Adapter tuning
Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。
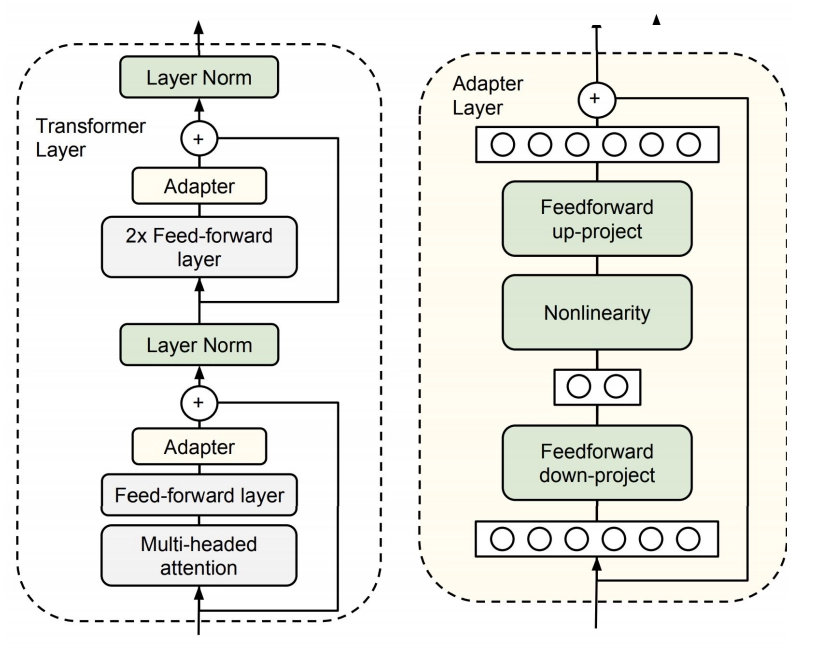
在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度\(d\)投影到\(m\),通过控制\(m\)的大小来限制Adapter模块的参数量,通常情况下\(m\ll d\)。在输出阶段,通过第二个前馈子层还原输入维度,将\(m\)重新投影到\(d\),作为Adapter模块的输出(如上图右侧结构)。通过添加Adapter模块来产生一个易于扩展的下游模型,每当出现新的下游任务,通过添加Adapter模块来避免全模型微调与灾难性遗忘的问题。Adapter方法不需要微调预训练模型的全部参数,通过引入少量针对特定任务的参数,来存储有关该任务的知识,降低对模型微调的算力要求。
缺点:需要修改原有模型结构,同时还会增加模型参数量。
Adapter算法改进
2020年,Pfeiffer J等人对Adapter进行改进,「提出AdapterFusion算法,用以实现多个Adapter模块间的最大化任务迁移」(其模型结构如下图所示)。
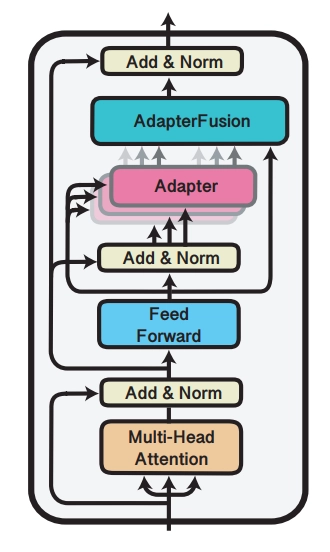
AdapterFusion将学习过程分为两个阶段:
- 「知识提取阶段」:训练Adapter模块学习下游任务的特定知识,将知识封装在Adapter模块参数中。
- 「知识组合阶段」:将预训练模型参数与特定于任务的Adapter参数固定,引入新参数学习组合多个Adapter中的知识,提高模型在目标任务中的表现。
其中首先,对于N个不同的下游任务训练N个Adapter模块。然后使用AdapterFusion组合N个适配器中的知识,将预训练参数\(Θ\) 和全部的Adapter参数 \(Φ\) 固定,引入新的参数 \(Ψ\),使用N个下游任务的数据集训练,让AdapterFusion学习如何组合N个适配器解决特定任务。参数 \(Ψ\) 在每一层中包含Key、Value和Query(上图右侧架构所示)。在Transformer每一层中将前馈网络子层的输出作为Query,Value和Key的输入是各自适配器的输出,将Query和Key做点积传入SoftMax函数中,根据上下文学习对适配器进行加权。在给定的上下文中,AdapterFusion学习经过训练的适配器的参数混合,根据给定的输入识别和激活最有用的适配器。(像MoE)
「作者通过将适配器的训练分为知识提取和知识组合两部分,解决了灾难性遗忘、任务间干扰和训练不稳定的问题。Adapter模块的添加也导致模型整体参数量的增加,降低了模型推理时的性能」。
Adapter Fusion 在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。作者对全模型微调(Full)、Adapter、AdapterFusion三种方法在各个数据集上进行和对比试验。AdapterFusion在大多数情况下性能优于全模型微调和Adapter,特别在MRPC(相似性和释义任务数据集)与RTE(识别文本蕴含数据集)中性能显著优于另外两种方法。
Prefix-Tuning
Paper: 2021.1 Optimizing Continuous Prompts for GenerationGithub:https://github.com/XiangLi1999/PrefixTuningPrompt: Continus Prefix PromptTask & Model:BART(Summarization), GPT2(Table2Text)

最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。
Prefix-Tuning可以理解是CTRL模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评前面加'Reviews Rating:5.0',差评前面加'Reviews Rating:1.0', 政治评论前面加‘Politics Title:’,把语言模型的生成概率,优化成了基于文本主题的条件概率。
Prefix-Tuning进一步把control code优化成了虚拟Token,每个NLP任务对应多个虚拟Token的Embedding(prefix),对于Decoder-Only的GPT,prefix只加在句首,对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头。在下游微调时,LM的参数被冻结,只有prefix部分的参数进行更新。不过这里的prefix参数不只包括embedding层而是虚拟token位置对应的每一层的activation都进行更新。

对于连续Prompt的设定,论文还讨论了几个细节如下
- prefix矩阵分解
作者发现直接更新多个虚拟token的参数效果很不稳定,因此作者在prefix层加了MLP,分解成了更小的embedding层 * 更大的MLP层。原始的Embedding层参数是n_prefix * emb_dim, 调整后变为n_prefix * n_hidden + n_hidden * emb_dim。训练完成后这部分就不再需要只保留MLP输出的参数进行推理即可 - prefix长度
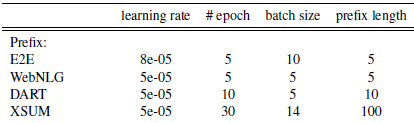
prefix部分到底使用多少个虚拟token,直接影响模型微调的参数量级,以及处理长文本的能力。默认的prefix长度为10,作者在不同任务上进行了微调,最优参数如下。整体上prompt部分的参数量都在原模型的~0.1%
- 其他:作者还对比了把prefix放在不同位置,以及使用任务相关的Token来初始化prefix embedding的设定,前者局限性较大,后者在后面的paper做了更详细的消融实验
效果上在Table2Text任务上,只有0.1%参数量级的prompt tuning效果要优于微调
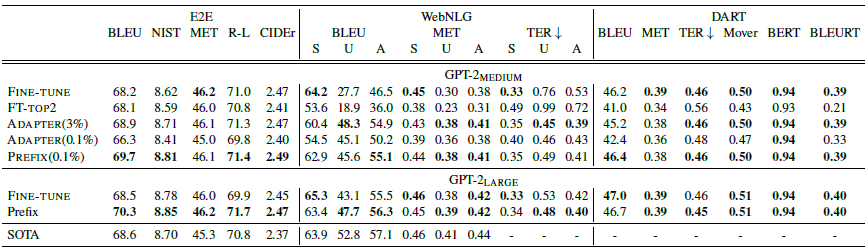
在Xsum摘要任务上,prompt的效果要略差于微调。

Promot Tuning
一切还是从BERT说起,当年Google提出BERT模型的时候,一个最大的贡献是使用了Masked Language Model(MLM),即随机掩盖输入序列的一个token,然后利用相邻的tokens预测这个token是什么,这样模型可以学会更好地理解上下文。
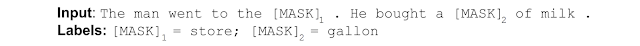
BERT这种训练方式让模型在文本生成方面有很强的能力,因此,大家发现有时候不一定需要做fine-tuning即可让模型帮我们解决感兴趣的任务。只要我们把希望输出的部分删除掉,然后尽量构造与该输出有关的其它tokens即可。这就是prompt-tuning的一种想法!
与输出相关的tokens组成的上下文信息即可理解为是一个prompt。Prompt通常是一种短文本字符串,用于指导语言模型生成响应。Prompt提供上下文和任务相关信息,以帮助模型更好地理解要求,并生成正确的输出。例如,在问答任务中,prompt可能包含问题或话题的描述,以帮助模型生成正确的答案。Prompt通常是人类设计的,以帮助模型更好地理解特定任务或领域。
简单总结就是说Prompt就是利用语言模型的生成能力帮我们完成任务。而Prompt-tuning的目的就是设计更加精巧的prompt,然后让模型输出我们想要的内容。
以句子的情感分类为例,基于prompt方式让模型做情感分类任务的做法通常是在句子前面加入前缀“该句子的情感是”即可。
本质上BERT这样的模型是一种生成模型,是无法完成特定任务的。它只是一个提取文本特征的通用模型。
当你在句子前加入“该句子的情感是”这样的前缀,你实际上是将情感分类任务转换为一个“填空”任务。这是因为,在训练过程中,BERT可以学习到这个前缀与句子情感之间的关联。例如,它可以学习到“该句子的情感是积极的”和“该句子的情感是消极的”之间的差异。
甚至是到GPT-3的时候,大模型的主要能力还是利用模型生成的能力完成任务。尽管GPT-3模型在很多任务中都表现非常好,但是官方的博客和Google都在论文中说明了GPT-3的生成模型在few-shot方面表现非常remarkable,但是在zero-shot上表现很一般,也就是因为这种生成模式只能通过设计精巧的Prompt来让模型去做完形填空。因此,在few-shot里面它的能力依然很强,而在zero-shot中表现一般。
具体方法
Prompt Tuning设计了一种prefix prompt方法,即在模型输入的token序列前添加前缀prompt token,而这个前缀prompt token的embedding是由网络学到。
Prompt Tuning可以看做token已经确定,但是embedding是可以学的。
它相当于仅用prompt token的embedding去适应下游任务,相比手工设计或挑选prompt,它是一种Soft的prompt(软提示)
给定\(𝑛\)个token组成的输入序列 \({{x}{1} , {x}{2}, \ldots,{x}_{n}}\) ,其对应token embedding矩阵为 \(\mathbf{X}_{e} \in \mathbb{R}^{n \times d}\),𝑑代表嵌入维度。
Soft-prompts对应参数\(\mathbf{P}_{e} \in \mathbb{R}^{p \times d}\),𝑝 代表prompt的长度。
然后,将prompt拼接到输入前面,就能得到完整的模型输入 \([\mathbf{P}_{e} ; \mathbf{X}_{e}] \in \mathbb{R}^{(p+n) \times d}\)。

这个新的输入将会送入模型\(f([\mathbf{P}; \mathbf{X}]; \Theta, \Theta_{p})\),以最大化交叉熵损失来最大化条件概率 \(Pr_{\Theta, \Theta_{p}}(\mathbf{Y} | [\mathbf{P}; \mathbf{X}])\),以拟合其标签token序列 𝑌。
在针对下游任务微调时,Prompt Tuning将冻结原始LLM的参数,只学习独立的prompt token参数(参数化的prompt token加上输入的token送入模型进行前向传播,反向传播只更新prompt token embedding的参数)。
在针对不同的下游任务微调时,就可以分别学习不同的Task Specifical的Prompt Token参数。
- Soft Prompt Tuning在模型增大时可以接近Model Tuning(fine-tuning)的效果
- 离散Prompt Tuning(Prompt Design)基本不能达到Model Tuning的效果

Promot Tuning方法的参数成本是 𝑒𝑑,其中 𝑒 是提示长度,𝑑是token嵌入维度。提示越短,必须调整的新参数就越少,那么调参的目标是就是找到表现仍然良好的最小prefix prompt长度。
Promot Tuning在输入序列前缀添加连续可微的软提示作为可训练参数,其缺点在于:由于模型可接受的最大输入长度有限,随着软提示的参数量增多,实际输入序列的最大长度也会相应减小,影响模型性能。
看到这里可以知道,Prefix-Tuning可以算是Promot Tuning的一个特例(Promot Tuning只在输入侧加入可学习的Prefix Prompt Token,Prefix-Tuning推广到Transformer Layer每一层的\(K\)、\(V\)上)
Instruction-Tuning
与Prompt不同,Instruction通常是一种更详细的文本,用于指导模型执行特定操作或完成任务。Instruction可以是计算机程序或脚本,也可以是人类编写的指导性文本。Instruction的目的是告诉模型如何处理数据或执行某个操作,而不是简单地提供上下文或任务相关信息。
因此,Prompt和Instruction都是用于指导模型生成输出的文本,但它们的目的和使用方式是不同的。Prompt更多地用于帮助模型理解任务和上下文,而Instruction则更多地用于指导模型执行具体操作或完成任务。
Instruction-Tuning这种方法Google和OpenAI几乎都同时使用了。
Google Research在2021年的论文《Finetuned Language Models Are Zero-Shot Learners》中提出了instruction-tuning。Google认为instruction-tuning是一种简单的方法来提高语言模型的zero-shot学习能力。

指令微调的动机是提高语言模型对自然语言处理指令的响应能力。这个想法是,通过使用监督来教授语言模型执行通过指令描述的任务,模型将学会遵循指令,即使是对于未见过的任务也能如此。
而OpenAI在InstructGPT中也是类似的想法!InstructGPT就是ChatGPT的前身!

Instruction可以提供更直接的任务指导,以帮助模型执行任务。对于问答任务,Instruction可以提供具体的指令,例如“请回答下列问题:谁是美国第一位总统?”,并将文本段落作为输入提供给模型。
以InstructGPT为例,其基本流程如下:
- 准备自然语言指令集:针对特定任务,准备一组自然语言指令,描述任务类型和任务目标,例如情感分类任务的指令可以是“该文本的情感是正面的还是负面的?”。
- 准备训练数据集:针对特定任务,准备一个标记化的数据集,其中每个数据样本都包含输入文本和标签,例如情感分类任务的标签可以是“正面”或“负面”。
- 将自然语言指令和数据集转换为模型输入:将自然语言指令和数据集转换为模型输入,例如对于情感分类任务,将自然语言指令和文本拼接作为输入,例如:“该文本的情感是正面的还是负面的?这家餐厅的食物很好吃。”
- 在指令上进行微调:在指令上进行微调,以适应特定任务的需求,提高模型在任务上的性能。
这样的方式训练了出来的模型可以让模型更好地识别输入的意图,同时也在zero-shot中表现更好!
而Instruction-tuning的主要思想就是在输入阶段对指令做调整以其适合更好地模型输出!
GPT-4生成的使用Instruction-Tuning微调GPT-4的案例
这是GPT-4给出的如何使用Instruction-Tuning微调GPT-4的案例。
Instruction-tuning 是一种微调大型预训练语言模型(如 GPT-4)的方法,可以让模型根据特定任务提供指令来执行任务。在这个具体的情感分类案例中,我们将使用 instruction-tuning 来对给定的文本进行情感分析。我们的目标是根据文本内容,判断其情感是正面、负面还是中性。以下是一个简单的指南:
- 准备数据集:
首先,你需要一个带有标签的文本数据集,以便在情感分类任务上微调模型。数据集应该包含多个实例,每个实例都有一段文本和一个对应的情感标签(正面、负面或中性)。数据集可以是开源的,如 IMDB 电影评论数据集,也可以是你自己收集和标注的数据。
- 数据预处理:
将文本和情感标签转换为适用于 GPT-4 模型的格式。例如,将文本和情感标签拼接在一起,用特定的分隔符(如 “|||”)分隔。如下所示:
文本1 ||| 标签1文本2 ||| 标签2文本3 ||| 标签3- 微调 GPT-4 模型:
使用准备好的数据集和拼接格式,对 GPT-4 模型进行 instruction-tuning。在训练过程中,模型将学习如何根据输入文本预测相应的情感标签。
- 模型测试和评估:
在微调后,使用测试数据集(不包含在训练数据集中的数据)对模型进行测试。输入文本并观察模型生成的情感标签,然后与实际标签进行比较,计算准确率、召回率等性能指标。
- 使用微调后的模型进行情感分类:
在实际应用中,当你需要对给定的文本进行情感分类时,可以这样使用微调后的 GPT-4 模型:
输入:这部电影的剧情令人惊叹,特效也非常出色,我非常喜欢。输出:正面通过 instruction-tuning,GPT-4 模型能够根据输入文本生成对应的情感标签,从而实现情感分类任务。
Chain-of-Thought(CoT)
Chain-of-thought 是一种处理复杂问题或执行多步骤任务的技巧,通常用于大型预训练语言模型中。这种方法允许模型在多个步骤中生成连贯的回答,从而更好地解决问题或完成任务。
在 chain-of-thought 方法中,模型的输出被视为一个序列,每个部分都是一个独立的“思考链”或步骤。模型通过将先前的输出作为后续输入的一部分来迭代地生成这些部分,这样可以让模型在一定程度上模拟人类解决问题的过程。
以下是一个简单的示例,说明语言模型如何解决一个数学问题:
问题:计算 3 * (4 + 5)
使用 chain-of-thought,我们可以将问题分解成以下步骤:
- 将问题输入模型:“计算 3 * (4 + 5)”
- 模型输出第一步的结果:“计算 4 + 5”
- 将上一步的结果作为输入,再次输入模型:“计算 3 * 9”
- 模型输出最终结果:“结果是 27”
在这个例子中,我们可以看到模型是如何通过一系列连贯的思考链(步骤)来逐步解决问题的。那么这样的能力是如何获得的?这就是chain-of-thought技术。通过思维链式方法训练大型语言模型需要将训练过程分解成较小、相互关联的任务,以帮助模型理解和生成连贯、上下文感知的响应。以GPT-3为例,以下是一些步骤,可以用Chain-of-thought方法训练一个更先进的GPT-3模型:
- 收集大量的语料库,包括各种主题和风格的文本。可以从各种来源获取数据,如网站、社交媒体、新闻、书籍等。
- 对语料库进行预处理,包括分词、标记化、去除停用词、处理语法结构等。
- 定义一个上下文窗口,即模型需要考虑的前面和后面的文本内容。
- 将训练过程分解为一系列逐步更复杂的子任务。例如,可以将训练过程分解为理解语法和词汇、生成单词和短语、生成连贯的句子和段落、理解上下文等子任务。
- 为每个子任务定义适当的训练目标和损失函数,并使用训练数据来训练模型。例如,为了训练模型理解上下文,可以定义一个损失函数,它评估模型生成的响应与上下文的相关性。
- 在训练完成后,使用测试数据来评估模型的性能。例如,检查模型是否能够生成连贯的响应,以及是否能够维护文本中的思维链。
- 迭代地对模型进行微调和优化。
可以看到,在Chain-of-thought训练中,将数据集中的输入分解为一系列任务是非常关键的一步。一般来说,这个过程需要根据特定的任务和数据集来进行定制。以下是一些通用的方法:
- 首先,需要定义一个目标任务,即要求模型完成的最终任务。例如,如果目标任务是自然语言生成,那么数据集中的输入可能是一句话或一个段落,模型需要将其转化为自然语言响应。
- 然后,需要将目标任务分解为一系列子任务。这些子任务应该是相互关联的,每个子任务的输出都可以作为下一个子任务的输入。例如,在自然语言生成任务中,可以将其分解为理解输入的语义、确定输出的语法结构、生成文本等子任务。
- 每个子任务的输入和输出都需要定义。例如,在自然语言生成任务中,输入可能是一组与上下文相关的单词,输出可能是下一个单词或整个句子。
- 每个子任务都需要为其定义一个训练目标和相应的损失函数。这些目标和损失函数应该与任务相关,并帮助模型学习与该任务相关的知识。
- 最后,需要将所有子任务组合起来,构建一个完整的模型。每个子任务的输出都将成为下一个子任务的输入,直到完成目标任务。
需要注意的是,如何分解数据集中的输入取决于特定的任务和数据集。一个好的分解方案应该具有适当的层次结构,使得模型能够在学习过程中逐步掌握更加复杂的任务。在实际应用中,可能需要进行多次尝试和调整,才能找到最优的分解方案。
尽管 chain-of-thought 方法在处理一些复杂问题时可能有所帮助,但它并非万能的。有时,模型可能无法生成正确的答案,或者在多次迭代中陷入死循环。
总之,chain-of-thought 是一种有效的技巧,可以帮助大型预训练语言模型在多步骤任务和复杂问题中生成连贯的输出。然而,在实际应用中,可能需要结合其他技巧来克服其局限性,以实现更好的性能。
小结
Prompt-tuning、instruction-tuning和chain-of-thought都是用于训练大型语言模型的方法,它们都有助于提高模型的生成能力和上下文理解能力,但是它们的方法和目的略有不同。
- Prompt-tuning:Prompt-tuning是一种使用自然语言提示(prompt)的方法,以指导模型生成特定的输出。这种方法的目的是通过对模型进行定向训练,使其在特定任务上表现出更好的性能。与其他方法不同,Prompt-tuning的重点在于设计良好的提示,这些提示可以引导模型生成准确、上下文相关的响应。
- Instruction-tuning:Instruction-tuning是一种通过为模型提供任务相关的指令来指导模型学习的方法。这种方法的目的是使模型更好地理解任务的要求,并提高其生成能力和上下文理解能力。Instruction-tuning通常需要较少的训练数据,并且可以提高模型的泛化性能。
- Chain-of-thought:Chain-of-thought是一种通过分解训练过程为较小的相互关联的任务来训练模型的方法。这种方法的目的是使模型能够理解和维护文本中的思维链,从而生成连贯的、上下文相关的响应。与其他方法不同,Chain-of-thought的重点在于将训练过程分解为一系列逐步更复杂的任务,并使用注意机制来帮助模型集中于相关的部分。
总之,这些方法都有助于提高大型语言模型的生成能力和上下文理解能力,但是它们的方法和目的略有不同。Prompt-tuning和instruction-tuning通常用于特定任务的优化,而Chain-of-thought通常用于提高模型的生成能力和上下文理解能力。
LoRA
LoRA(Low-Rank Adaptation of LLMs),即LLMs的低秩适应,被提出用于高效参数微调。
LoRA的核心思想,是假设LLM在下游任务上微调得到的增量参数矩阵 \(Δ𝑊\) 是低秩的,即是存在冗余参数的高维矩阵,但实际有效矩阵是更低维度的。
相关论文表明训练学到的过度参数化的模型实际上存在于一个较低的内在维度上。类似于机器学习中的降维算法,假设高维数据实际是在低维的流形上一样。
Lora架构
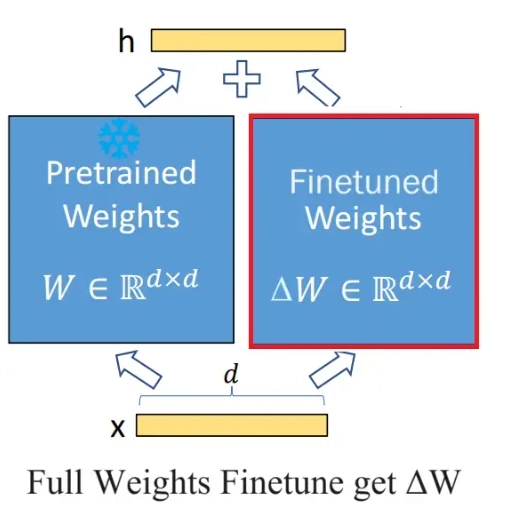
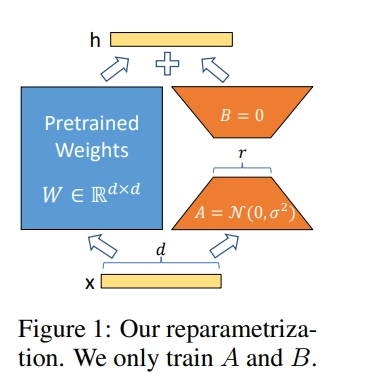
左侧为全参数微调,右侧为Lora微调
全参数微调会优化LLM的所有参数。这相当于在LLM的原始权重 \(\mathbf{W}_{0} \in \mathbb{R}^{d \times d}\) 上,加上一个了微调增量参数\(\Delta \mathbf{W} \in \mathbb{R}^{d \times d} \)(相当于冻结原始权重,插入增量参数并仅对做优化)。
对于全参数微调后的LLM权重,给定输入\(𝑥\),其输出为下式:
既然,对增量参数矩阵 \(Δ𝑊\)有低秩假设, 那么在微调LLM时,完全可以对每一层的参数,加入参数\(𝐵\) 和 \(𝐴\) 对增量参数\(Δ𝑊\) 进行来低秩近似,同时只训练参数\(𝐵\) 和 \(𝐴\)。这就是上图右侧的Lora微调。
这样一来,在微调过程中,可训练的参数量大大减少(使得微调参数量从 \(𝑑×𝑑\) 降低至 \(2𝑟𝑑\) , 有 \(𝑟\ll 𝑑\) )
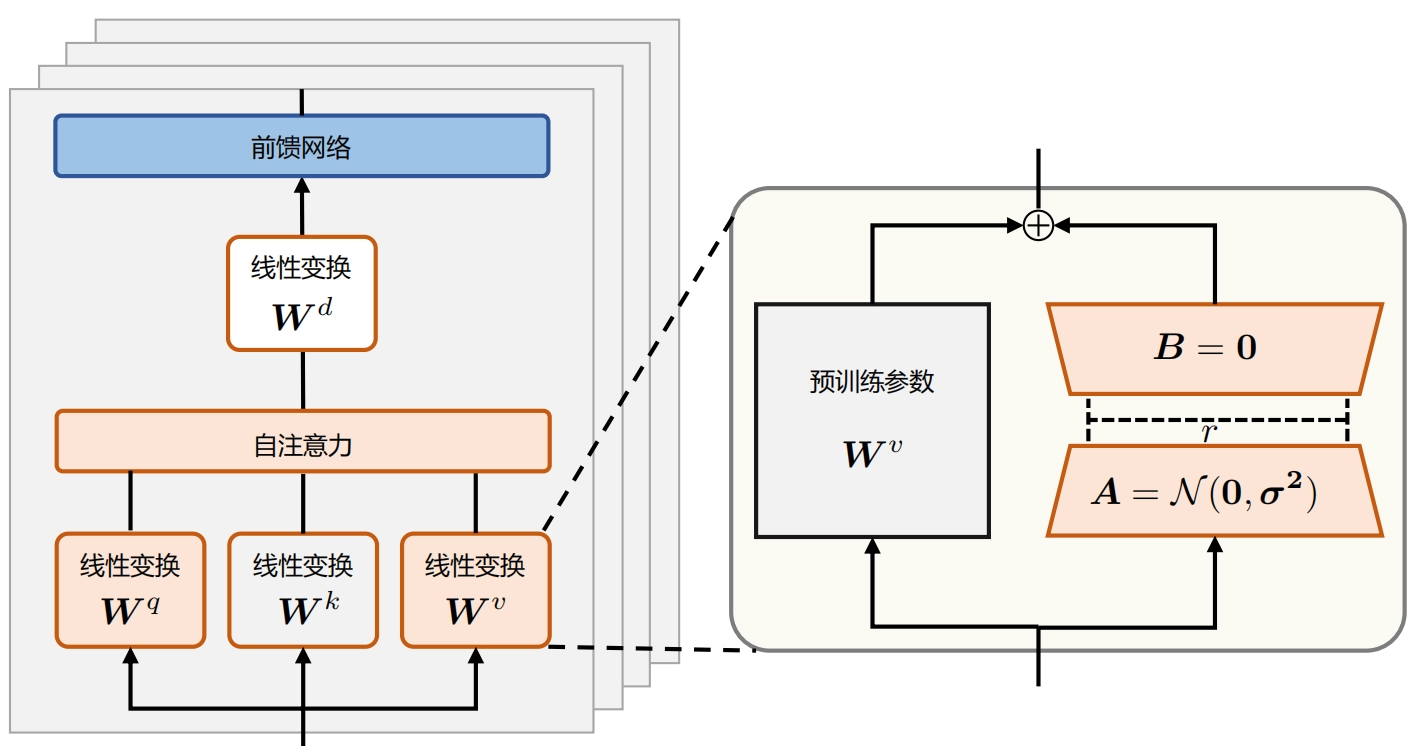
具体来说,LoRA将\(\Delta \mathbf{W} = \mathbf{B} \mathbf{A} \in \mathbb{R}^{d \times d} \) 用两个更小的参数矩阵进行低秩近似,其中 \(𝑟\) 是LoRA的需要近似\(Δ𝑊\) 的秩的维度,\(\mathbf{B}\in \mathbb{R}^{d\times r}\) 和 \(\mathbf{A}\in \mathbb{R}^{r \times d}\)。
在LoRA微调时,冻结预训练的模型权重 \(\mathbf{W}_{0} \in \mathbb{R}^{d \times d}\),并将可训练的LoRA低秩分解矩阵注入到LLM的每个Transformer Decoder层中。在训练时,只优化所有的 𝐵 和 𝐴 矩阵,从而大大减少了下游任务的可训练参数量。
对于该权重的输入𝑥来说,输出为下式:
LoRA参数初始化时,矩阵 \(𝐴\) 通过高斯函数初始化。矩阵 𝐵 为全零初始化,其目的是希望训练开始之前旁路对原模型不造成影响(带来噪声),即参数改变量为0。
对于使用LoRA的模型来说,由于可以将原权重与训练后权重合并,因此在推理时不存在额外的开销。
PEFT对LORA的实现
接下来是代码部分,我们以HF的PEFT(当前版本0.2.0)为例,介绍一下LORA是如何作用在HF模型上的。
以LORA为例,PEFT模型的使用非常方便,只需要按照原本的方式实例化模型,然后设置一下LORA的config,调用一下get_peft_model方法,就获得了在原模型基础上的PEFT模型,对于LORA策略来讲,就是在某些参数矩阵W的基础上增加了矩阵分解的旁支。在下面的例子中,选择了attention中的q和v的部分做LORA。
# 设置超参数及配置
LORA_R = 8
LORA_ALPHA = 16
LORA_DROPOUT = 0.05
TARGET_MODULES = [
"q_proj",
"v_proj",
]
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=TARGET_MODULES,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
# 创建基础transformer模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
# 加入PEFT策略
model = get_peft_model(model, config)简单介绍一下Lora config相关的配置:
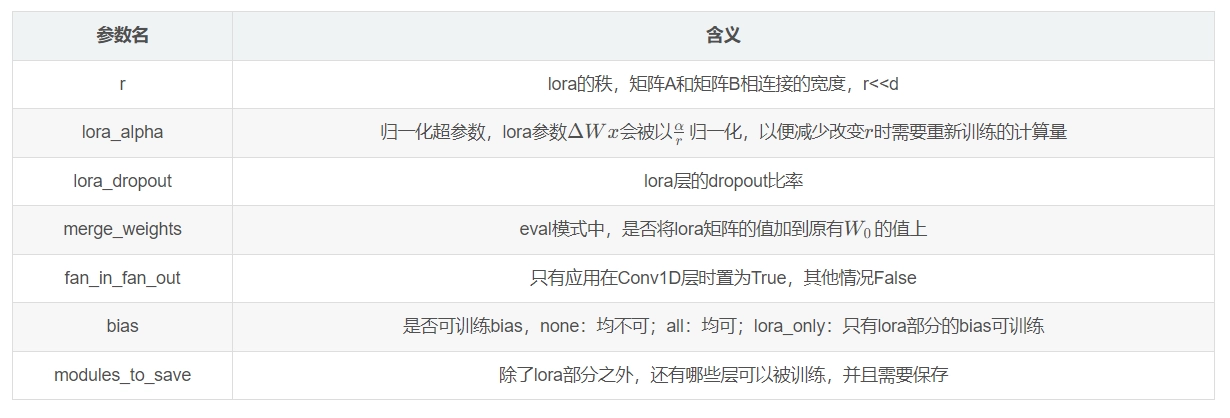
具体参数可参考:https://huggingface.co/docs/peft/package_reference/lora#peft.LoraConfig
接下来,结合PEFT模块的源码,来看一下LORA是如何实现的。
在PEFT模块中,peft_model.py中的PeftModel类是一个总控类,用于模型的读取保存等功能,继承了transformers中的Mixin类,我们主要来看LORA的实现:
上面是比较新的代码,已经融合了很多的方法,并且做了很多工程化的东西,读起来比较复杂,这里就看比较早之前的一份代码
class LoraModel(torch.nn.Module):
def __init__(self, config, model):
super().__init__()
self.peft_config = config
self.model = model
self._find_and_replace()
mark_only_lora_as_trainable(self.model, self.peft_config.bias)
self.forward = self.model.forward从构造方法可以看出,这个类在创建的时候主要做了两件事:
- _find_and_replace: 找到所有需要加入lora策略的层,例如q_proj,把它们替换成lora模式;
- 保留lora部分的参数可训练,其余参数全都固定下来不动。
_find_and_replace的逻辑很清晰,就是先找到需要的做lora的层,然后创建lora层把它替换掉。这里把关键语句列出如下:
找目标层:
# 其中的target_modules在上面的例子中就是"q_proj","v_proj"
# 这一步就是找到模型的各个组件中,名字里带"q_proj","v_proj"的
target_module_found = re.fullmatch(self.peft_config.target_modules, key)然后对于每一个找到的目标层,创建一个新的lora层:
# 注意这里的Linear是在该py中新建的类,不是torch的Linear
new_module = Linear(target.in_features, target.out_features, bias=bias, **kwargs)最后调用_replace_module方法替换掉原来的linear:
self._replace_module(parent, target_name, new_module, target)其中这个replace的方法并不复杂,就是把原来的weight和bias赋给新创建的module,然后再分配到指定的设备上:
def _replace_module(self, parent_module, child_name, new_module, old_module):
setattr(parent_module, child_name, new_module)
new_module.weight = old_module.weight
if old_module.bias is not None:
new_module.bias = old_module.bias
if getattr(old_module, "state", None) is not None:
new_module.state = old_module.state
new_module.to(old_module.weight.device)
# dispatch to correct device
for name, module in new_module.named_modules():
if "lora_" in name:
module.to(old_module.weight.device)接下来主要看一下Lora层的实现,首先是Lora的基类,可以看出这个类就是用来构造Lora的各种超参数用:
class LoraLayer:
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
self.disable_adapters = False然后就要讲到上文中所提到的Linear类,也就是Lora的具体实现,它同时继承了nn.Linear和LoraLayer。
class Linear(nn.Linear, LoraLayer):
# Lora implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs,
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Linear(in_features, r, bias=False)
self.lora_B = nn.Linear(r, out_features, bias=False)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.T在构造方法中,除了对各个超参数进行配置之外,还对所有参数进行了初始化,定义如下:
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, "lora_A"):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
nn.init.zeros_(self.lora_B.weight)其中lora的A矩阵采用了kaiming初始化,是Xavier初始化针对非线性激活函数的一种优化;B矩阵采用了零初始化,以确保在初始状态 \( \Delta W =BA\) 为零。(值得注意的是在LORA的论文中,A采用的是Gaussian初始化)。
对于train和eval方法,放在一起介绍,它主要是需要对merge状态进行记录:
def train(self, mode: bool = True):
nn.Linear.train(self, mode)
self.lora_A.train(mode)
self.lora_B.train(mode)
if not mode and self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = True
elif self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = False
def eval(self):
nn.Linear.eval(self)
self.lora_A.eval()
self.lora_B.eval()首先对于新定义的这个Linear层,其本身继承了torch.nn.Linear,所以需要调用nn.Linear.train(self, mode)来控制一下自身原本参数的状态,并且此外它加入了lora_A和lora_B两部分额外的参数,这两部分本质上也是nn.Linear,也需要控制状态。
然后主要来理解一下merge_weights是在做什么,也就是看train中的if分支,not mode说明是eval模式,而self.merge_weights在上文中有介绍,是配置文件中的,意思是评估时是否需要将lora部分的weight加到linear层原本的weight中,not self.merged是状态的记录,也就是说,如果设置了需要融合,而当前状态没有融合的话,就把lora部分的参数scale之后加上去,并且更新self.merged状态;在elif分支中,是为了在训练的过程中,确保linear本身的weights是没有经过融合过的(理论上这一步应该是在eval之后的下一轮train的第一个step触发)。
至于为什么是在train中涉及merge_weights,其实在torch的源码中,nn.Linear.eval()实际上是调用了nn.Linear.train(mode=False),所以这里train方法中的merge_weigths,实际上是在eval中也发挥作用的。
forward中也是类似的原理,正常情况下训练过程应该是走elif的分支:
def forward(self, x: torch.Tensor):
if self.disable_adapters:
if self.r > 0 and self.merged:
self.weight.data -= (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = False
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
elif self.r > 0 and not self.merged:
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
if self.r > 0:
result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
return result
else:
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)在了解了这些基本原理之后,就可以类似地去实现更多更加灵活的功能了,例如对transformer的某些层增加lora,而其余的层保持不变等。
LST
论文地址: https://papers.cool/arxiv/2206.06522
论文提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?
这里借用此文中的配图,来说明一下,在LORA之前的常见的Memory Efficient Transfer Learning方法。
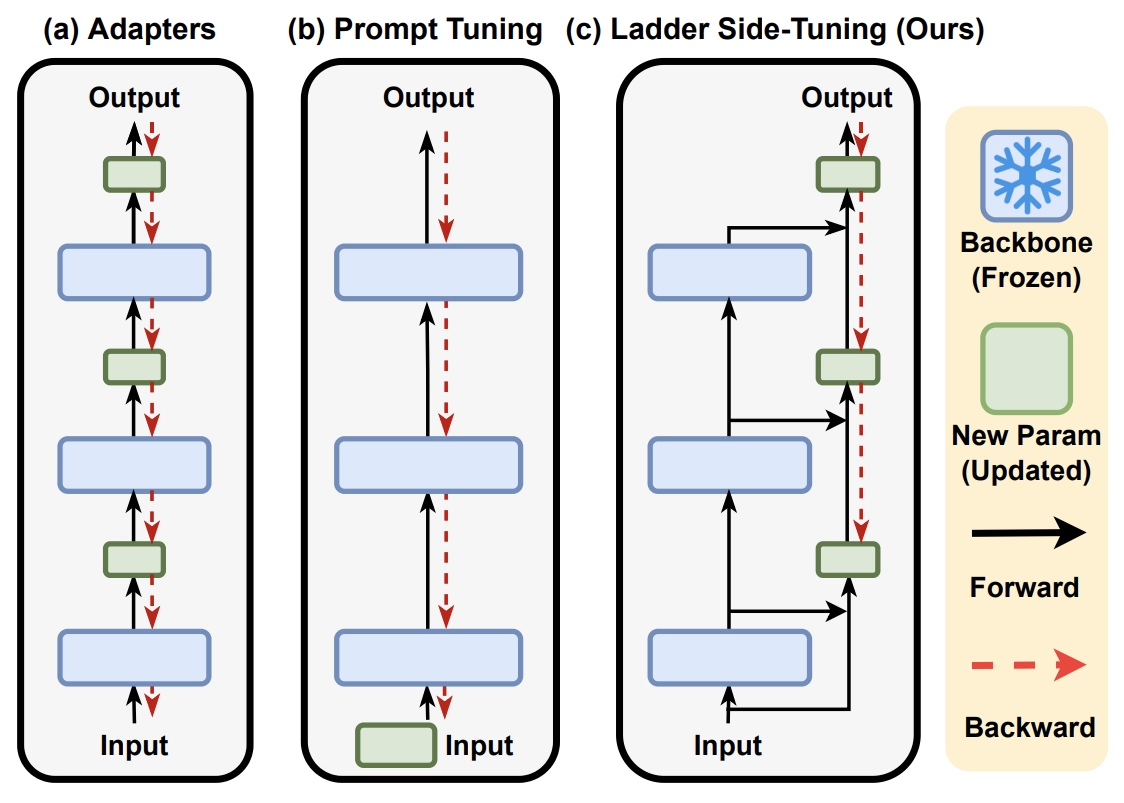
反向传播,也就是求模型梯度,是从输出层向输入层逐步计算的,因此反向传播的深度/计算量,取决于最靠近输入层的参数深度,跟可训练的参数量没有太必然的联系。对于Adapter来说,它在每一层后面都插入了一个小规模的层,虽然其余参数都固定了,只有新插入的层可训练,但每一层都新层,所以反向传播要传到输入层;对于P-tuning来说,本质上它是只有在Embedding层中有少量可训练参数,但Embedding层是输入层,因此它的反向传播也要贯穿整个模型。因此,这两种方案能提升的训练效率并不多。
至于LST,它是在原有大模型的基础上搭建了一个“旁支”(梯子),将大模型的部分层输出作为旁枝模型的输入,所有的训练参数尽在旁枝模型中,由于大模型仅提供输入,因此反向传播的复杂度取决于旁枝模型的规模,并不需要直接在原始大模型上执行反向传播,因此是可以明显提升训练效率的。
实验效果
原论文做了不少LST的实验,包括NLP、CV的,下面是LST在GLUE数据集上的效果:
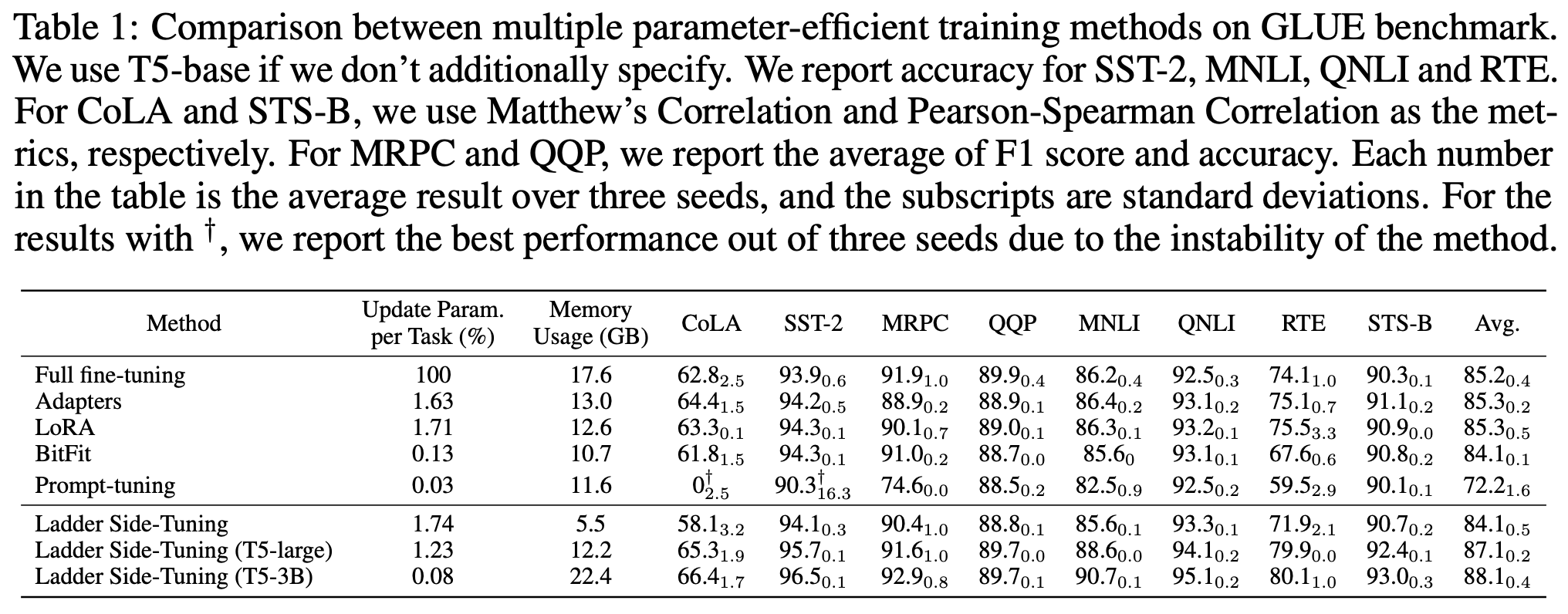
可以看到,LST确实具备了参数高效和训练高效的特点,能够在较小的训练参数和训练成本的情况下,达到一个不错的微调效果。特别是最后两行的实验结果,体现出了LST在有限训练资源下微调大模型的可能性。
与LORA的区别
LST与LORA类似,在原有参数矩阵的一侧增加了一个旁支通路,但是二者有些许区别:
- LORA是将上一步的输入,在分支的时候,分别经过原有参数(类似于图中蓝色部分),以及旁支的通路(绿色可训练参数),二者之间是类似平等的,然后再将结果相加,作为下一层的输入;
- LST是在将输入先经过原有参数,再与输入本身相加,一起送入旁支通路。
基于Lora的优化
LoRA+
论文:LoRA+: Efficient Low Rank Adaptation of Large Models
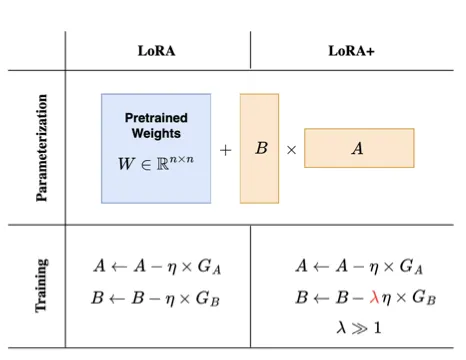
LoRA+ 引入了一种更高效的 LoRA 适配器训练方法,即为矩阵 \(A\) 和 \(B\) 设置不同的学习率。通常情况下,训练神经网络时,所有权重矩阵都使用相同的学习率。然而,对于 LoRA 中使用的适配器矩阵,LoRA+ 的作者证明,使用单一学习率并非最优。通过将矩阵 \(B\) 的学习率设置得远高于矩阵 \(A\) 的学习率,可以显著提高训练效率。
理论上,这种方法是合理的,其主要依据是神经网络初始化时,当模型神经元数量非常多时,其数值特性会受到限制。然而,证明这一点所需的数学推导相当复杂(如果您对此感兴趣,可以参考原始论文)。直观地讲,您可能会认为初始化为零的矩阵 \(B\) 可以使用比随机初始化的矩阵 \(A \)更大的更新步长。此外,经验证据也表明这种方法确实有效。通过将矩阵 \(B\) 的学习率设置为矩阵 \(A \)的 16 倍,作者成功地将模型准确率略微提高了约 2%,同时将 RoBERTa 或 Llama-7b 等模型的训练速度提高了一倍。
VeRA
论文:Vera: Vector-based random matrix adaptation
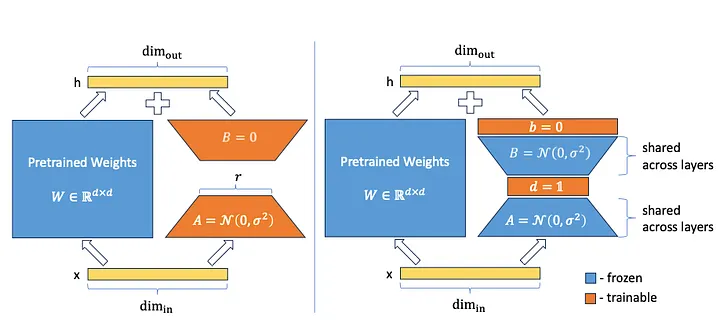
VeRA (Vector-based Random Matrix Adaptation) 提出了一种大幅减少 LoRA 适配器参数规模的方法。与 LoRA 的核心思想——训练矩阵 \(A\) 和 \(B\) 不同,他们使用共享的随机权重初始化这些矩阵(即所有层中的所有矩阵 \(A\) 和 \(B\) 都具有相同的权重),并添加两个新向量 \(d\) 和 \(b\)。后续训练仅使用这两个向量 \(d\) 和 \(b\)。
你可能会好奇这究竟是如何运作的。\(A\) 和 \(B\) 是随机权重矩阵。如果它们根本没有经过训练,又如何能对模型的性能做出贡献呢?这种方法基于一个有趣的研究领域——所谓的随机投影。大量研究表明,在大型神经网络中,只有一小部分权重被用来引导模型的行为,并使其在训练任务上达到预期的性能。由于采用了随机初始化,模型的某些部分(或子网络)从一开始就对模型的预期行为贡献更大。然而,在训练过程中,所有参数都会被训练,因为此时已经知道哪些子网络是重要的。这使得训练成本非常高昂,因为大多数更新的参数对模型的预测没有任何帮助。
基于此思路,存在一些方法可以仅训练这些相关的子网络。类似的效果也可以通过不训练子网络本身,而是在矩阵之后添加投影向量来实现。由于矩阵与向量相乘,这可以产生与调整矩阵中某些稀疏参数相同的输出。这正是 VeRA 的作者所提出的,他们引入了向量 \(d\) 和 \(b\),并对它们进行训练,而矩阵 \(A\) 和 \(B\) 则保持固定。此外,与原始 LoRa 方法不同的是,矩阵 \(B\) 不再被设置为零,而是像矩阵 \(A\) 一样随机初始化。
这种方法自然而然地导致参数数量远小于完整的矩阵 \(A\) 和 \(B\)。例如,如果将秩为 16 的 LoRa 层引入 GPT-3,则会产生 7550 万个参数。而使用 VeRA,参数数量仅为 280 万(减少了 97%)。但是,如此少的参数数量性能如何呢?VeRA 的作者使用一些常用的基准测试(例如 GLUE 或 E2E)以及基于 RoBERTa 和 GPT2 Medium 的模型进行了评估。结果表明,VeRA 模型的性能仅略低于经过完全微调或使用原始 LoRa 技术的模型。
LoRA-FA
论文:Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning
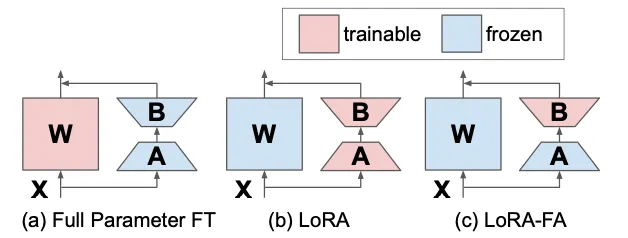
另一种方法 LoRA-FA,即 LoRA with F rozen- A, 与 VeRA 的方向类似。在 LoRA-FA 中,矩阵 \(A\) 在初始化后被冻结,因此可以作为随机投影。与添加新向量不同,矩阵 \(B\) 在初始化为零后(与原始 LoRA 相同)进行训练。这使得参数数量减半,同时性能与普通 LoRA 相当。
LoRa-drop
论文:LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation
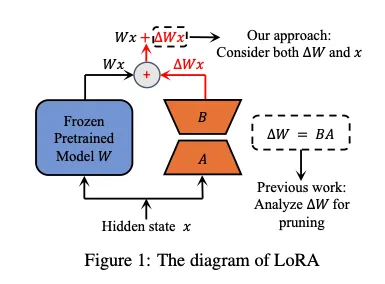
可以将 LoRA 矩阵添加到神经网络的任何一层。LoRA -drop 引入了一种算法,用于判断哪些层值得用 LoRA 进行增强,哪些层则不值得。尽管训练 LoRA 适配器比微调整个模型要便宜得多,但添加的 LoRA 适配器越多,训练成本就越高。
LoRA-drop 包含两个步骤。
- 对数据进行抽样,并对 LoRA 适配器进行几次迭代训练。
- 计算每个 LoRA 适配器的重要性,公式为 \(B*A*x\),其中 \(A\) 和 \(B\) 是 LoRA 矩阵,\(x\) 是输入。
这实际上是将每个 LoRA 适配器的输出加到冻结层的输出上。如果该输出值较大,则表明该适配器对冻结层的行为影响较大;如果输出值较小,则表明该 LoRA 适配器对冻结层的影响很小,可以忽略不计。
鉴于这些层的重要性,现在你需要选择最重要的 LoRa 层。有多种方法可以做到这一点。你可以将重要性值相加,直到达到一个阈值(该阈值由超参数控制),或者你可以直接选取重要性最高的 \(n\) 个 LoRa 层(\(n\) 为固定值)。无论采用哪种方法,下一步你都将对整个数据集进行完整训练(请记住,之前的步骤你使用的是数据子集),但仅针对你刚刚选择的那些层。其他层将使用一组固定的共享参数,这些参数在训练过程中将不再更改。
因此,LoRA-drop 算法允许仅使用 LoRA 层的一个子集来训练模型。作者提供的实证证据表明,与训练所有 LoRA 层相比,准确率仅有微小的变化,但由于需要训练的参数数量较少,计算时间也得以缩短。
AdaLoRA
论文:Adaptive budget allocation for parameter-efficient fine-tuning
确定哪些 LoRA 参数比其他参数更重要的方法有很多种。本节将介绍 AdaLoRA,即自适应 LoRA。这里 LoRA 的自适应之处在于 LoRA 矩阵的秩(即大小)。主要问题与上一节相同:并非每一层都值得添加 LoRA 矩阵 \(A\) 和 \(B\),但对于某些层而言,LoRA 训练可能比其他层更重要(即可能导致模型行为发生更大变化)。为了确定这种重要性,AdaLoRA 的作者提出将 LoRA 矩阵的奇异值作为其重要性的指标。
这是什么意思呢?首先,我们需要理解,矩阵乘法也可以看作是对向量应用一个函数。在处理神经网络时,这一点显而易见:大多数情况下,神经网络被当作函数来使用,也就是说,你输入一个参数(例如,一个像素值矩阵),然后得到一个结果(例如,对图像进行分类)。在底层,这个函数应用是由一系列矩阵乘法实现的。现在,假设你想减少这样一个矩阵中的参数数量。这会改变函数的行为,但你希望这种改变尽可能小。
一种方法是计算矩阵的特征值,特征值告诉你矩阵的每一行分别捕获了多少方差。然后,你可以决定将一些只捕获了很小一部分方差的行设置为零,这样它们就不会给函数增加太多信息。这就是 AdaLoRA 的核心思想,因为前面提到的奇异值恰好是特征值的平方根。也就是说,AdaLoRA 基于奇异值来决定哪些 LoRA 矩阵的哪些行更重要,哪些行可以省略。这有效地降低了某些矩阵的秩,因为这些矩阵包含许多贡献不大的行。
然而,需要注意的是,它与上一节中的 LoRA-drop 有一个重要的区别:在 LoRA-drop 中,每个层的适配器要么被完全训练,要么完全不训练。而 AdaLoRA 还可以决定保留某些层的适配器,但降低它们的秩。这意味着,最终不同的适配器可以具有不同的秩(而在原始的 LoRA 方法中,所有适配器的秩都相同)。
AdaLoRA 方法还有一些细节,为了简洁起见我省略了。不过我想提一下其中两点:首先,AdaLoRA 方法并非总是显式计算奇异值(因为这样做成本很高),而是使用奇异值分解来分解权重矩阵。这种分解方式与单个矩阵表示相同信息的方式相同,但它可以直接获得奇异值,而无需进行昂贵的计算。其次,AdaLoRA 不仅根据奇异值来决定损失函数,还会考虑损失对某些参数的敏感性。如果将某个参数设置为零会对损失产生显著影响,则称该参数具有高敏感性。在决定缩减秩的位置时,除了奇异值之外,还会考虑行元素的平均敏感性。
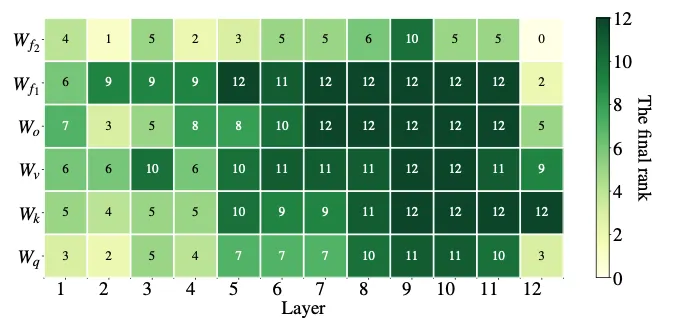
通过将 AdaLoRA 与相同秩预算的标准 LoRA 进行比较,可以得到该方法价值的实证证据。也就是说,两种方法总共具有相同数量的参数,但参数分布不同。在 LoRA 中,所有矩阵的秩相同;而在 AdaLoRA 中,部分矩阵的秩较高,部分矩阵的秩较低,最终参数数量相同。在许多情况下,AdaLoRA 的得分优于标准 LoRA 方法,这表明 AdaLoRA 将可训练参数更好地分布在模型中对特定任务至关重要的部分。下图展示了 AdaLoRA 如何为给定模型分配秩的示例。如图所示,AdaLoRA 将更高的秩分配给模型末尾的层,表明调整这些层更为重要。
DoRA
论文:DoRA: Weight-Decomposed Low-Rank Adaptation
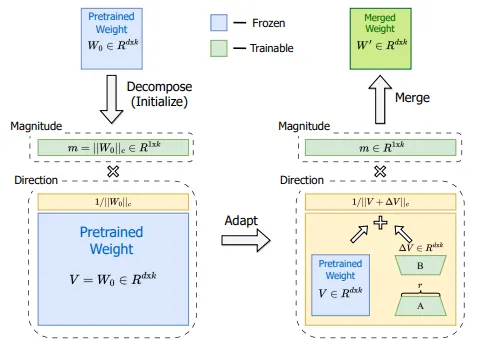
另一种提升 LoRa 性能的方法是权重分解 LoRa 自适应 (Weight-Decomposed Low-Rank Adaption ,简称 DoRA )。DoRA 的核心思想是,每个矩阵都可以分解为幅值和方向的乘积。对于二维空间中的向量,我们可以很容易地理解这一点:向量就是一个从零点出发,指向向量空间中某一点的箭头。向量的元素可以用来指定该点,例如,如果空间是二维的(\(x\) 和 \(y\)),则表示 \(x=1 \)和 \(y=1\)。或者,我们也可以用另一种方式来描述同一个点,即指定一个幅值和一个角度(也就是方向),例如 \(m=√2\) 和 \(a=45°\)。这意味着从零点出发,沿 \(45°\) 方向移动,箭头长度为 \(√2\)。这将引导你到达同一个点 (\(x=1\), \(y=1)\)。
这种分解为幅值和方向的方法也可以用于更高阶的矩阵。DoRA 的作者将此方法应用于权重矩阵,这些权重矩阵描述了使用常规微调训练的模型和使用 LoRA 适配器训练的模型在训练步骤中的更新。下图比较了这两种技术:
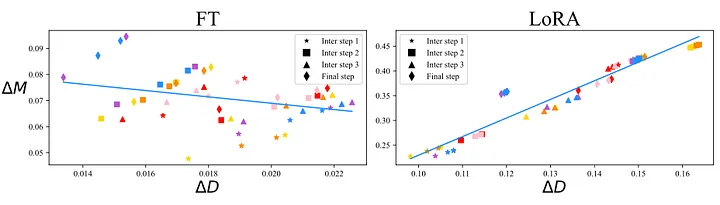
我们看到两张图,一张是微调模型(左图),另一张是使用 LoRa 适配器训练的模型(右图)。\(x \)轴表示方向的变化,\(y\) 轴表示幅度的变化,图中的每个散点代表模型的一层。两种训练方式之间存在显著差异。在左图中,方向更新和幅度更新之间存在微弱的负相关,而在右图中,二者之间存在更强的正相关。您可能会想知道哪种方法更好,或者这种差异是否有意义。请记住,LoRa 的主要思想是在参数更少的情况下达到与微调相同的性能。这意味着,理想情况下,我们希望 LoRa 的训练尽可能多地与微调共享特性,只要这不会增加成本。如果在微调中方向和幅度之间的相关性略微为负,那么如果 LoRa 也能实现,这或许也是一个理想的特性。换句话说,如果 LoRA 中方向和幅度之间的关系与完全微调不同,这可能是 LoRA 有时性能不如微调的原因之一。
DoRA 的作者提出了一种独立训练幅值和方向的方法,即将预训练矩阵 \(W\) 分解为一个 \(1×d\) 的幅值向量 \(m\) 和一个方向矩阵 \(V\)。然后,方向矩阵 \(V\) 像标准的 LoRA 方法一样,通过 \(B*A\) 进行增强,而 \(m\) 则直接进行训练,由于它只有一维,因此这种方法是可行的。LoRA 倾向于同时改变幅值和方向(如两者之间的高度正相关性所示),而 DoRA 可以更容易地单独调整其中一个,或者用一个的负向变化来补偿另一个的变化。我们可以看到,方向和幅值之间的关系更类似于微调中的关系:
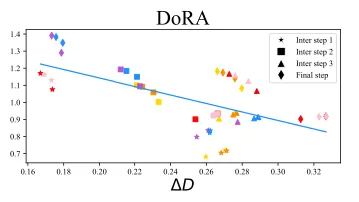
在多个基准测试中,DoRA 的准确率优于 LoRA。将权重更新分解为幅度和方向,可能使 DoRA 能够执行更接近微调阶段的训练,同时仍然使用 LoRA 引入的较小参数空间。
Delta-LoRA
论文:Delta-lora: Fine-tuning high-rank parameters with the delta of low-rank matrices
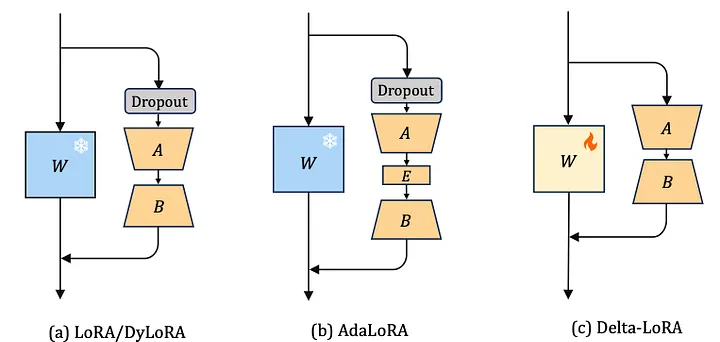
Delta-LoRA 引入了另一种改进 LoRA 的方法。这次,预训练矩阵 \(W\) 再次发挥作用。请记住,LoRA 的核心思想是不要调整预训练矩阵 \(W\),因为这样做成本太高(而且这属于常规的微调)。因此,LoRA 引入了新的、更小的矩阵 \(A\) 和 \(B\)。然而,这些更小的矩阵学习下游任务的能力较弱,这也是为什么 LoRA 训练的模型性能通常低于经过微调的模型。在训练过程中调整 \(W\) 固然很好,但我们如何才能承担得起这样的成本呢?
Delta-LoRA 的作者提出通过 \(A*B\) 的梯度来更新矩阵 \(W\),其中 \(A*B\) 是两个连续时间步长内 \(A*B\) 的差值。该梯度会根据超参数 \(λ\) 进行缩放,\(λ\) 控制着新训练对预训练权重的影响程度,然后将缩放后的梯度添加到 \(W\) 中(而 \(α\) 和 \(r\)(秩)是原始 LoRA 设置中的超参数):
这样一来,在几乎没有计算开销的情况下,需要训练的参数就更多了。我们无需像微调那样计算整个矩阵 \(W\) 的梯度,而是利用 LoRA 训练中已经获得的梯度进行更新。作者使用 RoBERTA 和 GPT-2 等模型在多个基准测试中比较了这种方法,发现其性能优于标准的 LoRA 方法。
小结
我们刚才看到了一些方法,它们都围绕着 LoRa 的核心思想展开,旨在减少计算时间或提高性能(或两者兼顾)。最后,我将对这些不同的方法做一个简要总结:
- LoRA 引入了低秩矩阵 \(A\) 和 \(B\) 进行训练,而预训练的权重矩阵 \(W\) 则被冻结。
- LoRA+ 建议 \(B \)的学习率要比 \(A \)的学习率高得多。
- VeRA 不训练 \(A\) 和 \(B\),而是随机初始化它们,并在此基础上训练新的向量 \(d\) 和 \(b\)。
- LoRA-FA 仅训练矩阵 \(B\)。
- LoRA-drop 使用 \(B*A\) 的输出来确定哪些层值得训练。
- AdaLoRA 动态地调整不同层中 \(A\) 和 \(B\) 的排名,允许在这些层中具有更高的排名,因为在这些层中,对模型性能的贡献预计会更大。
- DoRA 将 LoRA 适配器拆分为幅度和方向两个部分,并允许对它们进行更独立的训练。
- Delta-LoRA 通过 \(A*B\) 的梯度改变 \(W\) 的权重。
Inference
实际案例说明AI时代大语言模型三种微调技术的区别——Prompt-Tuning、Instruction-Tuning和Chain-of-Thought
解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning