UI-TARS
简介
UI-TARS(User Interface - Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型:
- 输入方式:仅使用屏幕截图作为视觉输入
- 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等)
-
模型特性:端到端的原生智能体模型,无需复杂的中间件或框架
传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: -
平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。
- 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。
- 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。
- 模块化架构:许多现有的 GUI 系统采用模块化框架,将不同功能分配给不同的组件,例如视觉语言模型(VLM)负责理解和推理,而其他模块则负责接地或记忆。这种架构依赖于人工设计和专家知识,难以扩展和适应新的环境。
因此,基于纯视觉的端到端模型 成为了 GUI 智能体发展的新趋势。这种模型直接以屏幕截图为输入,绕开了文本信息的限制,更符合人类的认知过程,同时端到端的架构可以优化信息流动,提高效率
GUI Agents 发展

Stage1: Rule-based Agents
这些 Agent 通常通过将用户指令与预定义规则进行匹配并相应地调用 API 来处理用户指令。尽管这些系统对于定义明确的重复性任务很有效,但受到对人类定义的启发式和显式指令的依赖的限制,阻碍了它们处理新颖和复杂场景的能力。
在此阶段,Agent无法从其环境或以前的经验中学习,并且对工作流的任何更改都需要人工干预。此外,这些Agent需要直接访问 API 或底层系统权限,这使得它不适合此类访问受到限制或不可用的情况。
这种固有的刚性限制了它们在不同环境中扩展的适用性。 基于规则的局限性强调了过渡到基于 GUI 智能体的重要性
Stage2: Agent Framework
具体来说,这些代理系统主要利用高级基础模型(例如 GPT-4 和 GPT-4o等) 的理解和推理能力来增强任务执行的灵活性,从而成为更灵活的、基于框架的智能体。这些智能体通过实现更加自动化和灵活的交互,标志着纯粹基于规则的系统的重大进步。AutoGPT 和 LangChain 等框架允许Agent集成多个外部工具、API 和服务,从而实现更加动态和适应性更强的工作流程。
为了增强基于基础模型的Agent框架的性能,通常涉及设计特定于任务的工作流程和优化每个组件的提示。例如,一些方法通过专门的模块(例如短期或长期记忆)来增强这些框架,以提供特定于任务的知识或存储作经验以进行自我改进。
尽管智能体框架相比基于规则的系统具有更强的适应性,但它们仍然依赖人工定义的工作流程来构建行动结构。"智能体工作流知识"通过自定义提示词、外部脚本或工具使用启发式方法手动编码,主要体现在:
- 脆弱性与高维护成本
- 割裂的学习范式
- 模块不兼容性
虽然智能体框架在狭窄范围内能够提供快速演示和一定的灵活性,但它们在真实世界部署中最终仍然是脆弱的。
核心矛盾:
- ✅ 优势:比规则系统更灵活,适合快速原型开发
- ❌ 劣势:依赖人工定义工作流,无法自主学习和适应,本质上不可扩展
演进方向:需要从"设计驱动"转向"学习驱动",使智能体能够从经验中自主学习,无需持续人工干预即可泛化到新任务和环境。
Stage 3: Native Agent Model
原生智能体模型代表了自主智能体发展的未来方向,其核心特征是:
- 工作流知识直接嵌入模型内部,通过定向学习实现
- 端到端方式学习和执行任务
- 将感知、推理、记忆和行动统一在单一的、持续演进的模型中
- 数据驱动而非设计驱动
Native Agent Model 的优势:
- 整体性学习与适应 (Holistic Learning and Adaptation)
- 减少人工工程 (Reduced Human Engineering)
- 通过统一参数实现强泛化 (Strong Generalization via Unified Parameters)
- 持续自我改进 (Continuous Self-Improvement)
代表性工作
当前 GUI 智能体的发展已逐步进入这一阶段,代表性工作包括:
- Claude Computer-Use (Anthropic, 2024)
- Aguvis (Xu et al., 2024)
- ShowUI (Lin et al., 2024)
- OS-Atlas (Wu et al., 2024)
- Octopus v2-4 (Chen & Li, 2024)
共同特点:这些模型主要利用现有的世界数据,专门为 GUI 交互领域定制大型视觉语言模型(VLM)。
Stage 4: Action and Lifelong Agent
尽管原生智能体在适应性方面有所改进,但仍存在着限制:严重依赖人类专家进行数据标注和训练指导,这种依赖性本质上限制了其能力,使其依赖于人类提供的数据和知识的质量和广度
向主动与终身学习(Active and Lifelong Learning)的转变代表了 GUI 智能体演进的关键下一步,包含:主动环境交互,自主奖励机制和自主探索与学习
这些智能体迭代式地开发和修改技能,类似于机器人学中的持续学习:从成功和失败中学习,逐步增强在越来越广泛的任务和场景中的泛化能力,持续演进和自我改进
核心内容
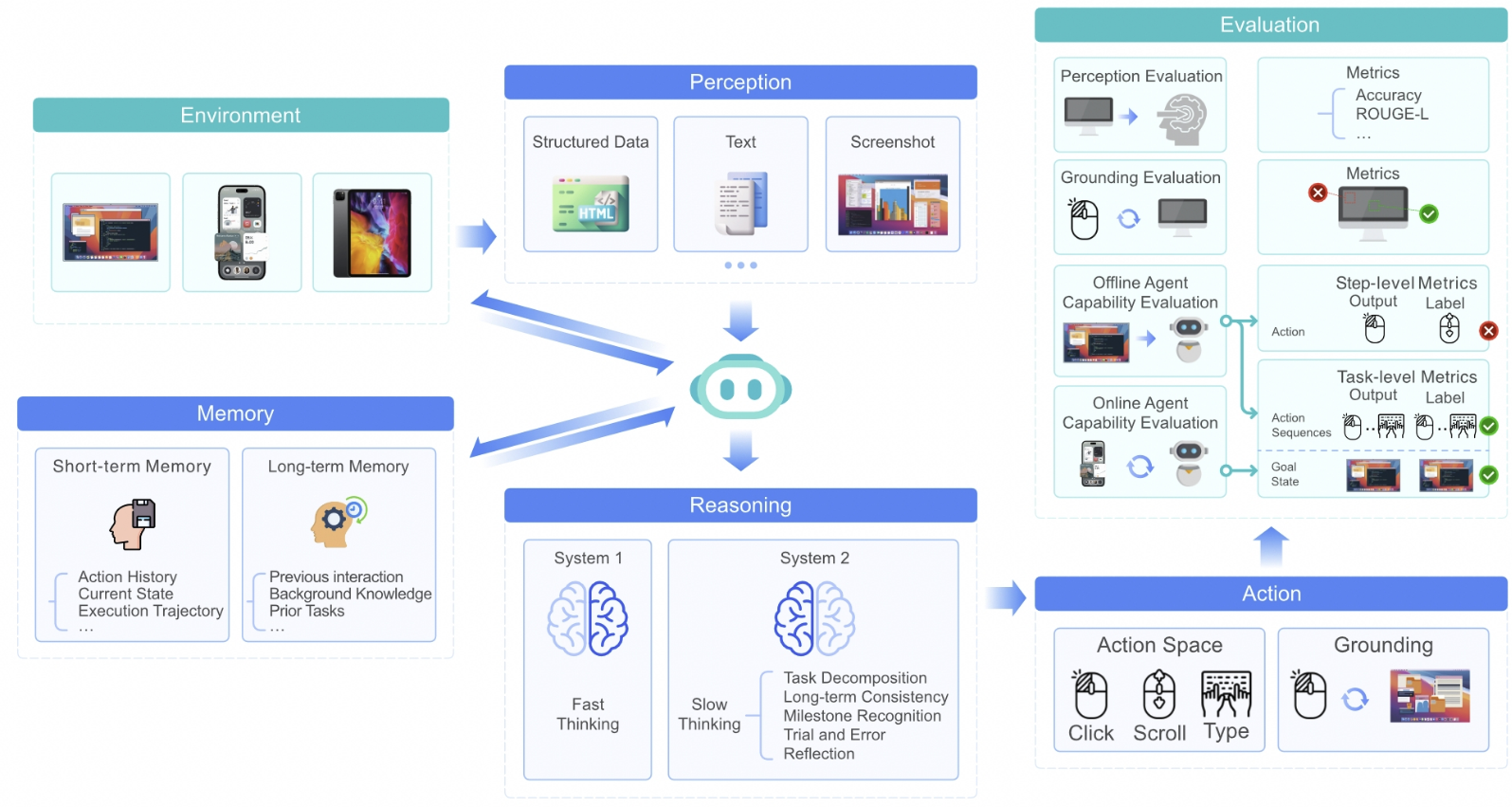
UI-TARS 的核心创新在于它是一个完全基于视觉的、端到端的 GUI 智能体模型。它主要有以下几个关键贡献:
- 增强的感知能力: UI-TARS 通过大规模的 GUI 屏幕截图数据集进行训练,从而能够理解 UI 元素的上下文,并进行精确的标注。这包括:
- 统一的动作建模:UI-TARS 将不同平台上的操作标准化为一个统一的空间,并通过大规模的动作轨迹实现了精确的Grounding和交互。
- System-2 推理:UI-TARS 在多步骤决策中融入了深思熟虑的推理,包括任务分解、反思思考、里程碑识别等多种推理模式。
- 长短期记忆:原生智能体模型与智能体框架不同,它们将任务的长期操作经验编码在其内部参数中,将可观察的交互过程转换为隐式的参数化存储。可以采用上下文学习(ICL)或思维链(CoT)推理等技术来激活这种内部记忆。
UI-TARS 的端到端架构使其能够直接处理原始的屏幕截图,避免了对文本信息的依赖。同时,系统 2 推理 能力使其能够执行复杂的、多步骤的任务,而不是仅仅执行简单的、反应式的操作。
方法解析
下面我们来更深入地了解一下 UI-TARS 的技术细节:
- 数据构建
- 动作建模和接地
-
系统 2 推理
-
迭代改进
- 训练
模型性能

UI-TARS2
背景&挑战
- 数据缺失
- 多轮强化学习训练
- GUI操作的局限性
-
RL环境的可扩展性和稳定性
论文也是针对以上四点进行的展开,针对性的构建了基于四大支柱的系统化方法。 -
针对数据稀缺的问题,设计了一个可扩展的数据飞轮(Data Flywheel),可以持续预训练、监督微调、拒绝采样与多回合RL使模型与训练语料协同演化,不断提升模型能力;
- 针对多轮RL困难的问题,设计了稳定优化的训练框架(后面展开);
- 针对纯GUI交互局限性的问题,设计了以GUI为中心的混合工具环境,将文件系统、终端和其他外部工具合并;
- 针对RL训练和测评的环境问题,搭建了统一的沙箱平台,可以在一致的API下编排异构环境——从用于GUI交互的云端虚拟机到基于浏览器的游戏沙箱。
UI-TARS-2主要方法
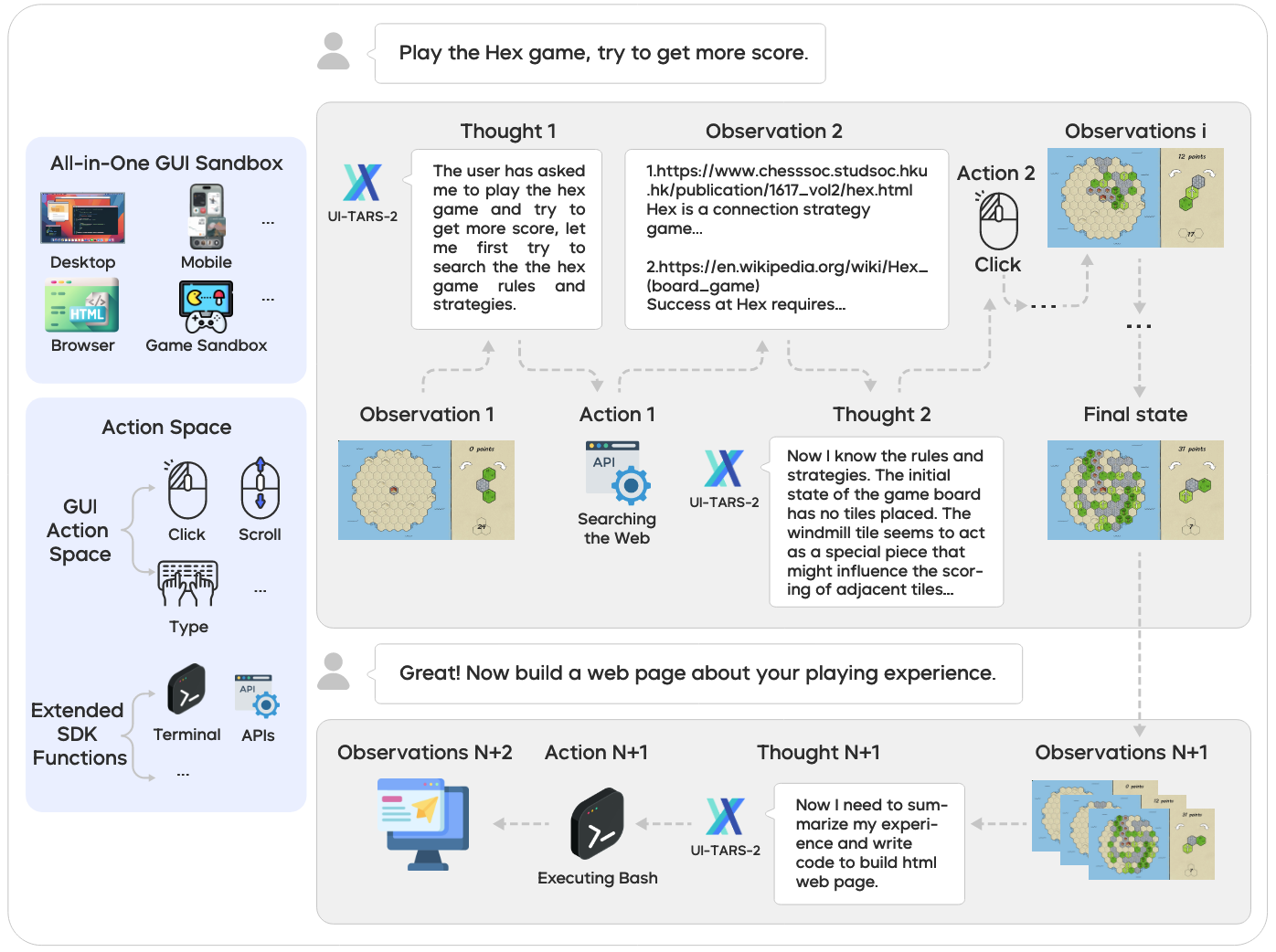
格式
还是延用UI-TARS中原生智能体模型的视角,其中的Agent被建模为参数化策略:将历史上下文、记忆状态和当前环境映射到行为输出中。在时间步骤 \(t\),智能体遵循ReAct范式,将推理、行动和观察交错在一个结构化循环中:
- 推理(\(t_t\)):内部认知处理,包括上下文分析、记忆回忆、计划和自我反思
- 动作(\(a_t\)):外部交互,例如 GUI操作、系统命令或工具调用
- 观察(\(o_t\)):来自用于更新Agent状态的环境反馈。
对于动作空间整体分文两个大类:
- GUI动作:遵循UI-Tars的直接界面操作
- SDK函数:用于文件管理和软件开发的直接终端命令,以及用于编排外部服务与多工具推理的MCP工具调用。
如果将GUI轨迹看做是一个马尔科夫链,其过程是LLM不断ReAct的过程,可以表示成以下格式(假设轨迹的总时间步是 \(T\) ):
对于长时间步的轨迹来说,肯定不能将所有记忆(之前步骤的三元组内容)都输入给模型,一是模型上下文有限,二是每个图片会切分成很多token,很长的输入会使得模型计算耗时严重。
论文中是使用了一个关键组成部分是分层记忆状态:
其中 \(\mathcal{W}_t\)( working memory) 以存储最近的步骤(\(t_{t−k}\)、\(a_{t−k}\)、\(o_{t−k}\))以进行短期推理,而 \(\mathcal{E}_t\)(Episodic Memory) 则保持过去情节的语义压缩摘要,保留关键意图和结果以进行长期回忆。在每个时间步,策略预测下一步的推理和行动可以表达为: