传统的图像金字塔
最开始在深度学习方法流行之前,对于不同尺度的目标,大家普遍使用将原图构建出不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标,以求在金字塔底部检测出小目标;或者只用一个原图,在原图上,用不同分辨率的分类器来检测目标,以求在比较小的窗口分类器中检测到小目标。经典的基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标,早期的CNN目标识别框架同样采用该方式,但对图像金字塔中的每一层分别进行CNN提取特征,耗时与内存消耗均无法满足需求。但该方式毫无疑问仍然是最优的。值得一提的是,其实目前大多数深度学习算法提交结果进行排名的时候,大多使用多尺度测试。同时类似于SNIP使用多尺度训练,均是图像金字塔的多尺度处理。
SNIP
图像分类算法,比如ResNeXt-101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 \(AP_{50}\)为62%,显然,总体上来看,准确率差了20个点左右,那么问题来了,为什么检测算法比识别算法的效果低这么多呢?
- 尺度差异
作者认为原因在于,检测任务中的目标存在较大的尺度变化(large scale variation)。作者统计了Imagenet和COCO数据集的特点,如下图,
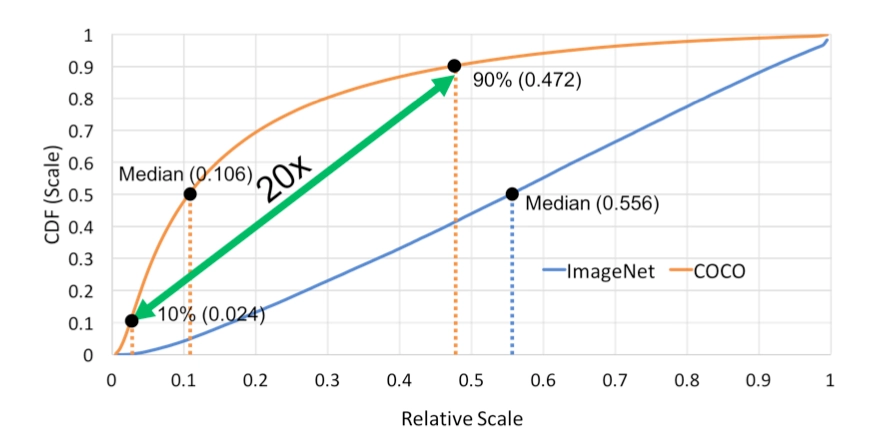
其中,横坐标表示目标相对于原图的比例,纵坐标表示累计分布(cumulation distribution function)。显然,由图中可以看出,COCO数据集中50%的目标相对原图的比例小于0.106,而Imagenet数据集中相对原图的比例小于0.106的目标的比例不足10%,因此,COCO数据集中的目标尺寸明显小于Imagenet数据集中的目标。
而且,COCO数据集中,最小的10%的目标尺寸小于0.024,最大的10%的目标尺寸大于0.472,显然,对于待检测的所有目标,它们的尺寸差异是很大的,那么如何把所有尺寸的目标都召回来呢?
文章中总结的目前尺度变化的方案:
- 使用FPN这种把浅层特征和深层特征融合的,或者最后在预测的时候,使用浅层特征和深层特征一起预测;
- 也有比较直接地在浅层和深层的feature map上直接各自独立做预测的 (e.g. SSD);
- 使用dilated或者deformable这类特殊的卷积来提高检测器对分辨率的敏感度(提高感受野)
- 最常用的,upsample来rezie网络输入图像的大小
- domain-shift
通常,对于目标检测任务,我们会使用imagenet预训练的模型,然后做finetune。但是,上面提到了分类数据集中目标的尺寸比检测数据集中的大,所以直接finetune会引入“domain-shift” 问题,那么如何保证finetune用的数据集中目标尺寸和检测数据集中保持一致呢?
图像分辨率对分类任务的影响
在分类任务中,我们常常遇到训练集或者测试集中包含了不同分辨率的图片。根据经验这时候会有很多种选择,(1) 把所有的图片缩放到相同尺寸,然后训练和推理;(2) 训练大网络和小网络,分别用来处理大分辨率和小分辨率的图片。在论文中,作者用数据说话,证明了这两种方案都是次优的。
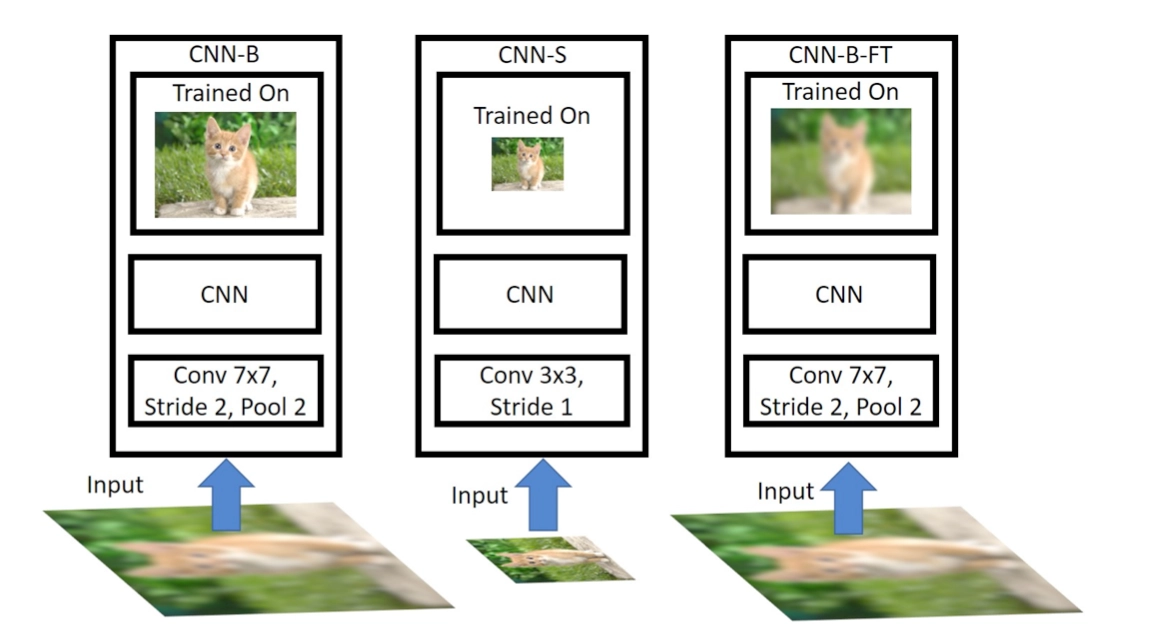
(a)CNN-B方案:在224x224尺度上训练的模型, 其stride=2. 我们将测试图片降采样到 [48x48, 64x64, 80x80, 96x96,128x128], 然后再放大回224x224用于测试;
(b)CNN-S方案:训练集将图像下采样到48 × 48 , 64 × 64 , 80 × 80 , 96 × 96 , 128 × 128 ,模拟出低分辨率图片,作为网络的输入,测试集将所有图像resize到相同分辨率,低清训练/低清测试;
(c)CNN-B-FT:先使用224 × 224 的高分辨率图像对网络做预训练,然后将图像下采样到48 × 48 , 64 × 64 , 80 × 80 , 96 × 96 , 128 × 128 ,模拟出低分辨率图片,接着将低分辨率图像resize到224×224,然后用这些上采样的模糊图片finetune模型参数。
它们的对比结果如下,

结论1:由图(a)可以看出,训练集和测试集的图像分辨率差异越大,测试集的效果越低;因此,至少在图像分类方面,对未经网络训练的分辨率进行测试显然不是最佳选择。
解释:因为先下采样然后resize,相当于训练集图片变模糊了,也即模型学习的是模糊图像的特征,且采样率越低,图片越模糊,对应的测试集(非模糊图像)效果就越差。
结论2:从图(b)可以看出,模型效果 CNN-B-FT > CNN-S > CNN-B;
解释:CNN-B-FT的效果优于CNN-S,作者认为原因是,从高分辨率图像中学习到的知识有助于识别低分辨率的图像。
可以这样理解作者的三个实验:ImageNet物体大、分辨率高,而COCO目标都很小,直接迁移会有问题,作者在试图探究如何进行迁移。降采样后的小图像数据集其实对应的是COCO数据集普遍存在的小目标的情况,试图模仿COCO数据集。因此三个网络的含义应该是:CNN-B,ImageNet预训练后的参数直接用来给COCO这种分辨率低的数据集用;CNN-S,不用ImageNet这种高分辨率的数据集做训练,我把网络就设置成适合COCO这类数据集的,训练和测试都用分辨率低的数据集;CNN-B-FT,ImageNet人家都训练好了,不用白不用,但是用之前,先用低分辨率数据集做一下fine-tune改良效果。
从CNN-B-FT的实验可以得出:在高清训练集学出来的模型依然有办法在低清晰度的图片上做预测. 直接用低清晰度图片微调好过将stride降低重新训练一个网络推广到目标检测上, 当尺度不同时, 我们可以选择更换在ImageNet上pre-trained网络架构.
目标检测的影响因素
- 图像分辨率
这里研究了训练集和测试集的分辨率对结果的影响,做了如下对比实验
实验1(简写为\(800_{all}\)):训练集分辨率设置为800 × 1400,学习训练集中的所有目标,测试集分辨率设置为1400 × 2000 ;
实验2(简写为\(1400_{all}\)):训练集分辨率设置为1400 × 2000,学习训练集中的所有目标,测试集分辨率设置为1400 × 2000 ;
对比结果:实验2的效果略微优于实验1;
解释:(1)为什么实验2的效果更好呢?因为实验2的训练集和测试集图像分辨率相同;(2)为什么效果提升不明显呢?因为实验2训练集图片分辨率大,那么其中的medium-to-large目标会变得太大导致分类出错。也就是说,高分辨率的训练集图片提升了小目标的识别效果,但是降低了medium-to-large目标的识别效果。
思考:怎么在提升小目标的识别效果的同时,也提升medium-to-large目标的识别效果呢?
- 图像中目标的尺寸
实验3(简写为\(1400_{<80px}\)):训练集分辨率设置为1400 × 2000,只学习训练集中的小目标,忽略掉medium-to-large目标,测试集分辨率设置为1400 × 2000;
对比结果:实验3的效果明显低于实验1;
解释:medium-to-large目标在所有目标中的比例为30%左右,完全忽略掉会导致模型对目标的差异性的学习不够充分,比如形状、姿态的变化。相反地,保留这一部分目标的话,虽然模型学的不好,但还是能学到一些信息的,好处>坏处。
- 3.3 数据增强
多尺度训练(Multi-Scale Training)的方法,简称为MST,通常使用全卷积网络,然后用不同分辨率的图像batch来优化模型参数,因此网络可以学习到目标在不同分辨率下的特征,但是对于特别小或者特别大的目标效果也不好。
结果与结论
论文中给出了不同实验的结果,如下图,

为了使检测器的效果更好,要满足两点要求,(1)检测器要学习合理尺寸的目标;(2)检测器要学习目标的差异化,比如目标本身形状、姿态的变化。
网络结构
SNIP,全称为“Scale Normalization for Image Pyramids”,它的结构和MST很相似,但是算是MST的改进版本。与MST类似,它也是把输入图像缩放到不同的尺寸,论文中取了3个尺寸,480 × 800 , 800 × 1200 , 1400 × 2000,对于尺寸为1400 × 2000 的高分辨率图像,作者意识到大目标很难分类,所以只学习small目标(改进点);对于尺寸为480 × 800的低分辨率图像,作者意识到小目标很难分类,所以只学习big目标(改进点);对于尺寸为800 × 1200 800的中等分辨率图像,只学习middle目标(改进点),SNIP整个的网络结构如下图,
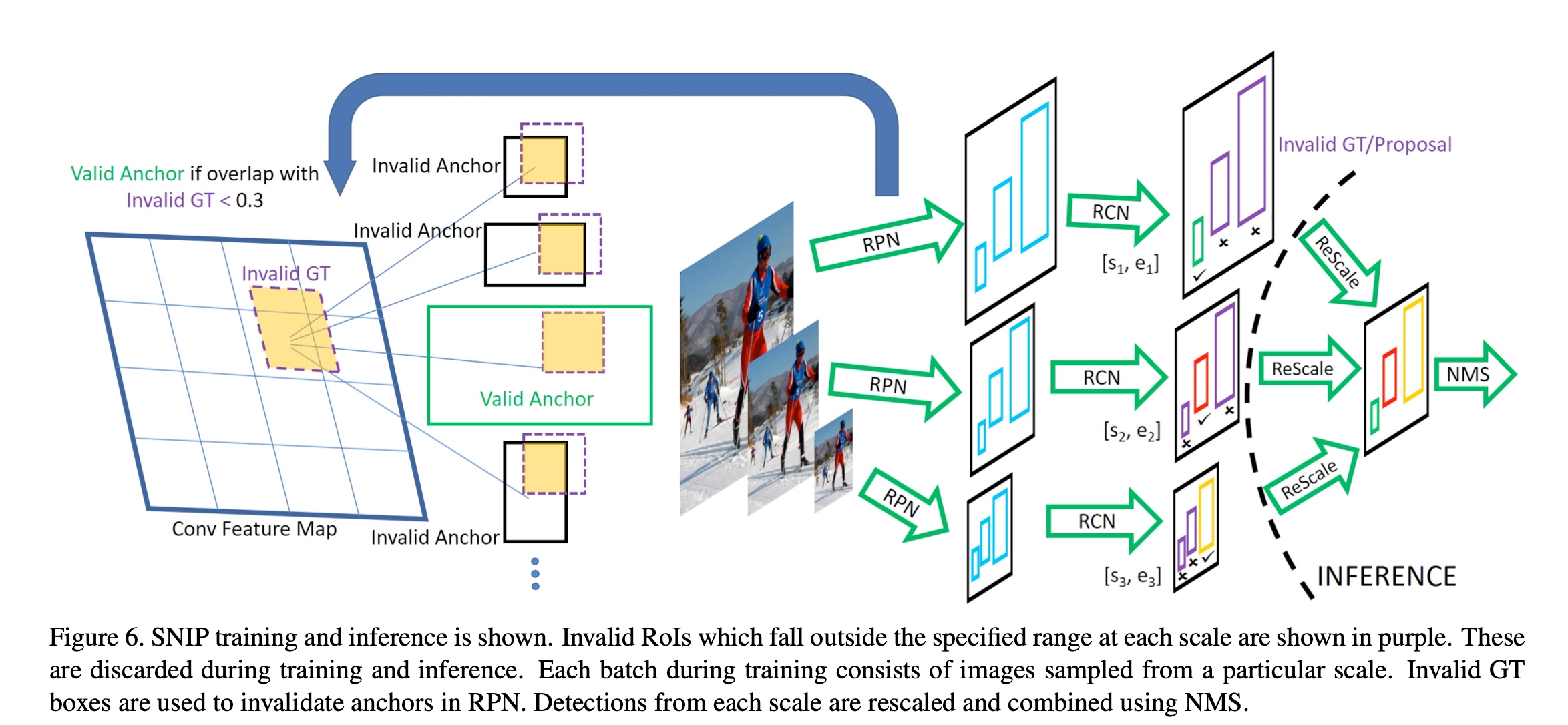
从单一分支维度来看,该分支能够学习合理尺度的目标。从目标尺度的维度来看,SNIP框架能够学习所有尺度的目标,因此保证了3.4.2中提到的两点要求。
Q&A
(1)SNIP结构中的三个分支,是否存在参数共享?
回答:上图中的三个分支的参数是共享的,在训练的时候,每个batch中的数据会缩放到某一个尺寸,比如480 × 800,然后学习该分辨率下的big目标。当训练过程完成时,网络能够学习到所有目标(small、middle、big)的特征了。
(2)Invalid GT和Invalid Anchor怎么定义?
回答:仍然以480 × 800 的训练batch为例,使用阈值 \([s_{3}, e_{3}]\)可以筛选出所有的big目标,这些big目标即为valid GT,其余的middle和small目标为Invalid GT。在RPN网络中,若当前Anchor与所有Invalid GT的IoU小于0.3,则被认为valid anchor(positive sample),否则被认为Invalid anchor(negative sample)。
- 训练与测试分辨率从不一致的时候性能会下降;
- 大分辨率输入图像虽然能提升小目标检测性能,但同时使得大目标过大导致其很难分类,此消彼长,最终精度提升并不明显;
- 多尺度训练(Mutil-Scale training),采样到的图像分辨率很大(1400x2000),导致大目标更大,而图像分辨率过小时(480x640),导致小目标更小,这些均产生了非最优的结果;
- SNIP针对不同分辨率挑选不同的proposal进行梯度传播,然后将其他的设置为0。即针对每一个图像金字塔的每一个尺度进行正则化表示;
总体来说,SNIP让模型更专注于物体本身的检测,剥离了多尺度的学习难题。在网络搭建时,SNIP也使用了类似于MST的多尺度训练方法,构建了3个尺度的图像金字塔,但在训练时,只对指定范围内的Proposal进行反向传播,而忽略掉过大或者过小的Proposal。
SNIP方法虽然实现简单,但其背后却蕴藏深意,更深入地分析了当前检测算法在多尺度检测上的问题所在,在训练时只选择在一定尺度范围内的物体进行学习,在COCO数据集上有3%的检测精度提升,可谓是大道至简。
SNIPER:SNIP方法的改进
SNIPER的关键是减少了SNIP的计算量。SNIP借鉴了multi-scale training的思想进行训练,multi-scale training是用图像金字塔作为模型的输入,这种做法虽然能够提高模型效果,但是计算量的增加也非常明显,因为模型需要处理每个scale图像的每个像素,而SNIPER(Scale Normalization for Image Pyramids with Efficient Resampling)算法以适当的比例处理ground truth(称为chips)周围的上下文区域,在训练期间每个图像生成的chips的数量会根据场景复杂度而自适应地变化,由于SNIPER在采样后的低分辨率的chips上运行,故其可以在训练期间收益于Batch Normalization,而不需要在GPU之间再用同步批量标准化进行统计信息。实验证明,BN有助于最后性能的提升。
这些chips主要分为两大类:
一种是postivice chips,这些chips包含ground truth;
另一种是从RPN网络输出的ROI抽样得到的negative chips,这些chips相当于是难分类的背景,而那些容易分类的背景就没必要进行多尺度训练了。
因此模型最终只处理这些chips,而不是处理整张图像,这样就达到提升效果的同时提升速度。相比于SNIP,基于Faster RCNN(ResNet101作为Backbone)的实验结果显示SNIPER的mAP值比SNIP算法提升了4.6百分点,所以效果也还是非常不错的。在单卡V100上,每秒可以处理5张图像,这个速度在two-stage的算法中来看并不快,但是效果是非常好。
SNIPER的思路:
把图片丢到网络中时,就会产生不同尺度的feature map。作者的想法就是在特征图上的ground truth box周围去crop一些图片,这些图片称为chips。
- 如何选择positive chips : 就是在图像金字塔的每一层中,都设定一个范围,在该大小范围内的目标就可以标出来作为ground truth box,然后对图片中ground truth box所在的地方进行crop,crop出来的图片就是chips。这决定哪些gt目标参与该尺度的训练。在每个尺度贪婪地选择包含gt目标最多的chip作为正chip,每个gt至少在一个chip中(因为范围R有重叠)。

左侧中,绿色框起来的就是ground truth的所在,其他颜色是生成的chips,这张图就生成了4个chips,右侧中绿色线条就是valid box,红色的线就是invalid box。可以看出,合适尺度内的ground truth box就是valid box(蓝色和红色框内绿线),否则就是invalid box(黄色和紫色图中的红线就是invalid)(clip的尺寸要比原图小很多,不然就起不到减少计算量的目的,对于高分辨率的图,clip可以比它小十倍不止)
- 如何选择negative chips : 如果只基于前面的positive chip,那么因为大量的背景区域没有参与训练,所以容易误检(比较高的false positive rate),传统的multi scale训练方式因为有大量的背景区域参与计算,所以误检率没那么高,但因为大部分背景区域都是非常容易分类的,所以这部分计算量是可以避免的,于是就有了negative chip seleciton。选择negative chips的目的在于要让网络更容易去判断出哪些是背景,而不必花费太多的时间在上面。在Faster-RCNN中的RPN的其中一步就是,将anchor和ground truth box交并比小于0.3视为背景,全部去掉(去掉易分样本)。然后剩下的再去掉完全覆盖groun truth box的proposal(去掉易分样本),大部分proposal都是具有假阳性的,也就是和ground truth 都有一部分的交集,但是比较小,我们的negative chips都从这里来。(negative chips就是难分样本)。这样可以用来减少假阳率。

上面一行就是ground truth boxes,下面一行就是作者选择的negative chips,比如最后两个,negative chips都和ground truth box有一定的交集。这就是我们所需要的negative chips。第二行图像中的红色小圆点表示没有被positive chips(Cipos)包含的negative proposals,因为proposals较多,用框画出来的话比较繁杂,所以用红色小圆点表示。橘色框表示基于这些negative proposals生成的negative chips,也就是Cineg。每个negative chip是这么得到的:对于尺度i而言,首先移除包含在Cipos的region proposal,然后在Ri范围内,每个chip都至少选择M个proposal。在训练模型时,每一张图像的每个epoch都处理固定数量的negative chip,这些固定数量的negative chip就是从所有scale的negative chip中抽样得到的。
- 标注label:每一张chip上大概产生300个proposal,但是对这300个proposals不做限制(比如faster-rcnn会滤除掉背景部分,我们不这样),而是对里面的一些proposal抽出来做positive proposal。
- 模型训练:应该是先生成chips,然后再用chips去训练一个端到端的网络,所以其实是分开进行的。
优点
- 确实可以减少计算量;(一张图片可以Crop出5个512x512的chips,而且进行3个尺度的训练,但是它的计算量只比一张800x1333的图片进行单尺度训练多出30%,要是800x1333也进行多尺度训练时,训练量可比这种方法大多了)
- 用固定大小的chips去进行训练时,数据很容易被打包,更利于GPU的使用。(把数据丢到GPU中去训练,这30%的差距算个毛线,GPU计算速度那么大呢)
- 更为重要的是,可以进行多尺度训练,设置更大的batch_size和batch normalization,而且再也不用担心这些操作会拉低我们的速度了!
实验细节:用图像金字塔生成chips的时候,在不同scale的层上使用的ground truth box范围在[0,80²]、[32²,150²]、[120², inf]。训练RPN是为了获取negative chips。每一张图上产生的chips是不同的,如果这张图包含的目标多,产生的chips就会增多,相反则减少。
在SNIP的基础上加了一个「positive/negative chip selection」,从实验结果来看是非常SOTA的,可以说碾压了Mosaic反应出来的结果。另外基于ResNet101的Faster RCNN架构结合SNIPER,精度超过了YOLOV4接近4个点,效果是非常好的。
SSD中的多尺度处理
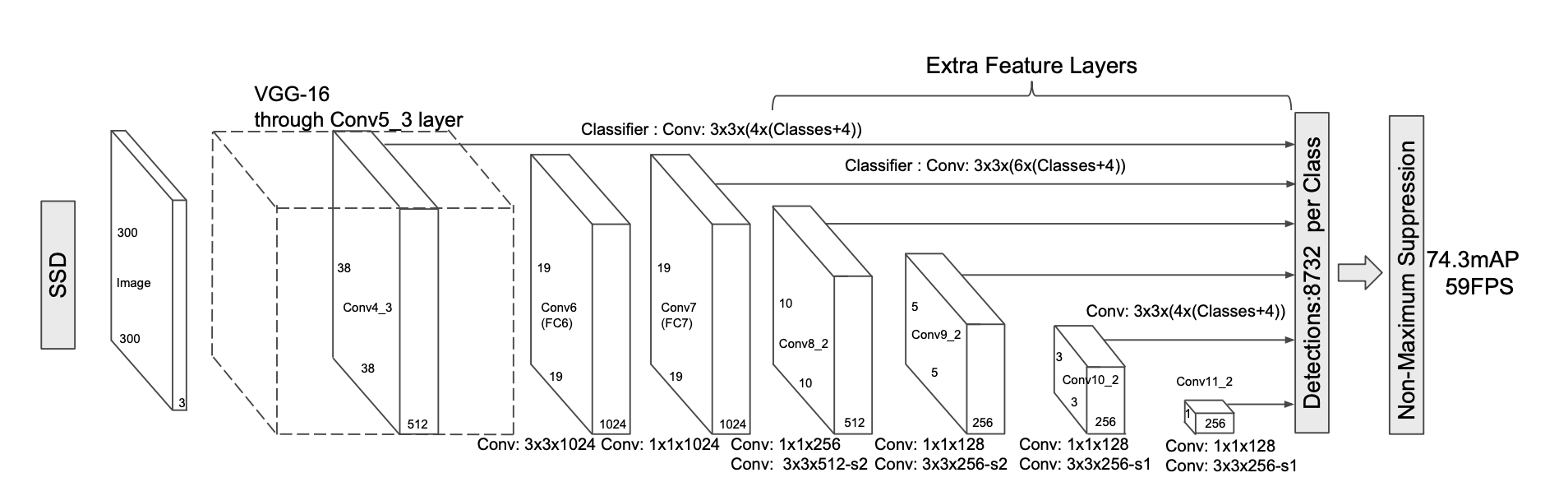
SSD以不同stride的feature map作为检测层分别检测不同尺度的目标,用户可以根据自己的任务的目标尺度制定方案。该方式尺度处理简单有效,但存在一些缺陷:
- 一般使用低层检测小目标,但低层感受野小,上下文信息缺乏,容易引入误检;
- 使用简单的单一检测层多尺度信息略显缺乏,很多任务目标尺度变化范围十分明显;
- 高层虽然感受野较大,但毕竟经过了很多次降采样,大目标的语义信息是否已经丢失;
- 多层特征结构,是非连续的尺度表达,是非最优的结果
空洞卷积处理多尺度
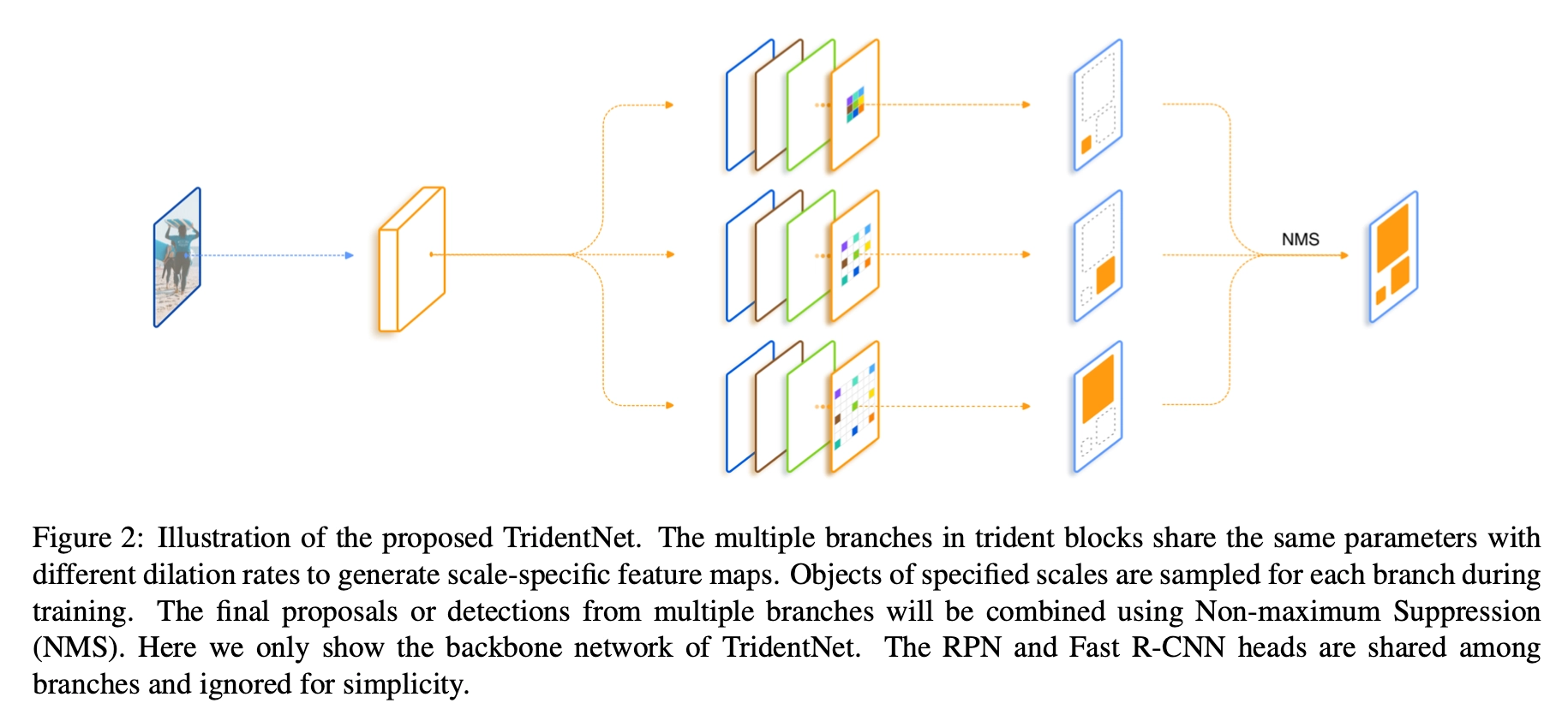
传统的解决多尺度检测的算法,大都依赖于图像金字塔与特征金字塔。与上述算法不同,图森组对感受野这一因素进行了深入的分析,并利用了空洞卷积这一利器,构建了简单的三分支网络TridentNet,对于多尺度物体的检测有了明显的精度提升。
- 控制实验证明了感受野大小与目标尺度呈现正相关;
- 设计三个并行分支获取不同大小的感受野,以分别处理不同尺度的目标,感受野使用空洞卷积表征;每个分支采用Trident block构建,取代ResNet-res4中的多个原始的Block;
- 训练类似于SNIP,三个分支分别采用不同尺度的目标训练。
TridentNet
在正式介绍之前,先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multi-scale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。
另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid。非Deep时代在检测中便有经典的channel feature这样的方法,这个想法在CNN中其实更加直接,因为本身CNN的feature便是分层次的。从开始的MS-CNN直接在不同downsample层上检测大小不同的物体,再到后续TDM和FPN加入了新的top down分支补充底层的语义信息不足,都是延续类似的想法。然而实际上,这样的近似虽然有效,但是仍然性能和image pyramid有较大差距。

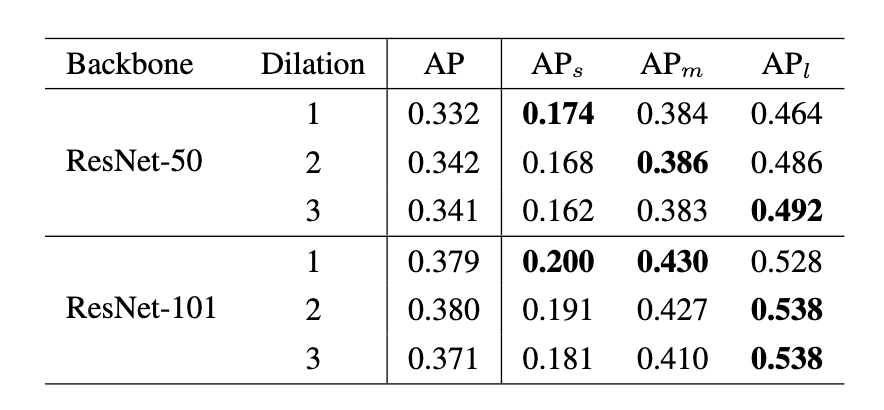
我们考虑对于一个detector本身而言,backbone有哪些因素会影响性能。总结下来,无外乎三点:network depth(structure),downsample rate和receptive field。对于前两者而言,其影响一般来说是比较明确的,即网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。但是没有工作,单独分离出receptive field,保持其他变量不变,来验证它对detector性能的影响。所以,我们做了一个验证性实验,分别使用ResNet50和ResNet101作为backbone,改变最后一个stage中每个3*3 conv的dilation rate。通过这样的方法,我们便可以固定同样的网络结构,同样的参数量以及同样的downsample rate,只改变网络的receptive field。我们很惊奇地发现,不同尺度物体的检测性能和dilation rate正相关!也就是说,更大的receptive field对于大物体性能会更好,更小的receptive field对于小物体更加友好。于是下面的问题就变成了,我们有没有办法把不同receptive field的优点结合在一起呢?
所以我们最开始的一个想法便是直接加入几支并行,但是dilation rate不同的分支,在文中我们把每一个这样的结构叫做trident block。这样一个简单的想法已经可以带来相当可观的性能提升。我们进一步考虑我们希望这三支的区别应该仅仅在于receptive field,它们要检测的物体类别,要对特征做的变换应该都是一致的。所以自然而然地想到我们对于并行的这几支可以share weight。 一方面是减少了参数量以及潜在的overfitting风险,另一方面充分利用了每个样本,同样一套参数在不同dilation rate下训练了不同scale的样本。最后一个设计则是借鉴SNIP,为了避免receptive field和scale不匹配的情况,我们对于每一个branch只训练一定范围内样本,避免极端scale的物体对于性能的影响。总结一下,我们的TridentNet在原始的backbone上做了三点变化:
- 第一点是构造了不同receptive field的parallel multi-branch,
- 第二点是对于trident block中每一个branch的weight是share的。
- 第三点是对于每个branch,训练和测试都只负责一定尺度范围内的样本,也就是所谓的scale-aware。这三点在任何一个深度学习框架中都是非常容易实现的。
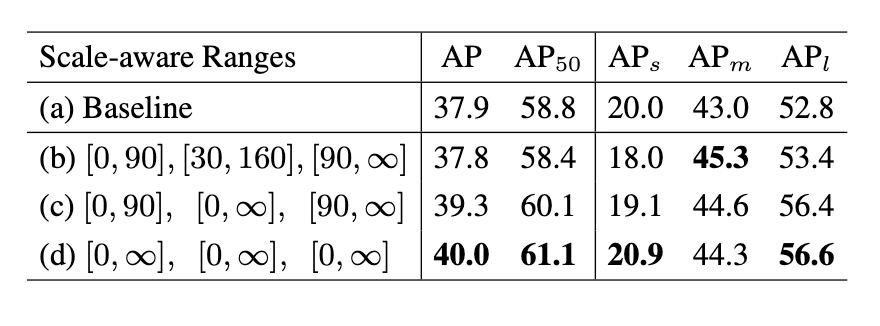
在测试阶段,我们可以只保留一个branch来近似完整TridentNet的结果,后面我们做了充分的对比实验来寻找了这样single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1点map,但是和baseline比起来不会引入任何额外的计算和参数。
一个值得一提的ablation是,对于我们上面提出的single branch approximation,我们如何选择合适的scale-aware training参数使得近似的效果最好。其实我们发现很有趣的一点是,如果采用single branch近似的话,那么所有样本在所有branch都训练结果最好。这一点其实也符合预期,因为最后只保留一支的话那么参数最好在所有样本上所有scale上充分训练。如果和上文40.6的baseline比较,可以发现我们single branch的结果比full TridentNet只有0.6 map的下降。
这也意味着我们在不增加任何计算量和参数的情况,仍然获得2.1 map的提升。
这对于实际产品中使用的detector而言无疑是个福音。
FPN中的多尺度处理及其改进
自从2016年FPN网络出来后,目前各大视觉任务的baseline基本都是以backbone-FPN。FPN以更为轻量的最近邻插值结合侧向连接实现了将高层的语义信息逐渐传播到低层的功能,使得尺度更为平滑,同时它可以看做是轻量级的decoder结构。FPN看起来很完美,但仍然有一些缺陷:
- 在上采样时使用了比较粗糙的最近邻插值,使得高层的语义信息不一定能有效传播;
- 由于经过多次下采样,最高层的感受野虽然很丰富,但可能已经丢失了小目标的语义信息,这样的传播是否还合适;
- FPN的构建只使用了backbone的4个stage的输出,其输出的多尺度信息不一定足够;
- FPN中虽然传播了强的语义信息到其他层,但对于不同尺度的表达能力仍然是不一样的,因为本身就提取了不同backbone的输出。
ThunderNet
ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自Light-Head R-CNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。
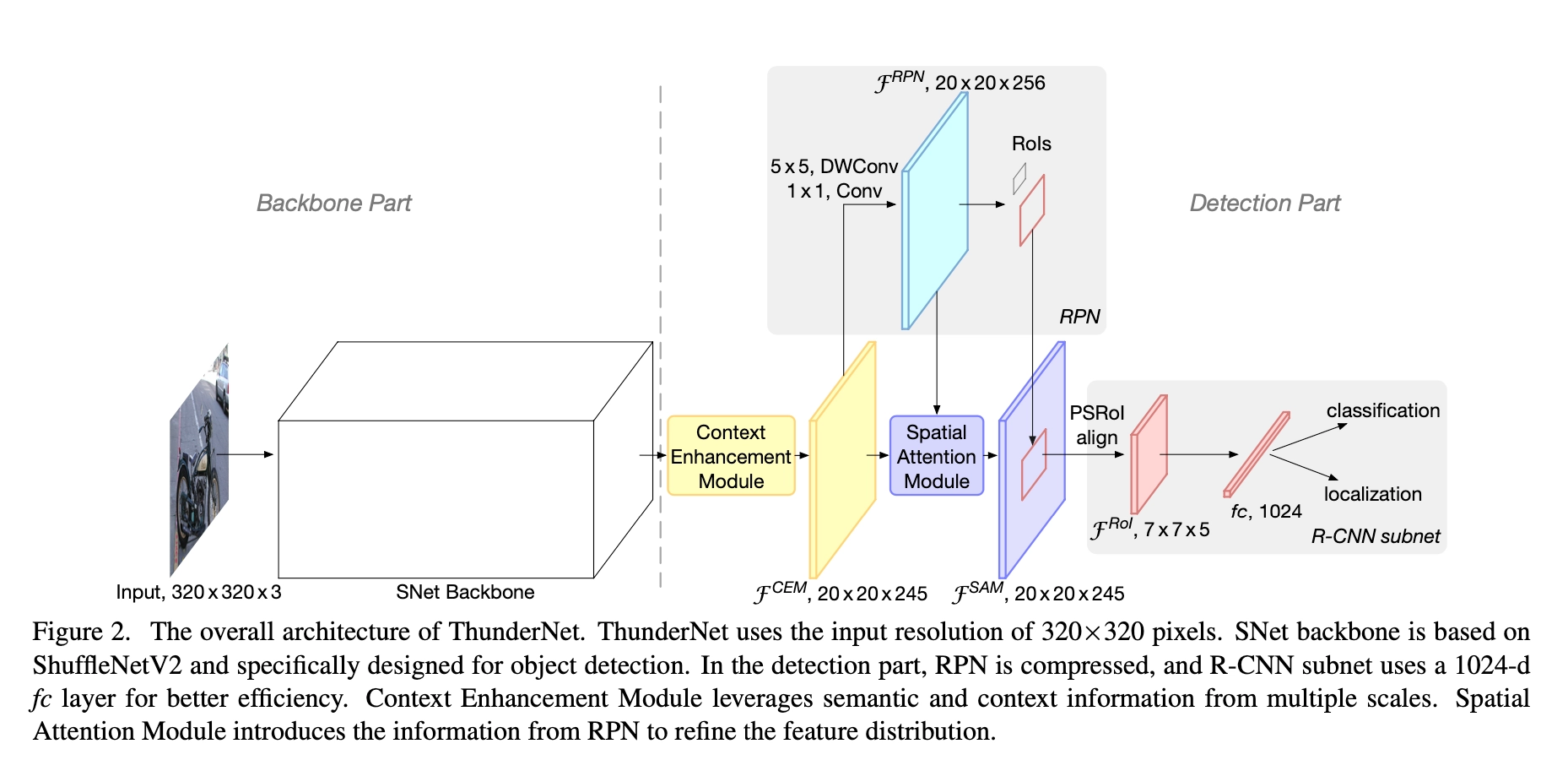
backbone 部分
- 输入分辨率 为了加快推理(前向操作)速度,作者使用320*320大小的输入图像。需要注意的是,在实践中,我们观察到输入分辨率应该与骨干网络的能力相匹配。 具有大输入的小骨干和具有小输入的大骨干都不是最佳的选择。
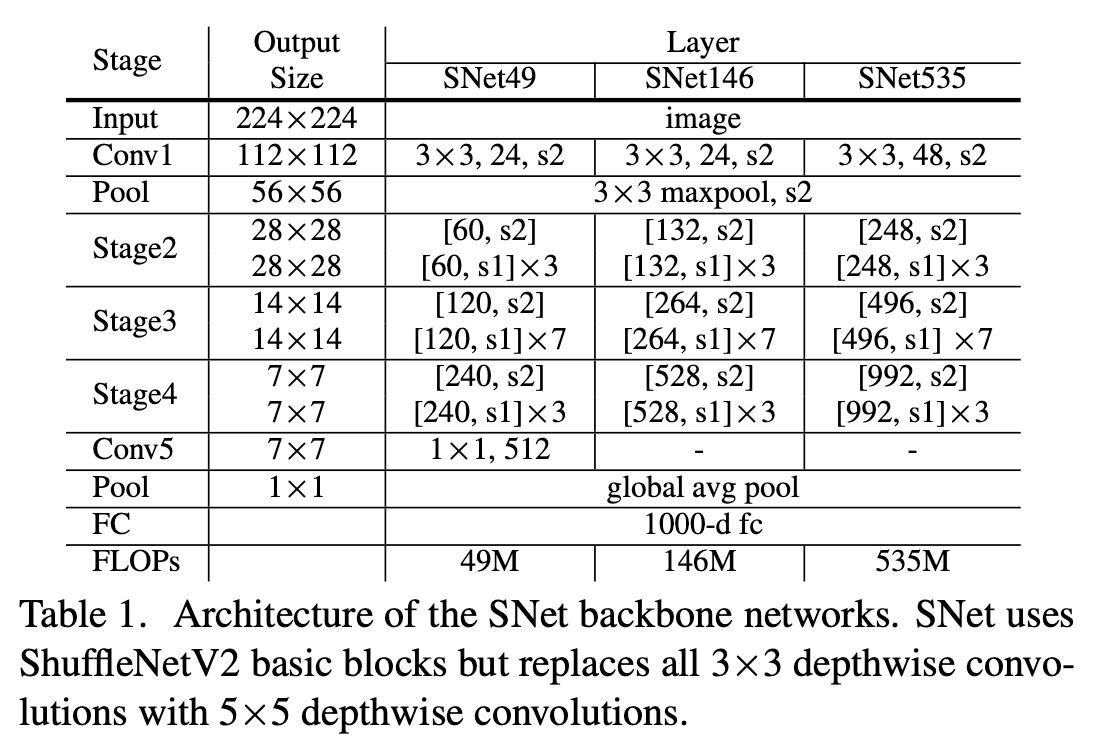
- 骨干网络(backbone) 需要具有两大特点,第一:大的感受野很重要。第二:浅层特征位置信息丰富,深层特征区分度更大,因此需要兼顾这两种特征。而作者认为主流的轻量级网络违法了上述原则,比如ShuffleNetV1/V2限制了感受野。ShuffleNetV2 和MobileNetV2 缺乏浅层特征,而Xception 在计算预算低下的情况下缺乏深层特征。
基于上述原因,作者在ShufflenetV2的基准下,结合上述特性对ShufflenetV2进行修改并命名为SNet。如下图所示,作者给出了集中不同形式的SNet网络。
Detection 部分
检测部分沿用了Light-Head R-CNN网络的结构,虽然该网络使用轻量级的检测器,但当与上述的SNet这个更轻量级的骨干网络耦合时它仍然太重,并且会引起骨干网络和检测器之间的不平衡。 这种不平衡不仅导致冗余计算,而且增加了过度拟合的风险。上述骨干网络部分中输入分辨率不匹配也会导致类似问题。 为了解决这个问题,作者使用一个5×5的深度可分离卷积(mobilenetv1中)和1×1卷积,替换原始RPN网络中的3×3的卷积。并且在RPN网络中使用的尺度大小为{32×32,64×64,128×128,256×256,512×512},anchor的长宽比为{1:2,3:4,1:1,4:3,2:1}。其余参数和Light-Head R-CNN中的一致。检测部分主要的创新点是,提出了Context Enhancement Module和Spatial Attention Module这两种策略。
Context Enhancement Module
Light-Head R-CNN网络中在骨干网络之后利用GCN:Global Convolutional Network产生更小的特征图,这虽然增加了感受野但却提升了计算复杂度,因此在本文提出的网络中没有使用GCN。然而,感受野小且在没有GCN的情况下网络很难提取到足够的可分辨的特征信息。 为了解决这个问题,本文使用了特征金字塔网络(FPN)。 然而,原始的FPN结构涉及许多额外的卷积和多个检测分支,这增加了计算成本并且引起了巨大的运行时间延迟。因此,基于FPN,本文提出了Context Enhancement Module (CEM),示意图如下。
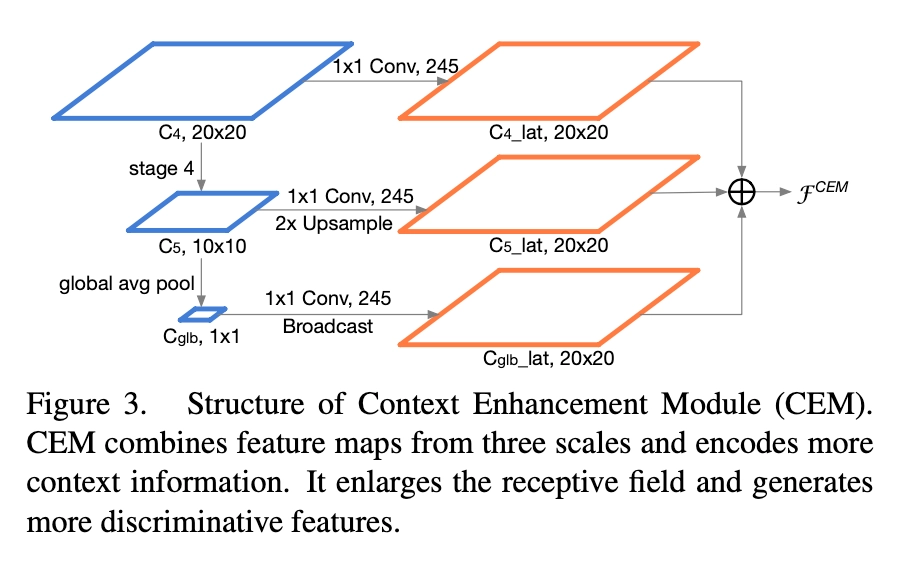
CEM的关键思想是聚合多尺度局部信息和全局信息,以生成区分性更强的特征。在CEM中,合并三个尺度的特征图:C4,C5和Cglb(在C5上应用全局平均池化得到Cglb作为全局特征信息)。
- 尺度一:C4特征图上应用1×1卷积以将通道数量压缩为α×p×p = 245
- 尺度二:C5进行上采样 + C5特征图上应用1×1卷积以将通道数量压缩为α×p×p = 245
- 尺度三:Cglb进行Broadcast + Cglb特征图上应用1×1卷积以将通道数量压缩为α×p×p = 245 。
通过利用局部和全局信息,CEM有效地扩大了感受野,并细化了薄特征图的表示能力。与先前的FPN结构相比,CEM仅涉及两个1×1卷积和fc层,这更加计算友好。
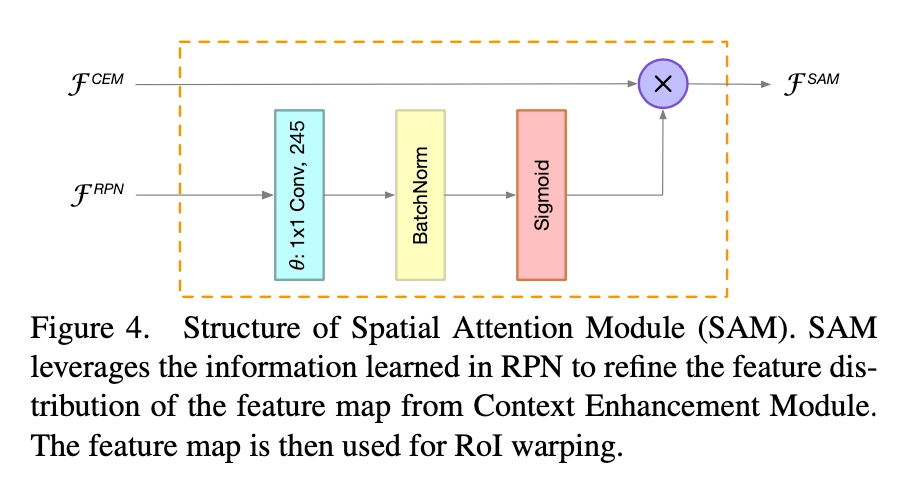
Spatial Attention Module
在进行RoI操作的时候,我们期望背景区域中的特征不被关注,且前景物体的特征被强烈关注。 然而,由于本文的检测网络利用的是轻量级骨干网络和小分辨率输入图像,因此很难学习到正确的特征分布。出于这个原因,作者设计了一个计算友好的空间注意模块(SAM),以便在RoI扭曲空间维度之前显式地重新加权特征图,引导网络学习到正确的前景背景特征分布。SAM的关键思想是使用来自RPN学习到的知识来细化特征图的特征分布。因为训练RPN网络时,网络就是以前景目标作为监督来训练的。 因此,RPN网络可以用于区分前景特征和背景特征。
SAM有两个输入,分别来自于CEM和RPN,而输出如下公式所示:
这里\(θ(·)\)是一个尺寸变换,以匹配两组特征图中的通道数。 sigmoid函数用于约束[0,1]内的值。 最后,通过生成的特征映射对,使得CEM进行重新加权,以获得更好的特征分布。 为了计算效率,我们将1×1卷积应用于\(θ(·)\),因此CEM的计算成本可以忽略不计。 如下图所示,显示了SAM的结构。
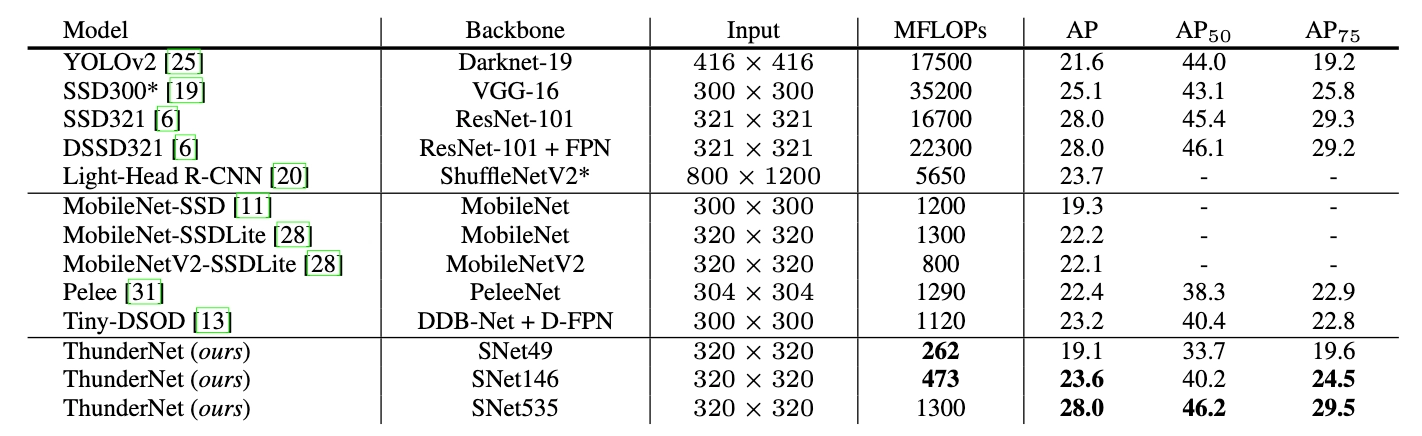
实验
VOC 2007测试的评估结果。 ThunderNet以更低的计算成本超越竞争模型
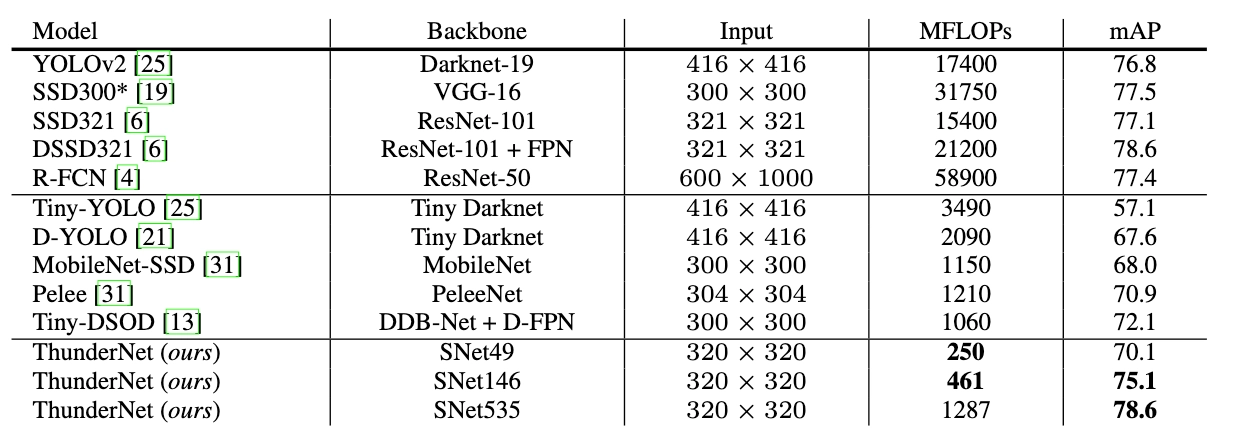
COCO test-dev的评估结果。 采用SNet49的ThunderNet实现了MobileNet-SSD级精度,确快将近五倍。 采用SNet146的ThunderNet与轻型one-stage检测网络相比,具有更高的精度。 采用SNet535的ThunderNet可与大型检测网络相媲美,计算成本显着降低。