LLaMA
论文名称:LLaMA: Open and Efficient Foundation Language Models
论文地址:https://arxiv.org/pdf/2302.13971.pdf
代码链接:https://github.com/facebookresearch/llama
模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大?
以 GPT-3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT-3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是:模型参数量级的增加就会带来同样的性能提升。
但是事实确实如此吗?
最近的 "Training Compute-Optimal Large Language Models" 这篇论文提出一种缩放定律 (Scaling Law):
训练大语言模型时,在计算成本达到最优情况下,模型大小和训练数据 (token) 的数量应该比例相等地缩放,即:如果模型的大小加倍,那么训练数据的数量也应该加倍。
翻译过来就是:当我们给定特定的计算成本预算的前提下,语言模型的最佳性能不仅仅可以通过设计较大的模型搭配小一点的数据集得到,也可以通过设计较小的模型配合大量的数据集得到。
那么,相似成本训练 LLM,是大 LLM 配小数据训练,还是小 LLM 配大数据训练更好?
缩放定律 (Scaling Law) 告诉我们对于给定的特定的计算成本预算,如何去匹配最优的模型和数据的大小。但是本文作者团队认为,这个功能只考虑了总体的计算成本,忽略了推理时候的成本。因为大部分社区用户其实没有训练 LLM 的资源,他们更多的是拿着训好的 LLM 来推理。在这种情况下,我们首选的模型应该不是训练最快的,而应该是推理最快的 LLM。呼应上题,本文认为答案就是:小 LLM 配大数据训练更好,因为小 LLM 推理更友好。
LLaMa 做到了什么
LLaMa 沿着小 LLM 配大数据训练的指导思想,训练了一系列性能强悍的语言模型,参数量从 7B 到 65B。例如,LLaMA-13B 比 GPT-3 小10倍,但是在大多数基准测试中都优于 GPT-3。大一点的 65B 的 LLaMa 模型也和 Chinchilla 或者 PaLM-540B 的性能相当。
同时,LLaMa 模型只使用了公开数据集,开源之后可以复现。但是大多数现有的模型都依赖于不公开或未记录的数据完成训练。
预训练数据
LLaMa 预训练数据大约包含 1.4T tokens,对于绝大部分的训练数据,在训练期间模型只见到过1次,Wikipedia 和 Books 这两个数据集见过2次。
如下图所示是 LLaMa 预训练数据的含量和分布,其中包含了 CommonCrawl 和 Books 等不同域的数据。
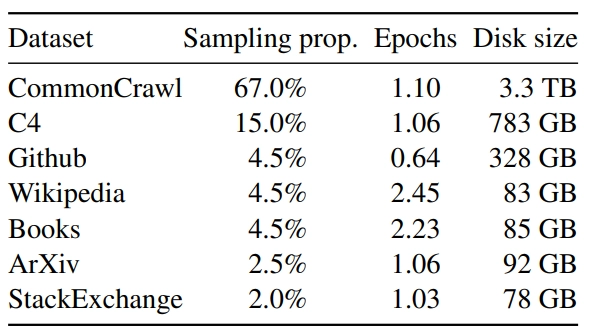
- CommonCrawl (占 67%):包含 2017 到 2020 的5个版本,预处理部分包含:删除重复数据,去除掉非英文的数据,并通过一个 n-gram 语言模型过滤掉低质量内容。
- C4 (占 15%):在探索性实验中,作者观察到使用不同的预处理 CommonCrawl 数据集可以提高性能,因此在预训练数据集中加了 C4。预处理部分包含:删除重复数据,过滤的方法有一些不同,主要依赖于启发式方法,例如标点符号的存在或网页中的单词和句子的数量。
- Github (占 4.5%):在 Github 中,作者只保留在 Apache、BSD 和 MIT 许可下的项目。此外,作者使用基于行长或字母数字字符比例的启发式方法过滤低质量文件,并使用正则表达式删除标题。最后使用重复数据删除。
- Wikipedia (占 4.5%):作者添加了 2022 年 6-8 月的 Wikipedia 数据集,包括 20 种语言,作者处理数据以删除超链接、评论和其他格式样板。
- Gutenberg and Books3 (占 4.5%):作者添加了两个书的数据集,分别是 Gutenberg 以及 ThePile (训练 LLM 的常用公开数据集) 中的 Book3 部分。处理数据时作者执行重复数据删除,删除内容重叠超过 90% 的书籍。
- ArXiv (占 2.5%):为了添加一些科学数据集,作者处理了 arXiv Latex 文件。作者删除了第一部分之前的所有内容,以及参考文献。还删除了 .tex 文件的评论,以及用户编写的内联扩展定义和宏,以增加论文之间的一致性。
- Stack Exchange (占 2%):作者添加了 Stack Exchange,这是一个涵盖各种领域的高质量问题和答案网站,范围从计算机科学到化学。作者从 28 个最大的网站保留数据,从文本中删除 HTML 标签并按分数对答案进行排序。
Tokenizer 的做法基于 SentencePieceProcessor,使用 bytepair encoding (BPE) 算法。
LLaMa 的 PyTorch 代码如下,用到了 sentencepiece 这个库。
# 引入 sentencepiece 库的 SentencePieceProcessor 模块,用于进行分词操作
from sentencepiece import SentencePieceProcessor
# 引入 logging 库的 getLogger 模块,用于生成日志
from logging import getLogger
# 引入 typing 库的 List 模块,用于注释函数参数或返回值的类型
from typing import List
# 引入 os 库,提供了大量与操作系统进行交互的接口
import os
# 创建一个日志记录器
logger = getLogger()
# 定义一个 Tokenizer 类
class Tokenizer:
# 初始化函数,参数为 SentencePiece 模型的路径
def __init__(self, model_path: str):
# 判断指定的模型文件是否存在
assert os.path.isfile(model_path), model_path
# 加载 SentencePiece 模型
self.sp_model = SentencePieceProcessor(model_file=model_path)
# 记录日志,提示模型加载成功
logger.info(f"Reloaded SentencePiece model from {model_path}")
# 获取模型的词汇量、开始标记 ID、结束标记 ID、填充标记 ID
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
# 记录日志,显示获取的信息
logger.info(
f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}"
)
# 确保模型的词汇量与词片段大小一致
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
# 编码函数,将输入的字符串编码为 token id 列表
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
# 检查输入的是否是字符串
assert type(s) is str
# 使用 SentencePiece 模型将字符串编码为 token id 列表
t = self.sp_model.encode(s)
# 如果需要在开头添加开始标记,就将开始标记 id 添加到列表的开头
if bos:
t = [self.bos_id] + t
# 如果需要在结尾添加结束标记,就将结束标记 id 添加到列表的结尾
if eos:
t = t + [self.eos_id]
# 返回 token id 列表
return t
# 解码函数,将 token id 列表解码为字符串
def decode(self, t: List[int]) -> str:
# 使用 SentencePiece 模型将 token id 列表解码为字符串
return self.sp_model.decode(t)模型架构
RMSNorm
Pre-normalization [受 GPT3 的启发]:
为了提高训练稳定性,LLaMa 对每个 Transformer 的子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
# torch.rsqrt是开平方并取倒数
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight常规的 Layer Normalization:
式中, \(𝑔_𝑖\) 和 \(𝑏_𝑖\) 是 LN 的 scale 和 shift 参数, \(𝜇\) 和 \(𝜎\) 的计算如下式所示:
RMSNorm:
相当于是去掉了 \(𝜇\) 这一项。
看上去就这一点小小的改动,有什么作用呢?RMSNorm 的原始论文进行了一些不变性的分析和梯度上的分析。具体可参考:RMSNorm
SwiGLU 激活函数 [受 PaLM 的启发]
为了更好的理解SwiGLU,首先你得先了解什么是ReLU和GLU
- ReLU的函数表达式为\(f(x) = max(0, x)\),这意味着对于所有负的输入值,ReLU函数的输出都是0,对于所有正的输入值,ReLU函数的输出等于输入值本身
- GLU 的基本思想是引入一种称为“门”机制,该机制可以动态地控制信息的流动
这个公式意味着,对于每个输入 \(x\),都会有一个相应的门值,这个门值由 sigmoid 函数产生,其范围在 0 到 1 之间(在正数区域接近于1,负数区域接近于0),这个门值用于调节相应的输入值 如果 接近 1,那么“门”就几乎完全开启,输入 x 的信息能够自由流动,于是 GLU 的输出接近于 \(x\) 如果 接近 0,意味着“门”几乎完全关闭,即输入 \(x\) 的大部分或全部信息被阻止通过,于是 GLU 的输出接近 0
而LLaMA采用Shazeer(2020)提出的SwiGLU替换了原有的ReLU,SwiGLU的作用机制是根据输入数据的特性,通过学习到的参数自动调整信息流动的路径,具体是采用SwiGLU的Feedforward Neural Network (简称FNN,这是一种使用可学习的门控机制的前馈神经网络)
其在论文中以如下公式进行表述:
解释下这个公式
- 该公式先是通过Swish非线性激活函数处理 “输入\(x\) 和权重矩阵\(W\)的乘积”
- 上面步骤1得到的结果和 “输入与权重矩阵的乘积” 进行逐元素的乘法
这个操作相当于在 Swish 激活的输出和第二个线性变换的输出之间引入了一个类似于GLU的“门”,这个门的值是由原始输入 \(x\) 通过线性变换 \(V\) 计算得到的,因此,它可以动态地控制 Swish 激活的输出 - 最后乘以权重矩阵 \(W_2\)
至于Swish激活函数可表示为
\(\sigma\)表示sigmoid函数,但其输入被缩放了 \(\beta\) 倍,\(\beta\) 是一个可以学习的参数,比如下图,\(\beta\) 不同,Swish激活函数的形状则各异
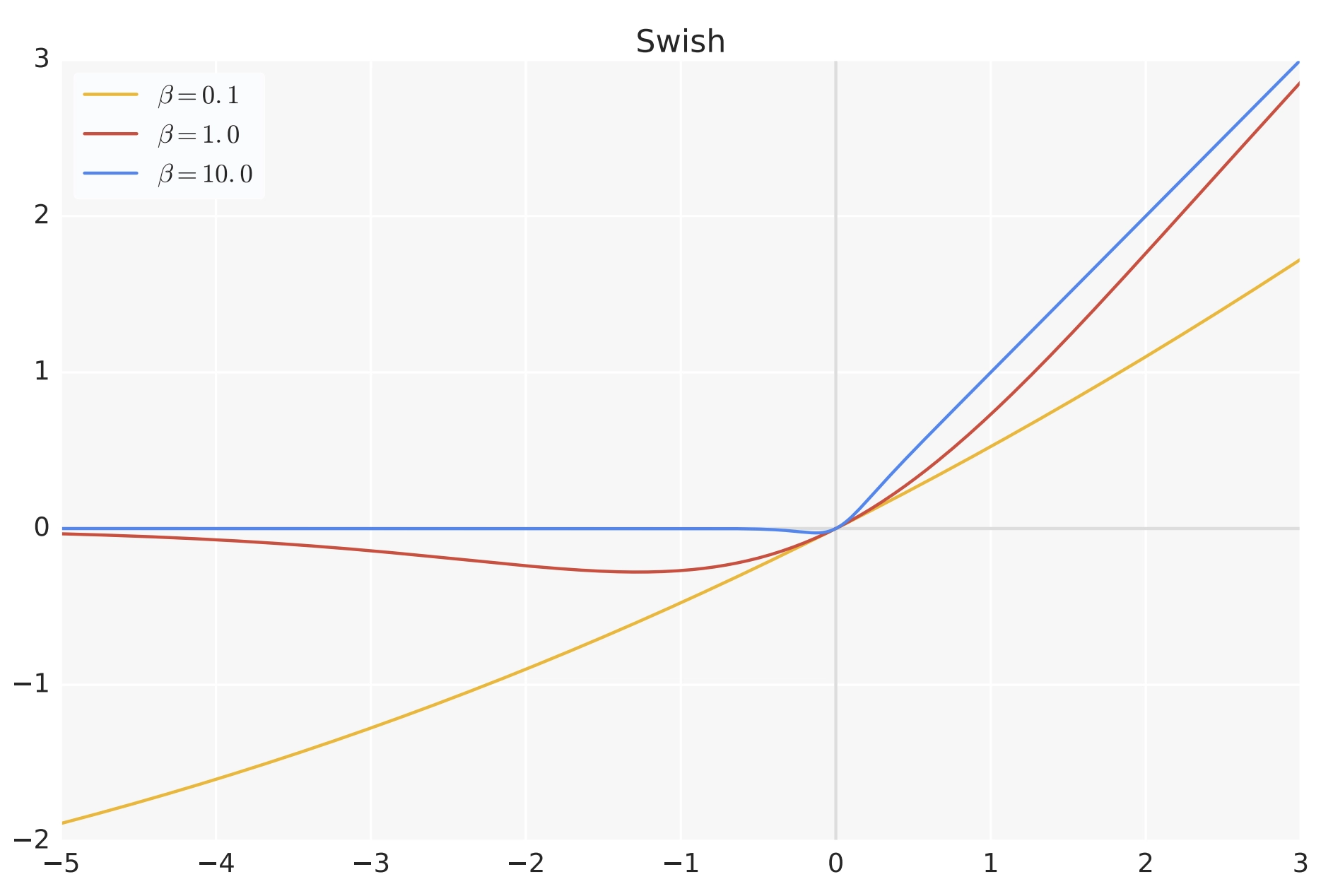
- 当 \(\beta\) 趋近于 0 时,Swish 函数趋近于线性函数 y = x
- 当 \(\beta\) 趋近于无穷大时,Swish 函数趋近于 ReLU 函数
Rotary Embeddings
LLaMa 去掉了绝对位置编码,使用旋转位置编码 (Rotary Positional Embeddings, RoPE) 详细见:旋转式位置编码 RoPE
LLaMa 的优化
AdamW, \(\beta_1=0.9, \beta_2=0.95\) ,使用 cosine 学习率衰减策略,2000 步的 warm-up,最终学习率等于最大学习率的 10%,使用 0.1 的权重衰减和 1.0 的梯度裁剪。
快速的注意力机制:LLaMa 采用了高效的 causal multi-head attention (基于 xformers),不存储注意力权重,且不计算 mask 掉的 query 和 key 的值。
手动实现反向传播过程,不使用 PyTorch autograd:使用 checkpointing 技术减少反向传播中的激活值的计算,更准确地说,LLaMa 保存计算代价较高的激活值,例如线性层的输出。
通过使用模型和序列并行减少模型的内存使用。此外,LLaMa 还尽可能多地重叠激活的计算和网络上的 GPU 之间的通信。
LLaMa-65B 的模型使用 2048 块 80G 的 A100 GPU,在 1.4T token 的数据集上训练 21 天。
由于LLaMa的效果很好,最主要的是他是一个开源的大模型,所以后续在社区中就产生了一系列基于llama的微调模型。具体可以参考:微调LLaMA模型
LLaMA 2
23年7月份,Meta发布LLAMA 2,是 LLAMA 1 的更新版本
项目地址:huggingface.co/meta-llama
论文地址:ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
简介
- 模型结构
采用了 Llama 1 的大部分预训练设置和模型架构,比如使用标准Transformer 架构,使用 RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE - 32K词表大小
继续沿用Llama1 所用的通过SentencePiece实现的BPE,且整个词表的大小依然为 32K We use the same tokenizer as Llama 1; it employs a bytepair encoding (BPE) algorithm(Sennrich et al., 2016) using the implementation from SentencePiece (Kudo and Richardson, 2018). As with Llama 1, we split all numbers into individual digits and use bytes to decompose unknown UTF-8 characters. The total vocabulary size is 32k tokens. - 2T训练数据
使用一种新的混合的公开可用数据进行训练,训练数据规模是2T个token(即2万亿个token),相比1代的1.4T多出了40% - 4K上下文长度
上下文长度达到了4096,相比1代的2048直接翻了一倍 - 模型种类:7B、13B、70B(用了GQA)
目前 LLAMA 2 的系列模型有 7B、13B、70B 三种(34B的后续发布) 值得特别注意的是,其中的70B模型采用了分组查询注意力(grouped-query attention,简称GQA,关于什么是GQA ),至于其中的7B和13B则没用GQA「Transformer原始论文中用的多头注意力(MHA)、ChatGLM2-6B则用的多查询注意力(Multi-query attention,简称MQA)」
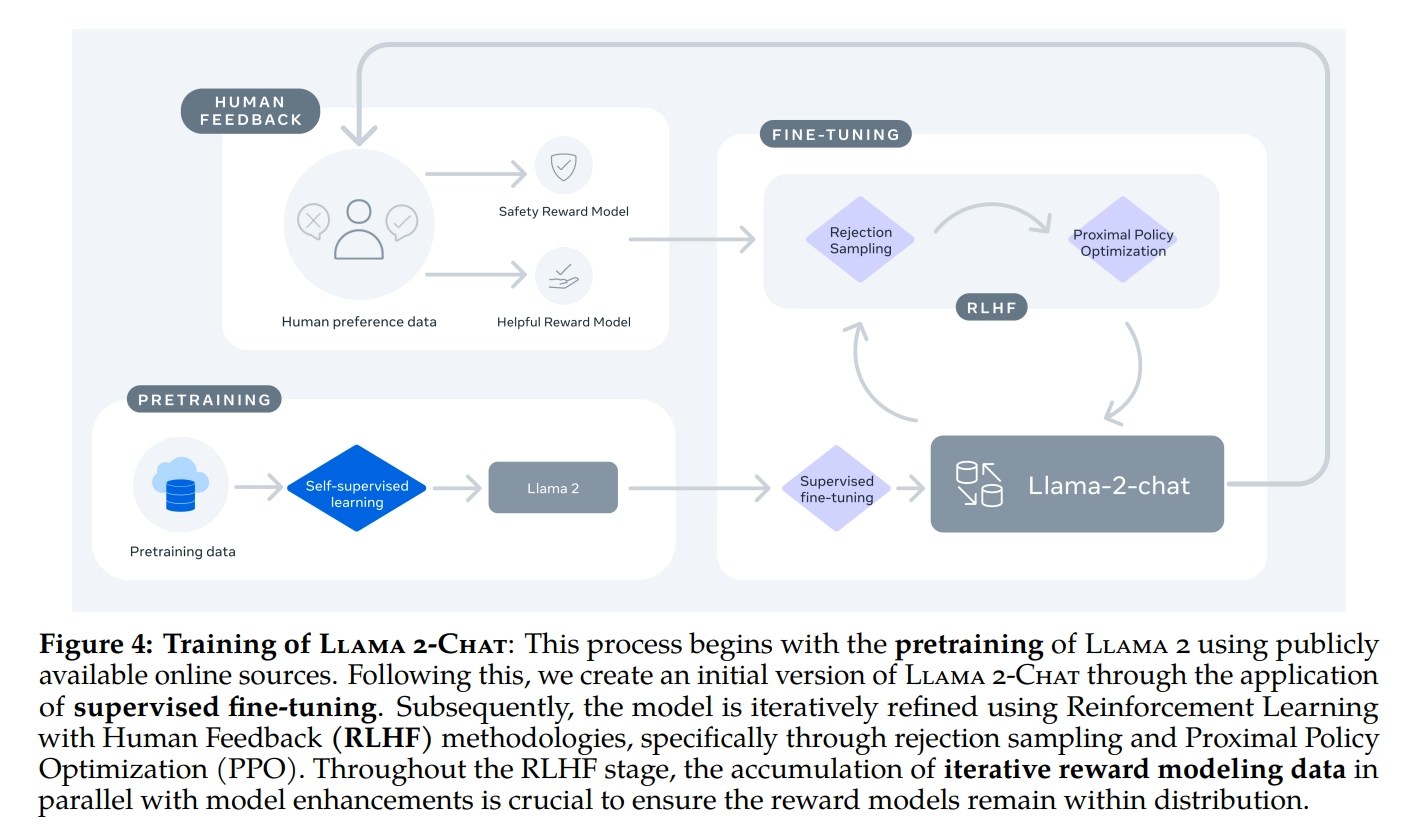
LLaMA 2-Chat
同时 Meta 还发布了 LLaMA 2-CHAT,其是基于 LLAMA 2 针对对话场景微调的版本,同样 7B、13B 和 70B 参数三个版本,具体的训练方法与ChatGPT类似
- 先是监督微调LLaMA2得到SFT版本 (接受了成千上万个人类标注数据的训练,本质是问题-答案对 )
- 然后使用人类反馈强化学习(RLHF)进行迭代优化 先训练一个奖励模型 然后在奖励模型/优势函数的指引下,通过拒绝抽样(rejection sampling)和近端策略优化(PPO)的方法迭代模型的生成策略
LLAMA 2 的性能表现更加接近 GPT-3.5,Meta 也承认距离 GPT-4 和 PaLM 2 等领先非开源模型还有差距
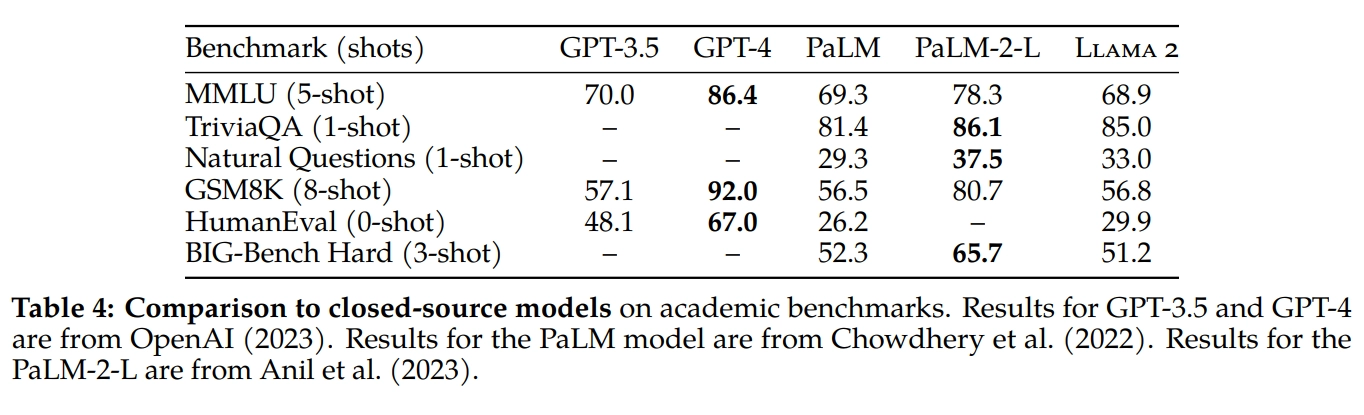
Meta 在技术报告中详细列出了 LLAMA 2 的性能、测评数据,以及分享了重要的训练方法,具体详见原论文
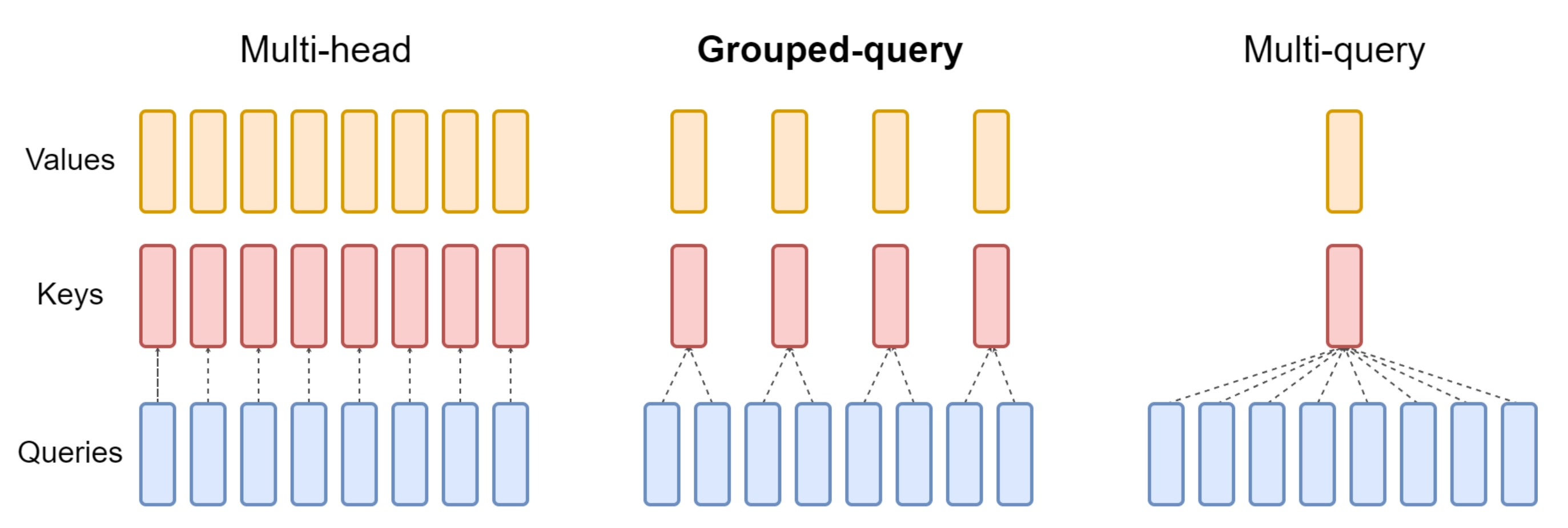
Grouped-Query Attention(GQA)
自回归解码的标准做法是缓存序列中先前标记的键 (\(K\)) 和值 (\(V\)) 对,从而加快注意力计算速度 然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显着增长
对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能,可以使用
- 具有单个 KV 投影的原始多查询格式(MQA) ChatGLM2-6B即用的这个,详见此文《ChatGLM两代的部署/微调/实现:从基座GLM、ChatGLM的LoRA/P-Tuning微调、6B源码解读到ChatGLM2的微调与实现》的3.1.2节 不过,多查询注意(Multi-query attention,简称MQA)只使用一个键值头,虽大大加快了解码器推断的速度,但MQA可能导致质量下降,而且仅仅为了更快的推理而训练一个单独的模型可能是不可取的
- 或具有多个 KV 投影的分组查询注意力(grouped-query attention,简称GQA),速度快 质量高 23年,还是Google的研究者们提出了一种新的方法,即分组查询注意(GQA,论文地址为:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)
这是一种多查询注意的泛化,它通过折中(多于一个且少于查询头的数量,比如4个)键值头的数量,使得经过强化训练的GQA以与MQA相当的速度达到接近多头注意力的质量
Llama 2-Chat中的RLHF
监督微调(SFT)
在SFT的数据上
- 他们先是重点收集了几千个高质量 SFT 数据示例 (注意:很多新闻稿会说SFT的数据达到百万以上,这就是没仔细看论文的结果,论文之意是胜过百万低质量的数据,
As a result, we focused first on collecting several thousand examples of high-quality SFT data. By setting aside millions of examples from third-party datasets and using fewer buthigher-quality examples from our own vendor-based annotation efforts, our results notably improved)
- 之后发现几万次的SFT标注就足以获得高质量的结果,最终总共收集了27540条用于SFT的标注数据
We found that SFT annotations in the order of tens ofthousands was enough to achieve a high-quality result. We stopped annotating SFT after collecting a total of 27,540 annotations.
在微调过程中
- 每个样本都包括一个prompt和一个response(说白了,就是问题-答案对,和instructGPT/ChatGPT本身的监督微调是一个本质),且为确保模型序列长度得到正确填充,Meta 将训练集中的所有prompt和response连接起来。他们使用一个特殊的 token 来分隔prompt和response片段,利用自回归目标,将来自用户提示的 token 损失归零,因此只对答案 token 进行反向传播,最后对模型进行了 2 次微调
- 微调过程中的参数则如此设置:we use a cosine learning rate schedule with an initiallearning rate of 2 ×10−5 , a weight decay of 0.1, a batch size of 64, and a sequence length of 4096 token

奖励模型:一个偏实用 一个偏安全
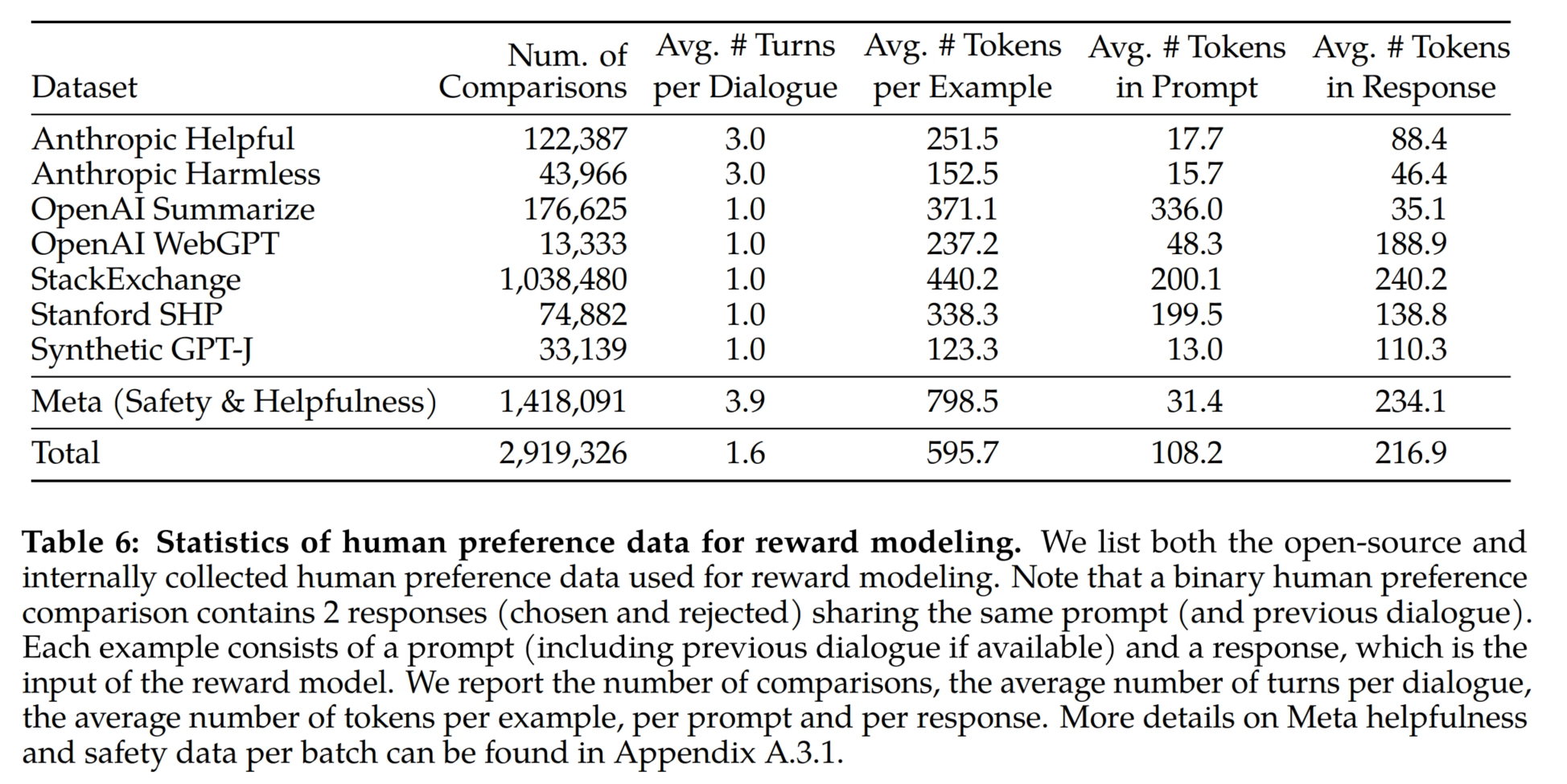
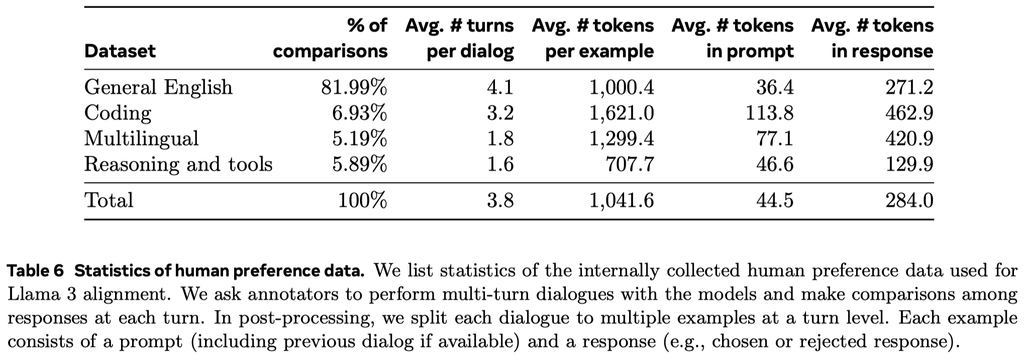
下表 6 报告了 Meta 长期以来收集到的奖励建模数据的统计结果,并将其与多个开源偏好数据集进行了对比。他们收集了超过 100 万个基于人类应用指定准则的二元比较的大型数据集,也就是奖励建模数据.
关于奖励数据
- prompt和response中的标记数因文本领域而异,比如摘要和在线论坛数据的prompt通常较长,而对话式的prompt通常较短。与现有的开源数据集相比,本文的偏好数据具有更多的对话回合,平均长度也更长
- 奖励模型将模型响应及其相应的提示(包括前一轮的上下文)作为输入,并输出一个标量分数来表示模型生成的质量(例如有用性和安全性),利用这种作为奖励的响应得分,Meta 在 RLHF 期间优化了 Llama 2-Chat,以更好地与人类偏好保持一致,并提高有用性和安全性 在每一批用于奖励建模的人类偏好标注中,Meta 都拿出 1000 个样本作为测试集来评估模型,并将相应测试集的所有prompt的集合分别称为实用性和安全性 (很多新闻稿会翻译成元实用、元安全,其实没必要加个“元”字,你理解为是Meta内部定义的“实用”与“安全”两个概念即可)
故为了兼顾和平衡模型的实用性和安全性,LLaMA 2团队训练了两个独立的奖励模型
- 一个针对实用性(称为实用性RM)进行了优化,在内部所有偏实用的奖励数据集上进行训练,并结合从内部偏安全的奖励数据集和开源安全性数据集中统一采样的同等部分剩余数据
- 另一个针对安全性(安全性RM)进行了优化,在内部所有偏安全的奖励数据和人类无害数据上进行训练,并以90/10的比例混合内部偏实用的奖励数据和开源实用性数据
并通过预训练的LLaMA 2初始化奖励模型(意味着奖励模型的架构与参数与预训练模型一致,只是用于下一个token预测的分类头被替换为用于输出标量奖励的回归头),因为它确保了两个模型都能从预训练中获得的知识中受益 「虽然论文中的原文是:We initialize our reward models from pretrained chat model checkpoints, as it ensures that both modelsbenefit from knowledge acquired in pretraining,以及The model architecture and hyper-parameters are identical to thoseof the pretrained language models, except that the classification head for next-token prediction is replacedwith a regression head for outputting a scalar reward,但为何没有类似ChatGPT那样,通过微调过的SFT初始化RM模型,该点存疑 」
为了使模型行为与人类偏好相一致,Meta 收集了代表了人类偏好经验采样的数据,通过针对同一个prompt模型给出的两个不同的response,人类标注者选择他们更喜欢的模型输出。这种人类偏好被用于训练奖励模型 奖励模型的训练目标使用了一个binary ranking loss 保证chosen response的分数高于rejected
其中,\(y_c\) 是标注者选择的首选response,\(y_r\) 是被拒绝的对应response, \(r_\theta(x, y)\)即为奖励模型输出的score
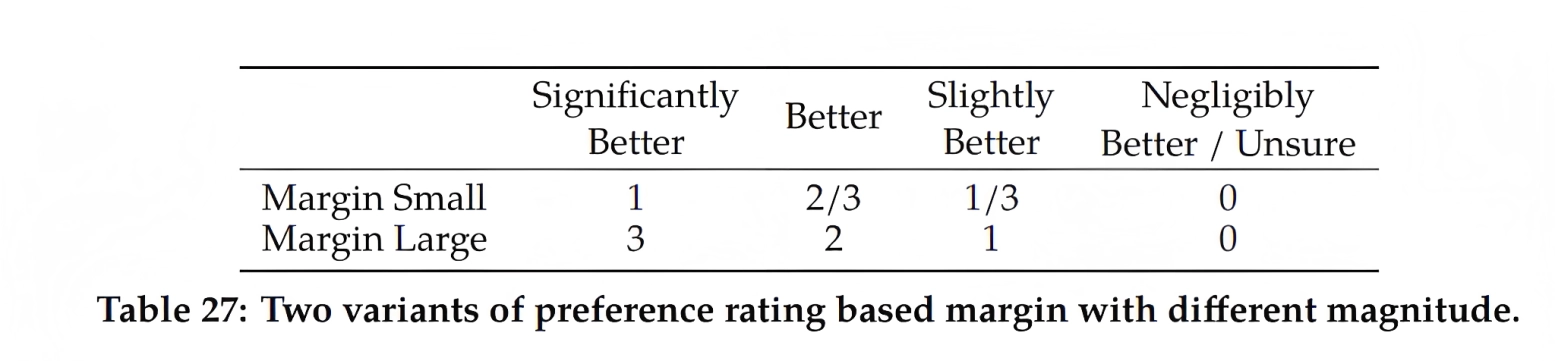
且为了让模型可以更好的体会到不同response质量之间的差异,作者团队将偏好评级被分为4层评级,且考虑到根据这些评级信息使得奖励模型对有更多差异的生成,有着不同分数且这些分数上彼此之间的差距尽可能拉开是有用的「Given that our preference ratings is decomposed as a scale of four points (e.g.,significantly better), it can be useful to leverage this information to explicitlyteach the reward model to assign more discrepant scores to the generations that have more differences」,为此,我们在损失中进一步添加一个边际成分
其中边际 \(m(r)\) 是偏好评级的离散函数,他们发现这个边际成分可以提高帮助性奖励模型的准确性,特别是在两个response更好区分的的样本上「where the margin \(m(r)\) is a discrete function of the preference rating. We found this margin component can improve Helpfulness reward model accuracy especially on sampleswhere two responses are more separable」
具体而言,为了衡量不同response好坏的程度,划分为4个等级(比如很好、好、较好、一般好或不确定),那这4个等级是需要有一定的间隔的,彼此之间不能模棱两可(模棱两可就容易把模型搞糊涂),而这个间隔大小是个超参数,可以人为设定,比如为小点的间隔1/3或大点的间隔1,如下图所示
策略迭代:PPO与拒绝采样
此处使用两种主要算法对 RLHF 进行了微调:
- 近端策略优化(PPO)
- 拒绝采样(Rejection Sampling) 即在模型生成多个回复后,选择最佳的回复作为模型的输出,过程中,如果生成的回复不符合预期,就会被拒绝,直到找到最佳回复 从而帮助提高模型的生成质量,使其更符合人类的期望
LLaMA 3
ai.meta.com/research/publications/the-llama-3-herd-of-models/
24年3月 发布了llama 3,7月又发布了3.1,是在3的基础上又增加了部分能力包含多模态、tools、多语言。
llm的训练分为两个主要阶段:
- 预训练阶段 pre-training,模型通过使用简单的任务如预测下一个词或caption进行大规模训练
- 后训练阶段 post-training,模型经过调整以遵循指令、与人类偏好保持一致,并提高特定能力, 例如编码和推理。
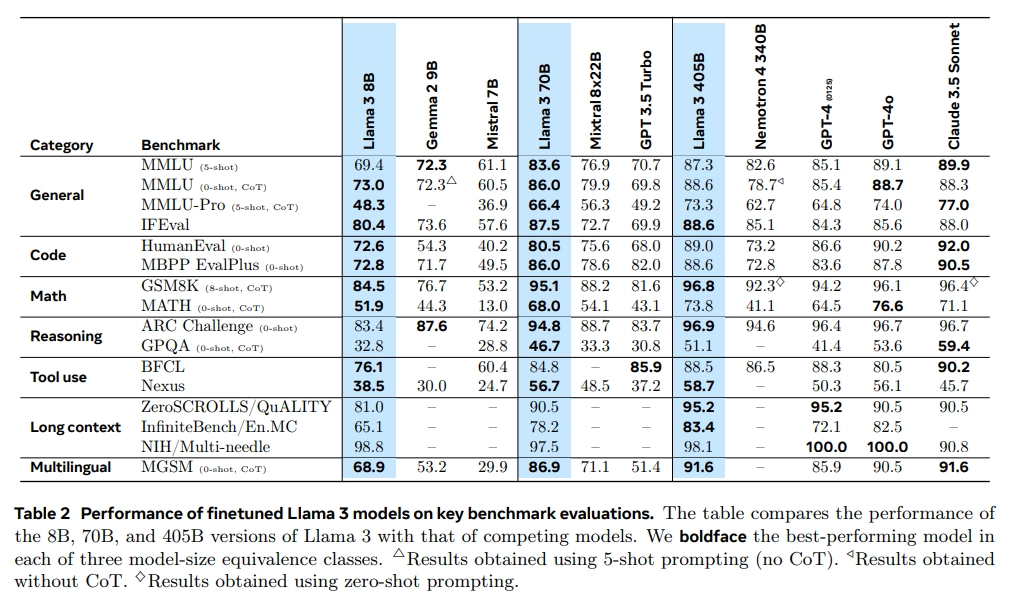
Llama 3.1 发布,在 15.6T 多语言 tokens 上训练,支持多语言,编程,推理和工具使用。新模型支持 128K tokens 长度的上下文。最大的旗舰模型参数量为 405B,效果达到了闭源模型的 SOTA。
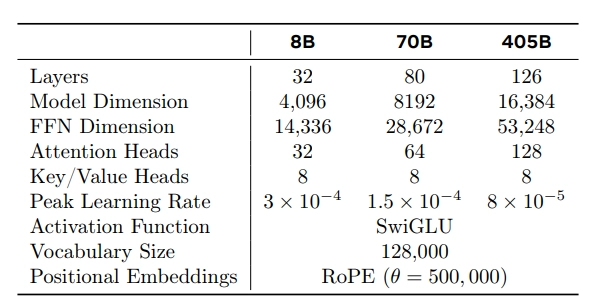
模型结构

Llama 3.1 的模型和 Llama 3 是一样的,只是做了更精细的训练。各个模型的结构如下:
- LLaMA 3 依旧使用的是 decoder-only transformer 架构。
- LLaMA 3 使用了 128K token vocabulary (LLaMA 2 是 32K),提升了编码效率,从而大幅提高了模型性能。
- 采用了分组查询注意力(GQA),提升了推理效率。
- 在长度为 8,192 长度的 token 序列上训练(之前是 4K),并使用掩码确保自注意力不会跨越文档边界。
- 将 RoPE 基频率超参数增加到 500,000。这使得能够更好地支持更长的上下文
预训练
Llama 3 预训练包括三个主要阶段:
1. 初始预训练:就是常规的预训练阶段.
2. 长上下文预训练:在预训练的后面阶段,采用长文本数据对长序列进行训练,支持最多128K token的上下文窗口。这个长上下文预训练阶段使用了大约800B训练token数据。
3. 退火(Annealing): 在预训练的最后4000万个token期间,线性地将学习率退火至0,同时保持上下文长度为128K个token。在这一退火阶段,调整了数据混合配比,以增加高质量数据比如数学、代码、逻辑内容的影响。最后,将若干退火期间模型Check Point的平均值,作为最终的预训练模型。
总体而言,和目前一些其它开源模型的训练过程差别不大,不过技术报告公开了很多技术细节。
预训练参数为 405B 的模型,使用了15.6T tokens,并且设置了上下文窗口大小为 8K tokens。标准预训练阶段之后,接着是继续预训练(continued pre-training)阶段,增加支持的上下文窗口到 128K tokens。
语言模型预训练包括:
- 大规模训练语料库的策划和过滤,
- 模型架构的开发及确定模型规模的相应缩放法则(Scaling laws)
- 大规模高效预训练技术的开发
- 预训练方案的制定。
数据过滤,去重等步骤就不在这里详说了,论文有点细节但不多。
- 为确保 LLaMA 3 训练用的是最高质量的数据,作者开发了一系列数据过滤流水线,包括使用启发式过滤器、NSFW 过滤器、语义去重方法和文本质量分类器等。作者发现,前几代 LLaMA 在识别高质量数据时表现出乎意料的出色,因此使用 LLaMA 2 生成了用于训练 LLaMA 3 文本质量分类器的训练数据。
Scaling Laws
作者借助缩放法则在预训练计算预算(compute budgets)下确定旗舰模型的最佳模型规模。除了确定最佳模型规模外,主要挑战是预测旗舰模型在下游基准任务上的性能,原因有几个:
- 现有的缩放法则通常只预测下一个 token 的预测损失,而不是具体的基准性能。
- 缩放法则可能会有噪声且不可靠,因为它们是基于小计算预算的预训练运行开发的。
计算预算 = Model Size ✖️ # Tokens
确定旗舰模型的参数规模
具体来说,作者通过在 \(6×10^{18}\) FLOPs 到 \(10^{22}\) FLOPs 之间的计算预算(compute budgets)下进行预训练模型来构建缩放法则。在每个计算预算下,作者预训练规模各异的多个模型,模型大小范围在40M到16B参数之间。
这些实验产生了 下图中的 IsoFLOPs 曲线。这些曲线中的损失是在一个单独的验证集上测量的。并使用二次多项式拟合测量的损失值,并确定每个抛物线的最小值。将抛物线的最小值对应模型称为对应预训练计算预算下的计算最优(compute-optimal)模型。
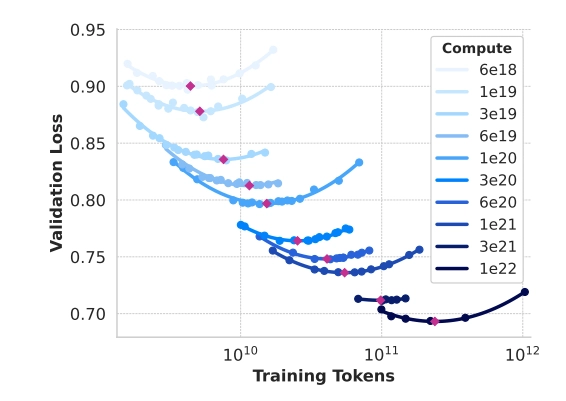
作者使用识别出的计算最优模型来预测特定计算预算下的最佳训练 tokens 数量(上图中红点的横坐标取值)。假设计算预算 \(C \)与最佳训练 tokens 数量 \(N^⋆(C)\) 之间存在以下幂律关系:
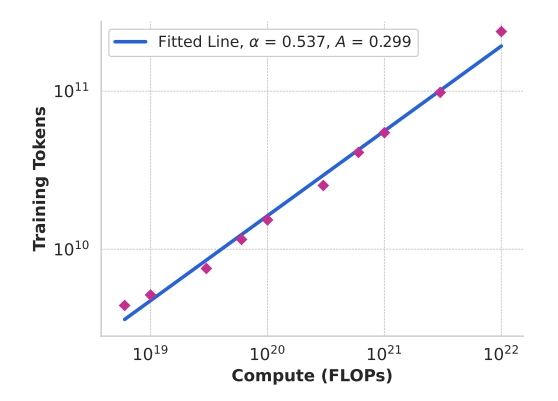
使用IsoFLOPs 曲线图中的数据拟合 \(A\) 和 \(α\) ,发现 \((α,A)=(0.53,0.29)\);相应的拟合结果显示在上图中。将结果缩放法则外推至 \(3.8×10^{25}\) FLOPs,表明可以在 16.55T 训练 tokens 上训练一个 402B 参数的模型。
并且从IsoFLOPs 曲线图中可以看出,随着计算预算的增加,IsoFLOPs 曲线在最小值附近变得更平坦。这表明旗舰模型的性能对模型大小和训练标记之间的小变化相对稳健。基于这一观察,作者最终决定训练一个405B参数的旗舰模型。
确定旗舰模型在下游任务的效果
为了解决这些挑战,作者实施了一个两阶段的方法来开发准确预测下游基准性能的缩放法则:
- 首先,建立计算最优(compute-optimal)模型在下游任务上的负对数似然与训练浮点运算(FLOPs)之间的相关性。
- 接下来,利用计算最优模型和更高计算浮点运算(FLOPs)训练的旧模型如 Llama 2 系列模型,将下游任务上的负对数似然与任务准确性相关联。
这种方法使作者能够在给定计算预算的情况下预测计算最优模型在下游任务上的性能。
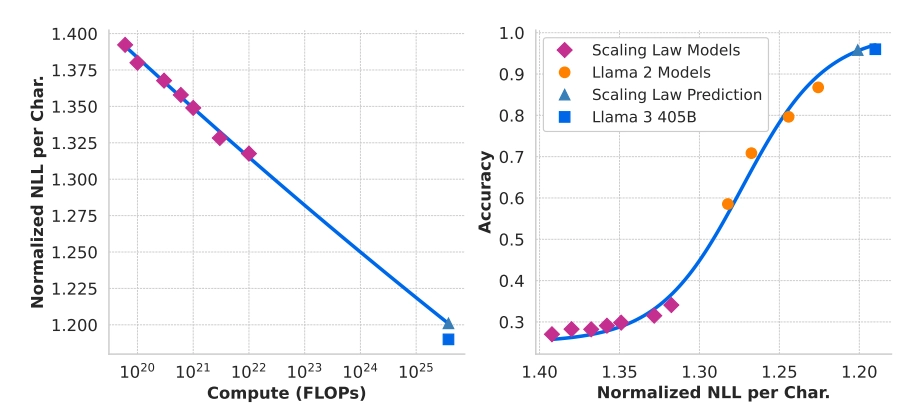
作者使用计算最优模型来预测旗舰 Llama 3 模型在基准数据集上的性能。首先,将基准中的正确答案的(归一化)负对数似然与训练 FLOPs 线性相关。在此分析中,作者仅使用训练到 10221022 FLOPs 的缩放法则模型以及上文描述的数据混合。
接下来,作者使用缩放法则模型(IsoFLOPs 曲线图中的计算最优模型)和 Llama 2 模型(使用 Llama 2 数据混合和分词器训练)之间的对数似然和准确性建立S型关系。作者在 图4 中展示了 ARC Challenge 的实验结果。发现这种两步 scaling laws 预测,跨越四个数量级的外推非常准确:它仅略微低估了旗舰 Llama 3 模型的最终性能。
分两步预测的好处是在第二步中可以把已有的大模型的 NLL 和对应准确率作为训练样本(下图右侧中的黄点)加入进来。
确定旗舰模型的训练数据混合比例
为了获得高质量的语言模型,必须仔细确定预训练数据混合中不同数据源的比例。作者主要通过知识分类和缩放法则实验来确定这一数据混合。
知识分类。作者开发了一种分类器,用于分类网络数据中包含的信息类型,以更有效地确定数据混合。作者使用该分类器对在网络上过度代表的数据类别(例如艺术和娱乐)进行降采样。
数据混合的缩放法则。类似上面的做法,作者通过缩放法则实验来选择预训练数据最佳混合比例。作者在某种数据混合上训练几个小模型,并用它来预测大型模型在该混合上的性能(类似上面,先预测 NLL 值,再通过 NLL 预测精度)。作者对不同的数据混合重复多次这一过程,以选择最优的数据混合候选。随后,作者在该候选数据混合上训练一个较大的模型,并评估该模型在几个关键基准上的性能。
数据混合总结。最终数据混合大致包含50%的通用知识 tokens,25%的数学和推理 tokens,17%的代码 tokens,以及8%的多语言 tokens。
预训练过程
预训练 Llama 3 405B 的方案包括三个主要阶段:(1) 初始预训练,(2) 长上下文预训练,(3) 退火。
- 初始预训练:作者使用余弦学习率调度预训练 Llama 3 405B,峰值学习率为 \(8×10^{−5}\),线性预热8000步,并在120万个训练步骤内衰减至 \(8×10^{−7}\)。为了提高训练稳定性,作者在训练初期使用较小的批量大小,随后增加批量大小以提高效率。具体而言,初始批量大小为4Mtokens,序列长度为4096;在预训练252M tokens 后,将这些值 double 为 8M和8192;预训练 2.87T tokens 后,再次将批量大小加倍至16M。作者发现这种训练方案非常稳定:观察到的损失峰值很少,不需要干预来纠正模型训练的偏差。
调整数据混合。作者在训练过程中对预训练数据混合进行了多次调整,以提高模型在特定下游任务上的性能。作者在预训练期间增加了非英语数据的比例,以提高 Llama 3 的多语言性能。作者还上采样了数学数据以提高模型的数学推理性能,在预训练的后期阶段添加了更多最新的网络数据以更新模型的知识截止点,并对后期被识别为质量较低的预训练数据子集进行降采样。 - 长上下文预训练:在预训练的最后阶段,作者在长序列上进行训练,以支持最多
128Ktokens的上下文窗口。作者早期没有在长序列上训练,因为自注意力层的计算量随着序列长度的平方增长。训练过程中逐渐增加支持的上下文长度:直到模型成功适应新的上下文长度后再增加长度。作者通过以下两点来评估成功适应:(1) 模型在短上下文评估中的性能是否完全恢复,以及 (2) 模型是否完美解决了长度范围内的“海底捞针”任务。在 Llama 3 405B 预训练中,作者分六个阶段逐步增加上下文长度,从最初的8K上下文窗口开始每次翻倍,最终达到128K上下文窗口。这个长上下文预训练阶段总共使用了大约**800B**训练 tokens。 - 退火:在预训练的最后
40Mtokens 期间,作者线性退火学习率至0,保持128Ktokens的上下文长度。在退火阶段,还调整了数据混合,上采样非常高质量的数据源,具体见下面说明👇。最后,平均退火过程保存的多个模型权重值以生成最终预训练模型。
在少量高质量代码和数学数据上进行退火可以提升预训练模型在关键基准测试上的性能。作者使用数据混合进行退火,上采样特定领域的高质量数据。退火数据中不包括任何常用基准测试的训练集。
作者发现,退火使得预训练的 Llama 3 8B 模型在 GSM8k 和 MATH 验证集上的性能分别提高了 24.0% 和 6.4%。然而,对 405B 模型的改进则微乎其微,表明旗舰模型具有很强的上下文学习和推理能力,不需要特定的域内训练样本即可获得强大的性能。
使用退火评估数据质量。与Blakeney等(2024)类似,作者发现退火能够判断小型特定领域数据集的价值。作者通过对 50% 训练完成的 Llama 3 8B 模型在 40B tokens 上线性降低学习率至0 的方式来衡量这些数据集的价值。在这些实验中,作者对新数据集赋予30%的权重,其余70%权重分配给默认数据混合。使用退火评估新数据源比对每个小数据集进行缩放法则实验更有效。
后训练
- 首先用人工标注数据训练RM模型,用来评价一个<Prompt,answer>数据的质量,
- 然后用RM参与拒绝采样(Rejection Sampling),就是说对于一个人工Prompt,用模型生成若干个回答,RM给予质量打分,选择得分最高的保留作为SFT数据,其它抛掉。这样得到的SFT数据再加上专门增强代码、数学、逻辑能力的SFT数据一起,用来调整模型得到SFT模型。
- 之后用人工标注数据来使用DPO模型调整LLM参数,DPO本质上是个二分类,就是从人工标注的<Prompt,Good Answer,Bad Answer>三元数据里学习,调整模型参数鼓励模型输出Good Answer,不输出Bad Answer。这算完成了一个迭代轮次的Post-Training。
上述过程会反复迭代几次,每次的流程相同,不同的地方在于拒绝采样阶段用来对给定Prompt产生回答的LLM模型,会从上一轮流程最后产生的若干不同DPO模型(不同超参等)里选择最好的那个在下一轮拒绝采样阶段给Prompt生成答案。很明显,随着迭代的增加DPO模型越来越好,所以拒绝采样里能选出的最佳答案质量越来越高,SFT模型就越好,如此形成正反馈循环。
可以看出,尽管RLHF 和DPO两种模式都包含RM,但是用的地方不一样,RLHF是把RM打分用在PPO强化学习阶段,而LLaMA 3则用RM来筛选高质量SFT数据。而且因为拒绝采样的回答是由LLM产生的,可知这里大量采用了合成数据来训练SFT模型。
产生对齐模型的过程包含了 6 轮迭代,每轮都包括有监督微调(SFT)和直接偏好优化(DPO)。数据来自人类标注或者自动生成。在后训练阶段,作者还整合了新的功能,例如工具使用,并观察到在其他领域(如编码和推理)有显著改进。安全缓解措施也在后训练阶段被纳入模型。
后训练包含了一个奖励模型(Reward Model)和一个语言模型。首先,作者使用人工标注的偏好数据基于预训练模型训练奖励模型。使用奖励模型对人工标注的 prompts 进行拒绝采样。然后,通过 SFT 进一步微调预训练模型,并通过 DPO 进一步对齐模型。此过程如下图所示。
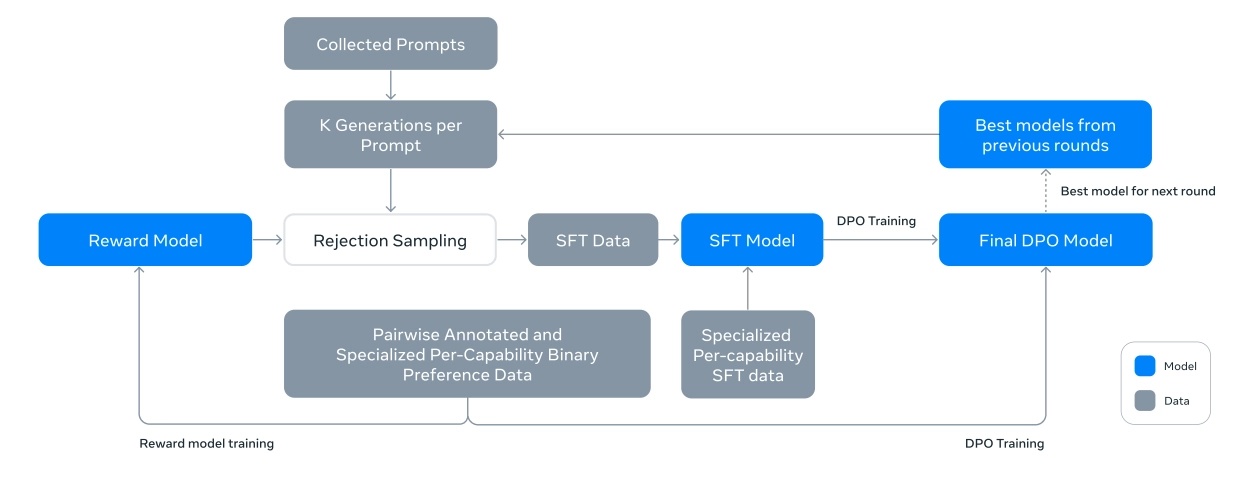
在奖励模型(RM)、有监督微调(SFT)或直接偏好优化(DPO)各个阶段中使用不同的数据或超参数获得了很多模型权重。最终模型的权重值使用了它们的平均值。
和 Llama 2 一样,应用上述方法迭代了 6 轮。在每个循环中,作者收集**新的偏好标注和SFT数据,**并从最新模型中采样合成数据
偏好数据(Preference Data)
偏好数据标注过程类似于Llama 2。每轮迭代后,作者会部署多个模型,并为每个用户 prompt 采样两个来自不同模型的响应。这些模型可以用不同的数据组合和对齐方法训练得到,从而具有不同的能力强度(例如代码专业知识),这样可以增加数据的多样性。标注员会依据选择的响应(chosen response)与拒绝的响应(rejected response)的偏好差距程度将其分为四个级别:显著更好、较好、稍好或略好。作者还在偏好排名后加入了编辑步骤,鼓励标注员进一步改进选择的响应。标注员可以直接编辑选择的响应或使用反馈提示模型改进其自身的响应。因此,部分偏好数据包含三个排名的响应(编辑后的 > 选择的 > 拒绝的,edited > chosen > rejected)。
作者会严格评估收集的数据,并逐渐优化 prompts 以便为标注员提供系统的、可操作的反馈。例如,随着 Llama 3 在每轮训练后的不断改进,作者会针对模型滞后的领域相应地增加 prompt 的复杂性。
在每轮训练后,作者使用当时可用的所有偏好数据训练奖励模型,同时仅使用来自各种能力的最新批次数据进行 DPO 训练。对于奖励建模和 DPO,作者使用那些被标注为选择响应显著优于拒绝响应的样本进行训练,并丢弃响应相似的样本。
以下是偏好数据中包含的各个类型的数据统计:
SFT 数据
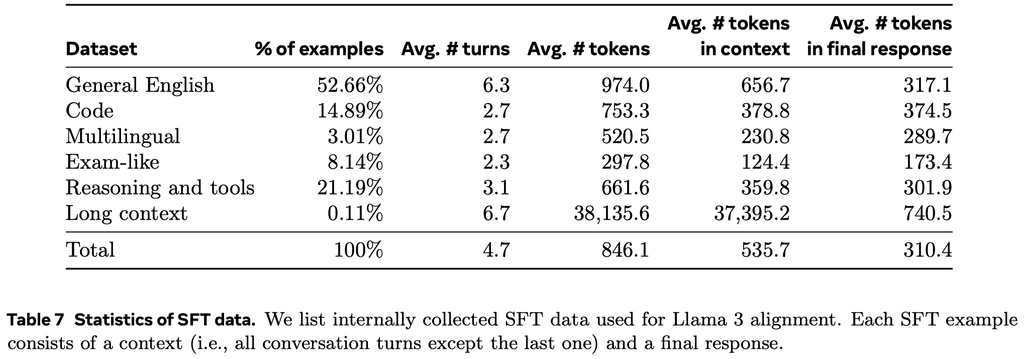
微调数据主要由以下来源组成:
- 来自人类标注集合的 prompt 与拒绝采样(RS)的响应
- 在拒绝采样(RS)过程中,对于在人工标注期间收集的每个 prompt,会从最新的模型(通常是上一次训练后迭代中表现最好的模型权重,或者某个特定能力表现最好的模型权重)中采样
K个输出(通常在10到30之间),并使用奖励模型选择最佳输出。在后训练的后期阶段,引入 system prompt 以引导 RS 响应符合期望的语气、风格或格式。
- 在拒绝采样(RS)过程中,对于在人工标注期间收集的每个 prompt,会从最新的模型(通常是上一次训练后迭代中表现最好的模型权重,或者某个特定能力表现最好的模型权重)中采样
- 针对特定能力的合成数据,详见后面。
- 少量人工精选的数据。
以下是 SFT 数据中包含的各个类型的数据统计:
下面介绍几种特定能力的数据是如何合成的。其他特定能力数据合成的方式类似,细节可见原论文。
代码特定能力数据
作者训练了一个代码专家模型,用于在后续的微调阶段收集高质量的人工标注。这个专家模型是在预训练模型的基础上继续在一个主要由代码数据(>85%)组成的 1T 标注混合数据上进行预训练来实现的。在训练的最后几千步中,作者在一个高质量的库级代码数据混合上执行了长上下文微调(long-context finetuning, LCFT),将专家的上下文长度扩展到 16K 标注。最后,作者遵循前面描述的类似后训练建模策略来对齐这个模型,但 SFT 和 DPO 数据混合主要针对代码。这个模型也用于代码 prompt 的拒绝采样。
合成数据生成。在开发过程中,作者识别出代码生成中的关键问题,包括难以遵循指令、代码语法错误、生成不正确的代码以及难以修复错误。作者使用 Llama 3 和代码专家生成了大量的合成 SFT 对话。
作者描述了生成合成代码数据的三种高级方法。总共生成了超过 2.7M 个用于 SFT 的合成示例。
- 合成数据生成:执行反馈。作者使用以下过程生成了大约
1M个合成编码对话的大型数据集:- 问题描述生成:首先,作者生成了大量涵盖广泛主题的编程问题描述,包括长尾分布中的主题。为了实现这种多样性,作者从各种来源中随机抽取代码片段,并通过 prompt 让模型基于代码片段生成编程问题。
- 解决方案生成:然后,作者通过 prompt 让 Llama 3 用给定的编程语言解决每个问题。作者观察到,在 prompt 中添加一般良好编程规则可以提高生成的解决方案质量。此外,要求模型在注释中解释其思考过程也很有帮助。
- 正确性分析:生成的解决方案未必正确,而在微调数据集中包含不正确的解决方案可能会损害模型质量。为验证正确性,作者从生成的解决方案中提取源代码,并应用静态和动态分析技术来测试其正确性,包括:
- 静态分析:作者通过解析器和 linter 运行所有生成的代码,以确保语法正确,捕捉诸如语法错误、未初始化变量或未导入函数的使用、代码风格问题、类型错误等错误。
- 单元测试生成和执行:对于每个问题和解决方案,作者通过 prompt 让模型生成单元测试,并在容器化环境中与解决方案一起执行,捕捉运行时执行错误和一些语义错误。
- 错误反馈和迭代自我纠正:当解决方案在任何步骤失败时,作者通过 prompt 让模型进行修正。prompt 包含原始问题描述、错误解决方案以及来自解析器/linter/测试器的反馈(stdout、stderr 和返回代码)。在单元测试执行失败后,模型可以修正代码以通过现有测试,或修改其单元测试以适应生成的代码。只有通过所有检查的对话才包含在最终数据集中,用于 SFT 训练。值得注意的是,作者观察到大约 20% 的解决方案最初是不正确的,但经过自我纠正后表明模型从执行反馈中学习并改进了其性能。
- 微调和迭代改进:微调过程分多轮进行,每轮建立在前一轮的基础上。每轮之后,模型都会得到改进,生成更高质量的合成数据用于下一轮。这种迭代过程允许模型性能逐步优化和增强。
- 合成数据生成:编程语言翻译。作者观察到较不常见的编程语言(如 Typescript/PHP)与主流编程语言(如 Python/C++)之间存在性能差距。为了解决这一问题,作者通过将常见编程语言的数据翻译成不常见的语言来补充现有数据。
- 合成数据生成:反向翻译(backtranslation)。某些编码场景(如文档编写、解释等)的代码执行反馈返回信息很少无法用于判断结果的质量,作者采用了一种替代性的多步骤方法。通过这一方法,作者生成了约
1.2M个与代码解释、生成、文档编写和调试相关的合成对话。从预训练数据中的各种编程语言代码片段开始,具体步骤如下:- 生成:通过 prompt 让 Llama 3 生成代表目标能力的数据 (如为代码片段添加注释和接口说明,或要求模型解释一段代码)。
- 反向翻译:然后通过 prompt 让模型将上面生成的数据**"反向翻译"回原始代码** (如仅根据文档生成代码,或仅根据解释生成代码)。
- 过滤:以原始代码为参考,通过 prompt 让 Llama 3 评估输出质量 (如询问模型反向翻译的代码与原始代码的忠实度)。最后,在 SFT 训练中使用的是自验证得分最高的生成样例。
拒绝采样过程中的系统提示引导。在拒绝采样过程中,作者使用了针对代码的特定 system prompt,以提高代码的可读性、文档质量、全面性和特异性。图 9 展示了系统提示如何改进生成代码质量的示例——它增加了必要的注释、使用了更具描述性的变量名、优化了内存使用等

使用执行结果和"模型作为判断者"信号来过滤训练数据。作者在拒绝采样的数据中偶尔会遇到质量问题,例如包含 bug 的代码块。在拒绝采样数据中检测这些问题并不像在合成代码数据中那样直接,因为拒绝采样的响应通常包含自然语言和代码的混合,其中的代码并不总是预期可执行 (例如,用户 prompt 可能明确要求伪代码或仅对可执行程序的一小部分进行编辑)。为解决这个问题,作者采用了"模型作为判断者" (model-as-judge) 的方法,使用 Llama 3 的早期版本根据代码正确性和代码风格两个标准进行评估,并给出二元 (0/1) 评分。作者只保留了获得满分 2 分的样本。
初期,这种严格的过滤导致了下游基准测试性能的下降,主要是因为它不成比例地删除了具有挑战性 prompt 的样例。为了克服这一问题,作者策略性地修改了一些被归类为最具挑战性的编码数据的响应,直到它们满足基于 Llama 的"模型作为判断者"的标准。通过改进这些具有挑战性的问题,编码数据在质量和难度之间达到了平衡,从而实现了最佳的下游性能。
数学和推理能力数据
作者对推理的定义是:推理为执行多步骤计算并得出正确最终答案的能力。
作者在训练擅长数学推理的模型时遇到以下挑战。为了应对这些挑战,作者应用了以下方法:
- 解决缺少 prompt 的问题:作者从数学背景文档中获取相关的预训练数据,并将其转换为问答格式,然后用于有监督微调。此外,作者识别出模型表现不佳的数学技能,并积极从人类那里获取 prompt 来教授这些技能。为此,作者创建了数学技能分类法(Didolkar et al., 2024),并要求人类相应地提供相关的 prompt 或问题。
- 用逐步推理痕迹增强训练数据:作者使用 Llama 3 为一组 prompt 生成逐步的解决方案。对于每个 prompt,模型生成多个结果。这些结果根据正确答案进行筛选。同时还引入了自我验证,使用 Llama 3 验证给定问题的特定逐步解决方案是否有效。这个过程通过消除模型未生成有效推理痕迹的实例来提高微调数据的质量。
- 筛选错误的推理痕迹:作者训练结果和逐步奖励模型(Lightman et al., 2023; Wang et al., 2023a)来过滤掉中间推理步骤不正确的训练数据。这些奖励模型用于消除无效的逐步推理数据,确保微调数据的高质量。对于更具挑战性的 prompt,作者使用蒙特卡罗树搜索(MCTS)和学习的逐步奖励模型来生成有效的推理痕迹,进一步增强高质量推理数据的收集(Xie et al., 2024)。
- 交替使用代码和文本推理:作者让 Llama 3 通过结合文本推理和相关的 python 代码来解决推理问题。代码执行被用作反馈信号,以消除推理链无效的情况,确保推理过程的正确性。
- 从反馈和错误中学习:为了模拟人类反馈,作者利用不正确的生成(即导致错误推理痕迹的生成)并利用 Llama 3 提供正确的生成来进行错误修正(An et al., 2023b; Welleck et al., 2022; Madaan et al., 2024a)。这种使用不正确示例的反馈并加以纠正的迭代过程有助于提高模型准确推理和从错误中学习的能力。
长上下文能力数据
在最终的预训练阶段,作者将 Llama 3 的上下文长度从 8K tokens 扩展到 128K tokens。与预训练类似,作者发现,在微调过程中,必须仔细调整方案,以平衡短上下文和长上下文的能力。
SFT 和合成数据生成:简单地应用现有仅使用短上下文数据的 SFT 方案,会导致预训练中的长上下文能力显著退化,这表明需要在 SFT 数据混合中加入长上下文数据。然而,实际上,由于阅读冗长上下文的枯燥和耗时性质,很难让人类标注这样的示例,因此作者主要依赖合成数据来填补这一空白。作者使用早期版本的 Llama 3 生成基于关键长上下文用例的合成数据:可能是多轮的问答、长文档的摘要、以及代码库的推理。
- 问答:作者精心策划了一组来自预训练混合数据的长文档。将这些文档分成 8K tokens 的块,并 通过 prompt 让早期版本的 Llama 3 模型生成基于随机选择块的问答对。在训练期间,整篇文档作为上下文使用。
- 摘要:作者对长上下文文档进行了分层摘要,首先使用最强的 Llama 3 8K 上下文模型对 8K 输入长度的块进行摘要,然后对摘要进行汇总。在训练期间,提供整个文档并通过 prompt 让模型生成摘要,同时保留所有重要细节。作者还根据文档的摘要生成问答对,并通过 prompt 让模型提出需要对整个长文档有全局理解的问题。
- 长上下文代码推理:作者解析 Python 文件以识别 import 语句并确定它们的依赖关系。**从中选择最常被依赖的文件,特别是那些被至少五个其他文件引用的文件。**作者从一个代码库中移除其中一个关键文件,并通过 prompt 让模型识别哪些文件依赖这个缺失的文件,以及生成所需的缺失代码。
作者进一步根据序列长度(16K、32K、64K 和 128K)对这些合成生成的样本进行分类,以便更精细地针对输入长度进行目标定位。
通过仔细的消融实验,作者观察到将 0.1% 的合成长上下文数据与原始短上下文数据混合,可以优化在短上下文和长上下文基准上的性能。
DPO:作者观察到**,只要 SFT 模型在长上下文任务上表现良好,在 DPO 中仅使用短上下文训练数据并不会对长上下文性能产生负面影响。**这可能是因为 DPO 的优化器步骤比 SFT 少。鉴于此发现,作者在长上下文 SFT 模型之后为 DPO 保持标准的短上下文训练。
事实性能力数据
幻觉(Hallucinations)仍然是大型语言模型的主要挑战。即使在模型知识匮乏的领域,模型也往往表现得过于自信。尽管事实性问题不止包括幻觉,作者在此首先关注幻觉问题。
作者遵循的原则是,通过后训练使模型“了解自己所知道的”,而不是自以为是地增加新的知识(Gekhman et al., 2024; Mielke et al., 2020)。主要方法是生成与预训练数据中部分事实数据对齐的数据。为了实现这一目标,作者开发了一种利用 Llama 3 上下文能力的知识探测技术。该数据生成过程包括以下步骤:
- 从预训练数据中提取数据片段。
- 通过 prompt 让 Llama 3 生成关于这些片段(上下文)的事实性问题。
- 从 Llama 3 采样对问题的多个回答。
- 使用原始上下文作为参考,并让 Llama 3 作为评判者,对生成的答案的正确性进行评分。
- 使用 Llama 3 作为评判者,对生成的答案的信息量进行评分。
- 对于包含一致信息但错误的回答,生成拒答。
作者使用通过知识探测生成的数据来鼓励模型只回答它有知识的问题,并拒绝回答那些它不确定的问题。此外,预训练数据并不总是事实一致或正确的。因此,作者还收集了一小部分标注的事实性数据,以处理涉及敏感话题且存在事实矛盾或错误的陈述。
数据清理
由于大多数训练数据是由模型生成的,因此需要进行仔细的清理和质量控制。
数据清理。 在早期轮次中,观察到数据中存在许多不良模式,例如过度使用表情符号或感叹号。因此,实施了一系列基于规则的数据删除和修改策略,以过滤或清理有问题的数据。例如,为了缓解过度道歉的语调问题,识别过度使用的短语(如“I'm sorry”或“I apologize”),并仔细平衡数据集中此类样本的比例。
数据修剪(Pruning)。 还应用了一系列基于模型的技术来删除低质量的训练样本,并提高整体模型性能:
- 主题分类: 首先将 Llama 3 8B 微调为主题分类器,并对所有数据进行推理,将其分类为粗粒度的桶(如“数学推理”)和细粒度的桶(如“几何和三角学”)。
- 质量评分: 使用奖励模型(RM)和基于 Llama 的信号为每个样本获取质量评分。对于来自 RM 的评分,考虑 RM 评分排名前四分之一的数据为高质量。对于来自 Llama 的评分,通过 prompt 让 Llama 3 模型按三分制对每个样本进行评分(对于一般英语数据为“准确性”、“指令跟随”和“语气/表达”),对编程数据按两分制评分(“错误识别”和“用户意图”),并将获得最高分的样本视为高质量。RM 和基于 Llama 的评分有很高的不一致率,发现结合这些信号在内部测试集上具有最佳召回率。最终,选择被 RM 或基于 Llama 的过滤器标记为高质量的示例。
- 难度评分: 由于也希望优先处理对模型来说更复杂的示例,使用两个难度度量标准对数据进行评分:Instag 和基于 Llama 的评分。对于 Instag,通过 prompt 让 Llama 3 70B 执行 SFT prompt 的意图标记,意图越多表示复杂性越高。同时通过 prompt 让 Llama 3 对对话的难度进行三分制评分。
- 语义去重: 最后,执行语义去重。首先使用 RoBERTa 对完整对话进行聚类,并在每个聚类内按质量评分 × 难度评分进行排序。然后通过遍历所有排序示例进行贪心选择,仅保留在聚类中与之前看到的示例余弦相似度小于阈值的示例。
Llama3.2
ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
2024年九月底 llama又发布了llama 3.2模型,主要发布内容如下:
- 发布了适用于边缘设备和移动设备的中小型视觉 LLM(11B 和 90B)以及轻量级纯文本模型(1B 和 3B),包括预训练和指令调整版本。
- Llama 3.2 1B 和 3B 型号支持 128K 标记的上下文长度,在边缘本地运行支持高通和联发科硬件,并针对 Arm 处理器进行了优化。
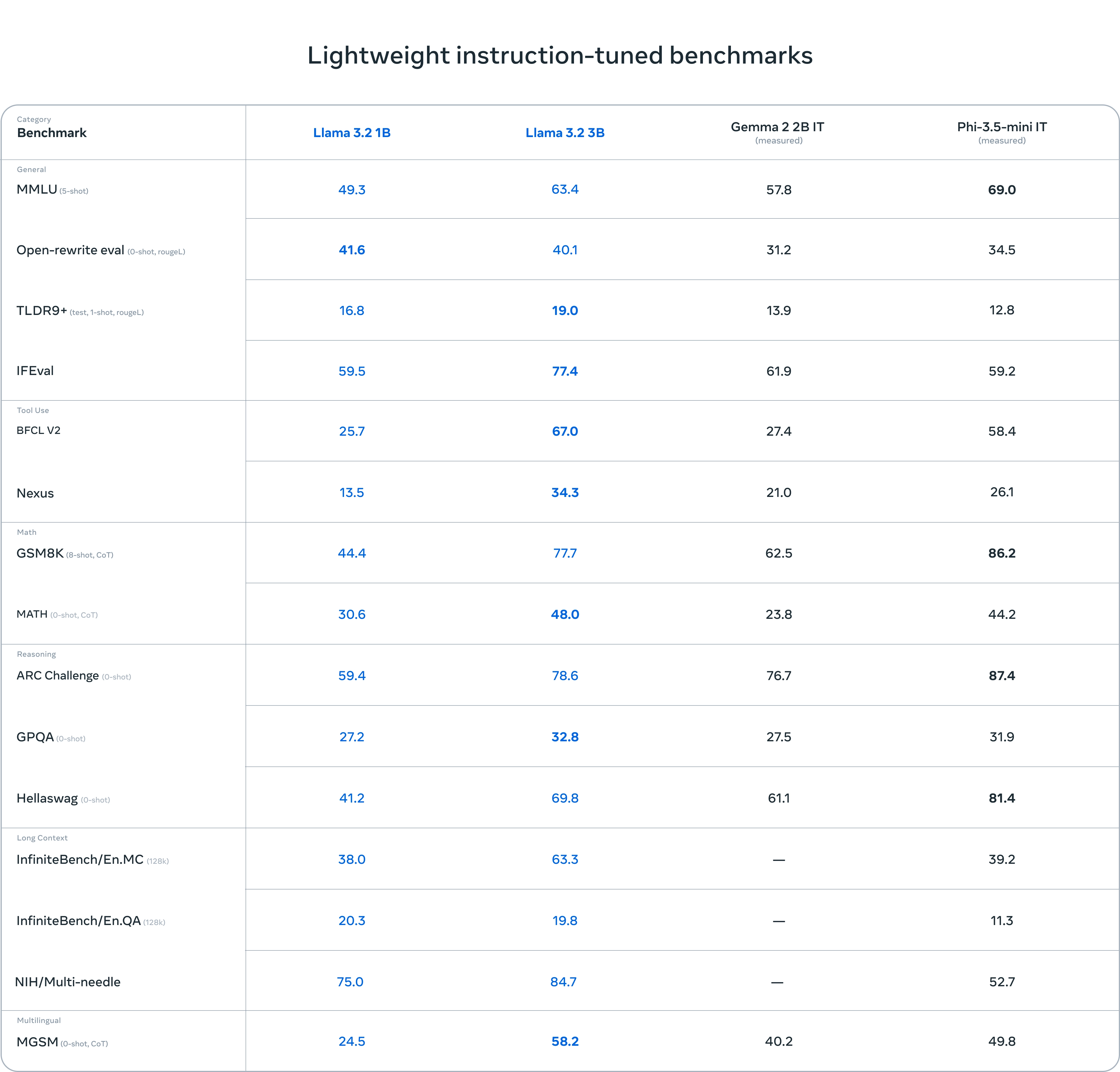
- Llama 3.2 11B 和 90B 视觉模型可直接替代相应的文本模型,同时在图像理解任务方面优于 Claude 3 Haiku 等封闭模型。
Llama 3.3
www.llama.com/docs/model-cards-and-prompt-formats/llama3_3/
2024.12月 3.3又来了 不过这次没什么技术报告,只有个简单介绍,并且模型也没提供预训练版本,只有指令微调后的70B版本
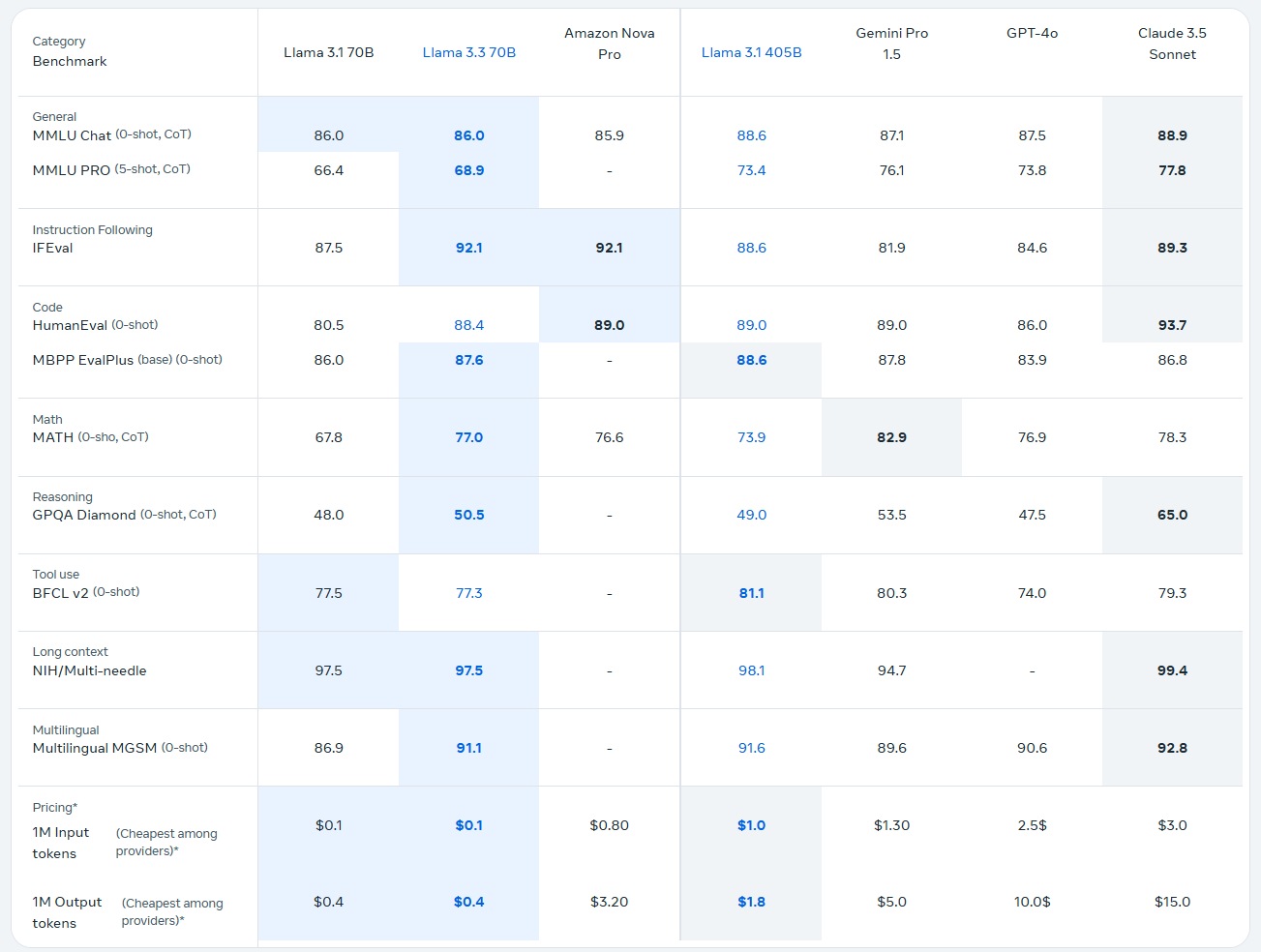
Llama 3.3 是一个纯文本的 70B 指令调整模型,与 Llama 3.1 70B 相比性能更强,与 Llama 3.2 90B 相比用于纯文本应用时性能更强。此外,在某些应用中,Llama 3.3 70B 的性能接近 Llama 3.1 405B。
Reference
LLM 系列超详细解读 (六):LLaMa:开源高效的大语言模型