这是OpenCompass的offitial ranking 榜单
🔖 https://rank.opencompass.org.cn/home

MMBench
鉴于现行评测方式所存在的问题,我们重新定义了一套针对当前多模态大模型的评测流程——MMBench。其主要包含两个方面:
- 自上而下的能力维度设计,根据定义的能力维度构造了一个评测数据集
- 引入 ChatGPT,以及提出了 CircularEval 的评测方式,使得评测的结果更加稳定
Paper 链接:
🔖 https://arxiv.org/pdf/2307.06281
github:
数据集
数据集构造
主要目的是对模型的各种能力进行全方位的考察,所以我们自上而下定义了三级能力维度 (L1-L3),
- 第一级维度(L1)包含感知与推理两项能力,
- 第二级能力维度(L2) 在第一级的能力维度下进行拓展,包含 6 项能力,
- 最后第三级能力维度(L3)进一步在第二级能力维度的基础上进行拓展,包含 20 个能力维度
各级能力维度的包含关系如下图所示:
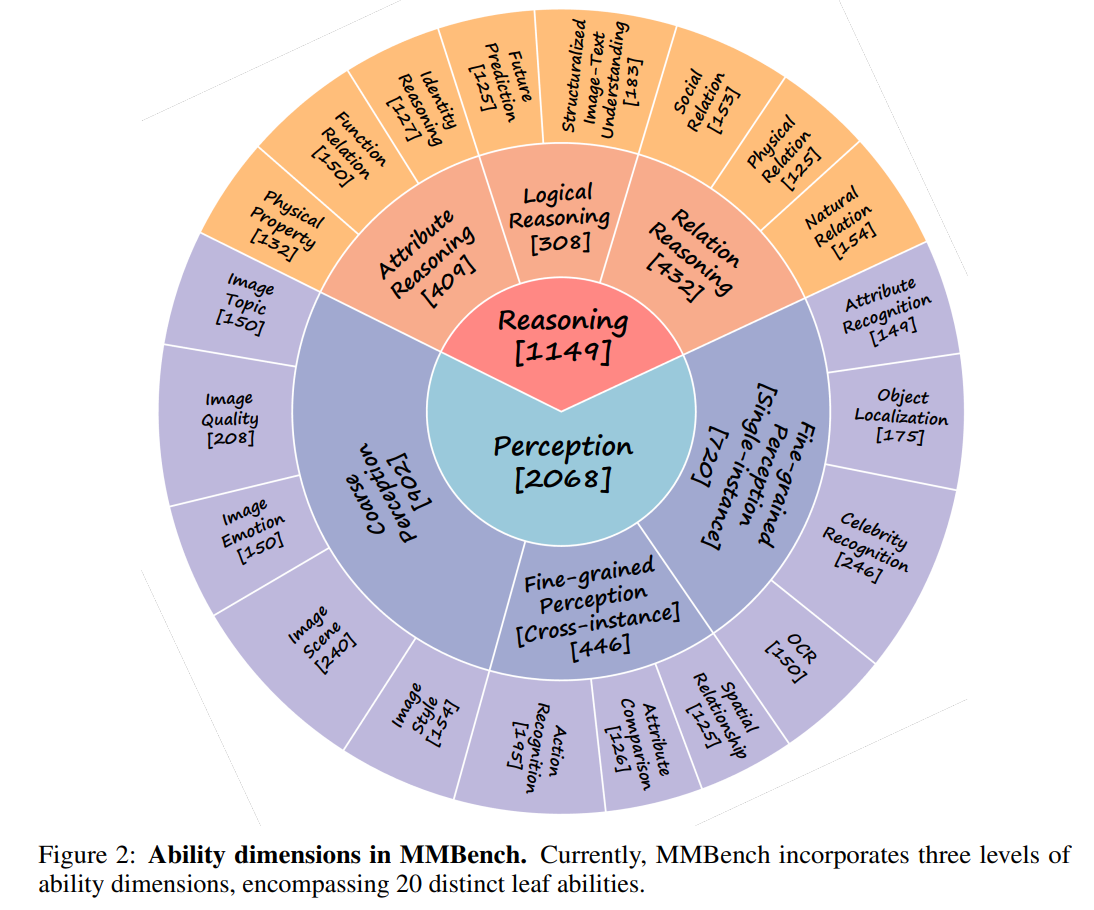
针对每一项 L3 能力,我们进行了相关问题的收集,为了保证评估的结果更稳定全面,针对每一项 L3 能力我们都收集了超过 75 题,具体的数量分布如上图所示,括号里面显示了该项能力维度下有多少道题目。目前我们的评测集总共包含 2974 道题目。我们收集的数据集,问题,题目的来源分布十分广泛,下表列出了所有来源。
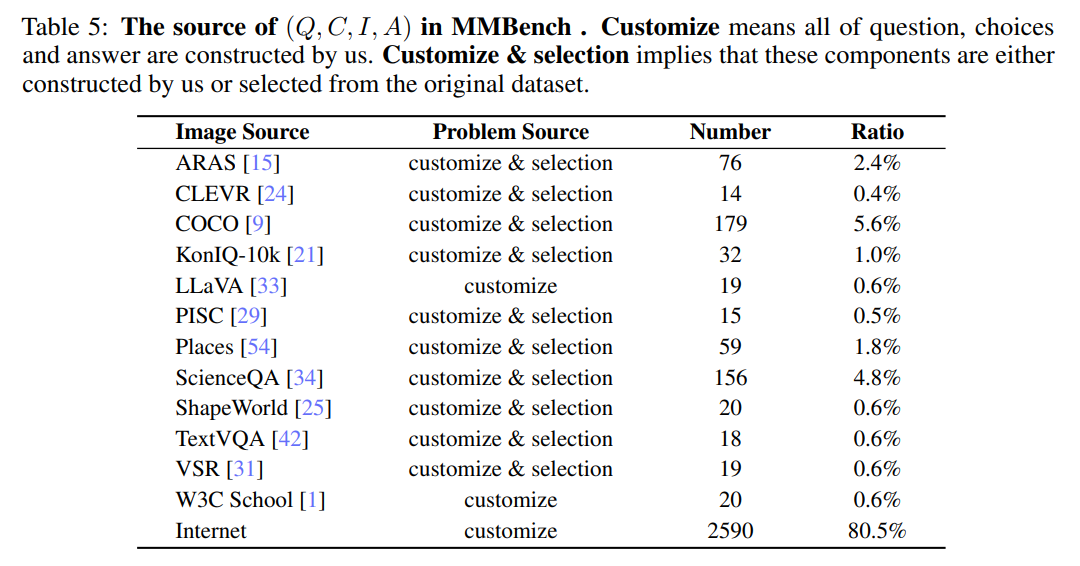
尽管,我们有些题目、图片来源于一些公开数据集,例如 COCO-Caption、ScienceQA,但是这些题目来源于 test 集合,并且这些题目的总数占总题目数的比例大概在 10% 左右,所以在我们这个数据集上的评测仍然可以看作是 held-out 评测。
题目展示
为了简化评测流程,我们将所有的题目都设计为单项选择形式,下图展示了我们评测数据集中的一些题目:
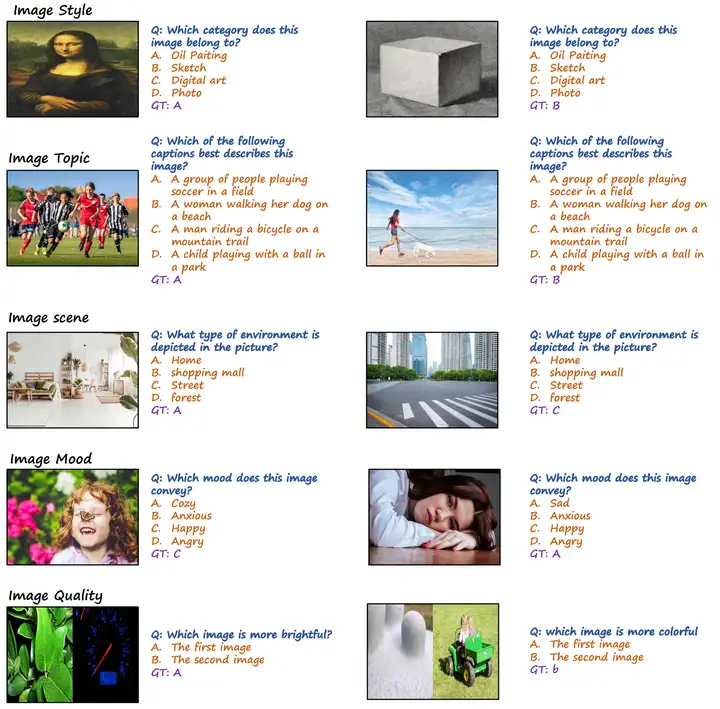
你可以参考我们的论文,以及数据集查看更多的数据样例。
评测方式
对于单项选择题,我们期待模型能够直接输出 A, B, ... 中的一个 label,但是由于现在开源模型的指令跟随性并不完善。在实验中我们发现,大部分情况下,模型的输出往往不直接是,甚至根本不包含选项的 label。这对我们的评测带来了很大的困扰。针对这个问题,我们提出了利用 ChatGPT 来辅助我们评测,针对某一题,具体的流程如下:
- 首先,如果可以从模型的输出中直接提取出选项的 label,那么我们就直接把提取出来的选项的 label 作为模型的回答
- 如果我们不能从模型的输出中提取出选项的 label,我们就会利用 ChatGPT 去找到选项中和模型输出最相似的选择,并输出该选项的 label 作为模型的回答
- 如果模型发现模型的输出无法和任何选项进行匹配,就直接输出一个 pseudo label 'X' 来表示模型无法回答此题 (该步骤仅为提升流程的完善性,事实上,评测过程中从未来到这一流程节点)
下图展示了我们提供给 ChatGPT 的 prompt:

同时,为了衡量 ChatGPT 来辅助打分的可靠性,我们做了进一步的实验。
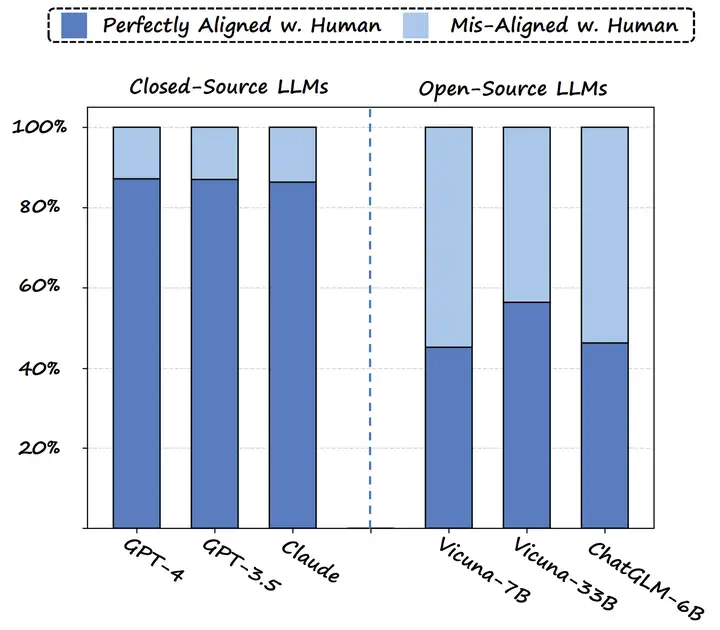
上图比较了各种模型来辅助打分与人类打分的相似程度,可以发现 GPT-4 和 GPT-3.5 与人类打分具有较高的相似度,同时 GPT-4 和 GPT-3.5 的打分效果类似,所以考虑到成本,我们便选取了 GPT-3.5 作为了我们的打分器。
除此之外,为了尽可能消除随机性以及让评测结果更 robust,我们提出了 CircularEval。CircularEval 的主要思想就是将问题选项按环状进行重排,然后将每次重排之后的选项提供给多模态模型,当且仅当每次模型都回答正确了,我们才认为模型成功回答该题,具体流程如下:

同时我们也进一步比较了 CircularEval 和 常规评测 (VanillaEval) 在评测结果上面的区别:
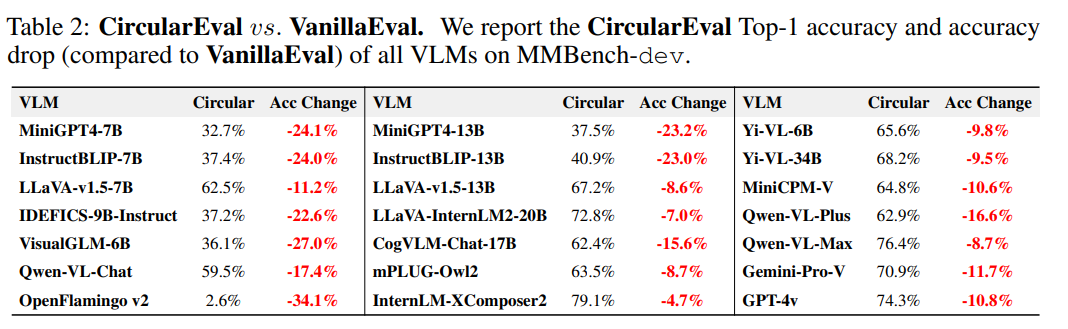
可以发现 CircularEval 下模型的性能出现了显著的降低,更好地体现出了多模态模型的真实性能。
MMMU
主页链接:
🔖 https://mmmu-benchmark.github.io/
总体结论
MMMU基准测试的几个亮点:
- 精心收集了来自大学考试、测验和教科书的11.5K个多模态问题
- 跨越艺术与设计、商业、科学、健康医学、人文社会科学、技术工程等30个学科和183个子领域
- 包含30种异构的图像类型,如图表、图示、地图、表格、乐谱和化学结构式
-
关注特定领域知识的高级感知和推理
评估了14个开源模型和GPT4-Vision的结果和启示: -
MMMU基准对现有大语言模型是一个巨大的挑战: GPT4V的准确率只有56%,显示了言语模型进一步发展的广阔前景
- 开源语言模型还有很长的路要走。如BLIP2-FLAN-T5-XXL和 LLaVA-1.5的准确率只有34%左右
- MMMU中加入OCR和图像字幕对语言模型帮助很小,突出了更深层次的图像文本联合理解的需要
- 模型在照片和绘画上的表现优于图表和表格,后两者包含了更细微和复杂的视觉信息
- 对GPT-4V的150个错误案例分析显示,35%的错误源自感知,29%是由于知识不足,26%则是推理过程的缺陷
该数据集评估这些模型不仅能够感知和理解不同模式的信息,而且能够应用特定主题的知识进行推理来得出解决方案。此外, MMMU中的许多问题需要专家级推理,例如应用“傅立叶变换”或“平衡理论”来推导解决方案,因此满足了深度目标。

eval代码
参考官方给出的步骤
🔖 https://github.com/MMMU-Benchmark/MMMU/tree/main/eval
- 选择题
- 这里应该是问非选项的问题, 去匹配字符串
最终的输出文件格式如下:
[
{
"id": "validation_Electronics_28",
"question_type": "multiple-choice",
"answer": "A", # given answer
"all_choices": [ # create using `get_multi_choice_info` in
"A",
"B",
"C",
"D"
],
"index2ans": { # create using `get_multi_choice_info` in
"A": "75 + 13.3 cos(250t - 57.7°)V",
"B": "75 + 23.3 cos(250t - 57.7°)V",
"C": "45 + 3.3 cos(250t - 57.7°)V",
"D": "95 + 13.3 cos(250t - 57.7°)V"
},
"response": "B" # model response
},
{
"id": "validation_Electronics_29",
"question_type": "short-answer",
"answer": "30", # given answer
"response": "36 watts" # model response
},
...
]
MMStar
项目主页:
🔖 https://mmstar-benchmark.github.io/
对于大多数评估集中图像重要吗?
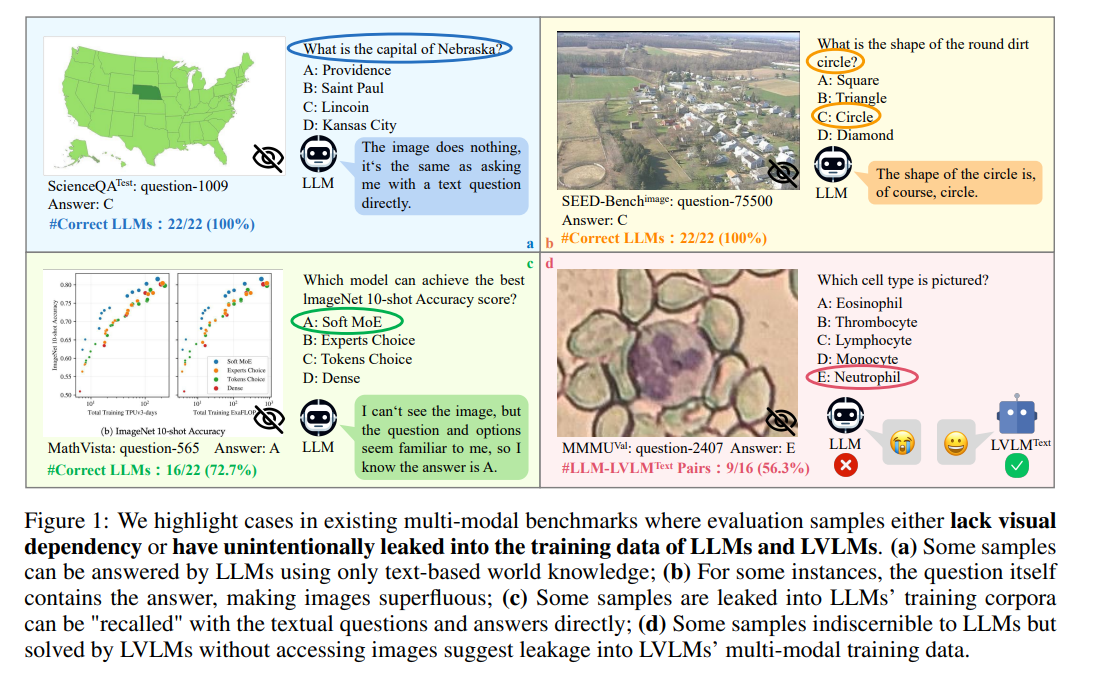
一些语言大模型和多模态大模型竟然能在没有看到图片的情况下正确回答出一些视觉问答题目。研究者们发现闭源语言大模型GeminiPro和开源语言大模型Qwen1.5-72B在极具挑战性的MMMU基准上竟然只根据问题和选项就可以分别取得42.7和42.4的惊人成绩,并且开源多模态大模型Yi-VL-34B以及LLaVA-Next-34B在不看图的情况下也可以取得37.3和40.4的成绩,一度逼近GeminiPro-Vision (44.4)等翘楚LVLM在看到图片情况下的表现。下图就说明了有些数据集中存在的问题,图可有可无
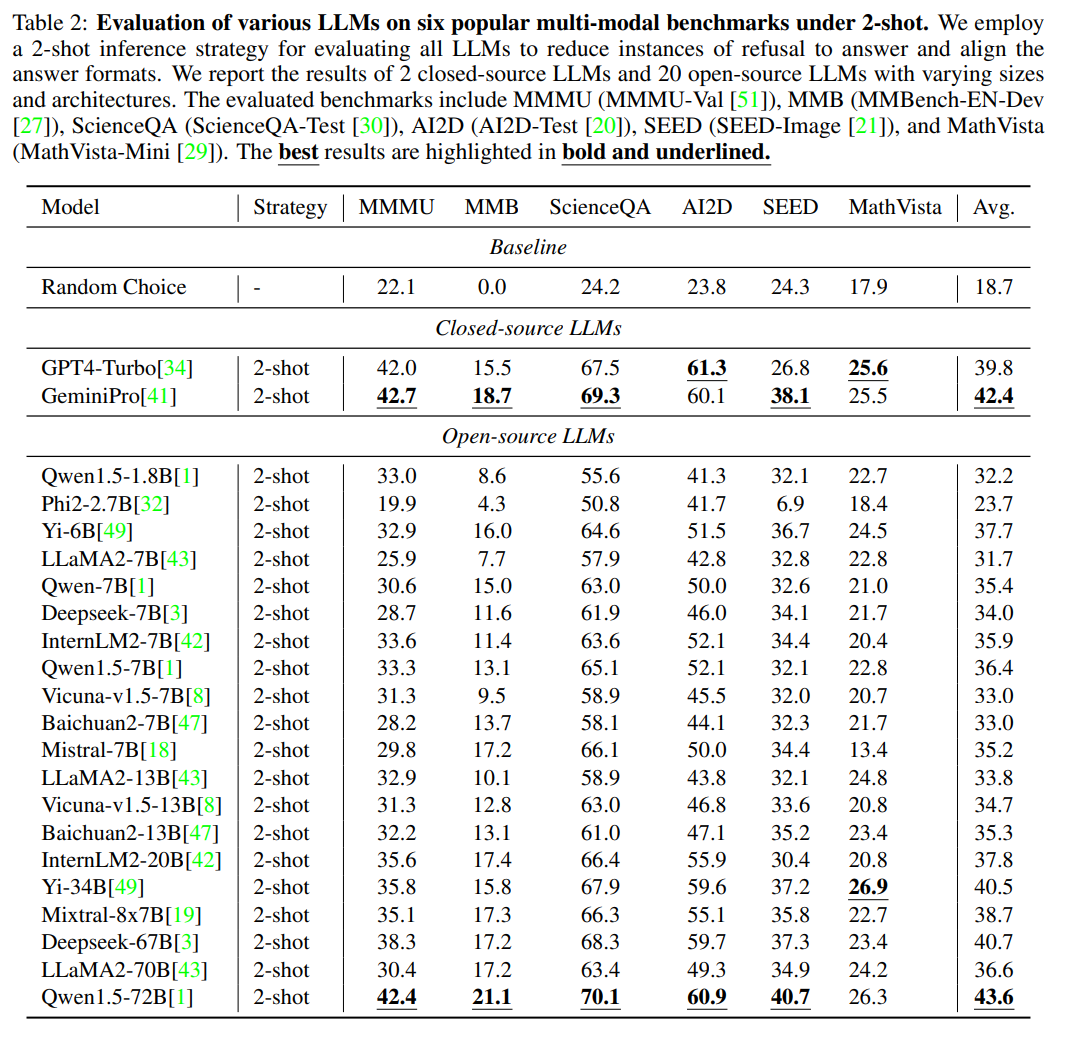
文章也评估了LLM模型在主流的多模态数据集上的评估效果, 并且发现2-shot的的方式评估效果会更加稳定, 如下表2所示,闭源模型GeminiPro和开源模型Qwen1.5-72B在极具挑战性的MMMU基准上可以分别取得42.7和42.4的惊人成绩,一度逼近GeminiPro-Vision (44.4),LLaVA-Next-34B (47.0)和Yi-VL-34B (43.2)等翘楚LVLM在能看到图片情况下的表现
LVM和LLM训练存在数据泄露问题
研究者们做了一个有趣的实验来定量观察LVLMs在其多模态训练过程中的数据泄露情况。具体而言,研究者们除了使用LVLM正常评估,使用LLM只根据文本问题进行选项评估,还额外屏蔽了LVLM的图片输入从而只根据文本问题和选项来进行评估(标记为LVLM-text)。
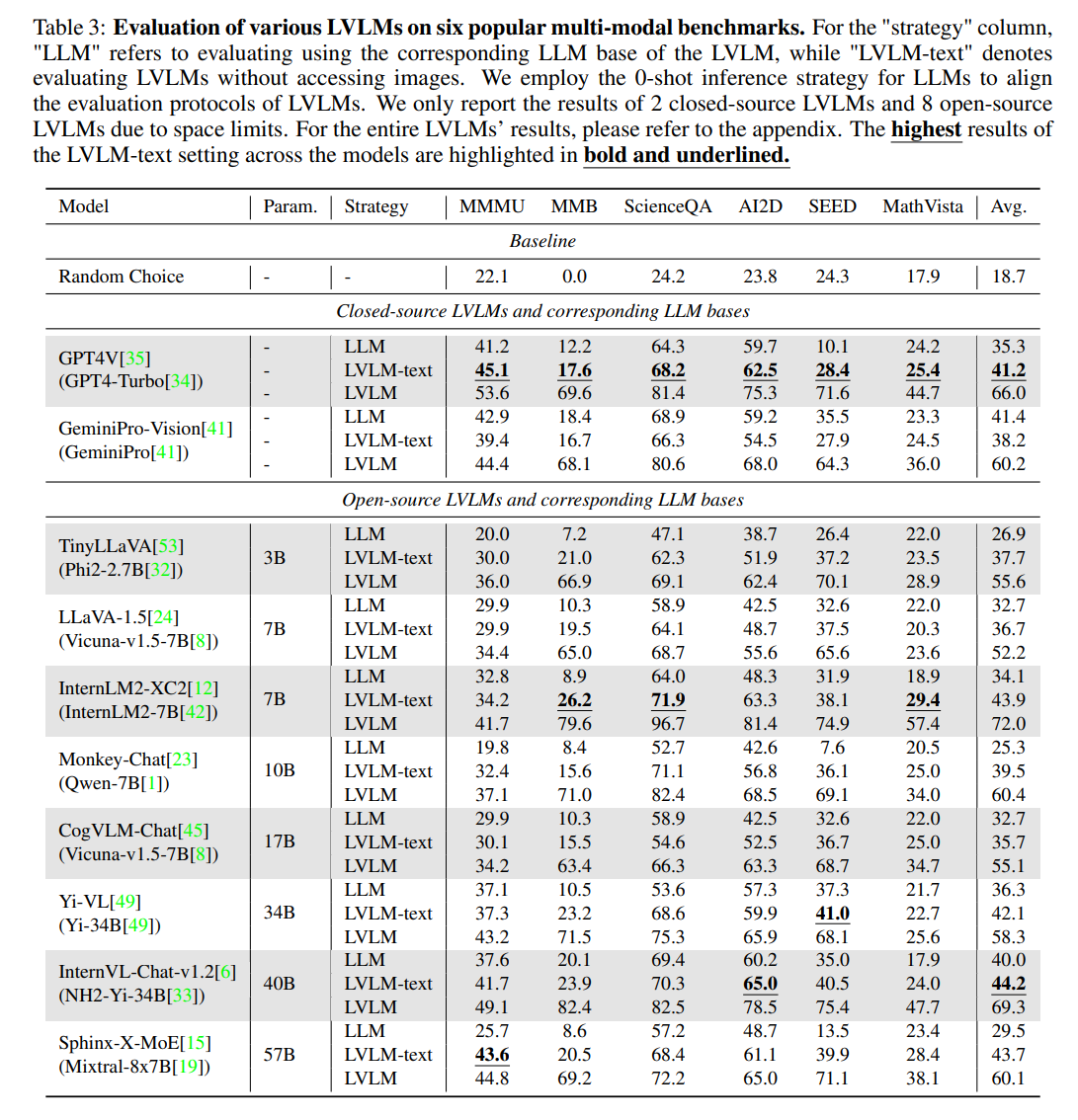
在这样的实验设定下,可以根据LVLM-text相对于LLM的性能提升来反映出存在着一些本身LLM不看图做不对但经过多模训练后的LVLM不看图竟然又能做对的题目。这暗示着LVLM在多模态训练过程中存在着一定程度的数据泄露。比如,Sphinx-X-MoE和Monkey-Chat经过多模态训练后在不看图的情况下相比原始LLMs在MMMU基准上可以分别提升惊人的17.9和12.6,而它们即使进一步在看到图片的情况下也只能获得1.2和4.7的性能提升。这无疑是社区在评估LVLM时不想看到情况。下图中则展示出了一些可能被泄露在了LVLM的多模态训练数据中的评估样本

MMStar数据
根据存在的问题, MMStar建立了自己数据集的标准:Visual dependency、Minimal data leakage、Requiring advanced multi-modal capabilities for resolution
展示核心能力:
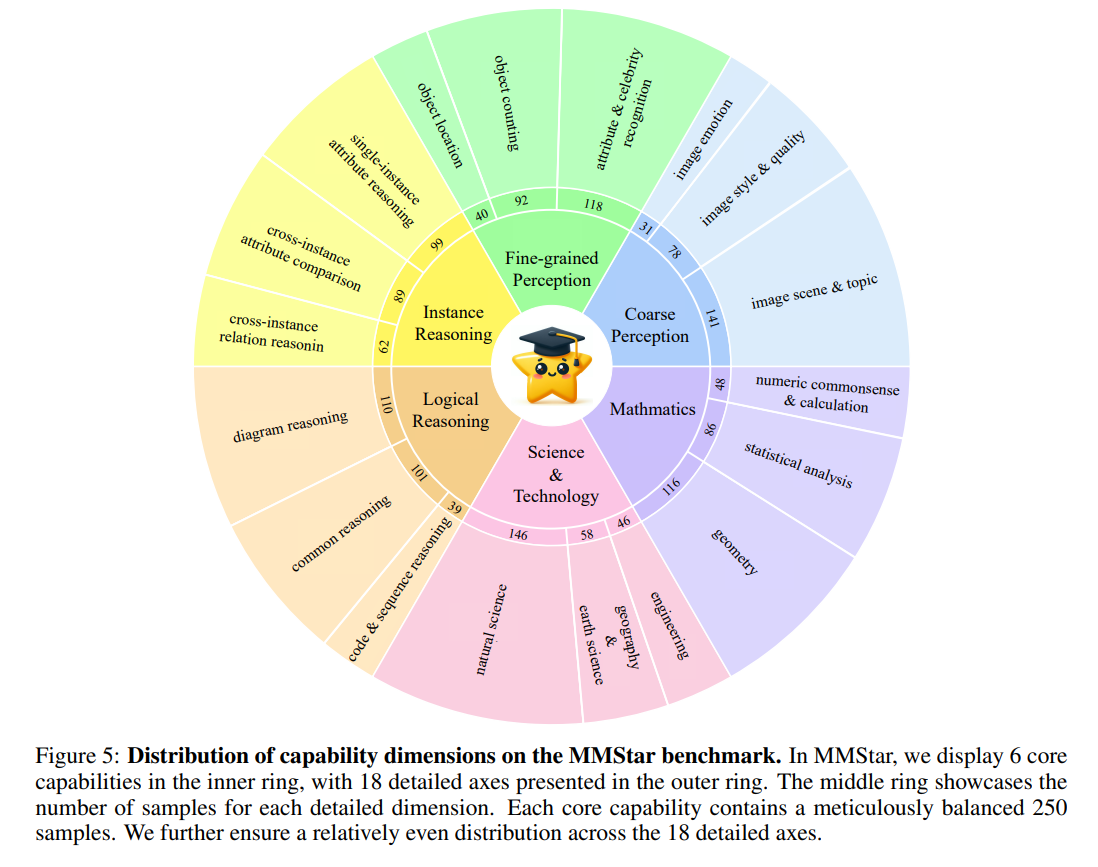
还提出了multi-modal gain (MG)和 multi-modal leakage (ML)两个评估指标来反映出LVLMs在多模训练过程中的真实性能增益和数据泄露程度。
其中\(S_v\), \(S_{wv}\)代表有没有视觉输入的结果
\(S_t\)是对应LLM的评估结果
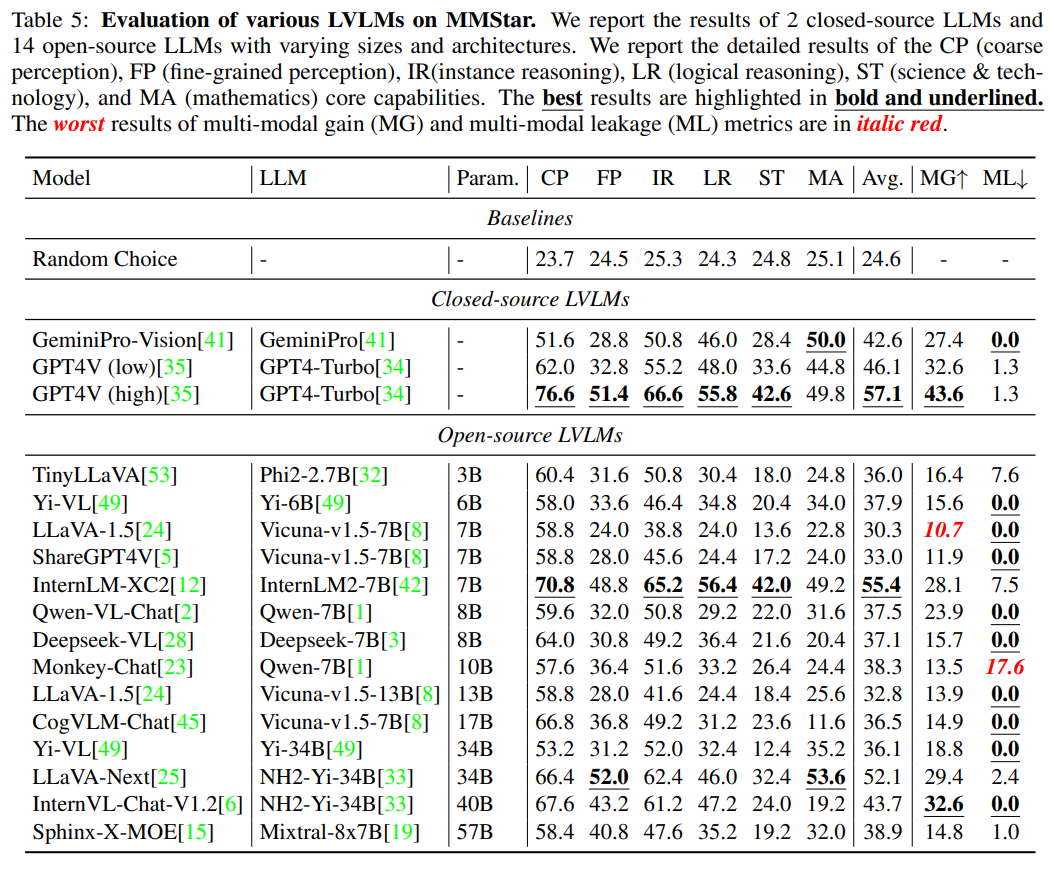
下表展示了一些评测结果
MM-Vet
github地址:
论文:
🔖 https://arxiv.org/pdf/2308.02490
数据构建
MM-Vet 定义了 6 个核心 VL 功能:识别、OCR、知识、语言生成、空间感知和数学计算,并检查了从功能组合中得出的 16 个感兴趣的集成。MM-Vet需要将这些能力的多个组合,并进行综合判断。
比如下图中d, MM-Vet中需要识别三个孩子的性别,在空间上定位被查询的女孩,识别女孩写的场景文本,最后计算结果。
