型也是应用在rescaling的latent上,在解码时只需要将生成的latent除以\(1/\hat \sigma\),然后再送入autoencoder的decoder即可。对于SD所使用的autoencoder,这个rescaling系数为0.18215。
CLIP text encoder
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。在transofmers库中,可以如下使用CLIP text encoder:
from transformers import CLIPTextModel, CLIPTokenizer
text_encoder = CLIPTextModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="text_encoder").to("cuda")
# text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda")
tokenizer = CLIPTokenizer.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="tokenizer")
# tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
# 对输入的text进行tokenize,得到对应的token ids
prompt = "a photograph of an astronaut riding a horse"
text_input_ids = text_tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
).input_ids
# 将token ids送入text model得到77x768的特征
text_embeddings = text_encoder(text_input_ids.to("cuda"))[0]
值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。 在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
UNet
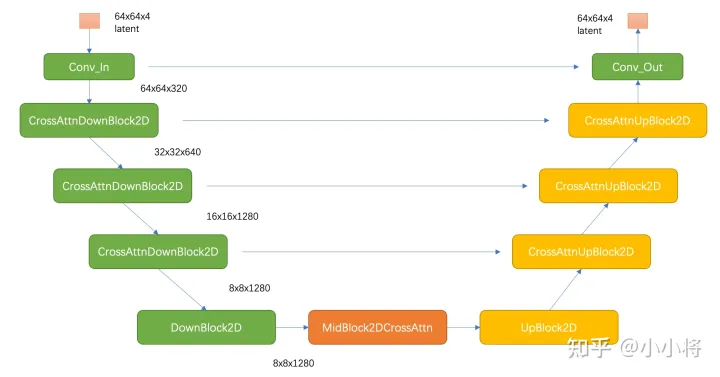
SD的扩散模型是一个860M的UNet,其主要结构如下图所示(这里以输入的latent为64x64x4维度为例),其中encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,而decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,中间还有一个UNetMidBlock2DCrossAttn模块。encoder和decoder两个部分是完全对应的,中间存在skip connection。注意3个CrossAttnDownBlock2D模块最后均有一个2x的downsample操作,而DownBlock2D模块是不包含下采样的。
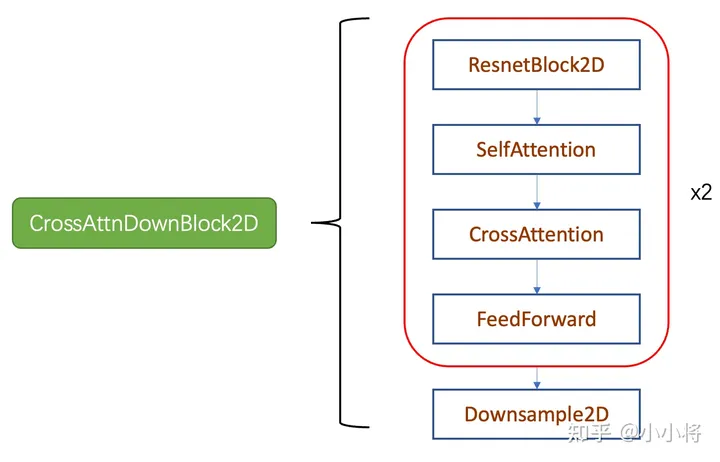
其中CrossAttnDownBlock2D模块的主要结构如下图所示,text condition将通过CrossAttention模块嵌入进来,此时Attention的query是UNet的中间特征,而key和value则是text embeddings。 CrossAttnUpBlock2D模块和CrossAttnDownBlock2D模块是一致的,但是就是总层数为3。
SD和DDPM一样采用预测noise的方法来训练UNet,其训练损失也和DDPM一样:
\(L^{\text{simple}}=\mathbb{E}_{\mathbf{x}_{0},\mathbf{\epsilon}\sim \mathcal{N}(\mathbf{0}, \mathbf{I}), t}\Big[ \| \mathbf{\epsilon}- \mathbf{\epsilon}_\theta\big(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\mathbf{\epsilon}, t, \mathbf{c}\big)\|^2\Big]\)
这里的 \(c\) 为text embeddings,此时的模型是一个条件扩散模型。基于diffusers库,我们可以很快实现SD的训练,其核心代码如下所示(这里参考diffusers库下examples中的finetune代码):
import torch
from diffusers import AutoencoderKL, UNet2DConditionModel, DDPMScheduler
from transformers import CLIPTextModel, CLIPTokenizer
import torch.nn.functional as F
# 加载autoencoder
vae = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
# 加载text encoder
text_encoder = CLIPTextModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="text_encoder")
tokenizer = CLIPTokenizer.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="tokenizer")
# 初始化UNet
unet = UNet2DConditionModel(**model_config) # model_config为模型参数配置
# 定义scheduler
noise_scheduler = DDPMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
)
# 冻结vae和text_encoder
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
opt = torch.optim.AdamW(unet.parameters(), lr=1e-4)
for step, batch in enumerate(train_dataloader):
with torch.no_grad():
# 将image转到latent空间
latents = vae.encode(batch["image"]).latent_dist.sample()
latents = latents * vae.config.scaling_factor # rescaling latents
# 提取text embeddings
text_input_ids = text_tokenizer(
batch["text"],
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
).input_ids
text_embeddings = text_encoder(text_input_ids)[0]
# 随机采样噪音
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# 随机采样timestep
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# 将noise添加到latent上,即扩散过程
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# 预测noise并计算loss
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states=text_embeddings).sample
loss = F.mse_loss(model_pred.float(), noise.float(), reduction="mean")
opt.step()
opt.zero_grad()
注意的是SD的noise scheduler虽然也是采用一个1000步长的scheduler,但是不是linear的,而是scaled linear,具体的计算如下所示:
betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
在训练条件扩散模型时,往往会采用Classifier-Free Guidance(这里简称为CFG),所谓的CFG简单来说就是在训练条件扩散模型的同时也训练一个无条件的扩散模型,同时在采样阶段将条件控制下预测的噪音和无条件下的预测噪音组合在一起来确定最终的噪音,具体的计算公式如下所示:
这里的\(w\) 为guidance scale,当\(w\) 越大时,condition起的作用越大,即生成的图像其更和输入文本一致。CFG的具体实现非常简单,在训练过程中,我们只需要 以一定的概率(比如10%)随机drop掉text即可,这里我们可以将text置为空字符串(前面说过此时依然能够提取text embeddings)。这里并没有介绍CLF背后的技术原理,感兴趣的可以阅读CFG的论文Classifier-Free Diffusion Guidance以及guided diffusion的论文Diffusion Models Beat GANs on Image Synthesis。CFG对于提升条件扩散模型的图像生成效果是至关重要的。
训练细节
前面我们介绍了SD的模型结构,这里我们也简单介绍一下SD的训练细节,主要包括训练数据和训练资源,这方面也是在SD的Model Card上有说明。 首先是训练数据,SD在laion2B-en数据集上训练的,它是laion-5b数据集的一个子集,更具体的说它是laion-5b中的英文(文本为英文)数据集。laion-5b数据集是从网页数据Common Crawl中筛选出来的图像-文本对数据集,它包含5.85B的图像-文本对,其中文本为英文的数据量为2.32B,这就是laion2B-en数据集。
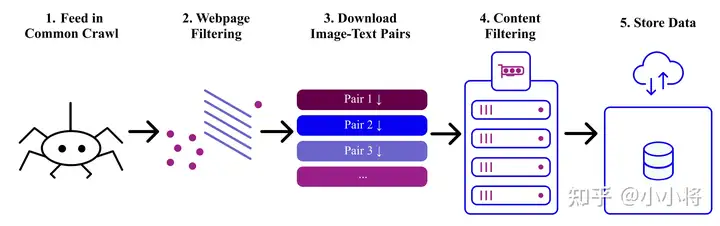
下面是laion2B-en数据集的元信息(图片width和height,以及文本长度)统计分析:其中图片的width和height均在256以上的样本量为1324M,在512以上的样本量为488M,而在1024以上的样本为76M;文本的平均长度为67。
laion数据集中除了图片(下载URL,图像width和height)和文本(描述文本)的元信息外,还包含以下信息:
- similarity:使用CLIP ViT-B/32计算出来的图像和文本余弦相似度;
- pwatermark:使用一个图片水印检测器检测的概率值,表示图片含有水印的概率;
- punsafe:图片是否安全,或者图片是不是NSFW,使用基于CLIP的检测器来估计;
-
AESTHETIC_SCORE:图片的美学评分(1-10),这个是后来追加的,首先选择一小部分图片数据集让人对图片的美学打分,然后基于这个标注数据集来训练一个打分模型,并对所有样本计算估计的美学评分。
上面是laion数据集的情况,下面我们来介绍SD训练数据集的具体情况,SD的训练是多阶段的(先在256x256尺寸上预训练,然后在512x512尺寸上精调),不同的阶段产生了不同的版本: -
SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。 SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),所需要的训练硬件还是比较多的,但是相比语言大模型还好。单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
模型评测
上面介绍了模型训练细节,那么最后的问题就是模型评测了。对于文生图模型,目前常采用的定量指标是FID(Fréchet inception distance)和CLIP score,其中FID可以衡量生成图像的逼真度(image fidelity),而CLIP score评测的是生成的图像与输入文本的一致性,其中FID越低越好,而CLIP score是越大越好。当CFG的gudiance scale参数设置不同时,FID和CLIP score会发生变化,下图为不同的gudiance scale参数下,SD模型在COCO2017验证集上的评测结果,注意这里是zero-shot评测,即SD模型并没有在COCO训练数据集上精调。
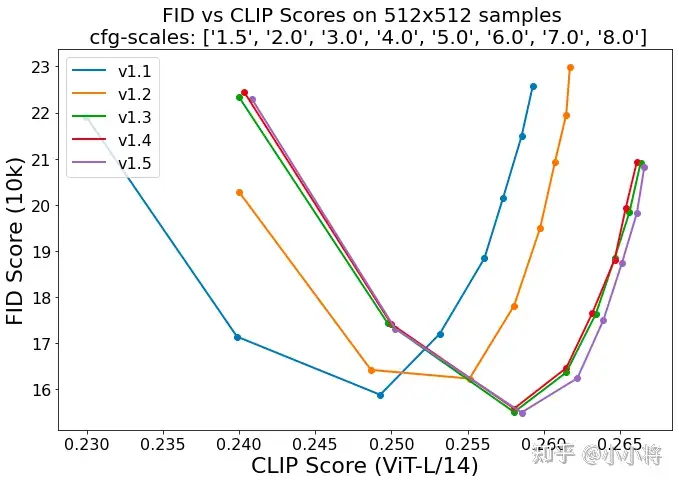
可以看到当gudiance scale=3时,FID最低;而当gudiance scale越大时,CLIP score越大,但是FID同时也变大。在实际应用时,往往会采用较大的gudiance scale,比如SD模型默认采用7.5,此时生成的图像和文本有较好的一致性。从不同版本的对比曲线上看,SD的采用CFG训练后三个版本其实差别并没有那么大,其中SD v1.5相对好一点,但是明显要比未采用CFG训练的版本要好的多,这说明CFG训练是比较关键的。 目前在模型对比上,大家往往是比较不同模型在COCO验证集上的zero-shot FID-30K(选择30K的样本),大家往往就选择模型所能得到的最小FID来比较,下面为eDiff和GigaGAN两篇论文所报道的不同文生图模型的FID对比(由于SD并没有给出FID-30K,所以大家应该都是自己用开源SD的模型计算的,由于选择样本不同,可能结果存在差异):
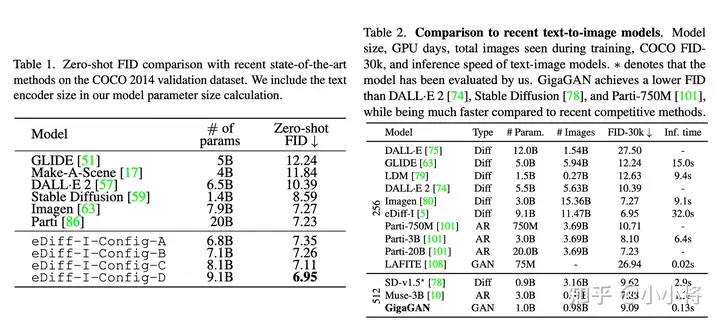
可以看到SD虽然FID不是最好的,但是也能达到比较低的FID(大约在8~9之间)。不过虽然学术界常采用FID来定量比较模型,但是FID有很大的局限性,它并不能很好地衡量生成图像的质量,也是因为这个原因,谷歌的Imagen引入了人工评价,先建立一个评测数据集DrawBench(包含200个不同类型的text),然后用不同的模型来生成图像,让人去评价同一个text下不同模型生成的图像,这种评测方式比较直接,但是可能也受一些主观因素的影响。总而言之,目前的评价方式都有一定的局限性,最好还是直接上手使用来比较不同的模型。
SD的主要应用
下面来介绍SD的主要应用,这包括文生图,图生图以及图像inpainting。其中文生图是SD的基础功能:根据输入文本生成相应的图像,而图生图和图像inpainting是在文生图的基础上延伸出来的两个功能。
文生图
根据文本生成图像这是文生图的最核心的功能,下图为SD的文生图的推理流程图:首先根据输入text用text encoder提取text embeddings,同时初始化一个随机噪音noise(latent上的,512x512图像对应的noise维度为64x64x4),然后将text embeddings和noise送入扩散模型UNet中生成去噪后的latent,最后送入autoencoder的decoder模块得到生成的图像。
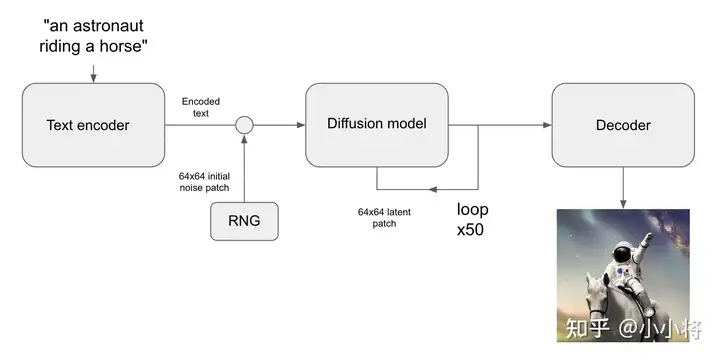
使用diffusers库,我们可以直接调用StableDiffusionPipeline来实现文生图,具体代码如下所示:
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# 组合图像,生成grid
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
# 加载文生图pipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", # 或者使用 SD v1.4: "CompVis/stable-diffusion-v1-4"
torch_dtype=torch.float16
).to("cuda")
# 输入text,这里text又称为prompt
prompts = [
"a photograph of an astronaut riding a horse",
"A cute otter in a rainbow whirlpool holding shells, watercolor",
"An avocado armchair",
"A white dog wearing sunglasses"
]
generator = torch.Generator("cuda").manual_seed(42) # 定义随机seed,保证可重复性
# 执行推理
images = pipe(
prompts,
height=512,
width=512,
num_inference_steps=50,
guidance_scale=7.5,
negative_prompt=None,
num_images_per_prompt=1,
generator=generator
).images
grid = image_grid(images, rows=1, cols=4)
生成的图像效果如下所示:

参数一: 分辨率
这里可以通过指定width和height来决定生成图像的大小,前面说过SD最后是在512x512尺度上训练的,所以生成512x512尺寸效果是最好的,但是实际上SD可以生成任意尺寸的图片:一方面autoencoder支持任意尺寸的图片的编码和解码,另外一方面扩散模型UNet也是支持任意尺寸的latents生成的(UNet是卷积+attention的混合结构)。然而,生成512x512以外的图片会存在一些问题,比如生成低分辨率图像时,图像的质量大幅度下降,下图为同样的文本在256x256尺寸下的生成效果:

如果是生成512x512以上分辨率的图像,图像质量虽然没问题,但是可能会出现重复物体以及物体被拉长的情况,下图为分别为768x512和512x768尺寸下的生成效果,可以看到部分图像存在一定的问题:


所以虽然SD的架构上支持任意尺寸的图像生成,但训练是在固定尺寸上(512x512),生成其它尺寸图像还是会存在一定的问题。解决这个问题的办法就相对比较简单,就是采用多尺度策略训练,比如NovelAI提出采用Aspect Ratio Bucketing策略来在二次元数据集上精调模型,这样得到的模型就很大程度上避免SD的这个问题,目前大部分开源的基于SD的精调模型往往都采用类似的多尺度策略来精调。比如我们采用开源的dreamlike-diffusion-1.0模型(基于SD v1.5精调的),其生成的图像效果在变尺寸上就好很多:


参数二:推理时间步数
另外一个参数是num_inference_steps,它是指推理过程中的去噪步数或者采样步数。SD在训练过程采用的是步数为1000的noise scheduler,但是在推理时往往采用速度更快的scheduler:只需要少量的采样步数就能生成不错的图像,比如SD默认采用PNDM scheduler,它只需要采样50步就可以出图。当然我们也可以换用其它类型的scheduler,比如DDIM scheduler和DPM-Solver scheduler。我们可以在diffusers中直接替换scheduler,比如我们想使用DDIM:
from diffusers import DDIMScheduler
# 注意这里的clip_sample要关闭,否则生成图像存在问题,因为不能对latent进行clip
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config, clip_sample=False)
换成DDIM后,同样的采样步数生成的图像如下所示,在部分细节上和PNDM有差异:

当然采样步数越大,生成的图像质量越好,但是相应的推理时间也更久。这里我们可以试验一下不同采样步数下的生成效果,以宇航员骑马为例,下图展示了采样步数为10,20,30,50,70和100时的生成图像,可以看到采样步数增加后,图像生成质量是有一定的提升的,当采样步数为30时就能生成相对稳定的图像。

参数三: guidance_scale
我们要讨论的第三个参数是guidance_scale,前面说过当CFG的guidance_scale越大时,生成的图像应该会和输入文本更一致,这里我们同样以宇航员骑马为例来测试不同guidance_scale下的图像生成效果。下图为guidance_scale为1,3,5,7,9和11下生成的图像对比,可以看到当guidance_scale较低时生成的图像效果是比较差的,当guidance_scale在7~9时,生成的图像效果是可以的,当采用更大的guidance_scale比如11,图像的色彩过饱和而看起来不自然,所以SD默认采用的guidance_scale为7.5。

过大的guidance_scale之所以出现问题,主要是由于训练和测试的不一致,过大的guidance_scale会导致生成的样本超出范围。谷歌的Imagen论文提出一种dynamic thresholding策略来解决这个问题,所谓的dynamic thresholding是相对于原来的static thresholding,static thresholding策略是直接将生成的样本clip到[-1, 1]范围内(Imagen是基于pixel的扩散模型,这里是将图像像素值归一化到-1到1之间),但是会在过大的guidance_scale时产生很多的饱含像素点。而dynamic thresholding策略是先计算样本在某个百分位下(比如99%)的像素绝对值\(s\),然后如果它超过1时就采用\(s\)来进行clip,这样就可以大大减少过饱和的像素。两种策略的具体实现代码如下所示:

dynamic thresholding策略对于Imagen是比较关键的,它使得Imagen可以采用较大的guidance_scale来生成更自然的图像。下图为两种thresholding策略下生成图像的对比:

虽然SD是基于latent的扩散模型,但依然可以采用类似的dynamic thresholding策略,感兴趣的可以参考目前的一个开源实现:sd-dynamic-thresholding,使用dynamic thresholding策略后,SD可以在较大的guidance_scale下生成相对自然的图像。
