Janus
论文名称: Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
论文地址: arxiv.org/pdf/2410.13848
项目主页: github.com/deepseek-ai/Janus
模型
Janus 是使用一个统一的 Transformer 架构来统一多模态图像理解和多模态图像生成任务的模型。这种方法通常使用单个视觉编码器来处理这 2 个任务的输入。然而,多模态理解和生成任务所需的表征差异很大:多模态理解任务中,视觉编码器的目的是提取高级语义信息。理解任务的输出不仅涉及从图像中提取信息,还涉及复杂的语义推理。因此,视觉编码器表示的粒度往往主要集中在高维语义的表征上。相比之下,视觉生成任务中,主要关注点是生成局部细节并保持图像中的全局一致性。在这种情况下,表征需要表示出细粒度的空间结构,以及纹理细节。在同一空间中统一这两个任务的表示将导致冲突。因此,现有的多模态理解和生成的统一模型通常会影响多模态理解性能,明显低于最先进的多模态理解模型。
Janus 作为一个类似的统一多模态模型,为了解决这个问题,将视觉编码进行解耦来进行多模态理解和生成。Janus 引入了 2 个独立的视觉编码路径:一个用于多模态理解,一个用于多模态生成,由相同的 Transformer 架构统一。
这有两个主要好处:
- Janus 减轻了源自多模态理解和生成的不同粒度需求的冲突,并消除了在选择视觉编码器时需要在 2 个任务之间进行权衡的需要。
- Janus 灵活且可扩展。在解耦后,理解和生成任务都可以采用各自领域里最先进的编码技术。
如下图所示是 Janus 的架构。对于纯文本理解、多模态理解和视觉生成,Janus 应用独立的编码方法将原始输入转换为特征,然后由统一的 Autoregressive Transformer 处理。
- 文本理解:使用 LLM 内置的 tokenizer 将文本转换为离散的 ID,并获得与每个 ID 对应的特征表征。
- 多模态理解:使用 SigLIPEncoder 从图像中提取高维语义特征。这些特征从二维网格 flattened 为一维序列,利用 Understanding Adaptor 将这些图像特征映射到 LLM 的输入空间。
- 图像生成:使用 LLamaGen中的 VQ tokenizer 将图像转换为离散的 ID。在 ID 序列被 flattened 为一维之后,使用 Generation Adaptor 将每个 ID 对应的 codebook embedding 映射到 LLM 的输入空间。
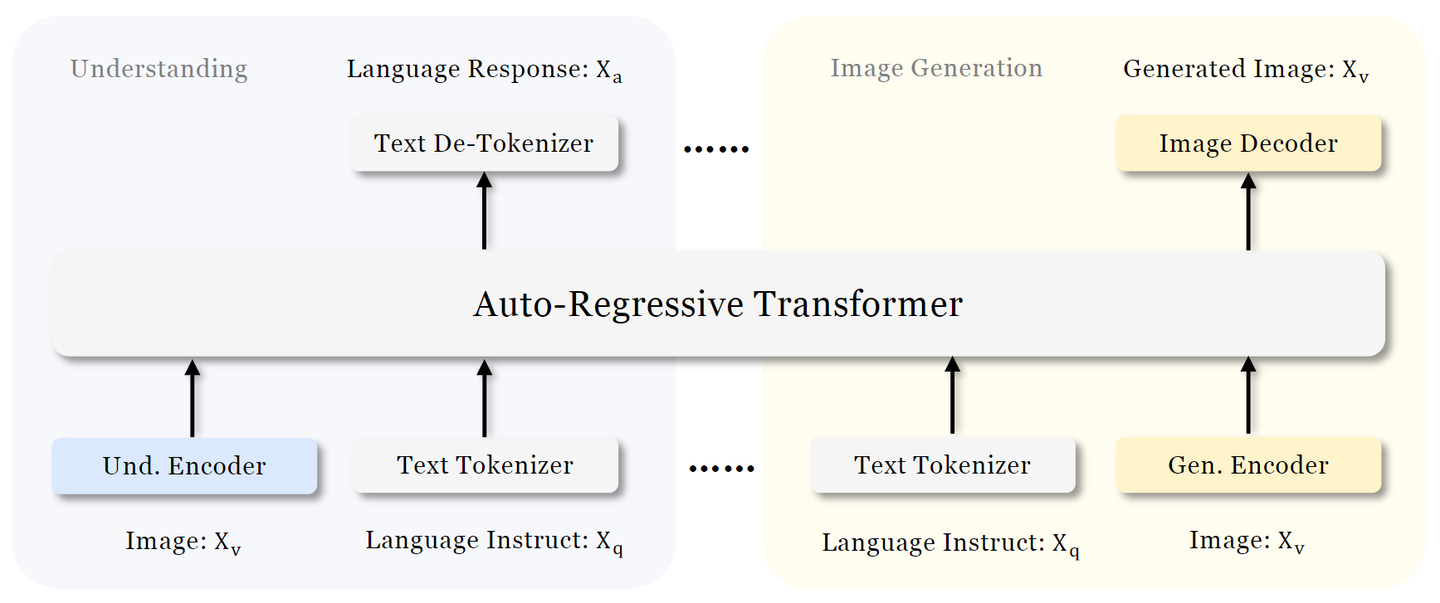
然后,将这些特征序列 Concatenate 起来形成一个多模态特征序列,然后将其输入到 LLM 进行处理。LLM 内置的预测头用于纯文本理解和多模态理解任务中的文本预测,而随机初始化的预测头用于生成任务中的图像预测。
整个模型遵循自回归框架,无需专门设计 Attention Mask。
训练策略
Janus 的训练分为 3 个阶段,如下图所示。
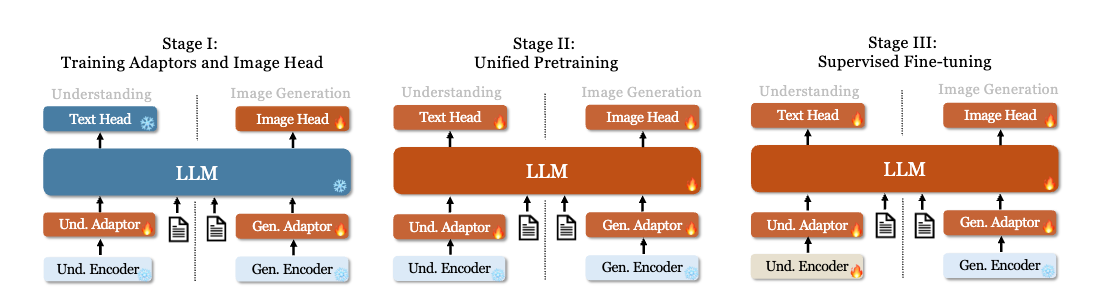
第 1 阶段:训练 Adaptors 和 Image Head。
这一阶段的主要目标是在嵌入空间中创建视觉和语言元素之间的概念联系,使 LLM 能够理解图像中显示的实体,并具有初步的视觉生成能力。作者在这个阶段保持 Vision Encoder (SigLIP) 和 LLM 完全冻结,只允许更新 Understanding Adaptor、Generation Adaptor 和 Image Head 中的可训练参数。
第 2 阶段:联合预训练,除了理解编码器和生成编码器之外的所有组件都更新参数。
在这个阶段,作者使用多模态语料库进行统一预训练,使 Janus 能够学习多模态理解和生成。作者解冻 LLM 并利用所有类型的训练数据:纯文本数据、多模态理解数据和视觉生成数据。受 PixArt的启发,作者首先使用 ImageNet-1K 进行简单的视觉生成训练,以帮助模型掌握基本像素依赖关系。随后,作者使用通用 T2I 数据增强了模型的开放域视觉生成能力。
第 3 阶段:有监督微调,进一步解锁理解编码器的参数。
这个阶段作者使用 instruction tuning 数据,增强其指令跟随和对话能力。作者微调除生成编码器之外的所有参数。作者只微调答案,mask 掉系统和用户的提示。为了确保 Janus 在多模态理解和生成方面的熟练程度,作者不会为特定任务微调单独的模型。相反,作者使用纯文本对话数据、多模态理解数据和视觉生成数据的混合,确保跨各种场景的多功能性。
训练目标
Janus 是一个自回归模型,作者在训练期间简单地采用交叉熵损失:
这里, \(P(\cdot|\cdot)\) 表示由 Janus 的权重建模的条件概率。对于纯文本理解和多模态理解任务,作者计算纯文本序列的 loss。对于视觉生成任务,作者仅在图像序列上计算 loss。为了使设计简单,没有为不同的任务分配不同的权重。
推理过程
在推理过程中,Janus 模型采用 next-token prediction 方法。对于纯文本理解和多模态理解,作者遵循从预测分布顺序采样 token 的标准实践。对于图像生成,利用 classifier-free guidance (CFG),类似于先前的工作 Muse,LLamaGen。具体来说,对于每个 token,logit 的计算如下: \(l_g = l_u+s(l_c-l_u)\) ,其中 \(l_c\) 是条件 logit, \(l_u\) 是无条件 logit, \(s\) 是无分类器指导的尺度。以下评估的默认数量为 5。
实验设置
Janus 利用最大支持序列长度为 4096 的 DeepSeek-LLM (1.3B)作为基础语言模型。对于理解任务中使用的视觉编码器,选择 SigLIP-Large-Patch16-384。generation encoder 有一个大小为 16,384 的 codebook,并将图像下采样 16 倍。Understanding Adaptor 和 Generation Adaptor 都是两层 MLP。所有图像都被调整为 384×384 像素。对于多模态理解数据,调整图像的长边,并用背景颜色 (RGB: 127, 127, 127) 填充短边,达到 384。对于视觉生成数据,短边被调整为 384,长边裁剪为 384。
训练数据
阶段1:
作者使用包含来自 ShareGPT4V 的 1.25 million 个图文配对字幕的数据集做多模式理解,以及来自 ImageNet-1K 的大约 1.2 million 样本用于视觉生成。ShareGPT4V 数据格式化为 "<image><text>"。ImageNet 数据使用类别名称组织成文本到图像数据格式:"<category_name><image>"。
阶段2:将数据组织成以下类别。
- 纯文本数据:使用来自 DeepSeek-LLM 的预训练文本 copus。
- 交错图像文本数据:使用 WikiHow 和 WIT 数据集。
- Image caption 数据。
- 表和图表数据:使用来自 DeepSeek-VL 的相应表格和图表数据。
- 视觉生成数据:利用图像标题对 (包括 2M 内部数据)。视觉生成数据格式:"<caption><image>"。
在训练期间,以 25% 的概率只使用标题的第 1 句,鼓励模型为短描述开发强大的生成能力。ImageNet 数据只在前 120K 训练步骤中提出,而其他数据集的图像出现在后面的 60K 步。这种方法帮助模型首先学习基本像素依赖关系,然后再发展到更复杂的场景理解。
阶段3:
对于文本理解,使用来自Lllava-onevision的数据。对于多模态理解,使用来自Lllava-onevision等的指令微调数据。对于视觉生成,使用来自Laion等以及 4M 内部数据图像-文本对。利用以下格式进行指令微调:"用户:<Input Message>\n Assistant:<Response>"。
评测
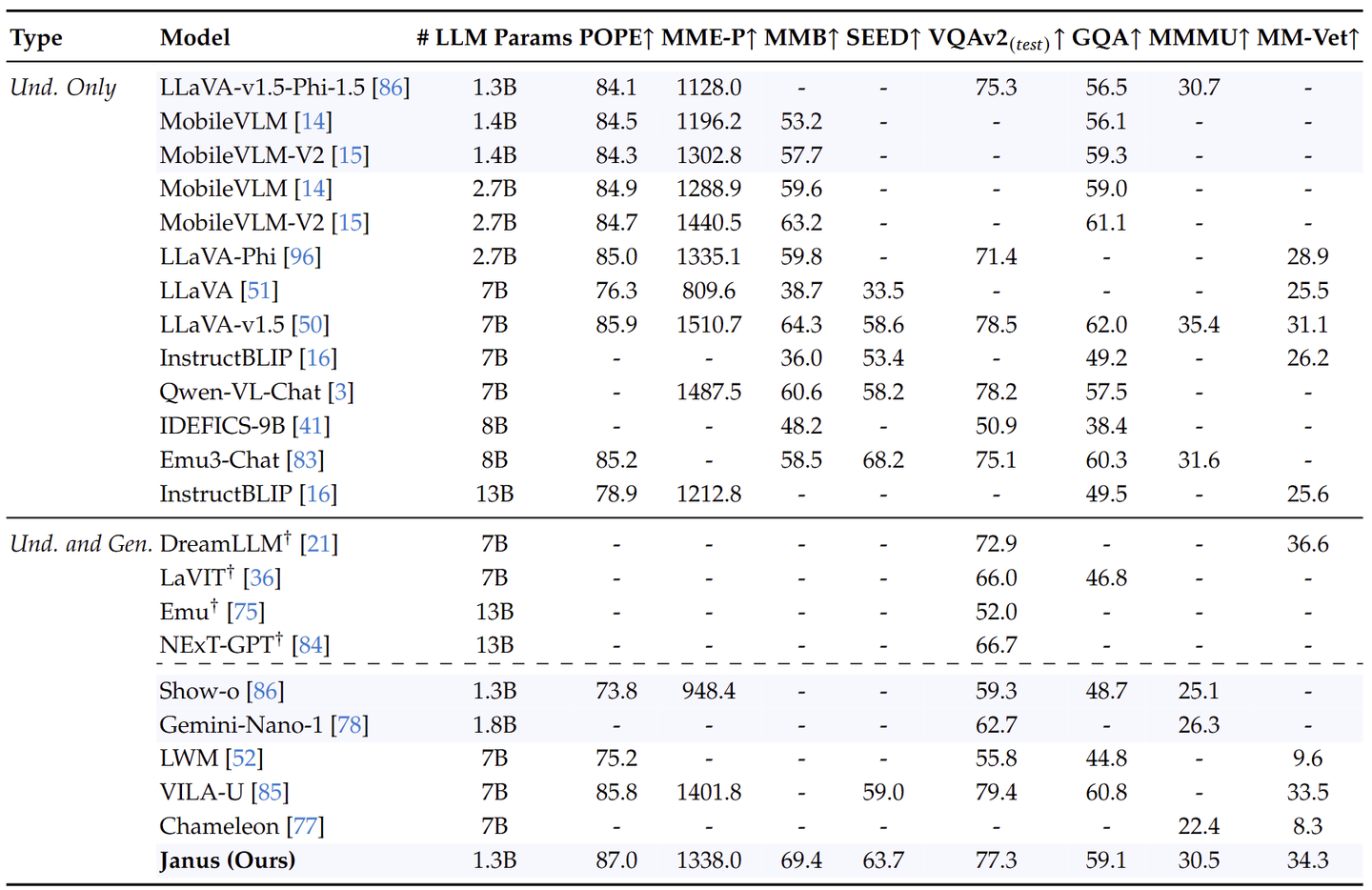
多模态理解
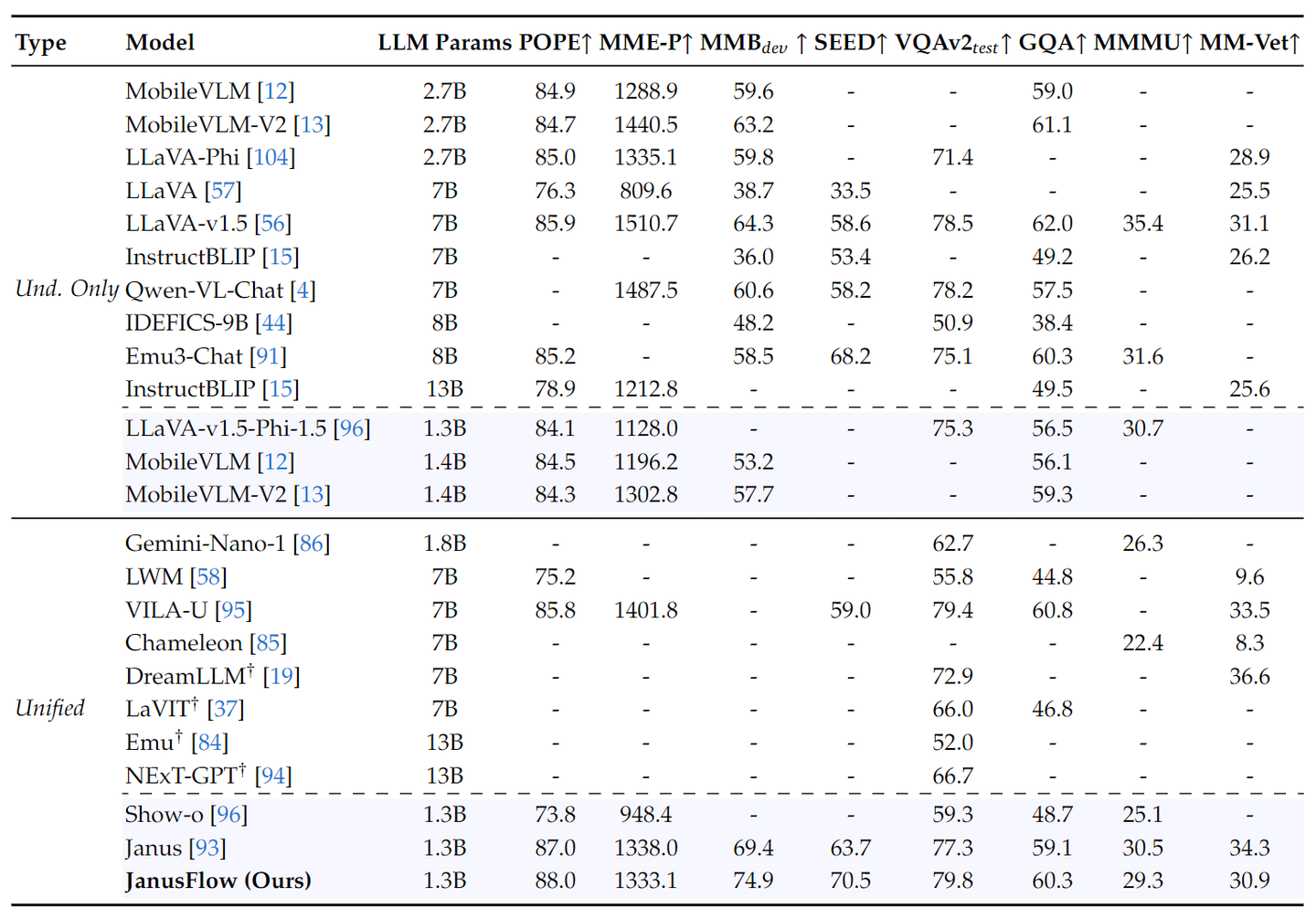
如下图所示,比较了 Janus 与最先进的 Unified 模型以及 Understanding-only 模型。 Janus 在类似规模的模型中取得了最好的结果。具体来说,与之前的最佳统一模型 Show-o 相比,Janus 在 MME 和 GQA 数据集上分别实现了 41% (949 → 1338) 和 30% (48.7 → 59.1) 的性能改进。这可以归因于 Janus 将视觉编码解耦以进行多模态理解和生成,减轻了这两个任务之间的冲突。与尺寸明显较大的模型相比,Janus 仍然具有很强的竞争力。例如,Janus 在多个数据集上优于 LLaVA-v1.5 (7B),包括 POPE、MMbench、SEED Bench 和 MM-Vet。
(多模态) 视觉生成
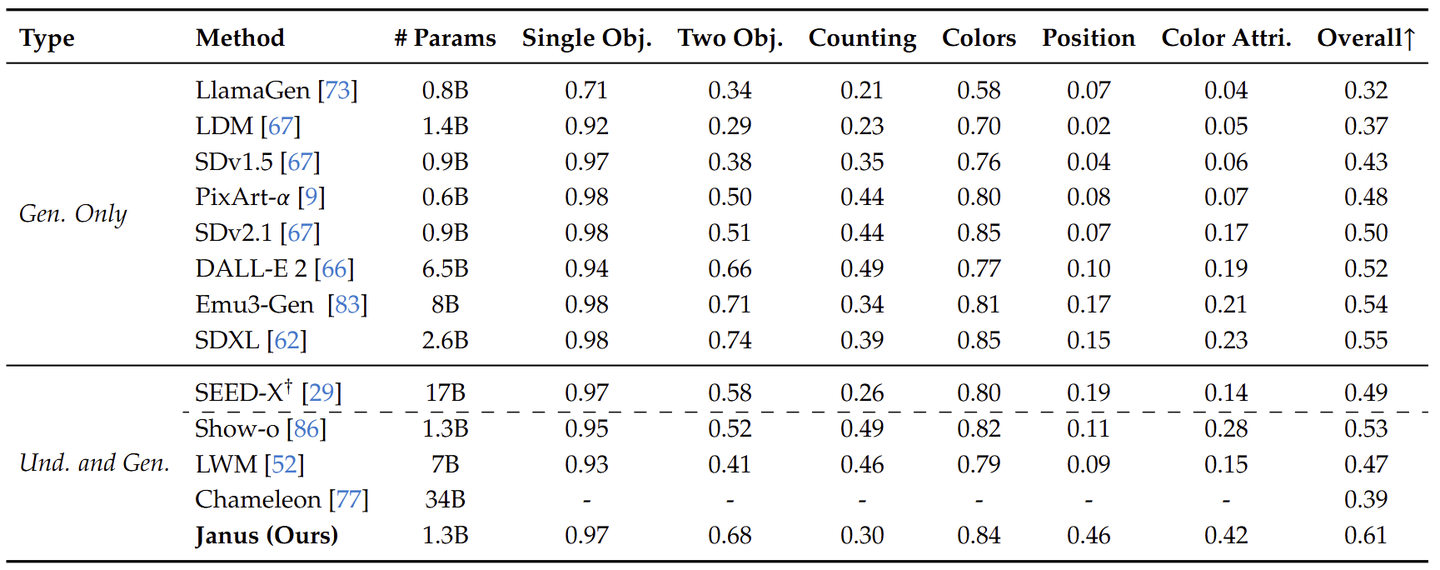
作者报告了 GenEval、COCO30K 和 MJHQ-30K 基准上的视觉生成性能,如下图所示。Janus 在 GenEval 上获得了 61% 的整体精度,优于之前最好的统一模型 Show-o (53%) 和一些流行的生成模型,例如 SDXL (55%) 和 DALL-E 2 (52%)。这表明本文方法具有更好的指令跟随能力。
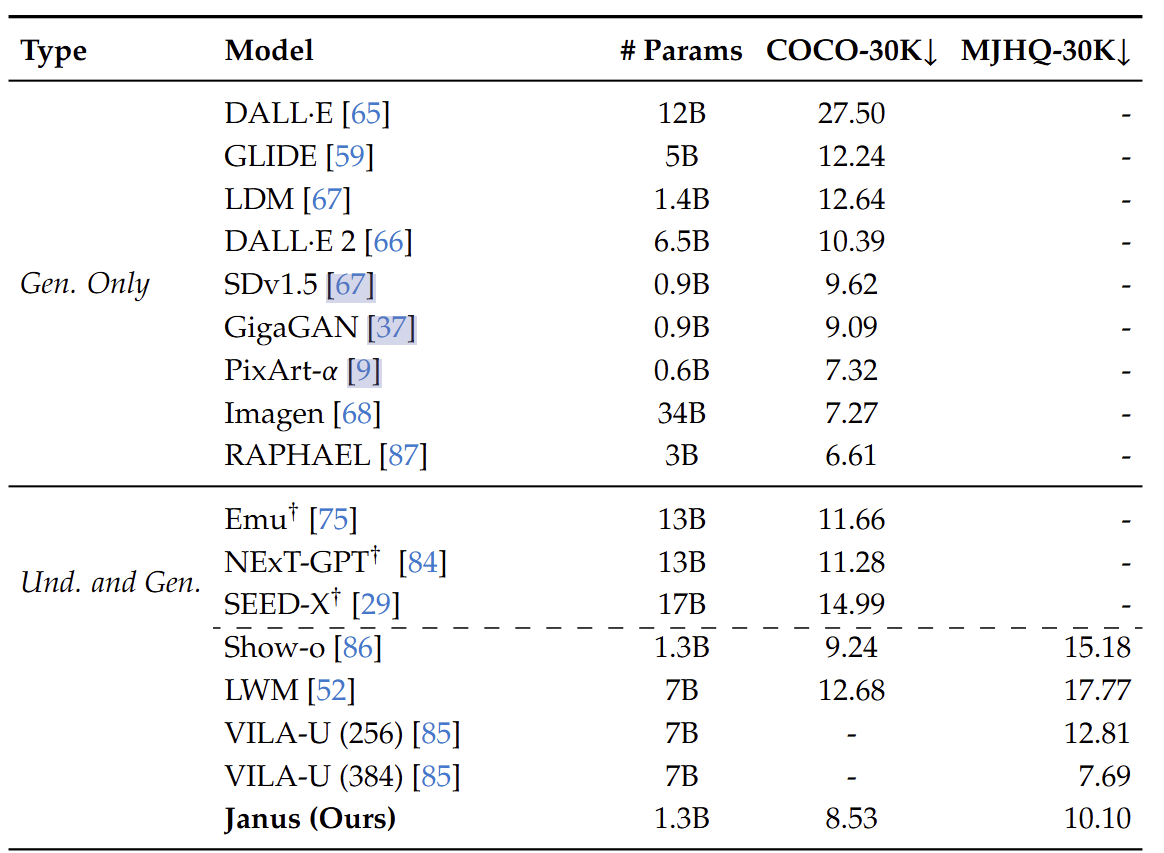
如下表所示,Janus 在 COCO-30K 和 MJHQ-30K Benchmark 上分别实现了 8.53 和 10.10 的 FID,超过了统一模型 Show-o 和 LWM,并且与一些众所周知的仅生成方法相比表现出具有竞争力的性能方法。这表明 Janus 生成的图像具有良好的质量,并突出了其在视觉生成方面的潜力。
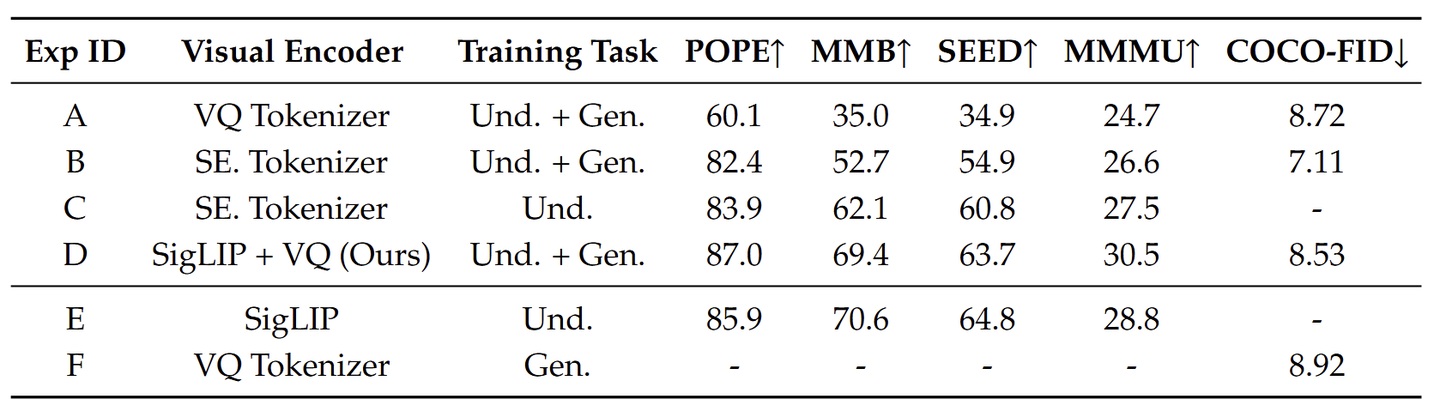
有一个消融实验的细节值得注意,即如图 7 所示。Exp-D 为 Unified Training,Exp-E 相当于是训练了一个纯理解模型,Exp-F 相当于是训练了一个纯生成模型。对于纯理解模型,作者省略了视觉生成数据;对于纯生成模型,作者省略了理解数据。注意,统一训练和纯理解训练对于理解部分遵循相同的步骤,统一训练和纯生成训练对于生成部分遵循相同的步骤。实验结果表明,Unified Training 的性能与 Pure Understanding 或 Pure Generation 的训练相当。这表明 Janus 能够结合强大的生成能力,同时最低限度地影响多模态理解性能。
视觉生成可视化
下图显示了 Janus 多模态理解能力的定性结果,与 Chameleton 和 Show-o 相比。Janus 准确地解释文本标题并捕获记忆中传达的情感。相比之下,Chameleon 和 Show-o 都难以准确识别图像中的文本。此外,Chameleon 无法识别 meme 中的对象,而 Show-o 误解了狗的颜色。这些示例强调,与 Chameleon 和 Show-o 使用的共享编码器相比,解耦视觉编码器显着提高了 Janus 的细粒度多模态理解能力。

Janus-Pro
论文名称:Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
项目主页:github.com/deepseek-ai/Janusgithub.com/deepseek-ai/Janus
模型
Janus 在 1B 参数量级上得到验证。然而,由于训练数据量有限,模型容量相对较小,存在一定的不足,例如:在短提示图像生成的性能次优,文生图质量不稳定。
Janus-Pro 是一种增强的 Janus 版本,结合了 3 个维度的改进:训练策略、数据和模型大小。Janus-Pro 系列包括两个模型大小:1B 和 7B,展示了视觉编码解码方法的可扩展性。
作者在多个基准上评估了 Janus-Pro,结果揭示了其优越的多模态理解能力,并显着提高了文生图的指令跟随性能。Janus-Pro-7B 在多模态理解基准 MMBench 上得分为 79.2,超过了最先进的统一多模态模型,例如 Janus (69.4)、TokenFlow (68.9) 和 MetaMorph (75.2)。此外,在文生图指令跟随排行榜 GenEval 中,Janus-Pro-7B 得分为 0.80,优于 Janus (0.61)、DALL-E 3 (0.67) 和 SD-3 Medium (0.74)。

Janus-Pro 的模型架构与 Janus 完全相同。整体架构的核心设计原则是将视觉编码解耦以进行多模态理解和生成。
作者应用独立的编码方法将原始输入转换为特征,然后由 Unified Autoregressive Transformer 来处理。
对于多模态理解,使用 SigLIP Encoder 从图像中提取高维语义特征 (和 Janus 一致)。这些特征从二维网格 flattened 为一维序列,利用 Understanding Adaptor 将这些图像特征映射到 LLM 输入空间。
对于视觉生成任务,使用 LLamaGen中的 VQ tokenizer 将图像转换为离散的 ID (和 Janus 一致)。在 ID 序列被 flattened 为 1D 之后,使用 Generation Adaptor 将每个ID 对应的 codebook 嵌入映射到 LLM 输入空间。
然后,作者将这些特征序列连接起来形成一个多模态特征序列,然后将其输入到 LLM 进行处理。除了 LLM 的内置预测头外,作者还利用随机初始化的预测头进行视觉生成任务中的图像预测 (和 Janus 一致)。整个模型遵循 Autoregressive 框架。
训练策略
Janus 的训练分为 3 个阶段
- 第 1 阶段:训练 Adaptors 和 Image Head。
- 第 2 阶段:联合预训练,除了理解编码器和生成编码器之外的所有组件都更新参数。
- 第 3 阶段:有监督微调,进一步解锁理解编码器的参数。
但是 Janus 的训练策略有问题:
在第 2 阶段,Janus 按照 PixArt 将文生图的训练分为 2 部分。第 1 部分在 ImageNet 数据上进行训练,使用图像类别名称作为文生图的提示,目标是对像素依赖进行建模。第 2 部分在正常的文生图数据上训练。实施过程中,第 2 阶段的文本-图像训练步骤中有 66.67% 被分配给第 1 部分。
但是通过进一步的实验,作者发现这种策略是次优的,并导致计算效率显著低下。
第 1 阶段较长训练:在第 1 阶段增加训练步骤,允许在 ImageNet 数据集上进行足够的训练。本文的研究结果表明,即使 LLM 参数固定,该模型也能有效建模像素依赖性,并根据类别名称生成合理的图像。
第 2 阶段集中训练:在第 2 阶段丢弃 ImageNet 数据,直接利用正常的文生图数据训练模型,根据密集描述生成图像。这种重新设计的方法使第 2 阶段能够更有效地利用文生图数据,提高训练效率和整体性能。
作者还调整了第 3 阶段监督微调过程在不同类型数据集上的数据比率,将多模态数据、纯文本数据和文本图像数据的比例从 7:3:10 更改为 5:1:4。通过略微降低文生图数据的比例,作者观察到这种调整允许我们保持强大的视觉生成能力,同时实现改进的多模态理解性能。
数据缩放
作者在多模态理解和视觉生成方面扩展了用于 Janus 的训练数据。
- 多模态理解:对于第 2 阶段的预训练数据,参考 DeepSeekVL2 并添加大约 90 万个样本。这些包括图像标题数据集 (例如 YFCC),以及表、图表和文档理解的数据 (例如,Docmatix)。对于第 3 阶段的监督微调数据,作者还结合了 DeepSeek-VL2 的附加数据集,例如 MEME 理解、中文会话数据和旨在增强对话体验的数据集。这些添加显着扩展了模型的能力,丰富了它在提高整体对话体验的同时处理各种任务的能力。
- 视觉生成:作者观察到,先前版本的 Janus 中使用的真实世界数据缺乏质量并且包含显著的噪声,通常会导致文生图的不稳定性,从而导致美学上较差的输出。在 Janus-Pro 中,作者结合了大约 7200 万个合成美学数据,在统一的预训练阶段将真实数据与合成数据的比率提高到 1:1。这些合成数据样本的提示是公开的。实验表明,该模型在对合成数据进行训练时收敛速度更快,得到的文生图不仅更稳定,而且显著提高了审美质量。
模型缩放
先前版本的 Janus 使用 1.5B LLM 验证了视觉编码解耦的有效性。在 Janus-Pro 中,作者将模型缩放到 7B,1.5B 和 7B LLM 的超参数如图 10 所示。作者观察到,当使用更大规模的 LLM 时,与较小的模型相比,多模态理解和视觉生成的损失收敛速度显著提高。这一发现进一步验证了这种方法的强大可扩展性。
实验设置
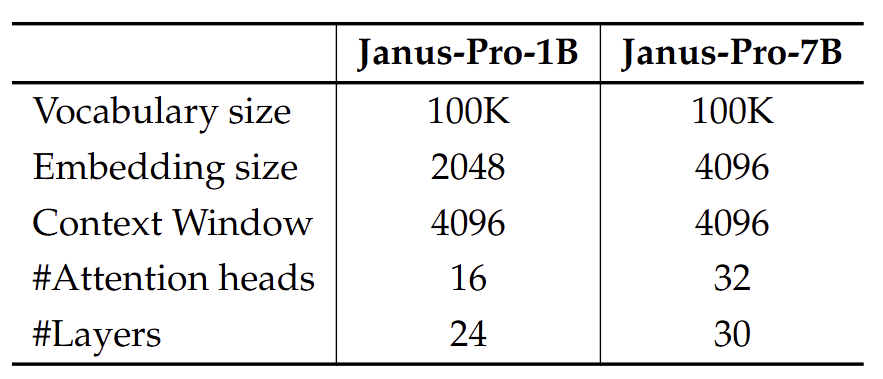
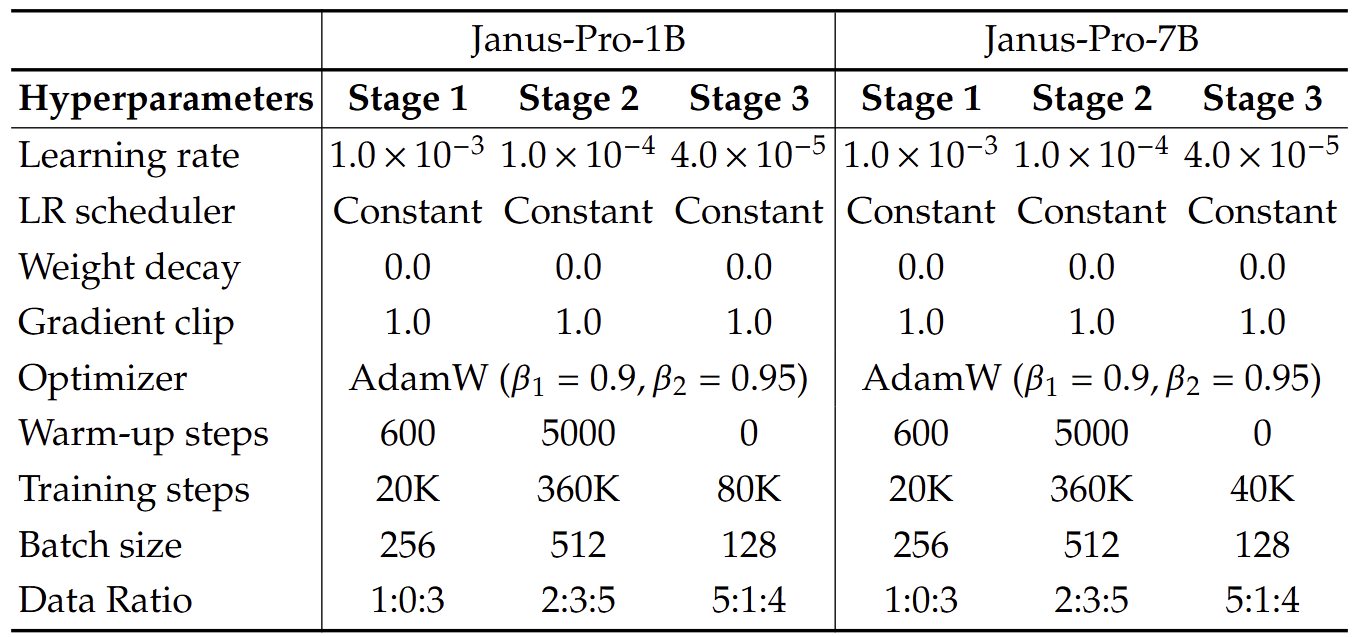
作者利用最大支持序列长度为 4096 的 DeepSeek-LLM (1.5B 和 7B) 作为基础语言模型。对于理解任务中使用的视觉编码器,选择 SigLIP-Large-Patch16-384。生成编码器有一个大小为 16,384 的 codebook,并将图像下采样 16 倍。Understanding Adaptor 和 Generation Adaptor 都是 2 层的 MLP。每个阶段的详细超参数如下图所示。所有图像都被调整为 384×384 像素。
对于多模态理解数据,作者调整图像的长边,并用背景颜色 (RGB: 127, 127, 127) 填充短边,达到 384。
对于视觉生成数据,短边被调整为 384,长边裁剪为 384。
在训练期间使用序列打包来提高训练效率。Janus 使用 HAI-LLM (幻方-深度求索研发的深度学习训练工具) 训练和评估,这是一个建立在 PyTorch 之上的轻量级且高效的分布式训练框架。对于 1.5B/7B 的模型,整个训练过程在 16/32 个 mode 的集群上大约需要 7/14 天,每个模型配备 8 个 Nvidia A100 (40GB) GPU。
评测
多模态理解
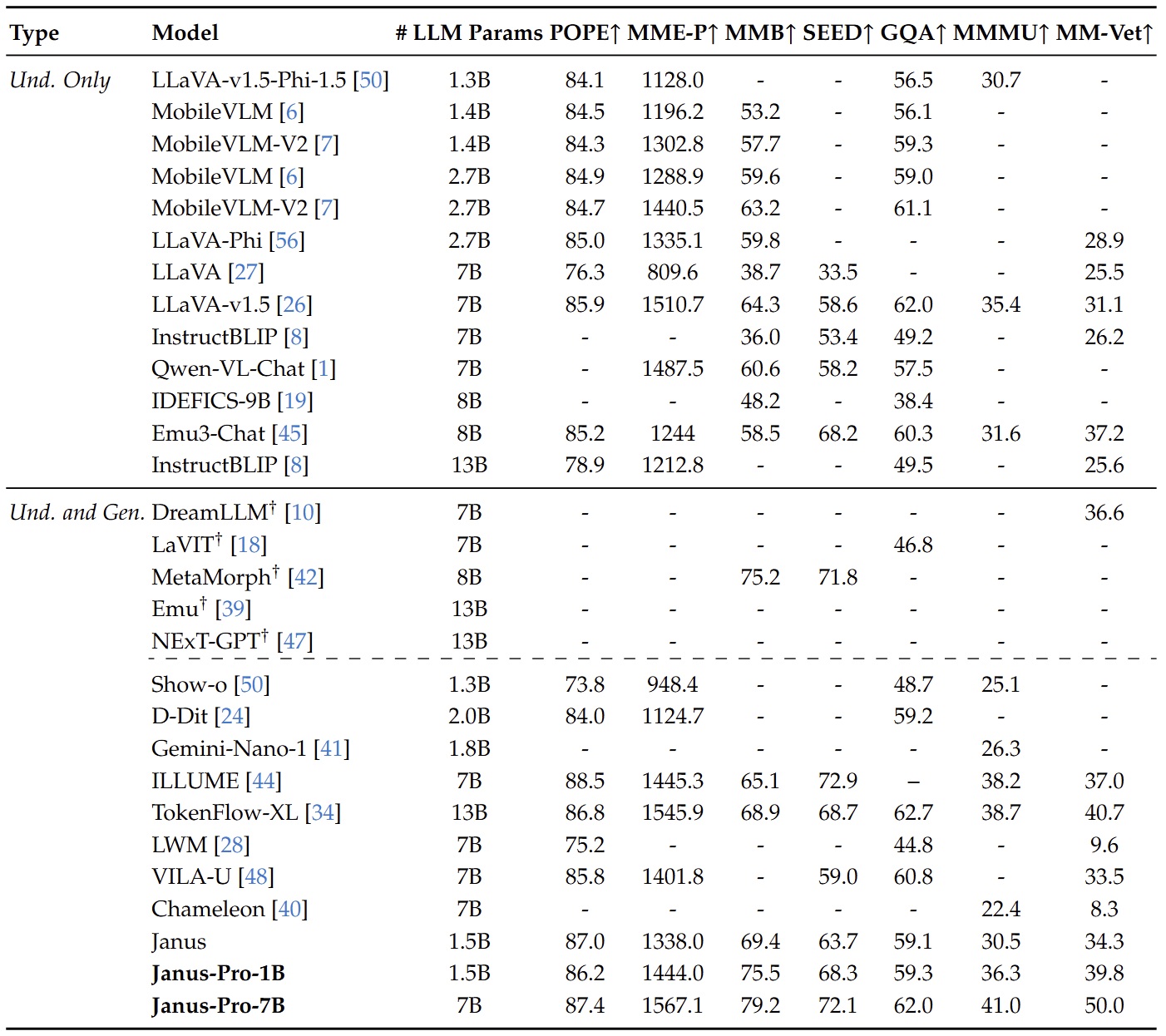
为了评估多模态理解能力,作者在广泛认可的基于图像的视觉语言基准上评估我们的模型,其中包括 GQA,POPE,MME,SEED,MMB,MM-Vet,和 MMMU。
下图比较了 Janus-Pro 和最先进的 Unified Model 和 Pure Understanding Model。 Janus-Pro 取得了最好的结果。这可以归因于解耦视觉编码以进行多模态理解和生成,减轻了这两个任务之间的冲突。与尺寸明显较大的模型相比,Janus-Pro 仍然具有很强的竞争力。例如,除了 GQA 之外,Janus-Pro-7B 在所有基准测试中都优于 TokenFlow-XL (13B)。
视觉生成
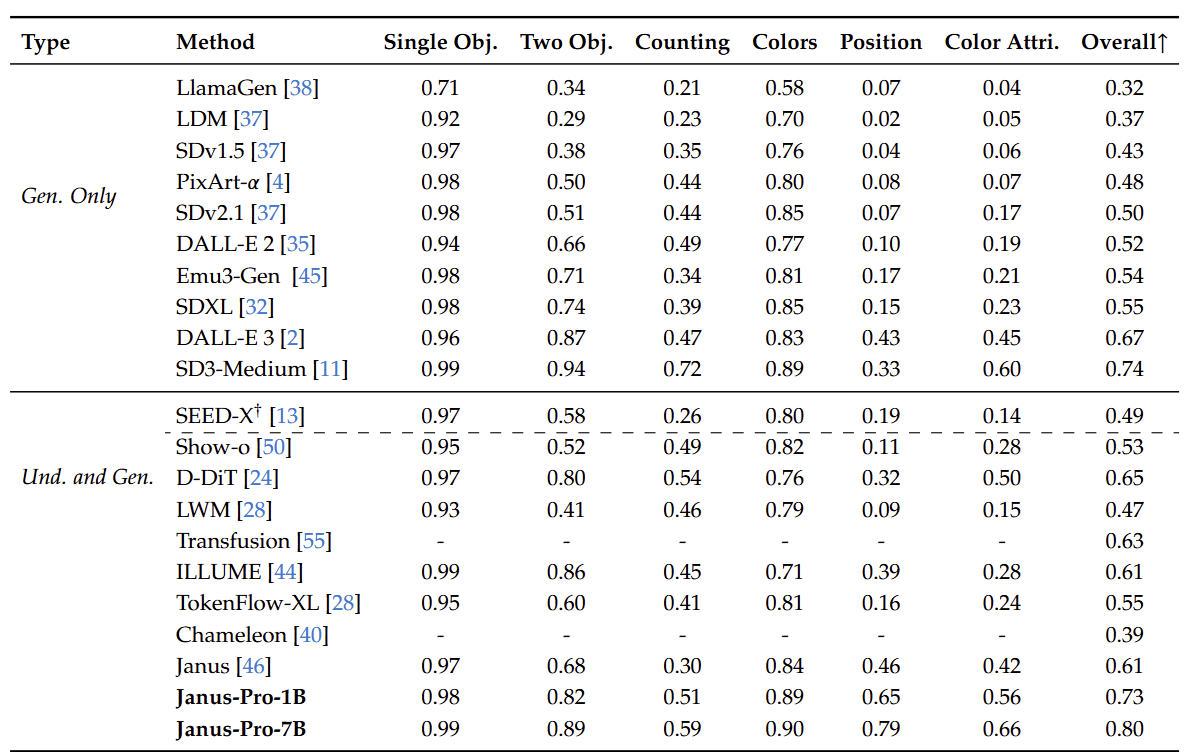
为了评估视觉生成能力,作者使用 GenEval 和 DPG-Bench。GenEval 是文生图的一个具有挑战性的基准,旨在通过对其组合能力进行详细的实例级分析来反映视觉生成模型的综合生成能力。DPG-Bench (Dense Prompt Graph Benchmark) 是一个由 1065 个冗长的密集提示组成的综合数据集,旨在评估文生图模型的复杂语义对齐能力。
作者报告了 GenEval 和 DPG-Bench 上的视觉生成性能。如下图所示,Janus-Pro-7B 在 GenEval 上获得了 80% 的整体准确率,优于所有其他统一或仅生成的方法,例如 Transfusion (63%) SD3-Medium (74%) 和 DALL-E 3 (67%)。这表明本文方法具有更好的指令跟随能力。
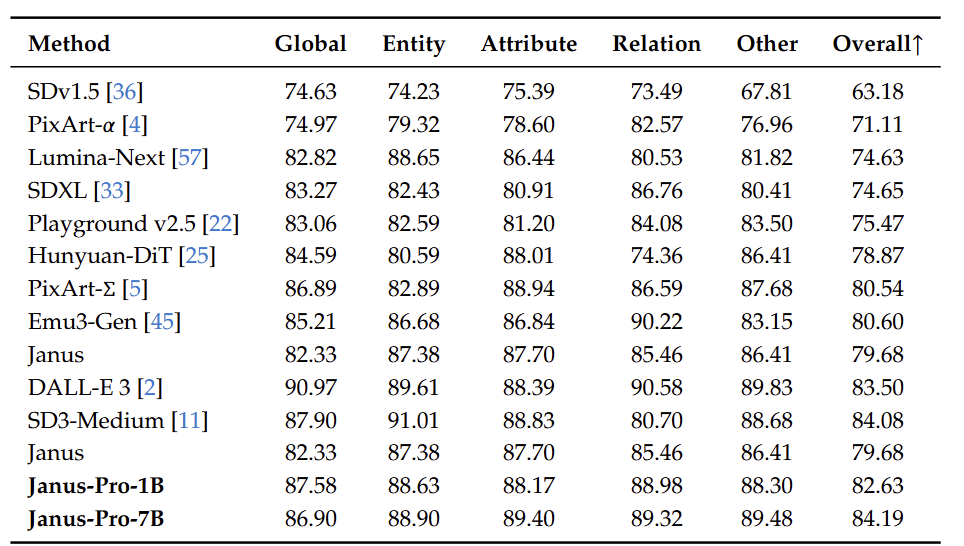
Janus-Pro 在 DPG-Bench 上得分为 84.19,超过了所有其他方法。这表明 Janus-Pro 擅长遵循文生图的密集指令。
定性结果
作者展示了多模态理解的结果。 Janus-Pro 在处理来自不同上下文的输入时表现出令人印象深刻的理解能力,展示了其强大的能力。作者还在下图 的下半部分展示了一些文生图的结果。 Janus-Pro-7B 生成的图像是高度现实的,尽管分辨率只有 384×384,但它们仍然包含大量细节。对于富有想象力和创造性的场景,Janus-Pro7B 准确地从提示中捕获语义信息,产生合理和连贯的图像。

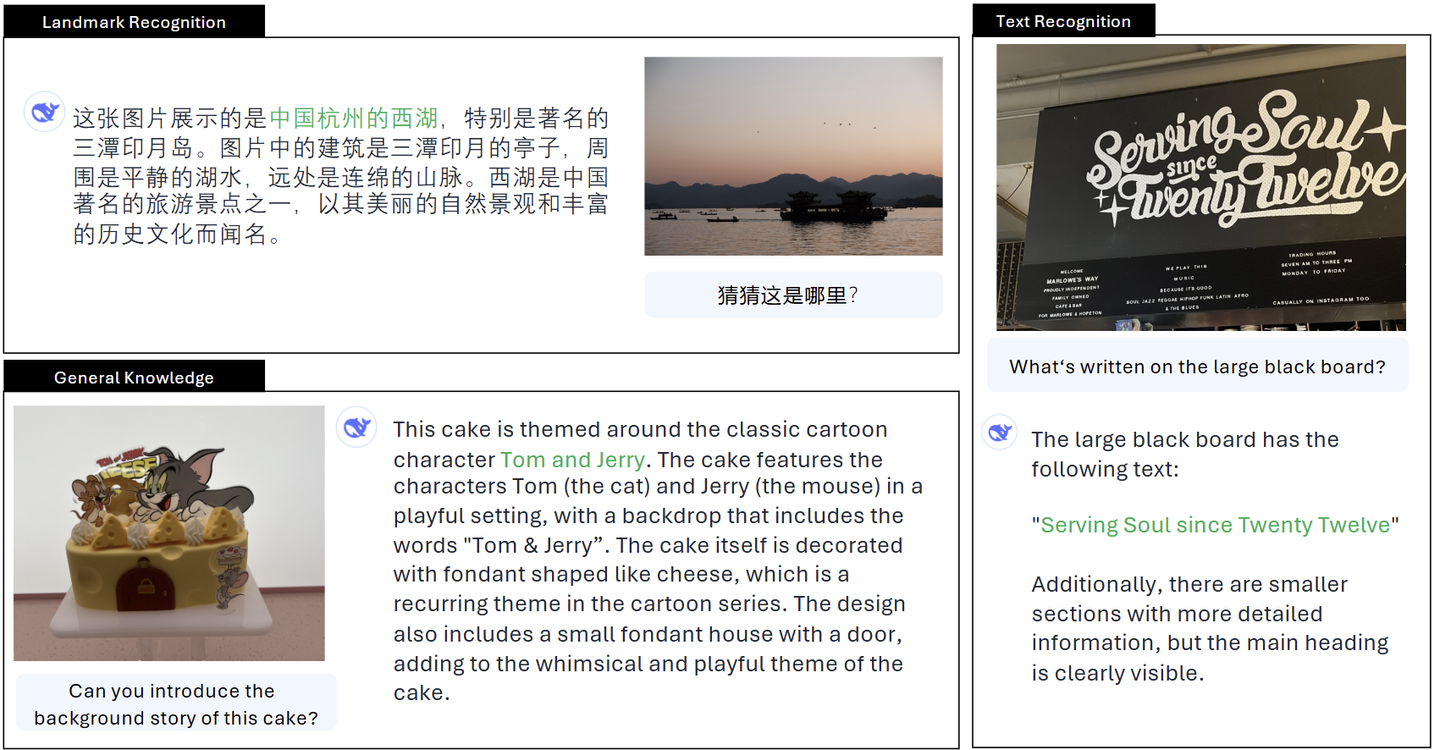

JanusFlow
论文名称:JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
项目主页:github.com/deepseek-ai/Janus
JanusFlow 模型
Janus 是使用一个统一的 Transformer 架构来统一多模态图像理解和多模态图像生成任务的模型。JanusFlow 是 Janus 的后续版本,一个统一多模态模型,将 Rectified Flow 与 LLM 架构无缝集成。
为了让设计尽量简单,JanusFlow 只需一个轻量化的 Encoder 和 Decoder 来 adapt LLM 完成 Rectified Flow 的操作。为了优化 JanusFlow 的性能,作者实现了 2 个关键的策略:
- 维护单独的视觉编码器和解码器进行理解和生成任务,防止任务干扰,从而提高理解能力。
- 在训练期间对其生成和理解模块的中间表征,增强生成过程中的语义一致性。
与现有的 Unified Model 相比,JanusFlow 在多模态理解和文本到图像生成方面表现出最先进的性能,甚至优于几种专门的方法。具体来说,在文生图 Benchmark 上,MJHQ FID-30k、GenEval 和 DPG-Bench,JanusFlow 的得分分别为 9.51、0.63 和 80.09%,超过了现有文生图模型,包括 SDv1.5 和 SDXL。在多模态理解 Benchmark 中,JanusFlow 在 MMBench、SeedBench 和 GQA 上分别获得 74.9、70.5 和 60.3 的分数,超过 LLAVA-v1.5 和 Qwen-VL-Chat 等专门用于理解的模型。值得注意的是,这些结果来自只有 1.3B 参数的 LLM。
Rectified Flow
对于由从未知数据分布 \(\pi_{1}\) 中提取的连续数据点 \(x = (x_1, \cdots, x_d)\) 组成的数据集 \(\mathcal{D}\) ,Rectified Flow 通过学习定义在时间 \(t \in [0,1]\) 上的常微分方程 (ODE) 来建模数据分布:
其中, \(\theta_{NN}\) 表示速度神经网络的参数, \(\pi_{0}\) 是一个简单的分布,通常是标准的高斯噪声 \(\mathcal{N}(0, I)\) 。通过最小化 neural velocity 与连接 \(\pi_{0}\) 和 \(\pi_1\) 之间随机点的 linear path 方向之间的欧氏距离来训练网络。
这里, \(\mathbb{p}(t)\) 是时间 \(t\in [0,1]\) 上的分布。当网络具有足够的容量并且目标被完美地最小化时,最优速度场 \(v_{\theta^*_{NN}}\) 将基本分布 \(\pi_0\) 映射到真实数据分布 \(\pi_1\) 。
更准确地说,分布 \(z_1 = \int_{0}^1 v_{\theta^*_{NN}}(z_t, t) {\rm{d}} t\) , \(z_0 \sim \pi_0\) ,遵循 \(\pi_1\) 。
尽管 Rectified Flow 在概念上很简单,但在各种生成建模任务中表现出了优越的性能,包括文生图等等。
具体详情参考:Rectified Flow
模型架构
JanusFlow 提出了一个统一框架,旨在解决视觉理解和图像生成任务。
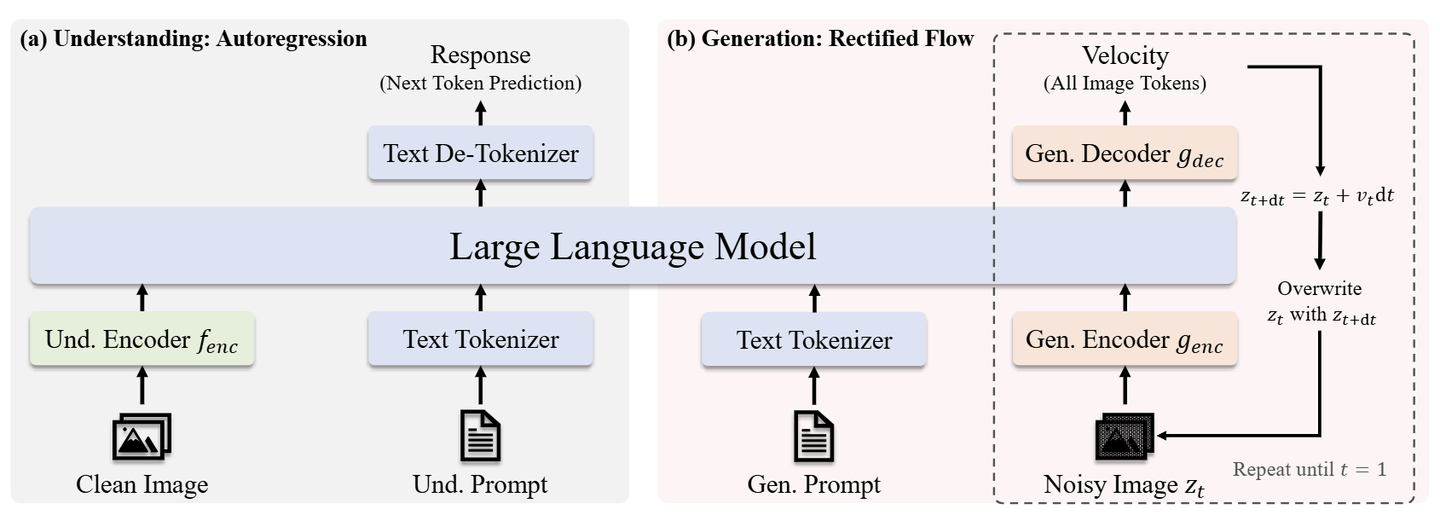
- 多模态理解
在多模态理解任务中,LLM 处理由交错文本和图像数据组成的输入序列。文本被标记为离散 token,每个 token 都被转换为维度 \(D_{emb}\) 的嵌入。对于图像,图像编码器 \(f_{enc}\) 将每个图像 \(x_{im}\) 编码成形状为 \(H_{im}\times W_{im}\times D_{enc}\) 的特征。这个特征图被 flattened 并通过线性变换层投影到一系列形状为 \(H_{im}W_{im}\times D_{emb}\) 的 Embedding 中。 \(H_{im}\) 和 \(W_{im}\) 由图像编码器决定。文本和图像 Embedding 被连接起来形成 LLM 的输入序列,然后根据 Embedding 的输入序列 Autoregressive 地预测下一个 token。在图像之前添加了特殊标记 |BOI| 和图像后的 |EOI|,以帮助模型定位序列中的 Image Embedding。
- 图像生成
对于图像生成,LLM 以文本序列为 condition,并使用 Rectified Flow 生成相应的图像。为了提高计算效率,使用预训练的 SDXL-VAE 在 Latent Space 中生成。
生成过程首先在潜在空间中对形状为 \(H_{latent}\times W_{latent}\times D_{latent}\) 的高斯噪声 \(z_0\) 进行采样,然后由生成编码器 \(g_{enc}\) 处理成一系列嵌入 \(H_{gen}W_{gen}\times D_{enc}\) 。这个序列与一个 time Embedding 连接,该 Embedding 表示当前时间步 \(t\) (开始时刻 \(t=0\) ),从而产生长度为 \(H_{gen}W_{gen}+1\) 的序列。
与之前使用各种 Attention Masking 策略不同,作者发现 Causal Attention 就足够了。LLM 的输出对应于 \(z_0\) 通过生成解码器 \(g_{dec}\) 转换回 latent 空间,产生形状为 \(H_{latent}\times W_{latent}\times D_{latent}\) 的 velocity 向量。该状态由标准欧拉求解器更新:
其中, \(\rm{d} t\) 是用户定义的步长。作者在输入上用 \(z_{\rm{d} t}\) 替换 \(z_0\) ,并迭代该过程,直到我们得到 \(z_1\) ,然后由 VAE 解码器将其解码为最终图像。为了提高生成质量,在计算速度时使用无分类器指导 (CFG):
其中, \(v(z_t, t~|~\varnothing)\) 表示 no condition 的 velocity,并且 \(w \geq 1\) 控制 CFG 的大小。根据经验,增加 \(w\) 会产生更高的语义对齐。与多模态理解类似,使用特殊标记 |BOI| 指示序列中的图像生成的开始。
JanusFlow 采用解耦的编码器设计。JanusFlow 使用预训练的 SigLIP-Large-Patch/16 模型作为 \(f_{enc}\) 来提取语义连续特征以进行多模态理解,同时使用从头开始初始化的单独 ConvNeXt Block 作为 \(g_{enc}\) 和 \(g_{dec}\) ,选择其有效性。解耦编码器设计显著提高了 Unified Model 的性能。JanusFlow 的完整架构如图 3 所示。
训练策略
JanusFlow 的训练分为 3 个阶段
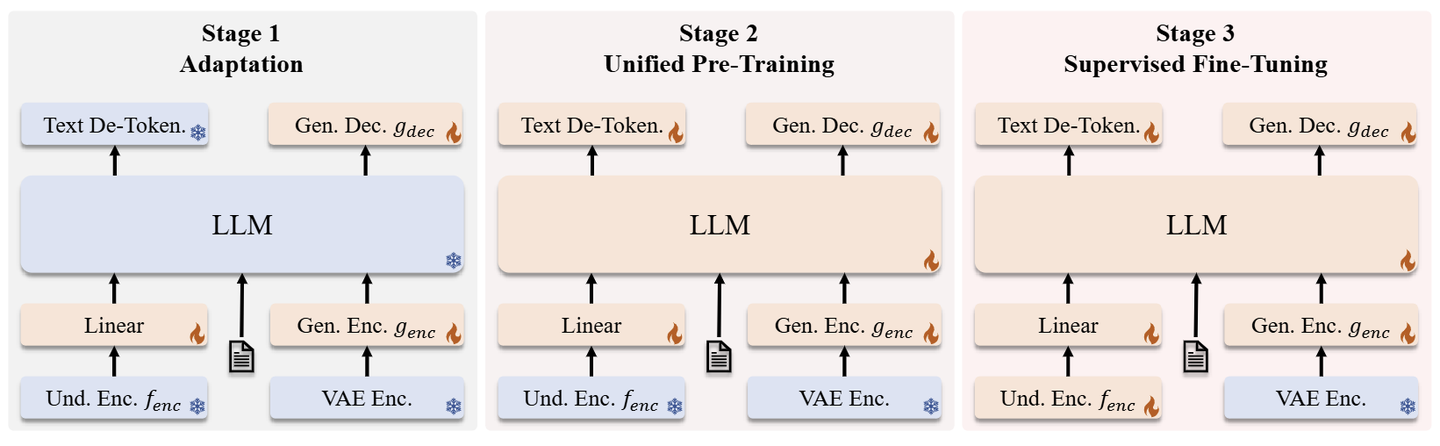
- 第 1 阶段:训练 Linear 层,生成编码器和生成解码器。
这一阶段的主要目标是训练 Linear 层 (\(f_{enc}\)之后的东西,可以理解为 Adaptor),Generation Encoder,Generation Decoder。这一阶段旨在使这些新的模块与 Pre-trained 的 LLM 和 SigLIP Encoder 有效适配。
- 第 2 阶段:联合预训练,除了理解编码器和 VAE Encoder 之外的所有组件都更新参数。
这个阶段训练整个模型,除了理解编码器和 VAE Encoder。训练结合了 3 种数据类型:多模态理解、图像生成和纯文本数据。作者最初分配更高比例的多模态理解数据来建立模型的理解能力。随后,增加了图像生成数据的比例,以适应基于扩散的模型的收敛要求。
- 第 3 阶段:有监督微调,进一步解锁理解编码器的参数。
这个阶段作者使用指令调整数据微调预训练模型,其中包括对话、特定于任务的对话和高质量的文生图示例。在这个阶段,作者还解冻了 SigLIP Encoder 参数。这种微调过程使模型能够有效地响应用户指令以进行多模态理解和图像生成任务。
训练目标
训练 JanusFlow 涉及两种类型的数据、多模态理解数据和图像生成数据。
这两种类型的数据都包含两部分:"Condition" 和 "Response"。"Condition" 是指任务的提示 (例如,多模态理解任务中的 image,图像生成任务中的 text),而 "Response" 是指两个任务的响应。数据可以格式化为 \(x = (x^{con}, x^{res})\) ,其中上标 \({con}\) 表示 "Condition",而 \({res}\) 表示 "Response"。将整个序列 \(x\) 的长度表示为 \(\ell\) ,将 \(x^{con}\) 的长度表示为 \(\ell_{con}\) ,将 \(x^{res}\) 的长度表示为 \(\ell_{res}\) 。作者使用 \(\theta\) 来表示 JanusFlow 中所有可训练参数的集合,包括 LLM、 \(f_{enc}\) 、 \(g_{enc}\) 、 \(g_{dec}\)和 Linear 层。
- Autoregressive 训练目标
对于多模态理解任务, \(x^{res}\) 仅包含文本标记。JanusFlow 使用最大似然原理进行训练,
其中,期望在多模态理解数据集 \(\mathcal{D}_{und}\) 中接管所有 \((x^{con}, x^{res})\) 对,计算损失仅在 \(x^{res}\) 中的 token 上。
- Rectified Flow 训练目标
对于图像生成任务, \(x^{con}\) 由文本 token 组成, \(x^{res}\) 是对应的图像。JanusFlow 使用 Rectified Flow 进行训练:
其中, \(z_t = t x^{res} + (1-t) z_0\) 。在 Stable Diffusion 3 之后,将时间分布 \(\rm{P}(t)\) 设置为 Logit 正态分布。为了实现 CFG 推理,在训练期间随机丢弃 10% 的文本提示。
- 表征对齐正则化
对齐 Diffusion Transformer 和 Semantic Vision Encoder 之间的中间表征可以增强扩散模型的泛化能力。Janus 的解耦视觉编码器设计使这种对齐的有效实现成为一个 正则化项。具体地说,对于生成任务,作者将理解编码器 \(f_{enc}\) 的特征与 LLM 的中间特征对齐:
其中, \(q_\theta(z_t)\) 代表 LLM 的中间表征,给定输入 \(z_t\) 。 \(h_\phi\) 是一个小的可学习 MLP,把 \(q_\theta(z_t)\) 映射到 \(D_{enc}\) 维度。函数 \(\text{sim}(\cdot, \cdot)\) 计算嵌入之间的元素余弦相似度的平均值。
在计算 loss 之前,把 \(h_\phi(q_\theta(z_t))\) reshape 为 \(H_{gen} \times W_{gen} \times D_{enc}\) 。作者确保 \(H_{gen}=H_{im},W_{gen}=W_{im}\) 。 \(\mathcal{L}_{REPA}\) 的梯度不会通过 Understanding Encoder 反向传播。这种对齐损失有助于 LLM 的内部特征空间 (给定噪声输入 \(z_t\) ) 与 Understanding Encoder 的语义特征空间对齐,从而在推理过程中从新的随机噪声和文本条件生成图像时提高生成质量。
所有 3 个目标都用于所有训练阶段。多模态理解任务使用 \(\mathcal{L}_{AR}\) ,而图像生成任务使用损失 \(\mathcal{L}_{RF}+\mathcal{L}_{REPA}\) 。
实验设置
JanusFlow 建立在DeepSeek-LLM (1.3B) 的增强版本。LLM 由 24 个 Transformer Block 组成,支持 4,096 的序列长度。在 JanusFlow 中,理解和生成图像分辨率都为 384。
对于多模态理解,作者利用 SigLIP-Large-Patch/16 作为 \(f_{enc}\) 。对于图像生成,作者利用预训练的 SDXL-VAE 作为其 latent space。生成编码器 \(g_{enc}\) 包括 2×2 pathify 层,然后 2 个 ConvNeXt Block 和 Linear 层。生成解码器 \(g_{dec}\) 结合了 2 个 ConvNeXt Block、一个 pixel-shuffle 层上采样和 Linear 层。SigLIP 编码器包含约 300M 参数。 \(g_{enc}\) 和 \(g_{dec}\) 是轻量级模块,总共包含约 70M 参数。图5详细说明了每个训练阶段的超参数。在 Representation Alignment 中,使用第 6 块之后的 LLM 特征作为 \(q_{\theta}(z_t)\) ,将 3 层 MLP 用作 \(h_\phi\) 。使用 0.99 的指数移动平均 (EMA) 来确保训练稳定性。
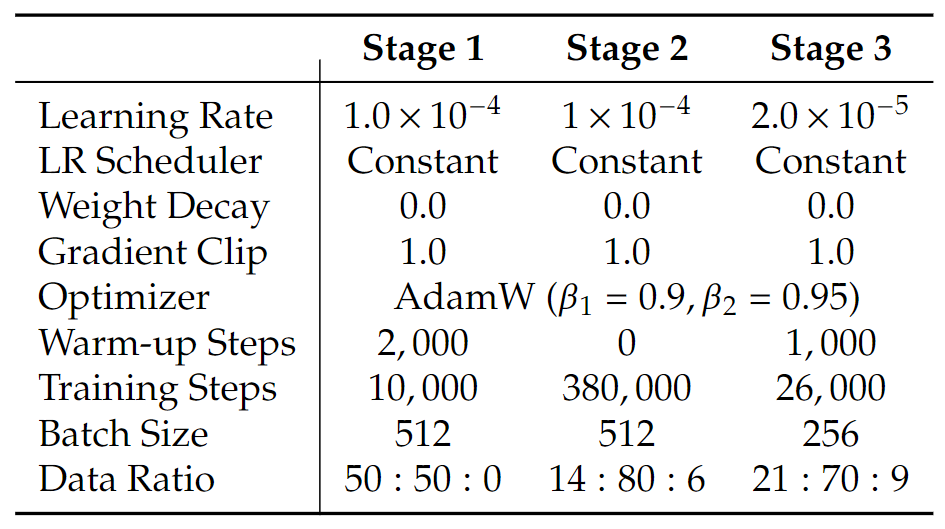
JanusFlow 以不同的方式处理理解和生成数据。对于理解任务,将长边调整为目标大小并将图像填充到正方形来维护所有图像信息。对于生成任务,将短边的大小调整为目标大小,并应用随机裁剪来避免填充伪影。
在训练期间,多个序列被打包以形成长度为 4096 的单个序列以提高训练效率。JanusFlow 的实现基于使用PyTorch 的 HAI-LLM 平台。训练是在 NVIDIA A100 GPU 上进行的,每个模型需要约 1600 A100 GPU 天。
训练数据设置
第 1 阶段和第 2 阶段的数据
JanusFlow 的前 2 个阶段使用 3 种类型的数据:多模态理解数据、图像生成数据和纯文本数据。
- 多模态理解数据。这种类型的数据包含多个子类别:(a) Image caption 数据:"<image>Generate the caption of this picture. <caption>"。(b) 图表和表格。(c) 任务数据。ShareGPT4V 数据用于促进预训练过程中的基本问答能力:"<image><question><answer>"。(d) 文本图像交织的数据。
- 图像生成数据。所有数据点都格式化为 "<prompt><image>"。
- 纯文本数据。直接使用 DeepSeek-LLM 的文本语料库。
第 3 阶段的数据。 SFT 阶段还使用 3 种类型的数据:
- 多模态指令数据。
- 图像生成数据:"User:<user prompt>\n\n Assistant:<image>"。
- 纯文本数据。
评测
视觉生成
作者报告了 GenEval、DPG-Bench 和 MJHQ FID-30k 的性能。下图比较了 GenEval,包括所有子任务的分数和总分。JanusFlow 的总体得分为 0.63,超过了之前的统一框架和几个生成特定模型,包括 SDXL 和 DALL-E 2。
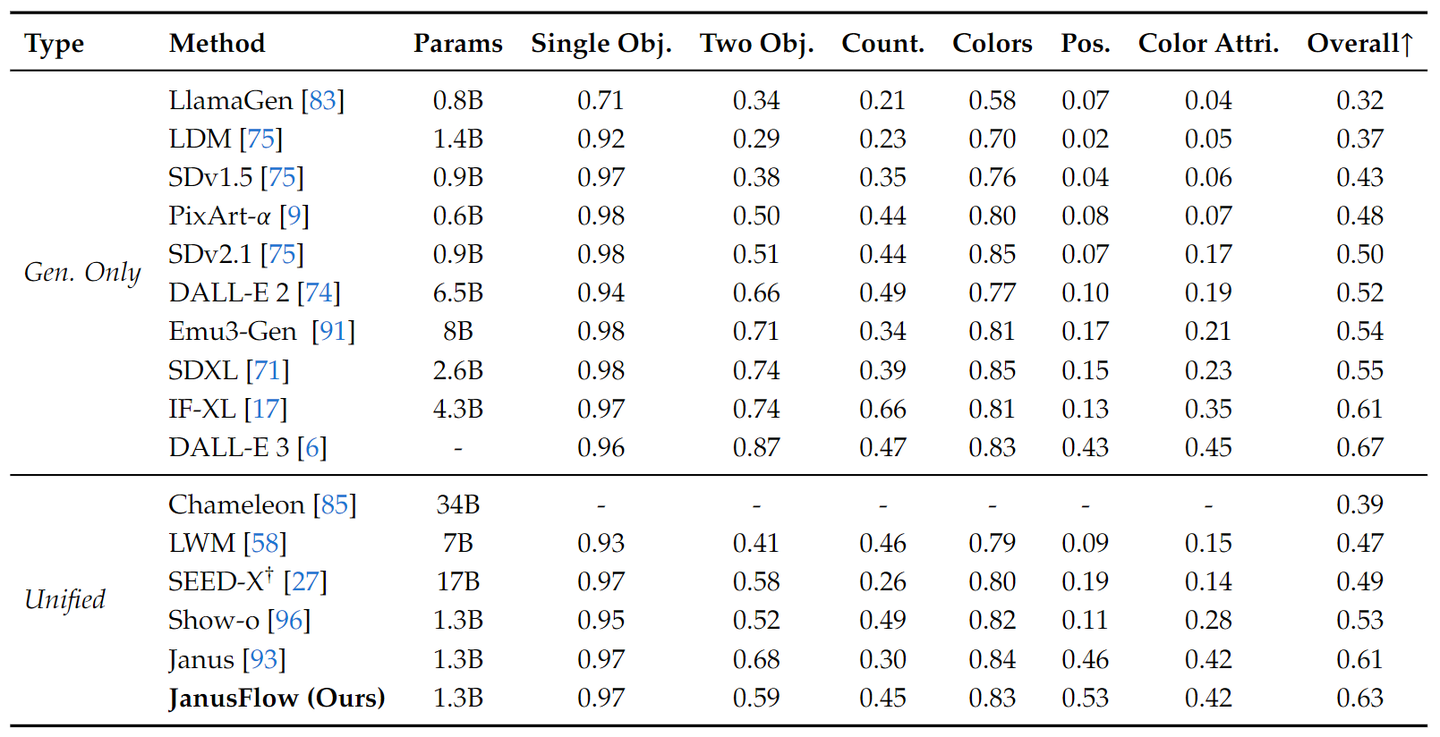
下图比较了 DPG-Bench 的结果。除了 JanusFlow 外,其他模型都是专门做生成的。
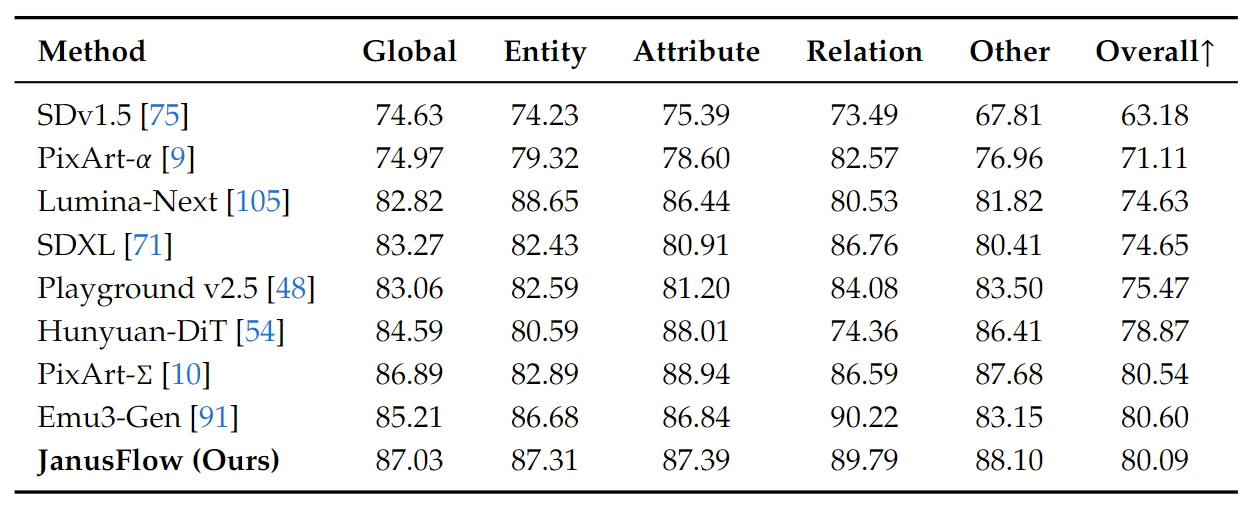
GenEval 和 DPGBench 上的结果展示了 JanusFlow 的指令跟随能力。
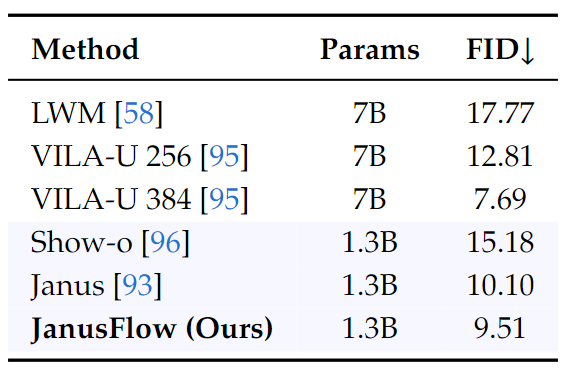
下图比较了 MJHQ FID-30k 的结果。采样的图片是使用 CFG factor \(w=2\) ,sampling steps 为 30 生成的。结果表明,Rectified Flow 能够在 Janus 等自回归模型上提高生成图像的质量。
多模态理解
下图展示了 JanusFlow 与其他方法的比较,包括专门做理解的模型和 Unified Model。JanusFlow 在具有相似参数量的所有模型中达到了最佳性能,甚至超过了多个专门做理解的方法。结果表明,JanusFlow 协调了自回归 LLM 和 Rectified Flow,在理解和生成方面都取得了令人满意的性能。