SD模型原理
SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。
SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。

基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。文生图模型往往参数量比较大,基于pixel的方法往往限于算力只生成64x64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256x256和1024x1024;而基于latent的SD是在latent空间操作的,它可以直接生成256x256和512x512甚至更高分辨率的图像。
SD模型的主体结构如下图所示,主要包括三个模型:
- autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像;
- CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;
- UNet:扩散模型的主体,用来实现文本引导下的latent生成。
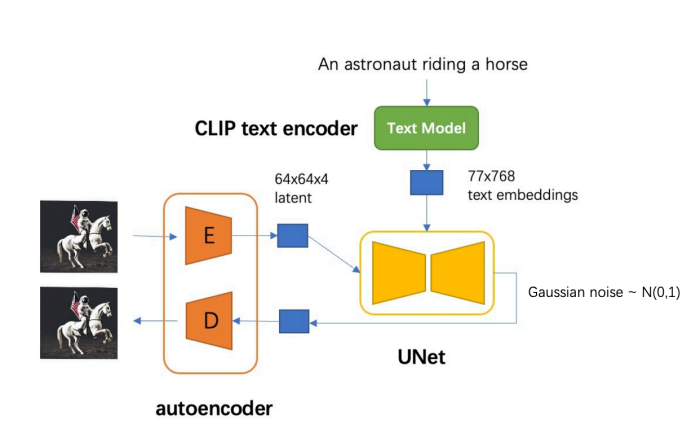
对于SD模型,其autoencoder模型参数大小为84M,CLIP text encoder模型大小为123M,而UNet参数大小为860M,所以SD模型的总参数量约为1B。
autoencoder
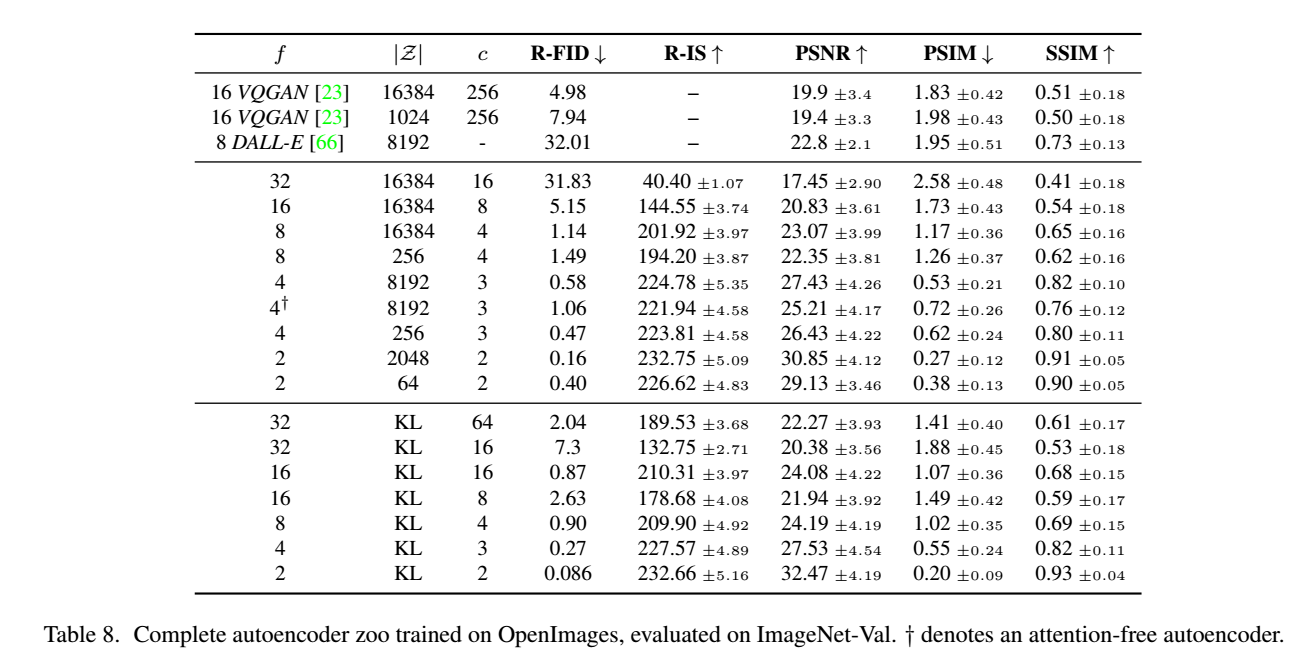
autoencoder是一个基于encoder-decoder架构的图像压缩模型,对于一个大小为\(H\times W \times 3\) 的输入图像,encoder模块将其编码为一个大小为 \(h\times w \times c\) 的latent,其中 \(f=H/h=W/w\) 为下采样率(downsampling factor)。在训练autoencoder过程中,除了采用L1 重建损失外,还增加了感知损失(perceptual loss,即LPIPS,具体见论文The Unreasonable Effectiveness of Deep Features as a Perceptual Metric)以及基于patch的对抗训练。辅助loss主要是为了确保重建的图像局部真实性以及避免模糊,具体损失函数见latent diffusion的loss部分。同时为了防止得到的latent的标准差过大,采用了两种正则化方法:第一种是KL-reg,类似VAE增加一个latent和标准正态分布的KL loss,不过这里为了保证重建效果,采用比较小的权重(~10e-6);第二种是VQ-reg,引入一个VQ (vector quantization)layer,此时的模型可以看成是一个VQ-GAN,不过VQ层是在decoder模块中,这里VQ的codebook采样较高的维度(8192)来降低正则化对重建效果的影响。 latent diffusion论文中实验了不同参数下的autoencoder模型,如下表所示,可以看到当\( f\) 较小和 \(c\) 较大时,重建效果越好(PSNR越大),这也比较符合预期,毕竟此时压缩率小。
论文进一步将不同\(f\) 的autoencoder在扩散模型上进行实验,在ImageNet数据集上训练同样的步数(2M steps),其训练过程的生成质量如下所示,可以看到过小的 \(f\)(比如1和2)下收敛速度慢,此时图像的感知压缩率较小,扩散模型需要较长的学习;而过大的 \(f\) 其生成质量较差,此时压缩损失过大。
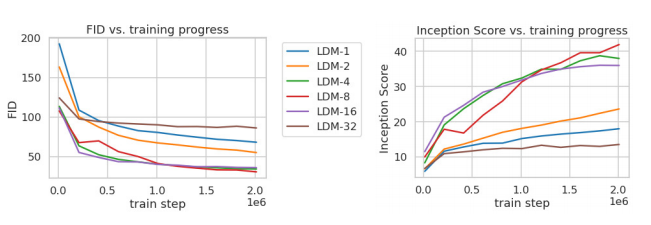
当 \(f\) 在4~16时,可以取得相对好的效果。SD采用基于KL-reg的autoencoder,其中下采样率 \(f=8\)
,特征维度为\(c=4\),当输入图像为512x512大小时将得到64x64x4大小的latent。 autoencoder模型时在OpenImages数据集上基于256x256大小训练的,但是由于autoencoder的模型是全卷积结构的(基于ResnetBlock,只有模型的中间存在两个self attention层),所以它可以扩展应用在尺寸>256的图像上。下面我们给出使用diffusers库来加载autoencoder模型,并使用autoencoder来实现图像的压缩和重建,代码如下所示:
import torch
from diffusers import AutoencoderKL
import numpy as np
from PIL import Image
#加载模型: autoencoder可以通过SD权重指定subfolder来单独加载
autoencoder = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
autoencoder.to("cuda", dtype=torch.float16)
# 读取图像并预处理
raw_image = Image.open("boy.png").convert("RGB").resize((256, 256))
image = np.array(raw_image).astype(np.float32) / 127.5 - 1.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
# 压缩图像为latent并重建
with torch.inference_mode():
latent = autoencoder.encode(image.to("cuda", dtype=torch.float16)).latent_dist.sample()
rec_image = autoencoder.decode(latent).sample
rec_image = (rec_image / 2 + 0.5).clamp(0, 1)
rec_image = rec_image.cpu().permute(0, 2, 3, 1).numpy()
rec_image = (rec_image * 255).round().astype("uint8")
rec_image = Image.fromarray(rec_image[0])这种有损压缩肯定是对SD的生成图像质量是有一定影响的,不过好在SD模型基本上是在512x512以上分辨率下使用的。为了改善这种畸变,stabilityai在发布SD 2.0时同时发布了两个在LAION子数据集上精调的autoencoder,注意这里只精调autoencoder的decoder部分,SD的UNet在训练过程只需要encoder部分,所以这样精调后的autoencoder可以直接用在先前训练好的UNet上(这种技巧还是比较通用的,比如谷歌的Parti也是在训练好后自回归生成模型后,扩大并精调ViT-VQGAN的decoder模块来提升生成质量)。我们也可以直接在diffusers中使用这些autoencoder,比如mse版本(采用mse损失来finetune的模型):autoencoder=AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse/“)
由于SD采用的autoencoder是基于KL-reg的,所以这个autoencoder在编码图像时其实得到的是一个高斯分布DiagonalGaussianDistribution(分布的均值和标准差),然后通过调用sample方法来采样一个具体的latent(调用mode方法可以得到均值)。由于KL-reg的权重系数非常小,实际得到latent的标准差还是比较大的,latent diffusion论文中提出了一种rescaling方法:首先计算出第一个batch数据中的latent的标准差 \(\hat \sigma\),然后采用 \(1/\hat \sigma\) 的系数来rescale latent,这样就尽量保证latent的标准差接近1(防止扩散过程的SNR较高,影响生成效果,具体见latent diffusion论文的D1部分讨论),然后扩散模型也是应用在rescaling的latent上,在解码时只需要将生成的latent除以\(1/\hat \sigma\),然后再送入autoencoder的decoder即可。对于SD所使用的autoencoder,这个rescaling系数为0.18215。
CLIP text encoder
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。在transofmers库中,可以如下使用CLIP text encoder:
from transformers import CLIPTextModel, CLIPTokenizer
text_encoder = CLIPTextModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="text_encoder").to("cuda")
# text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda")
tokenizer = CLIPTokenizer.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="tokenizer")
# tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
# 对输入的text进行tokenize,得到对应的token ids
prompt = "a photograph of an astronaut riding a horse"
text_input_ids = text_tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
).input_ids
# 将token ids送入text model得到77x768的特征
text_embeddings = text_encoder(text_input_ids.to("cuda"))[0]值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。 在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
UNet
SD的扩散模型是一个860M的UNet,其主要结构如下图所示(这里以输入的latent为64x64x4维度为例),其中encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,而decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,中间还有一个UNetMidBlock2DCrossAttn模块。encoder和decoder两个部分是完全对应的,中间存在skip connection。注意3个CrossAttnDownBlock2D模块最后均有一个2x的downsample操作,而DownBlock2D模块是不包含下采样的。

其中CrossAttnDownBlock2D模块的主要结构如下图所示,text condition将通过CrossAttention模块嵌入进来,此时Attention的query是UNet的中间特征,而key和value则是text embeddings。 CrossAttnUpBlock2D模块和CrossAttnDownBlock2D模块是一致的,但是就是总层数为3。

SD和DDPM一样采用预测noise的方法来训练UNet,其训练损失也和DDPM一样:
这里的 \(c\) 为text embeddings,此时的模型是一个条件扩散模型。基于diffusers库,我们可以很快实现SD的训练,其核心代码如下所示(这里参考diffusers库下examples中的finetune代码):
import torch
from diffusers import AutoencoderKL, UNet2DConditionModel, DDPMScheduler
from transformers import CLIPTextModel, CLIPTokenizer
import torch.nn.functional as F
# 加载autoencoder
vae = AutoencoderKL.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="vae")
# 加载text encoder
text_encoder = CLIPTextModel.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="text_encoder")
tokenizer = CLIPTokenizer.from_pretrained("runwayml/stable-diffusion-v1-5", subfolder="tokenizer")
# 初始化UNet
unet = UNet2DConditionModel(**model_config) # model_config为模型参数配置
# 定义scheduler
noise_scheduler = DDPMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
)
# 冻结vae和text_encoder
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
opt = torch.optim.AdamW(unet.parameters(), lr=1e-4)
for step, batch in enumerate(train_dataloader):
with torch.no_grad():
# 将image转到latent空间
latents = vae.encode(batch["image"]).latent_dist.sample()
latents = latents * vae.config.scaling_factor # rescaling latents
# 提取text embeddings
text_input_ids = text_tokenizer(
batch["text"],
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
).input_ids
text_embeddings = text_encoder(text_input_ids)[0]
# 随机采样噪音
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# 随机采样timestep
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# 将noise添加到latent上,即扩散过程
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# 预测noise并计算loss
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states=text_embeddings).sample
loss = F.mse_loss(model_pred.float(), noise.float(), reduction="mean")
opt.step()
opt.zero_grad()注意的是SD的noise scheduler虽然也是采用一个1000步长的scheduler,但是不是linear的,而是scaled linear,具体的计算如下所示:
betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2在训练条件扩散模型时,往往会采用Classifier-Free Guidance(这里简称为CFG),所谓的CFG简单来说就是在训练条件扩散模型的同时也训练一个无条件的扩散模型,同时在采样阶段将条件控制下预测的噪音和无条件下的预测噪音组合在一起来确定最终的噪音,具体的计算公式如下所示:
这里的\(w\) 为guidance scale,当\(w\) 越大时,condition起的作用越大,即生成的图像其更和输入文本一致。CFG的具体实现非常简单,在训练过程中,我们只需要 以一定的概率(比如10%)随机drop掉text即可,这里我们可以将text置为空字符串(前面说过此时依然能够提取text embeddings)。这里并没有介绍CLF背后的技术原理,感兴趣的可以阅读CFG的论文Classifier-Free Diffusion Guidance以及guided diffusion的论文Diffusion Models Beat GANs on Image Synthesis。CFG对于提升条件扩散模型的图像生成效果是至关重要的。
训练细节
前面我们介绍了SD的模型结构,这里我们也简单介绍一下SD的训练细节,主要包括训练数据和训练资源,这方面也是在SD的Model Card上有说明。 首先是训练数据,SD在laion2B-en数据集上训练的,它是laion-5b数据集的一个子集,更具体的说它是laion-5b中的英文(文本为英文)数据集。laion-5b数据集是从网页数据Common Crawl中筛选出来的图像-文本对数据集,它包含5.85B的图像-文本对,其中文本为英文的数据量为2.32B,这就是laion2B-en数据集。
下面是laion2B-en数据集的元信息(图片width和height,以及文本长度)统计分析:其中图片的width和height均在256以上的样本量为1324M,在512以上的样本量为488M,而在1024以上的样本为76M;文本的平均长度为67。
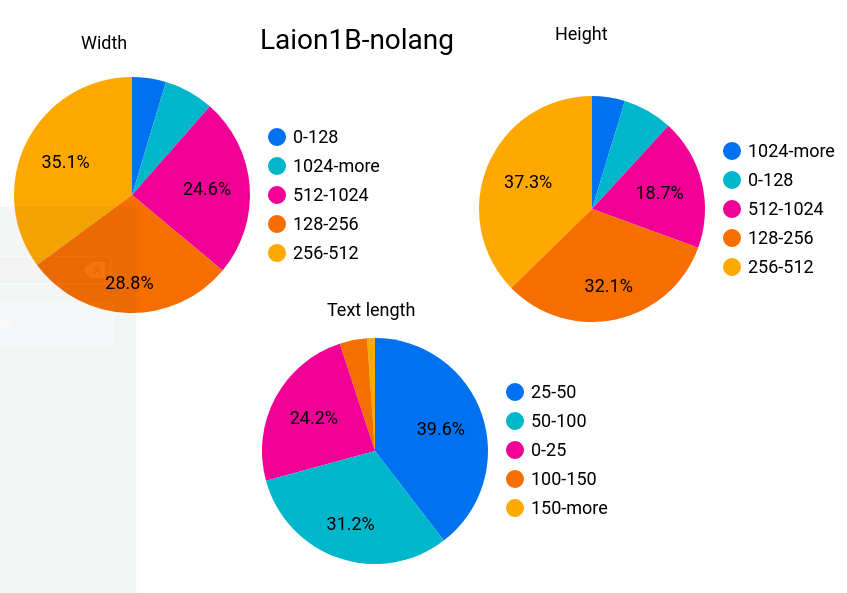
laion数据集中除了图片(下载URL,图像width和height)和文本(描述文本)的元信息外,还包含以下信息:
- similarity:使用CLIP ViT-B/32计算出来的图像和文本余弦相似度;
- pwatermark:使用一个图片水印检测器检测的概率值,表示图片含有水印的概率;
- punsafe:图片是否安全,或者图片是不是NSFW,使用基于CLIP的检测器来估计;
- AESTHETIC_SCORE:图片的美学评分(1-10),这个是后来追加的,首先选择一小部分图片数据集让人对图片的美学打分,然后基于这个标注数据集来训练一个打分模型,并对所有样本计算估计的美学评分。
上面是laion数据集的情况,下面我们来介绍SD训练数据集的具体情况,SD的训练是多阶段的(先在256x256尺寸上预训练,然后在512x512尺寸上精调),不同的阶段产生了不同的版本:
- SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。 SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),所需要的训练硬件还是比较多的,但是相比语言大模型还好。单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
模型评测
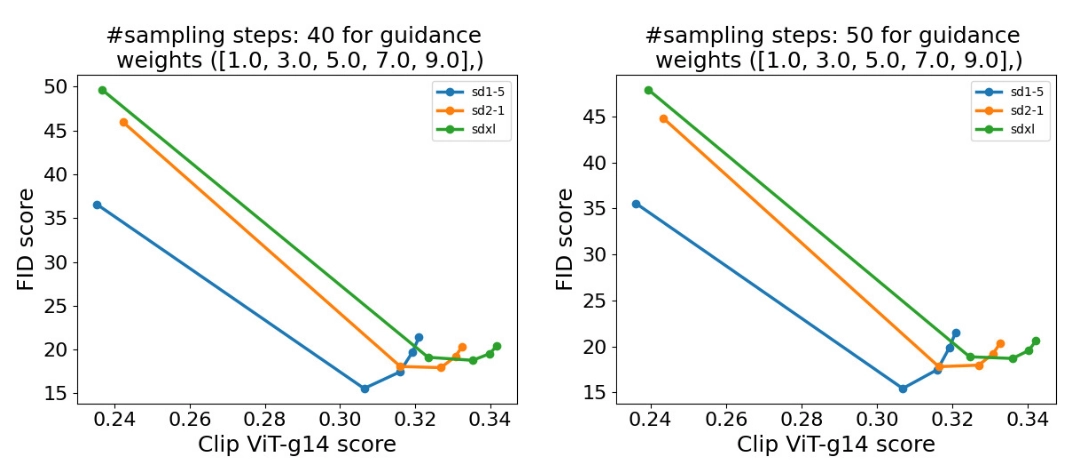
上面介绍了模型训练细节,那么最后的问题就是模型评测了。对于文生图模型,目前常采用的定量指标是FID(Fréchet inception distance)和CLIP score,其中FID可以衡量生成图像的逼真度(image fidelity),而CLIP score评测的是生成的图像与输入文本的一致性,其中FID越低越好,而CLIP score是越大越好。当CFG的gudiance scale参数设置不同时,FID和CLIP score会发生变化,下图为不同的gudiance scale参数下,SD模型在COCO2017验证集上的评测结果,注意这里是zero-shot评测,即SD模型并没有在COCO训练数据集上精调。
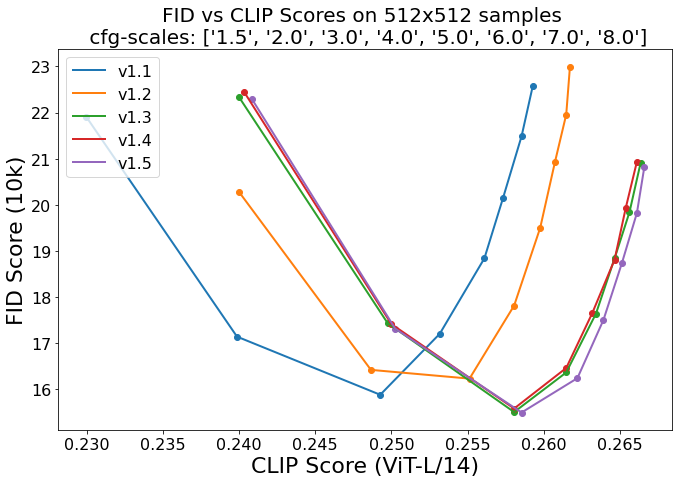
可以看到当gudiance scale=3时,FID最低;而当gudiance scale越大时,CLIP score越大,但是FID同时也变大。在实际应用时,往往会采用较大的gudiance scale,比如SD模型默认采用7.5,此时生成的图像和文本有较好的一致性。从不同版本的对比曲线上看,SD的采用CFG训练后三个版本其实差别并没有那么大,其中SD v1.5相对好一点,但是明显要比未采用CFG训练的版本要好的多,这说明CFG训练是比较关键的。 目前在模型对比上,大家往往是比较不同模型在COCO验证集上的zero-shot FID-30K(选择30K的样本),大家往往就选择模型所能得到的最小FID来比较,下面为eDiff和GigaGAN两篇论文所报道的不同文生图模型的FID对比(由于SD并没有给出FID-30K,所以大家应该都是自己用开源SD的模型计算的,由于选择样本不同,可能结果存在差异):
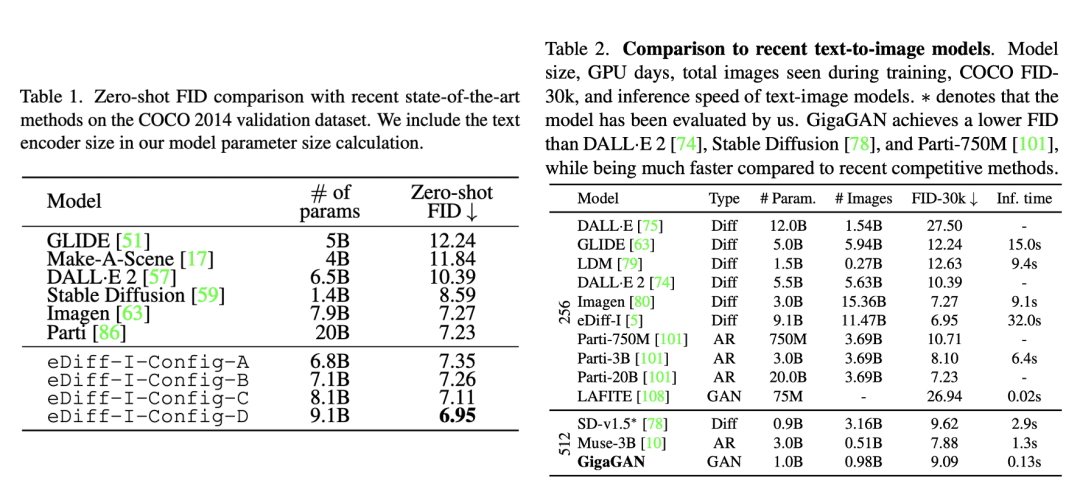
可以看到SD虽然FID不是最好的,但是也能达到比较低的FID(大约在8~9之间)。不过虽然学术界常采用FID来定量比较模型,但是FID有很大的局限性,它并不能很好地衡量生成图像的质量,也是因为这个原因,谷歌的Imagen引入了人工评价,先建立一个评测数据集DrawBench(包含200个不同类型的text),然后用不同的模型来生成图像,让人去评价同一个text下不同模型生成的图像,这种评测方式比较直接,但是可能也受一些主观因素的影响。总而言之,目前的评价方式都有一定的局限性,最好还是直接上手使用来比较不同的模型。
SD 2.0
SD 2.0
Stability AI公司在2022年11月(stable-diffusion-v2-release)放出了SD 2.0版本,这里我们也简单介绍一下相比SD 1.x版本SD 2.0的具体改进点。SD 2.0相比SD 1.x版本的主要变动在于模型结构和训练数据两个部分。

首先是模型结构方面,SD 1.x版本的text encoder采用的是OpenAI的CLIP ViT-L/14模型,其模型参数量为123.65M;而SD 2.0采用了更大的text encoder:基于OpenCLIP在laion-2b数据集上训练的CLIP ViT-H/14模型,其参数量为354.03M,相比原来的text encoder模型大了约3倍。两个CLIP模型的对比如下所示:
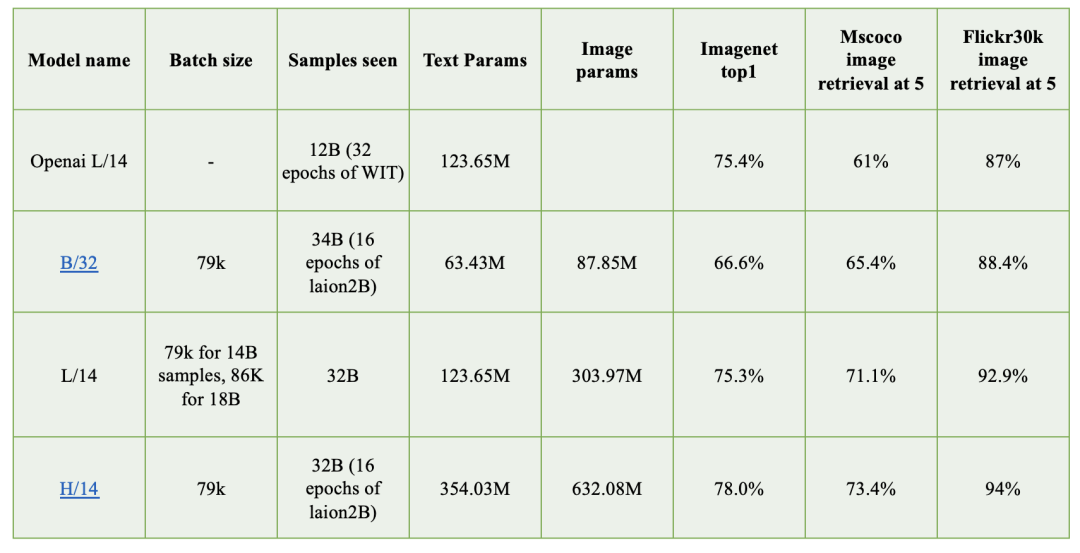
可以看到CLIP ViT-H/14模型相比原来的OpenAI的L/14模型,在imagenet1K上分类准确率和mscoco多模态检索任务上均有明显的提升,这也意味着对应的text encoder更强,能够抓住更准确的文本语义信息。另外是一个小细节是SD 2.0提取的是text encoder倒数第二层的特征,而SD 1.x提取的是倒数第一层的特征。由于倒数第一层的特征之后就是CLIP的对比学习任务,所以倒数第一层的特征可能部分丢失细粒度语义信息,Imagen论文(见论文D.1部分)和novelai(见novelai blog)均采用了倒数第二层特征。对于UNet模型,SD 2.0相比SD 1.x几乎没有改变,就是由于换了CLIP模型,cross attention dimension从原来的768变成了1024,这个导致参数量有轻微变化。另外一个小的变动是:SD 2.0不同stage的attention模块是固定attention head dim为64,而SD 1.0则是不同stage的attention模块采用固定attention head数量,明显SD 2.0的这种设定更常用,但是这个变动不会影响模型参数。 然后是训练数据,前面说过SD 1.x版本其实最后主要采用laion-2B中美学评分为5以上的子集来训练,而SD 2.0版本采用评分在4.5以上的子集,相当于扩大了训练数据集,具体的训练细节见model card。 另外SD 2.0除了512x512版本的模型,还包括768x768版本的模型(https://huggingface.co/stabilityai/stable-diffusion-2),所谓的768x768模型是在512x512模型基础上用图像分辨率大于768x768的子集继续训练的,不过优化目标不再是noise_prediction,而是采用Progressive Distillation for Fast Sampling of Diffusion Models论文中所提出的 v-objective。 下图为SD 2.0和SD 1.x版本在COCO2017验证集上评测的对比,可以看到2.0相比1.5,CLIP score有一个明显的提升,同时FID也有一定的提升。但是正如前面所讨论的,FID和CLIP score这两个指标均有一定的局限性,所以具体效果还是上手使用来对比。
Stability AI在发布SD 2.0的同时,还发布了另外3个模型:stable-diffusion-x4-upscaler,stable-diffusion-2-inpainting和stable-diffusion-2-depth。 stable-diffusion-x4-upscaler是一个基于扩散模型的4x超分模型,它也是基于latent diffusion,不过这里采用的autoencoder是基于VQ-reg的,下采样率为\(f=4\)。在实现上,它是将低分辨率图像直接和noisy latent拼接在一起送入UNet,因为autoencoder将高分辨率图像压缩为原来的1/4,而低分辨率图像也为高分辨率图像的1/4,所以低分辨率图像的空间维度和latent是一致的。另外,这个超分模型也采用了Cascaded Diffusion Models for High Fidelity Image Generation所提出的noise conditioning augmentation,简单来说就是在训练过程中给低分辨率图像加上高斯噪音,可以通过扩散过程来实现,注意这里的扩散过程的scheduler与主扩散模型的scheduler可以不一样,同时也将对应的noise_level(对应扩散模型的time step)通过class labels的方式送入UNet,让UNet知道加入噪音的程度。stable-diffusion-x4-upscaler是使用LAION中>2048x2048大小的子集(10M)训练的,训练过程中采用512x512的crops来训练(降低显存消耗)。SD模型可以用来生成512x512图像,加上这个超分模型,就可以得到2048x2048大小的图像。

在diffusers库中,可以如下使用这个超分模型(这里的noise level是指推理时对低分辨率图像加入噪音的程度):
import requests
from PIL import Image
from io import BytesIO
from diffusers import StableDiffusionUpscalePipeline
import torch
# load model and scheduler
model_id = "stabilityai/stable-diffusion-x4-upscaler"
pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")
# let's download an image
url = "<https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png>"
response = requests.get(url)
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
low_res_img = low_res_img.resize((128, 128))
prompt = "a white cat"
upscaled_image = pipeline(prompt=prompt, image=low_res_img, noise_level=20).images[0]
upscaled_image.save("upsampled_cat.png")
stable-diffusion-2-inpainting是图像inpainting模型,和前面所说的runwayml/stable-diffusion-inpainting基本一样,不过它是在SD 2.0的512x512版本上finetune的。

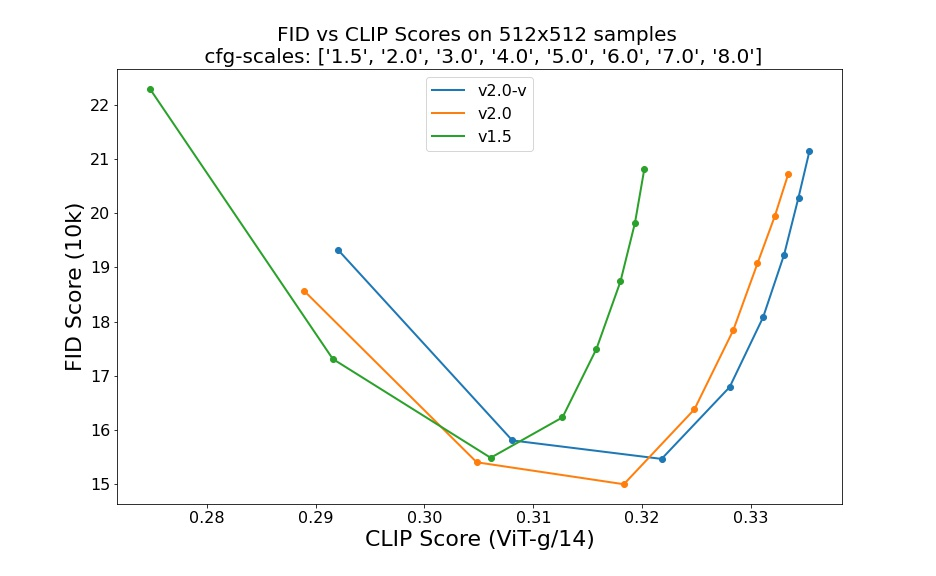
stable-diffusion-2-depth是也是在SD 2.0的512x512版本上finetune的模型,它是额外增加了图像的深度图作为condition,这里是直接将深度图下采样8x,然后和nosiy latent拼接在一起送入UNet模型中。深度图可以作为一种结构控制,下图展示了加入深度图后生成的图像效果:

你可以调用diffusers库中的StableDiffusionDepth2ImgPipeline来实现基于深度图控制的文生图:
import torch
import requests
from PIL import Image
from diffusers import StableDiffusionDepth2ImgPipeline
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
).to("cuda")
url = "<http://images.cocodataset.org/val2017/000000039769.jpg>"
init_image = Image.open(requests.get(url, stream=True).raw)
prompt = "two tigers"
n_propmt = "bad, deformed, ugly, bad anotomy"
image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
除此之外,Stability AI公司还开源了两个加强版的autoencoder:ft-EMA和ft-MSE(前者使用L1 loss后者使用MSE loss),前面已经说过,它们是在LAION数据集继续finetune decoder来增强重建效果。
SD 2.1
在SD 2.0版本发布几周后,Stability AI又发布了SD 2.1。SD 2.0在训练过程中采用NSFW检测器过滤掉了可能包含色情的图像(punsafe=0.1),但是也同时过滤了很多人像图片,这导致SD 2.0在人像生成上效果可能较差,所以SD 2.1是在SD 2.0的基础上放开了限制(punsafe=0.98)继续finetune,所以增强了人像的生成效果。

和SD 2.0一样,SD 2.1也包含两个版本:512x512版本和768x768版本。
SD unclip
Stability AI在2023年3月份,又放出了基于SD的另外一个模型:stable-diffusion-reimagine,它可以实现单个图像的变换,即image variations,目前该模型已经在在huggingface上开源:stable-diffusion-2-1-unclip。

这个模型是借鉴了OpenAI的DALLE2(又称unCLIP),unCLIP是基于CLIP的image encoder提取的image embeddings作为condition来实现图像的生成。
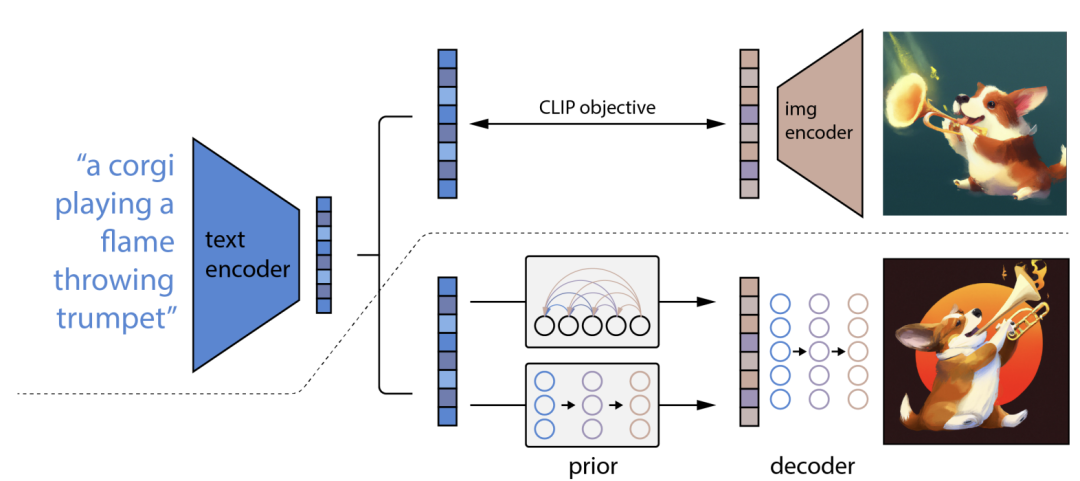
SD unCLIP是在原来的SD模型的基础上增加了CLIP的image encoder的nosiy image embeddings作为condition。具体来说,它在训练过程中是对提取的image embeddings施加一定的高斯噪音(也是通过扩散过程),然后将noise level对应的time embeddings和image embeddings拼接在一起,最后再以class labels的方式送入UNet。在diffusers中,你可以调用StableUnCLIPImg2ImgPipeline来实现图像的变换:
import requests
import torch
from PIL import Image
from io import BytesIO
from diffusers import StableUnCLIPImg2ImgPipeline
#Start the StableUnCLIP Image variations pipeline
pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
)
pipe = pipe.to("cuda")
#Get image from URL
url = "<https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png>"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
#Pipe to make the variation
images = pipe(init_image).images
images[0].save("tarsila_variation.png")
其实在SD unCLIP之前,已经有Lambda Labs开源的sd-image-variations-diffusers,它是在SD 1.4的基础上finetune的模型,不过实现方式是直接将text embeddings替换为image embeddings,这样也同样可以实现图像的变换。

这里SD unCLIP有两个版本:sd21-unclip-l和sd21-unclip-h,两者分别是采用OpenAI CLIP-L和OpenCLIP-H模型的image embeddings作为condition。如果要实现文生图,还需要像DALLE2那样训练一个prior模型,它可以实现基于文本来预测对应的image embeddings,我们将prior模型和SD unCLIP接在一起就可以实现文生图了。KakaoBrain这个公司已经开源了一个DALLE2的复现版本:Karlo,它是基于OpenAI CLIP-L来实现的,你可以基于这个模型中prior模块加上sd21-unclip-l来实现文本到图像的生成,目前这个已经集成了在StableUnCLIPPipeline中,或者基于stablediffusion官方仓库来实现。

SDXL-1.0
Announcing SDXL 1.0 — Stability AI
2023年7月4日 发布了SDXL 1.0版本,主要表达的就是 我们又迭代了Stable Diffusion,新版本名字叫Sdable Diffusion XL,比之前更强哦!!!而且我们开源哦!!!
如何获得了这样提升呢:
- 用了3倍大的unet backbone;
- 用了两个简单有效的附加条件技术;
- 又用了一个扩散模型把前面生成的结果增强了;
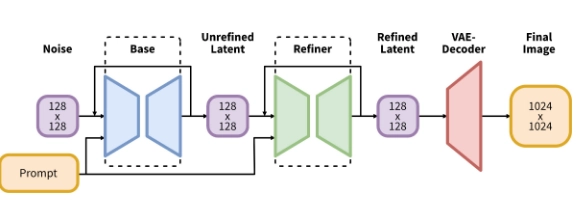
大体结构长下面这样,为了区分两个模型,基础的扩散模型叫 base SD,附加的扩散模型叫 refiner SD。
Architecture & Scale

上面这个表是 SDXL 相对于之前的 SD 的改进。第一行展示了unet的参数量高出了之前的3倍。
第一个改进点,为了提高计算效率,作者把 unet 里的 transformer 块放到较低层去计算。具体来说是省略了最高层特征里的 transformer 块,在较低层用了2和10个 transformer 块,去掉了最底层(8倍下采样)的 transformer 块。这段可以看上面表格Table 1的第二行,以往的SD是[1,1,1,1],现在的SDXL 是[0, 2, 10]。
第二个改进点,文本编码器从单个 CLIP 换成了 OpenClip ViT-bigG 和 Clip Vit-L 两个合并。作者将两个文本编码器倒数第二层的输出在通道维度上进行拼接。
第三个改进点,除了用cross-attention 做文本条件注入,还增加了来自 OpenClip 池化了的文本嵌入。
所有这些改进使得 unet 模型的参数两涨到了 2.6B,其中两个文本编码器占了 817M 的参数。
Micro-Conditioning
根据图像大小调节模型:LDM有个臭名昭著的问题是,由于它的两阶段结构,模型训练过程中模型需要一个最小图像尺寸image size。解决方式一个是放弃所有小于这个尺寸的图像(比如之前的SD模型放弃了所有小于边长512像素的图),另一个是把小图upscale放大。前一种方式会放弃一部分训练数据,导致效果降低生成图像变差(放弃256*256以下的图会导致损失39%的数据),后一种方式上采样的图不清晰,可能会让模型生成的图也变模糊。
基于此,作者提出了一种基于图像原始分辨率调整unet模型的方法。做法是,把原始图片(未经任何缩放)的高和宽(记作Csize)作为条件给到模型,使用傅里叶特征编码(Fourier feature encoding)分别对高度和宽度进行编码, 将编码后的特征拼接成一个向量, 该向量与时间步嵌入相加后输入模型
推理的时候,使用者可以通过这个Csize条件来设置期望的图像分辨率。可以看下图,很显然,模型学到了条件 Csize 和特征图分辨率之间的联系,这就使得模型可以根据给定的prompt来生成合适的图像。

这张图的意思是,同样是生成512*512的图,左边给的Csize比较小,生成的图像就比较模糊,右边给的Csize比较大,生成的图就很清晰,说明模型学到了图像与Csize之间的关系
下面这个表格是定性的实验 Csize 的效果,第一行CIN-512-only是丢弃单边小于512的图训练的,第二行CIN-nocond是用所有图但不加条件训练的,第三行CIN-size-cond是用 Csize 训练的。训练以后用50步的DDIM和scale是5的classifier-free guidance 各生成了5k张图,计算他们的FID和IS指标。对于第三行CIN-size-cond,生成时设置Csize为512*512。
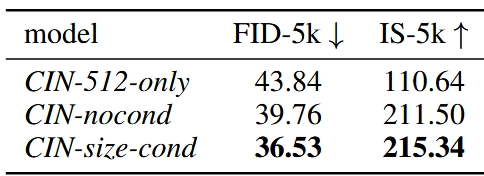
显然Csize的效果最好。第一行512-only不好是因为数据太少过拟合了,第二行nocond不好是因为把小图放大导致模糊,让模型的输出结果受损了。
根据crop参数调整模型:之前的SD模型还有个问题是,生成的图像可能不完整,比如下面的图里前两行的猫猫头就只有下半部分。这是因为训练时输入的图片都会被随机crop,因为pytorch训练时要求所有tensors都必须是相同的size。这里说一下模型训练时通常的图片预处理过程是:
- 把图resize到短边与模型期望size一致,
- 沿着长边的轴随机crop。尽管随机crop也是一种图像增强的方式,但它也会有坏处,比如导致生成图像的目标不完整,像被裁剪过一样。

这张图说明,之前的SD模型(前两行)受随即裁剪的影响,生成的目标不完整,但改进后的SDXL(第三行)生成的就很完整。
作者使用了一个简单有效的方案:裁剪条件控制方法。在数据加载时,统一采样两个裁剪坐标:\(c_{top}\)(从顶部裁剪的像素数)和 \(c_{left}\)(从左侧裁剪的像素数)。使用傅里叶特征嵌入对这些坐标进行编码,将编码后的特征拼接成裁剪条件向量 \(c_{crop}\) 。
在训练时,裁剪条件可以与之前的尺寸条件结合使用,将两种条件的特征在通道维度上拼接,拼接后的特征与UNet的时间步嵌入相加。
推理阶段:由于大规模数据集通常是物体居中的,推理时设置 \((c_{top}, c_{left}) = (0, 0)\) 以获得物体居中的生成结果,可以通过调整 \((c_{top}, c_{left})\) 来模拟不同程度的裁剪效果

这张图是说,设置不同的 \(c_{crop}\) 模型就可以模拟出不同裁剪程度的图像,说明模型确实学到了 \(c_{crop}\) 的信息。
虽然其他技术,比如数据桶等,也可以解决这个问题,但他们同时失去了随机裁剪的数据增强效果。作者的技术既能有数据增强效果,又避免了它的缺陷,而且我们可以利用它来获得对图像的更多控制,在训练期间在线应用,并且无需附加数据。并且该方法适用于任何扩散模型,不限于潜在扩散模型,实现简单,可以在训练过程中在线应用,不需要额外的数据预处理。
Multi-Aspect Training
真实世界的图片包含各种不同的图像尺寸,但通常的文生图的输出图像分辨率是512x512或1024x1024。鉴于横向(16:9)或纵向屏幕的广泛分布和使用,作者觉得把输出卡在512或1024是个非常不自然的选择。
所以作者微调了模型,来同时处理多种尺寸:作者 follow 了 GLIDE 这篇论文,把图像根据不同的高宽比划分为不同的桶,期间尽量保持像素个数接近1024*1024,然后以64的倍数相应地改变高度和宽度。附录 I 提供了所有的比例和尺寸。下面贴了个样例,比例上从h/w=0.25(超级横屏)逐渐到h/w=4(超级竖屏)。
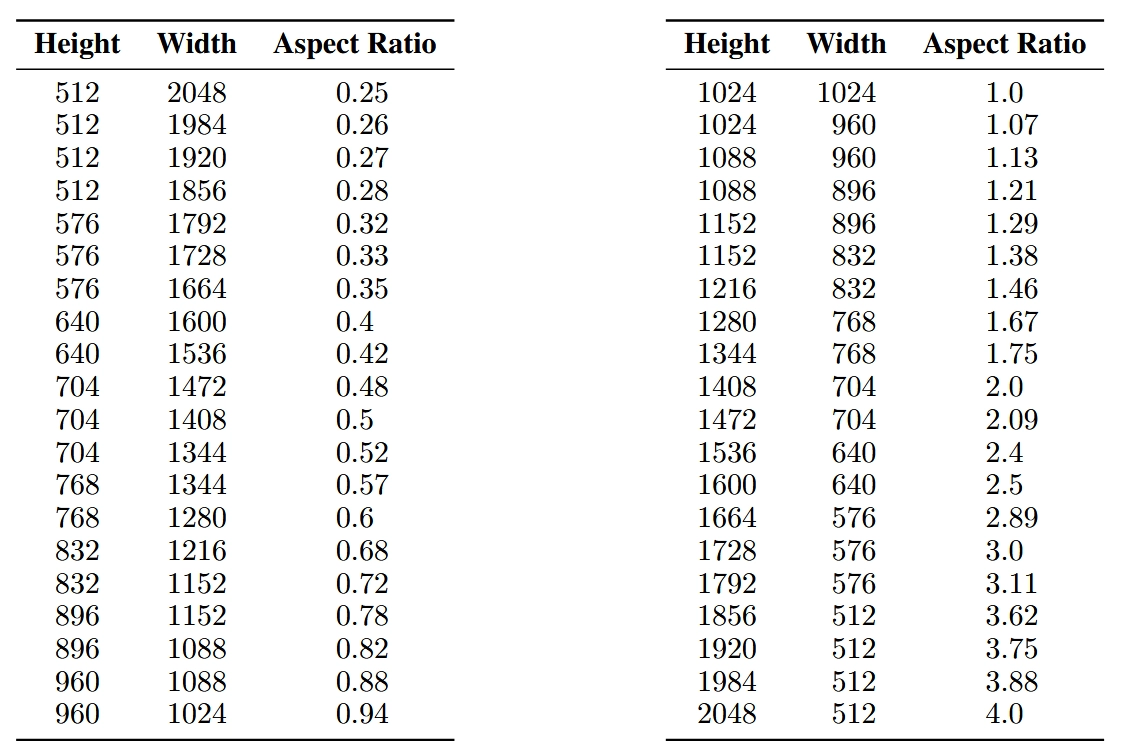
根据图像尺寸微调模型时的画面纵横比,每一行的比例设定都是一个桶
微调过程中,每个 batch 里的图片都来自同一个桶,然后把桶的尺寸,或者可以叫目标尺寸 Car=(htgt,wtgt) 作为条件编码到傅里叶空间中,做法类似于上面的尺寸调节和裁剪条件(真的是万物皆可训练哈!)。
综上,实际训练过程中,作者先用固定比例固定分辨率的图像进行训练,然后在微调阶段把上面这些条件技术concat到一起。注意裁剪和多比例训练是互补操作,裁剪调节仅在桶的边界(通常是64个像素)内起作用。为了方便实现,我们选择为多比例模型保留这个控制参数。
Improved Autoencoder
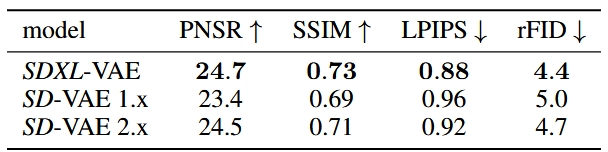
SD是一种LDM(潜空间扩散模型),在SD学成之后需要用VAE来提高细节信息。作者新训了一个VAE,这个VAE跟原来用的VAE在结构上相同,只是用了更大的batch size(256 vs 9),还用了EMA技术(权重移动平均)。
结果上新训练的VAE在所有指标上都比之前的VAE效果好,结果在下面的表格里。在所有实验中作者都用的是新的VAE。
Putting Everything Together
- Base Stage
训练SDXL是多步骤训的。SDXL使用了新训练的VAE和1000步的离散时间扩散策略。
首先,作者训练了一个 base SD,一共迭代了600,000步,数据分辨率是256x256,batch size 是2048,而且用了size-conditioning和crop-conditioning。
然后在512x512的分辨率上又迭代了200,000步。
最后多比例训练,多比例的像素面积大约是1024x1024,这一步的偏移噪声level是0.05。 - Refinement Stage
根据经验,我们发现模型有时候会生成局部质量比较低的图片。可以看下面这张图,左边是Base SDXL模型生成的,细节不是非常好。
为了提高图像质量,作者在同样的潜空间上训练了一个单独的 LDM 模型。它专门用高质量高分辨率的数据训练,以Base模型的输出作为输入,用SDEdit论文提出的加噪-去噪过程来训练。作者专门用前200个(离散)噪声scales来优化refiner模型。在推理期间,作者直接让Base模型出来的潜空间特征进到Refiner模型里,再用同样的text input 进行有条件的扩散和去噪。
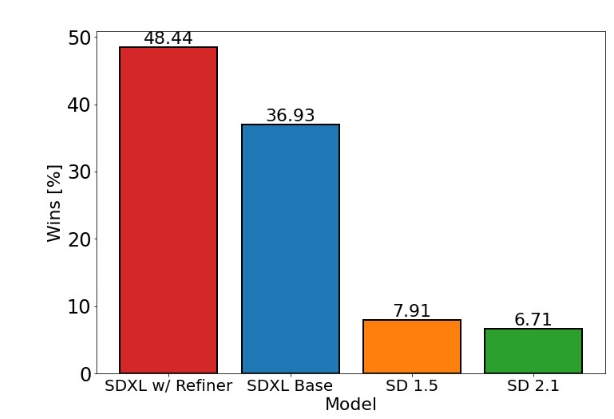
上面属于定性评估,为了定量评估refiner模型的作用,作者搞了个用户研究,让用户从下面4个模型生成的图像里选择它们最喜欢的图片:SDXL,SDXL(有refiner),SD1.5,SD2.1。结果说明有refiner的SDXL会被更多地选择,而且比SD1.5和SD2.1高得多。
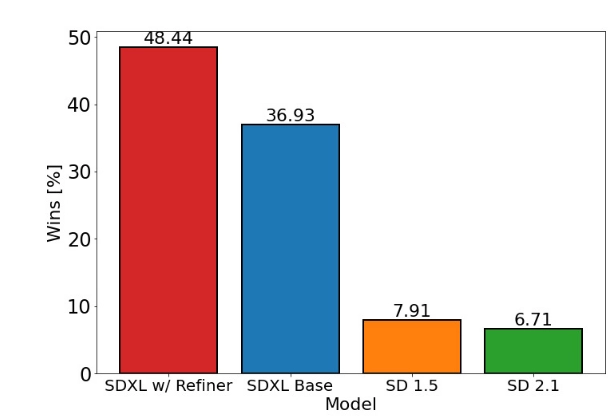
但是,当使用经典的评价指标比如FID和CLIP分数的时候,表现是相反的,可以看下图。这和Kirstaion等人的研究结果一致。至于为什么看着效果好但FID分数不好,附录F里有进一步讨论(附录也没讨论原因,只是说明了FID确实不适合作为评价指标,并且呼吁大家研发更准确的符合人类审美的评价指标)。
可以看出,SDXL(绿)只比SD2.1好了一点点,这跟人类评价并不完全一致。甚至有些研究中人类评价比SD1.5和SD2.1都高,但FID指标却更差。
Stable Diffusion 3
Stable Diffusion 3: Research Paper — Stability AI
SD3 模型与训练策略改进细节
SD3除了将去噪网络从 U-Net 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进:
- 改变训练时噪声采样方法
- 将一维位置编码改成二维位置编码
- 提升 VAE 隐空间通道数
- 对注意力 QK 做归一化以确保高分辨率下训练稳定
本文会简单介绍这些改进。
核心贡献
介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for High-Resolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它确实是按照撰写学术论文的一般思路,将正文的叙述重点放到了方法的核心创新点上,而没有过多叙述工程细节。正如其标题所示,这篇文章的内容很简明,就是用整流 (rectified flow) 生成模型、Transformer 神经网络做了模型参数扩增实验,以实现高质量文生图大模型。
由于这是一篇实验主导而非思考主导的文章,论文的开头没有太多有价值的内容。从我们读者学习论文的角度,文章的核心贡献如下:
从方法设计上:
- 首次在大型文生图模型上使用了整流模型。
- 用一种新颖的 Diffusion Transformer (DiT) 神经网络来更好地融合文本信息。
- 使用了各种小设计来提升模型的能力。如使用二维位置编码来实现任意分辨率的图像生成。
从实验上:
- 开展了一场大规模、系统性的实验,以验证哪种扩散模型/整流模型的学习目标最优。
- 开展了扩增模型参数的实验 (scaling study),以证明提升参数量能提升模型的效果。
整流模型
Rectified Flow 可以参考这里:Rectified Flow
文章也是通过设计一个通用的Loss 公式(兼顾diffusion和flow matching 等方法):
其中,\({w}_{t} = - \frac{1}{2}{\lambda }_{t}^{\prime }{b}_{t}^{2}\) 时对应于\({\mathcal{L}}_{CFM}\).
对于 Rectified Flow Model , 对应
对应上面(1) 中\({w}_{t}^{\mathrm{{RF}}} = \frac{t}{1 - t}\) .
非均匀训练噪声采样
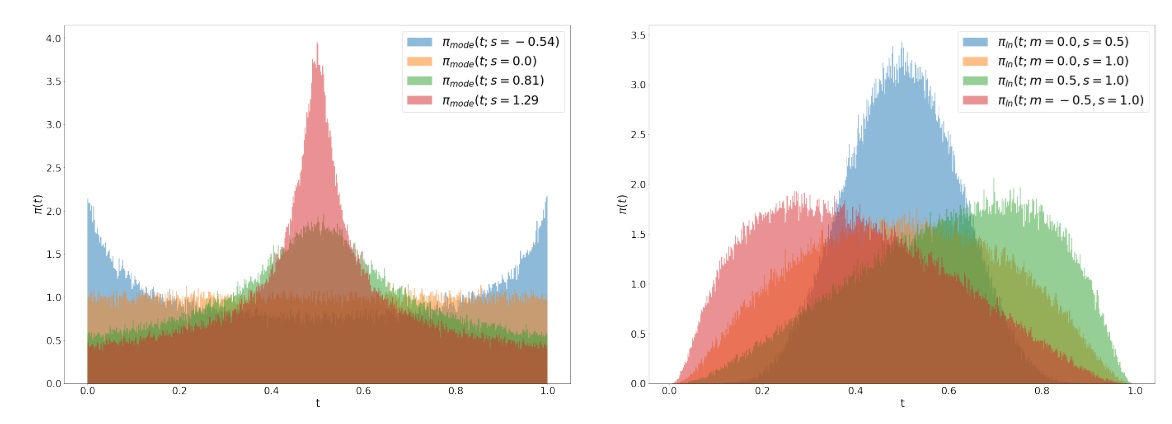
在学习这种生成模型时,会随机采样一个时刻 \(t \in [0, 1]\),并根据公式获取此时刻对应位置在生成路径上的速度(velocity field)。神经网络的任务是学习如何预测这个速度。在生成路径中,靠近起点(目标数据分布)和终点(噪声分布)的区域相对容易学习,因为起点附近数据的结构清晰,终点附近噪声特征简单。而路径的中间部分(即 \(t \approx 0.5\) 的区域)由于数据和噪声的混合程度较高,预测难度更大。因此,为了让模型更好地学习中间部分的生成路径,SD3 使用了一种非均匀采样分布 \(\pi(t)\),对中间的时间点赋予更高的采样概率,从而增强模型在这一部分的学习效果。
如下图所示,SD3 主要考虑了两种公式: mode(左)和 logit-norm (右)。二者的共同点是中间多,两边少。mode 相比 logit-norm,在开始和结束时概率不会过分接近 0。
logit-norm的公式如下所示:
在实际使用中,作者首先从\(u\sim\mathcal{N}(u;m,s)\)采样\(u\),再通过标准logitstic函数生成,下面是对应的mode采样
网络整体架构
以上内容都是和训练相关的理论基础,下面我们来看多数用户更加熟悉的文生图架构。
从整体架构上来看,和之前的 SD 一样,SD3 主要基于隐扩散模型(latent diffusion model, LDM)。这套方法是一个两阶段的生成方法:先用一个 LDM 生成隐空间低分辨率的图像,再用一个自编码器把图像解码回真实图像。
扩散模型 LDM 会使用一个神经网络模型来对噪声图像去噪。为了实现文生图,该去噪网络会以输入文本为额外约束。相比之前多数扩散模型,SD3 的主要改进是把去噪模型的结构从 U-Net 变为了 DiT。
提升自编码器通道数
在当时设计整套自编码器 + LDM 的生成架构时,SD 的开发者并没有仔细改进自编码器,用了一个能把图像下采样 8 倍,通道数变为 4 的隐空间图像。比如输入 \(512 \times 512 \times 3\) 的图像会被自编码器编码成 \(64 \times 64 \times 4\)。而近期有些工作发现,这个自编码器不够好,提升隐空间的通道数能够提升自编码器的重建效果。因此,SD3 把隐空间图像的通道数从 4 改为了 16。
多模态 DiT (MM-DiT)
SD3 的去噪模型是一个 Diffusion Transformer (DiT)。如果去噪模型只有带噪图像这一种输入的话,DiT 则会是一个结构非常简单的模型,和标准 ViT 一样:图像过图块化层 (Patching) 并与位置编码相加,得到序列化的数据。这些数据会像标准 Transformer 一样,经过若干个子模块,再过反图块层得到模型输出。DiT 的每个子模块 DiT-Block 和标准 Transformer 块一样,由 LayerNorm, Self-Attention, 一对一线性层 (Pointwise Feedforward, FF) 等模块构成。
图块化层会把 \(2\times 2\) 个像素打包成图块,反图块化层则会把图块还原回像素。
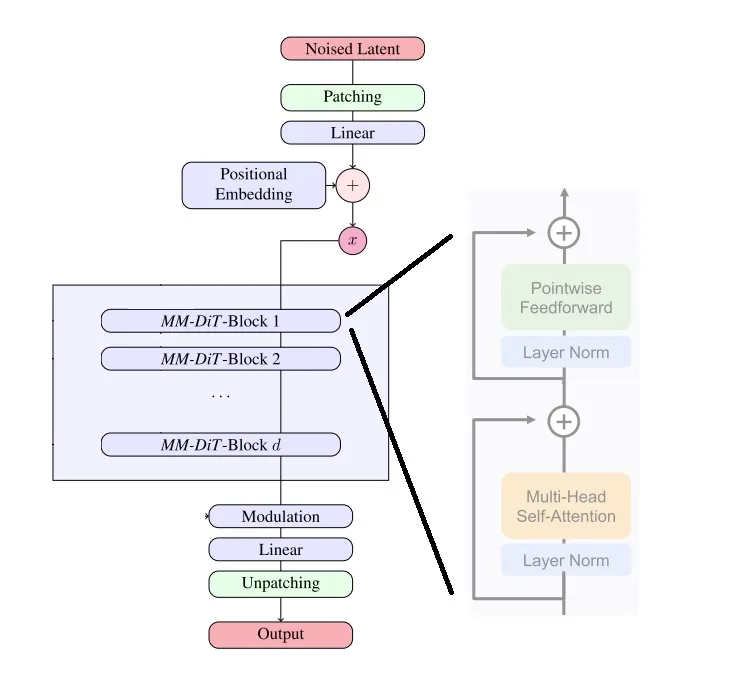
然而,扩散模型中的去噪网络一定得支持带约束生成。这是因为扩散模型约束于去噪时刻 。此外,作为文生图模型,SD3 还得支持文本约束。DiT 及本文的 MM-DiT 把模型设计的重点都放在了处理额外约束上。
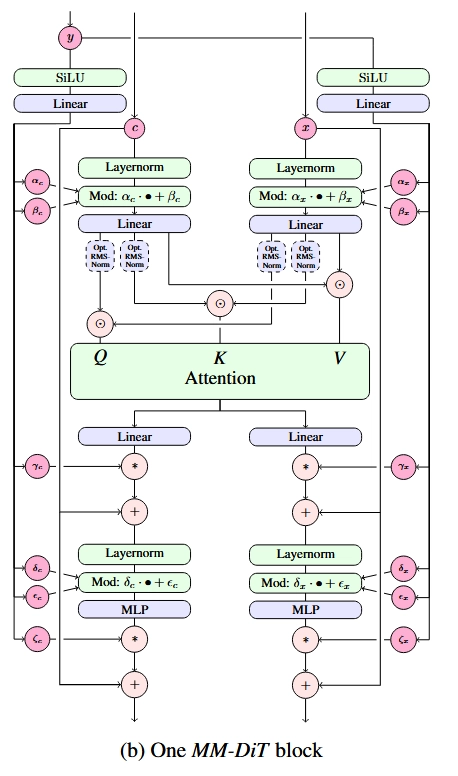
我们先看一下模块是怎么处理较简单的时刻约束的。此处,如下图所示,SD3 的模块保留了 DiT 的设计,用自适应 LayerNorm (Adaptive LayerNorm, AdaLN) 来引入额外约束。具体来说,过了 LayerNorm 后,数据的均值、方差会根据时刻约束做调整。另外,过完 Attention 层或 FF 层后,数据也会乘上一个和约束相关的系数。
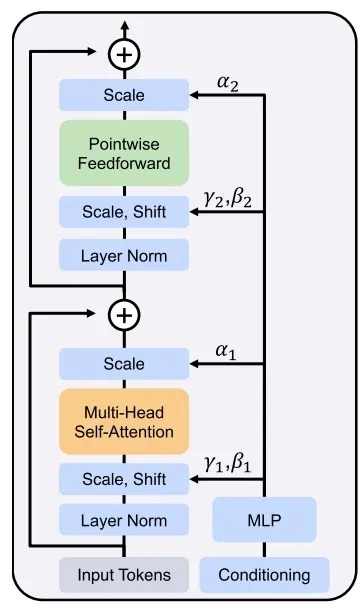
我们再来看文本约束的处理。文本约束以两种方式输入进模型:与时刻编码拼接、在注意力层中融合。具体数据关联细节可参见下图。如图所示,为了提高 SD3 的文本理解能力,描述文本 (“Caption”) 经由三种编码器编码,得到两组数据。一组较短的数据会经由 MLP 与文本编码加到一起;另一组数据会经过线性层,输入进 Transformer 的主模块中。
将约束编码与时刻编码相加是一种很常见的做法。此前 U-Net 去噪网络中处理简单约束(如 ImageNet 类型约束)就是用这种方法。
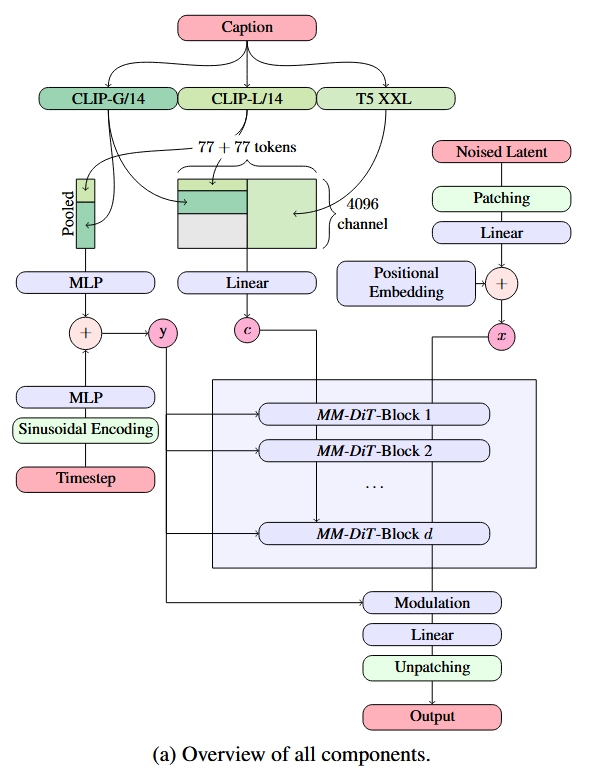
SD3 的 DiT 的子模块结构图如下所示。我们可以分几部分来看它。先看时刻编码 的那些分支。和标准 DiT 子模块一样, 通过修改 LayerNorm 后数据的均值、方差及部分层后的数据大小来实现约束。再看输入的图像编码 和文本编码 。二者以相同的方式做了 DiT 里的 LayerNorm, FF 等操作。不过,相比此前多数基于 DiT 的模型,此模块用了一种特殊的融合注意力层。具体来说,在过注意力层之前, 和 对应的 会分别拼接到一起,而不是像之前的模型一样, 来自图像, 来自文本。过完注意力层,输出的数据会再次拆开,回到原本的独立分支里。由于 Transformer 同时处理了文本、图像的多模态信息,所以作者将模型取名为 MM-DiT (Multimodal DiT)。
比例可变的位置编码
此前多数方法在使用类 ViT 架构时,都会把图像的图块从左上到右下编号,把二维图块拆成一维序列,再用这种一维位置编码来对待图块。
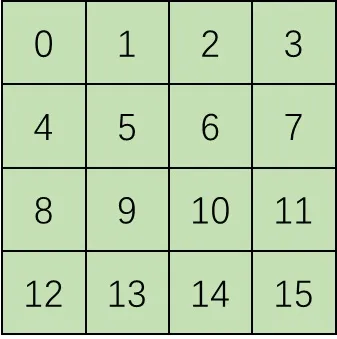
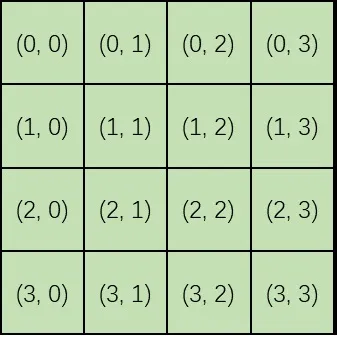
这样做有一个很大的坏处:生成的图像的分辨率是无法修改的。比如对于上图,假如采样时输入大小不是 ,而是 ,那么 号图块的下面就是 而不是 了,模型训练时学习到的图块之间的位置关系全部乱套。
解决此问题的方法很简单,只需要将一维的编码改为二维编码。这样 Transformer 就不会搞混二维图块间的关系了。
SD3 的 MM-DiT 一开始是在 固定分辨率上训练的。之后在高分辨率图像上训练时,开发者用了一些巧妙的位置编码设置技巧,让不同比例的高分辨率图像也能共享之前学到的这套位置编码。详细公式请参见原论文。
训练数据预处理
看完了模块设计,我们再来看一下 SD3 在训练中的一些额外设计。在大规模训练前,开发者用三个方式过滤了数据:
- 用了一个 NSFW 过滤器过滤图片,似乎主要是为了过滤色情内容。
- 用美学打分器过滤了美学分数太低的图片。
- 移除了看上去语义差不多的图片。
虽然开发者们自信满满地向大家介绍了这些数据过滤技术,但根据社区用户们的反馈,可能正是因为色情过滤器过分严格,导致 SD3 经常会生成奇怪的人体。
由于在训练 LDM 时,自编码器和文本编码器是不变的,因此可以提前处理好所有训练数据的图像编码和文本编码。当然,这是一项非常基础的工程技巧,不应该写在正文里的。
用 QK 归一化提升训练稳定度
按照之前高分辨率文生图模型的训练方法,SD3 会先在 的图片上训练,再在高分辨率图片上微调。然而,开发者发现,开始微调后,混合精度训练常常会训崩。根据之前工作的经验,这是由于注意力输入的熵会不受控制地增长。解决方法也很简单,只要在做注意力计算之前对 Q, K 做一次归一化就行,具体做计算的位置可以参考上文模块图中的 “RMSNorm”。不过,开发者也承认,这个技巧并不是一个长久之策,得具体问题具体分析。看来这种 DiT 模型在大规模训练时还是会碰到许多训练不稳定的问题,且这些问题没有一个通用解。
试验
哪种扩散模型训练目标最适合文生图任务?
最后我们来看论文的实验结果部分。首先,为了寻找最好的扩散模型/流匹配模型,开发者开展了一场声势浩大的实验。实验涉及 61 种训练公式,其中的可变项有:
- 对于普通扩散模型,考虑 \(\epsilon\)- 或 \(\mathbf{v}\)-prediction,考虑线性或 cosine 噪声调度。
- 对于整流,考虑不同的噪声调度。
- 对于 EDM,考虑不同的噪声调度,且尽可能与整流的调度机制相近以保证可比较。
在训练时,除了训练目标公式可变外,优化算法、模型架构、数据集、采样器都不可变。所有模型在 ImageNet 和 CC12M 数据集上训练,在 COCO-2014 验证集上评估 FID 和 CLIP Score。根据评估结果,可以选出每个模型的最优停止训练的步数。基于每种目标下的最优模型,开发者对模型进行最后的排名。由于在最终评估时,仍有采样步数、是否使用 EMA 模型等可变采样配置,开发者在所有 24 种采样配置下评估了所有模型,并用一种算法来综合所有采样配置的结果,得到一个所有模型的最终排名。最终的排名结果如下面的表 1 所示。训练集上的一些指标如表 2 所示。
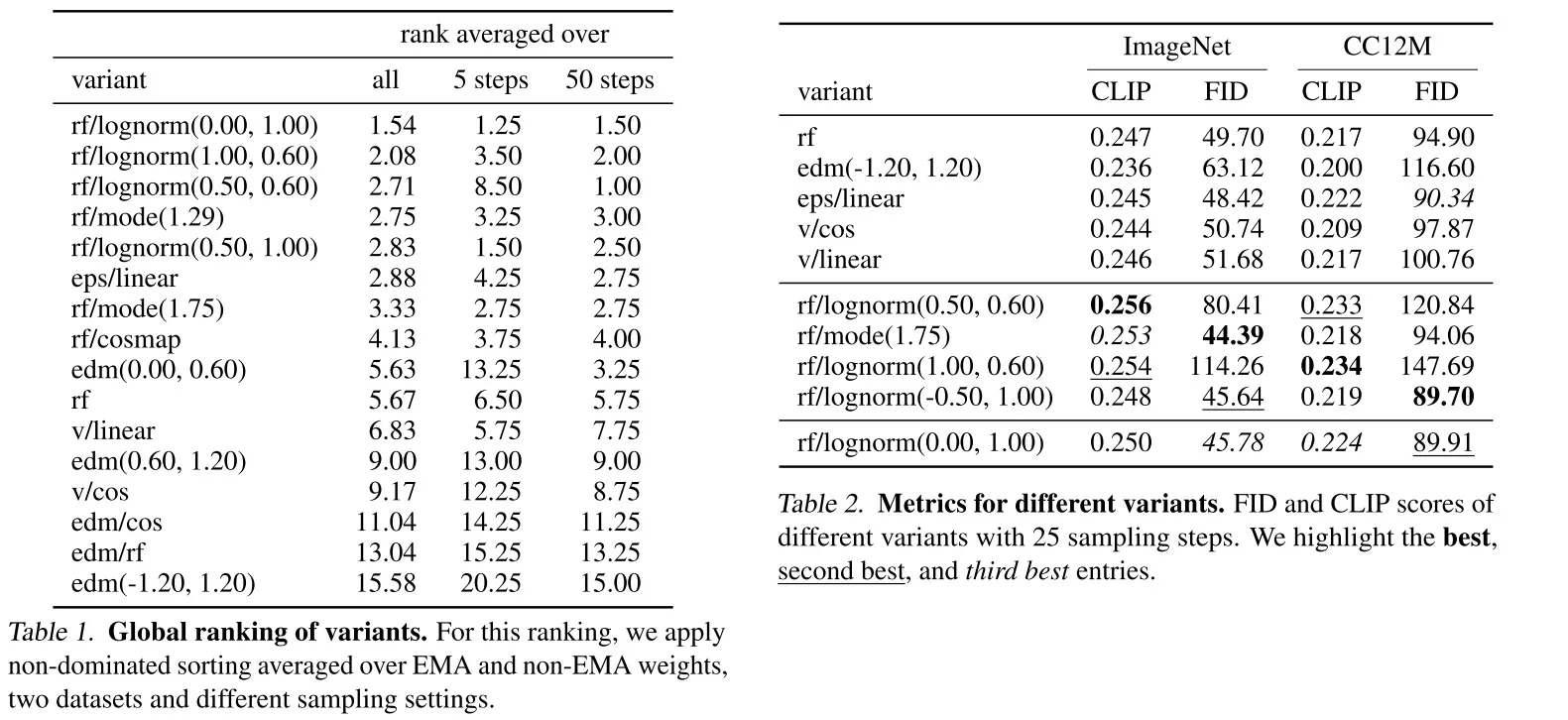
根据实验结果,我们可以得到一些直观的结论:整流领先于扩散模型。惊人的是,较新推出的 EDM 竟然没有战胜早期的 LDM (“eps/linear”)。
当然,我个人认为,应该谨慎看待这份实验结果。一般来说,大家做图像生成会用一个统一的指标,比如 ImageNet 上的 FID。这篇论文相当于是新提出了一种昂贵的评价方法。这种评价方法是否合理,是否能得到公认还犹未可知。另外,想说明一个生成模型的拟合能力不错,用 ImageNet 上的 FID 指标就足够有说服力了,大家不会对一个简单的生成模型有太多要求。然而,对于大型文生图模型,大家更关心的是模型的生成效果,而 FID 和 CLIP Score 并不能直接反映文生图模型的质量。因此,光凭这份实验结果,我们并不能说整流一定比之前的扩散模型要好。
会关注这份实验结果的应该都是公司里的文生图开发者。我建议体量小的公司直接参考这份实验结果,无脑使用整流来代替之前的训练目标。而如果有能力做同等级的实验的话,则不应该错过改良后的扩散模型,如最新的 EDM2,说不定以后还会有更好的文生图训练目标。
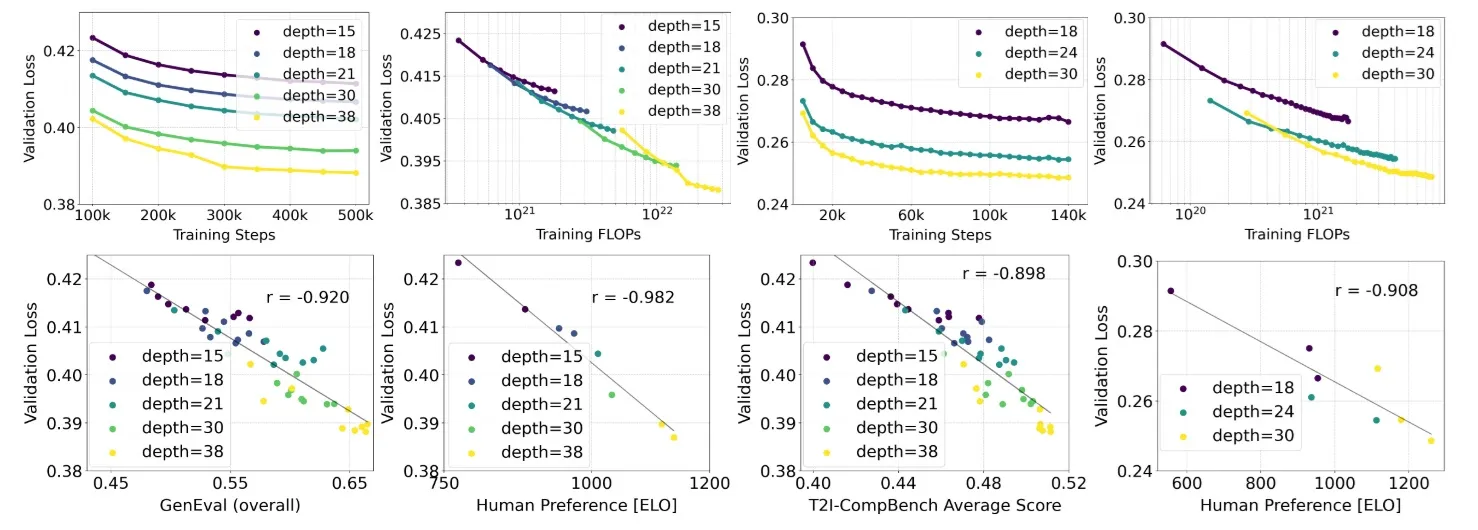
参数扩增实验结果
现在多数生成模型都会做参数扩增实验,即验证模型表现随参数量增长而增长,确保模型在资源足够的情况下可以被训练成「大模型」。SD3 也做了类似的实验。开发者用参数 来控制 MM-DiT 的大小,Transformer 块的个数为 ,且所有特征的通道数与 成正比。开发者在 的数据上训练了所有模型 500k 步,每 50k 步在 CoCo 数据集上统计验证误差。最终所有评估指标如下图所示。可以说,所有指标都表明,模型的表现的确随参数量增长而增长。更多结果请参见论文。
Diffusers 源码阅读
我们来阅读一下 SD3 在最流行的扩散模型框架 Diffusers 中的源码。在读源码前,我们先来跑通官方的示例脚本。
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
).images[0]
image.save('tmp.png')我得到的图片如下所示。看起来 SD3 理解文本的能力还是挺强的。

模型组件
接下来我们来快速浏览一下 SD3 流水线 StableDiffusion3Pipeline 的源码。在 IDE 里使用源码跳转功能可以在 diffusers/pipelines/stable_diffusion_3/pipeline_stable_diffusion_3.py 里找到该类的源码。
通过流水线的 __init__ 方法,我们能知道 SD3 的所有组件。组件包括自编码器 vae, MM-DiT Transformer, 流匹配噪声调度器 scheduler,以及三个文本编码器。每个编码器由一个 tokenizer 和一个 text encoder 组成.
def __init__(
self,
transformer: SD3Transformer2DModel,
scheduler: FlowMatchEulerDiscreteScheduler,
vae: AutoencoderKL,
text_encoder: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer_2: CLIPTokenizer,
text_encoder_3: T5EncoderModel,
tokenizer_3: T5TokenizerFast,
):
vae 的用法和之前 SD 的一模一样,编码时用 vae.encode 并乘 vae.config.scaling_factor,解码时除以 vae.config.scaling_factor 并用 vae.decode。
文本编码器的用法可以参见 encode_prompt 方法。文本会分别过各个编码器的 tokenizer 和 text encoder,得到三种文本编码,并按照论文中的描述拼接成两种约束信息。这部分代码十分繁杂,多数代码都是在处理数据形状,没有太多有价值的内容。
def encode_prompt(
self,
prompt,
prompt_2,
prompt_3,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
negative_prompt_2,
negative_prompt_3,
...
):
...
return prompt_embeds, negative_prompt_embeds,
pooled_prompt_embeds, negative_pooled_prompt_embeds
采样流水线
我们再来通过阅读流水线的 __call__ 方法了解 SD3 采样的过程。由于 SD3 并没有修改 LDM 的这套生成框架,其采样流水线和 SD 几乎完全一致。SD3 和 SD 的 __call__ 方法的主要区别是,生成文本编码时会生成两种编码。
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(...)
在调用去噪网络时,那个较小的文本编码 pooled_prompt_embeds 会作为一个额外参数输入。
noise_pred = self.transformer(
hidden_states=latent_model_input,
timestep=timestep,
encoder_hidden_states=prompt_embeds,
pooled_projections=pooled_prompt_embeds,
joint_attention_kwargs=self.joint_attention_kwargs,
return_dict=False,
)[0]
MM-DiT 去噪模型
相比之下,SD3 的去噪网络 MM-DiT 的改动较大。我们来看一下对应的 SD3Transformer2DModel 类,它位于文件 diffusers\\models\\transformers\\transformer_sd3.py。
类的构造函数里有几个值得关注的模块:二维位置编码类 PatchEmbed、组合时刻编码和文本编码模块 CombinedTimestepTextProjEmbeddings、主模块类 JointTransformerBlock。
def __init__(...):
...
self.pos_embed = PatchEmbed(...)
self.time_text_embed = CombinedTimestepTextProjEmbeddings(...)
...
self.transformer_blocks = nn.ModuleList(
[
JointTransformerBlock(..)
for i in range(self.config.num_layers)
]
)
类的前向传播函数 forward 里都是比较常规的操作。数据会依次经过前处理、若干个 Transformer 块、后处理。所有实现细节都封装在各个模块类里。
def forward(...):
hidden_states = self.pos_embed(hidden_states)
temb = self.time_text_embed(timestep, pooled_projections)
encoder_hidden_states = self.context_embedder(encoder_hidden_states)
for index_block, block in enumerate(self.transformer_blocks):
encoder_hidden_states, hidden_states = block(...)
encoder_hidden_states, hidden_states = block(
hidden_states=hidden_states, encoder_hidden_states=encoder_hidden_states, temb=temb
)
...
接下来我们来看这几个较为重要的子模块。PatchEmbed 类的实现写在 diffusers/models/embeddings.py 里。这个类的实现写得非常清晰。PatchEmbed 类本身用于维护位置编码宽高、特征长度这些信息,计算位置编码的关键代码在 get_2d_sincos_pos_embed 中。get_2d_sincos_pos_embed 会生成 (0, 0), (1, 0), ... 这样的二维坐标网格,再调用 get_2d_sincos_pos_embed_from_grid 生成二维位置编码。get_2d_sincos_pos_embed_from_grid 会调用两次一维位置编码函数 get_1d_sincos_pos_embed_from_grid,也就是 Transformer 里那种标准位置编码生成函数,来分别生成两个方向的编码,最后拼接成二维位置编码。
class PatchEmbed(nn.Module):
...
def forward(self, latent):
...
pos_embed = get_2d_sincos_pos_embed(...)
def get_2d_sincos_pos_embed(...):
grid_h = np.arange(...)
grid_w = np.arange(...)
grid = np.meshgrid(grid_w, grid_h)
...
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
def get_2d_sincos_pos_embed_from_grid(...):
# use half of dimensions to encode grid_h
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
return emb
组合时刻编码和文本编码模块 CombinedTimestepTextProjEmbeddings 的代码非常短。它实际上就是用通常的 Timesteps 类获取时刻编码,用一个 text_embedder 模块再次处理文本编码,最后把两个编码加起来。 text_embedder 是一个线性层、激活函数、线性层构成的简单模块。
class CombinedTimestepTextProjEmbeddings(nn.Module):
def __init__(self, embedding_dim, pooled_projection_dim):
super().__init__()
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
def forward(self, timestep, pooled_projection):
timesteps_proj = self.time_proj(timestep)
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
pooled_projections = self.text_embedder(pooled_projection)
conditioning = timesteps_emb + pooled_projections
return conditioning
class PixArtAlphaTextProjection(nn.Module):
def __init__(...):
...
def forward(self, caption):
hidden_states = self.linear_1(caption)
hidden_states = self.act_1(hidden_states)
hidden_states = self.linear_2(hidden_states)
return hidden_states
MM-DiT 的主要模块 JointTransformerBlock 在 diffusers/models/attention.py 文件里。这个类的代码写得比较乱。它主要负责处理 LayerNorm 及数据的尺度变换操作,具体的注意力计算由注意力处理器 JointAttnProcessor2_0 负责。两处 LayerNorm 的实现方式竟然是不一样的。
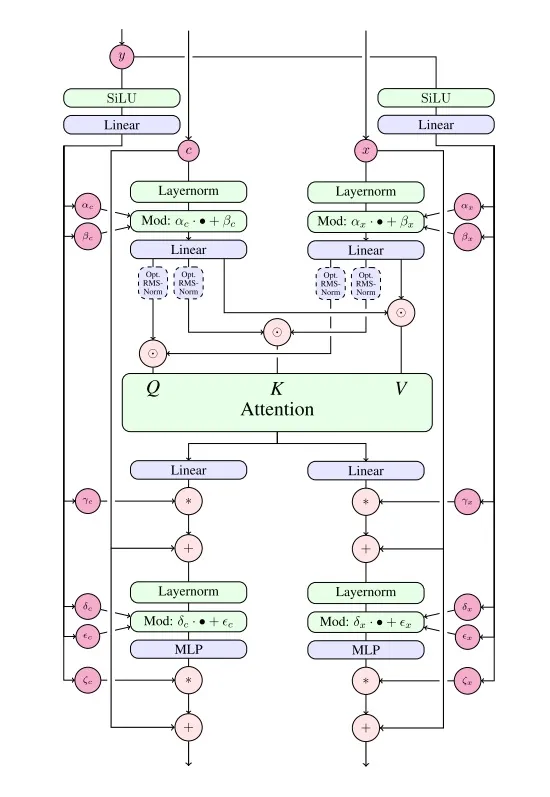
我们先简单看一下构造函数里初始化了哪些模块。代码中,norm1, ff, norm2 等模块都是普通 Transformer 块中的模块。而加了 _context 的模块则表示处理文本分支 的模块,如 norm1_context, ff_context。context_pre_only 表示做完了注意力计算后,还要不要给文本分支加上 LayerNorm 和 FeedForward。如前文所述,具体的注意力计算由 JointAttnProcessor2_0 负责。
class JointTransformerBlock(nn.Module):
def __init__(self, dim, num_attention_heads, attention_head_dim, context_pre_only=False):
super().__init__()
self.context_pre_only = context_pre_only
context_norm_type = "ada_norm_continous" if context_pre_only else "ada_norm_zero"
self.norm1 = AdaLayerNormZero(dim)
if context_norm_type == "ada_norm_continous":
self.norm1_context = AdaLayerNormContinuous(
dim, dim, elementwise_affine=False, eps=1e-6, bias=True, norm_type="layer_norm"
)
elif context_norm_type == "ada_norm_zero":
self.norm1_context = AdaLayerNormZero(dim)
processor = JointAttnProcessor2_0()
self.attn = Attention(
query_dim=dim,
cross_attention_dim=None,
added_kv_proj_dim=dim,
dim_head=attention_head_dim,
heads=num_attention_heads,
out_dim=dim,
context_pre_only=context_pre_only,
bias=True,
processor=processor,
)
self.norm2 = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
self.ff = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
if not context_pre_only:
self.norm2_context = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
self.ff_context = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
else:
self.norm2_context = None
self.ff_context = None
我们再来看 forward 方法。在前向传播时,图像分支和文本分支会分别过 norm1,再一起过注意力操作,再分别过 norm2 和 ff。大概的代码如下所示,我把较复杂的 context 分支的代码略过了。
这份代码写得很不漂亮,按理说模块里两个 LayerNorm + 尺度变换 (即 Adaptive LayerNorm) 的操作是一样的,应该用同样的代码来处理。但是这个模块里 norm1 是 AdaLayerNormZero 类,norm2 是 LayerNorm 类。norm1 会自动做完 AdaLayerNorm 的运算,并把相关变量返回。而在 norm2 处,代码会先执行普通的 LayerNorm,再根据之前的变量手动调整数据的尺度。我们心里知道这份代码是在实现论文里那张结构图就好,没必要去仔细阅读。
def forward(
self, hidden_states: torch.FloatTensor, encoder_hidden_states: torch.FloatTensor, temb: torch.FloatTensor
):
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb)
if self.context_pre_only:
...
# Attention.
attn_output, context_attn_output = self.attn(
hidden_states=norm_hidden_states, encoder_hidden_states=norm_encoder_hidden_states
)
# Process attention outputs for the `hidden_states`.
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = hidden_states + attn_output
norm_hidden_states = self.norm2(hidden_states)
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = hidden_states + ff_output
if self.context_pre_only:
...
return encoder_hidden_states, hidden_states
融合注意力的实现方法很简单。和普通的注意力计算相比,这种注意力就是把另一条数据分支 encoder_hidden_states 也做了 QKV 的线性变换,并在做注意力运算前与原来的 QKV 拼接起来。做完注意力运算后,两个数据又会拆分回去。
class JointAttnProcessor2_0:
"""Attention processor used typically in processing the SD3-like self-attention projections."""
def __call__(
self,
attn: Attention,
hidden_states: torch.FloatTensor,
encoder_hidden_states: torch.FloatTensor = None,
attention_mask: Optional[torch.FloatTensor] = None,
*args,
**kwargs,
) -> torch.FloatTensor:
...
# `sample` projections.
query = attn.to_q(hidden_states)
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
# `context` projections.
encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
# attention
query = torch.cat([query, encoder_hidden_states_query_proj], dim=1)
key = torch.cat([key, encoder_hidden_states_key_proj], dim=1)
value = torch.cat([value, encoder_hidden_states_value_proj], dim=1)
...
# Split the attention outputs.
hidden_states, encoder_hidden_states = (
hidden_states[:, : residual.shape[1]],
hidden_states[:, residual.shape[1] :],
)
总结
在这篇文章中,我们学习了 SD3 论文及源码中的主要内容。相比于 SD,SD3 做了两项较大的改进:用整流代替原来的 DDPM 中的训练目标;将去噪模型从 U-Net 变成了能更好地处理多模态信息的 MM-DiT。SD3 还在模型结构和训练目标上做了许多小改进,如调整训练噪声采样分布、使用二维位置编码。SD3 论文展示了多项大型消融实验的结果,证明当前的 SD3 是以最优配置训练得到的。SD3 可以在 Diffusers 中使用。当然,由于 SD3 的使用协议较为严格,我们需要做一些配置,才能在代码中使用 SD3。SD3 的采样流水线基本没变,原来 SD 的多数编辑方法能够无缝迁移过来。而 SD3 的去噪模型变动较大,和 U-Net 相关的编辑方法则无法直接用过来。在学习源码时,主要值得学习的是新 MM-DiT 模型中每个 Transformer 层的实现细节。
尽管 SD3 并没有提出新的流匹配方法,但其实验结果表明流匹配模型可能更适合文生图任务。作为研究者,受此启发,我们或许需要关注一下整流等流匹配模型,知道它们的思想,分析它们与原扩散模型训练目标的异同,以拓宽自己的视野。
Stable Diffusion 3.5
Introducing Stable Diffusion 3.5 — Stability AI
模型结构改进
对于 SD3.5-large 使用的 transformer 模型,其结构基本和 SD3-medium 里的相同,但有以下更改:
- QK normalization: 对于训练大型的 Transformer 模型,使用 QK normalization 已经成为标准做法,所以 SD3.5-large 也不例外。
- 双注意力层: 在 MMDiT 结构中,文本和图像两个模态都在使用同一个注意力层; 而 SD3.5-large 则使用了两个注意力层。
除此之外,文本编码器 (text encoder)、图像的变分自编码器 (VAE) 以及噪声调度器 (noise scheduler) 均和 SD3-medium 保持一致。