基于文章《Elucidating the Design Space of Diffusion-Based Generative Models》来统一扩散模型框架
通用扩散模型框架推导
加噪公式
\[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\]
写成概率分布形式:
\[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\]
\[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \]
写成概率分布形式:
\[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\]
\[\mathbf{x}_t=\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\varepsilon \]
写成概率分布形式:
\[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\sqrt{\bar{\alpha}_t}\mathbf{x}_0,(1-\bar{\alpha}_t)\mathbf{I})\]
其中, \(\mathbf{x}_0\)都是原始图像, \(\sigma\sim\mathcal{N}(\mathbf{0}, \mathcal{I})\)
通用加噪公式形式探索
发现这三者存在一定的规律,写成一个通用形式:
\[p_{0t}(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;s(t)\mathbf{x}_0,s^2(t)\sigma^2(t)\mathbf{I})\tag{1}\]
那这个形式一定对应一个随机微分方程,这个方程的解可以描述 \(x_t\) 分布的变化:
\[\mathrm{d}\mathbf{x}_t=f(\mathbf{x}_t,t)\mathrm{d}t+g(t)\mathrm{d}\mathbf{w_t}\tag{2}\]
根据DDPM和SMLD的推导结果,实际上 我们通常将漂移项简化为线性形式:
\[
f(x_t,t) \rightarrow f(t)x_t\tag{3}
\quad f(t):\mathbb{R}^1\rightarrow\mathbb{R}^1
\]
简化后的SDE形式为:
\[dx_t = f(t)x_tdt + g(t)dw\tag{4}\]
均值
SDE均值定义:\(m(t) = E[x_t]\), 对应的均值的微分:
\[\frac{dm}{dt}=E[f(t,x_t)]
\tag{5}\]
推导步骤:
对原始SDE两边取期望:
\[E[dx_t] = E[f(t)x_tdt + g(t)dw]
\]
运用期望的线性性质:
\[E[dx_t] = E[f(t)x_tdt] + E[g(t)dw]
\]
利用维纳过程的性质(\(E[dw] = 0\)):
\[E[g(t)dw] = g(t)E[dw] = 0
\]
因此:
\[E[dx_t] =dE[x_t]=dm= E[f(t,x_t)]dt
\]
即
\[\frac{dm}{dt}=E[f(t,x_t)]\]
\[E[dx_t] = E[f(t)x_t]dt = f(t)E[x_t]dt\]
根据均值公式 \(dm= E[f(t,x_t)]dt\) 可以推导:
代入均值定义:
\[dm(t) = E[f(t)x_t]dt = f(t)E[x_t]dt=f(t)m(t)dt\]
两边积分:
\[\int \frac{1}{m}dm = \int_0^t f(r)dr + C\]
求解得到:
\[\ln|m| = \int_0^t f(r)dr + C\]
指数化:
\[m = e^{\int_0^t f(r)dr + C}=e^{\int_0^t f(r)dr} e^C=Ae^{\int_0^t f(r)dr}\]
代入初始条件 \(m(0) = x_0\)(因为\(t=0\)时对应的是原图,原图的均值就是\(x_0\))最终得到解:
\[m(t) = e^{\int_0^t f(r)dr}x_0\tag{6}\]
所以在(1)通用形式中的\(s(t)\)对应为:
\[s(t) = \exp{\int_0^t f(r)dr}\tag{7}\]
协方差
SDE的协方差矩阵定义:\(P(t) = E[(x_t - m)(x_t - m)^T]\), 对应的协方差矩阵的微分:
\[\frac{dP}{dt} = E[f(x_t,t)(x_t - m)^T] + E[(x_t - m)f(x_t,t)^T] + E[g^2(t)]\tag{8}\]
上面式子的推导用了Itô公式(因为涉及随机过程),步骤略。
根据(3), 可将上面(8)化简为:
\[\frac{dP}{dt} = f(t)E[x_tx_t^T - x_tm^T] + f(t)E[x_tx_t^T - mx_t^T] + g^2(t)\]
再次考虑分离变量法,从\(P\)的定义出发, 可以得到:
\[P = E[(x_t - m)(x_t - m)^T] = E[x_tx_t^T - mx_t^T - x_tm^T + mm^T]\]
注意到:
\[E[mm^T] = mm^T = mE[x_t^T] = E[mx_t^T] = E[x_t]m^T = E[x_tm^T]\]
所以有:
\[E[x_tx_t^T - x_tm^T + x_tx_t^T - mx_t^T] = E[2x_tx_t^T - 2mm^T] = 2E[x_tx_t^T - mm^T] = 2P\]
这样(8)就可以接着化简得到:
\[\frac{dP}{dt} = 2f(t)P + g^2(t)\]
目前好像没办法接着化简了, 因为出现了\(f(t)P\),但这刚好又是另外一种方程,名叫一阶非齐次线性ODE,其标准形式为:
\[\frac{dy}{dx} + G(x)y(x) = Q(x)\]
其对应关系为:
\[y(x) \Rightarrow P(t), G(x) \Rightarrow -2f(t), Q(x) \Rightarrow g^2(t)\]
是有通解的,直接给出通解形式:
\[y(x)=e^{-\int G(x)\mathrm{d}x}\int Q(x)e^{\int G(x)\mathrm{d}x}\mathrm{d}x+Ce^{-\int G(x)\mathrm{d}x}\]
代入上面式子中的信息,可得:
\[\mathbf{p}(t)=e^{\int_0^t2f(r)\mathrm{d}r}\int_0^tg^2(r)e^{\int_0^t-2f(r)\mathrm{d}r}\mathrm{d}r+Ce^{\int_0^t2f(r)\mathrm{d}r}\]
代入初始条件\(\mathbf{P}(0)=0\)(\(t=0\)时刻原图的方差为0),有:
\[\begin{aligned}\mathbf{P}(0)&=e^{\int_0^02f(r)\mathrm{d}r}\int_0^0g^2(r)e^{\int_0^0-2f(r)\mathrm{d}r}\mathrm{d}r+Ce^{\int_0^02f(r)\mathrm{d}r}\\&=e^0*0+Ce^0\\&=C\end{aligned}\]
得到\(C=0\),因此有:
\[\mathbf{p}(t)=e^{\int_0^t2f(r)\mathrm{d}r}\int_0^tg^2(r)e^{\int_0^t-2f(r)\mathrm{d}r}\mathrm{d}r\]
又已知\(s(t)=e^{\int_0^tf(r)\mathrm{d}r}\),有:
\[s^2( t) = e^{\int _0^t2f( r) \mathrm{d} r}\]
对应的 \(\frac 1{s^2( t) }= e^{\int _0^t- 2f( r) \mathrm{d} r}\), 又由加噪公式通用形式(1), 可得:
\[\sigma^2(t)=\int_0^t\frac{g^2(r)}{s^2(r)}\mathrm{d}r\tag{9}
\]
小结
至此, 我们来稍微总结一下,加噪公式就是将一个分布变为另外一个分布的桥梁,实际上也就是大家耳熟能详的流(Flow)。加噪公式的存在是为训练过程服务的,只有建立这个桥梁,才能明确模型的训练目标,扩散模型的学习才有可能。 EDM给定的通用加噪公式为:
\[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;s(t)\mathbf{x}_0,s^2(t)\sigma^2(t)\mathbf{I})\]
其中, \(s(t)\) 和 \(σ(t)\) 分别为时间的函数, \(x_0\)是原始图像。 由于当前扩散模型的加噪流程基本都可满足上面公式,扩散模型的研究在EDM论文出现后变成了超参数的挑选过程了。其对应的连续形式的SDE为:
\[\mathrm{d}\mathbf{x}_t=f(\mathbf{x}_t,t)\mathrm{d}t+g(t)\mathrm{d}\mathbf{w}\]
注意,这个SDE的解\(x_t\)是能够与上面通用加噪公式获得的\(x_t\)在分布上保持一致(起点分布相同条件下)。
通过伊藤过程求解加噪公式的均值\(m(t)\)和协方差矩阵\(P(t)\), 可以找到对应的\(s(t)\)和\(\sigma(t)\):
\[s(t)=e^{\int_0^tf(r)\mathrm{d}r}\quad \sigma(t)=\sqrt{\int_0^t\frac{g^2(r)}{s^2(r)}\mathrm{d}r}\]
能够发现, \(σ(t)\) 和 \(s(t) \) 受到\( f(t) \)和 \(g(t)\) 的约束,也即定义好加噪公式的\(σ(t)\)和\(s(t)\),或者说在一定范围内随意指定,理论上都能对应一个SDE,反过来,指定\(f(t)\) 和 \(g(t)\),也能得到加噪公式的\(σ(t)\)和\(s(t)\)
扩散模型通用概率流常微分方程
有了前向随机微分⽅程的形式:
\[\mathrm{d}\mathbf{x}_t=f(\mathbf{x}_t,t)\mathrm{d}t+g(t)\mathrm{d}\mathbf{w_t}\tag{10}\]
通过福克普朗克⽅程(Fokker–Planck Equation)的推导,可以得到SDE对应的概率流常微分⽅程(Probability Flow Ordinary Differential Equation,PFODE)。这个PFODE在确定起点\(\mathbf{x}_0\)(前向)或\(\mathbf{x}_N\)(逆向)的前提下,解的分布(也即\(p(\mathbf{x}_t)\), \(\mathbf{x}_t\)的边缘概率密度)与加噪过程SDE求得的解的分布是完全相同的。这个PFODE的形式为:
\[\begin{aligned}\mathrm{d}\mathbf{x}&=\Big[\mathbf{f}(\mathbf{x},t)-\frac{1}{2}g(t)^{2}\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})\Big]\mathrm{d}t\\&=\Big[\mathbf{f}(t)x_t-\frac{1}{2}g(t)^{2}\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})\Big]\mathrm{d}t\end{aligned}\tag{11}\]
推导的过程见这里:SDE和扩散模型
推导不含\(f(t)\)和\(g(t)\)的PFODE表达式
现在我们的⽬标就是:摆脱复杂理论束缚,也不搞那些随机微分⽅程,就单纯通过设计加噪公式,直接写出对应的PFODE,然后直接⽤ODE求解器采样,进⽽获得⽣成图像。
假设我设计的⼀步加噪公式是下⾯这个通⽤形式
\[p_{0t}(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;s(t)\mathbf{x}_0,s^2(t)\sigma^2(t)\mathbf{I})\]
首先根据\(s(t)\)和\(f(t)\)的关系,也就是上面(7), 进一步可得到:
\[\ln s(t)=\int_0^tf(r)\mathrm{d}r\]
两边求导,积分上限函数 \(\int_0^tf(r)\mathrm{d}r\) 是\(f(t)\)的一个原函数
\[\begin{aligned}&\frac1{s(t)}\dot{s}(t)=f(t)\end{aligned}\]
即:
\[f(t)=\frac{\dot{s}(t)}{s(t)}\tag{12}\]
再根据\(\sigma(t)\)和\(f(t)\)、\(g(t)\)的关系, 也就是上面(9), 两边求导,积分上限函数是 \(\frac{g^2(t)}{s^2(t)}\) 的一个原函数
\[\begin{aligned}&2\sigma(t)\dot{\sigma}(t)=\frac{g^2(t)}{s^2(t)}\\&g(t)=\sqrt{2\sigma(t)\dot{\sigma}(t)s^2(t)}\end{aligned}\]
即:
\[g(t)=s(t)\sqrt{2\sigma(t)\dot{\sigma}(t)}\tag{13}\]
至此,\(f(t)\) 和 \(g(t)\) 可以完全由 \(s(t)\) 和 \(\sigma(t)\) 表示,反过来也可以表示。这样看似代入(11)就能解决问题了,但实际上还差一步
虽然搞定了\(f(t)\)和\(g(t)\),但是 \(p_t(\mathbf{x}_t)\) 是未知的,换句话说这种边缘分布如果能够知道,直接从里面采样即可,完全没必要这么复杂通过迭代的方式逐步获得结果。所以,还要对 \(\nabla\mathbf{x}_t\log p_t(\mathbf{x}_t)\) 进行分析,首先考虑边缘概率密度 \(p_t(\mathbf{x}_t)\)
\[\begin{aligned}p_{t}(\mathbf{x}_{t})&=\int_{\mathbb{R}^d}p_{\mathrm{data}}(\mathbf{x}_0)p_{0t}(\mathbf{x}_t|\mathbf{x}_0)\mathrm{d}\mathbf{x}_0\quad \text{全概率密度公式} \\&=\int_{\mathbb{R}_d}p_{\mathrm{data}}(\mathbf{x}_0)\left[\mathcal{N}\left(\mathbf{x}_t;s(t)\mathbf{x}_0,s^2(t)\sigma^2(t)\mathbf{I}\right)\right]\mathrm{d}\mathbf{x}_0
\\&=\int_{\mathbb{R}_{d}}p_{\mathrm{data}}(\mathbf{x}_{0})\left[\underbrace{s^{-d}(t)}_{\text{保证概率密度函数积分为}1}\mathcal{N}\left(\frac{\mathbf{x}_{t}}{s(t)};\mathbf{x}_{0},\sigma^{2}(t)\mathbf{I}\right)\right]\mathrm{d}\mathbf{x}_{0}
\\&=s^{-d}(t)\int_{\mathbb{R}d}p_{\mathrm{data}}(\mathbf{x}_0)\mathcal{N}\left(\frac{\mathbf{x}_t}{s(t)};\mathbf{x}_0,\sigma^2(t)\mathbf{I}\right)\mathrm{d}\mathbf{x}_0
\\&=s^{-d}(t)\int_{\mathbb{R}_d}p_{\mathrm{data}}(\mathbf{x}_0)\mathcal{N}\left(\frac{\mathbf{x}_t}{s(t)}-\mathbf{x}_0;0,\sigma^2(t)\mathbf{I}\right)\mathrm{d}\mathbf{x}_0\quad\text{不影响概率}
\\&=s^{-d}(t)\underbrace{\left[p_{\mathrm{data}}*\mathcal{N}\left(0,\sigma^2(t)\mathbf{I}\right)\right]}_\text{分布卷积运算}{\left(\frac{\mathbf{x}_t}{s(t)}\right)}\end{aligned}\tag{14}\]
上式就是边缘概率密度\(p_t(\mathbf{x}_t)\)的表达式。由于分布卷积运算等价于两个分布"相叠加”,所以实际上分布卷积运算后的分布就等于SMLD方法的加噪公式,只是随机变量 \(\mathbf{x}_t\) 除以一个系数 \(s(t)\),概率密度整体乘以了一个\(s^{-d}(t)\)。令
\[p( \mathbf{x}_t; \sigma ( t) ) = \left [ p_\text{data}* \mathcal{N} \left ( 0, \sigma ^2( t) \mathbf{I} \right ) \right ] ( \mathbf{x} _t) = \mathcal{N} \left ( \mathbf{x} _t; \mathbf{x} , \sigma ^2( t) \mathbf{I} \right ) = p( \mathbf{x} _t| \mathbf{x} )\]
注意这里为了方便说明问题假设\(p_\text{data}= \mathcal{N} ( \mathbf{x} , 0)\), 也即数据集只有一个数据的时候,最后两个等号才成立。若数据集包含很多数据,参考EDM论文公式(45)可进行更严谨的推导, 可以看出这个式子就是score matching中的条件概率分布函数,也就是说边缘概率密度和加噪的条件概率密度等价
把公式(12)、(13)和(14)代入公式(11)中,可得:
\[\begin{aligned}\mathrm{d}\mathbf{x}_{t}&=\left[f(t)\mathbf{x}_t-\frac12g^2(t)\nabla{\mathbf{x}_t}\log p_t(\mathbf{x}_t)\right]\mathrm{d}t\\&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}_t-s^2(t)\sigma(t)\dot{\sigma}(t)\nabla{\mathbf{x}_t}\log\left(s^{-d}(t)\left[p_\text{data}*\mathcal{N}\left(0,\sigma^2(t)\mathbf{I}\right)\right]\left(\frac{\mathbf{x}_t}{s(t)}\right)\right)\right]\mathrm{d}t\\&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}_t-s^2(t)\sigma(t)\dot{\sigma}(t)\left(\nabla{\mathbf{x}_t}\log s^{-d}(t)+\nabla{\mathbf{x}_t}\log p\left(\frac{\mathbf{x}_t}{s(t)};\sigma(t)\right)\right)\right]\mathrm{d}t\end{aligned}\]
再进一步, 我们就得到了通用概率流常微分方程(PFODE):
\[dx_t=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}_t-s^2(t)\sigma(t)\dot{\sigma}(t)\nabla{\mathbf{x}_t}\log p\left(\frac{\mathbf{x}_t}{s(t)};\sigma(t)\right)\right]\mathrm{d}t\tag{15}\]
小结
至此,通过将SDE转换为PFODE, 并结合对边缘概率分布 \(p_t(x)\)的推导,我们获得了仅仅依赖通用加噪公式中的\(s(t)\)和\(\sigma(t)\), 而不显式依赖\(f(t)\)和\(g(t)\)的通用概率流常微分方程PFODE
\[dx_t=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}_t-s^2(t)\sigma(t)\dot{\sigma}(t)\nabla{\mathbf{x}_t}\log p\left(\frac{\mathbf{x}_t}{s(t)};\sigma(t)\right)\right]\mathrm{d}t\]
从现在开始,就可以针对任意一个已知\(s(t)\)和\(\sigma(t)\)的加噪公式也即路径,直接写出去噪迭代公式也即对应的PFODE!
所以就可以通过神经网络预测一个score function,使用Euler等数值求解方法可实现生成图像的确定性采样, 但是这还是score matching的范式,有没有一个范式可以将所有的扩散过程的学习目标进行统一呢?
扩散模型通用推理过程:通用确定性采样
通用去噪学习目标
之前已经描述了随机微分⽅程(Stochastic Differential Equation,SDE)或概率流常微分⽅程(Probability Flow Ordinary Differential Equation,PFODE)的联系。还差最后⼀个⽬标,就是是否存在统⼀的推理过程框架?推理过程是需要⼀个神经网络预测的值逐步实现图像生成。由于扩散模型逆向迭代实际上还是去噪,那不妨假定存在⼀个去噪网络 \(D_θ(x; σ)\),这个去噪网络的输入为加噪后的图像 \(x = y + n\),其中 \(y\) 为原始图像,\(n\)为噪声,\(σ\)是噪声强度,实际上就和时间 \(t\) 等价,再联合L2损失函数可得:
\[\mathbb{E}_{\mathbf{y}\sim p_{\mathrm{data}},\mathbf{n}\sim\mathcal{N}(\mathbf{0},\sigma^2\mathbf{I})}{\left\|D_\theta(\mathbf{y}+\mathbf{n};\sigma)-\mathbf{y}\right\|_2^2}\tag{16}\]
对于去噪网络 \(D(\mathbf{x};\sigma)\) 来说,其最完美的状态应该为:
\[D_\theta(\mathbf{y}+\mathbf{n};\sigma)=\mathbf{y}\]
也即完全还原原始图像。
因为逆向PFODE采样公式里面存在分数score,需要首先分析score分数和去噪网络\(D(\mathbf{x};\sigma)\)的关系。假定扩散模型每一步满足高斯分布\(p(\mathbf{x}|\mathbf{y})=\mathcal{N}(\mathbf{x};\mathbf{y},\sigma^2\mathbf{I})=p(\mathbf{x};\sigma)\),其中 \(\mathbf{x}\) 为加噪后样本,\(\mathbf{y}\) 为原始样本,有:
\[\begin{aligned}\nabla_{\mathbf{x}}\log p(\mathbf{x};\sigma)&=\nabla_{\mathbf{x}}\log\frac1{\sqrt{2\pi}\sigma}\mathrm{exp}\left(-\frac12\frac{(\mathbf{x}-\mathbf{y})^2}{\sigma^2}\right)\\&=\nabla_{\mathbf{x}}\log\frac1{\sqrt{2\pi}\sigma}+\nabla_{\mathbf{x}}\left(-\frac12\frac{(\mathbf{x}-\mathbf{y})^2}{\sigma^2}\right)\\&=0-\frac{\mathbf{x}-\mathbf{y}}{\sigma^2}\\&=\frac{\mathbf{y}-\mathbf{x}}{\sigma^2}\quad\text{近似有}D_\theta(\mathbf{x};\sigma)\approx\mathbf{y}\text{,代入得}\\&\approx\frac{D_\theta(\mathbf{x};\sigma)-\mathbf{x}}{\sigma^2}\end{aligned}\tag{17}\]
这里的证明过程又是一个走邪道之法,至少存在两点不严谨的地方:
- 提前假设了 x 的分布为Score Matching那篇论⽂中定义的形式
- 向量计算与数值计算混⽤
相对更加严谨的证明⽅法可以看EDM论⽂的附录,在此不再赘述
实现确定性采样
有了加噪公式关键项\(σ(t)\)和\(s(t)\)的PFODE (15)
里面刚好有关于分数的一项,也即\(\nabla_{\mathbf{x}_t}\log p\left(\frac{\mathbf{x}_t}{s(t)};\sigma(t)\right)\), 试着看把学到的去噪模型代入进来。注意,这里需要假设 \(\mathbf{x}_t\) 是被系数 \(s(t)\) 缩放过的,也即\(\mathbf{x}_t=s(t)\hat{\mathbf{x}}_t\), 所以:
\[\begin{aligned}\nabla_{\mathbf{x}_t}\log p\left(\frac{\mathbf{x}t}{s(t)};\sigma(t)\right)&=\frac1{s(t)}\nabla{\frac{\mathbf{x}_t}{s(t)}}\log p\left(\frac{\mathbf{x}t}{s(t)};\sigma(t)\right)\\&=\frac1{s(t)}\nabla{\hat{\mathbf{x}}_t}\log p\left(\hat{\mathbf{x}}t;\sigma(t)\right)\\&=\frac{D\theta(\hat{\mathbf{x}}_t;\sigma)-\hat{\mathbf{x}}_t}{s(t)\sigma^2(t)}\end{aligned}\]
代入PFODF(15)中,有:
\[\begin{aligned}\mathrm{d}\mathbf{x}_{t}&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}t-s^2(t)\sigma(t)\dot{\sigma}(t)\nabla{\mathbf{x}_t}\log p\left(\frac{\mathbf{x}t}{s(t)};\sigma(t)\right)\right]\mathrm{d}t\\&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}t-s^2(t)\sigma(t)\dot{\sigma}(t)\frac{D\theta(\hat{\mathbf{x}}_t;\sigma)-\hat{\mathbf{x}}t}{s(t)\sigma^2(t)}\right]\mathrm{d}t\\&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}t-s(t)\dot{\sigma}(t)\frac{D\theta(\hat{\mathbf{x}}_t;\sigma)-\hat{\mathbf{x}}_t}{\sigma(t)}\right]\mathrm{d}t\end{aligned}\]
发现微分项为 \(\mathbf{x}_t\) , 模型输入是 \(\hat{\mathbf{x}}_t\) ,需要统一一下,再把 \(\hat{\mathbf{x}}_t\) 换为 \(\mathbf{x}_t\), 得:
\[\begin{aligned}\mathrm{d}\mathbf{x}_{t}&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}t-s(t)\dot{\sigma}(t)\frac{D\theta\left(\frac{\mathbf{x}_t}{s(t)};\sigma\right)-\frac{\mathbf{x}_t}{s(t)}}{\sigma(t)}\right]\mathrm{d}t\\&=\left[\frac{\dot{s}(t)}{s(t)}\mathbf{x}t-\frac{s(t)\dot{\sigma}(t)}{\sigma(t)}D\theta\left(\frac{\mathbf{x}_t}{s(t)};\sigma\right)+\frac{\dot{\sigma}(t)}{\sigma(t)}\mathbf{x}_t\right]\mathrm{d}t\end{aligned}\]
合并一下,得到:
\[\mathrm{d}\mathbf{x}_{t}=\left[\left(\frac{\dot{s}(t)}{s(t)}+\frac{\dot{\sigma}(t)}{\sigma(t)}\right)\mathbf{x}t-\frac{s(t)\dot{\sigma}(t)}{\sigma(t)}D\theta\left(\frac{\mathbf{x}_t}{s(t)};\sigma\right)\right]\mathrm{d}t\tag{18}\]
至此,我们将\(D_\theta\left(\frac{\mathbf{x}_t}{s(t)};\sigma\right)\) 放进了PFODE中,作者在这里采用了二阶求解器提升效果。

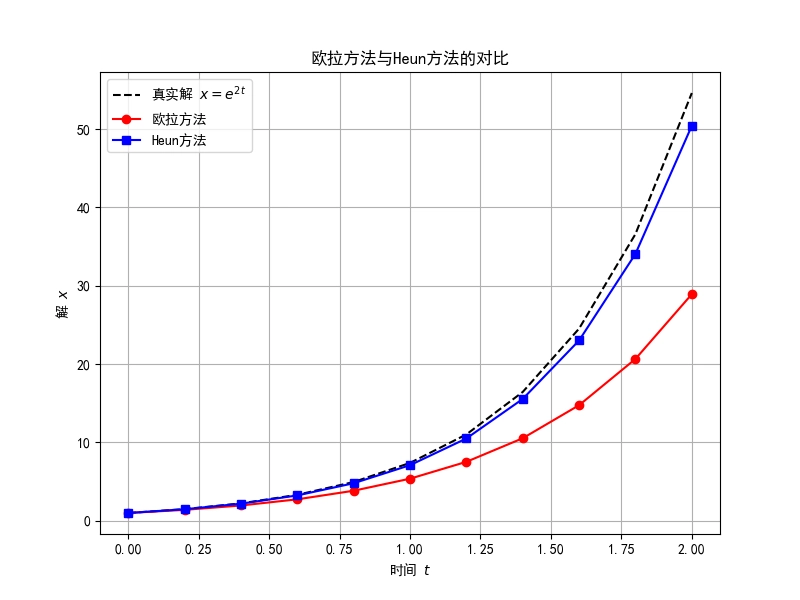
这里简单对二阶的求解器方法Heun’s,也叫梯形方法做一个感性的认识:
欧拉方法是一种一阶数值积分方法,其基本思想是用函数在当前点的切线来近似曲线的下一步。它计算简单,但误差较大,尤其是在步长较大或函数曲线变化较快时。
对应公式为:
\[x_{t+\Delta t}=x_t+hf(t,x_t)\]
其中:\(x_t\) 是当前点的值, \(h\)为步长,在这里步长为 \(h=t+\Delta t -t=\Delta t\), \(f(t,x_t)\)是微分方程的斜率(即导数)
Heun方法是一种改进的欧拉方法,也是一种二阶方法。它通过预测-校正的方式提高精度,实际上是对欧拉方法的斜率进行修正。具体来说,它先用欧拉方法预测一个值,然后再用该值计算校正的斜率,最终取两者的平均值。
公式为:
\[x_{t+\Delta t}=x_t+\frac{h}{2}[f(t,x_t)+f(t+\Delta t,x_{pre})]\]
其中:\(x_{pre} = x_t+hf(t,x_t)\),即欧拉方法的预测值。\(f(t+\Delta t,x_{pre})\)是用预测值计算的斜率。
- 欧拉方法:只用当前点的斜率来估计下一点,计算简单,但误差较大,容易偏离真实解。
- Heun方法:使用当前点和预测点的斜率平均值,精度更高,但计算稍微复杂一些。
对于\(dx=-2xdt\) 下面为对应的代码和生成的可视化对比图
def euler_method(f, x0, t):
x = [x0]
for i in range(len(t) - 1):
h = t[i+1] - t[i]
x_next = x[i] + h * f(t[i], x[i])
x.append(x_next)
return np.array(x)
def heun_method(f, x0, t):
x = [x0]
for i in range(len(t) - 1):
h = t[i+1] - t[i]
x_predict = x[i] + h * f(t[i], x[i]) # 欧拉预测
x_next = x[i] + h / 2 * (f(t[i], x[i]) + f(t[i+1], x_predict)) # 修正
x.append(x_next)
return np.array(x)
通过上述采样流程可以发现,关键项除了包括去噪神经网络\(D_\theta(\mathbf{x};\sigma)\), 还包括缩放因子\(s(t)\),噪声随时间的关系\(\sigma(t)\),时间序列\(t_i\in\{0,\cdots N\}\)。其中,缩放因子EDM推荐设置为\(s(t)=1\),也即不对输入进行任何放缩。噪声随时间的关系为\(\sigma_i=\sigma(t_i)=t_i\),也即噪声和时间等价,也可以表示为\(\sigma^{-1}(\sigma_i)=t_i\), EDM推荐的时间序列形式为:
\[\sigma_{i<N}=\left(\sigma_{\max}^{\frac1\rho}+\frac i{N-1}\left(\sigma_{\min}^{\frac1\rho}-\sigma_{\max}^{\frac1\rho}\right)\right)^\rho\quad\mathrm{and}\quad\sigma_N=0\]
其中,\(N\)为步数, \(\rho\) 为超参,论文试验设置\(\rho=7\)时效果最好。推荐设置论文里写的很清楚,至于为什么这么设置,作者结合了大量实验进行验证,效果好是第一导向!
小结
到这里, 我们有了仅仅依赖通用加噪公式中的\(s(t)\)和\(\sigma(t)\) 通用的PFODE方程, 进一步,我们设定了一个通用的训练loss方程:
\[\mathbb{E}{\mathbf{y}\sim p{\mathrm{data}},\mathbf{n}\sim\mathcal{N}(\mathbf{0},\sigma^2\mathbf{I})}{\left\|D_\theta(\mathbf{y}+\mathbf{n};\sigma)-\mathbf{y}\right\|_2^2}\]
即直接去学习一个\(D_\theta\)去预测原图,非常直接!
将\(D_\theta\) “代替” 之前PFODE公式中的score function, 顺利推导出了确定性采样的公式
\[\mathrm{d}\mathbf{x}_{t}=\left[\left(\frac{\dot{s}(t)}{s(t)}+\frac{\dot{\sigma}(t)}{\sigma(t)}\right)\mathbf{x}t-\frac{s(t)\dot{\sigma}(t)}{\sigma(t)}D\theta\left(\frac{\mathbf{x}_t}{s(t)};\sigma\right)\right]\mathrm{d}t\]
作者也用了二阶的Heun方法来代替之前的欧拉方法,可以得到更小的采样误差
有了训练和采样方法, 我们到这里可以得到一个完整的算法流程了! 但是这样的模型生成效果并不是很好,需要进一步更新
扩散模型通用模型框架
之前提到似乎可以用一个单纯的去噪模型\(D_\theta(\mathbf{x};\sigma)\)去作为扩散模型的通用模型范式,然而,实践证明直接训练一个去噪模型\(D_\theta(\mathbf{x};\sigma)\) 往往难以取得最优的效果。因此,还需要对\(D_\theta(\mathbf{x};\sigma)\)进行更深层次的分析与讨论。通过总结之前的一些扩散模型的训练过程,看是否能够得到一个更通用的形式。
从典型案例入手
DDPM/DDIM/VP
DDPM/DDIM/VP 形式的损失函数为:
\[\mathcal{L}_{\mathrm{VP}}=\mathbb{E}_{\mathbf{x}_t,t,\boldsymbol{\varepsilon}\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\lambda(t)\|\boldsymbol{\varepsilon}_\theta(\mathbf{x}_t;t)-\boldsymbol{\varepsilon}\|_2^2\]
其中,\(\varepsilon\) 表示真实噪声,\(\varepsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})\), \(\boldsymbol{\varepsilon}_\theta\)表示神经网络预测的噪声
通用框架需要出现一个单纯的去噪模型\(D\theta(\mathbf{x};\sigma)\), 这个去噪模型的输入为加噪图像\(\mathbf{x}_t\) , 输入为纯净图像 \(\mathbf{x}_0\)。考虑DDPM的一步加噪公式:
\[\mathbf{x}_t=\sqrt{\bar{\alpha}_t}\mathbf{x}_0+\sqrt{1-\bar{\alpha}_t}\boldsymbol{\varepsilon}\]
噪声图像\(\mathbf{x}_t\)和纯净图像\(\mathbf{x}_0\)的关系有:
\[\mathbf{x}_0=\frac{\mathbf{x}_t-\sqrt{1-\bar{\alpha_t}}\boldsymbol{\varepsilon}}{\sqrt{\bar{\alpha}_t}}\]
又因为单纯去噪模型\(D_\theta(\mathbf{x}_t;\sigma)\approx\mathbf{x}0\), 原始去噪模型\(*\boldsymbol\varepsilon\theta(\mathbf{x}_t,\sigma)\approx\boldsymbol\varepsilon*\)上式可进一步写为:
\[D_\theta(\mathbf{x}_t;\sigma(t))\approx\frac{\mathbf{x}_t-\sqrt{1-\bar{\alpha}_t}\boldsymbol{\varepsilon}}{\sqrt{\bar{\alpha}_t}}\approx\frac1{\sqrt{\bar{\alpha}_t}}\mathbf{x}_t-\frac{\sqrt{1-\bar{\alpha}_t}}{\sqrt{\bar{\alpha}_t}}\boldsymbol{\varepsilon}_\theta(\mathbf{x}_t;t)\tag{19}\]
SMLD/VE
SMLD形式的损失函数为:
\[\mathcal{L}_{\mathrm{SM}}=\mathbb{E}_{\mathbf{x},\sigma\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\lambda(\sigma)\|s_\theta(\mathbf{x};\sigma)-\nabla_\mathbf{x}\log p(\mathbf{x};\sigma)\|_2^2\]
同样,\(\nabla\mathbf{x}\log p(\mathbf{x};\sigma)\)表示真实分数,\(s_\theta\) 表示神经网络预测的分数。
之前的20式已经给出了下面的分数有关 \(D_{\theta}\) 的式子:
\[\nabla_\mathbf{x}\log p(\mathbf{x};\sigma)\approx\frac{D_\theta(\mathbf{x};\sigma)-\mathbf{x}}{\sigma^2}\]
结合\(s_\theta(\mathbf{x};\sigma)\approx\nabla_{\mathbf{x}}\log p(\mathbf{x};\sigma)\), 有:
\[s_{\theta}(\mathbf{x};\sigma)\approx\frac{D_{\theta}(\mathbf{x};\sigma)-\mathbf{x}}{\sigma^{2}}\]
整理成 \(D_{\theta}\) 在等式左边,有:
\[D_\theta(\mathbf{x};\sigma)\approx\mathbf{x}+\sigma^2s_\theta(\mathbf{x};\sigma)\tag{20}\]
Flow Matching/Rectified Flow
Flow Matching/Rectified Flow的损失函数为:
\[\mathcal{L}_{\mathrm{FM}}=\mathbb{E}_{\mathbf{x}t,t,\boldsymbol{\varepsilon}\sim\mathcal{N}(\mathbf{0},\mathbf{I})}\lambda(t)\|v_\theta(\mathbf{x}_t;t)-(\mathbf{x}_0-\boldsymbol{\varepsilon})\|_2^2\]
其中,\(\mathbf{x}_0\) 为纯净原始图像,\(\varepsilon\sim\mathcal{N}(\mathbf{0},\mathbf{I})\)。
对于优化目标\(\mathbf{x}0-\varepsilon\) 来说,也能找到与 \(D\theta\) 的关系,同样因为\(D_\theta(\mathbf{x};\sigma)\approx\mathbf{x}_0\)有,
\[v_\theta(\mathbf{x}_t;t)\approx D_\theta(\mathbf{x}_t;\sigma(t))-\boldsymbol{\varepsilon}\]
等式右边的 \(\varepsilon\) 最好可以消去,进一步分析Flow Matching的加噪公式
\[\mathbf{x}_t=t\mathbf{x}_0+(1-t)\boldsymbol{\varepsilon}\]
可得:
\[\begin{aligned}\boldsymbol{\varepsilon}&=\frac{\mathbf{x}_t-t\mathbf{x}_0}{1-t}\\&\approx\frac{\mathbf{x}_t-tD_\theta(\mathbf{x_t};\sigma(t))}{1-t}\end{aligned}\]
代回前式可得:
\[\begin{aligned}v_\theta(\mathbf{x}_t;t)&\approx D_\theta(\mathbf{x}_t;\sigma(t))-\boldsymbol{\varepsilon}\\&=D_\theta(\mathbf{x}_t;\sigma(t))-\frac{\mathbf{x}_t-tD_\theta(\mathbf{x}_t;\sigma(t))}{1-t}\\&=\frac{1}{1-t}D_\theta(\mathbf{x}_t;\sigma(t))-\frac{1}{1-t}\mathbf{x}_t\end{aligned}\]
把 \(D_\theta\) 写到等式的左边,有:
\[D_\theta(\mathbf{x}_t;\sigma(t))\approx\mathbf{x}_t+(1-t)v_\theta(\mathbf{x}_t;t)\tag{21}\]
放到一起看
把上面(19)、(20)和(21)放到一起看,似乎有一些规律,为了统一表示这种规律,EDM假设每个扩散模型方法对应的学习神经网络均为\(F_\theta(\mathbf{x};\sigma)\),有:
\[D_\theta(\hat{\mathbf{x}};\sigma)=C_\text{skip}(\sigma)\hat{\mathbf{x}}+C_\text{out}(\sigma)F_\theta(C_\text{in}(\sigma)\hat{\mathbf{x}};C_\text{noise}(\sigma))\tag{22}\]
其中,\(\hat{\mathbf{x}}\) 表示标准化输入,也即像素值为[0,255]或等价的标准化区间,\(\mathbf{x}=s(t)\hat{\mathbf{x}}\) ( 做这个\(\hat{\mathbf{x}}\)的定义是因为作者想将所有框架统一, 并定义一个标准化的输入形式)。系数\(C_\mathrm{skip}(\sigma)\)和\(C_\mathrm{out}(\sigma)\)都特别好理解,好像\(C_\mathrm{in}(\sigma)\)和 \(C_{\mathrm{noise}}(\sigma)\) 相对抽象。根据通用一步加噪(1), 这里再写一遍
\[p_{0t}(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;s(t)\mathbf{x}_0,s^2(t)\sigma^2(t)\mathbf{I})\]
首先,对于\(C_\mathrm{noise}\), 这是一个对 \(\sigma\) 的变换函数,因为神经网络的另外一个条件输入大概率不是噪声本身(就是时间编码!!),这个\(C_\mathrm{noise}\) 指有可能对输入噪声进一步的mapping处理,比如取对数(\(C_\mathrm{noise}(\sigma)=\log\left(\frac12\sigma\right)\),SMLD), 或者把噪声变换为时间作为条件(\(\sigma^{-1}(\sigma)=t\), FM、 DDPM)。
对于\(C_\mathrm{in}\),它的出现主要是因为EDM框架要求输入的图像具有标准化区间的像素值,但有些情况输入的带噪声的 \(x\) 的均值乘以了一个常数,进而导致其像素值的均值不满足原始标准化区间,需要额外表示为标准化区间的像素值。在上述三个等式当中,
- 对于DDPM/DDIM/VP有:\(s(t)=\sqrt{\bar{\alpha}_t}\), 所以\(C\mathrm{in}(\sigma)=\sqrt{\bar{\alpha}(t)}=\sqrt{\bar{\alpha}(\sigma^{-1}(\sigma))}\)
- 对于SMLD/VE有:\(s(t)=1\), 所以\(C_{\mathrm{in}}(\sigma)=1\)
- 对于FM/RF有:\(s(t)=t\), 所以\(C_\mathrm{in}(\sigma)=t=\sigma^{-1}(\sigma)\)
小结
到这里, 因为直接学习原图这个通用训练loss效果并不好, 所以我们又将经典的三个案例(ddpm/smld/flowmatching)的模型统一起来, 构成一个通用的模型框架,即
\[D_\theta(\hat{\mathbf{x}};\sigma)=C_\text{skip}(\sigma)\hat{\mathbf{x}}+C_\text{out}(\sigma)F_\theta(C_\text{in}(\sigma)\hat{\mathbf{x}};C_\text{noise}(\sigma))\]
- \(F_{\theta}\) 是真正扩散模型训练的神经网络(U-net、DiT等),\(D_{\theta}\) 是单纯的去噪网络,也即任意扩散模型训练的神经网络都可以转化为一个单纯的去噪网络,该单纯去噪网络由原始输入\(x\)和真正训练的神经网络\(F_{\theta}\) 加权求和获得,权重系数分别为\(C_\mathrm{skip}(\sigma)\) 和 \(C_{\mathrm{out}}(\sigma)\)。
- \(C_{\mathrm{noise}}(\sigma)\)是一个对 \(\sigma\) 的变换函数,EDM框架要求模型输入为 \(\sigma\),但是训练的神经网络的条件输入不一定是噪声\(\sigma\), 其中最典型的案例就是DDPM、DDIM、Flow Matching等输入的条件为时间\(t\), 但时间\(t\)又和噪声水平\(\sigma\)相关,所以给一个变换函数 \(C_{\mathrm{noise}}(\sigma)\) 统一把 \(\sigma\) 转换成你输入的条件就可以了。
- \(C_{\mathrm{in}}(\sigma)\) 的出现也是为了统一框架而进行设定,注意到这里的输入是\(\hat{\mathbf{x}}\), 表示EDM定义的标准化输出,像素值区间为\([-1,1]\)。由于加噪公式的\(s(t)\) 能够导致图像分布均值像素值区间变化,需要额外的\(C_\mathrm{in}(\sigma)\)将标准化输出x的像素值区间变换到均值的像素值区间。
所以我们有了这个统一的框架, 我们具体该如何去训练呢?
扩散模型通用训练框架
现在咱们已经有了⼀个通⽤的模型框架式25,有模型了,就可以开始训练了。为了训练模型,损失函数少不了,\(D_\theta({\mathbf{x}, \sigma})\) 实际上是⼀个单纯的去噪模型,就是把噪声图像 \(x = y + \mathbf{n}\) 变换为纯净图像 \(y\),其中 \(n ∼ \mathcal{N} (\mathcal{0}, σ^2\mathcal{I})\)
为什么在这个框架中加入这么多的前处理和后处理操作呢?为了模型训练的稳定性,包含loss的稳定,模型\(D_\theta\)的输入和输出稳定。
通用损失函数
既然\(D_\theta(\mathbf{x};\sigma)\) 是一个单纯的去噪模型,那它的损失函数也必定是一个单纯的与噪声的距离度量,假设就是MSE损失函数形式:
\[\begin{aligned}\mathcal{L}_{\mathrm{diff}}&=\mathbb{E}_{\sigma\sim p_{\mathrm{train}},\mathbf{x},\mathbf{y}\sim p_{\mathrm{data}}}\left[\lambda(\sigma)\|D_\theta(\mathbf{x};\sigma)-\mathbf{y}\|_2^2\right]\\&=\mathbb{E}_{\sigma\sim p_{\mathrm{train}},\mathbf{n}\sim\mathcal{N}(\mathbf{0},\sigma^{2}\mathbf{I}),\mathbf{y}\sim p_{\mathrm{data}}}\left[\lambda(\sigma)\|D_{\theta}(\mathbf{y}+\mathbf{n};\sigma)-\mathbf{y}\|_{2}^{2}\right]\end{aligned}\tag{23}\]
\(p_{train}\) 是 \(\sigma\) 的分布,也即在训练的时候,每个噪声水平(时间点)不一定是服从均匀分布,将(22)代入(23)可得:
\[\begin{aligned}\mathcal{L}_{\mathrm{diff}}&=\mathbb{E}_{\sigma,\mathbf{n},\mathbf{y}}\Big[\lambda(\sigma)\|C_{\mathrm{skip}}(\sigma)(\mathbf{y}+\mathbf{n})+C_{\mathrm{out}}(\sigma)F_{\theta}(C_{\mathrm{in}}(\sigma)(\mathbf{y}+\mathbf{n});C_{\mathrm{noise}}(\sigma))-\mathbf{y}\|_{2}^{2}\Big]\\&=\mathbb{E}_{\sigma,\mathbf{n},\mathbf{y}}\left[\underbrace{\lambda(\sigma)C_{\mathrm{out}}^{2}(\sigma)}_{\text{损失权重}\omega(\sigma)}\left\|\underbrace{F_{\theta}(C_{\mathrm{in}}(\sigma)(\mathbf{y}+\mathbf{n});C_{\mathrm{noise}}(\sigma))}_{\text{模型输出}}-\underbrace{\frac{1}{C{\mathrm{out}}(\sigma)}(\mathbf{y}-C_{\mathrm{skip}}(\sigma)(\mathbf{y}+\mathbf{n}))}_{\text{训练目标}F{\mathrm{target}}(\mathbf{y},\mathbf{n};\sigma)}\right\|_{2}^{2}\right]\end{aligned}\tag{24}\]
超参数选取
要使得训练稳定,不能使得噪声不同的时候,损失函数产生大幅度的变化,因此EDM考虑了以下四点来设计\(C_\mathrm{in}(\sigma)\)、\(C_\mathrm{out}(\sigma)\)、\(C_\mathrm{skip}(\sigma)\)、\(\lambda(\sigma)\) :
神经网络的输入保持单位方差
让输入在不同的噪声下都保持一个稳定的方差对模型训练的稳定性是有帮助的,故作者设定有:
\[\mathbb{D}_{\mathbf{y},\mathbf{n}}\left[C_{\mathrm{in}}(\sigma)(\mathbf{y}+\mathbf{n})\right]=1\tag{25}\]
根据概率论基础+初等运算可推导出:
\[C_\text{in}(\sigma)=\frac{1}{\sqrt{\sigma^2+\sigma_\text{data}^2}}\tag{26}\]
其中 \(\sigma_\text{data}\)是个超参数, 作者设定为\(\sigma_\text{data}=0.5\)
训练目标保持单位方差
\[\mathbb{D}_{\mathbf{y},\mathbf{n}}\left[\frac{1}{C_{\mathrm{out}}(\sigma)}(\mathbf{y}-C_{\mathrm{skip}}(\sigma)(\mathbf{y}+\mathbf{n})\right]=1\tag{27}\]
根据概率论基础+初等运算可推导出:
\[C_{\mathrm{out}}^2(\sigma)=(1-C_{\mathrm{skip}}(\sigma))^2\sigma_{\mathrm{data}}^2+C_{\mathrm{skip}}^2(\sigma)\sigma^2\tag{28}\]
可以发现上式的\(C_\mathrm{out}(\sigma)\) 和 \(C_\mathrm{skip}(\sigma)\) 相关,还需要进行解耦。可以从(22)看出,因为 \(C_\mathrm{out}(\sigma)\) 直接关系到神经网络\(F_\theta\) 的输出尺度,太大的 \(C_\mathrm{out}(\sigma)\) 会放大 \(F_\theta\) 的估计误差,所以EDM通过求解下面的最优化问题来先求出会导致 \(C_\mathrm{out}(\sigma)\) 最小的 \(C_\mathrm{skip}(\sigma)\) 的值:
\[C_{\mathrm{skip}}(\sigma)=\argmin_{C_{\mathrm{skip}}(\sigma)}C_{\mathrm{out}}^2(\sigma)\]
作为一个单纯的凸优化问题,导数为0就是最小值,能获得一些额外的信息:
\[\frac{\mathrm{d}C_{\mathrm{out}}^2(\sigma)}{\mathrm{d}C_{\mathrm{skip}}(\sigma)}=0\]
初等运算可得:
\[C_{\mathrm{skip}}(\sigma)=\frac{\sigma_{\mathrm{data}}^2}{\sigma^2+\sigma_{\mathrm{data}}^2}\tag{29}\]
将(29)代入(28)中,初等运算可得:
\[C_{\mathrm{out}}(\sigma)=\frac{\sigma\cdot\sigma_{\mathrm{data}}}{\sqrt{\sigma^2+\sigma_{\mathrm{data}}^2}}\tag{30}\]
损失权重\(w(\sigma)=1=>\)等价对待所有的噪声水平损失函数
也即
\[\lambda(\sigma)C_{\mathrm{out}}^2(\sigma)=1\tag{31}\]
初等运算可得:
\[\lambda(\sigma)=\frac{\sigma^2+\sigma_{\mathrm{data}}^2}{(\sigma\cdot\sigma_{\mathrm{data}})^2}\tag{32}\]
组合1、2和3可得:
\[\mathbb{E}_{\mathbf{n},\mathbf{y}}\left[\underbrace{\lambda(\sigma)C_{\mathrm{cout}}^2(\sigma)}_{\text{损失权重}w(\sigma)}\left\|\underbrace{F_\theta(C_{\mathrm{in}}(\sigma)(\mathbf{y}+\mathbf{n});C_{\mathrm{noise}}(\sigma))}_{\text{模型输出}}-\underbrace{\frac{1}{C_{\mathrm{out}}(\sigma)}(\mathbf{y}-C_{\mathrm{skip}}(\sigma)(\mathbf{y}+\mathbf{n}))}_{\text{训练目标}F{\mathrm{target}}(\mathbf{y},\mathbf{n};\sigma)}\right\|_2^2\right]= 1\tag{33}\]
当 \(\sigma\) 固定时,损失函数的期望恒为 1,保证了训练过程的稳定,也提高了扩散模型的鲁棒性。
\(\sigma\) 的分布如何设定?
EDM设定\(p_{train}(\sigma)\)为下面形式:
\[\ln(\sigma)\sim\mathcal{N}(P_{\mathrm{mean}},P_{\mathrm{std}}^2)\tag{34}\]
并设定:\(P_{\mathrm{mean}}=-1.2,P_{\mathrm{std}}=1.2\), 采用上述分布的原因如下:
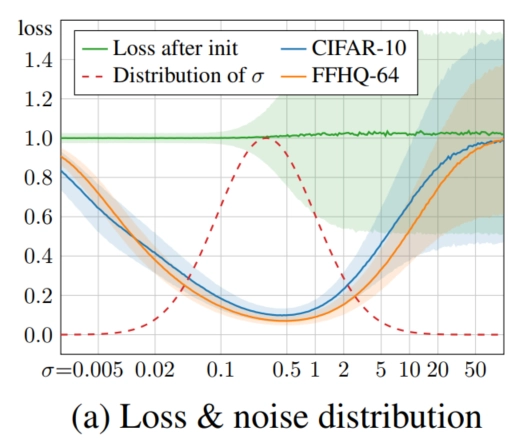
- 根据实验发现,损失函数下降比较多的是中间的噪声水平。
- 在噪声水平很低时,也即噪声几乎可以忽略不计的情况下,模型预测的相对误差大,损失函数难以下降。
- 在噪声水平较高时,对真实图像扰动大,模型学习难度更大,每一个样本的学习目标与样本均值目标差距大(可以从RF中相交的例子去考虑),损失函数难以下降。
- 既然损失函数在噪声很小和噪声很大的时候都不怎么下降,那为什么要花精力去学习呢?EDM设计的 \(\sigma\) 分布从实验角度出发,以结果为导向,是一种推荐的选择。下图为EDM的试验中, 随着 \(\sigma\) 变化的loss值。
小结
到此为止,我们在上一节得到了一个模型框架,接下来就是得到一个统一的模型训练的过程范式:
\[\mathcal{L}_{\mathrm{diff}}=\mathbb{E}_{\sigma,\mathbf{n},\mathbf{y}}\left[\underbrace{\lambda(\sigma)C_{\mathrm{out}}^{2}(\sigma)}_{\text{损失权重}\omega(\sigma)}\left\|\underbrace{F_{\theta}(C_{\mathrm{in}}(\sigma)(\mathbf{y}+\mathbf{n});C_{\mathrm{noise}}(\sigma))}_{\text{模型输出}}-\underbrace{\frac{1}{C{\mathrm{out}}(\sigma)}(\mathbf{y}-C_{\mathrm{skip}}(\sigma)(\mathbf{y}+\mathbf{n}))}_{\text{训练目标}F{\mathrm{target}}(\mathbf{y},\mathbf{n};\sigma)}\right\|_{2}^{2}\right]\]
为了模型在训练过程中保持稳定,EDM在此做了一系列约束,
- 神经网络的输入保持单位方差: \(\mathbb{D}_{\mathbf{y},\mathbf{n}}\left[C_{\mathrm{in}}(\sigma)(\mathbf{y}+\mathbf{n})\right]=1\)
- 训练目标保持单位方差: \(\mathbb{D}{\mathbf{y},\mathbf{n}}\left[\frac{1}{C{\mathrm{out}}(\sigma)}(\mathbf{y}-C_{\mathrm{skip}}(\sigma)(\mathbf{y}+\mathbf{n})\right]=1\)
- 损失权重为1:\(w(\sigma)=1\)
得到了一个稳定的训练范式,即当 \(\sigma\) 固定时,损失函数的期望恒为 1
关于\(\sigma\)的设定, EDM也通过一系列理论和试验的论证,给出了自己的最优设定,即:
\[\ln(\sigma)\sim\mathcal{N}(P_{\mathrm{mean}},P_{\mathrm{std}}^2)\quad P_{\mathrm{mean}}=-1.2,P_{\mathrm{std}}=1.2\]
上述分布保证了 \(σ\) 在训练中更集中在中间水平,有利于模型训练稳定与性能提升
扩散模型通用随机微分方程
推导思路
扩散模型的加噪过程实际上就是一系列概率分布的变化,从初始概率密度 \(q( \mathbf{x} , 0) : = p_\mathrm{data}( \mathbf{x} )\)到最终概率密度 \(p(\mathbf{x},t_N)=p(\mathbf{x},\sigma(t_N))\)。在初始分布给定的情况下,一旦明确加噪过程每个时刻 \(x\) 的分布随时间 \(t\) 的变化关系,那个加噪过程的分布变化就唯一确定了。实际上,在物理学中有描述概率分布随时间变化的方程,也即热方程偏微分方程(heat equation PDE):
\[\frac{\partial q(\mathbf{x},t)}{\partial t}=\kappa(t)\Delta_\mathbf{x}q(\mathbf{x},t)\tag{35}\]
我们的目标就是让这个偏微分方程的解 \(q(\mathbf{x},t)\) 等于加噪过程的边缘概率密度,边缘概率密度前面我们已经推导过,即(14),又因为在EDM框架下\(s(t)=1\), 所以加噪过程的边缘概率密度有:
\[q(\mathbf{x},t)=p(\mathbf{x};\sigma(t))=p_\text{data}*\mathcal{N}(\mathbf{0},\sigma^2(t)\mathbf{I})(\mathbf{x})\]
通过对 \(q(\mathbf{x},t)\) 沿着 \(\mathbf{x}\) 的维度做傅里叶变换,可以推导出:
\[\kappa(t)=\dot{\sigma}(t)\sigma(t)\tag{36}\]
带入到(35),得:
\[\frac{\partial q(\mathbf{x},t)}{\partial t}=\dot{\sigma}(t)\sigma(t)\Delta_\mathbf{x}q(\mathbf{x},t)\tag{37}\]
与此同时,还有一个描述如下的随机微分方程(SDE)
\[\mathrm{d}\mathbf{x}=f(\mathbf{x},t)\mathrm{d}t+g(t)\mathrm{d}w_t\]
解 \(x\) 的概率密度时间随变化关系的公式,也即福克普朗克(Fokker-Planck)公式,其形式如下:
\[\frac{\partial q(\mathbf{x},t)}{\partial t}=-\nabla\cdot(f(\mathbf{x},t)q(\mathbf{x},t))+\frac12g^2(t)\Delta_\mathbf{x}q(\mathbf{x},t)\tag{38}\]
让(38)的右边和(37)的右边相等,经过化简,可以得到一个SDE公式:
\[\mathrm{d}\mathbf{x}=\left(\frac12g^2(t)-\dot{\sigma}(t)\sigma(t)\right)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t+g(t)\mathrm{d}w_t\tag{39}\]
理论上,上面式子的 \(g(t)\) 可以随意取,因为我们是从一个通用的SDE通过福克普朗克公式推出来的,求解的 \(\mathbf{x}\) 的概率密度符合加噪边缘概率密度,EDM给出了两种特殊情况
- 当 \(g(t)=0\) 时,(39)退化为一个概率流常微分方程 ( 满足EDM框架 \(s(t)=1\) 的情形的PFODE,(15)
\[\mathrm{d}\mathbf{x}=-\dot{\sigma}(t)\sigma(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t\]
- 当 \(g(t)=\sqrt{2\beta(t)}\sigma(t)\) ,得到EDM框架对应的SDE形式:
\[\mathrm{d}\mathbf{x}_\pm=-\dot{\sigma}(t)\sigma(t)\nabla\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t\pm\beta(t)\sigma^2(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t+\sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t\tag{40}\]
其中,\(d\mathbf{x}_+\) 表示前向SDE,\(d\mathbf{x}_-\) 表示逆向SDE,去噪随机性采样过程使用逆向SDE形式。
随机微分方程分析
最后,仔细分析公(40),可以发现其由三个部分组成,分别分析其作用:
- 第一部分:\(-\dot{\sigma}(t)\sigma(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))dt\)
这个部分就是EDM框架下的通用PFODE形式,只是在\(s(t)=1\) 的情形下。这一部分的出现预示着基于逆向SDE的随机性采样过程也一定包含与确定性采样类似的过程。
- ODE是一个确定性过程,因此单纯使用ODE无法直接模拟加噪过程,因为加噪本质上是一个随机过程,需要通过SDE来描述随机性。如果使用ODE直接进行加噪,无法引入随机性,因而无法有效地匹配目标分布的随机特性。
- 在确定一个随机过程(如通过SDE描述加噪过程)后,可以通过概率流ODE等价地表示分布的演化。这种等价性允许我们在采样阶段使用ODE代替SDE,从而实现确定性的采样过程。
- 在通过学习完成了加噪过程(由SDE描述)后,可以使用概率流ODE进行确定性的采样,从初始分布生成目标数据分布。这种方法避免了随机性,通常能够提高采样效率。
- 第二部分:\(\pm\beta(t)\sigma^2(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t\)
这一部分是确定性噪声衰减项,代入Score与单纯去噪模型\(D_\theta(\mathbf{x};\sigma)\) 的关系(17),有:
\[ \begin{aligned}\pm\beta(t)\sigma^2(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t&=\pm\beta(t)\sigma^2(t)\frac{D_\theta(\mathbf{x};\sigma(t))-\mathbf{x}}{\sigma^2(t)}\mathrm{d}t\\&=\pm\beta(t)\left(D_\theta(\mathbf{x};\sigma(t))-\mathbf{x}\right)\mathrm{d}t\end{aligned}\]
由于\(D_\theta(\mathbf{x};\sigma)\) 是单纯去噪模型,又有\(\mathbf{x}=\mathbf{y}+\mathbf{n}\), 其中 \(\mathbf{y}\) 为原始图像,\(\mathbf{n}\) 为噪声,满足\(\mathbf{n}\sim\mathcal{N}(\mathbf{0},\sigma^2(t)\mathbf{I})\), 自然有:
\[\pm\beta(t)(D_\theta(\mathbf{x};\sigma(t))-\mathbf{x})\mathrm{d}t\approx\pm\beta(t)(\mathbf{y}-\mathbf{x})\mathrm{d}t=\mp\beta(t)\mathbf{n}\mathrm{d}t\tag{41}\]
也就是说,第二部分的值实际上与噪声水平成正比,噪声水平越大对 \(x\) 的改变越大。
- 第三部分:\(\sqrt2\beta(t)\sigma(t)dw_t\)
由于维纳过程\(dw_t\)的存在,这一项显然属于随机项,被称为随机噪声注入项。由于随机项的存在,在采样的同时需要“不断加噪”,可以认识是一种去噪过程的回退,往回退一点,再往前走,有助于修正之前采样过程存在的误差。所以SDE的采样过程会慢,但是精度会高一些。
\[\begin{aligned}\sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t&=\sqrt{2\beta(t)}\sigma(t)\boldsymbol{\varepsilon}\sqrt{\mathrm{d}t}\\&=\sqrt{2\beta(t)}\mathbf{n}^{\prime}\sqrt{\mathrm{d}t}\end{aligned}\tag{42}\]
这里,噪声 \(\mathbf{n}^{\prime}\) 和 \(\mathbf{n}\) 均服从分布 \(\mathcal{N}(\mathbf{0},\sigma^2(t)\mathbf{I})\), 但他们有本质的区别。其中 \(\mathbf{n}\)是采样图像当前存在的噪声,是确定值,但是维纳过程的 \(\boldsymbol{\varepsilon}\) 是每一个采样步骤随机,所以二者噪声水平相当但不相等!联合(41)和(42)来看,对于加噪SDE有:
\[\begin{aligned}&\beta(t)\sigma^2(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t+\sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t\\&=-\beta(t)\mathbf{n}\mathrm{d}t+\sqrt{2\beta(t)}\mathbf{n}^{\prime}\sqrt{\mathrm{d}t}\end{aligned}\tag{43}\]
观察(43),在前向SDE当中,同时在进行着相同水平噪声的加噪和去噪过程,\(\beta(t)\) 控制二者的相对速率。
根据上述的分析,EDM框架下的随机微分方程可以写为:
\[\begin{aligned}\mathrm{d}\mathbf{x}_{\pm}=&\underbrace{-\dot{\sigma}(t)\sigma(t)\nabla{\mathbf{x}}\log p(\mathbf{x};\sigma(t))\mathrm{d}t}_{\mathrm{PFODE}}\\
&\pm\underbrace{\underbrace{\beta(t)\sigma^2(t)\nabla{\mathbf{x}}\log p(\mathbf{x};\sigma(t))\mathrm{d}t}_{\text{deterministic noise odecay}}+\underbrace{\sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t}_{\text{noise injection}}}_{\text{Langvin diffusion SDE}}\end{aligned}\tag{44}\]
有了上述的前向和逆向SDE,就可以采用随机性采样实现对噪声图像的去噪采样了~
小结
这一节主要是确立了一个扩散模型的通用随机微分方程sde,通过物理上的热方程偏微分方程和SDE的福克普朗克公式联合,进而确立了这个通用的SDE:
\[\mathrm{d}\mathbf{x}_\pm=-\dot{\sigma}(t)\sigma(t)\nabla\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t\pm\beta(t)\sigma^2(t)\nabla_\mathbf{x}\log p(\mathbf{x};\sigma(t))\mathrm{d}t+\sqrt{2\beta(t)}\sigma(t)\mathrm{d}w_t\]
这就是通用SDE的加噪和去噪过程,理解这个公式每一项的含义可以得出:前向和逆向SDE在进行着相同水平噪声的加噪和去噪过程,而\(\beta(t)\) 控制二者的相对速率。
扩散模型通用推理过程:随机性采样
有了前向和逆向的通用扩散SDE (44),可以发现一个有趣的现象,仅仅使用该式中的常微分方程(PFODE)部分采样的每⼀步 \(\mathbf{x}_i\) 的概率密度(分布)与使⽤完整的SDE采样的每⼀步 \(\mathbf{x}_i\) 的概率密度(分布)是完全⼀样的,哪个效果更好?Langevin diffusion SDE中的随机项到底起了什么作⽤呢?
随机性采样算法

随机性采样并没有完全依赖SDE,⽽是在确定性采样的基础上,先给原有样本 \(\mathbf{x}_i\) 进⼀步加噪(对应算法2中的4-6),有⼀个回退的操作(后面的操作其实跟确定性采样的算法没什么区别),因此图像⽣成效果通常会⽐ODE效果好。
超参数设置
在随机性采样中,需要设置很多超参数,EDM论⽂中也对这些超参数给出了简明的含义和设置原则,所有超参数设置全部以实验结果为导向,也即实验效果怎么好怎么来。

该实验⾸先从数据集中采样⼀张图像,给图像加噪后满⾜分布 \(p(\mathbf{x}; σ)\),⽤固定的 \(σ\) 不断进行随机性采样(Algorithm 2),图像中间的 \(σ\) 表示随机性采样过程使⽤的噪声,图像下方表明使用随机性采样的步数。在上述过程执行完,采用 \(D_\theta(\mathbf{x};\sigma(t)\) 生成可视化的⽣成图像。
- 发现⼀:小噪声水平过多次的随机噪声注入影响图像分布
现象描述:当噪声水平低于0.2或者更低的时候,过多次的噪声注⼊会使得⽣成图像会出现过饱和现象,甚⾄完全被破坏,证明了SDE中的过分的随机噪声注⼊对⽣成过程没有好处。
解决办法:设置⼀个\(S_{tmin}>0\),当图像噪声水平已经足够小了,就不进行噪声注入,等价于采用确定性采样。 - 发现⼆:大噪声水平过多次的随机噪声注入影响图像分布
现象描述:当噪声水平较高时,过多次的随机噪声注入会让图像变得抽象,背景变得色彩单调。
解决办法:设置⼀个\(S_{noise}\),这个值略大于1.0,但这个办法不能缓解发现⼀中的问题。 - 发现三:随机噪声注入强度与生成图像效果有关
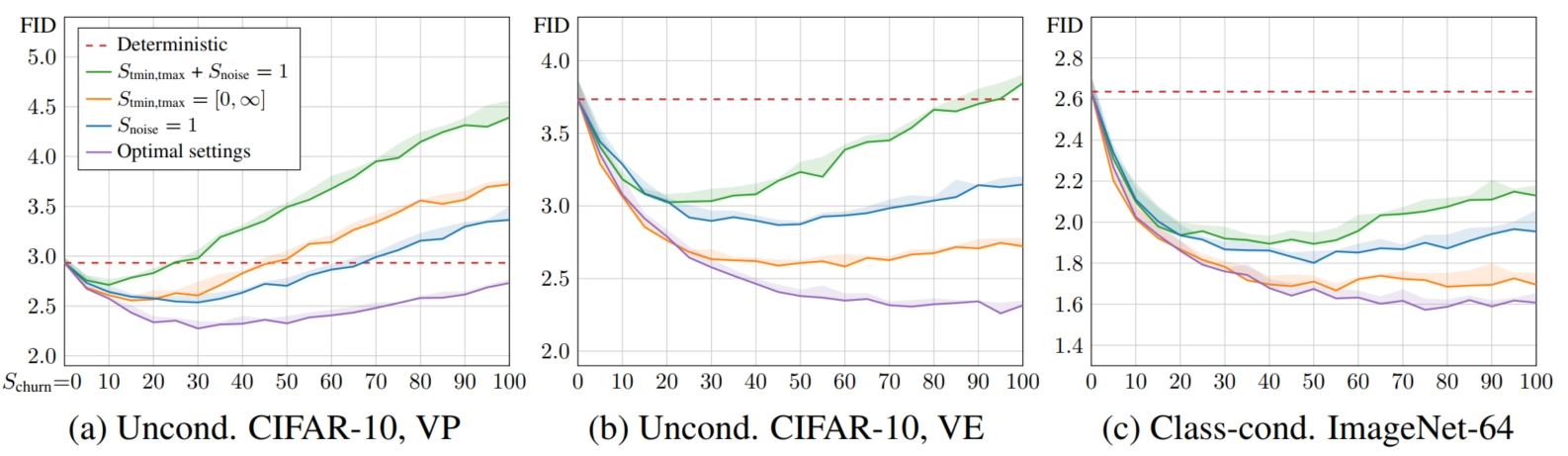 现象描述:实验发现 \(S_{churn}\) 的取值与性能有关。
现象描述:实验发现 \(S_{churn}\) 的取值与性能有关。
解决办法:依据最优设置(紫色曲线),根据不同数据集选取最优的\(S_{churn}\)。
小结
可以看出这一节的标题中随机性采样没有加上“通用”二字,这是因为随机性采样过程方法众多,甚至和逆向SDE公式本身“关系不大”。 EDM论文也表示它设计的随机性采样过程不是一种通用的SDE求解器,而是一种面向扩散模型问题的垂类SDE求解器。
EDM设计的随机性采样过程非常简单,其核心就是在确定性采样的基础上增加了“回退”操作,也即先对样本额外加噪,再采用ODE求解器采样获得下一个时间点的图像。 这种回退操作可以有效修正前面迭代步骤产生的误差,所以通常相比PFODE的生成效果更好,但同时也要花费更多的采样步数。
上图中,红色线代表确定性采样的结果,橙色线代表不采用\(S_{tmin}\)和\(S_{tmax}\),绿⾊线代表不采用\(S_{tmin}\)和\(S_{tmax}\),同时也不采用\(S_{noise}\),蓝⾊线代表不采用\(S_{noise}\),紫⾊线为最优设置。
- 确定性采样可以在更短的时间达到更低的FID,表明可以加速采样
- 随机性采样在更多步数以后可以达到更低的FID,效果⽐确定性采样要好
- 随机性采样以超参数设置与更多迭代步数为代价,换来了更好的采样性能
Reference
【AI知识分享】历时一个半月,全网最用心EDM论文核心知识点串讲,EDM论文讲解之扩散模型通用框架超详细解读第八回:最终一战