三维深度学习简介
- 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体;
- 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了;
- 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割;
- 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。

点云的特性
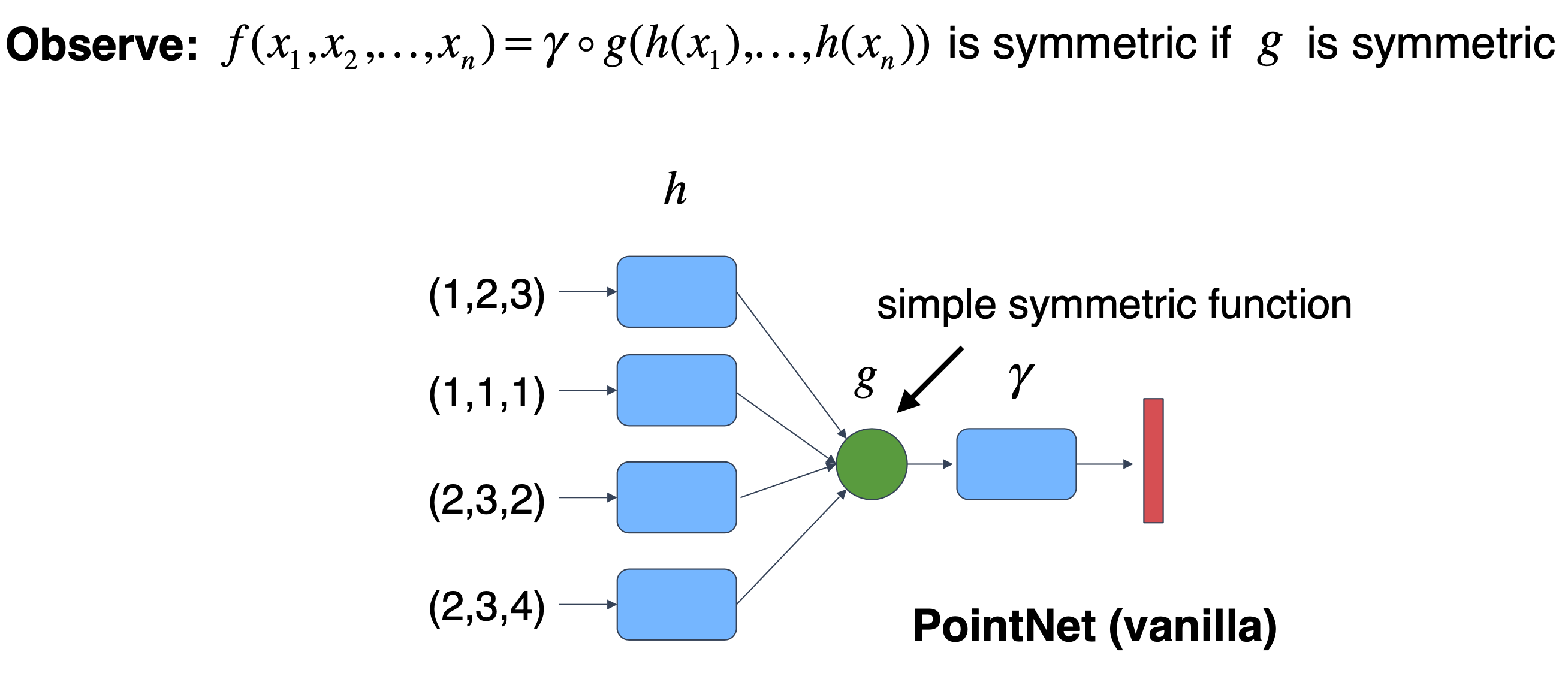
无序性:点云本质上是一长串点(nx3矩阵,其中n是点数),对数据的顺序是不敏感的。这就意味这处理点云数据的模型需要对数据的不同排列保持不变性。目前文献中使用的方法包括将无序的数据重排序、用数据的所有排列进行数据增强然后使用RNN模型、用对称函数来保证排列不变性。由于第三种方式的简洁性且容易在模型中实现,论文作者选择使用第三种方式,既使用maxpooling这个对称函数来提取点云数据的特征

我们知道,网络的一般结构是:提特征-特征映射-特征图压缩(降维)-全连接。
下图中x代表点云中某个点,h代表特征提取层,g叫做对称方法,r代表更高维特征提取,最后接一个softmax分类。g可以是maxpooling或sumpooling,也就是说,最后的D维特征对每一维都选取N个点中对应的最大特征值或特征值总和,这样就可以通过g来解决无序性问题。pointnet采用了max-pooling策略。
点与点之间的空间关系:一个物体通常由特定空间内的一定数量的点云构成,也就是说这些点云之间存在空间关系。为了能有效利用这种空间关系,论文作者提出了将局部特征和全局特征进行串联的方式来聚合信息。
旋转性:点云数据所代表的目标对某些空间转换应该具有不变性,如旋转和平移。论文作者提出了在进行特征提取之前,先对点云数据进行对齐的方式来保证不变性。对齐操作是通过训练一个小型的网络来得到转换矩阵,并将之和输入点云数据相乘来实现。
作者提出了T-Net来解决这个问题。其实T-Net相当于几何空间中的旋转矩阵,作者希望通过T-Net来实现点云的自动对齐。

实际上通过网络结构看出T-net结构是一个mini的Pointnet做特征提取,是个弱监督学习设计,我理解为需要训练一个矩阵对输入点(或者深层特征)进行坐标变换,个人认为这样的设计实际上是可以保留原始点云的部分特征,为后面的concat操作提供更多特征。源码中在点云分类部分使用到了T-net,点云分割部分可以不用,对结果并没有太大的提升,原因在于pointnet结构自身不能学到点云点的局部联系,因此即使加入类似结构的T-net也是一样。
def input_transform_net(point_cloud, is_training, bn_decay=None, K=3):
""" Input (XYZ) Transform Net, input is BxNx3 gray image
Return:
Transformation matrix of size 3xK """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
input_image = tf.expand_dims(point_cloud, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay)
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='tmaxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay)
with tf.variable_scope('transform_XYZ') as sc:
assert(K==3)
weights = tf.get_variable('weights', [256, 3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases = tf.get_variable('biases', [3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases += tf.constant([1,0,0,0,1,0,0,0,1], dtype=tf.float32)
transform = tf.matmul(net, weights)
transform = tf.nn.bias_add(transform, biases)
transform = tf.reshape(transform, [batch_size, 3, K])
return transform
PointNet
先来看网络的两个亮点:
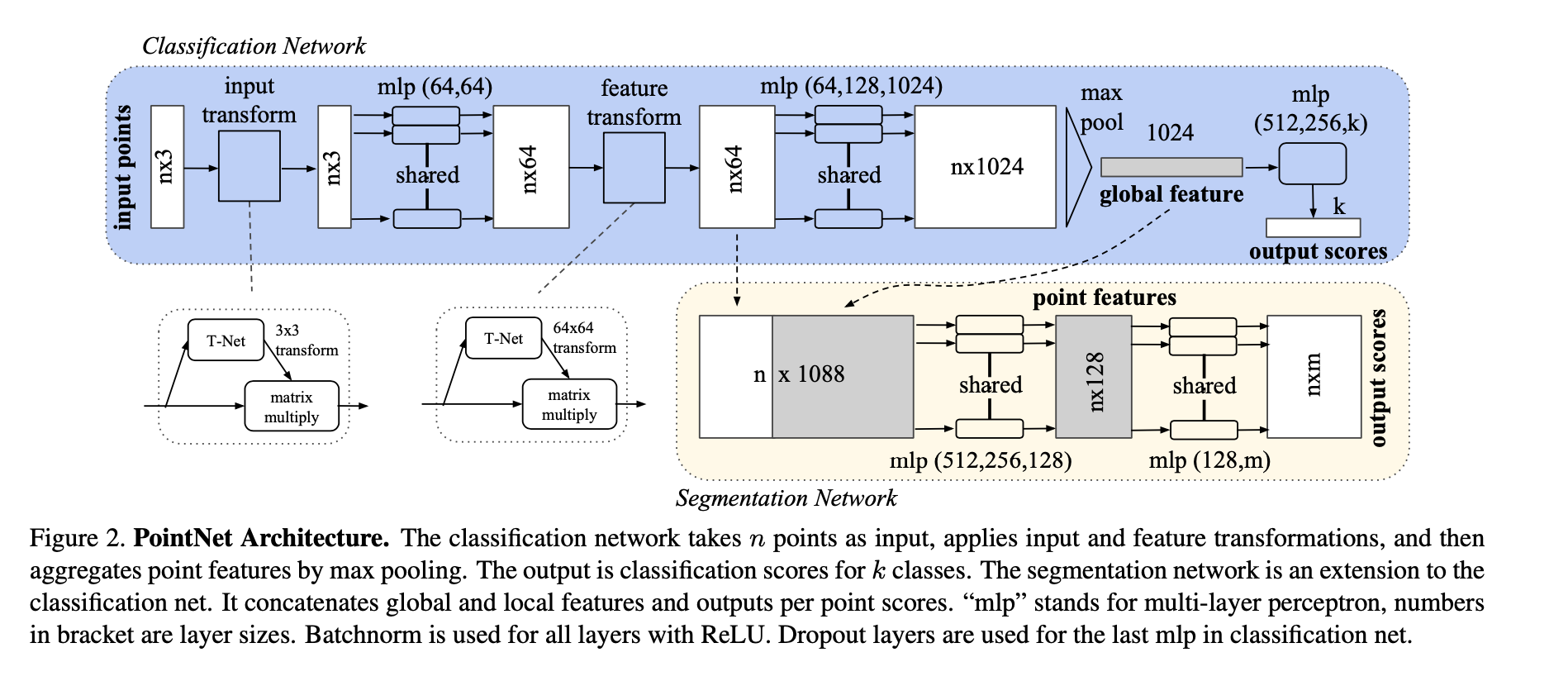
- 空间变换网络解决旋转问题:三维的STN可以通过学习点云本身的位姿信息学习到一个最有利于网络进行分类或分割的DxD旋转矩阵(D代表特征维度,pointnet中D采用3和64)。至于其中的原理,我的理解是,通过控制最后的loss来对变换矩阵进行调整,pointnet并不关心最后真正做了什么变换,只要有利于最后的结果都可以。pointnet采用了两次STN,第一次input transform是对空间中点云进行调整,直观上理解是旋转出一个更有利于分类或分割的角度,比如把物体转到正面;第二次feature transform是对提取出的64维特征进行对齐,即在特征层面对点云进行变换。
- maxpooling解决无序性问题:网络对每个点进行了一定程度的特征提取之后,maxpooling可以对点云的整体提取出global feature。
整体的关键流程如下:
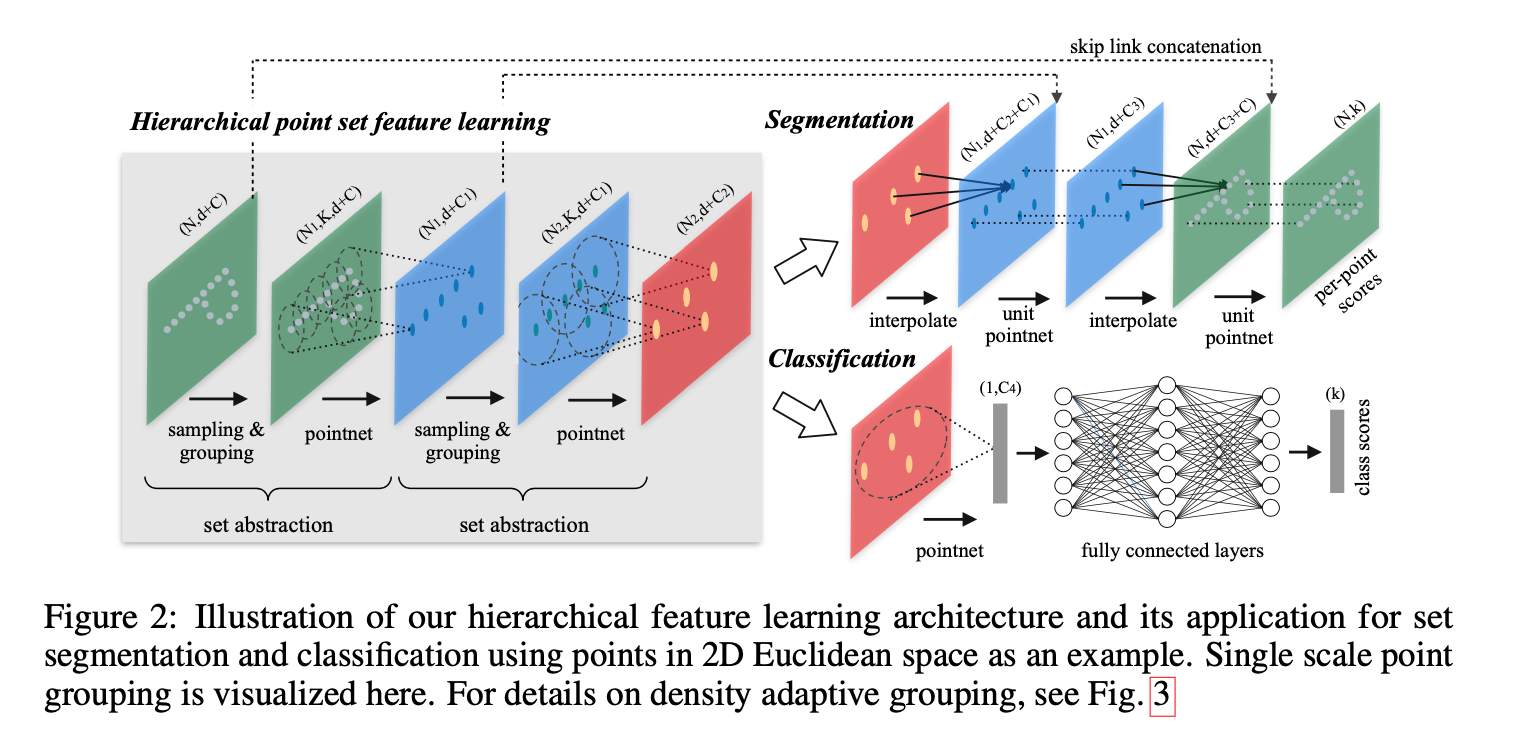
1、输入为一帧的全部点云数据的集合,表示为一个nx3的2d tensor,其中n代表点云数量,3对应xyz坐标。
2、输入数据先通过和一个T-Net学习到的转换矩阵相乘来对齐,保证了模型的对特定空间转换的不变性。
3、通过多次mlp对各点云数据进行特征提取后,再用一个T-Net对特征进行对齐。
4、在特征的各个维度上执行maxpooling操作来得到最终的全局特征。
5、对分类任务,将全局特征通过mlp来预测最后的分类分数;对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,再通过mlp得到每个数据点的分类结果。
PointNet++
PointNet提取特征的方式是对所有点云数据提取了一个全局的特征,显然,这和目前流行的CNN逐层提取局部特征的方式不一样。

所以继pointnet之后,很多人的着重点都在提取局部区域特征方面。为了解决这个问题, pointnet++ 的整体思想就是:首先选取一些比较重要的点作为每一个局部区域的中心点,然后在这些中心点的周围选取k个近邻点(欧式距离的近邻)。再将k个近邻点作为一个局部点云采用pointnet网络来提取特征。
网络的两个亮点:
1.改进特征提取方法:pointnet++使用了分层抽取特征的思想,把每一次叫做set abstraction。分为三部分:采样层、分组层、特征提取层。
2.解决点云密度不同问题:由于采集时会出现采样密度不均的问题,所以通过固定范围选取的固定个数的近邻点是不合适的。pointnet++提出了两个解决方案。
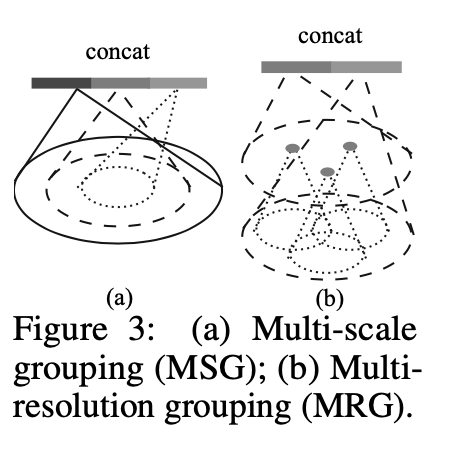
方案一:多尺度分组
如上图左所示,比较直观的思想是,在每一个分组层都通过多个尺度来确定每一个中心点的邻域范围,并经过pointnet提取特征之后将多个特征联合起来,得到一个多尺度的新特征。
方案二:多分辨率分组
很明显,通过上述做法,对于每一个中心点都需要多个patch的选取与卷积,计算开销很大,所以pointnet++提出了多分辨率分组法解决这个问题。如上图右所示,类似的,新特征通过两部分连接起来。左边特征向量是通过一个set abstraction后得到的,右边特征向量是直接对当前patch中所有点进行pointnet卷积得到。并且,当点云密度不均时,可以通过判断当前patch的密度对左右两个特征向量给予不同权重。例如,当patch中密度很小,左边向量得到的信息就没有对所有patch中点提取的特征可信度更高,于是将右特征向量的权重提高。以此达到减少计算量的同时解决密度问题。
PointNet++由以下几个关键部分构成:
采样层(sampling)
激光雷达单帧的数据点可以多达100k个,如果对每一个点都提取局部特征,计算量是非常巨大的。因此,作者提出了先对数据点进行采样。作者使用的采样算法是最远点采样(farthest point sampling, FPS),相对于随机采样,这种采样算法能够更好地覆盖整个采样空间。
组合层(grouping)
为了提取一个点的局部特征,首先需要定义这个点的“局部”是什么。一个图片像素点的局部是其周围一定曼哈顿距离下的像素点,通常由卷积层的卷积核大小确定。同理,点云数据中的一个点的局部由其周围给定半径划出的球形空间内的其他点构成。组合层的作用就是找出通过采样层后的每一个点的所有构成其局部的点,以方便后续对每个局部提取特征。
特征提取层(feature learning)
因为PointNet给出了一个基于点云数据的特征提取网络,因此可以用PointNet对组合层给出的各个局部进行特征提取来得到局部特征。值得注意的是,虽然组合层给出的各个局部可能由不同数量的点构成,但是通过PointNet后都能得到维度一致的特征(由上述K值决定)。
上述各层构成了PointNet++的基础处理模块。如果将多个这样的处理模块级联组合起来,PointNet++就能像CNN一样从浅层特征得到深层语义特征。对于分割任务的网络,还需要将下采样后的特征进行上采样,使得原始点云中的每个点都有对应的特征。这个上采样的过程通过最近的k个临近点进行插值计算得到。完整的PointNet++的网络示意图如下图所示。