简介
论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》
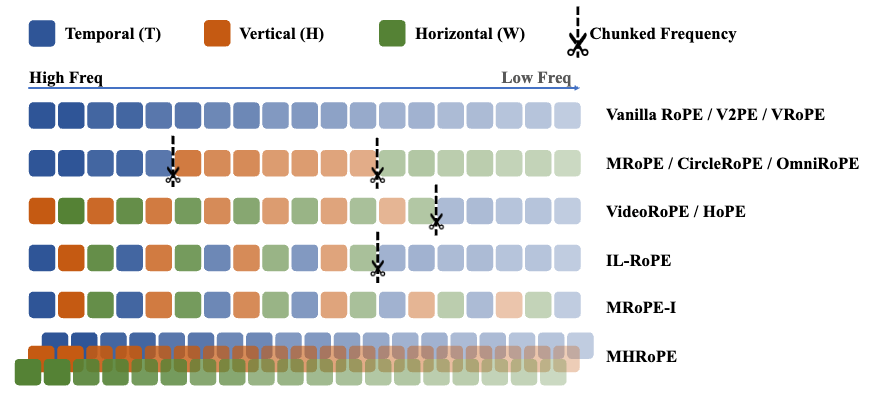
通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。
为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案:
- 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标;
- 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度;
- 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。
Vanilla RoPE
RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置\(m\)的查询向量\(q\)和位置\(n\)的键向量\(k\),注意力分数\(S\)的计算如下:
(1)中,变换矩阵 \(\mathcal{R}\) 本质上是一种正交旋转操作。这种设计的巧妙之处在于,它使得最终的注意力得分 \(S\) 仅取决于两个标记(Token)之间的相对位置差 \(n - m\)。
为了实现这一数学特性,\(\mathcal{R}_m\) 被构造为一个分块对角矩阵,其参数由当前元素的绝对位置 \(m\) 以及一组预设的固定频率 \(\theta_i\) 共同决定。具体而言,旋转频率 \(\theta_i\) 遵循等比数列(Geometric sequence)的形式进行设定:\(\theta_i = \text{base}^{-2i/d}\),其中维度索引 \(i \in [0, d/2 - 1]\)。
这种机制为模型引入了丰富的频率谱——从高频(对应较小的 \(i\) 值)平滑过渡到低频(对应较大的 \(i\) 值),并将这些频率依次映射到特征向量的每一对维度上。
1. 为什么强调“正交旋转”?
正交矩阵的一个重要性质是保持向量的内积和长度不变。这意味着,当我们对向量 \(\boldsymbol{q}\) 和 \(\boldsymbol{k}\) 分别施加旋转操作后,它们之间的点积大小不会因为绝对位置的改 变而发生畸变,而是纯粹地反映了它们在空间中的相对夹角(即相对位置 \(n-m\))。
2. 分块对角矩阵的作用
“分块对角矩阵”实际上是将一个高维向量(维度为 \(d\))划分成了 \(d/2\) 个二维子空间。在每一个二维平面内,模型使用一个特定的频率 \(\theta_i\) 对向量进行二维旋转。这种做法极大地降低了计算复杂度,同时保证了各个维度对之间的信息独立性。
3. 高频与低频的物理意义
频率的设计是 RoPE 的灵魂所在:
- 高频部分(较小的 \(i\)):旋转速度快,对位置变化非常敏感,主要用于捕捉局部、近距离的上下文依赖。
- 低频部分(较大的 \(i\)): 旋转速度慢,对位置变化不敏感,主要用于捕捉全局、远距离的语义关联。
位置设计
本节介绍了如何将位置标识符\(m\)分配给文本/视觉标记。
1D顺序设计。
最直观的方法是将多模态输入视为一个展平的(Flattened)、一维的序列。原始的 RoPE 和 V2PE 都采用了这种策略。在这种设计下,位置索引是递增分配的,第 \(i\) 个标记的位置 \(m_i\) 定义为:
其中,\(s_{\text{mod}}\) 是特定于该标记模态的步长(Step size)。在原始的 RoPE 中,所有模态都被一视同仁,步长统一设定为 \(s = 1\)。
一维设计的两大显著缺陷:
- 丢失了固有的 3D 结构:视觉内容(尤其是视频)天然具有空间和时间维度,将其强行展平为一维序列,会破坏这些结构信息,进而削弱视觉语言模型(VLM)的时空推理能力。
- 位置索引过度膨胀:在处理长序列时,位置索引会随着序列长度线性增长变得非常大。这会严重影响模型的外推性能(Extrapolation performance),即模型在面对比训练时更长的序列时,表现会大幅下降。
V2PE 的改进尝试:动态位置缩放
为了解决位置索引过大的问题,V2PE 为视觉标记引入了动态位置缩放(Dynamic position scaling)技术。它将视觉标记的步长 \(s_{\text{visual}}\) 设定为 \(\{1, 1/2, \dots, 1/256\}\) 中的某个分数。将步长 \(s_{\text{visual}}\) 设置为小于 1 的分数(如 \(1/2\) 或 \(1/4\)),本质上是让多个视觉 Token “共享”相近的位置编码,或者说让位置编码的变化变得更“缓慢”。
这一改进有效缓解了位置索引的快速增长,并在长视频理解任务中展现出了实际收益。然而,这种方法治标不治本——一维序列设计依然完全忽略了视觉内容的 3D 结构。
多维设计
这部分内容将视线从局限性较大的一维序列,转向了更符合物理直觉的多维位置编码设计(Multi-Dimensional Design)。为了保留视觉内容原生的 3D 结构,研究者们尝试将单一的标量位置扩展为多维坐标。
为了克服一维展平带来的结构丢失问题,多维设计试图在位置编码中还原图像和视频的空间与时间属性。
- MRoPE:将视觉内容视为“数据立方体”
MRoPE提出将标量位置标识符扩展为多维元组(Tuple)。例如,一个视觉 Token 的位置可以被表示为包含时间、高度、宽度三个维度的坐标:
在这种概念下,一段视觉内容(如一张图片或一组视频帧)被视为一个巨大的“数据立方体”。为了防止文本和视觉内容的位置发生重叠,后续 Token 的时间位置会直接“跳过”当前区块的最大坐标值。其更新规则如下:
这个设计的初衷非常务实,(2)的核心目的就是强制隔离——确保不同模态之间的位置索引绝对不会“撞车”。
- VideoRoPE 与 HoPE:追求对称性的“对角线布局”
尽管 MRoPE 避免了重叠,但 VideoRoPE 和 HoPE 的提出者认为,MRoPE 缺乏模态间的对称性(Inter-modal symmetry)。
为此,他们引入了“对角线布局(Diagonal layout)”,通过将空间坐标居中对齐,使得视觉帧不仅在时间轴上堆叠,还在垂直和水平轴上发生偏移。
- 致命缺陷(位置重叠与模态混淆):尽管在理论上很优雅,但这种布局引入了一个极其严重的问题。对于高分辨率图像(如文档截图),视觉 Token 的空间坐标会大幅向外延伸,最终侵入并重叠到后续生成的文本 Token 的索引范围中。
- 实验现象:作者指出,这种位置上的歧义会导致模型在生成时发生“模态混淆(Modalities confusion)”,具体表现为模型会陷入无休止的文本重复(Endless text repetition)。
- CircleRoPE:正交的“环形布局”
CircleRoPE另辟蹊径,将图像 Token 排列成一个环形布局,并且与文本位置的线性轴保持正交。
- 理论优势:这种设计的巧妙之处在于,任何一个视觉 Token 到任意给定文本 Token 的距离都是相等的,这在理论上促进了模型对整张图像的均匀注意力(Uniform attention)。
- 两大局限:
- 模态之间的间隔过大,可能会阻碍有效的跨模态交互。
- 缺乏时间轴:它将所有视频帧强行坍缩到了同一个圆环上,这会引入严重的时间歧义(Temporal ambiguity),使得模型无法分辨动作的先后顺序。
迈向最优的位置设计
基于前文的分析,一个鲁棒的位置编码设计必须满足几个核心标准,作者将其统称为位置连贯性(Positional Coherence):
- 保留视觉内容的原生 3D 结构;
- 保持位置索引的缓慢增长(有利于长序列外推);
- 避免生成时的模态混淆(防止文本与视觉索引重叠);
- 建立合适的模态间隔。
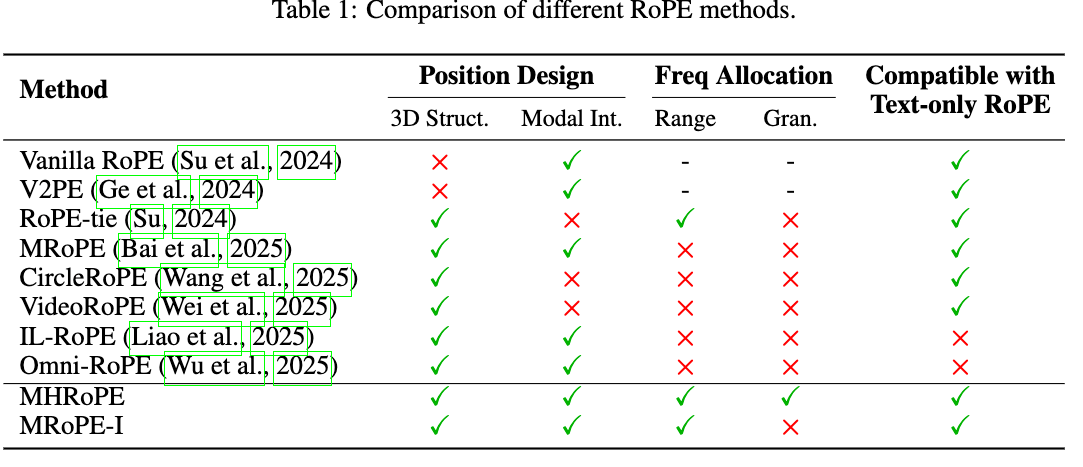
虽然 MRoPE 满足了上述大部分要求,但作者在分析中发现了一个关键现象:MRoPE 存在视觉上的“注意力池”(attention sink)效应。如下图所示,模型的注意力会异常集中在每张图像或视频帧的左上角。
这种现象与大型语言模型(LLM)中注意力集中在初始 Token 的现象如出一辙。基于这一洞察,作者提出了空间重置(Spatial-reset)机制:即对每一个独立的视觉内容,都将其空间维度(高和宽)的坐标重置为从零开始。
通过应用空间重置,作者旨在将这种视觉上的“注意力池”与 LLM 天生偏好较小位置 ID 的特性对齐,从而加速模型对视觉特征的适配。
除了解决注意力池问题,空间重置在视频理解中还提供了一个巨大的优势:解耦时空维度。
假设一个物体在时间 \(t_1\) 的空间坐标为 \((h_1, w_1)\),在时间 \(t_2\) 移动到了 \((h_2, w_2)\)。我们设它们对应的绝对位置索引分别为 \(\boldsymbol{m}_1\) 和 \(\boldsymbol{m}_2\)。
- 在标准的 MRoPE 设定下(时空耦合):
由于时间维度会不断累加到空间维度上,其绝对位置被定义为:
这导致计算出的相对位置索引 \(\boldsymbol{m}_{\text{rel}} = \boldsymbol{m}_2 - \boldsymbol{m}_1\) 变得相互纠缠(Entangled):
- 在本文提出的空间重置机制下(时空解耦):
空间维度被独立重置,不再受时间累加的影响。绝对位置被干净地定义为:
这产生了一个纯粹的时空相对向量:
观察(3),在旧方法中,物体在高度上的相对位移竟然包含了时间差 \((t_2 - t_1)\)。这意味着,即使物体在原地不动(\(h_2 = h_1\)),只要时间流逝了,模型也会认为它在空间坐标上发生了相对偏移。这显然是违背物理常识的。 (4)则完美解决了这个问题:时间归时间,空间归空间。模型可以非常直观地通过 \(h_2 - h_1\) 和 \(w_2 - w_1\) 来判断物体的运动轨迹,这大大降低了模型学习视频中物体运动规律的难度。
这种解耦后的运动表征更加符合物理直觉,为模型学习提供了更清晰的归纳偏置(Inductive bias)。因此,本文提出的 MHRoPE 和 MRoPE-I 方法正是建立在结合了“空间重置”的 MRoPE 基础之上
小结
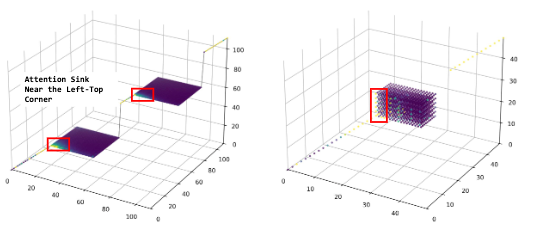
如上图所示,对比总结了文中出现的基于rope的方案,在看具体的子图之前,我们先明确图中的基本元素:
- 三个坐标轴:\(T\) 轴代表时间/序列维度(文本的先后顺序),\(H\) 轴和 \(W\) 轴代表视觉内容的高度和宽度(空间维度)。
- 点的颜色:蓝色点代表输入的文本(如 System prompt),橙色方块/点代表视觉内容(图片或视频),绿色点代表模型最终生成的文本。
我们的核心目标是观察橙色视觉模块是如何在这三个维度中摆放的,以及它们与绿色/蓝色文本模块的关系。
- Vanilla RoPE / V2PE:简单粗暴的“一维拉面”
- 所有点连成了一条笔直的对角线。\(H\) 轴和 \(W\) 轴完全没有被利用。
- 这就是前文提到的“一维序列设计”。图片和视频被强行压扁成了一根线。
- 图中红圈标出了 \(T\) 轴的刻度飙升到了 500(Fast-growing Position IDs)。不仅完全丢失了 3D 空间结构,还导致位置 ID 迅速膨胀,拖垮模型的长文本能力。
- MRoPE:稳扎稳打的“阶梯积木”
- 橙色的视觉内容终于变成了有长宽的“方块”(保留了 3D 结构)。为了防止和文本重叠,每次遇到方块,\(T\) 轴就会往上“跳”一截,形成阶梯状。
- 优势:完美保留了 3D 结构,且文本和视觉的 ID 绝对不会重叠。
- 局限:随着序列变长,方块在 \(H\) 和 \(W\) 轴上的绝对坐标也在不断变大,没有对齐 LLM 喜欢“小 ID”的偏好(即前文提到的注意力池问题)。
- VideoRoPE / HoPE:弄巧成拙的“对角线偏移”
- 为了追求所谓的“对称性”,橙色方块被沿着对角线错开摆放。
- 致命伤(红框标注):由于高分辨率图像的方块太大了,它的边缘直接撞进了代表生成文本的绿色点区域(Modalities Confusion in Generation!)。这就导致了前文提到的“模态混淆”,模型会开始无限重复生成废话。
- CircleRoPE:支离破碎的“呼啦圈”
- 视觉内容被排成了奇怪的环形,且与文本序列隔得很远。
- 致命伤:视频帧被强行挤压在一起(Squeezed Video Frames,丢失了时间先后顺序),且视觉和文本之间的 ID 跨度太大(Large ID Spacing),导致图文之间难以产生有效的注意力交互。
- IL-RoPE / Omni-RoPE:不兼容的“另起炉灶”
- 视觉方块确实都靠在了左边,但文本的 \(T\) 轴却在天上飞。
- 致命伤:“与纯文本 RoPE 不兼容”(Not Compatible with Text-only RoPE)。这意味着如果用这种方式,原本预训练好的强大纯文本语言模型的能力会大打折扣,后文具体介绍。
- MHRoPE / MRoPE-I(本文提出的终极方案)
- 注意看所有的橙色方块——无论它出现在序列的哪个位置,它的 \(H\) 和 \(W\) 坐标永远从 0 开始(紧贴着左侧的墙壁)。这就是前文提到的“空间重置 (Spatial-reset)”。
- 核心优势:
- 完美解耦:时间 \(T\) 轴缓缓上升,而空间坐标每次归零,时空不再纠缠。
- 对齐注意力池:红字标出“Attention Sink Near (t, 0, 0)”,所有的视觉起点都在小 ID 处,模型能极其高效地聚焦视觉信息(More Focus on Visual Info)。
- 安全无重叠:绝不会出现 (c) 图中的模态混淆现象。
频率分配
这部分内容将我们的视角从“位置坐标的分配”转移到了 RoPE 的另一个底层核心机制:频率分配(Frequency Allocation)。
如果说前面的内容是在讨论“Token 应该放在 3D 空间的哪个坐标上”,那么这一节探讨的就是“如何将这些坐标映射到模型的特征通道(Feature channels)中”。作者在这一节犀利地指出了现有方法在分配高低频通道时面临的“拆东墙补西墙”的困境。
频率分配决定了位置标识符 \(\boldsymbol{m}\) 的各个轴(时间 \(t\)、高度 \(h\)、宽度 \(w\))是如何与特征通道及其对应的旋转频率 \(\theta_i\) 绑定的。
一维 RoPE 的频率分配
在 Vanilla RoPE 和 V2PE 等一维方法中,所有的特征通道都被用来编码单一的序列轴。
- 频率衰减特性:随着通道索引 \(i\) 的增加,旋转频率 \(\theta_i\) 会逐渐衰减。这就形成了一个连续的频谱:高频通道负责捕捉短距离依赖(Short-range dependencies),而低频通道负责捕捉长距离依赖(Long-range dependencies)。
- 注意力衰减:这种设计赋予了注意力分数一种“长程衰减”的物理特性——两个 Token 距离越远,它们之间的注意力上限就越低。前文提到的 V2PE 通过缩放位置索引,实际上就是减缓了这种衰减,从而让模型能看清更长的视觉内容。
这里证明一下这个结论,“注意力长程衰减特性”的底层硬核基石:为什么距离越远的 Token,它们之间的注意力上限就越低。
在 Transformer 模型中,注意力分数本质上是 Query 向量(\(\boldsymbol{q}\))和 Key 向量(\(\boldsymbol{k}\))的内积。在 RoPE 中,位于位置 \(m\) 的 Query 向量 \(\boldsymbol{q}\) 和位于位置 \(n\) 的 Key 向量 \(\boldsymbol{k}\) 之间的点积(即注意力分数的基础),可以被优雅地转化为复数域的表达形式:
在这里:
- \(d\) 是特征维度。
- \(\boldsymbol{v}^*\) 表示将 2D 向量视为复数时的复共轭。
- \(\cdot\) 表示复数乘法。
- \(\theta_i\)是第 \(i\) 个通道的固定旋转频率。
为了解开这个复杂的求和式,作者引入了数学分析中非常经典的分部求和法(Summation by parts)。其标准公式为:\(\sum_{i=a}^b u_i \Delta v_i = [u_i v_i]_a^{b+1} - \sum_{i=a}^b v_{i+1} \Delta u_i\)
为了套用这个公式,我们需要先定义两个关键序列,并设定边界条件:
- 内容依赖序列 (Content-dependent sequence) \(h_i\):
注:它只和输入的特征有关,与位置无关。
- 位置依赖序列 (Position-dependent sequence) \(S_j\)(即部分和):
注:它只和相对位置 \((m-n)\) 以及频率有关,与内容无关。
- 边界条件 (Boundary conditions):
为了让推导成立,设定 \(S_0 = 0\) 且 \(h_{d/2} = 0\)。
将上述定义的 \(h_i\) 和 \(S_i\) 代入初始的求和项中,并应用分部求和法,我们就可以得到整个论文中最核心的不等式推导:
这里
- 第一步到第二步:直接应用分部求和公式。
- 第二步到第三步:展开边界项 \([h_i S_i]_0^{d/2}\)。
- 第三步到第四步:代入我们预设的边界条件(\(S_0 = 0\) 和 \(h_{d/2} = 0\)),前面的项直接归零,只剩下后面的求和项。
- 第四步到第五步:应用绝对值不等式(三角不等式),将绝对值符号放缩到求和号内部。
- 第五步到最后一步:提取出 \(|h_{i+1} - h_i|\) 在所有通道中的最大值作为公共的放大系数,从而彻底将 \(h\)(内容)和 \(S\)(位置)分离。
最终的表达式揭示了一个极其深刻的结论:RoPE 注意力分数的上限,是两个完全独立部分的乘积。
- 内容缩放因子:\(\max_{0 \le i < d/2} |h_{i+1} - h_i|\)
这是一个纯粹由 Query 和 Key 向量决定的项。它在公式中扮演了一个“基础缩放系数”的角色,完全独立于位置信息。
- 位置衰减因子:\(\sum_{i=0}^{d/2-1} |S_{i+1}|\)
这是一个纯粹由相对位置 \((m-n)\) 和固定频率 \(\theta_i\) 决定的项。
因为第一项(内容项)与位置无关,所以模型在处理长序列时,注意力分数的长程衰减特性(Long-range decay property)完全由第二项(位置项)主导。
因此,作者提出,我们可以直接用这个位置项的平均值(即 \(\frac{1}{d/2} \sum_{i=1}^{d/2} |S_i|\))作为一个极具实用价值的指标,来量化和刻画注意力上限是如何随着相对距离的增加而衰减的。这就为后续分析 MRoPE 的频率分配缺陷,以及提出 MRoPE-I 提供了最坚实的数学武器。
多维频率分配的“权衡困境”
当位置编码从一维扩展到多维时,如何将有限的 \(d\) 个特征维度分配给 \(t, h, w\) 三个轴,成为了一个巨大的难题。
- MRoPE 的“高频时间偏见”与“空间不对称”
标准的 MRoPE 采用了一种最直接的切分法:将 \(d\) 个维度切成三个连续的块,依次分给 \(t, h, w\) 轴。
- 致命缺陷 1(时间衰减过快):由于频率是按通道索引递减的,排在最前面的 \(t\) 轴被迫包揽了所有最高频的通道。这产生了一个极强的归纳偏置,导致模型对时间的注意力衰减得极其迅速,严重破坏了模型理解长序列的能力。
- 致命缺陷 2(空间不对称):\(h\) 轴和 \(w\) 轴被分配到了互不重叠的不同频段,导致它们在长距离上的衰减率完全不同。这种不对称性会阻碍模型学习一致的空间几何关系。
- 后续方法的“拆东墙补西墙”
为了拯救被高频毁掉的时间轴,后续的 VideoRoPE、HoPE 甚至 IL-RoPE 尝试了各种重新分配策略,它们的核心思路出奇一致:把时间轴 \(t\) 移到低频通道去。
- 未解决的致命代价:虽然这确实缓解了长文本/长视频的理解问题,但它引入了一个极其糟糕的 Trade-off——空间维度 \(h\) 和 \(w\) 被无情地挤压到了受限的、几乎全是高频的频段中。
- 后果:这严重限制了模型捕捉“多尺度空间关系”的能力。在需要精细化空间推理的任务(如视觉定位 Visual grounding)中,模型的性能会大幅缩水。
此外,作者还一针见血地指出:无论怎么分配,只要你硬性切分了特征维度,就必然会导致每个坐标轴的“频率分辨率”变粗糙。
💡 深度解析:为什么高低频分配如此重要?
高频像“秒针”,低频像“时针”。
- 高频通道变化极其剧烈,它对极其微小的距离变化非常敏感。如果只用高频来编码时间,模型就会变成一个“近视眼”,只能记住刚刚发生的事情,稍微久远一点的信息就会在剧烈的波动中被衰减殆尽。
- 低频通道变化缓慢,它能跨越很长的距离保持稳定的信号,是模型理解长上下文的基石。
现有多维方法的悲哀在于通道总数是固定的。MRoPE 把“秒针”给了时间,导致模型记不住长视频;VideoRoPE 把“时针”抢过来给了时间,却导致空间维度只剩下“秒针”,模型瞬间失去了对宏观图像结构的感知能力。
迈向最优的频率分配
为了彻底打破前文提到的“频率分配困境”,作者在这一节亮出了他们的两把“杀手锏”:多头分配(Multi-Head Allocation)与交错分配(Interleaved Allocation)。这两种策略的核心目标非常一致——让每一个坐标轴(时间、高度、宽度)都能同时拥有“秒针”(高频)和“时针”(低频),从而实现统一的衰减曲线。
为了解决 MRoPE 带来的时间衰减过快和空间衰减不对称的问题,作者提出了两种全新的频率分配策略。
MHRoPE (Multi-Head Allocation)
- 设计灵感:近期的研究发现,在注意力头(Attention head)存在冗余,RoPE 在通道级别存在类似的冗余。
- 核心机制:与其在一个注意力头内部把通道切碎分给 \(t, h, w\),不如直接让不同的注意力头负责不同的坐标轴。例如,头 \(A\) 专门负责编码时间 \(t\),头 \(B\) 专门负责高度 \(h\)。
- 优势:
- 全频段覆盖:每个轴在其专属的注意力头内,都能使用完整的频率频谱(从最高频到最低频),彻底避免了频率分辨率的损失。
- 极强的扩展性:如果未来引入了更多的维度(比如 3D 医疗影像的深度轴 \(d\)),传统的通道切分法会因为通道数不够而崩溃,而多头分配只需要分配新的注意力头即可,极其灵活。
MRoPE-I (Interleaved Allocation)
- 核心机制:在同一个注意力头内,采用细粒度的轮询(Round-robin)方式,将特征通道交错分配给 \(t, h, w\) 轴。就像发扑克牌一样,通道 1 给 \(t\),通道 2 给 \(h\),通道 3 给 \(w\),通道 4 再给 \(t\)……以此类推。
- 核心优势:
- 多尺度建模:这种交错设计确保了每个坐标轴在宏观上都均匀地分布在整个频谱中。无论是时间还是空间,都能同时捕捉到高频的细节和低频的宏观结构。
- 外推算法的完美伴侣:均匀的频率分布使得它能够与现有的上下文扩展算法(如 NTK-aware 和 YaRN)无缝兼容。
在附录中,作者详细解释了为什么 MRoPE-I(交错分配)在处理超长上下文时具有得天独厚的优势。
- 为什么标准 MRoPE 难以使用 YaRN?
YaRN 等外推算法的核心原理是对频率频谱进行缩放(Rescaling)。在标准的 MRoPE 中,由于 \(t, h, w\) 的频谱是被生硬切断的,导致很难找到一个统一的缩放边界。而 MRoPE-I 的交错设计让所有轴共享完整的频谱,使得 YaRN 的应用变得极其直接和对称。
- 更小的缩放代价 (Smaller Scaling Factor)
这是一个非常亮眼的工程优势。相比于传统的 Vanilla RoPE,MRoPE-I 需要的 YaRN 缩放因子(Scaling factor)更小。
- 底层原因:在 Vanilla RoPE 中,一张图像的位置 ID 增长速度是 \(O(h \times w)\)(面积级别膨胀);而在 MRoPE-I 的空间重置设计下,位置 ID 的推进速度仅为 \(O(\max(h, w))\)(边长级别增长)。
- 实验数据:经验表明,对于 \(512 \times 512\) 分辨率的输入,MRoPE-I 所需的缩放因子仅仅是 Vanilla RoPE 的 3/4。这意味着模型在扩展上下文时,需要进行的“数学妥协”更少,能更好地保持原有性能。
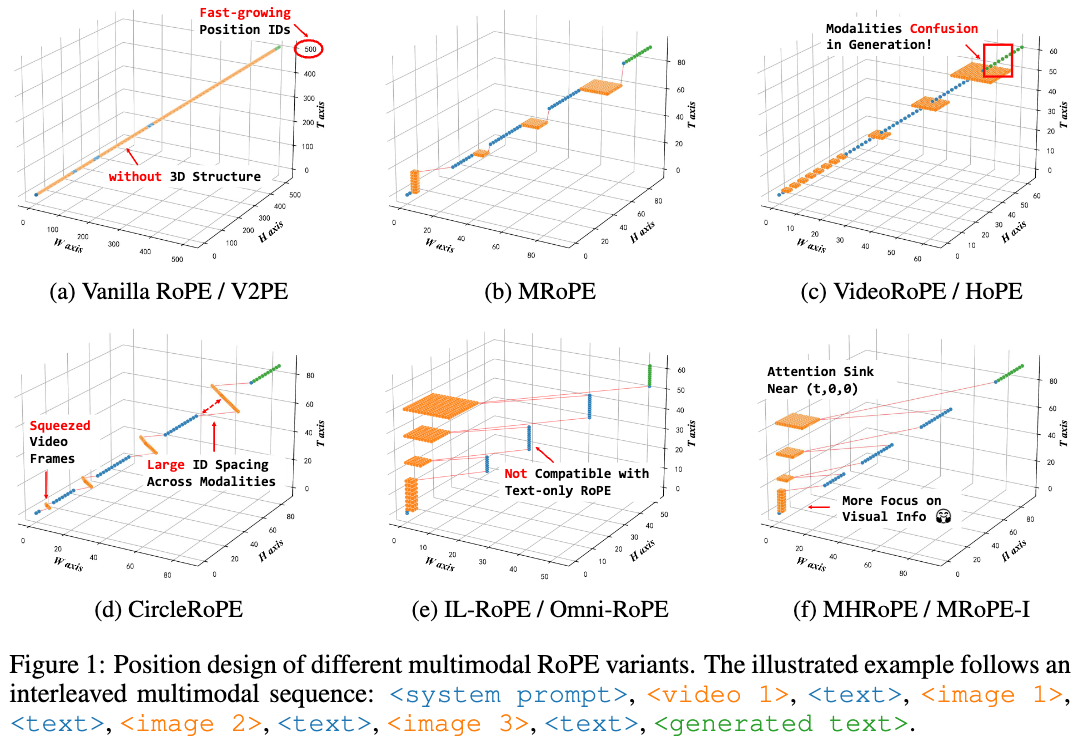
下图展示了不同多模态RoPE的频率分配。
与纯文本 RoPE 的兼容性
作者在这里探讨了一个经常被忽视但极其致命的工程陷阱——与纯文本语言模型(LLM)的兼容性,并在最后对提出的两种方案(MHRoPE 和 MRoPE-I)给出了极具实践指导意义的最终建议。
目前绝大多数的多模态大模型(VLM)都是站在“巨人”的肩膀上——即基于已经预训练好的强大纯文本 LLM 微调而来的。这就引出了一个灵魂拷问:在加入多模态能力时,我们能不能修改原本纯文本的编码方式?
作者通过正反两方面的论证,给出了坚定的答案:绝对不能。
- 位置设计的反面教材
像 IL-RoPE 和 Omni-RoPE 这样的方法,为了方便图像编辑,在重置图像坐标的同时,强行把文本 Token 的空间维度设为了零。这就像是强行改变了原本 LLM 习惯的“坐标系”,直接破坏了与预训练 LLM 中标准 RoPE 的兼容性,导致模型原有的文本能力受损。
- 频率分配的失败尝试
作者自己也坦诚地分享了一个“失败的实验”。由于图像的空间坐标范围(比如 0~50)远小于文本的时间坐标范围(可能高达几万),作者曾尝试为空间维度使用一个更小的旋转“底数”(Base)。
然而,实验结果惨不忍睹。这个失败的教训得出了一个极其重要的结论:为了有效地继承预训练 LLM 中蕴含的海量知识,必须保持与纯文本 RoPE 的完全兼容。 任何试图在底层数学机制上“抖机灵”的修改,都会遭到预训练权重的反噬。
MHRoPE vs. MRoPE-I
基于前文所有的分析与避坑指南,作者正式总结了他们提出的两种多模态 RoPE 变体。它们拥有共同的强大基因,但在具体的频率分配上走向了不同的道路。
共同的制胜基因:
- 空间重置 (Spatial-reset):解决视觉注意力池问题,解耦时空运动表征。
- 绝对兼容:严格保持与纯文本 RoPE 的兼容,完美继承 LLM 能力。
虽然两种方法都很优秀,但在实际的工程落地中,作者强烈推荐使用 MRoPE-I(交错分配)。
- 微弱但稳定的性能优势:MHRoPE 把不同的坐标轴分给了不同的注意力头,这导致在单一的注意力头内部,模型无法同时综合考虑时间、高度和宽度信息。而 MRoPE-I 的交错设计让每个注意力头都能看到完整的时空信息,因此性能略胜一筹。
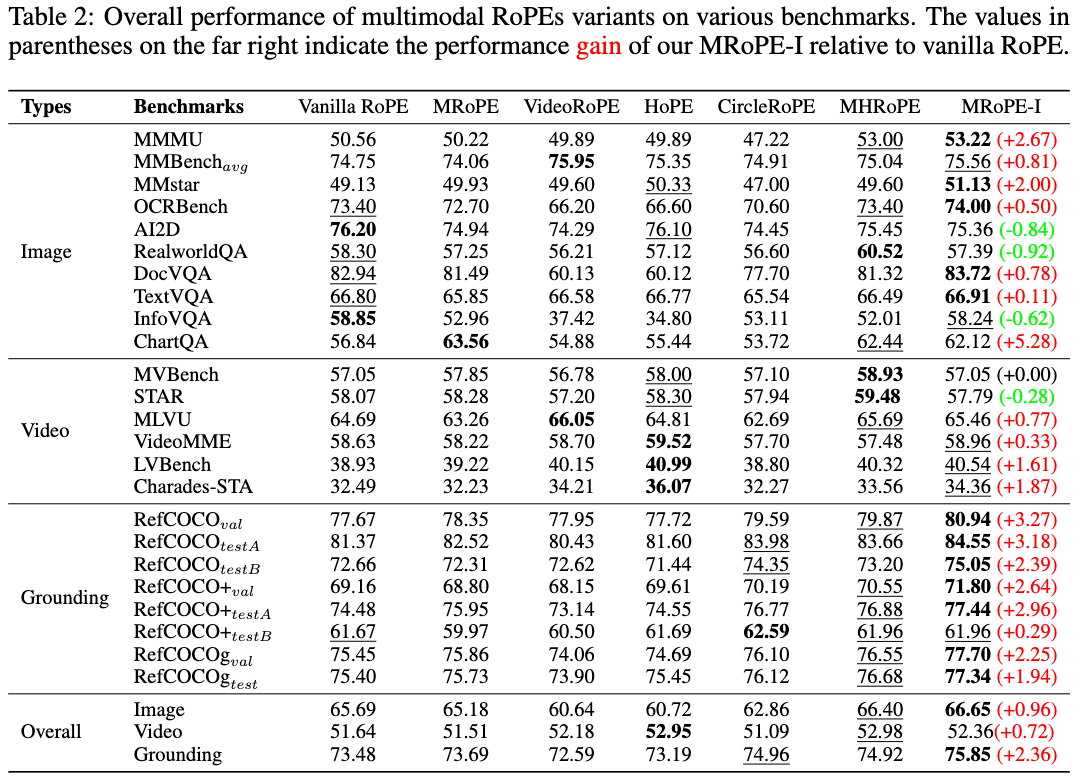
- 工程实现的极简性 (最关键):在训练千亿级别的大模型时,通常会使用张量并行(Tensor Parallelism)等分布式训练技术,这会将注意力头切分到不同的 GPU 上。如果使用 MHRoPE,不同 GPU 负责的坐标轴都不一样,这会引入极其复杂的工程灾难。而 MRoPE-I 在每个通道内的交错设计,完美避开了这些分布式训练的复杂性。
最终结论: 如果您现在就要训练一个图文视频多模态大模型,MRoPE-I是兼顾性能、长文本外推与工程实现的最优解;但如果未来我们要迈向包含 3D 空间、深度、甚至更多物理维度的“全模态”时代,MHRoPE那种无限扩展的架构潜力将成为新的希望。这应该也是Qwen3-VL选择MRoPE-I的原因。