通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。
Upsampling(上采样)[没有学习过程]
在FCN、U-net等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。

在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种:
- PixelShuffle
- Upsample
- UpsamplingNearest2d
- UpsamplingBilinear2d
PixelShuffle
当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network” 这篇paper。
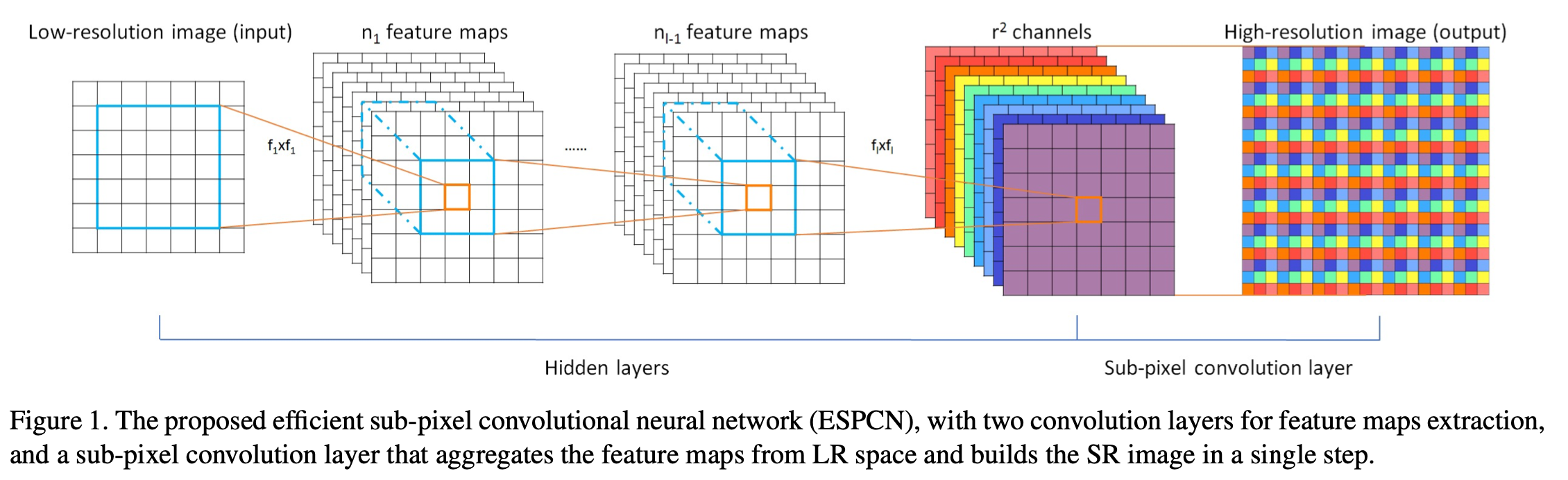
pixelshuffle算法的实现流程如上图,其实现的功能是:将一个\(H × W\) 的低分辨率输入图像(Low Resolution),通过Sub-pixel操作将其变为\(rH \times rW\)的高分辨率图像(High Resolution)。
但是其实现过程不是直接通过插值等方式产生这个高分辨率图像,而是通过卷积先得到\(r^2\)个通道的特征图(特征图大小和输入低分辨率图像一致),然后通过周期筛选(periodic shuffing)的方法得到这个高分辨率的图像,其中\(r\)为上采样因子(upscaling factor),也就是图像的扩大倍率。
例子:
>>> pixel_shuffle = nn.PixelShuffle(3)
>>> input = torch.randn(1, 9, 4, 4)
>>> output = pixel_shuffle(input)
>>> print(output.size())
torch.Size([1, 1, 12, 12])Upsample
对给定多通道的1维(temporal)、2维(spatial)、3维(volumetric)数据进行上采样。
对volumetric输入(3维点云数据),输入数据Tensor格式为5维:minibatch x channels x depth x height x width对spatial输入(2维jpg、png等数据),输入数据Tensor格式为4维:minibatch x channels x height x width对temporal输入(1维向量数据),输入数据Tensor格式为3维:minibatch x channels x width
此算法支持最近邻,线性插值,双线性插值,三次线性插值对3维、4维、5维的输入Tensor分别进行上采样(Upsample)。
UpsamplingNearest2d
本质上其实就是对jpg、png等格式图像数据的Upsample(mode='nearest')
UpsamplingBilinear2d
本质上其实就是对jpg、png等格式图像数据的Upsample(mode='bilinear')
上池化(Unpooling)[没有学习过程]
Unpooling是在CNN中常用的来表示max pooling的逆操作。这是从2013年纽约大学Matthew D. Zeiler和Rob Fergus发表的《Visualizing and Understanding Convolutional Networks》中引用的:因为max pooling不可逆,因此使用近似的方式来反转得到max pooling操作之前的原始情况:

对比上面示意图,可以发现与上采样的区别:
- 两者的区别在于UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。第一幅图中右边4*4矩阵,用了四种颜色的正方形框分割为四个区域,每一个区域内的内容是直接复制上采样前的对应信息。
- UnPooling的过程,特点是在Maxpooling的时候保留最大值的位置信息,之后在unPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。从图中即可看到两者结果的不同。
测试:
m=nn.MaxPool2d((3,3),stride=(1,1),return_indices=True)
upm=nn.MaxUnpool2d((3,3),stride=(1,1))
data4=torch.randn(1,1,3,3)
output5,indices=m(data4)
output6=upm(output5,indices)
print('\ndata4:',data4,
'\nmaxPool2d',output5,
'\nindices:',indices,
'\noutput6:',output6)其输出为:
data4: tensor([[[[ 2.3151, -1.0391, 0.1074],
[ 1.9360, 0.2524, 2.3735],
[-0.1151, 0.4684, -1.8800]]]])
maxPool2d tensor([[[[2.3735]]]])
indices: tensor([[[[5]]]])
output6: tensor([[[[0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 2.3735],
[0.0000, 0.0000, 0.0000]]]])反卷积(Deconvolution)或称为fractionally-strided convolutions[具有学习过程]
在介绍反卷积之前,我们需要深入了解一下卷积,一个简单的卷积层运算,卷积参数为(\(i=4,k=3,s=1,p=0\))示意图如下:
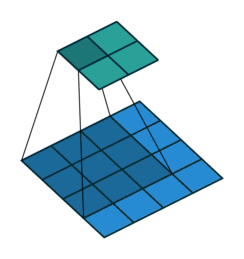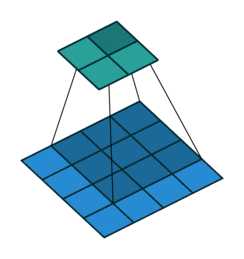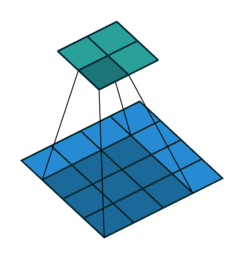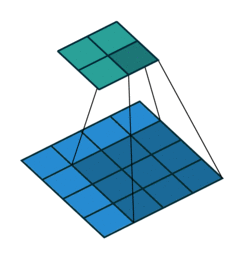
对于上述卷积运算,我们把上图所示的3×3卷积核展成一个如下所示的[4,16]的稀疏矩阵C,如下:

我们再把4×4的输入特征展成[16,1]的矩阵\(X\),那么 \(Y=CX\) 则是一个[4,1]的输出特征矩阵,把它重新排列2×2的输出特征就得到最终的结果,从上述分析可以看出卷积层的计算其实是可以转化成矩阵相乘的。
ps. 值得注意的是,在一些深度学习网络的开源框架中并不是通过这种这个转换方法来计算卷积的,因为这个转换会存在很多无用的0乘操作。
通过上述的分析,我们已经知道卷积层的前向操作可以表示为矩阵\(X\)和矩阵\(C\)相乘,
很容易得到卷积层的反向传播就是和\(C\)的转置相乘。我们已经说过反卷积又被称为Transposed(转置) Convolution,我们可以看出其实卷积层的前向传播过程就是反卷积层的反向传播过程,卷积层的反向传播过程就是反卷积层的前向传播过程。因为卷积层的前向反向计算分别为乘 \(C\)和\(C^T\),而反卷积层的前向反向计算分别为乘\(C^T\)和\((C^T)^T\),所以它们的前向传播和反向传播刚好交换过来。
下图表示一个和上图卷积计算对应的反卷积操作,其中他们的输入输出关系正好相反。如果不考虑通道以卷积运算的反向运算来计算反卷积运算的话,还可以通过离散卷积的方法来求反卷积。
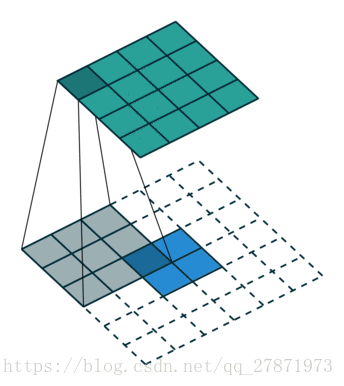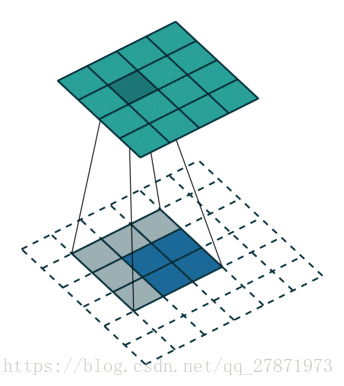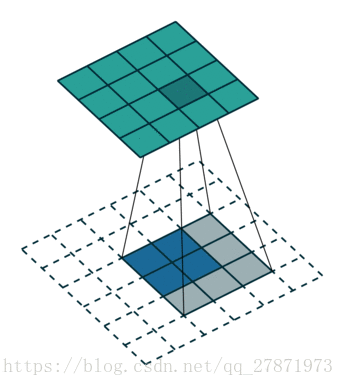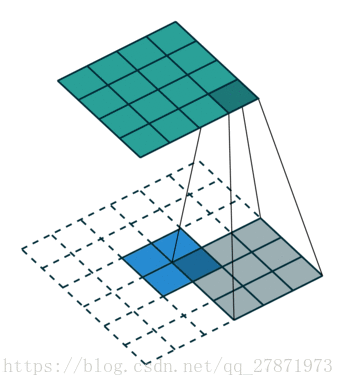
当给一个特征图a, 以及给定的卷积核设置,我们分为三步进行逆卷积操作:
第一步:对输入的特征图a进行一些变换,得到新的特征图a’
第二步:求新的卷积核设置,得到新的卷积核设置,后面都会用右上角加撇点的方式区分
第三步:用新的卷积核在新的特征图上做常规的卷积,得到的结果就是逆卷积的结果,就是我们要求的结果。
再谈PixelShuffle
1d情况
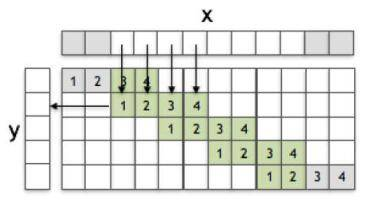
上图是一个简单的1D的卷积网络,\(x\)为输入\(y\)为输出,通过滤波器\(f\)来实现这个过程,\(x\)的size为8,\(f\)为4,\(y\)为5,\(x\)中灰色的方块表示用0进行padding。在\(f\)权重中的灰色方块代表\(f\)中某些值与\(x\)中的0进行了相乘。这个图就是1D卷积的过程,从\(x\)到\(y\)。
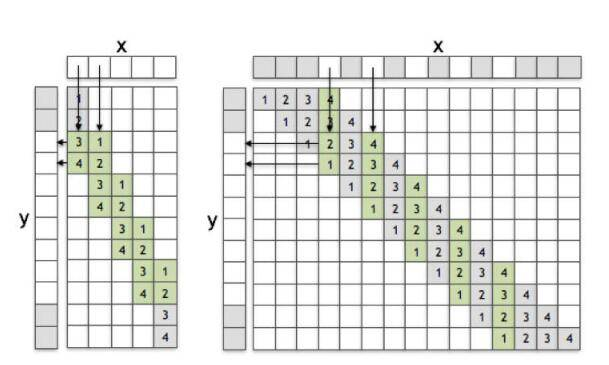
上图左面是一个转置卷积(stride为2),右面是sub-pixel convolution(stride为1/2),作用在1D上。
通过观察可以很容易的看到左边\(x\)为5,\(y\)为8,\(f\)为4,\(y\)中灰色部分代表被截去的部分,而右边通过对\(x\)进行部分取值达到 过滤效果。通过比较两个卷积方法可以发现:如果把右边的fliter进行reverse(倒转),会发现两边得到的\(y\)值相同(自己可以试着加一下)。也就是说在参数(filter中权重值)可以学习的情况下,右边的操作和左边的操作完全相同。
Deconvolution layer vs Convolution in LR
接下来我们展示的是:在LR space中用一个简单的卷积参数为(\(o*r^2\)\(,i,k,k\))-(输出通道,输入通道,kernel width,kernel height)的卷积操作,和deconvolution(其中卷积参数为(\(o, i ,k * r,k * r\)),\(k\)为正数)的作用是相同的。
我们用2D来进行演示,input为(1,4,4),kernel为(1,1,4,4),假设我们upsample的比率为2,我们要得到(1,8,8)的输出。
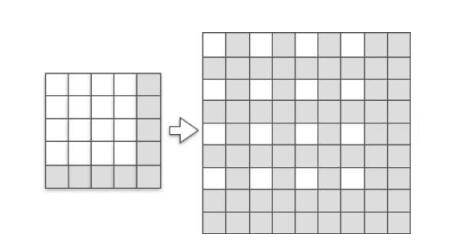
如上图,我们首先通过fractional indices从原input中创建一个sub-pixel图像,其中白色的像素就是原input中的像素(在LR sapce中),灰色是通过zero padding而来的。
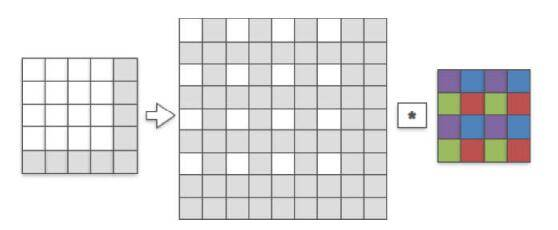
用一个(1,1,4,4)的卷积核来和刚才生成的sub-pixel图像进行卷积,首先发现卷积核和sub-pixel图像中非零的像素进行了第一次有效卷积(图中紫色像素代表被激活的权重),然后我们将sub-pixels整体向右移动一格,让卷积核在进行一次卷积,会发现卷积核中蓝色的像素权重被激活,同理绿色和红色(注意这里是中间的那个8×8的sub-pixel图像中的白色像素点进行移动,而每次卷积的方式都相同)。
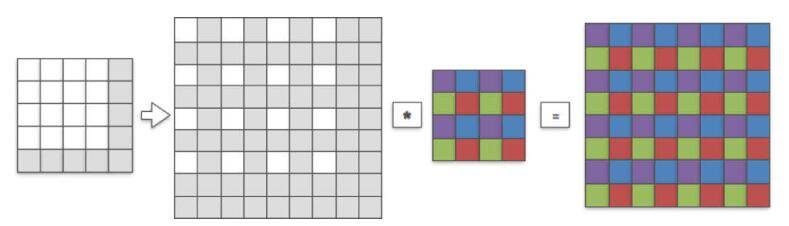
最后我们输出得到HR图像,HR图像和sub-pixel图像的大小是一致的,我们将其涂上颜色,颜色代表这个卷积核中权重和sub-pixel图像中哪个像素点进行了卷积(也就是哪个权重对对应的像素进行了贡献)。
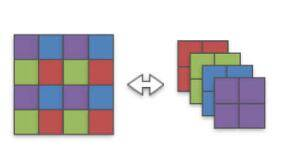
需要注意的是,这是一个(1,1,4,4)的卷积核,上面每个权重皆为独立地被激活,也就是说我们可以轻易地将其分成(4,1,2,2)的卷积核(如上图)。这个操作是可逆的因为每个卷及权重在操作过程中都是独立的。
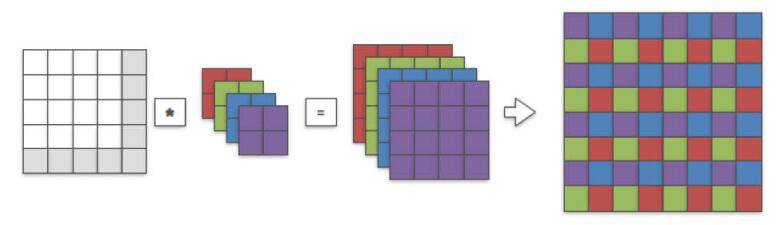
这样,这里不适用(1,1,4,4)的卷积核,而是使用(4,1,2,2)的卷积核,,对sub-pixel图像直接在LR space中进行卷及操作(如上图)。再将得到的(4,4,4)的输出进行周期筛选(periodic shuffling)将其reshape为HR image。

这个图片展示了将左面图像上方的(9,32,3,3)卷积层转化为底部的(1,32,9,9)卷积层,转化过程正如右方所示。也就是说,上方的卷积层对一个32通道的图像进行卷积然后周期筛选后得到的图像和使用下方的卷积层进行反卷积(deconvolution)得到的结果相同。
这个卷积操作是很灵活的,看一下之前的1D的卷积操作,可以将滤波器\(f=(1,2,3,4)\)更换为\(f1=(2,4) \)以及\(f2=(1,3)\),然后产生\(y1 = f1*x\) 和\(y2 = f2 * 2\)其中\(*\)代表卷积操作。通过对\(y1\)和\(y2\)进行组合得到最终的结果\(y\)。还记得上面谈说过:“在LR space中用一个简单的卷积参数为\((o r r,i,k,k)\)-(输出通道,输入通道,kernel width,kernel height)的卷积操作,和deconvolution,其中卷积参数为(\((o,i,k * r,k * r)\),\(k\)为正数)的作用是相同的。”这里的\(f\)我们一般都以\((k\ r)\)来表示,但其实这个\(f\)可以为任意值,加入\(f=(1,2,3)\),我们就可以分成\(f=(2)\),\(f=(1,3)\),同样,得到结果组合起来即可。
Reference
一边Upsample一边Convolve:Efficient Sub-pixel-convolutional-layers详解