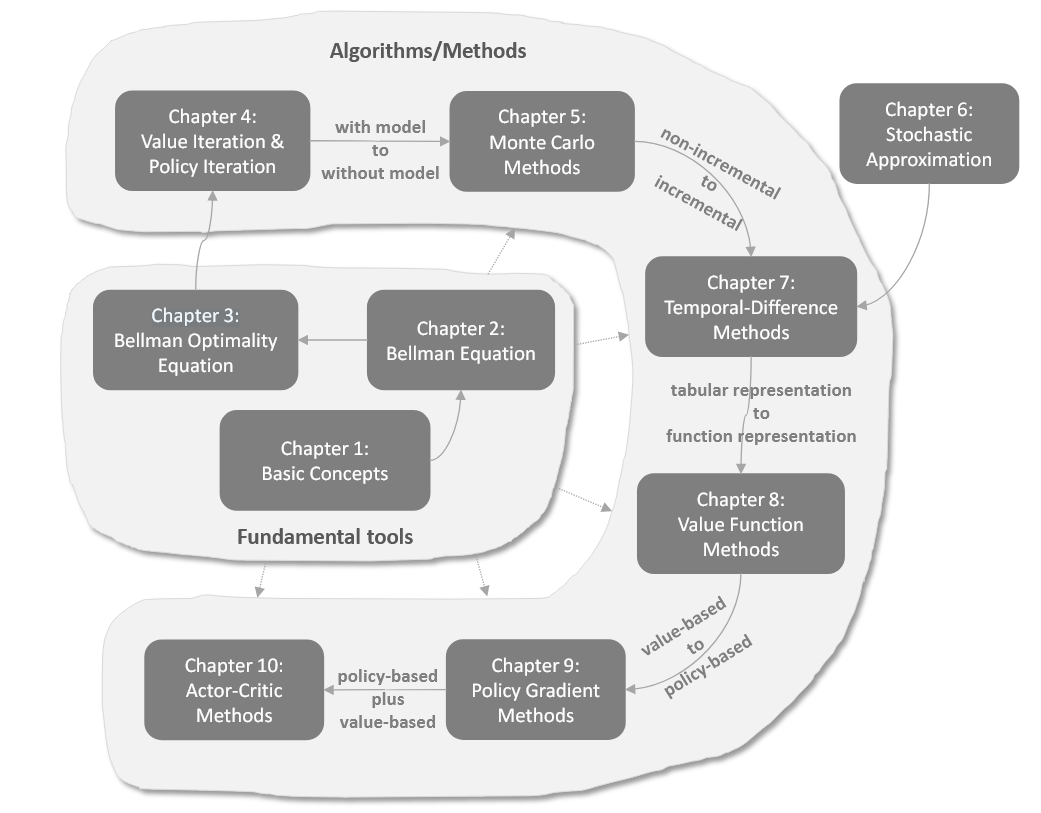
Reinforcement Learning
DPO(Direct Preference Optimization)
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) 奖励建模阶段 (Reward Model) RL微调阶段 直接偏好优化(DPO) 传统的RLHF方法分两步走: 1. 先训练一个奖励模型来判断哪个回答更好 1. 然后用强化学习让语言模型去最大化这个奖励 这个过程很复杂,就像绕了一大圈:先学习"什么是好的",再学习"如何做好"。 DPO发现了一个数学上的捷径: 1. 关键发现:对于任何奖励函数,都存在一个对应的最优策略(语言模型);反过来说,任何语言模型也隐含着一个它认为最优的奖励函数 1. 直接优化:与其先训练奖励模型再训练语言模型,不如直接训练语言模型,让它自己内化"什么是好的" 1. 数学转换:DPO将"学习判断好坏"和"学习生成好内容"这两个任务合二为一,通过一个简单的数学变换...
#LLM
#Reinforcement Learning