讨论一下推荐系统三板斧:数据、特征和模型,因为搜索的排序套路和推荐十分类似,除了多了query维度特征,对相关性有一定的要求,其他很大程度上思想一致。
这里先行引用一个比较形象的推荐系统优化流程:

- 明确业务目标
- 将业务目标转化为机器学习可优化目标
- 样本收集
- 特征工程
- 模型选择和训练
- 离线评测验证
- 在线AB验证
- 通过离线验证和在线AB的结果反馈到2,形成一个增强回路慢慢起飞。
而在一般情况下,各个环节的贡献占比:样本>>特征工程>模型。另外如果离线验证集85分,线上很多时候也会略低,各种原因也不胜枚举:特征延迟、特征不一致、甚至在样本落盘时的数据丢失等等。
本篇先行介绍上述过程特征工程的一般方法,包括特征设计、清洗、变换以及特征选择,并在最后讨论深度学习背景下的特征工程。
特征设计
特征工程的第一步是要找到对模型预测有用的特征,最常用的方式是基于经验分维度梳理,如电商领域第一层可以按场景元素分成User特征、Item特征、Seller特征、Query特征、上下文特征等,第二层可以按特征类型分成如类别特征、统计特征、语义特征、画像特征、时间特征、空间特征等。此外,基于已有特征还可以进一步构造组合特征,对于一些重要的特征可以优化为实时特征。
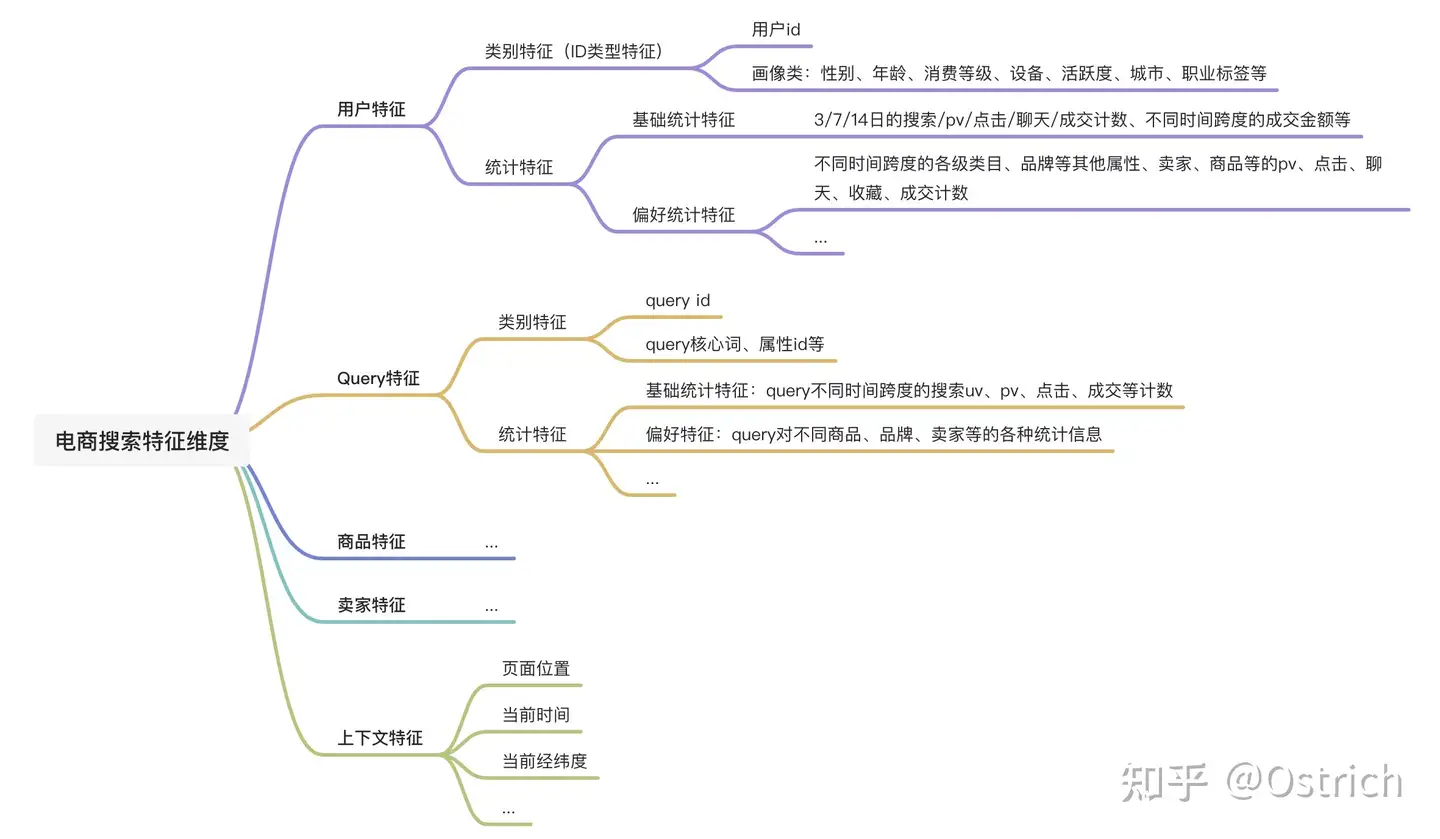
以上特征梳理方式并不是标准答案,通过不断细化一般可以得到一个有力的baseline。如果想要找到更多有用的特征,则往往需要深入到业务和数据之中去发现,脑爆一下什么因素可能会影响用户的点击、成交,并通过数据分析予以验证。另一种比较奢侈的方式则是领域专家咨询、用户报告调研等。
最后,选择特征的过程也要考虑特征是否可以取到,以及该特征在线上是否能够及时获取。
数据清洗
通常情况下,在梳理并得到想要的特征后,第一步需要对异常数据进行清洗,最常见的异常有空值异常(缺省值处理)、数值溢出(数值异常处理)。
1、对于缺省值处理,如果缺失量级较大,可以考虑直接删除该特征;缺失量较少,则可以使用均值、中位数、众数等统计值填充,亦可通过建模方式,使用模型对缺失值进行预测;此外,对于一些特殊模型,如gbdt、xgboost等树模型本身也可以兼容缺失值。
2、对于数值异常,可以使用箱线图观察分析,如个别样本特征出现极大值或极小值,可以采用最简单的均值、中位数等填充,或者在数据量级不大的情况下,直接删除存在异常特征的样本。
特征变换
剔除存在异常的样本之后,需要进一步对特征进行变换,毕竟不是所有类型的特征都能直接作为模型输入,可以作为模型输入的特征也不一定是最高效的方式。下面分特征类型,分别介绍不同类型的特征常见的特征变换方式。
类别特征(离散特征、id类特征)
原始的类别特征一般是字符串(如 性别“男”和“女”)或者整型数值形式(如用户ID),该类型特征通常预先使用one-hot或multi-hot编码。如性别特征可以使用one-hot将男女分别编码为[1, 0]和[0, 1],变换后的特征可直接作为线性模型或深度模型的输入,对深度模型来讲常见的还会预先通过嵌入层索引得到相应特征的embedding,再接入下游网络。
数值型特征
对于数值类型特征,可以直接作为模型输入,但对于大多数模型来说,预先对数值类型特征做归一化/标准化,可以使各特征量纲一致,加速模型收敛速度,提升模型效果。
另一种数值型特征常见的变换方式是离散化,即对数据进行分桶,常见的有等频分桶或等距离分桶,也可根据实际情况使用分位点进行分桶,或更高级一点的卡方分桶等。举例来说,对于价格特征,假如值域0~100,等距离分成100个桶,对于特定价格找到其落在的区间范围,即可得到相应的区间ID作为其离散值特征。
将连续数值特征变换为离散特征,相当于将特征变换到更高维度的空间,更有利于模型对特征的进行区分(尤其对于线性模型)。值得一提的是,将数值类型hash为id特征,作为深度模型的输入也是比较主流的方式。
时间特征
时间特征通常情况下是比较重要的特征,该类特征可以构造为数值类型,如页面停留时长、距离上次曝光/点击时间等;亦可以为离散特征形式,如年份、月份、星期、小时点、节假日等。相应的可以通过上述变换方式转化为对模型友好的数据类型。
内容特征
很多时候如文本、图像等的内容特征对模型效果也会很有帮助,在内容推荐、推荐冷启动等场景的作用尤为明显。该类特征有两种比较常见的处理方式,一是直接离散化作为模型的输入,如对于文本的词或字进行ID编码即可将其转化为离散特征,并进一步变换为模型可输入数据类型;
另一种方式则是先对内容进行隐语义表示,并将隐语义表示作为模型输入。如对于文本,常见的隐语义表示可以通过word-embeding、经过微调的bert等Encoder进行语义向量特征提取;对于图像亦可以使用常见的图像encoder模型微调后预测得到其向量表示。
统计特征
统计类特征通常为对用户行为、商品表现等维度的统计值,一般情况可根据情况作为离散特征或数值型特征进行变换处理。
组合特征(特征交叉)
特征交叉是提升模型效果的有效方式,几乎是推荐模型的必备操作,常见的特征交叉方式如特征两两组合,FM等,很多时候深度模型架构下,往往也自带特征交叉效果,也有一些深度模型专门设计了特征交叉模块,如DeepFM、DeepCrossing等。
特征选择
特征选择希望剔除和目标预测无关的特征,可以降低模型大小,提升训练和预测效率,有时也能提升模型预测效果(如模型容量不足的情况下)。
而更多的时候,模型选择(删除不相关特征)法不得当的话对模型效果有会有负向作用。常见的特征选择方式有过滤法、迭代法和模型选择等方法。
过滤法直接通过统计方法计算单特征和目标label的相关性,并选择topk,或通过卡阈值过滤掉一定数量的特征。常见的特征相关性可以使用皮尔逊相关系数、卡方检验等方式度量。
迭代法通过迭代的方式进行特征选择,如预先使用所有的特征训练LR模型,接着丢弃5%~10%的弱特征(对应权重低的特征),如此反复直到评价指标下降明显,剩下的特征则保留。
模型选择方法也比较直觉,使用L1正则训练LR模型,如剔除权重为0的特征;或者训练LR模型,使用单特征输入计算单特征AUC衡量特征重要性;亦或者使用树模型进行自动特征工程,同样也是特征选择的一种,如经典的GBDT、GBDT+LR。
一些讨论
深度学习盛行,很多时候模型可以帮我们做好绝大多数的工作,如特征筛选或特征组合等,不少人会问特征工程是否还如以往那么重要?这个问题目前来看,答案应该依然是肯定的。
一方面,绝大多的模型都不能保证能够完美挖掘出基础特征所蕴含的所有信息,即模型存在精度问题,在数据量不足,特殊场景等情况下更是如此。手动的人工特征设计可以借助人的专业经验减轻模型学习负担,使模型收敛更快更好,更轻松的取得更好的结果。
另一方面,无脑将想到的特征灌给模型,无疑会增加模型的大小,其中可能会有很大一部分参数并没有很大的贡献,对线上inference速度要求较高或是资源有限的场景的影响尤为重要。
最后,深度学习一直因为其“黑盒“的不可解释性被诟病。很长一段时间,虽然深度学习在推荐领域盛行,不少公司场景依然会优先使用基础的LR或GBDT模型服务线上,运行效率高,同时模型可解释性更强,特征工程做的足够细致的情况下,很多时候效果也不输深度模型。
小结
至此,推荐系统特征工程部分的介绍告一段落。下一篇仍是番外,将梳理推荐系统模型的演化路径和一般优化思路。