Chameleon
论文:https://arxiv.org/pdf/2405.09818
Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixed-modal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。
如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像 token 用蓝色表示

研究背景
Chameleon 开创了一种新的模型范式,生成理解统一架构。
多模态基础模型的一般特点是单独去建模不同的模块,一般而言通过 modal-specific 的编码器或者解码器。这带来了一个问题就是可能会限制模型跨模态整合信息的能力,以及生成可以包含任意图像和文本序列的多模态文档的能力。
因此,本文提出的 Chameleon 是一种混合模态基础模型,能够处理图文交织的混合序列,包括生成以及推理。这种模型能完整地做多模态相关的任务,包括图像生成,图像理解以及文本 LLM 能做的纯文本任务。Chameleon 的训练数据是所有模态的交错混合数据,即图像、文本和代码。且 Chameleon 以端到端的方式从头开始训练。
- Chameleon 把图片和文本数据全部使用了基于 token 的表征。通过将图像量化为离散 token,类似于文本中的单词,Chameleon 可以把一种 Transformer 架构应用于图像和文本 token 序列,且无需单独的图像/文本编码器或特定领域的解码器。这种 early-fusion 的方法,要求所有模态的数据从一开始就投影到共享的表征中,允许跨模态的理解和生成。但是也带来了重大的技术挑战,尤其是在优化稳定性和 Scaling 方面。
- Chameleon 通过架构创新和训练技术的结合来解决这些挑战。架构方面,对 Transformer 进行了一些修改,比如 query-key normalization 和 revised placement of layer norms。作者发现这对于混合模态设置中的稳定训练至关重要。训练技术方面,Chameleon 展示了如何将用于纯文本 LLM 的 SFT 方法应用于混合模态中。使用以上技术,本文成功训练了 Chameleon-34B,使用 Llama-2 5× 的 token 数。
- 作为一个生成理解统一模型,Chameleon 可以做图像理解任务 (visual question answering 和 image captioning)。在这个 benchmark 上超过了 Flamingo, IDEFICS 和 Llava-1.5。Chameleon 还可以做纯文本任务,在常识推理和阅读理解任务上与 Mixtral 8x7B 和 Gemini-Pro 匹敌。最令人印象深刻的是,Chameleon 在混合模态推理和生成方面解锁了全新的功能。
- 作者还通过一个精心设计的人工测试来评测对 open-ended prompts 的混合模态的长响应,并发现 Chameleon-34B 超过了 Gemini-Pro 和 GPT-4V:在成对比较中实现了对 Gemini-Pro 的 60.4% 偏好率以及对 GPT-4V 的 51.6% 偏好率。
下面展示了一个 Chameleon 生成的图文交织数据的样例:

Transfusion
Transfusion 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。Transfusion 的训练数据是图像文本混合模态的数据,训练的目标函数是 Diffusion Loss (常用于训练图像生成模型) 和 Language Modeling Loss (Next Token Prediction,常用于训练语言模型)。Transfusion 可以达到 7B 的参数量级。
实验表明,Transfusion 模型既可以做文本生成和图像生成任务,也可以做图像理解任务。且作者将其与具有相似功能的 Chameleon 模型进行了对比,Transfusion 模型明显优于 Chameleon。通过引入特定于模态的编码和解码层,可以进一步提高 Transfusion 模型的性能,甚至将每个图像压缩到只有 16 个 Patch。
将 Transfusion 扩展到 7B 参数和 2T 多模态 token 训练之后可以得到一个模型,该模型可以与相似尺度的扩散模型相媲美生成图像,与相似尺度的语言模型媲美生成文本。
研究背景
多模态生成模型需要能够感知、处理并生成离散元素 (比如 text 或 code) 和连续元素 (比如 image、audio 和 video 数据)。虽然使用 next-token prediction 技术训练的 LLM 主导离散模态的数据,那对于连续模态的数据而言,Diffusion Model 及其变体 Flow Matching 仍是最好的技术。
一个很自然的想法就是组合这两者,即 LLM 和 Diffusion Model。事实上已经有很多这样的尝试了。比如 DreamLLM,把预训练的 Diffusion Model 嫁接到 LLM 上。或者,在离散 token 上训练标准语言模型,以丢失信息为代价简化模型架构。
本文提出 Transfusion,通过训练单个模型 (不是一个 Diffusion Model,一个 LLM 嫁接)来预测离散 text token 和扩散连续 image ,可以在不损失信息的情况下完全集成两种模态。Transfusion 无缝集成了连续和离散两种模态。
Transfusion 为每个模态使用不同的目标:在 50% 文本和 50% 图像数据上预训练 Transformer 模型,文本使用 next token prediction,图像使用 diffusion。在训练的每一步,Transfusion 都使用两种模态的损失函数来训练。标准 Embedding 层将 text token 转换为向量,patchify 层把 image 表示为 patch 向量的序列。对 text token 应用 causal mode attention,对 image patch 应用 bi-directional attention。对于推理,引入了一种解码算法,它结合了语言模型文本生成的标准做法和来自扩散模型的图像生成。
Transfusion 是一个 7B transformer (包含约 0.27B 的 U-Net down/up 层),在 2T token 上进行训练。1T text token,1T image tokens (约 692M images)。在 GenEval 基准测试中,Transfusion 优于其他流行的模型,如 DALL-E 2 和 SDXL;与图像生成模型不同,Transfusion 还可以生成文本,且达到与 Llama 1 相同的性能水平。因此,Transfusion 是训练生成理解统一模型的一种很有前途的方法。
方法
Transfusion 是一个用两个目标训练的单一模型:语言建模和扩散。
语言建模损失就是给定一系列离散 tokens \(y = y_1, ..., y_n\) ,语言模型预测序列 \(P(y)\) 的概率。标准语言模型将 \(P(y)\) 分解为条件概率的乘积 \(\prod_{i=1}^n P_\theta(y_i|y_{<i})\) 。这就是一个自回归分类任务。next-token prediction 的目标函数,也可以说成是 LM Loss:
一旦经过训练之后,语言模型也可用于通过从模型分布 \(P_\theta\) 的 token 中采样 token 来生成文本,通常使用温度和 top-p 截断。
DDPM 学习逆转噪声添加的过程。与通常使用离散 token ( \(y\) ) 的语言模型不同,扩散模型在连续向量 ( \(x\) ) 上运行,这使它们特别适合涉及图像等连续数据的任务。扩散模型涉及 2 个过程:描述原始数据如何变成噪声的前向过程,以及模型学习执行的反向去噪过程。
- 前向过程
前向过程定义了如何创建噪声数据。给定一个数据点 \(\mathbf{x}_0\) ,定义一个马尔可夫链,它在 \(T\) 步上逐渐添加高斯噪声,创建一系列越来越嘈杂的版本 \(\mathbf{x}_1, \mathbf{x}_2, ..., \mathbf{x}_T\) 。每个步骤的定义是: \(q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t}\mathbf{x}_{t-1}, \beta_t\mathbf{I})\) ,其中 \(\beta_t\) 根据预定义的噪声时间表随时间增加。这个过程可以重参数化,允许使用单个高斯噪声样本 \(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\) 从 \(\mathbf{x}_0\) 直接采样 \(\mathbf{x}_t\) :
其中, \(\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)\) 。
- 反向过程
训练扩散模型执行反向过程 \(p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)\) ,学习逐步去噪数据。训练一个参数为 \(\theta\) 的模型 \(\epsilon_\theta(\cdot)\) 来估计给定噪声数据 \(\mathbf{x}_t\) 和时间步 \(t\) 的噪声 \(\epsilon\) 。在实践中,模型通常以额外的上下文信息 \(c\) 为条件,例如在生成图像时的 caption。因此,通过最小化均方误差损失来优化噪声预测模型的参数:
- 噪声 schedule
在创建噪声 \(\mathbf{x}_t\) 时, \(\bar{\alpha}_t\) 决定了噪声方差,本文基本遵循 \(\sqrt{\bar{\alpha}_t} \approx \cos(\frac{t}{T}\cdot\frac{\pi}{2})\) 。
- 推理
解码是迭代完成的,每一步处理一些噪声。从 \(\mathbf{x}_T\) 处的纯高斯噪声开始,模型 \(\boldsymbol{\epsilon}_{\theta}(\mathbf{x}_t, t, c)\) 预测在时间步 \(t\) 积累的噪声。然后根据噪声调度对预测的噪声进行缩放,从 \(\mathbf{x}_t\) 中去除预测噪声的比例量,生成 \(\mathbf{x}_{t-1}\) 。Classifier-free guidance (CFG) 将以上下文 \(c\) 为条件的模型的预测与无条件得预测进行对比来改进生成,但代价是计算量加倍。
数据准备
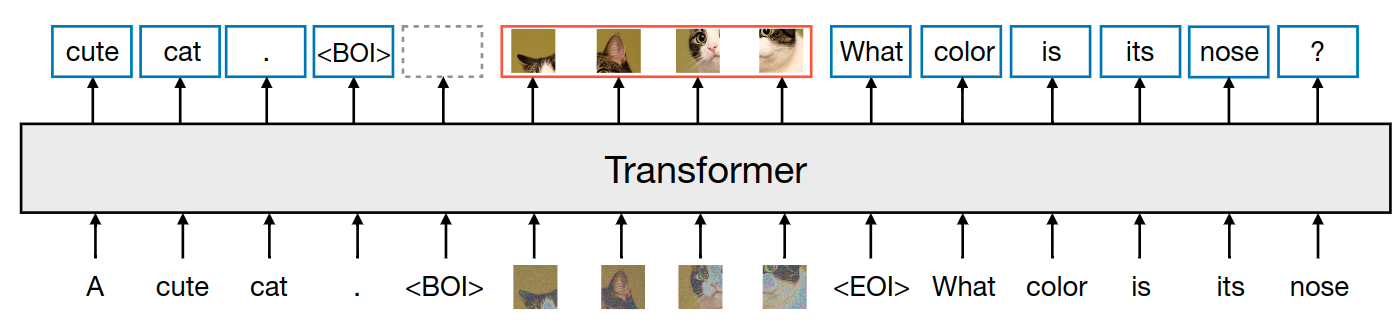
作者对两种模态的数据进行了实验:离散的文本和连续的图像。每个文本字符串都被标记为来自固定词汇表的离散 token 序列,其中每个 token 表示为一个整数。每个图像都使用 VAE 编码为 latent patch,其中每个 patch 表示为一个连续向量。patch 从左到右的从上到下排序。也就是每个图像最终都会转化为一系列的 patch 向量。作者在把这些向量插入到文本序列之前,使用特殊的 BOI 作为开始 token,EOI 作为结束 token,围绕图像序列。
因此,最终序列的样子是:包含了离散元素 (表示文本 token 的整数) 和连续元素 (表示图像 patch 的向量)。
模型架构
模型参数的绝大部分都属于一个 Transformer,它输入一个序列,输出一个序列,无论模态如何。为了将数据转换到这个空间,作者对于不同模态的数据使用了具有非共享参数的特定的组件。
对于文本而言,文本是嵌入矩阵,将每个输入整数转换为向量空间,每个输出向量转换为词汇表上的离散分布。
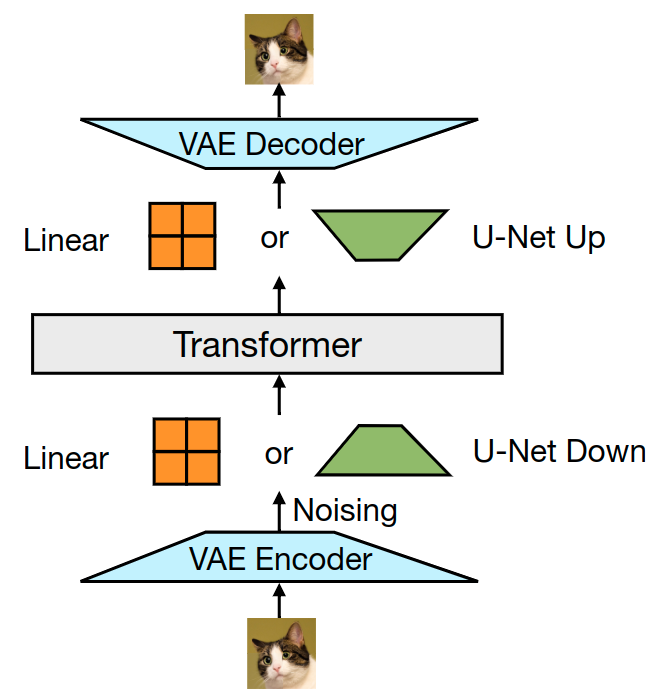
对于图像,将 \(k\times k\) 的 patch 转化为单个向量的方法,作者试了 2 种:1) 线性层;2) U-Net Up 或者 Down 层。如下图所示。
注意力机制
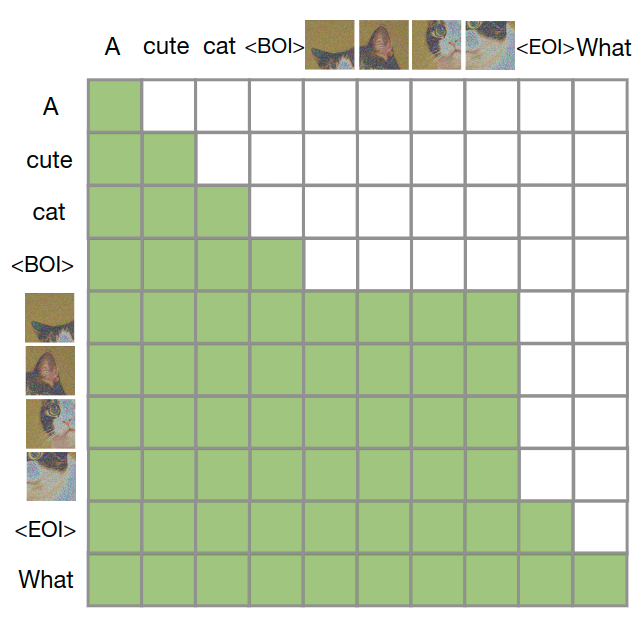
Transfusion 模型结合了因果注意力和双向注意力。文本的处理通常使用因果注意力,以防止未来信息泄露,而图像通常使用不受限制的双向注意力。Transfusion 通过对序列中的每个元素应用因果注意力,同时在每个单独图像元素之间应用双向注意力,将这两种注意力模式结合起来。这意味着每个图像 patch 可以关注同一图像中的所有其他 patch,但只能关注序列中之前出现的其他图像 patch 或文本。启用图像内注意力显著提高了模型性能。下图显示了一个示例 Transfusion attention mask。
为了训练本文模型,作者将语言建模目标 LM Loss 应用于文本标记的预测,将扩散目标 DDPM Loss 应用于图像 patch 的预测。LM Loss 是 per-token 计算的,而 DDPM Loss 是 per-image 计算的,这可能会跨越序列中的多个元素 (图像 patch)。具体来说,根据扩散过程为每个输入 \(\mathbf{x}_0\) 添加噪声 \(\epsilon\) ,在 patchification 之前产生 \(\mathbf{x}_t\) ,然后计算图像级扩散损失。通过简单地将每个模态上计算的损失与平衡系数 \(\lambda\) 结合起来:
这个目标函数将离散分布损失与连续分布损失结合以优化相同的模型。未来作者将继续探索将扩散替换为流匹配。
推理过程
Transfusion 的解码算法在两种模式之间切换:LM 和 Diffusion。在 LM 模式下,遵循从预测分布中逐 token 采样。当采样 BOI 令牌时,解码算法切换到扩散模式,从扩散模型中解码。具体来说,以 \(n\) 个图像 patch 的形式附加到输入序列 (取决于所需的图像大小),并去噪 \(T\) 步。在每一步 \(t\),采用噪声预测并使用它来生成 \(\mathbf{x}_{t-1}\) ,然后覆盖序列中的 \(\mathbf{x}_t\) 。一旦扩散过程结束,将 EOI 标记附加到预测图像上,并转换回 LM 模式。该算法能够生成任何混合文本和图像模式。
Janus
DeepSeek 团队生成理解统一架构代表作 Janus 以及后续扩大版本 Janus-Pro。
本文介绍 DeepSeek 团队的 Janus 系列模型 (Janus 和 Janus-Pro)。Janus 系列是 DeepSeek 多模态团队的作品,是一种既能做图像理解,又可以做图像生成任务的 Transformer 模型。这类模型存在的问题之一是:由于多模态理解和生成所需的信息粒度不同,这种方法可能会导致次优的性能。
为了解决这个问题,Janus 仍利用单个统一的 Transformer,但是将视觉编码解耦为单独的路径。这种解耦不仅缓解了视觉编码器在理解和生成中的作用之间的冲突,而且增强了框架的灵活性。比如多模态理解和生成组件都可以独立选择最合适的编码方法。
Janus-Pro 是先前工作 Janus 的高级版本。Janus-Pro 具体特点:
- 优化的训练策略;
- 扩展训练数据;
- 更大的模型大小。
通过这些改进,Janus-Pro 在多模态理解和文本到图像指令跟踪能力方面都取得了显著进步,同时还提高了文生图任务的稳定性。
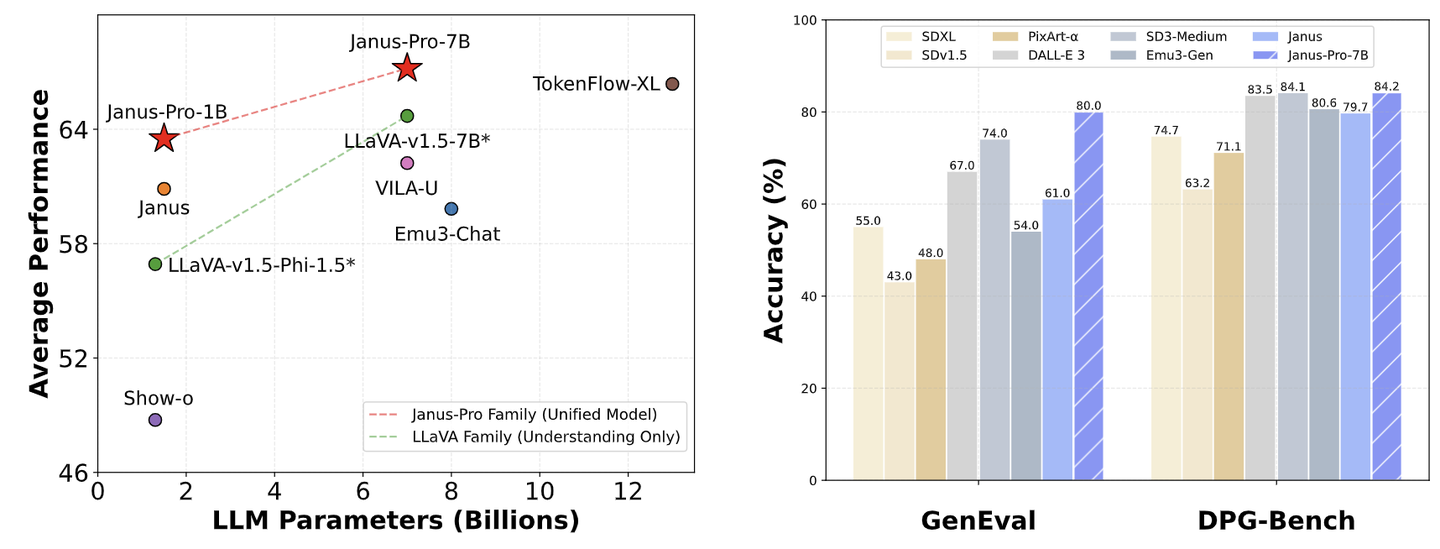
详情可以参考:Janus 系列
Show-o
论文名称:Show-o: One Single Transformer to Unify Multimodal Understanding and Generation (ICLR 2025)
项目主页:github.com/showlab/Show-o
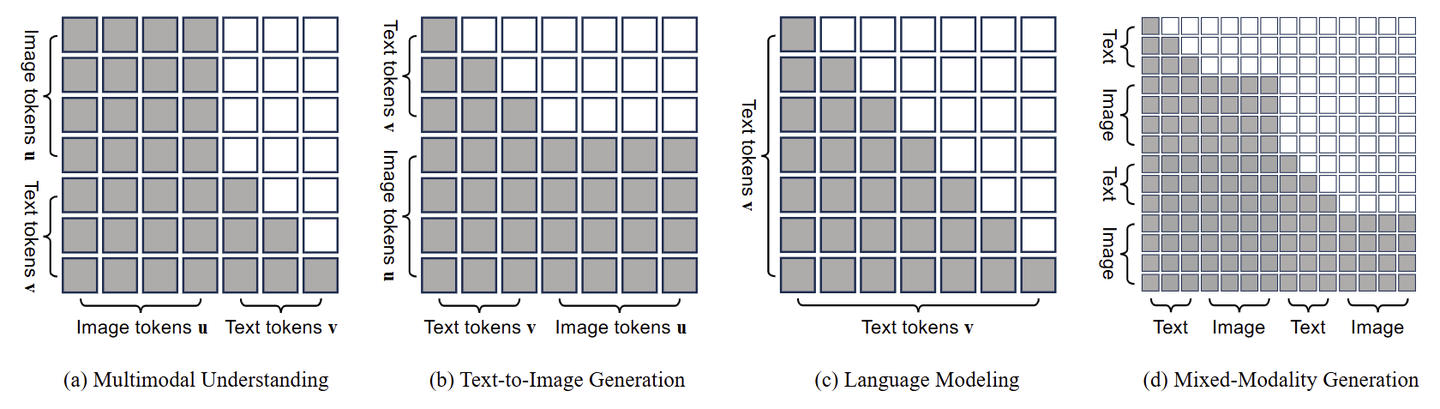
用一个统一的模型 (Unified Model) 来处理多模态理解和生成任务的常见做法如下图(c) 所示,比如 Next-GPT, SEED-X,使用模型独立处理视觉域和语言域。另一个最近很热门的方向是:使用单个 Single Transformer 同时处理理解和生成任务。
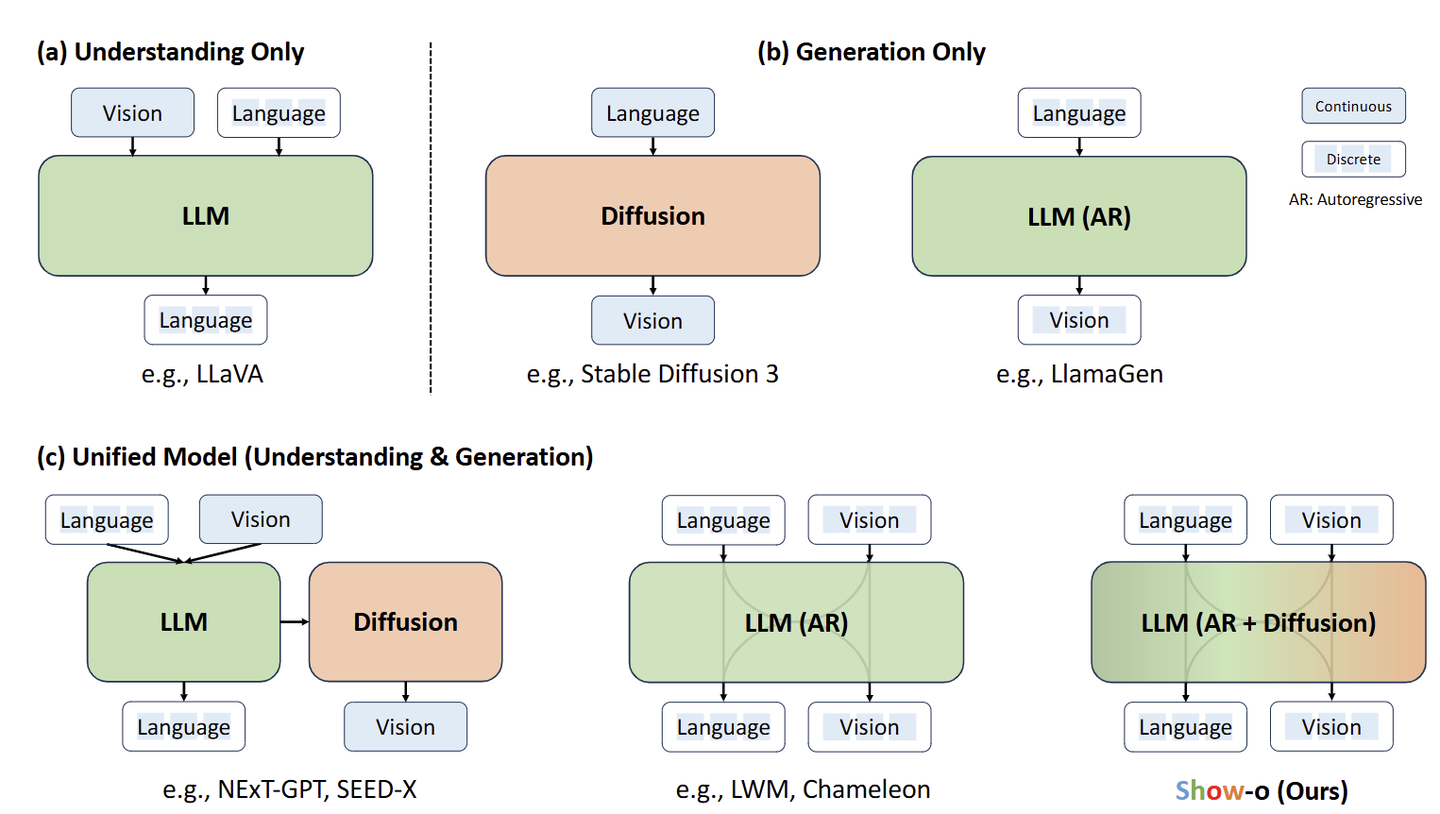
Chameleon 证明了这点,即:早期融合不同模态的数据,通过相同的自回归建模方式生成文本和图像 token。自回归预测图像的一个明显的瓶颈是:
Causal attention 需要大量采样步骤,尤其是处理高分辨率图像或者视频时。扩散模型在视觉生成方面表现出比自回归模型更好的潜力。
这促使作者思考:单个 Single Transformer 能否同时涉及自回归和扩散建模?
Show-o 设想了一种新的范式,即文本被表示为 discrete tokens,用大语言模型 (LLM) 自回归建模。图像被表示为连续的,使用 Denoising Diffusion Model 进行建模。
然而,由于离散文本 token 和连续图像表征之间的显着差异,将这两种不同的技术集成到一个单一网络中并非易事。另一个挑战是,现有的最先进的扩散模型通常依赖于 2 个不同的模型,即 Text Encoder 对文本 Condition 信息进行编码,以及用于预测噪声的去噪网络。
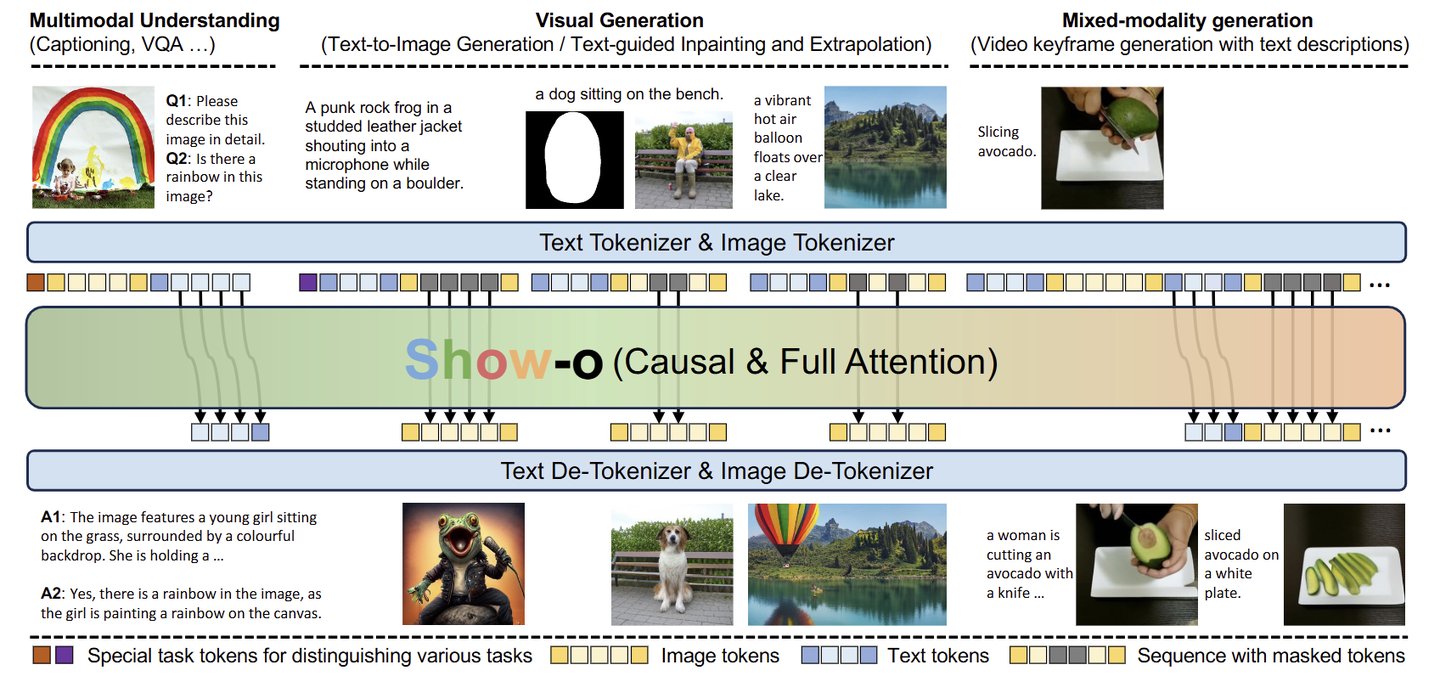
Show-o 可以同时处理理解和生成任务,使用自回归-扩散混合建模。Show-o 建立在预训练 LLM 上,继承了基于文本的推理的自回归建模能力。Show-o 还采用 discrete denoising diffusion model 对离散图像 token 进行建模。为了适应任务的不同输入数据和变化,采用文本 tokenizer 和图像 tokenizer 将它们编码为离散 token,并进一步提出了统一的提示策略,将这些 token 作为输入处理。因此,给定一个伴随问题的图像,Show-o 自回归给出答案。当只提供文本 token 时,Show-o 以离散去噪扩散的风格生成图像。
Show-o 基于 MaskGIT。MaskGIT 是一种 mask token prediction 的方法。
Show-o 的最终目标是开发一个统一模型,涉及自回归和扩散建模,且可以联合多模态理解和生成。
核心问题:
- 如何定义模型的输入和输出空间?
- 如何统一来自不同模态的各种输入数据?
- 如何在单个 Transformer 中涉及自回归和扩散建模?
- 如何有效地训练这样一个统一的模型?
主要方法
Tokenization
Show-o 建立在预训练的 LLM 上,在离散空间上执行统一学习是一种自然的方式。需要维护一个统一的词汇表,其中包括离散文本和图像 token。统一模型的任务是预测离散 token。
Text Tokenization
Show-o 基于预训练的 LLM,使用相同的 tokenizer 进行文本数据标记化,无需任何修改。
Image Tokenization
按照 MAGVIT-v2的做法,训练一个 quantizer,维持一个 \(K=8192\) 的 codebook,把 \(256×256\) 图片编码为 \(16×16\) 的 discrete token。按照 MAGVIT-v2 的原因是它易于微调,可以很容易变成一个 video tokenizer。
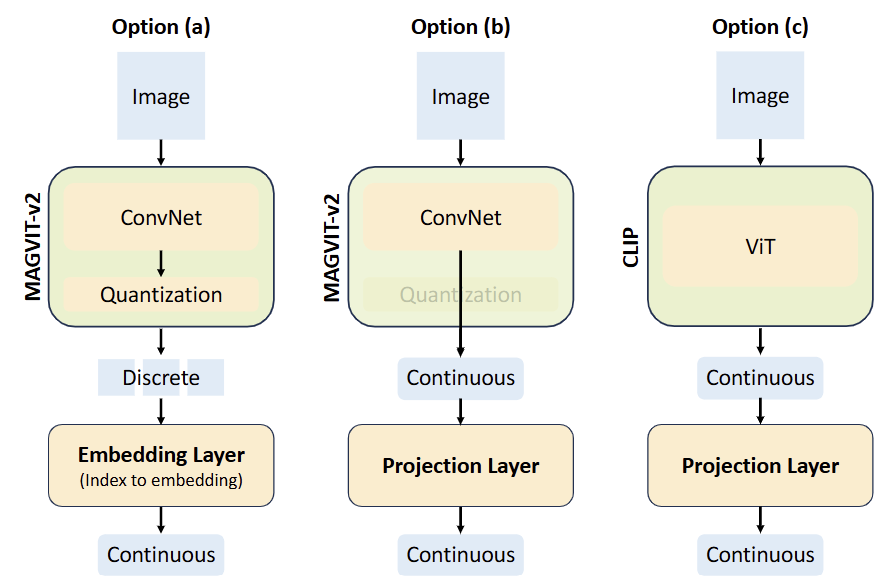
还有 2 种做法是使用 continuous 的图片表征,如图 (b),(c) 所示。Show-o 默认使用 discrete image tokens 用于理解和生成。
模型架构
Show-o 继承了现有 LLM 的架构,除了添加 QK-Norm 操作外,没有任何架构修改。作者使用预训练 LLM 的权重初始化 Show-o。
Unified Prompting 策略
为了统一训练多模态理解和生成,作者设计了一种 Unified Prompting 策略来格式化各种输入数据。给定 image-text pair,首先 tokenized 变为 \(M\) 个 image tokens \(\textbf{u}=\{u_i\}_{i=1}^M\) 和 \(N\) 个 text tokens \(\textbf{v}=\{v_i\}_{i=1}^N\) 。根据下图所示的格式的任务类型将它们形成输入序列。
[MMU] 和 [T2I] 是预定义的 task token,表示输入序列的学习任务。
[SOT] 和 [EOT] 分别作为表示 text token 的开始和结束 token。
[SOI] 和 [EOI] 分别作为表示 image token 的开始和结束 token。
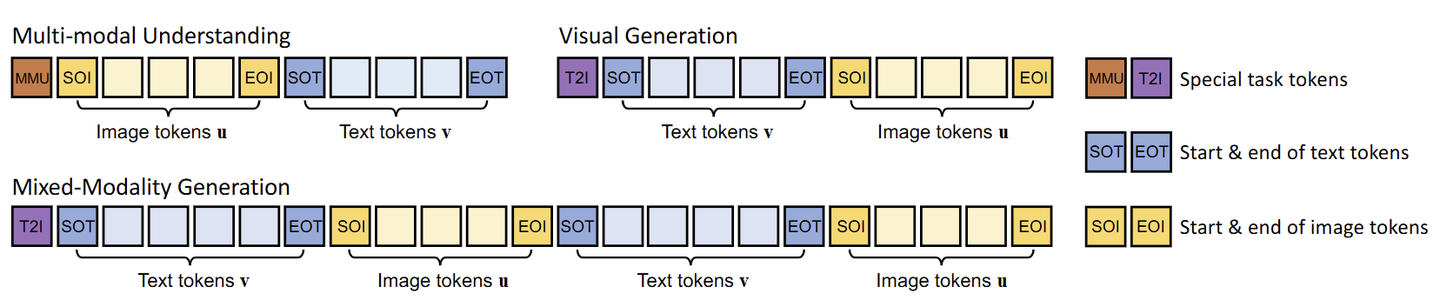
使用这种提示设计可以有效编码各种输入数据进行多模态理解、文生图和混合模态生成。一旦训练好,就可以相应地提示 Show-o 以处理各种视觉语言任务,包括视觉问答和文生图。
Omni-Attention 机制
Show-o 的注意力机制并非全是 Causal Attention,也并非全是 Full Attention,而是一种综合注意力机制,根据输入序列的格式自适应地混合和更改。
如下图所示,Show-o 能够以不同的方式对各种类型的信号进行建模。Show-o 通过 Causal Attention 对序列中的文本 token \(\textbf{v}\) 进行建模。对于图像 token \(\textbf{u}\) ,Show-o 通过 Full Attention 建模它们。给定一个格式化的输入序列:
- 多模态理解中 (图 (a)),文本 token 可关注所有先前的图像 token。
- 文生图中 (图 (b)),图像 token 能够与所有先前的文本 token 交互。
- 文本建模中 (图 (c)),退化为 Causal Attention。
模型训练
为了执行自回归和(离散)扩散建模,Show-o 采用了 2 个训练目标:
- Next Token Prediction (NTP)
- Mask Token Prediction (MTP)
给定 \(M\) 个 image tokens \(\mathbf{u} = \{u_1, u_2, \cdots, u_M\}\) , \(N\) 个 text tokens \(\mathbf{v} = \{v_1, v_2, \cdots, v_N\}\) 。
NTP 使用语言建模损失来最大化文本 token 可能性:
式中, \(p(\cdot | \cdot)\) 代表条件概率, \(\theta\) 为 Show-o 的权重。
MTP 作为另一个训练目标,可以无缝集成到 discrete diffusion modeling 中。对于输入序列中的 \(M\) 个 image tokens \(\mathbf{u} = \{u_1, u_2, \cdots, u_M\}\) , 首先以一定的比例 (受 timestep 控制) 随机将图像 token 随机替换为 [MASK] token,得到 \(u_{*}\) 。然后目标是以 unmasked 区域和 text token 为 condition,重建原始的图像 token。可以写成:
注意到这个损失函数仅应用于 masked token。具体来说,以 unmasked image token 和所有 text token 为条件,重建那些 masked image tokens。遵循 classifier-free guidance 的做法,以一定的概率用空文本 "" 随机替换 conditioned text token。
给定 1 个 Batch 的输入序列,总的损失函数:
其中, \(\alpha\) 是超参数。
训练策略
Show-o 采用 3 阶段的方法逐步有效地训练 Show-o:
- Stage 1:Image Token Embedding 以及像素依赖关系的学习。使用 RefinedWeb 数据集来训练 Show-o 以保持语言建模能力。同时,采用 ImageNet-1K 数据和图像-文本对分别训练 Show-o 进行类条件图像生成和图像字幕。作者直接使用 ImageNet-1K 中的类名作为文本输入来学习类条件图像生成。这一阶段主要涉及学习 learnable embeddings 为今后的离散图像 token 打底,还有图像生成的像素依赖关系,以及图文之间的对齐来进行图像字幕。
- Stage 2:多模态理解和生成的图文对齐。基于预训练的权重,继续训练文生图。这一阶段主要关注图像字幕和文生图中的图像和文本对齐。
- Stage 3:高质量的数据微调。结合高质量图文对进行文生图,以及教学数据进行多模态理解和混合模态生成。
推理
推理中,Show-o 涉及 2 种类型的预测,即 text token 和 image token。
在多模态理解中,给定图像和问题,text token 是从具有更高置信度的预测 token 中自回归采样的。
在视觉生成中,生成图像需要 \(T\) 步。最初,是 \(N\) 个 text token 作为 condition,以及 \(M\) 个 [MASK] token 作为输入。然后 Show-o 为每个 [MASK] token 预测一个 logit \(\ell^t \) ,其中 \(t\) 是时间步。每个 [MASK] token 的最终预测 logit 使用 conditional logit \(\ell^t_{c}\) 和 masked token 的 unconditional logit \(\ell^t_u\) ,通过下式计算:
其中, \(w\) 是 guidance scale。
每一步保留置信度更高的 image token,同时用 [MASK] token 替换置信度较低的 image token,这些 token 随后都被反馈到 Show-o 以进行下一轮预测。下图提供了一个说明。这个去噪过程需要 \(T\) 步,类似于 Diffusion Model 的方法。

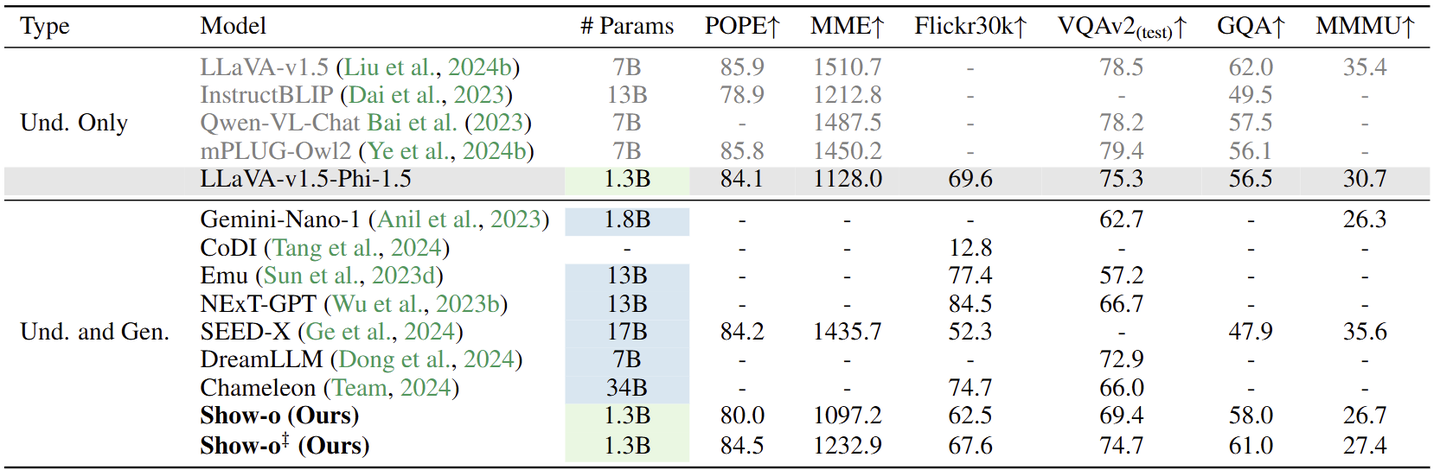
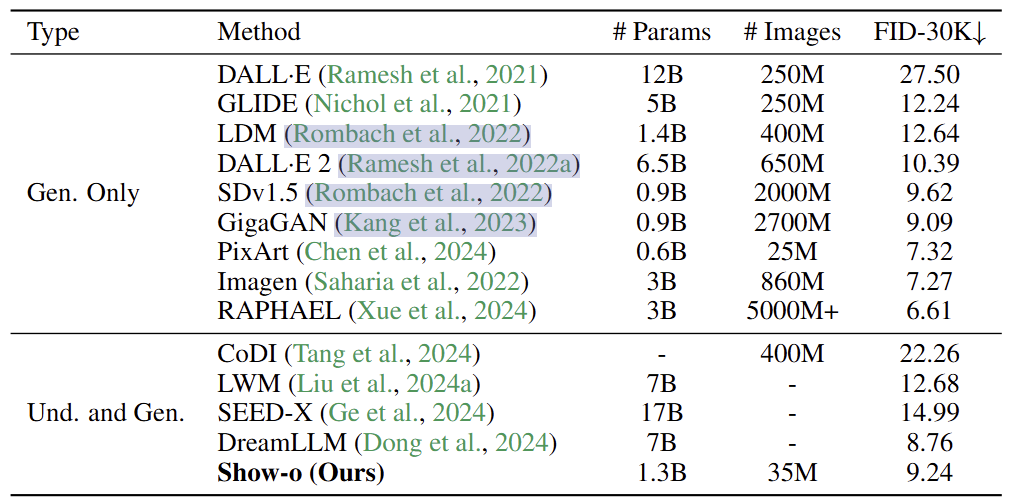
1.7 Show-o 实验设置
数据:3种类型的数据:
- Text-only Data:使用公开可用的 RefinedWeb 数据集来保留预训练的 LLM 的文本推理能力。
- Image Data with Class Names:使用来自 ImageNet1K 数据集的 1.28M 图像来学习像素依赖关系。
- Image-Text Data:多模态理解和生成,从公开可用的数据集中组装了大约 35M 的图像-文本对,包括 CC12M 、SA1B 和 LAION-aesthetics-12M。此外,通过结合 DataComp 和 COYO700M 以及一些过滤策略,进一步将数据规模增加到 2.0B 左右。使用 ShareGPT4V 来重新描述这些数据集。此外,LAION-aesthetics-12M 和 JourneyDB 作为用于最终微调的高质量数据集。继 LLaVA-v1.5 之后,结合了 LLaVA-Pretrain558K 和 LLaVA-v1.5-mix-665K 做指令微调。此外,GenHowTo 用于混合模态生成。
评测
多模态理解
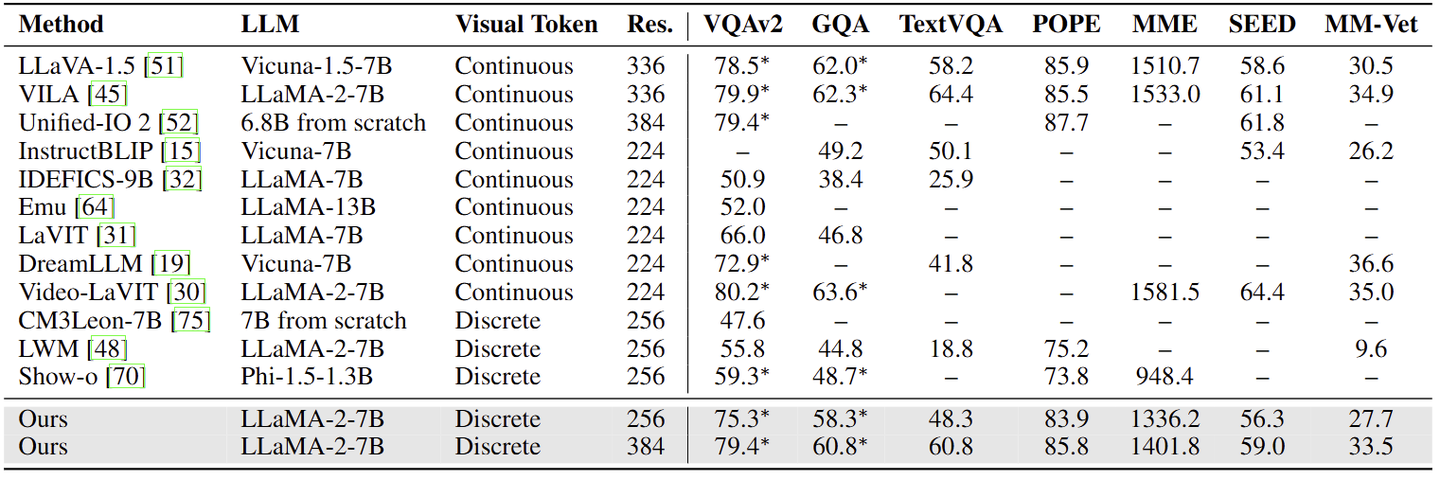
视觉生成--MSCOCO 30K 结果
GenEval 结果
VILA-U
论文名称:VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation (ICLR 2025)
项目主页:github.com/mit-han-lab/vila-u
结合视觉和语言模式的一个方向是多模态理解,另一个重要研究方向是视觉生成。文本引导图像生成有 2 种流行的方法。一种方法是使用 Diffusion Model。另一种方法通过 Vector Quantization (VQ) 将视觉内容转换为 discrete tokens,然后利用自回归 Transformer 进行高质量和多样化的生成。
一个新兴趋势是将这些技术统一到一个多模态框架中。有 2 种实现这种统一的主要方法。许多 VLM维护一个面向理解的框架,并将生成任务卸载到外部扩散模型中。这种不相交的方法增加了基础设施设计的复杂性。可用的大规模基础模型的 training pipeline 和 development system 已经针对 Next Token Prediction 的模型进行了高度优化。设计一个新的堆栈来支持扩散模型会产生重大的工程成本。为了规避这样的成本,现在的趋势是设计一个端到端的自回归框架。VLM 的趋势采用 VQ Encoder 将视觉输入转换为 discrete tokens,并以与语言数据相同的 Next Token Prediction 的方式处理视觉 token。但是,用 VQ token 替换连续 token 通常会导致下游视觉感知任务的严重性能下降。
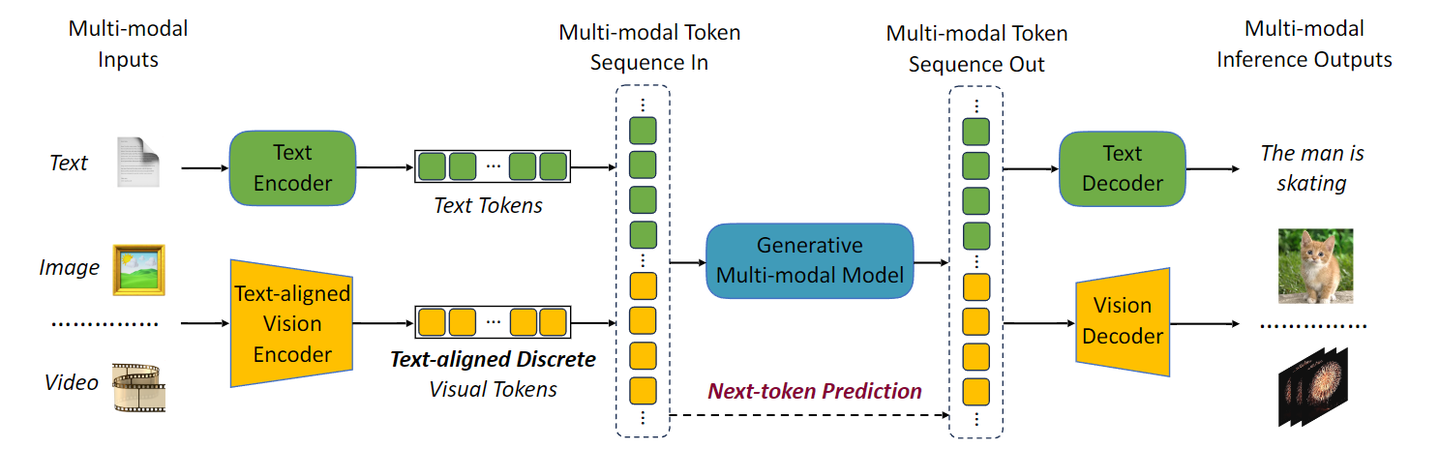
如下图所示,VILA-U 是一个端到端的自回归框架,对于视觉和文本输入具有统一的 Next Token Prediction 训练目标。VILA-U 是一种生成理解统一架构,在视觉语言理解和生成任务上取得具有竞争力的性能,同时不需要借助扩散模型等外部组件。
VILA-U 确定关键的 2 点:
- 现有端到端 VLM 视觉理解性能不佳的原因是:discrete VQ tokens 只在 Reconstruction Loss 上训练,与文本输入不对齐。因此,在 VQ vision 模型预训练中引入文本对齐以增强感知能力至关重要。
- 如果在具有足够大小的高质量数据语料库上进行训练,自回归图像生成可以获得与扩散模型相似的质量。
基于这 2 点,VILA-U 的 vision 模型通过 vector quantization 将视觉输入转化为 discrete token,并且使用 Contrastive Learning 将这些 token 与文本输入对齐。
主要方法
VILA-U 的关键之一是视觉架构 Unified Foundation Vision Tower,它将视觉输入转换为与文本对齐的 discrete token。也就是说,Unified Foundation Vision Tower 在训练的时候,考虑了图像与文本的对齐。VILA-U 的另一个关键之一是统一的多模态生成式训练方案。VILA-U 的方案如图 1 所示。视觉输入被 tokenized 成 discrete tokens,与 text token 拼接在一起,形成多模态的输入序列。所有的 token 都按照 next-token prediction 训练。推理的时候,文本 token 使用 text detokenizer 输出,视觉 token 使用 vision tower decoder,形成多模态输出。
为了支持视觉理解和生成任务,VILA-U 首先构建了一个 Unified Foundation Vision Tower 来获取视觉特征。
在训练中,VILA-U 使用了
- 文本-图像之间的 Contrastive Loss,
- 基于 Vector Quantization 的图像 Reconstruction Loss。
使得 Unified Foundation Vision Tower 同时具有文本对齐和 discrete tokenization 的能力。
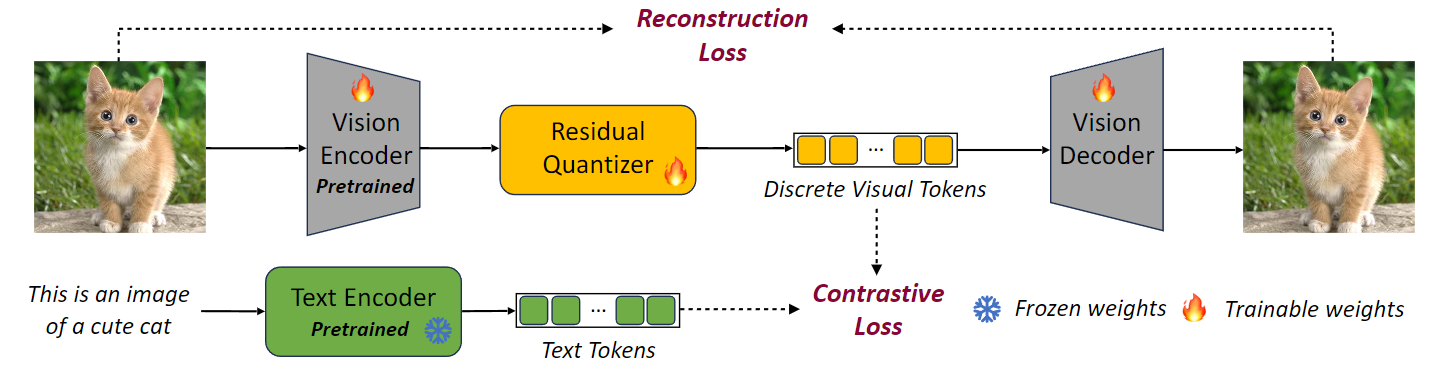
如下图所示,从图像中提取的特征主要是通过 Residual Quantization 离散化的。一方面,离散的视觉特征输入解码器来重建图像并计算重建损失;另一方面,离散视觉特征与文本编码器提供的文本特征之间计算图像-文本对比损失。
但是,在实践中作者发现直接这样训练有问题 (对比损失和重建损失的直接组合不能收敛)。因为图文对齐和重建任务分别需要高级语义特征和低级外观性特征。使用 2 个目标从头开始训练可能会导致相互冲突的目标。从头开始训练 Unified Foundation Vision Tower 导致ImageNet 上 Zero-Shot 图像分类的 Top-1 精度仅为 5%。
为此,作者尝试了不同的 training recipe。本文使用的 training recipe 不是同时学习 2 个目标,而是首先为模型配备文本图像对齐能力,然后在保持对齐能力的同时学习重建。作者使用 CLIP 预训练权重初始化 vision encoder 和 text encoder,以确保良好的文本图像对齐。接下来,冻结文本编码器,并保持所有视觉模型使用 Contrastive 和 Reconstruction Loss 训练。这种训练方法收敛很快并产生强大的性能。预训练的 CLIP 权重包含高级先验,对于从头开始学习来说既困难又计算成本高。使用这些权重进行初始化可以使视觉编码器更快、更轻松地结合低级和高级特征。通过这种训练配方,可以有效地训练出具有良好文本对齐和图像重建的视觉模型。具体而言,使用加权和来组合图文对比损失和 VQ 图像重建损失:
其中, \(w_{contra}=1,w_{recon}=1\) 。
Residual Vector Quantization
VILA-U 的视觉特征是离散化,因此其表征能力在很大程度上取决于 Quantizer Codebook 的大小。由于希望它们同时包含高级特征和低级特征,因此向量特征空间中需要更多的容量,需要 Codebook 比较大。
VILA-U 按照 RQ-VAE的做法使用 Residual Vector Quantization,把一个向量 \(\mathbf{z}\) 离散化成 \(D\) 个 discrete tokens:
其中, \(\mathcal{C}\) 是 codebook, \(K = |\mathcal{C}|\) 和 \(k_d\) 是向量 \(\mathbf{z}\) 在深度 \(d\) 时的 code 值。从 \(\mathbf{r}_0 = \mathbf{z}\) 开始,对每一维度深度 \(d\) 递归地执行向量量化:
其中, \(\mathbf{e}\) 为 codebook embedding table, \(\mathcal{Q}\) 是标准向量量化。
其中, \(\mathbf{z}\) 的 Quantized Vector 是所有深度的求和: \(\widehat{\mathbf{z}} = \sum_{i = 1}^D\mathbf{e}\left(k_i\right)\) 。
生成式预训练
视觉编码器按顺序处理视觉输入,生成一个一维 token 序列。然后将这个序列与文本 token 连接起来形成一个多模态序列。为了区分模态并实现视觉内容生成,在图像 token 的开始和结束处插入特殊标记:<image_start> 和 <image_end>,在视频 token 的开始和结束位置插入 <video_start> 和 <video_end>。视频 token 是多帧图像标记的直接连接。
预训练数据格式
[image, text], [text, image], 和 [text, video],只把 supervision loss 加到后面的模态数据。
还使用交错 text 和 image 连接形式来增强理解,supervision loss 仅应用于 text。
出于效率原因,在预训练期间排除了 [video, text] 形式,因为发现在 supervised fine-tuning 期间结合它可以有效地产生出色的视频理解能力。
训练目标
对于 text tokens,使用:
其中, \(T\) 是多模态序列的总长度, \(i\) 只计算 text token 存在的位置。
对于 visual tokens,使用:
其中, \(T\) 是多模态序列的总长度, \(j\) 只计算 visual token 存在的位置。按照 RQ-VAE[2]的做法使用一个 depth transformer 自回归地预测 \(D\) 个 residual tokens。
实验结果
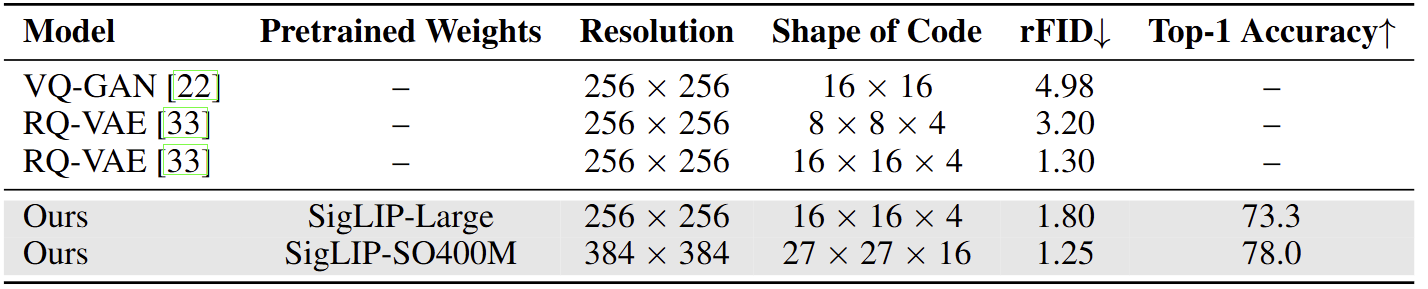
Unified Foundation Vision Tower
ImageNet 上 Zero-Shot 图像分类 Top-1 精度以及重建 FID (rFID),以衡量模型的重建和文本对齐能力。模型实现了比 VQ-GAN 更好的重建结果。rFID 略逊于 RQ-VAE,这是意料之中的,因为在训练期间引入对比损失,目的是增强图像理解,但会导致重建质量下降。
多模态理解
视觉生成
UniFluid
论文名称:Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
UniFluid 是一个用于统一视觉生成和理解的纯自回归框架,不受矢量量化 (vector quantization, VQ) 的限制。UniFluid 利用连续的视觉 token 来联合处理视觉语言生成和理解任务。
UniFluid 基于在大规模文本语料库上预训练的 Gemma,使用成对的图像-文本数据进行训练,得到强大的视觉生成和理解能力,并进一步允许这两个任务在单个架构中相互受益。
具体来说,UniFluid 采用统一的自回归框架,其中文本和连续视觉输入都会被编码到同一个空间的 token 里面,实现图像生成和理解任务的联合训练。
UniFluid 证明了统一训练策略的几个关键优势。作者发现尽管这 2 个任务之间存在 trade-off,但经过仔细调整的 training recipe 可以让任务相互支持并优于单任务的 baseline。这个发现说明高效地去平衡任务之间的损失,可以使得 Unified Model 的结果优于单任务模型或与其性能相当。
此外,预训练的 LLM Backbone 的选择显著影响视觉生成性能。作者还发现,使用随机生成顺序对于高质量的图像生成至关重要,但是对于理解任务不太关键。UniFluid 表现出很强的泛化能力和迁移性,在图像编辑以及各种视觉语言理解 Benchmark 中实现了令人信服的结果。
主要方法
UniFluid 模型以图像和文本序列作为输入,在生成和理解任务上实现联合训练,使用 next-token prediction 作为训练目标。
使用连续 token 进行联合自回归训练
UniFluid 用自回归范式在单个框架内统一视觉理解和生成。给定一个有序的 token 序列 \(X = \{x^1, ..., x^n\}\),自回归模型将联合概率分布分解为条件概率的乘积,将生成任务构建为顺序 next-token prediction 的建模,这个方案表示为:\(p(X) = \prod_{i=1}^n p(x^i \mid x^1, ..., x^{i-1})\)。这种自回归方法适用于离散 token 和连续 token。
UniFluid 利用这个性质,在 decoder-only 的架构下生成连续的视觉 token。文本和图像 token 都被视为统一序列中的元素,它们各自的 logits 由 Transformer Backbone 以自回归的方式迭代预测。
为了适应文本和图像的不同性质,UniFluid 采用 modality-specific 的预测头来计算每个模态的 loss 以及采样。这种方法允许模型通过统一的训练过程学习 shared representation space,促进不同模态之间的协同学习,实现视觉生成和理解之间的无缝转换。
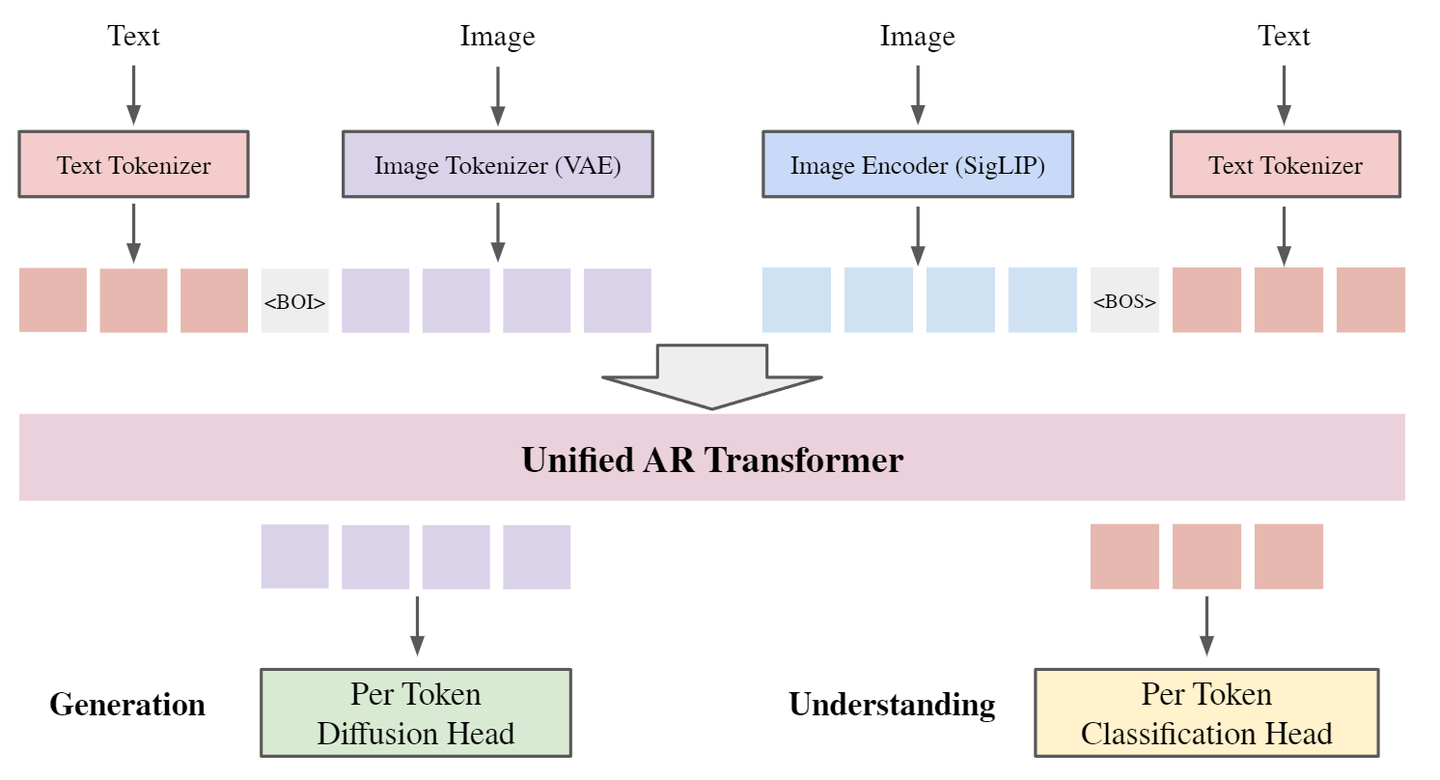
模型架构
如上图所示,UniFluid 采用统一框架,其中文本和图像输入都被 tokenized,投影到共享 embedding space。这允许其使用 decoder-only transformer 作为自回归任务的 Backbone。
- 文本生成
text 输入使用 SentencePiece tokenizer 进行 tokenization,得到词汇量为 \(V\) 的离散 token。
- 图像生成
image 通过连续的 VAE Encoder 编码为连续的视觉 token。
- 图像理解
image 通过 SigLIP 作为一个单独的 image Encoder,从视觉输入中提取高级信息。
- 特定于模态的 head
UniFluid 使用 Classification Head 将 Transformer 输出的文本 logits 转换为分布,Diffusion Head 将 Transformer 输出的图像 logits 转换为每个 token 的概率分布。
text 作为固有的线性序列的结构,与 LLM 的标准一维位置编码可以很好地对齐,足以用于文本建模和图像理解任务。
image 是种二维空间结构。为了捕捉这种固有的 2D 性质,作者结合了可学习的 2D 位置编码,这些 embedding 被添加到图像 token embedding 中。
为了实现随机顺序生成,UniFluid 还将下一个预测标记的位置编码添加到每个图像 token 中。
为了提高模型启动和引导图像生成的能力,将 "Beginning of Image" (BOI) token 添加到连续 image token 序列中。这个 BOI 令牌充当一个独立的信号,表示视觉生成过程开始。鉴于生成的 image token 的序列长度是预定义的 (256 × 256 图像,256 token),因此无需显式的 "End of Image" token。
具体实现
- 对离散文本 token 使用的 Classification Head
使用与 Gemma 相同的 SentencePiece tokenizer。Transformer 的文本输出 logits 被转换为词汇表上的分类概率分布。应用标准交叉熵损失 \(L_{Text}\) ,以优化这些离散文本 token 的预测。
- 对连续视觉 token 使用的 Diffusion Head
使用与 Fluid 相同的连续 tokenizer 将 \(256×256 \)的图像嵌入到 \(32×32×4\) 的连续 token,并使用 patch size 2 将 4 个 token 合为一个。
为了对这些连续视觉 token 的 per-token distribution 进行建模,UniFluid 使用 MAR 做法,通过轻量级 MLP 作为 Diffusion Head。采用相同的扩散过程和损失函数 \(L_{Visual}\) 。对于理解任务,输入图像分辨率为 \(224×224\),使用 SigLIP 作为图像编码器。SigLIP 特征训练期间仅作为理解任务的 prefix,它们上也没加 loss。
图像理解训练配置
对于图像理解任务,模型提供 image embedding 和 question token 作为输入前缀。作者遵循 PaliGemma 对图像和问题 token 应用 bidirectional attention mask。将 causal attention mask 应用于答案 token,确保模型在自回归生成期间只关注先前的答案 token。text token 的损失 \(L_{Text}\) 是专门为答案文本 token 计算的。
图像生成训练配置
对于图像生成任务,text prompt 作为条件输入。为了保持适当的信息流,作者对 text prompt token 使用 bidirectional attention mask,使它们能够关注所有其他文本 token。对图像 token 应用 causal attention mask,确保每个图像 token 只关注前面的图像 token。视觉 token loss \(L_{Visual}\) 是在生成的图像 token 位置计算的。
Unified 的损失函数
UniFluid 的总训练损失是文本 token 预测 loss 和视觉 token 预测 loss 的加权和,定义为: \(L=L_{Visual}+\lambda L_{Text}\) ,其中, \(\lambda\) 是一个超参数,表示分配给文本 token 预测 loss 的权重,允许在训练期间平衡两种模态的贡献。
UniFluid 推理过程
对于文本解码,对每个生成的文本做分类任务。然后根据采样的概率分布从词汇表 \(V\) 中选择预测的 token。使用与 PaliGemma 相同的解码策略。除了下游 COCOcap (beam search \(n=2)\) 以及 TextCaps (beam search \(n=3\)) 之外,对所有任务使用 greedy decoding。对于图像解码,使用扩散采样过程来生成连续的视觉 token。Diffusion Sampling 的步骤设置为 100。
MetaQuery
论文名称:Transfer between Modalities with MetaQueries
主要方法
Unified Model,生成理解统一模型在高效连接不同的输出模态相当困难,比如一个问题是我们该如何高效地将世界知识从自回归多模态 LLM 转移到图像生成器。大多数已发表的方法依靠仔细调整基础多模态 LLM (MLLM) 来处理理解和生成任务。这个过程涉及复杂的架构设计、data / loss 平衡、多个训练阶段和其他复杂的 training recipe。没有这些,优化一个能力可能会破坏另一个能力。
这篇工作聚焦于不同输出的模型之间能力的迁移,即:将某一输出模态的预训练模型 (比如 MLLM) 的能力高效迁移到另一输出模态的模型 (比如 Diffusion Model)。具体而言,本文冻结 MLLM,以使得其可以专注于理解,然后把图像生成交给 Diffusion Model。本文证明,即使冻结参数,只要有正确的桥接范式,MLLM 的固有世界知识、强推理和上下文学习能力是可以 transfer 到图像生成中的。
但是,利用 MLLM 做多模态理解和生成并不直接。之前的一些工作已经试过了使用冻结的 LLM 作为 T2I 模型的文本编码器,但是也与 Unified Model 的很多需要的任务不兼容,比如 in-context learning 以及多模态交织输出。
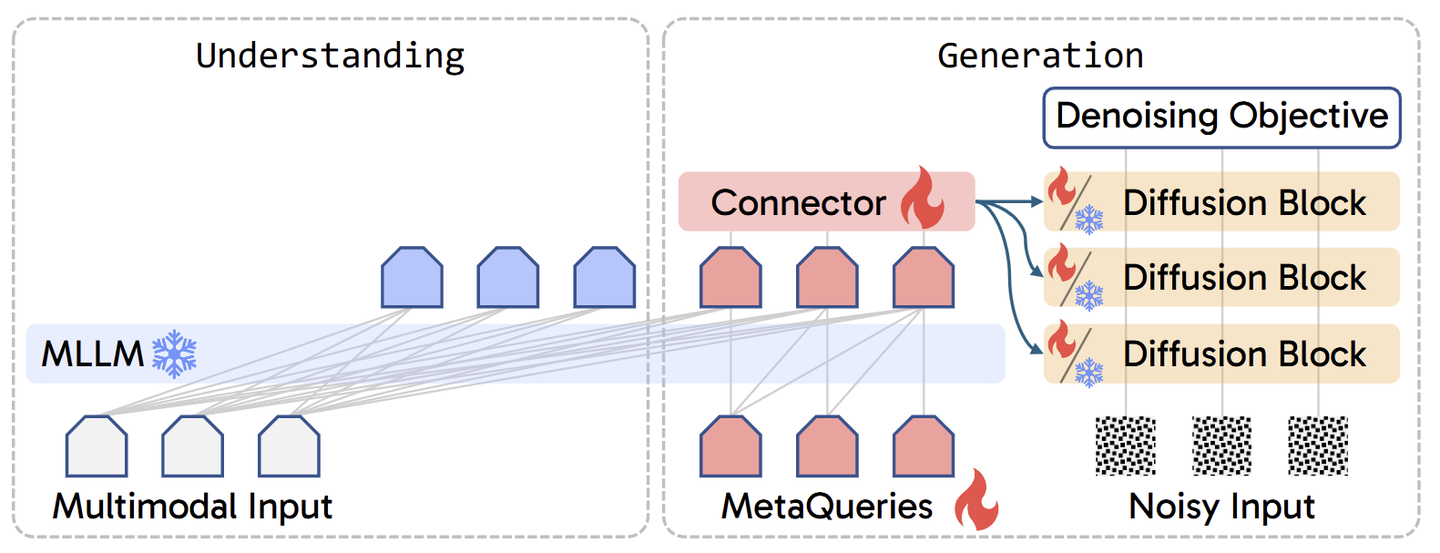
MetaQuery 的做法是:设置一些可学习的 queries,直接输入冻结的 MLLM,提取 condition 进行多模态生成。实验表明,即使没有微调或双向注意,冻结的 LLM 也可以为多模态生成生成高质量的 condition。使用 MetaQueries 训练 Unified Model 只需要少量的配对 image caption 数据将这些 prompt 条件连接到任何扩散模型。由于整个 MLLM 对于理解保持不变,因此 MetaQueries 的训练就相当于是训练 Diffusion Model,训练目标仍然是原始的 denoising objective,就像微调扩散模型一样高效稳定。
MetaQuery 将 MLLM 的自回归先验与强大的 Diffusion Model 相结合,直接利用冻结的 MLLM 在建模压缩语义表示方面的强大能力,从而避免了直接生成像素的更具挑战性的任务。
模型架构
MetaQuery 将冻结的 MLLM 与 Diffusion Model 连接起来。使用随机初始化的可学习查询 \( \mathcal{Q} ∈ \mathbb{R}^{N ×D} \) 来 query 出用来进行生成任务的 condition \(\mathcal{C}\) 。其中, \(N\) 是 query 的数量, \(D\) 是 query 的维度,与 MLLM 隐藏维度相同。
为简单起见,MetaQuery 依然对整个序列使用 causal mask,而不是专门为 \(\mathcal{Q}\) 启用 full attention。然后将 condition \(\mathcal{C}\) 输入可训练的 Connector,与 Diffusion Model 的输入空间对齐。Diffusion Model 只要它有 Condition 的输入接口就可以。只需将其原始条件替换为 condition \(\mathcal{C}\)。
整个模型在配对数据上使用原始生成目标进行训练。MLLM Backbone 使用 LLaVA-OneVision-0.5B,扩散模型使用 Sana-0.6B 512 resolution。learnable queries 使用 \(N=64\) tokens。Connector 使用 24 层的 transformer encoder。
设计选择
- learnable queries
许多模型,如 Lumina-Next、Sana 和 KosmosG 使用 (M)LLM 的输入 token 的最后一层 embedding 作为图像生成的 condition。然而,这种方法对于 Unified Model 来讲并不理想,这种方法与 Unified Model 的许多期待任务不兼容,比如 in-context learning 或者生成多模态交错的输出。
如下图所示,仅使用 \( N = 64 \) 个 token 的 learnable queries 实现了与使用输入 token 的最后一层 embedding 相当的图像生成质量。此外,由于最后一层 embedding 序列长度更长,因此作者还测试了使用 \( N = 64 \) 个 token 的 learnable queries,进一步提高了性能,甚至优于最后一层 embedding 的方法。

- Frozen MLLM
MetaQuery 维持了原来的 MLLM 架构和参数不变,来维持其 SOTA 的多模态理解的能力。
对于多模态生成,一个关键问题是:MetaQuery 在冻结 MLLM 参数的情况下,其性能是否会比完全微调 MLLM 的方法差。实验结果如下图所示,冻结 MLLM 实现了与完整 MLLM 微调相当的性能,视觉质量略有提高。
微调 DiT 可以进一步提高两种设置的性能。

模型训练
作者进一步研究了 MetaQuery 的两个主要组件的关键训练选项:learnable queries (token 的数量) 和 connectors。
- token 数量
learnable queries 一般负责提取 condition。关于这个 queries 的 token 数的选择,一般要么是去 match image decoder 的需求 (比如 Stable Diffusion v1.5 的 \(N=77\) ),要么是使用固定的数量 (比如 \(N=64\) )。考虑到最近的 Diffusion Model 比如 Lumina-Next 和 Sana 都支持可变长度的 condition,因此确定可学习 queries 的最佳 token 数量至关重要。
在下图中,作者对 queries token 数量进行了仔细研究。观察到对于 T2I 而言,视觉质量在 64 个 token 之后开始收敛,而更多的 token 始终可以实现更好的提示对齐。对于长字幕来说更为明显,因为随着 token 数量的增加,GenEval with rewritten prompts 会更快地增加。
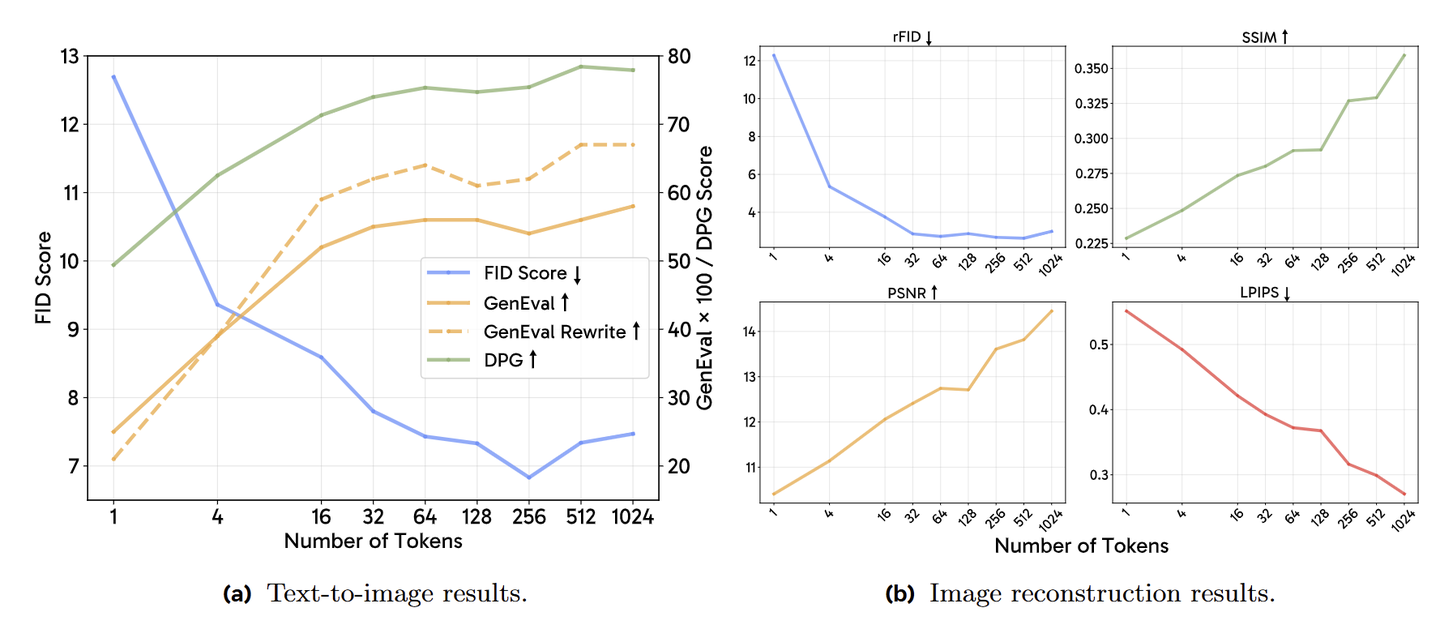
对于图像重建,作者观察到更多的 token 不断提高重建图像的质量 (视觉样本如下图所示)。

在后面的实验中,作者将所有模型的令牌数设置为 \( N = 256\) ,因为它在性能和效率之间取得了很好的平衡。
- Connector 设计
Connector 是 MetaQuery 的另一个重要组件。作者使用与 Qwen2.5 LLM 相同的架构,但可以对 Connector 进行 bi-directional attention。
作者研究了两种不同的设计:Projection Before Encoder (Proj-Enc) 和 Projection After Encoder (Enc-Proj)。Proj-Enc 首先将 Condition 投影到 Diffusion Model 的输入维度上,然后使用 transformer encoder 来对齐 Condition。
Enc-Proj 首先使用 transformer encoder 来对齐到与 MLLM hidden state 相同的维度上,然后将这个 Condition 投影到 Diffusion Model 的输入维度上。如下图所示,Enc-Proj 设计在参数较少的情况下实现了比 Proj-Enc 设计更好的性能。
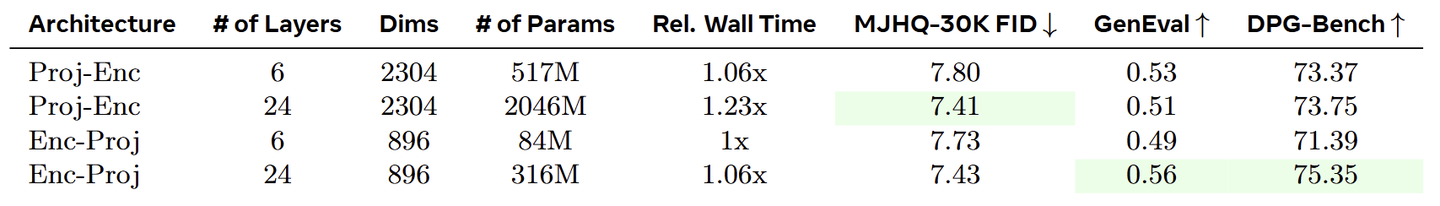
训练过程
MetaQuery 的训练分两个阶段:预训练阶段和指令微调阶段。
两个训练阶段都保持 MLLM 冻结,只去微调 learnable queries,connectors,和 diffusion models。对不同大小的 MetaQuery 使用 3 种不同的 MLLM Backbone:Base 使用 LLAVAOneVision 0.5B、Large 使用 Qwen2.5-VL 3B,X-Large 使用 Qwen2.5-VL 7B。将所有模型的 token 数量设置为 \(N=256\) ,Connector 架构为 24 层的 Enc-Proj 架构。对于图像生成头,本文测试了两种不同的扩散模型:Stable Diffusion v1.5 和 Sana-1.6B。
- 预训练阶段
作者在 25M 公开可用的 image-caption 对上预训练 8 Epoch,学习率为 1e-4,全局 batch size 为 4096。学习率遵循余弦衰减,4,000-step warmup,然后逐渐降低到 1e-5。
- 指令微调阶段
作者在本文中重新思考了图像生成中指令调优的数据管理过程。当前的方法都依赖于一个专家模型,来根据源图像和指令来生成目标图像。本文使用 web corpora 中的自然发生的图像对构建指令微调数据。这些语料库包含丰富的多模态上下文,具有交错的文本和相关主题或主题的图像。这些图像对通常表现出有意义的关联,无论是直接视觉上的相似性,亦或是更微妙的语义连接,如图 7 所示。这种自然得到的图像对为指令微调提供了多样化的监督信号。基于这一观察,作者开发了一个数据构建管道,它挖掘图像对并利用 MLLM 生成捕获其图像间关系的开放指令。
首先,作者从 mmc4 core fewer-faces subset 中收集分组图像,其中每个图像都带有 caption。使用 SigLIP 对具有相似标题的图像进行聚类。在每一组中,平均相似度最小的图像被指定为 target 图像,而其余的图像作为 source 图像。这个过程总共产生了 2.4M 图像对。最后,使用 Qwen2.5-VL 3B 为每对生成 instructions,描述如何将 source 图像转换为 target 图像。作者 2.4M 数据集上指令微调了 Base 大小的模型 3 个 Epoch,使用与预训练相同的学习率和 2048 的 Batch size。

实验结果
多模态理解和生成
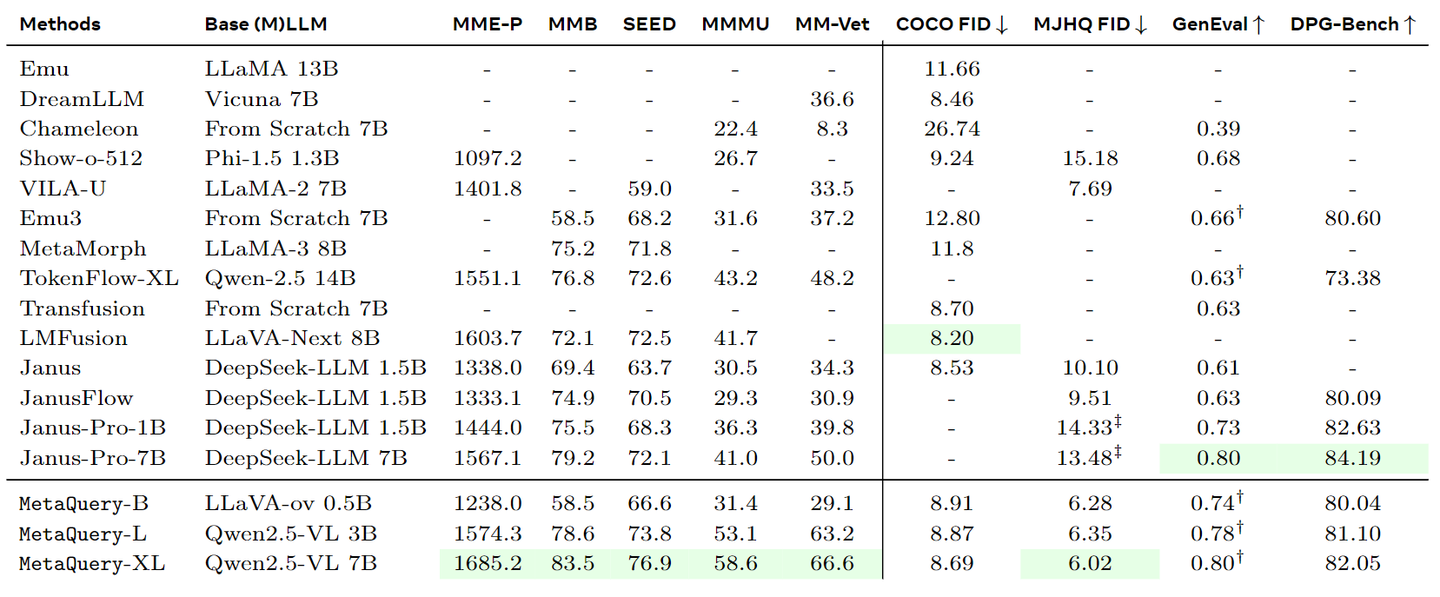
如下图所示,MetaQuery 在理解和生成任务方面表现出强大的能力。因为 MetaQuery 允许我们使用 SOTA 的 MLLM,不同大小的 MetaQuery 模型在所有理解基准上都表现出具有竞争力的性能。
在图像生成方面,MetaQuery 在 MJHQ-30K 上实现了 SOTA 视觉质量。MetaQuery 因为使用冻结的 MLLM,因此可以自然地与任意数量的 Diffusion Models 连接。由于 Sana-1.6B 模型已经在美学数据上进行微调,因此作者采用 Stable Diffusion v1.5 进行 COCO FID 的评估。
结果表明,在将其适配到强大的 MLLM 之后,可以获得改进的视觉质量,比如可以获得 8.69 的 COCO FID。这也在所有基于 Stable Diffusion v1.5 的 Unified Model 中建立了一个新的 SOTA COCO FID 分数,包括 MetaMorph (11.8) 和 Emu (11.66)。
- 讨论1:不同 LLM backbones 的对比
如下图所示,为了测试使用不同 LLM Backbone 对 MetaQuery 的影响,作者选择了一系列 Backbone:预训练的 LLM (Qwen2.5-3B)、指令微调 LLM (Qwen2.5-3B-Instruct) 和指令微调的 MLLM (Qwen2.5-VL-3B-Instruct)。实验结果表明,指令微调可以获得更好的 (多模态) 理解能力。而且,MLLM 只用于提供多模态生成的 Condition,这个改进还与图像生成性能正交。

- 讨论2:MetaQuery 与使用最后一层 embedding 的比较
MetaQuery 的 learnable queries 方法实现了与使用 LLM 的输入 token 的最后一层 embedding 相当的图像生成质量和提示对齐。然而,最后一层 embedding 方法本质上将 LLM 视为 text encoder,固有地限制了其上下文学习能力。虽然这种方法在某些情况下确实改进了基本的 Sana 模型,如图 13 所示,但它很难做知识增强生成。这些情况要求 LLM 在生成图像之前首先处理和回答输入问题,要求 in-context learning 的能力。下图中定量地证实了这种性能差距,其中 MetaQuery 在 WiScore 和 CommonsenseT2I 基准测试中显着优于最后一层 embedding 方法。MetaQuery 与 LLM 原生集成,自然地利用其上下文学习能力,使模型能够通过问题进行推理并生成适当的图像。

BLIP3-o
论文名称:BLIP3-o: A Family of Fully Open Unified Multimodal Models—Architecture, Training and Dataset
论文地址:www.arxiv.org/pdf/2505.09568
代码链接:github.com/JiuhaiChen/BLIP3o
模型:https://huggingface.co/BLIP3o/BLIP3o-Model
预训练数据:https://huggingface.co/datasets/BLIP3o/BLIP3o-Pretrain-Long-Caption
指令微调数据:https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
理解生成统一模型 (Unified Multimodal Model) 之前的方案主要围绕 2 种方法:
- 第 1 种方法 (如 Chameleon,Emu3,TokenShuffle) 将连续的视觉特征量化为离散的 token,并将它们建模为分类分布。
- 第 2 种方法 (如 MetaMorph,MetaQuery) 通过自回归模型生成视觉特征或 latent representation,然后以这些视觉特征的条件,通过 Diffusion Model 生成图像。
最近的 GPT-4o 图像生成被暗示采用具有自回归和扩散模型的混合架构,遵循第 2 种方法。
为此,本文系统研究了 Unified Model 中图像生成的 design choice。
本文研究的 3 个关键问题:
- 图像表征:将图像编码为 low-level 像素特征 (比如基于 VAE 的编码器) 或 high-level 语义特征 (比如来自 CLIP 图像编码器)。
- 训练目标:MSE 还是 Flow Matching。以及它们对训练效率和生成质量的影响。
- 训练策略:图像理解和生成的联合多任务训练 (如 Metamorph),还是像 LMFusion 和 MetaQuery 这样的顺序训练,其中模型首先被训练来理解,然后扩展到生成。
结论 (太长不看版):
- 图像表征:CLIP 特征比 VAE 特征提供更紧凑和信息量更大的表征,训练速度更快,图像生成质量更高。
- 训练目标:Flow Matching Loss 比 MSE Loss 更有效,实现更多样化的图像采样,产生更好的图像质量。
- 训练策略:顺序训练策略,即首先在图像理解任务上训练自回归模型,然后冻结之后做图像生成训练,可以获得最好的整体性能。
基于这些发现,本文提出 BLIP3-o。
BLIP3-o 在 CLIP 特征上使用 DiT,Flow Matching,先在图像理解任务上训练,再在生成任务训练。
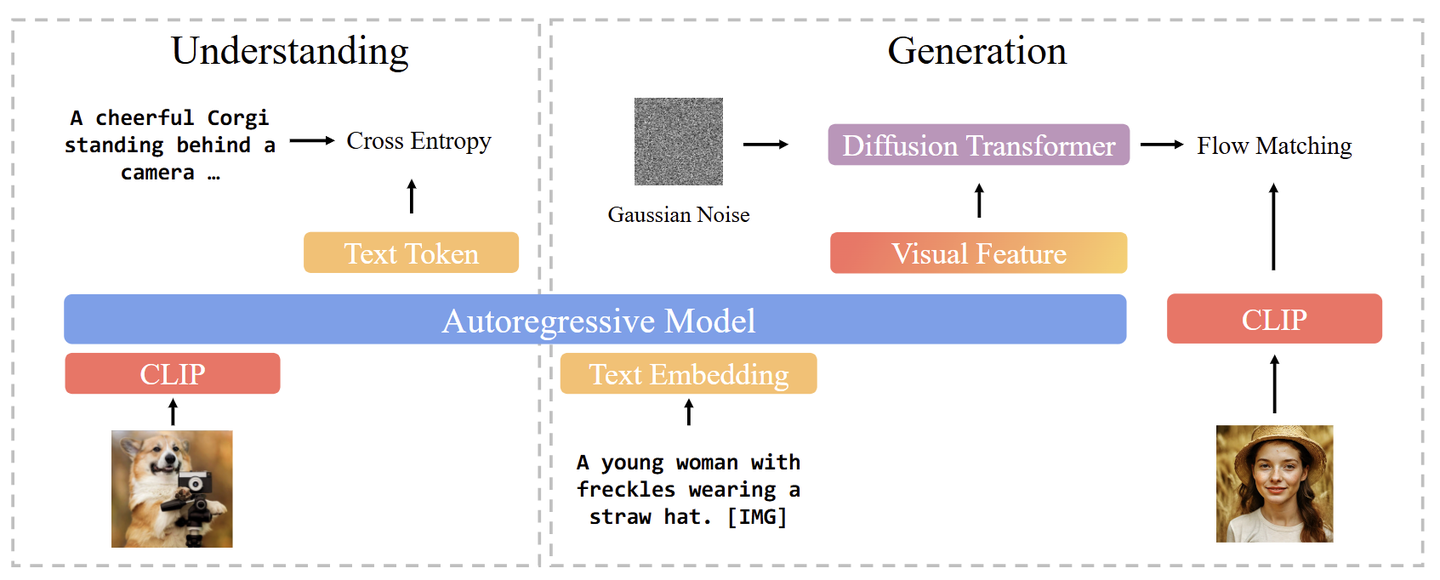
为了进一步提高美学和指令跟随能力,本文通过 prompting GPT-4o,curate 了 60k 高质量指令微调数据集 BLIP3o-60k。BLIP3o-60k 上的有监督指令微调可以显著提升 BLIP3-o 与人类偏好的对齐,以及提升美学质量。
主要方法
图像表征路线:VAE Autoencoder 还是 CLIP-Diffusion Autoencoder ?
BLIP3-o 采用了自回归+扩散框架。自回归模型产生连续的中间视觉特征,这就带来了两个关键问题。
- 其一,这个图像特征的 Ground-truth Embedding 是什么?我们应该使用 VAE 还是 CLIP 编码的特征?
- 其二,自回归模型生成视觉特征之后,我们应该如何有效将其与 GT 真实图像特征对齐?或者更一般地讲,我们如何对这些连续视觉特征的分布进行建模:通过 MSE Loss,还是 diffusion-based 方法?
图像生成通常首先使用 Encoder 将图像编码为连续的 latent embedding,然后使用 Decoder 从该 latent embedding 重建图像。这种 Encoder-Decoder Pipeline 可以有效地降低图像生成中输入空间的维数,促进高效训练。
图像表征相关的路线,有两种比较常见的 Encoder-Decoder 范式:
- VAE Autoencoder 路线。VAE 是一类生成模型,它学习将图像编码为结构化的连续 latent space。Encoder 估计给定图像的 latent 的后验分布,Decoder 根据从 latent distribution 中得到的采样,来重建原始图像。Latent Diffusion Model 就是建立在该框架的基础上,建模 latent 的分布,而不是原始图像的分布。通过在 VAE latent 空间中操作,可显著降低输出空间的维度,降低了计算成本,实现更高效训练。
- CLIP-Diffusion Autoencoder 路线。CLIP 模型因为在大规模图像-文本对上进行对比学习,因而具有很强的从图像中提取丰富、高级语义特征的能力。但是因为 CLIP 最初不是为重建任务设计的,所以利用 CLIP 特征进行图像生成仍不容易。
Emu2 的做法是:CLIP-based encoder + diffusion-based decoder。
使用 EVA-CLIP 将图像编码为连续的视觉 embedding,并通过 SDXL-base 初始化的扩散模型重建。在训练期间,diffusion decoder 被微调,将 EVA-CLIP 的视觉 embedding 作为 Condition,从高斯噪声重建原始图像。EVA-CLIP 冻结参数。
这个过程相当于是把 CLIP 和 Diffusion Model 结合为一个 image autoencoder:CLIP Encoder 把图像编码为语义丰富的 latent embedding,Diffusion-based Decoder 从这些 embedding 重建图像。
总结:
VAE Autoencoder,或者 CLIP-Diffusion Autoencoder,都属于是用于获得图像表征 Encoder-Decoder 路线。
VAE 将图像编码为 low-level 像素特征,提供更好的重建质量。且 VAE 可以直接集成到图像生成 training pipeline 中。
CLIP-Diffusion 需要额外的训练来使扩散模型适应各种 CLIP Encoder。但是,CLIP-Diffusion 架构在图像压缩比率方面更有优势。比如在 Emu2 和 BLIP3-o 中,无论分辨率如何都可编码为 64 个连续向量,提供紧凑且语义丰富的 latent embedding。相比之下,基于 VAE 的 Encoder 为更高分辨率的输入生成更长的 latent embedding 序列,增加了训练过程中的计算负担。
训练目标:MSE Loss 还是 Flow Matching?
在获得连续的 image embedding 后,继续使用自回归架构对它们进行建模。
假设 prompt 是 "A young woman with freckles wearing a straw hat."。
- 首先使用自回归模型的输入 Embedding 层将其编码为 embedding 向量 \(\mathbf{C}\) 。
- 将一组 learnable query 向量 \(\mathbf{Q}\) 附加到向量 \(\mathbf{C}\) ,得到 \(([\mathbf{C}; \mathbf{Q}])\) 。 \(\mathbf{Q}\) 随机初始化,且在训练期间更新参数。
- 把 \(([\mathbf{C}; \mathbf{Q}])\) 输入自回归模型, \(\mathbf{Q}\) 学习从向量 \(\mathbf{C}\) 中提取语义信息。
- 最后输出的 \(\mathbf{Q}\) 代表自回归模型输出的中间视觉特征。希望通过训练,使其近似 GT 图像特征 \(\mathbf{X}\) (从 VAE 或 CLIP 得到)。
如何将 \(\mathbf{Q}\) 与 GT 图像特征 \(\mathbf{X}\) 对齐?有 2 种方法:
MSE Loss
给定自回归模型输出的视觉特征 \(\mathbf{Q}\) 和 GT 图像特征 \(\mathbf{X}\) ,应用一个可学习的线性投影将 \(\mathbf{Q}\) 的维度与 \(\mathbf{X}\) 的维度对齐。然后 MSE Loss 为:
其中, \(\mathbf{W}\) 是可学习的投影矩阵。
Flow Matching
一个扩散框架,可以通过从先验分布 (如高斯) 迭代传输样本从目标连续分布中采样。给定一个 GT 真实图像特征 \(\mathbf{X}_1\) 和自回归模型编码的 Condition \(\mathbf{Q}\) ,在每个训练步骤中,对时间步长 \(t\sim\mathcal{U}(0,1)\) 和 noise \(\mathbf{X}_0\sim\mathcal{N}(0,1)\) 进行采样。然后 DiT 学习在以 \(\mathbf{Q}\) 为条件的时间步 \(t\) 预测速度 \(\mathbf{V}_t=\frac{d\mathbf{X}_t}{dt}\) ,朝着 \(\mathbf{X}_1\) 的方向。 通过在 \(\mathbf{X}_0\) 和 \(\mathbf{X}_1\) 之间进行简单的线性插值来计算 \(\mathbf{X}_t\) :
\(\mathbf{V}_t\) 的解析解可表示为:
最后的训练目标为:
其中, \(\theta\) 是 DiT 的参数, \(\mathbf{V}_\theta(\mathbf{X}_t,\mathbf{Q},t)\) 表示基于实例 \( (\mathbf{X}_1, \mathbf{Q})\) 、时间步长 \(t\) 和噪声 \(\mathbf{X}_0\) 预测的速度。
总结:
离散 token 支持基于采样的策略,可以探索不同的生成路径。连续表征缺少了这个性质。
在基于 MSE 的训练目标下,对于给定的 prompt,预测的视觉特征 \(\mathbf{Q}\) 几乎是确定的。因此,无论视觉 Decoder 是基于 VAE 的还是 CLIP + Diffusion 的架构,输出图像在多个推理运行中几乎保持不变。这突出了 MSE 目标的一个关键的限制:约束模型为每个 prompt 生成固定的输出,限制了生成的多样性。
相比之下,Flow Matching 使模型能够继承 diffusion 的随机性。允许模型在相同 prompt 时,生成不同图像样本。然而,这种灵活性是以模型复杂性增加为代价的。与 MSE 相比,Flow Matching 引入了额外的可学习参数。本文使用 DiT,并发现缩放模型容量可以提高性能。
三种设计选择
前面列举了 2 种图像表征路线:
- VAE 作为 Autoencoder
- CLIP-Diffusion (简记为 CLIP) 作为 Autoencoder
也列举了 2 种训练目标 (即 Loss Function):
- MSE Loss
- Flow Matching
排列组合,得到 4 种图像生成模型的设计方案如下。不同的方案影响生成图像的质量和可控性。
- CLIP + MSE
- CLIP + Flow Matching
- VAE + Flow Matching
- VAE + MSE
以上 4 种方案,如下图所示,下面一一介绍。
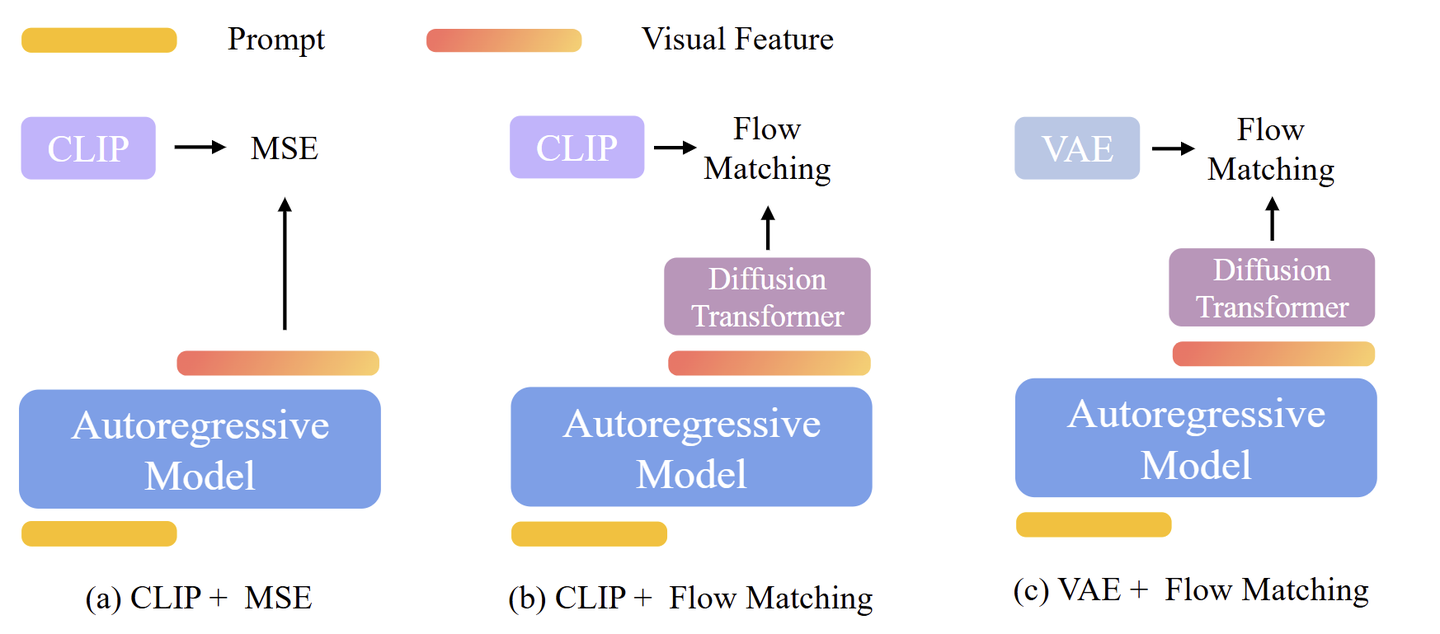
- CLIP + MSE [代表:Emu2, Seed-X,Metamorph]
如图(a) 所示,使用 CLIP 将图像编码为 64 个固定长度的语义丰富的视觉 embedding。训练自回归模型以最小化预测的视觉特征 \(\mathbf{Q}\) 和 GT 的 CLIP embedding \(\mathbf{X}\) 之间的 MSE Loss。在推理过程中,给定一个 prompt \(\mathbf{C}\) ,自回归模型预测 latent 视觉特征 \(\mathbf{Q}\) ,然后将其传递给 diffusion-based 的 Decoder 来重建真实图像。
- CLIP + Flow Matching
如图 (b) 所示,作为 MSE Loss 的替代方案,使用 Flow Matching Loss 来预测 GT CLIP embedding。给定一个 prompt \(\mathbf{C}\) ,自回归模型生成一系列视觉特征 \(\mathbf{Q}\) 。特征 \(\mathbf{Q}\) 被用作指导扩散过程的 Condition,产生一个预测的 CLIP embedding 来近似 GT 的 CLIP 特征。
推理过程涉及 2 个 Diffusion Model:
- 第 1 个使用视觉特征 \(\mathbf{Q}\) 作为 Condition,把 noise 去噪为 CLIP embedding。
- 第 2 个是 diffusion-based 视觉 Decoder,把 CLIP embedding 转换为真实图像。
- VAE + Flow Matching [代表:MetaQuery]
如图 (c) 所示,使用 Flow Matching Loss 来预测 GT 的 VAE 特征。在推理时,给定一个 prompt \(\mathbf{C}\) ,自回归模型产生视觉特征 \(\mathbf{Q}\) 。然后,以 \(\mathbf{Q}\) 为条件并在每一步迭代地去除噪声,真实图像由 VAE Decoder 生成。
- VAE + MSE
由于本文重点是 AR + Diffusion 框架,故排除了 VAE + MSE 方法,因为不包含任何 Diffusion 模块。
自回归模型使用 Llama-3.2-1B-Instruct 。训练数据由 CC12M、SA-1B 和 JourneyDB 组成,总计约 2500 万个样本。对于 CC12M 和 SA-1B,利用 LLaVA 生成的详细字幕,而对于 JourneyDB,使用原始字幕。
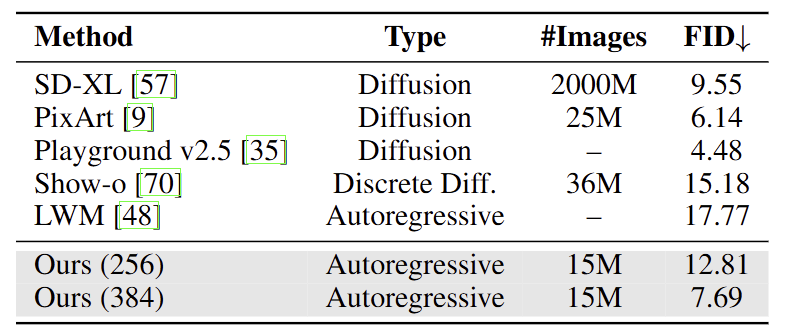
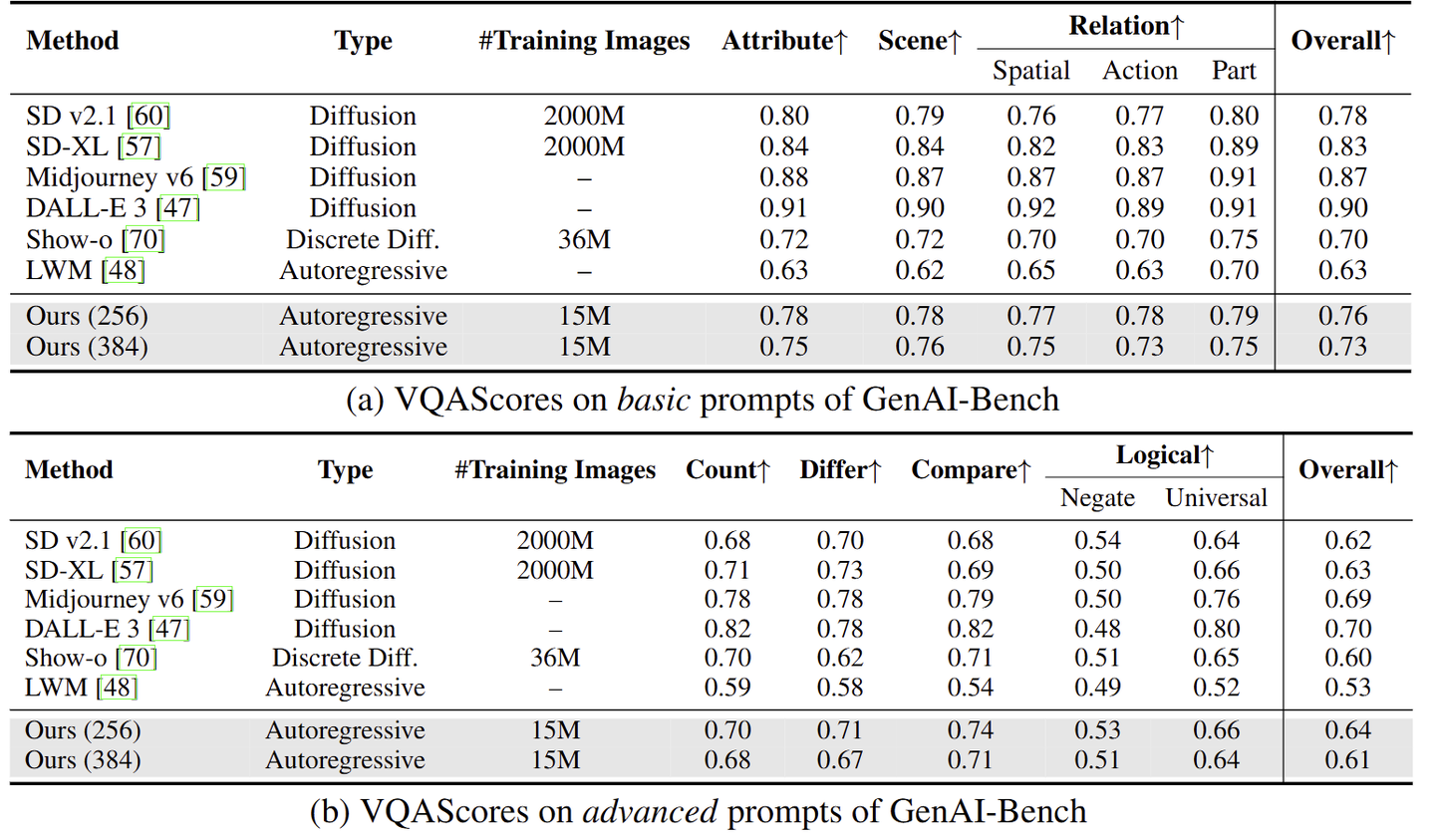
下图是这几种方法的结果,包括 FID,DPG-Bench,和 MJHQ-30k 的 FID。图 4 显示 CLIP + Flow Matching 在 GenEval 和 DPG-Bench 上都取得了最好的 prompt alignment 分数,而 VAE + Flow Matching 得到的 FID 最低,表明美学质量最好。
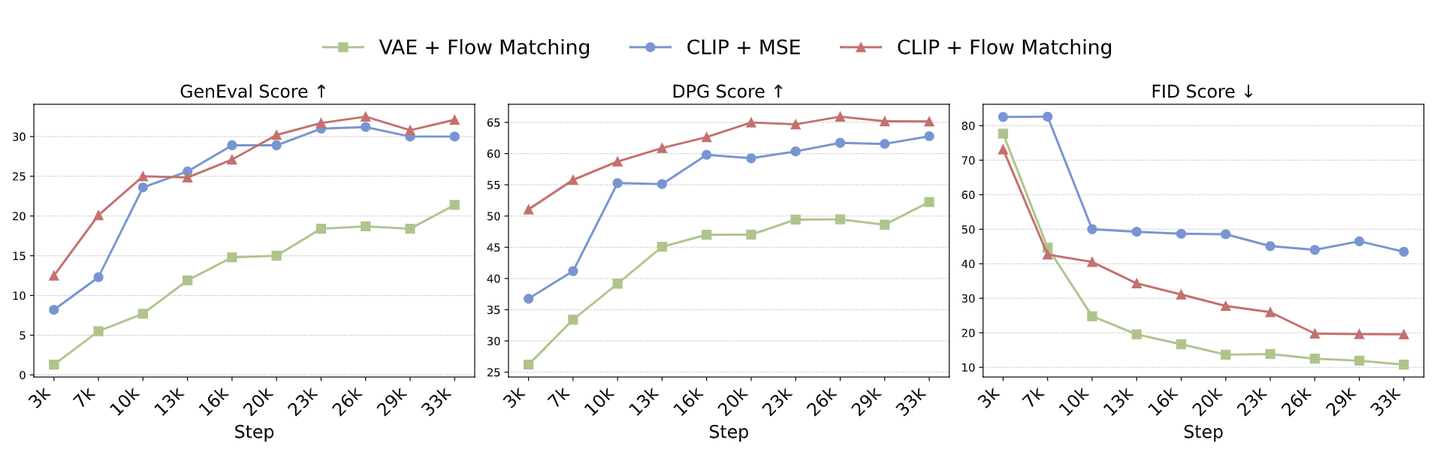
结论 1:把图像生成能力集成到 Unified Model 中时,Autoregressive Model 可以更有效学习语义特征 (CLIP),相比像素级特征 (VAE)。
结论 2:采用 Flow Matching 作为训练目标更好地捕捉底层图像分布,导致样本多样性和视觉质量增强。
模型训练
- 联合训练
联合训练通过混合图像理解和图像生成数据,执行多任务学习,同时更新 Autoregressive Backbone 和生成模块。比如 MetaMorph、Janus-Pro 和 Show-o。
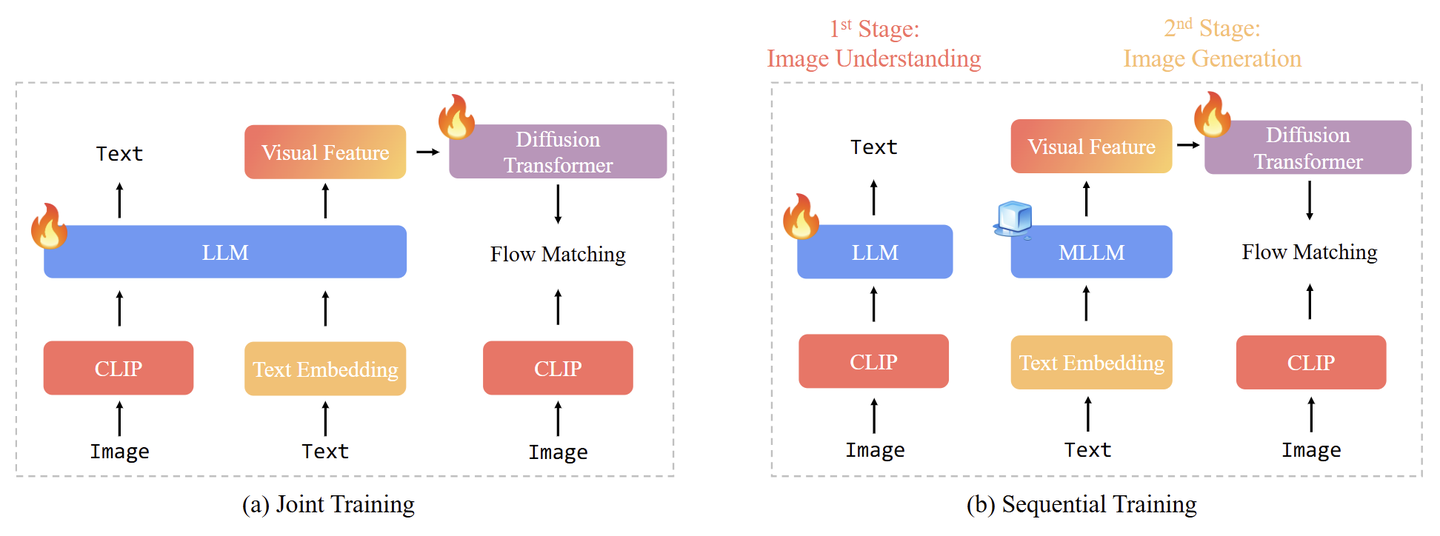
- 顺序训练
两阶段方法。第1阶段只训练图像理解模块。第2阶段,冻结 MLLM Backbone,只训练图像生成模块,比如 LMFusion 和 MetaQuery 等。
尽管像 Metamorph 所证明的那样,图像理解和生成任务可能相互受益,但有两个关键因素会影响它们的协同效应:1) 总数据量大小;2) 图像理解和生成数据之间的数据比率。相比之下,顺序训练提供了更大的灵活性:允许冻结 Autoregressive Backbone 并保持图像理解能力,可以将所有训练能力集中在图像生成上。
BLIP3-o 模型
BLIP3-o 基于前文的结论,采用 CLIP + Flow Matching 和顺序训练,是统一的多模态模型。
BLIP3-o 有两种不同的大小模型:在专有数据上训练的 8B 模型和仅使用开源数据的 4B 模型。
跳过图像理解训练阶段并直接在 Qwen 2.5 VL 上构建图像生成模块。
8B 模型冻结了 Qwen2.5-VL-7B-Instruct Backbone 并训练 DiT,共 1.4 B 可训练参数。
4B 模型使用 Qwen2.5-VL-3B-Instruct 作为 Backbone,遵循相同的图像生成架构。
DiT 使用 Lumina-Next。
训练策略
- 第1阶段:图像生成预训练
8B 模型:将大约 25M 的开源数据 (CC12M、SA-1B 和 JourneyDB) 与额外的 30M 专有图像相结合。所有图像标题均由 Qwen2.5-VL-7B-Instruct 生成,产生平均长度为 120 token 的长 caption。为了提高对不同提示长度的泛化能力,还包括了约 10% (6M) 短字幕 (长度大约 20 token,来自 CC12M)。每个 image–caption pair 都用 prompt:"Please generate an image based on the following caption: <caption>"。
4B 模型:使用来自 CC12M、SA-1B 和 JourneyDB 的 25M 公开可用的图像,每个图像使用相同的长 caption 配对。还混合了来自 CC12M 的大约 10% (3M) 短字幕。
- 第2阶段:图像生成指令微调
在图像生成预训练阶段之后,观察到模型的几个弱点:
- 生成复杂的人类手势。
- 生成常见对象,例如各种水果和蔬菜。
- 生成地标,例如 Golden Gate Bridge。
- 生成简单的文本,例如在街道表面编写的单词 "Salesforce"。
尽管这些类别在预训练中间也有涵盖,但预训练语料库的大小有限。因此,又做了专门针对这些领域的指令微调。对于每个类别,prompt GPT-4o 生成大约 10k prompt–image pairs,创建一个目标数据集,以提高模型处理这些情况的能力。为了提高视觉美学质量,还使用从 JourneyDB 和 DALL·E 3 中的 prompt 来扩展我们的数据。这个过程产生了大约 60k 个高质量 prompt–image pairs 的集合。
实验结果
图像理解任务
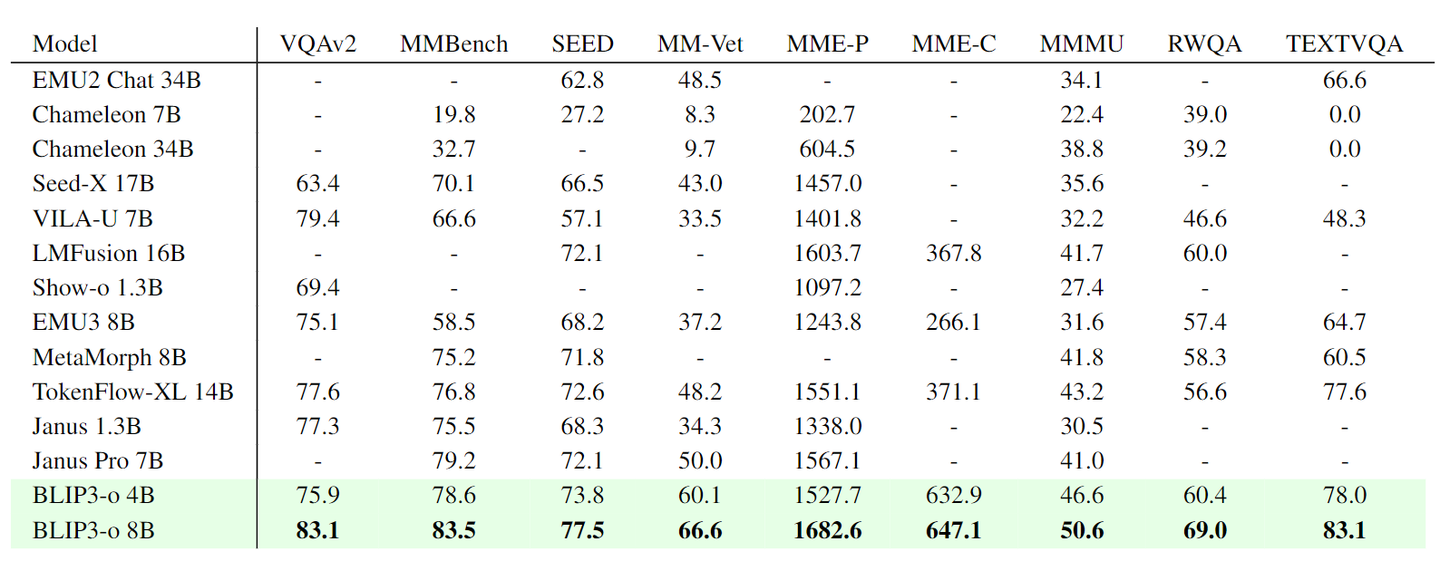
评估了 VQAv2、MMBench、SeedBench、MM -Vet、MME-Perception、MME-Cognition、MMMU、TextVQA、RealWorldQA 的性能。如下图所示,BLIP3-o 8B 在大多数 Benchmark 中实现了最佳性能。
图像生成任务
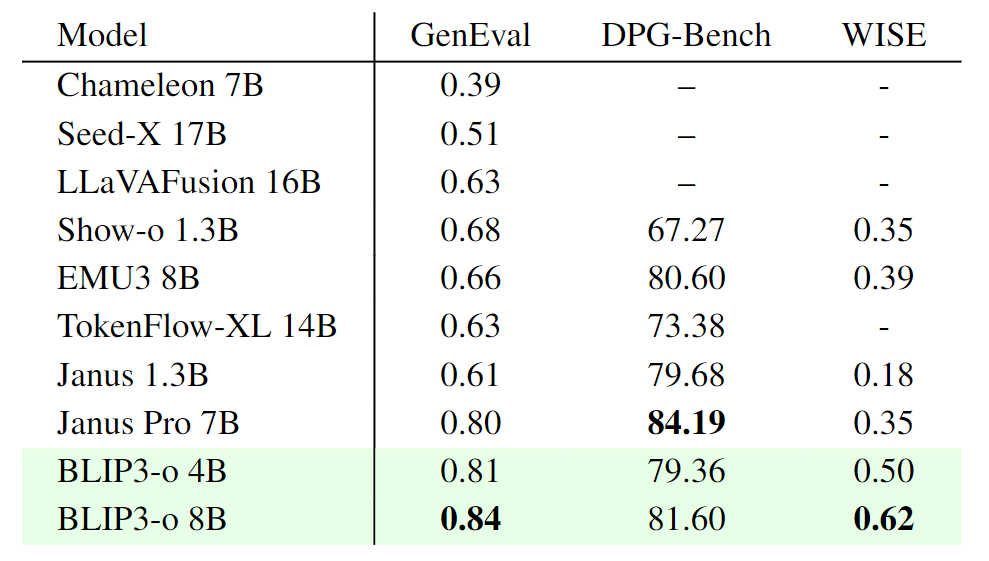
本文报告了 GenEval 和 DPG-Bench 来衡量 prompt alignment,WISE 来评估世界知识推理能力。如图 7 所示,BLIP3-o 8B 的 GenEval 得分为 0.84,WISE 得分为 0.62,但在 DPG-Bench 上得分较低。
为此,作者对所有 DPG-Bench prompt 进行了 human study 来补充这些结果。此外,还发现指令调整数据集 BLIP3o-60k 会产生收益:仅使用 60k 个 prompt–image pair,提示对齐和视觉美学都显著提高,而且许多生成伪影迅速减少。尽管这种指令调整数据集不能完全解决一些困难的情况,例如复杂的人类手势生成,但它仍然显著地提高了整体图像质量。
结论3:该模型可以快速适配 GPT-4o 风格,增强指令对齐和视觉质量。该模型从 AI 生成的图像中学习比真实图像更有效。
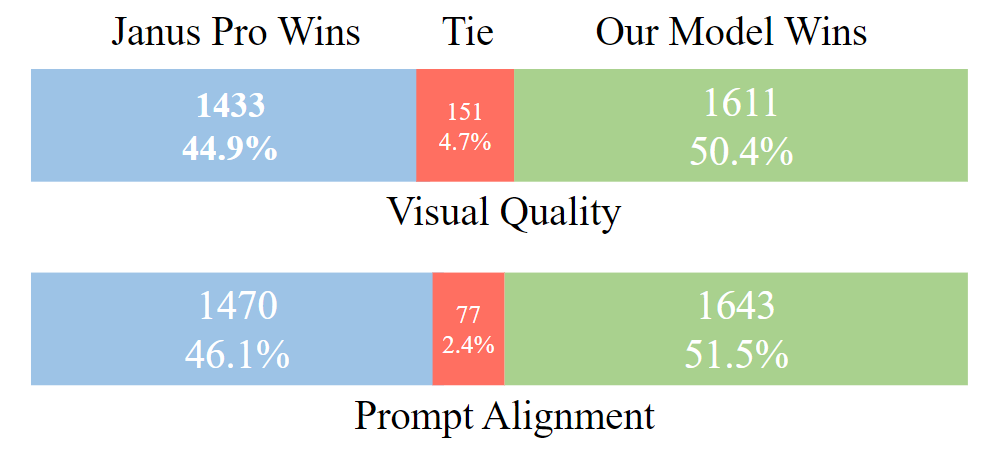
Human Study 结果
作者对从 DPG-Bench 中提取的大约 1,000 个 prompt 的 BLIP3-o 8B 和 Janus Pro 7B 进行了人工评估。对于每个 prompt,注释者在两个指标上比较:
- 视觉质量 (Visual Quality):instruction 是 "All images were generated from the same text input using different methods. Please select the BEST image you prefer based on visual appeal, such as layout, clarity, object shapes, and overall cleanliness."
- 指令对齐 (Prompt Alignment):instruction 是 "All images were generated from the same text input using different methods. Please select the image with the BEST image-text content alignment."
如下图所示,BLIP3-o 在视觉质量和指令对齐方面都优于 Janus Pro。
Bagel
BAGEL 是字节 2025.05 出品的理解生成统一的开源模型。BAGEL 搞了一个高质量多模态交错数据集,在这个数据集上进行训练,BAGEL 表现出了逐渐涌现的能力。从基本的理解,生成,逐渐到简单的编辑和复杂的编辑能力。这个现象很有趣。此外,BAGEL 在标准基准的多模态生成和理解方面明显优于开源统一模型,同时展示了先进的多模态推理能力。
详情可以参考:Bagel