LLaMA
一直致力于LLM模型研究的国外TOP 3大厂除了OpenAI、Google,便是Meta(原来的Facebook)
Meta曾第一个发布了基于LLM的聊天机器人——BlenderBot 3,但输出不够安全,很快下线;再后来,Meta发布一个专门为科学研究设计的模型Galactica,但用户期望过高,发布三天后又下线
23年2.24日,Meta通过论文《LLaMA: Open and Efficient Foundation Language Models》发布了自家的大型语言模型LLaMA,有多个参数规模的版本(7B 13B 33B 65B),并于次月3.8日被迫开源
LLaMA只使用公开的数据(总计1.4T即1,400GB的token,其中CommonCrawl的数据占比67%,C4数据占比15%,Github、Wikipedia、Books这三项数据均都各自占比4.5%,ArXiv占比2.5%,StackExchange占比2%),论文中提到
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM.
This means that training over our dataset containing 1.4T tokens takes approximately 21 days
试图证明小模型在足够多的的数据上训练后,也能达到甚至超过大模型的效果
比如13B参数的版本在多项基准上测试的效果好于2020年的参数规模达175B的GPT-3,而对于65B参数的LLaMA,则可与DeepMind的Chinchilla(70B参数)和谷歌的PaLM(540B参数)旗鼓相当
且Meta还尝试使用了论文「Scaling Instruction-Finetuned Language Models」中介绍的指令微调方法,由此产生的模型LLaMA-I,在MMLU(Massive Multitask Language Understanding,大型多任务语言理解)上要优于Google的指令微调模型Flan-PaLM-cont(62B)
LLaMA 2
23年7月份,Meta发布LLAMA 2,是 LLAMA 1 的更新版本
项目地址:
🔖 https://huggingface.co/meta-llama
论文地址:
🔖 https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
LLaMA 3
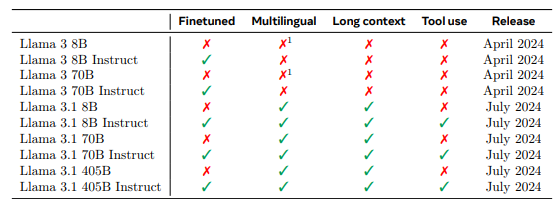
24年3月 发布了llama 3,7月又发布了3.1,是在3的基础上又增加了部分能力包含多模态、tools、多语言。
Llama3.2
🔖 https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
2024年九月底 llama又发布了llama 3.2模型,主要发布内容如下:
- 发布了适用于边缘设备和移动设备的中小型视觉 LLM(11B 和 90B)以及轻量级纯文本模型(1B 和 3B),包括预训练和指令调整版本。
- Llama 3.2 1B 和 3B 型号支持 128K 标记的上下文长度,在边缘本地运行支持高通和联发科硬件,并针对 Arm 处理器进行了优化。
- Llama 3.2 11B 和 90B 视觉模型可直接替代相应的文本模型,同时在图像理解任务方面优于 Claude 3 Haiku 等封闭模型。
Llama 3.3
🔖 https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_3/
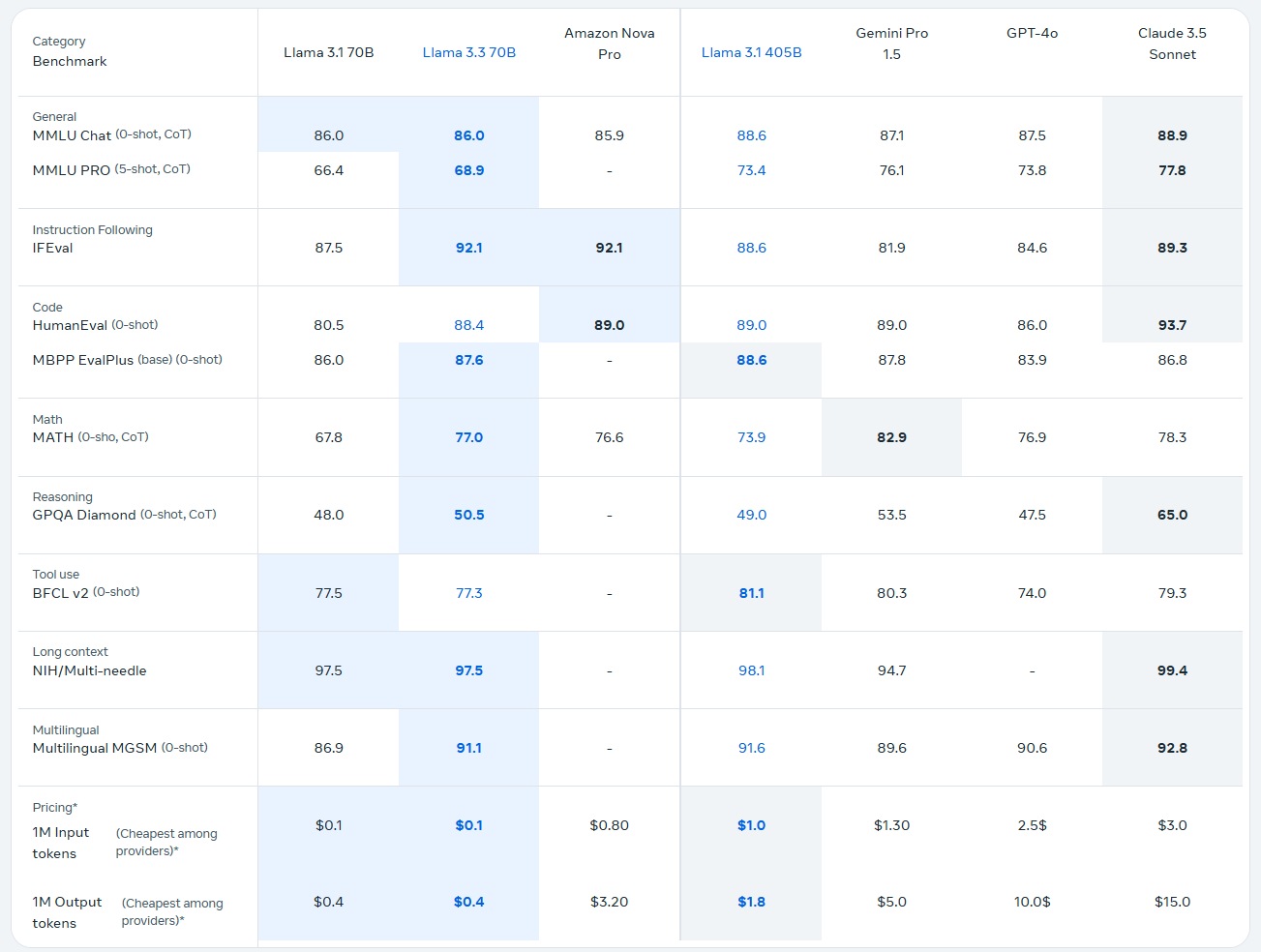
2024.12月 3.3又来了 不过这次没什么技术报告,只有个简单介绍,并且模型也没提供预训练版本,只有指令微调后的70B版本
Llama 3.3 是一个纯文本的 70B 指令调整模型,与 Llama 3.1 70B 相比性能更强,与 Llama 3.2 90B 相比用于纯文本应用时性能更强。此外,在某些应用中,Llama 3.3 70B 的性能接近 Llama 3.1 405B。