模型概述
Kimi-VL 是一个高效的开源混合专家视觉-语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(Kimi-VL-A3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等.

模型架构
Kimi-VL 的架构由三个主要部分组成:
- MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters
- 视觉模型 400M native-resolution MoonViT vision encoder.
- MLP Projector
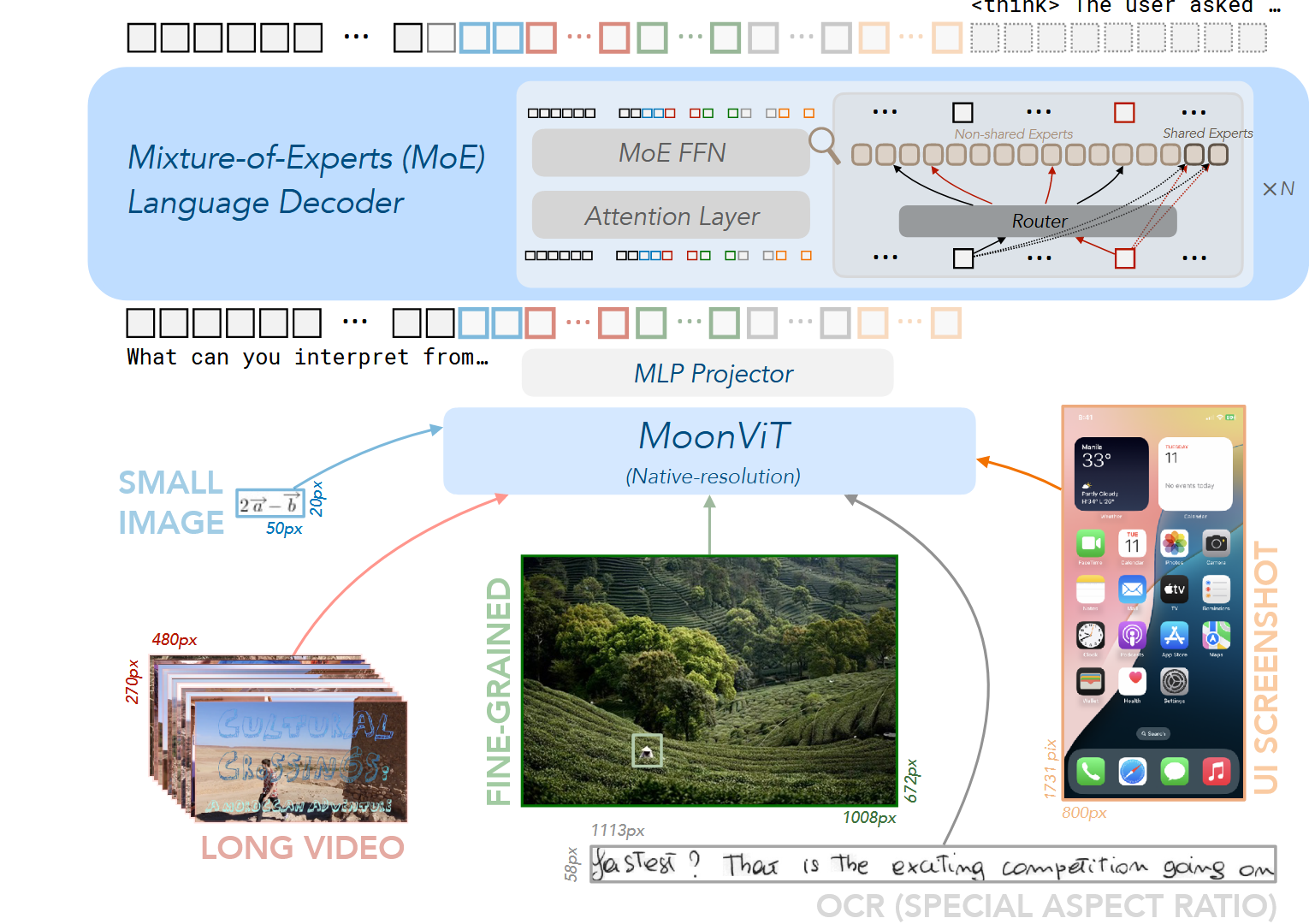
MoonViT: 原生分辨率视觉编码器
MoonViT 被设计为能够以原生分辨率处理各种尺寸的图像,无需复杂的子图像分割和拼接操作。
关键特点:
- 采用 NaViT 的打包方法,将图像分成块,展平,并按顺序连接成一维序列
- 这些预处理操作使 MoonViT 能够与语言模型共享相同的核心计算运算符和优化,例如使用 FlashAttention 支持的可变长度序列注意力机制,确保不同分辨率图像的训练吞吐量不受影响
- 模型从 SigLIP-SO-400M 初始化并持续预训练
- 结合了两种位置嵌入方法:
作者最终也放出了视觉模型的权重:
🔖 https://huggingface.co/moonshotai/MoonViT-SO-400M
MLP 投影器
MLP 投影器是连接视觉编码器和语言模型的桥梁,由两层 MLP 组成:
处理流程:
- 首先使用像素重排(Pixel Shuffle) 操作压缩由 MoonViT 提取的图像特征的空间维度, 执行 2×2 空间域下采样,相应地扩展通道维度
- 将重排后的特征输入两层 MLP,将其投影到 LLM 嵌入的维度
混合专家(MoE)语言模型
Kimi-VL 的语言模型使用 Moonlight 模型,这是一个具有 2.8B 激活参数和 16B 总参数的 MoE 语言模型,架构类似于 DeepSeek-V3.
实现细节:
- 从 Moonlight 预训练阶段的中间检查点初始化
- 该检查点已处理 5.2T 纯文本数据并激活了 8192 令牌(8K)上下文Tokens
- 随后使用多模态和纯文本数据的联合配方进行联合预训练,总计 2.3T Tokens
🔖 https://huggingface.co/moonshotai/Moonlight-16B-A3B
Muon 优化器
Kimi-VL 使用增强版的 Muon 优化器进行模型优化:
增强特点:
- 与原始 Muon 优化器相比,增加了权重衰减并仔细调整了每个参数的更新比例
- 遵循 ZeRO-1 优化策略开发了 Muon 的分布式实现
- 实现最佳内存效率和减少通信开销,同时保持算法的数学特性
- 在整个训练过程中用于优化所有模型参数,包括视觉编码器、投影器和语言模型
这部分需要参考 Moonlight
预训练阶段(Pre-Training)
Kimi-VL 的训练包括多个阶段,总计训练 4.4T tokens,整体的流程和训练参数如下面两图所示。

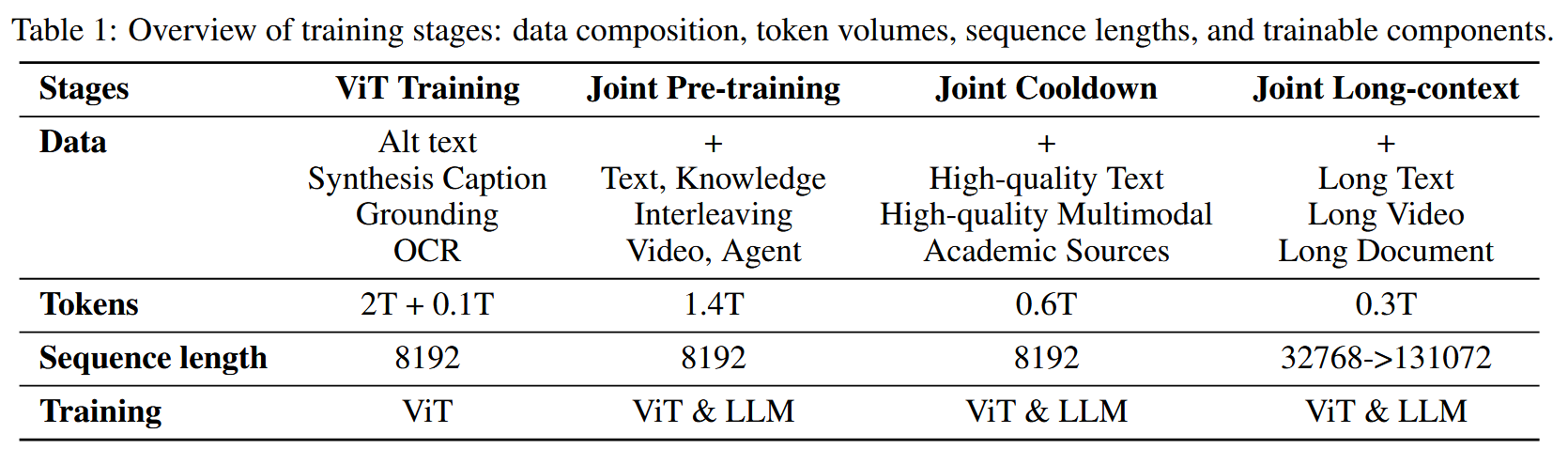
ViT Training&Align
MoonViT 在图像-文本对上进行训练,文本组件包含各种目标:图像替代文本(image alt texts)、合成标题、grounding bboxes 和 OCR 文本。
训练目标:
- SigLIP 损失 (对比损失的变体)
- 以输入图像为条件的caption生成交叉熵损失
最终损失函数:
其中
实现细节:
- 图像和文本编码器计算对比损失,为加速训练,两个编码器都使用 SigLIP SO-400M 权重初始化
- 文本解码器执行以图像编码器特征为条件的下一个token预测(NTP),文本解码器从一个小型仅解码器语言模型初始化
- 实施渐进分辨率采样策略,逐步允许更大尺寸
- 在 CoCa 类似阶段使用 2T tokens训练 ViT 后,使用另外 0.1T tokens将 MoonViT 与 MoE 语言模型对齐, 对齐阶段MoonViT 和MLP projector需要更新权重。
Joint Pre-training
在联合预训练阶段,模型使用纯文本数据(从与初始语言模型相同的分布中采样)和各种多模态数据的组合进行训练。
训练细节:
- 从加载的 LLM 检查点继续训练,使用相同的学习率调度器
- 训练量:1.4T Tokens
- 初始步骤仅使用语言数据,之后多模态数据的比例逐渐增加
- 通过这种渐进方法和前面的对齐阶段,联合预训练保留了模型的语言能力,同时成功整合了视觉理解能力
Joint Cooldown
联合预训练阶段之后是多模态冷却阶段,模型使用高质量语言和多模态数据集继续训练,以确保卓越的性能。
语言部分:
- 经验研究表明,在冷却阶段纳入合成数据会带来显著的性能改进,特别是在数学推理、基于知识的任务和代码生成方面
- 冷却数据集的一般文本部分从预训练语料库的高质量子集
- 而对于数学、知识和代码领域,采用混合方法:
多模态部分:
- 同样使用了文本冷却数据中的两种策略, 即QA数据合成和高质量子集重放
- 另外,为了允许更全面的以视觉为中心的感知和理解,过滤并重写各种学术视觉或视觉语言数据源为 QA 对
- 这些语言和多模态 QA 对在冷却阶段的比例保持在较低水平,以避免过拟合这些 QA 模式
Joint Long-contex
在最后的预训练阶段,模型的上下文长度从 8192(8K)扩展到 131072(128K),其 RoPE 嵌入的逆频率(reverse frequency)从 50,000 重置为 800,000。
实施细节:
- 联合长上下文阶段分为两个子阶段,每个子阶段将模型的上下文长度扩展四倍
- 数据组成:在每个子阶段中,过滤并上采样长数据的比例至 25%,使用剩余的 75% token重放其前一阶段的较短数据
- 这种组成允许模型有效学习长上下文理解,同时保持短上下文能力
- 为了使模型能够在纯文本和多模态输入上激活长上下文能力,长数据不仅包括长文本,还包括长多模态数据:
- 类似于冷却数据,也合成了一小部分 QA 对以增强长上下文激活的学习效率
后训练阶段(Post-Training)

联合监督微调(SFT)
在这个阶段,通过基于指令的微调来增强 Kimi-VL 的基础模型,提高其遵循指令和参与对话的能力,最终创建交互式 Kimi-VL 模型。
实现方法:
- 采用 ChatML 格式,允许有针对性的指令优化,同时保持与 Kimi-VL 的架构一致性
- 使用纯文本和视觉语言 SFT 数据的混合优化语言模型、MLP 投影器和视觉编码器
- 监督仅应用于回答和特殊token,系统和用户提示被屏蔽
- 精心策划的多模态指令-响应对,通过格式感知打包确保明确的对话角色标记(system,user,assistant)、结构化视觉嵌入注入(<image>)和跨模态位置关系(图文和多图顺序关系)的保存
- 为确保模型在对话中的全面熟练程度,纳入多模态数据和 Moonlight 中使用的纯文本对话数据的混合,确保其在各种对话场景中的多功能性
训练过程:
- 首先在 32k 令牌的序列长度上训练模型 1 个epoch
- 然后在 128k 令牌的序列长度上再训练 1 个epoch
- 在第一阶段(32K),学习率从 衰减到
- 在第二阶段(128K),学习率重新预热到 ,最终衰减到
- 为提高训练效率,将多个训练示例打包到一个训练序列中
长链思考监督微调
使用精炼的 RL 提示集,通过prompt工程构建一个小而高质量的长链思考预热数据集,包含针对文本和图像输入的经过准确验证的推理路径。
方法特点: