1. 搜索引擎概述
1.1 推荐和搜索比较
推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。
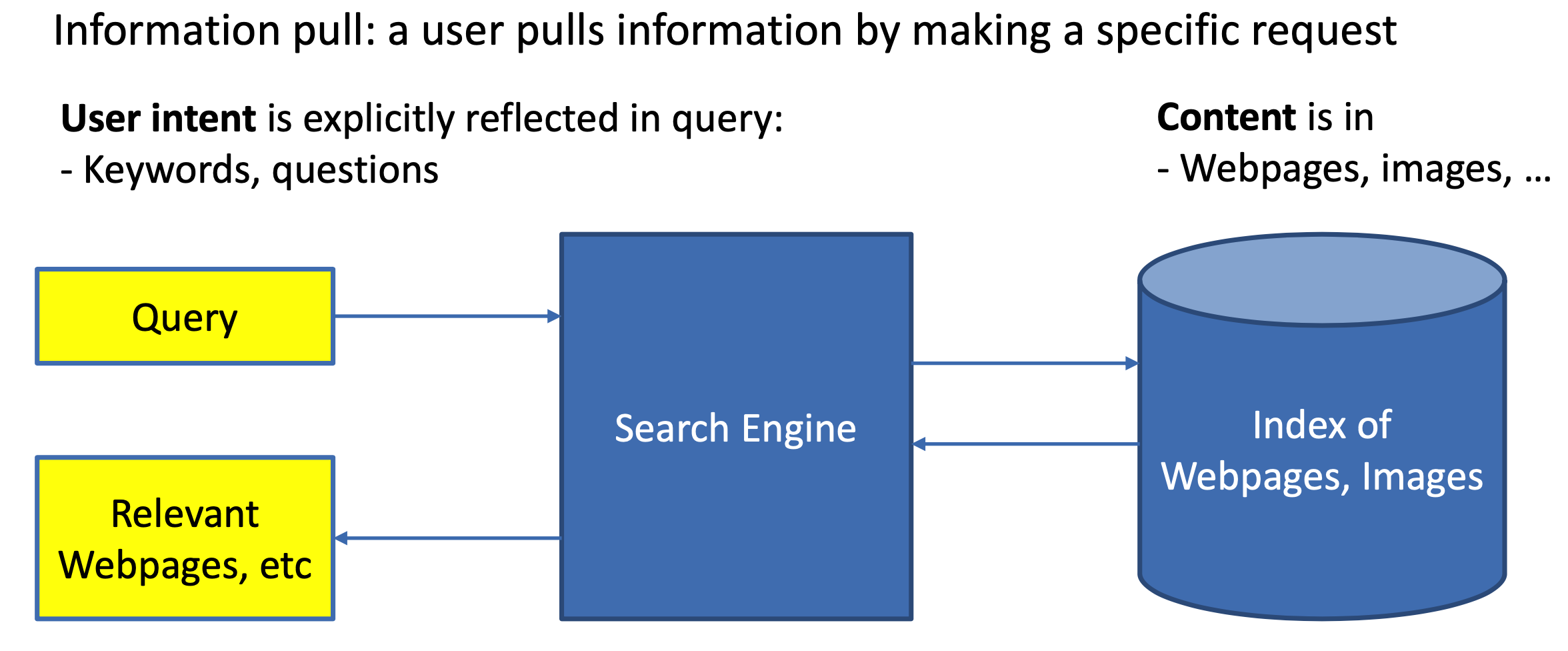
对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过query-doc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。
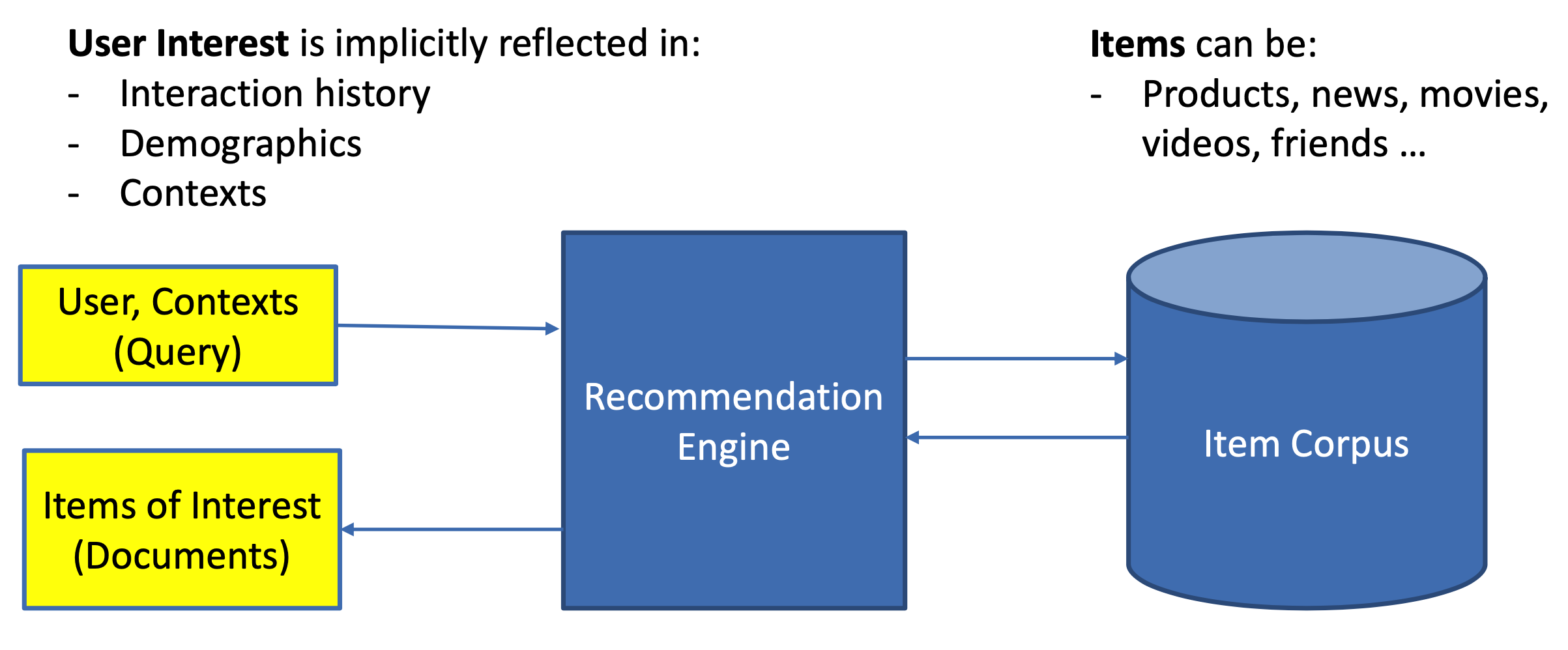
对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推荐用户可能感兴趣的物品(如电商的商品、feeds推荐的新闻、应用商店推荐的app等),从这个过程来看,推荐系统要解决的就是user和item的match,如图1.2所示。
1.1.1 搜索和推荐不同之处
(1) 意图不同
搜索是用户带着明确的目的,通过给系统输入query来主动触发的,搜索过程用户带着明确的搜索意图。而推荐是系统被动触发,用户是以一种闲逛的姿态过来的,系统是带着一种“猜”的状态给用户推送物品。
简单来说,搜索是一次主动pull的过程,用户用query告诉系统,我需要什么,你给我相关的结果就行;而推荐是一次push的过程,用户没有明显意图,系统给用户被动push认为用户可能会喜欢的东西吧。
(2) 时效不同
搜索需要尽快满足用户此次请求query,如果搜索引擎无法满足用户当下的需求,例如给出的搜索结果和用户输入的query完全不相关,尽是瞎猜的结果,用户体验会变得很差。
推荐更希望能增加用户的时长和留存从而提升整体LTV(long time value,衡量用户对系统的长期价值),例如视频推荐系统希望用户能够持续的沉浸在观看系统推荐的视频流中;电商推荐系统希望用户能够多逛多点击推荐的商品从而提高GMV。
(3) 相关性要求不同
搜索有严格的query限制,搜索结果需要保证相关性,搜索结果量化评估标准也相对容易。给定一个query,系统给出不同结果,在上线前就可以通过相关性对结果进行判定相关性好坏。例如下图中搜索query为“pool schedule”,搜索结果“swimming pool schedule”认为是相关的、而最后一个case,用户搜索“why are windows so expensive”想问的是窗户为什么那么贵,而如果搜索引擎将这里的windows理解成微软的windows系统从而给出结果是苹果公司的mac,一字之差意思完全不同了,典型的bad case。

而推荐没有明确的相关性要求。一个电商系统,用户过去买了足球鞋,下次过来推荐电子类产品也无法说明是bad case,因为用户行为少,推完全不相关的物品是系统的一次探索过程。推荐很难在离线阶段从相关性角度结果评定是否好坏,只能从线上效果看用户是否买单做评估。
(4) 实体不同
搜索中的两大实体是query和doc,本质上都是文本信息。这就是上文说到的为什么搜索可以通过query和doc的文本相关性判断是否相关。Query和doc的匹配过程就是在语法层面理解query和doc之间gap的过程。
推荐中的两大实体是user和item,两者的表征体系可能完全没有重叠。例如电影推荐系统里,用户的特征描述是:用户id,用户评分历史、用户性别、年龄;而电影的特征描述是:电影id,电影描述,电影分类,电影票房等。这就决定了推荐中,user和item的匹配是无法从表面的特征解决两者gap的。

(5) 个性化要求不同
虽然现在但凡是一个推荐系统都在各种标榜如何做好个性化,“千人千面”,但搜索和推荐天然对个性化需求不同。搜索有用户的主动query,本质上这个query已经在告诉系统这个“用户”是谁了,query本身代表的就是一类用户,例如搜索引擎里搜索“深度学习综述”的本质上就代表了机器学习相关从业者或者对其感兴趣的这类人。在一些垂直行业,有时候query本身就够了,甚至不需要其他用户属性画像。例如在app推荐系统里,不同的用户搜索“京东”,并不会因为用户过去行为、本身画像属性不同而有所不同。
而推荐没有用户主动的query输入,如果没有用户画像属性和过去行为的刻画,系统基本上就等于瞎猜。
1.2.2 搜索和推荐相同之处
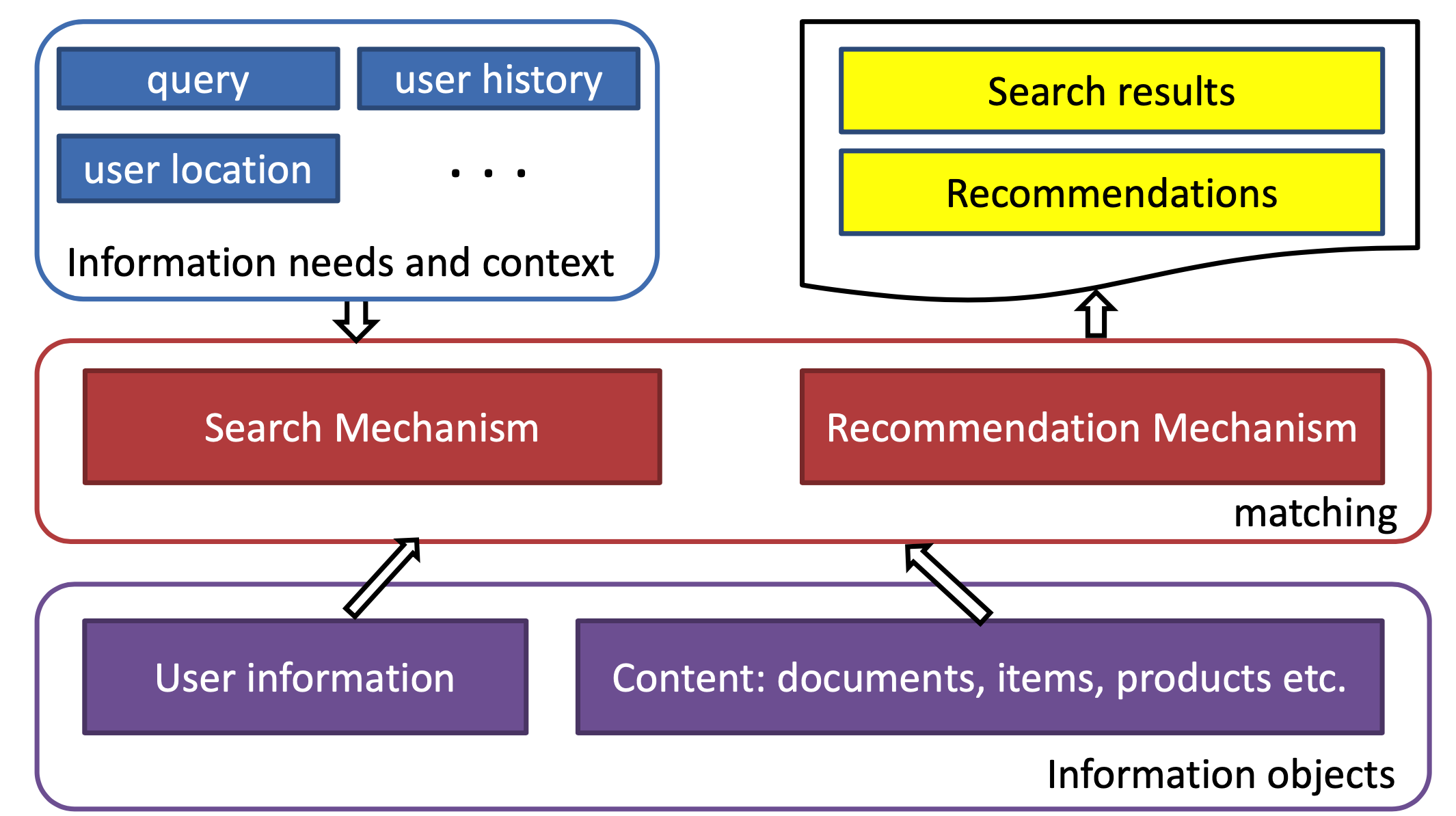
(1)本质是都是match过程
如果把user比作query,把item比作doc,那么推荐和搜索在这个层面又是相同的,都是针对一个query(一个user),从海量的候选物品库中,根据query和doc的相关性(user过去的历史、画像等和item的匹配程度),去推荐匹配的doc(item)
(2)目标相同
搜索和推荐的目标都是针对一次context(或者有明确意图,或者没有),从候选池选出尽可能满足需求的物品。两者区别只是挑选过程使用的信息特征不同。
(3)语义鸿沟(semantic gap)都是两者最大的挑战
在搜索里表现是query和doc的语义理解,推荐里则是user和item的理解。例如,搜索里多个不同的query可能表示同一个意图;而推荐里用来表示user和item的特征体系可能完全不是一个层面的意思。
1.2 搜索匹配
在目前工业界的大多数主流系统里,推荐系统和搜索引擎一般分为召回和排序两个过程,这个两阶段过程称呼较多,召回也会叫粗排、触发、matching;排序过程也会叫精排、打分、ranking。
而在本文要讲到的匹配,并不仅仅指的是第一阶段这个matching的过程,而是泛指整个query和doc的匹配。图1.6可以表示本文要讲的query和doc的匹配表示,通过给定的training data,通过learning system,学习得到query和doc的匹配模型\(f_M(q, d)\)。然后对于test data,也就是给定的需要预测的q和d,便可以通过这个模型,预测得到q和d的匹配分数\(f_M(q, d)\)。

由于query和doc本身都是文本表示,所以本质上来说,这篇文章要讲的东西也是文本的深度匹配模型。大部分自然语言处理的任务基本都可以抽象成文本匹配的任务。
(1) 信息检索(Ad-hoc Information Retrieval):也就是本文要介绍的主体,在搜索引擎里,用户搜索的query以及网页doc是一个文本匹配的过程
(2) 自动问答(Community Question Answer): 对于给定的问题question,从候选的问题库或者答案库中进行匹配的过程
(3) 释义识别(Paraphrase Identification):判断两段文本string1和string2说的到底是不是一个事儿
(4) 自然语言推断(Natural Language Inference):给定前提文本(premise),根据该premise去推断假说文本(hypothesis)与premise的关系,一般分为蕴含关系和矛盾关系,蕴含关系表示从premise中可以推断出hypothesis;矛盾关系即hypothesis与premise矛盾。
2. 搜索中的传统匹配模型
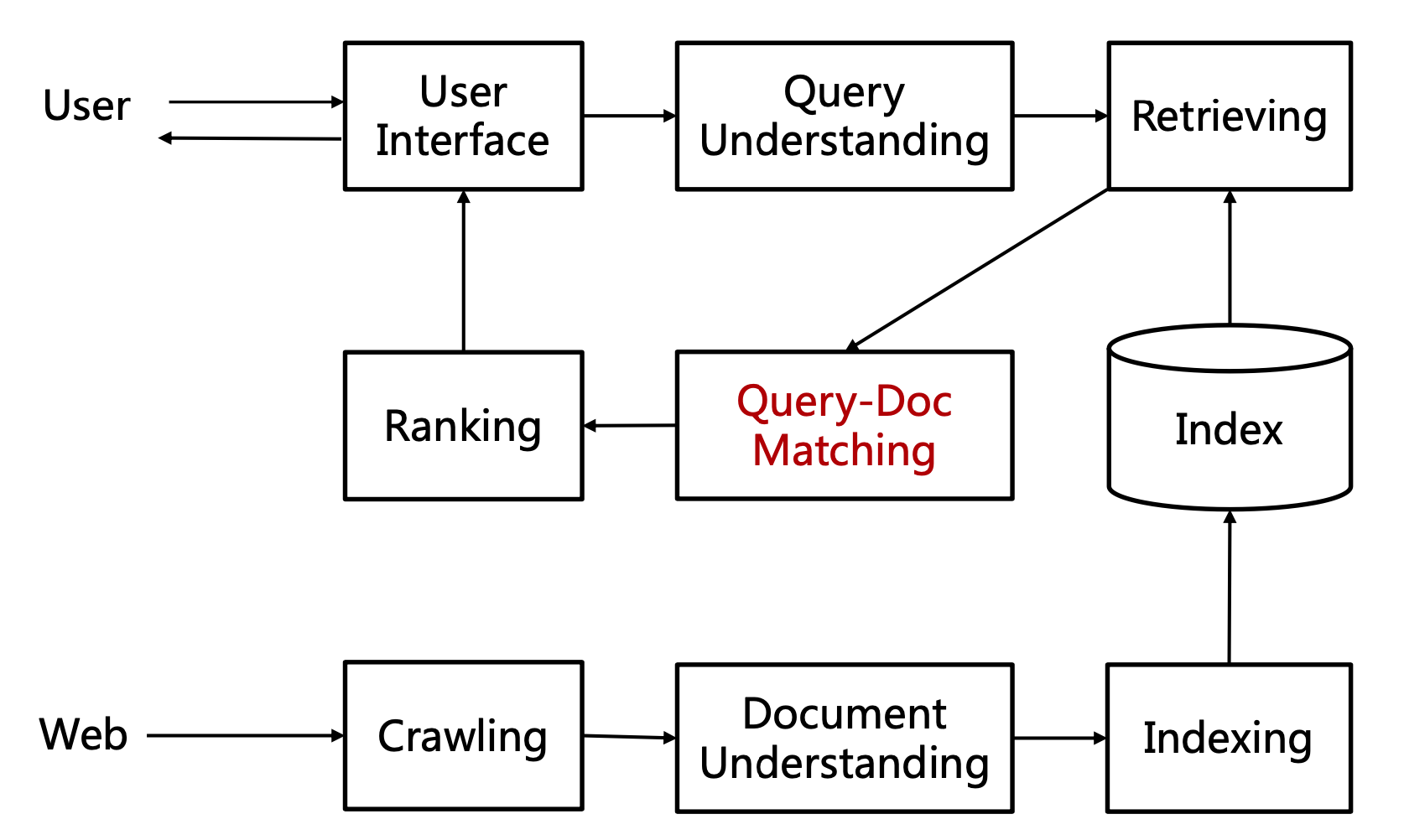
图2.1表示的是 query-doc的匹配在整个搜索引擎流程中的流程。在讲整个搜索的深度匹配模型之前,我们先来看下传统的匹配模型。
更早之前有基于term的统计方法,例如TF-IDF等,而从match的角度,按照query和doc是否映射到同一个空间,可以分为两大类,一类是基于隐空间的match,将query和doc都映射到同一个latent space,如图2.2所示;第二种是基于翻译空间的match,将doc映射到query的空间,然后学习两者的匹配。
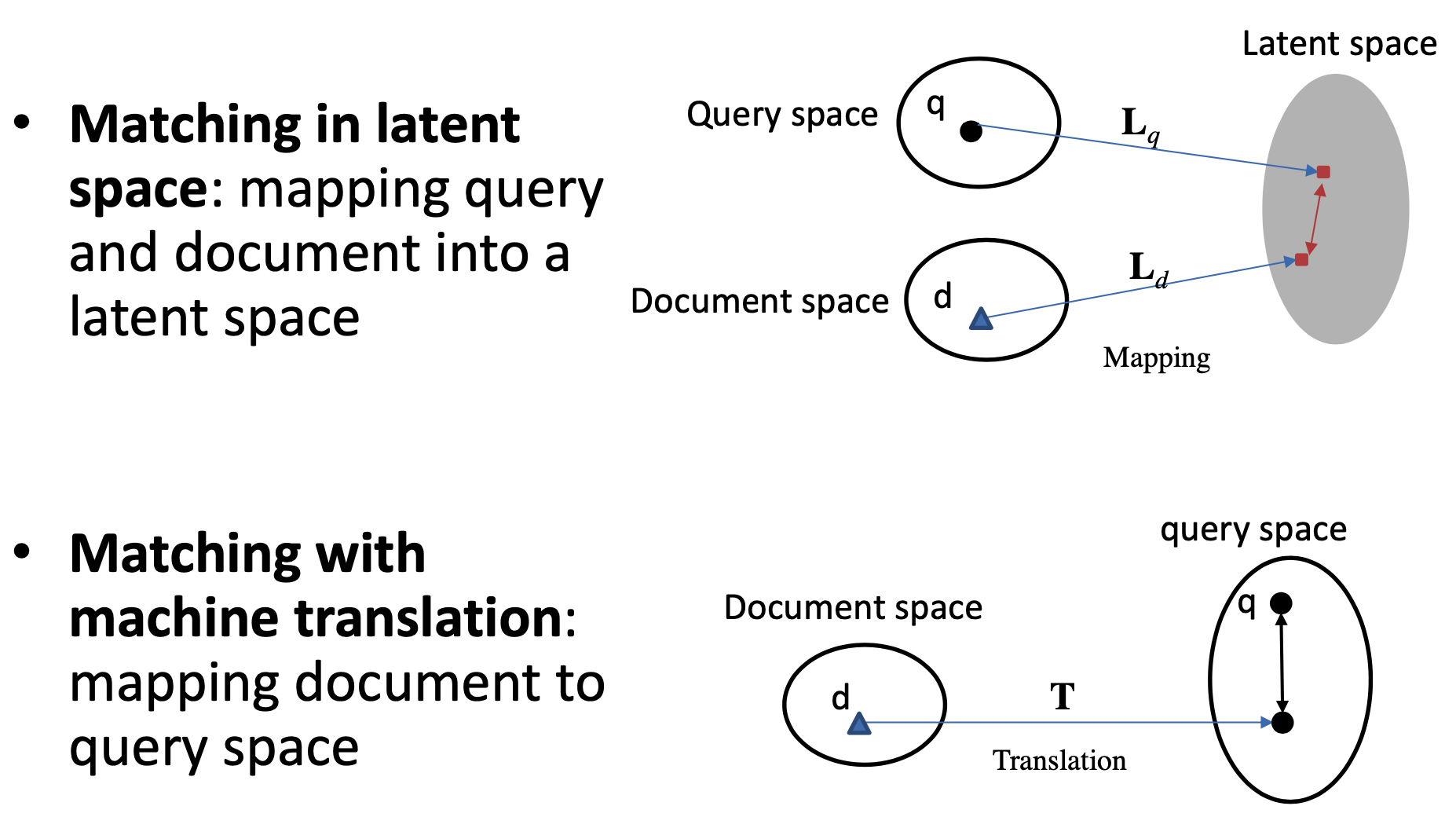
2.1 基于latent space的传统匹配方法
2.1.1 BM25
对于第一种方法,基于隐空间的匹配,重点是将query和doc都同时映射到同一空间,经典的模型有BM25。BM25方法核心思想是,对于query中每个term,计算与当前文档doc的相关性得分,然后对query中所有term和doc的相关得分进行加权求和,可以得到最终的BM25,整体框架如图2.3所示
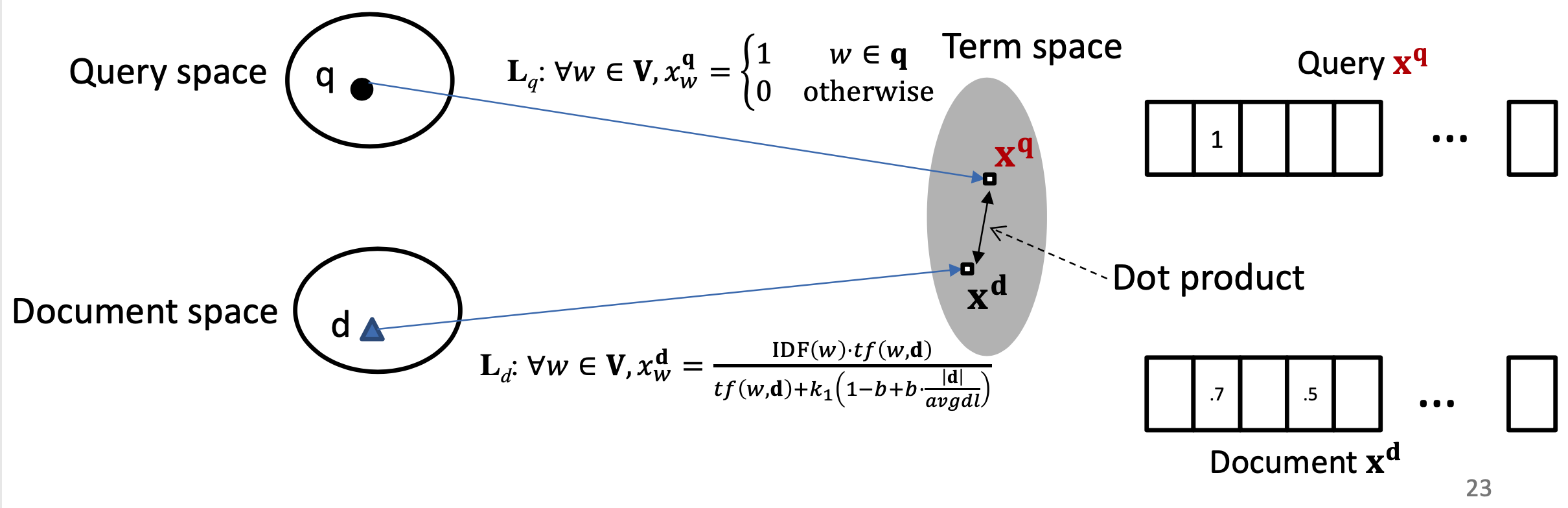
对于query的表示采用的是布尔模型表达,也就是term出现为1,否则为0;
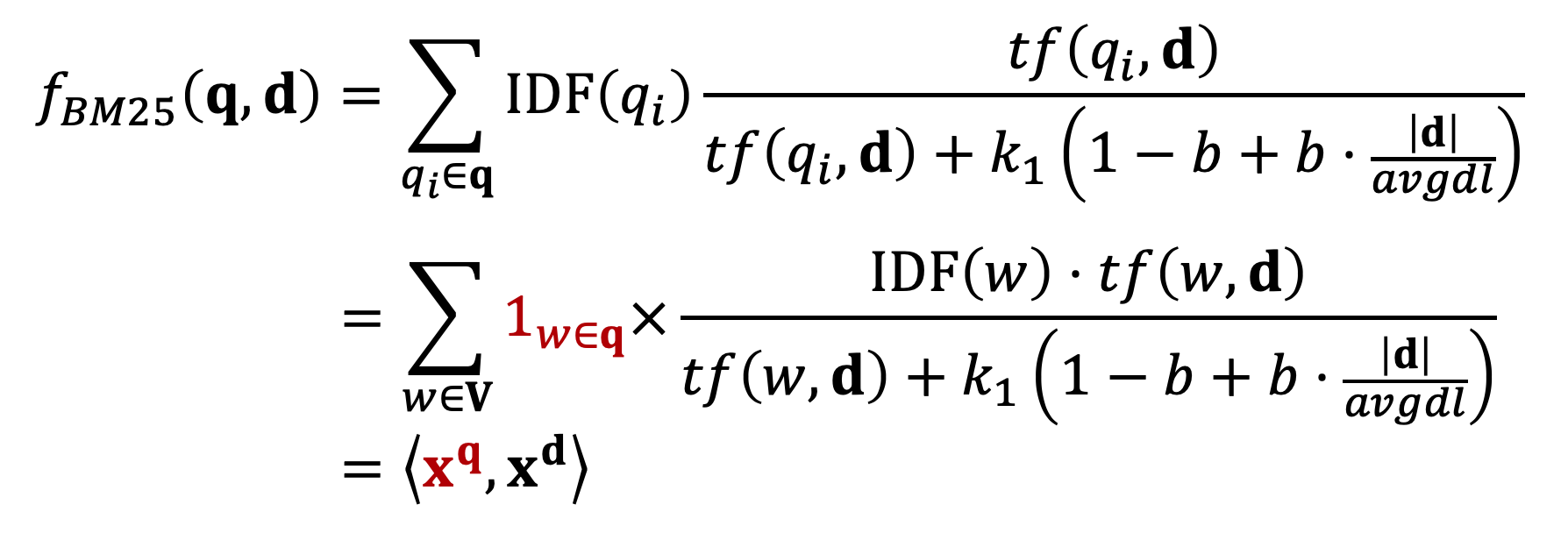
图2.4的BM25公式为query中所有term的加权求和表达,可以分为两部分,第一部分是每个term \(q_i\)的权重,用IDF表示,也就是一个term在所有doc中数显次数越多,说明该\(q_i\)对文档的区分度越低,权重越低。
公式中第二部分计算的是当前term \(q_i\)与doc d的相关得分,分子表示的是\(q_i\)在doc中出现的频率;分母第中\(dl\)为文档长度,\(avgdl\)表示所有文档的平均长度,\(|d|\)为当前文档长度,\(k1\)和\(b\)为超参数。直观理解,如果当前文档长度\(|d|\)比平均文档长度\(avgdl\)大,包含当前query中的term \(q_i\)概率也越高,对结果的贡献也应该越小。
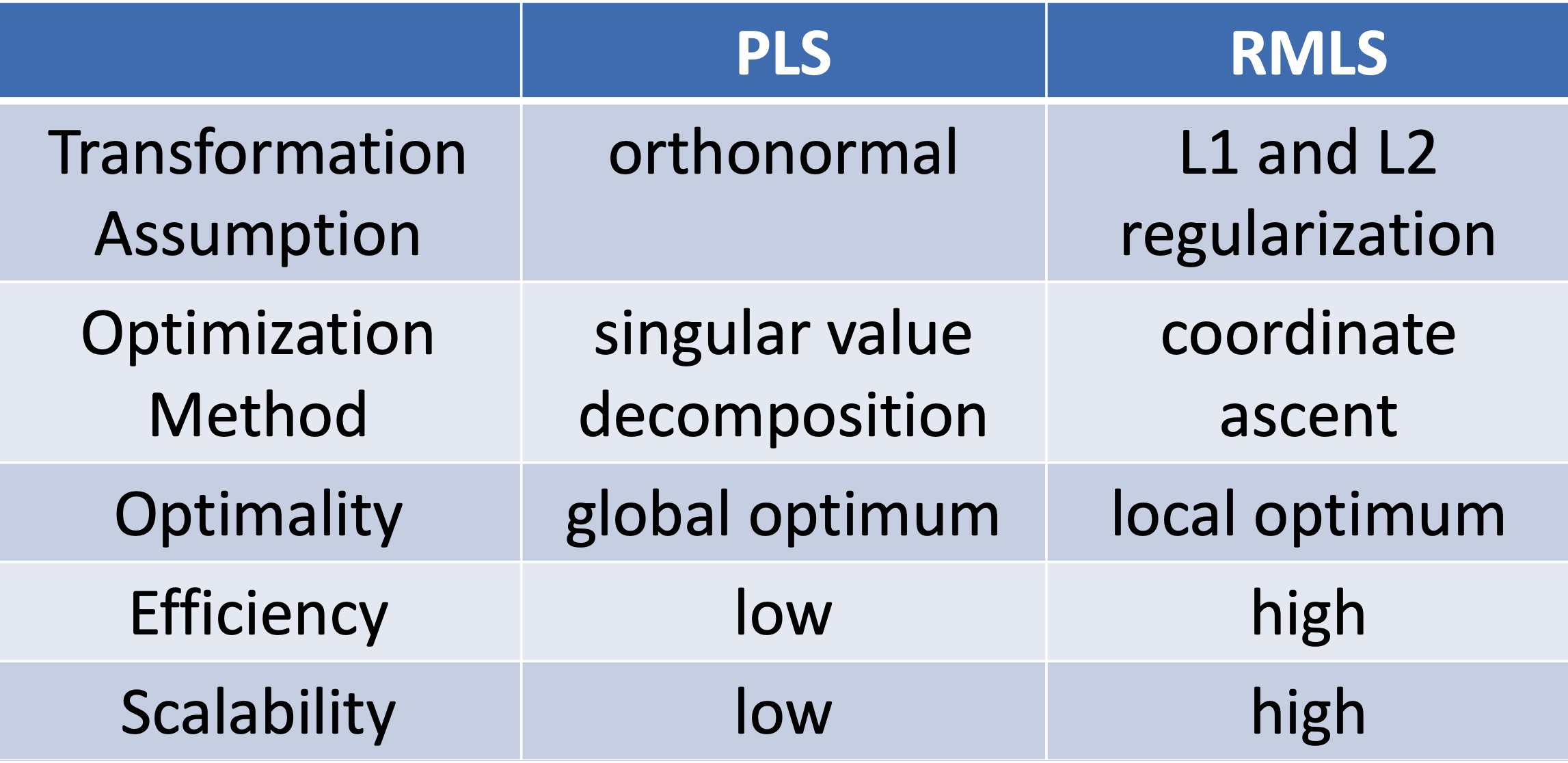
2.1.2 PLS方法
PLS方法全称是Partial Least Square,用偏最小二乘的方法,将query和doc通过两个正交映射矩阵LX和LY映射到同一个空间后得到向量点积,然后通过最大化正样本和负样本的点积之差,使得映射后的latent space两者的距离尽可能靠近。
- query和doc的空间表示
- 训练数据和模型
- 优化目标
2.1.3 RMLS模型
Regularized Mapping to Latent SpacePLS在空间表示、训练数据以及优化目标表示上都一致,区别在于转化矩阵\(L_X\)和\(L_Y\)上,PLS模型的基本假设要求两个矩阵是正定的;而RMLS模型在此基础上加入了正则限制,整体优化目标下公式所示
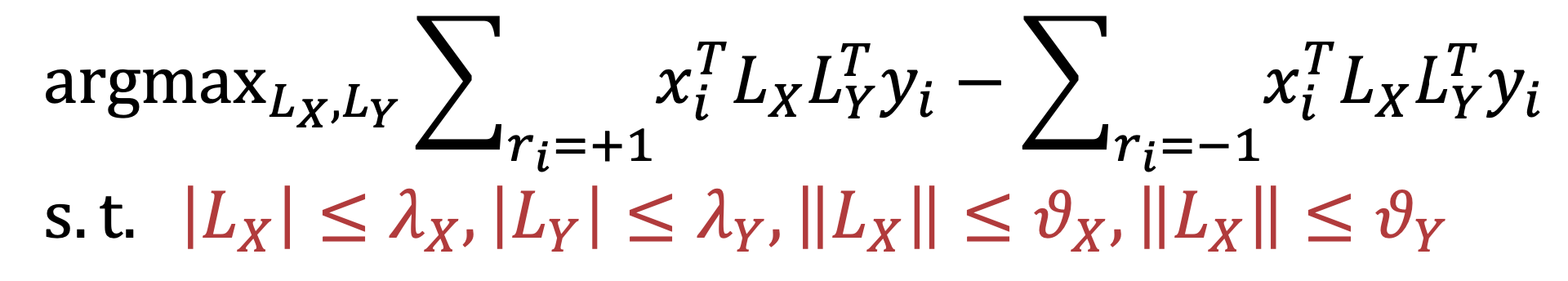
总结下PLS和RMLS的特点如下:
2.2 基于translation的传统匹配方法
query和doc的匹配过程,就是将原本属于不同空间的两段文本映射到一个空间后进行匹配。基于translation的方法把这个过程类比于机器翻译过程:query看成是目标语言E,把doc看成是源语言C,目的是为了得到源语言到目标语言的概率 \(P(E|C)\) 最大化,也就是\(P(query|doc)\) 最大化
2.2.1 SMT模型
Baseline方法的基于统计机器翻译的方法,给定源语言C(document),以及目标语言E(query),从源语言到目标语言的翻译过程,就是将doc映射到query的过程。
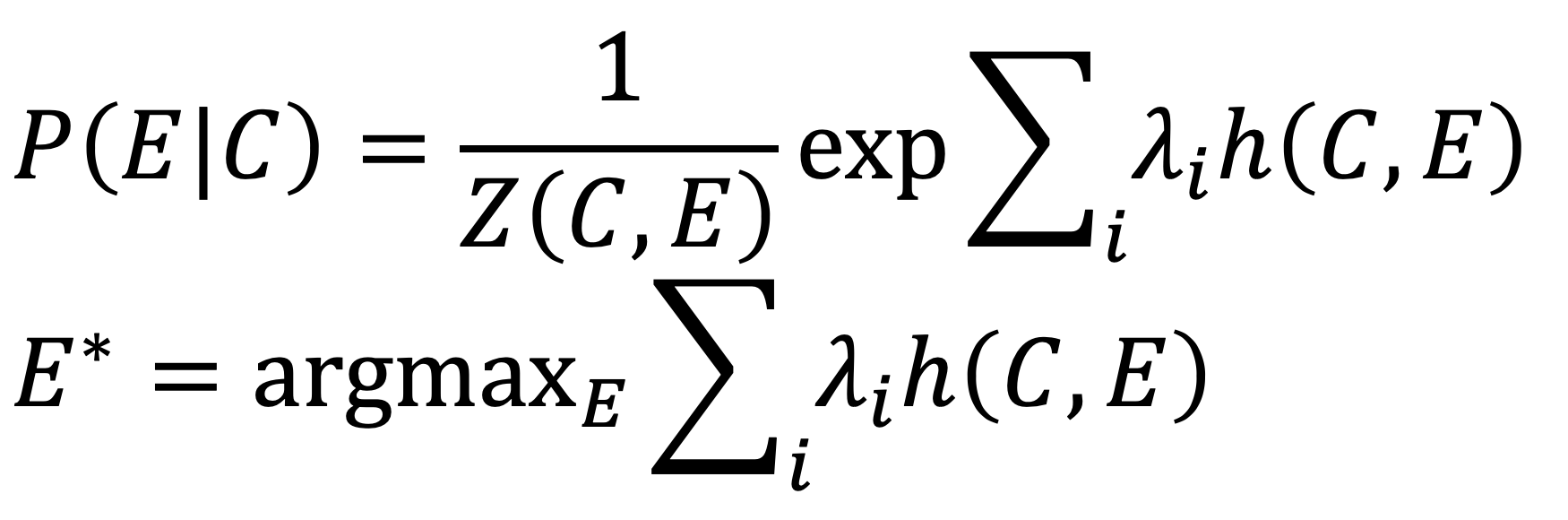
其中,\(h(C,E)\)是关于\(C\)和\(E\)的特征函数。整个求解过程看成是特征函数的线性组合
2.2.2 WTM模型
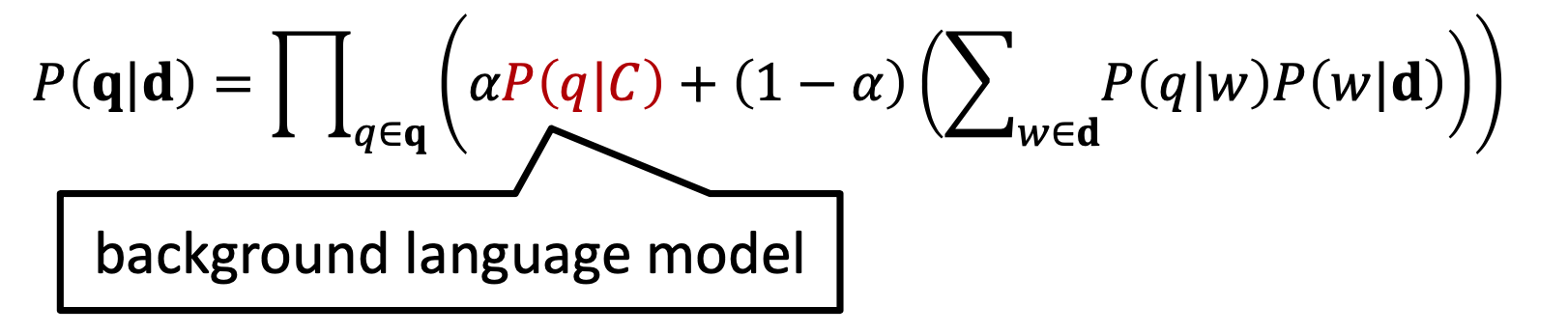
Word-base Translation Model,简称WTM模型,把doc和query的关系看成是概率模型,也就是给定doc,最大化当前的query的概率。Doc生成query的过程可以看成两部分组成,第一项\(p(q|w)\)是概率模型,也就是doc中的单词w,翻译到当前query的单词q的概率,称为translation probability;\(p(w|d)\)注意doc是加粗表示整个文档,也就是doc生成每个单词w的概率,称为document language model。

上述公式将doc->query的翻译过程拆成了两个模型的连乘,对于很多稀疏的term,一旦出现某个概率为0,最终结果也将变为0。为了防止这种情况就需要做平滑,下述公式通过引入background language model的\(p(q|C)\),并且用参数\(\alpha\)进行线性组合来做平滑。C代表的是整个collection.
从贝叶斯公式,可以得到\(p(q|C)\)以及\(p(w|D)\)的表达;\(C(q;C)\)表示的是当前query的单词q在整个collection出现的次数;\(C(w;D)\)表示的是单词w在文档D中出现的次数
但是这种方法也存在问题,就是self-translation问题。原本这个问题是在机器翻译过程中,但是在query和doc过程中,源语言和目标语言都是同一种语言,也就是doc中的每个term都有可能映射到query中相同的term,即\(p(q=w|w)>0\)。因此,CIKM2010年引入了unsmoothed document language model,也就是\(p(q|d)\)来解决这种问题
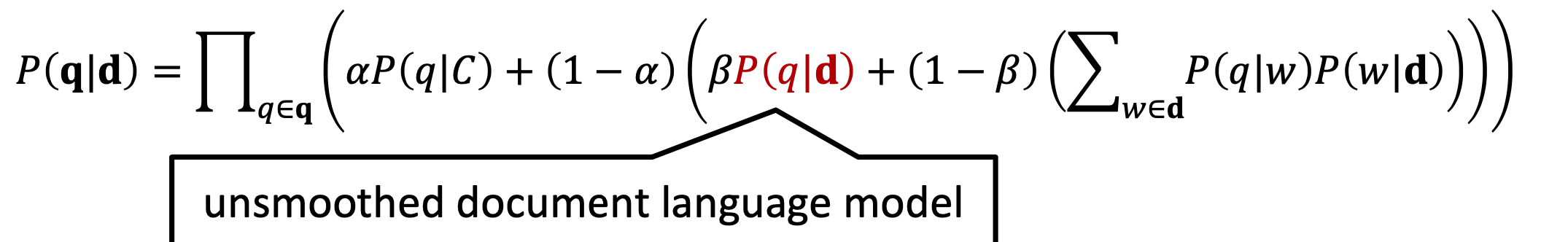
3. 基于representation learning的深度匹配模型
在搜索的深度模型匹配中,我们发现这一步和推荐系统的深度匹配模型一样,也可以分为两类模型,分别是基于representation learning的模型以及match function learning的模型。
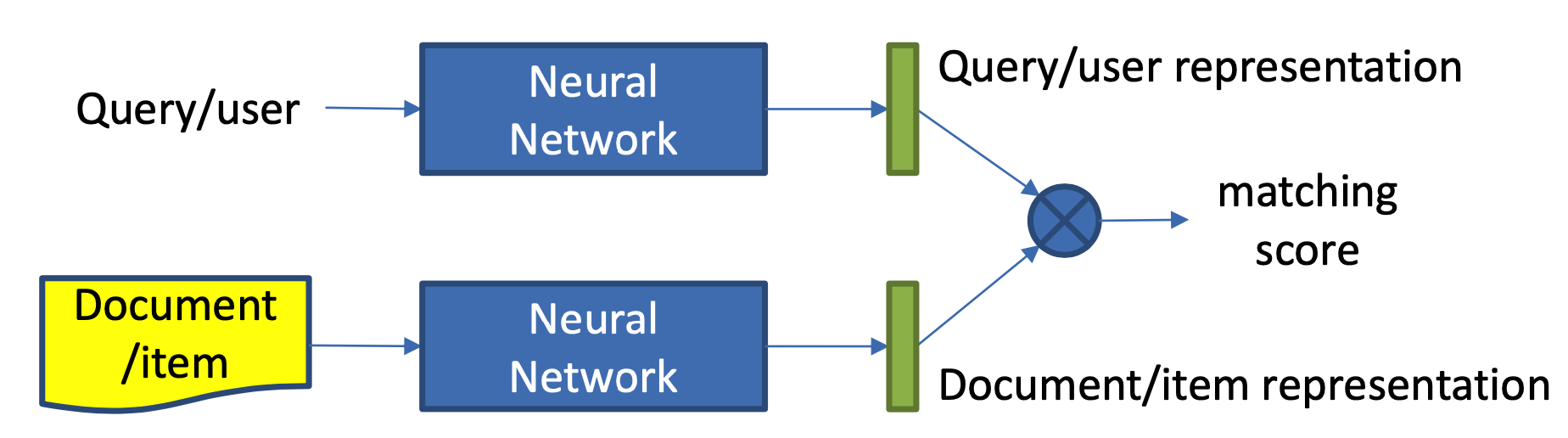
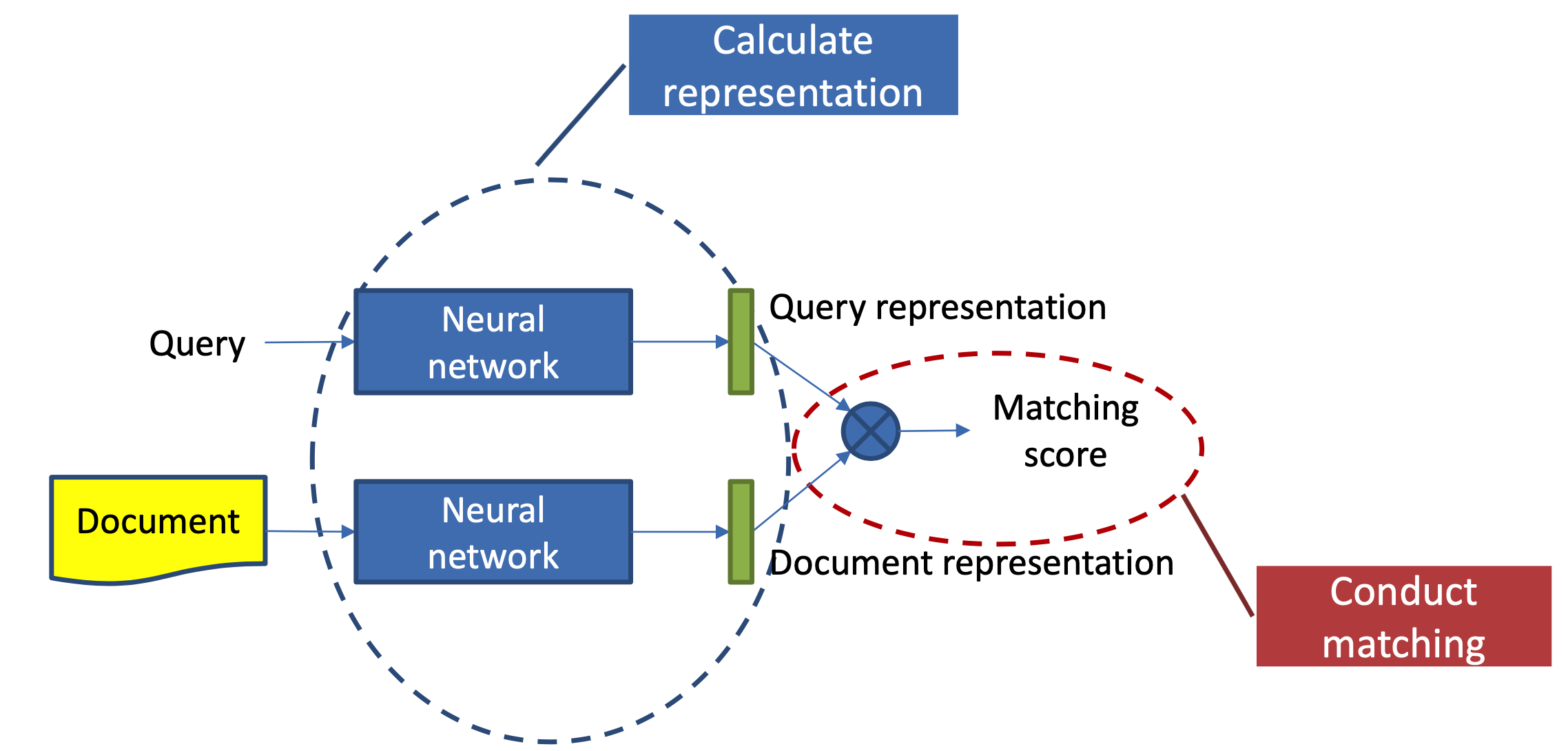
本章主要讲述第一种方法,representation learning,也就是基于表示学习的方法,这种方法会分别学习query和doc(放在推荐里就是user和item)的representation表示,然后通过定义matching score函数,例如简单点的做法有向量点积、cosine距离等来得到query和doc两者的匹配,整个representation learning的框架如图3.1所示,是个经典的双塔结构。
整个学习过程可以分为两步:
(1) 表示层:计算query和doc各自的representation,如图3.2中蓝色圈所示
(2) 匹配层:根据上一步得到的representation,计算query-doc的匹配分数,如图3.2中红色圈所示
因此,基于representation learning的深度匹配模型,无外乎围绕着表示层和匹配层进行模型结构的改造,其中大部分工作都集中在表示层部分。表示层的目的是为了得到query和doc的向量,在这里可以套用常用的一些网络框架,如DNN、CNN或者RNN等,本章也将沿着这3种框架进行表述。
representation learning匹配模型的特点是:
- 采用 Siamese 结构,共享网络参数。
- 对表示层进行编码,使用 CNN, RNN, Self-attention 均可。