ControlNet应该算是2023年文生图领域最重要的工作,它让文生图模型Stable Diffusion实现了文本之外的可控生成,让AI绘画实现了质的飞跃。这篇文章我们将简单总结一下ControlNet技术细节。

模型设计
ControlNet的模型结构如下所示,这里是直接复制一份SD的上半部分:Encoder和中间的Middle Block。
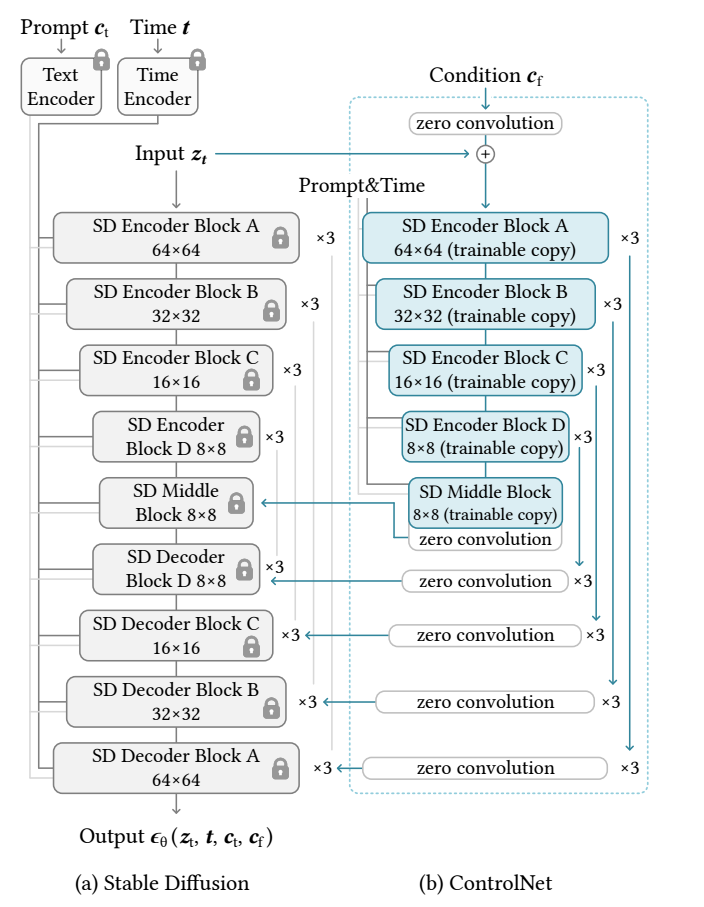
ControlNet的输入和原始的SD一样,包括noisy latents、time embedding以及text embedding。除此之外,ControlNet还需要引入额外的condition,这个condition是和原图一样大小的图像,比如canny边界图或者人体骨架图。这里并没有像SD那样采用VAE对condition进行编码,而且直接采用一个小的卷积网络来提出condition特征,并将特征加在noisy latents经过第一个卷积后的输出上。由于VAE编码后的latents分辨率降低了8x,所以这个小的卷积网络需要将condition下采样8x,并输出和noisy latents同维度的特征(对于SD 1.5,512x512的输入特征维度是64x64x320)。这个小卷积网络的结构如下所示,其中包含3个stride=2的卷积层来进行下采样:
input_hint_block = TimestepEmbedSequential(
conv_nd(dims, hint_channels, 16, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 16, 16, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 16, 32, 3, padding=1, stride=2),
nn.SiLU(),
conv_nd(dims, 32, 32, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 32, 96, 3, padding=1, stride=2),
nn.SiLU(),
conv_nd(dims, 96, 96, 3, padding=1),
nn.SiLU(),
conv_nd(dims, 96, 256, 3, padding=1, stride=2),
nn.SiLU(),
zero_module(conv_nd(dims, 256, model_channels, 3, padding=1))
)
ControlNet为什么没有采用VAE而是重新设计一个小卷积网络来编码condition,这个是不得而知的。但是我个人觉得也是没问题的,首先condition大部分是比较简单的图像比如canny边缘图,采用一个小卷积网络提取特征是足够的,此外VAE编码本身也会造成一定的信息损失。 另外一个重要的地方是ControlNet如何将特征嵌入原始SD的UNet中,这里是借鉴了UNet中skip connection设计,所谓的skip connection是指UNet的Encoder中的中间输出特征会以跳连的方式连接到Decoder中。对于SD 1.5,UNet的Encoder共包含4个stage,每个stage包含2个blocks,前三个stage的block是由ResBlock和Attention Block组成,而且最后会有Down操作,最后一个stage的block只是ResBlock,也没有Down操作。UNet的Decoder也包含4个stage,但是每个stage包含3个block,所以是和Encoder是有点不对称的。对于UNet的Encoder,第一个Conv层的输出、每个block的输出以及每个Down的输出将以skip connection方式进入Decoder中对应的block中(以concat的方式)。如果输入是512x512图像,那么UNet的Decoder会产生64x64、32x32、16x16以及8x8尺度的特征各3个,所以共有4x3=12个skip connection,而UNet的Decoder的block也正好是4x3=12个(不包含Up),这样就正好对上了。
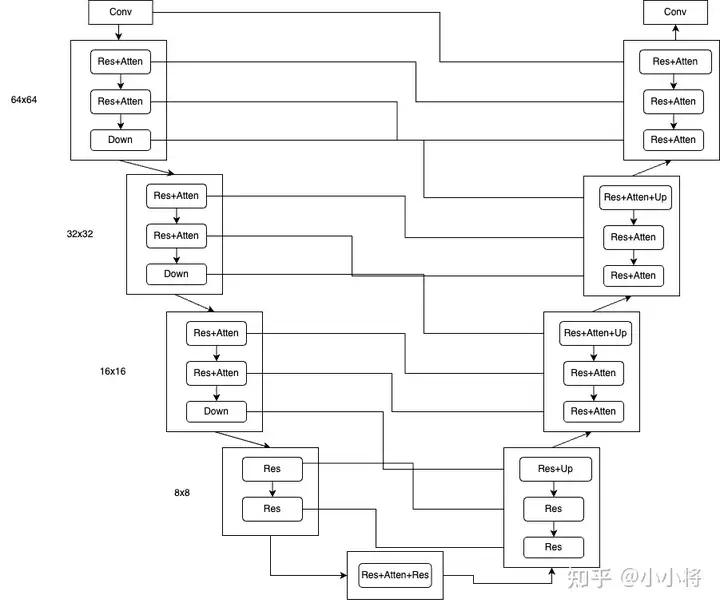
ControlNet复制了UNet的Encoder,所以也可以提取出12个特征,只需要将这个12个特征加在原来UNet的Encoder的12个特征输出上,然后以skip connection方式就可以嵌入UNet的Decoder中了。由于ControlNet还额外复制了Middle Block,这里也将Middle Block的输出加在原始UNet的Middle Block的输出上,这也意味着ControlNet共产生了13个skip connection。
class ControlledUnetModel(UNetModel):
def forward(self, x, timesteps=None, context=None, control=None, only_mid_control=False, **kwargs):
hs = []
with torch.no_grad():
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
emb = self.time_embed(t_emb)
h = x.type(self.dtype)
for module in self.input_blocks:
h = module(h, emb, context)
hs.append(h)
h = self.middle_block(h, emb, context)
# hs是SD UNet encoder产生的12个skip connection
# control是ControlNet产生的13个skip connection
if control is not None:
h += control.pop() # controlnet mid block skip connection
for i, module in enumerate(self.output_blocks):
if only_mid_control or control is None:
h = torch.cat([h, hs.pop()], dim=1)
else:
# 将controlnet的skip connection加在UNet encoder对应的skip connection
h = torch.cat([h, hs.pop() + control.pop()], dim=1)
h = module(h, emb, context)
h = h.type(x.dtype)
return self.out(h)
ControlNet复制UNet结构的同时继承权重来初始化,此外ControlNet还采用了zero初始化,这里在condition的特征输出后加了一个zero conv,同时13个skip connection特征输出上分别也加上了一个zero conv。zero初始化使得整个网络在训练开始时的输出和原始UNet是一样的,这样可以尽量避免初始训练的噪音对ControlNet复制的结构和权重的破坏。
训练
ControlNet的训练是将SD原始UNet和ControlNet一起训练,但SD的UNet是冻结的,只训练ControlNet部分的权重。训练的损失函数还是采用原始SD所用的拟合噪音的 \(L^{\text{simple}}\):
其中\(\mathbf{c}_{t}\) 和 \(\mathbf{c}_{f}\) 分别是text和ControlNet的condition,这意味着加上ControlNet的SD其实变成了双条件扩散模型。此外,在训练过程中,对text采用50%的drop(置为空文本),之所以采用比较大的drop是想让ControlNet的能力得到充分学习,模型只依赖ControlNet的condition就能生成符合结构的图像。 按论文里面所说,ControlNet总共训练了11个不同的conditions如Canny Edge和Hough Line,如下表所示:
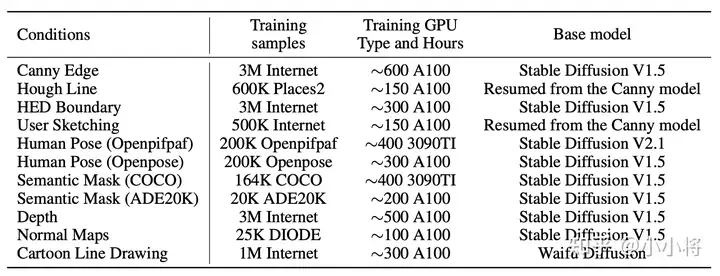
但是实际上放出来的ControlNet只有8个:
- control_sd15_canny.pth
- control_sd15_depth.pth
- control_sd15_hed.pth
- control_sd15_mlsd.pth
- control_sd15_normal.pth
- control_sd15_openpose.pth
- control_sd15_scribble.pth
- control_sd15_seg.pth

其中Human Pose (Openpifpaf),Semantic Mask (COCO)和Cartoon Line Drawing没有放出。但是论文里面也给出了效果图。我觉得Human Pose (Openpifpaf)和Semantic Mask (COCO)没有放出,应该是和Human Pose (Openpose)和Semantic Mask (ADE20K)有重合,而Cartoon Line Drawing没有放出按照作者github上的说法是担心风险(不过ControlNet V1.1放出了类似的模型)。


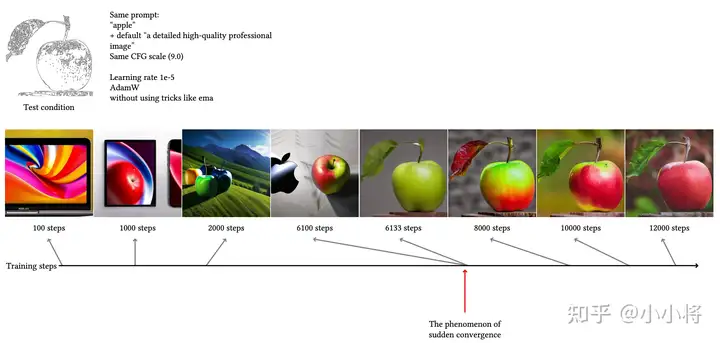
从上述表中,我们可以看到ControlNet的训练并不需要很大的数据量,从最少的20K到最多的3M,这相比SD的训练数据量(上B级别)要少很多。而且训练成本也不是太高,训练最长的模型Canny Edge模型也只需要600 A100卡时,如果用一台8卡A100也就训练3天左右。从训练数据量和训练时长看,ControlNet的训练是非常高效的。此外,论文里面发现ControlNet的训练并不是渐进的,而是存在突变点,如下图所示,在6133 step时模型突然学会到了ControlNet的condition。我个人觉得这还是和zero初始化有关,模型需要一定的时间让这些zero初始化的模块进行适配。
ControlNet的训练代码也比较容易实现,目前官方和diffusers库均有对应的训练脚本:
- https://github.com/lllyasviel/ControlNet/blob/main/tutorial_train.py
- https://github.com/huggingface/diffusers/tree/main/examples/controlnet
推理
对于SD这样的条件扩散模型,在推理阶段会采用classifier-free guidance(CFG):
其中 \(\mathbf{\epsilon}_{\text{uc}}\) 和 \(\mathbf{\epsilon}_{\text{c}}\) 分别为无条件扩散模型(文本为空)和有条件扩散模型预测的noise。上面说过,加上ControlNet之后,模型就变成了双条件的扩散模型。ControlNet在推理时采用的默认方式是condition都加在\(\mathbf{\epsilon}_{\text{uc}}\) 和 \(\mathbf{\epsilon}_{\text{c}}\) 上,即 \(\mathbf{\epsilon}_{\text{uc}}=\mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \varnothing, \mathbf{c}_{f}\big)\) 和 \(\mathbf{\epsilon}_{\text{c}}=\mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \mathbf{c}_{t}, \mathbf{c}_{f}\big)\)。 不过这种方式只对文本prompt存在时有效,如果文本prompt为空,那么CFG就失去了意义(无条件模型和有条件模型输出一样),相当于没有CFG(下图中b)。
一种解决办法是只将condition加在 \(\mathbf{\epsilon}_{\text{c}}\) 上,此时\(\mathbf{\epsilon}_{\text{uc}}=\mathbf{\epsilon}_\theta\big(\mathbf{z}_{t},t, \varnothing)\)(注意这里是直接不使用ControlNet,所以就没有额外的condition作为输入),但是实验发现这种实现方式会导致引导过强,出现图像的过饱和现象(下图中c)。
为了解决这个问题,论文提出了CFG Resolution Weighting方案,就是对ControlNet的13个输出特征根据特征大小设置不同的权重(下图d)。

CFG Resolution Weighting又称为Guess Mode,所谓的Guess Mode其实就是无文本prompt的情况下只依靠ControlNet来生成图像。下面是一个具体的例子,此时无prompt和negative prompt,只用深度图就能生成结构符合条件的图像。不过Guess Mode往往还需要采用比较长的去噪步数(50步)和采用较低的CFG guidance scale(3~5之间)。
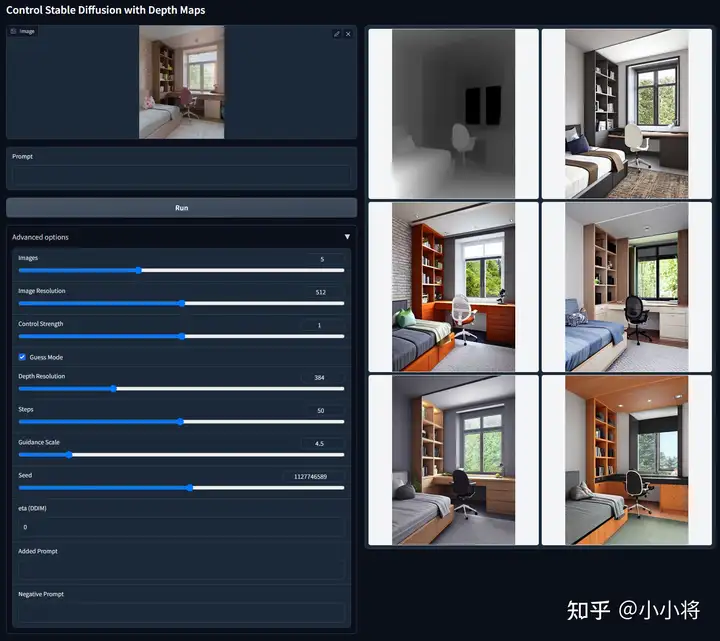
具体到代码实现,Guess Mode采用的特征权重系数如下:
model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13)
# Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01
可以看到从最浅的特征到最深的特征,权重系数从<0.01逐渐增加至1,按照作者的说法,这里的参数属于经验值。 在最新的ControlNet Webui Plugin中,ControlNet其实会有三种方式:Balanced,My prompt is more important和ControlNet is more important。
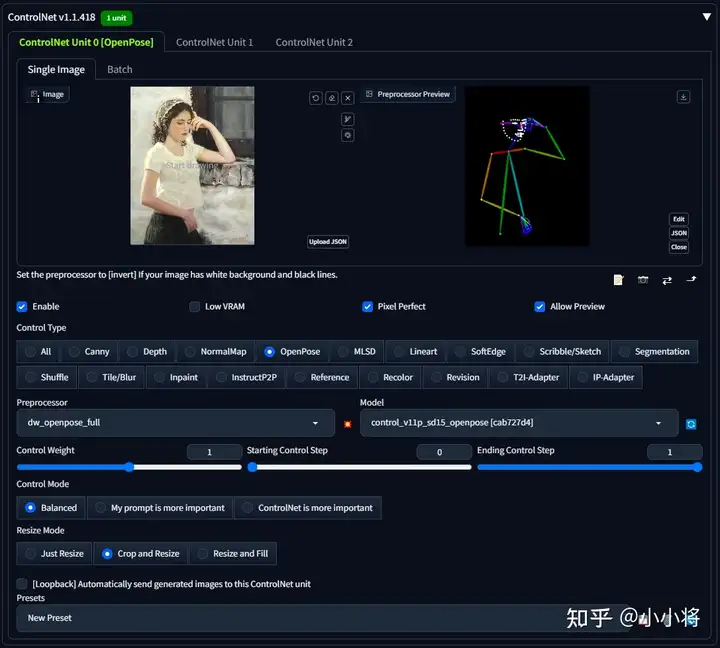
三者的主要区别就在于CFG的实现上有所不同。其中Balanced就是上面我们所说的默认方式,ControlNet均作用在CFG的两边。My prompt is more important模式是ControlNet虽然均作用在CFG的两边,但是采用上面所说的特征加权方式来降低ControlNet的引导强度,从而让生成的图像更符合prompt。而ControlNet is more important模式就是上面所说的Guess Mode,ControlNet只作用在CFG的有条件那一侧,并通过特征加权降低ControlNet的引导强度,这种模式你可以不用输入prompt就能得到满意的图像。下图是三种模式的一个具体对比:

我个人觉得ControlNet的CFG之所以变得有点复杂,一个可能的问题是ControlNet训练过程中没有对condition进行drop,即我们在训练过程中同时训练无条件的ControlNet(比如输入condition全zero),这样我们推理时令�uc=��(��,�,∅,∅)即可。不过实际的效果还需要实验来验证。
可迁移性
ControlNet是在SD 1.5上训练的,但是它的一个非常重要的特性是可迁移性,就是说在SD 1.5上训练的ControlNet可以直接应用在基于SD 1.5微调的模型,比如下面的两个微调的模型Comic Diffusion和Protogen 3.4。ControlNet的可迁移性大大增加了它的易用性,因为毕竟实际场景中往往使用的是C站上微调的模型。

此外,为了提升迁移效果,你还可以进行权重转换,比如你想将SD 1.5上训练好的ControlNet openpose模型迁移到动漫模型Anything V3上,你可以按如下方式进行转换:
AnythingV3_control_openpose = AnythingV3 + SD15_control_openpose – SD15
直观理解是先计算ControlNet模型相比SD 1.5的权重差值,然后再加上要迁移的模型Anything V3的权重。
关于ControlNet为什么具有这样的迁移性,并没有一个理论证明。但一个合理的解释是ControlNet本身只是一个Adapter,并没有改变原始SD模型的结构和权重,而微调的SD模型往往并没有偏离原始SD那么远。实际上,SD大部分的Adapter比如LoRA,IP-Adapter以及AnimateDiff均有这样的可迁移性。
多ControlNet
ControlNet的另外一个特性是你可以组合多个ControlNet一起使用,注意这里的每个ControlNet是单独训练的并不需要联合训练。在实现上,只需要将多个ControlNet的输出特征相加并送入SD的decoder。下图展示了将ControlNet openpose和ControlNet depth组合在一起用:

实际上ControlNet还可以和其它Adapter组合在一起使用,比如联合图像提示词插件IP-Adapter一起使用:
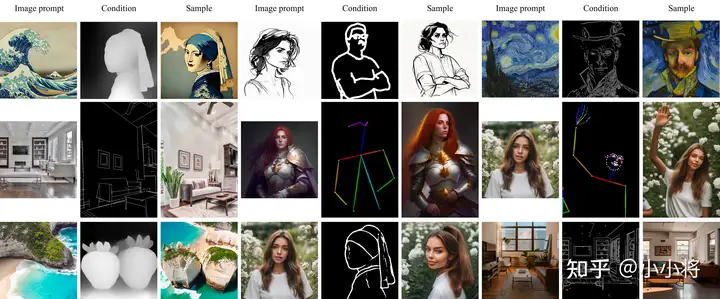
ControlNet设计合理性
ControlNet论文中还通过对比实验验证了ControlNet的设计合理性,这里要对比的设计如下所示:

其中(a)是现有ControlNet的实现,图(b)是去掉了zero初始化,图(c)采用一个从零训练的轻量级的网络并将输出连接在SD encoder上,图(d)和图(c)一样但是输出连接在SD decoder上,图(e)和图(d)一样但是加上了zero初始化,而最后的图(f)是加一个卷积将condition加在SD上并微调整个SD。下图给出了6个结构设计的一个实例对比,这里的文本提示词场景也设计成4种,第一个是no prompt(即上面所说的Guess Mode);第二是Insufficient prompt,就是说文本提示词描述的内容是有欠缺的;第三是Conflicting prompt,文本提示词和ControlNet的condition冲突;最后是Perfect prompt,文本提示词和condition一致。可以看到现有的ControlNet在4种场景下都是表现最好的。

这个对比实验无非是想说明ControlNet复制一份SD encoder以及采用zero初始化是非常重要的。不过这里的对比实验参数并没有给出,应该是同样的数据在相同的配置下训练同样的steps。但是我个人觉得zero初始化不一定会那么重要,比如(b)如果训练足够长是不是也可以达到类似的效果,甚至去掉额外加上的Conv是不是也可以,这些估计都需要更多的实验来分析了。 此外ControlNet同期的一个工作T2I-Adapter采用一个轻量级网络来提取condition的特征并加在SD的encoder上,应该和这里的方案(c)是类似的,而实际上T2I-Adapter的效果确实要比ControlNet要差一些,和这里的结论一致。
ControlNet 1.1
ControlNet 1.1是ControlNet的升级版,这个版本除了改进之前的ControlNet模型,还发布了新的模型,ControlNet 1.1模型包括:
- ControlNet 1.1 Depth
- ControlNet 1.1 Normal
- ControlNet 1.1 Canny
- ControlNet 1.1 MLSD
- ControlNet 1.1 Scribble
- ControlNet 1.1 Soft Edge
- ControlNet 1.1 Segmentation
- ControlNet 1.1 Openpose
- ControlNet 1.1 Lineart
- ControlNet 1.1 Anime Lineart
- ControlNet 1.1 Shuffle
- ControlNet 1.1 Instruct Pix2Pix
- ControlNet 1.1 Inpaint
- ControlNet 1.1 Tile
ControlNet1.1大部分的模型是进行了数据或者训练策略优化,或者是新的condition类型。这里重点介绍几个新增的ControlNet模型。 ControlNet 1.1 Shuffle:这个模型可以实现图像的风格迁移,它是采用random flow来打乱图像的内容,然后作为condition送入ControlNet中。所以这个ControlNet模型训练的目的其实根据打乱的图像来生成原来的图像。它的一个直接应用效果如下所示:
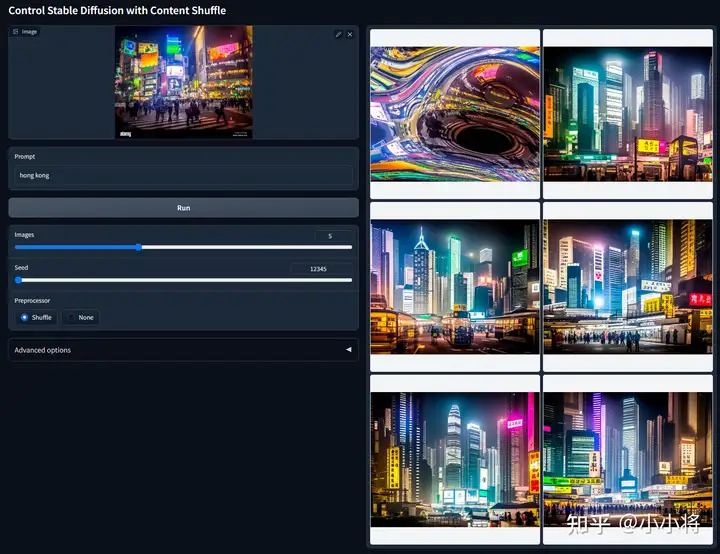
实际在推理时,你也可以不打乱图像直接用原图作为condition:
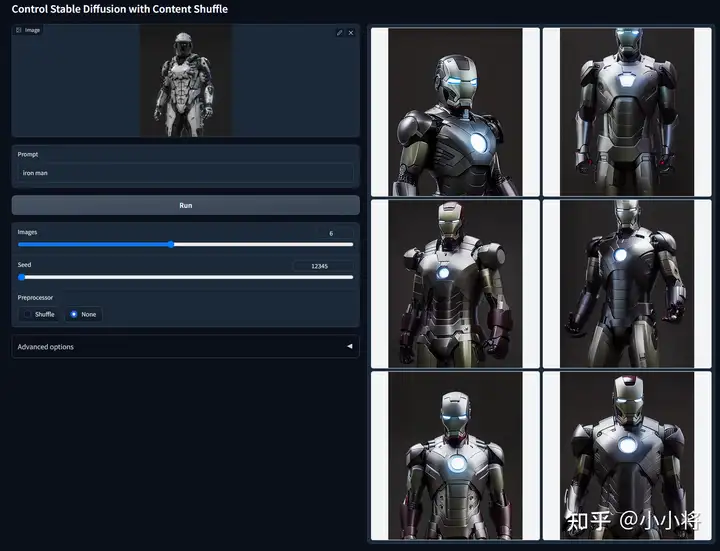
这个ControlNet模型在实现上会对ControlNet的特征输出做一个global average pooling,这个也合理因为condition图空间上已经和目标图不一致,而且这里只是想实现风格的迁移。此外,在做CFG时,ControlNet只加在有条件的那一边。
ControlNet 1.1 Instruct Pix2Pix:这个模型可以看成InstructPix2Pix的ControlNet版本,它可以实现图像的编辑,这里的condition是原图,然后用文本来编辑图像,这个ControlNet是使InstructPix2Pix的训练数据集进行训练。下面是一个具体的例子:
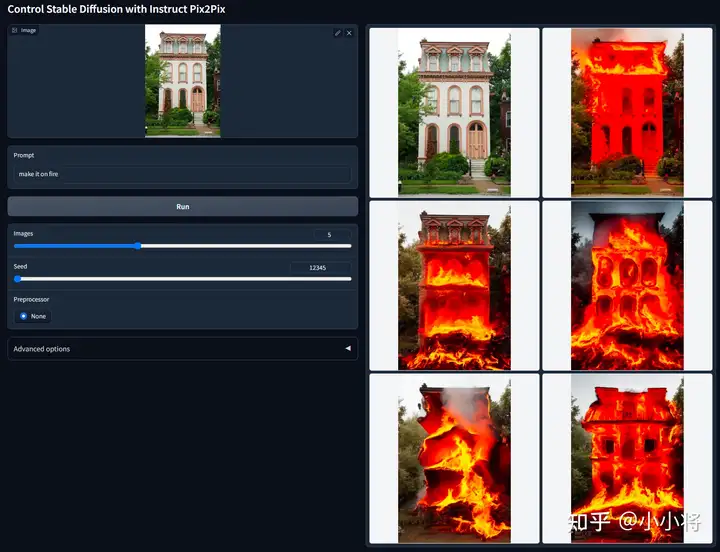
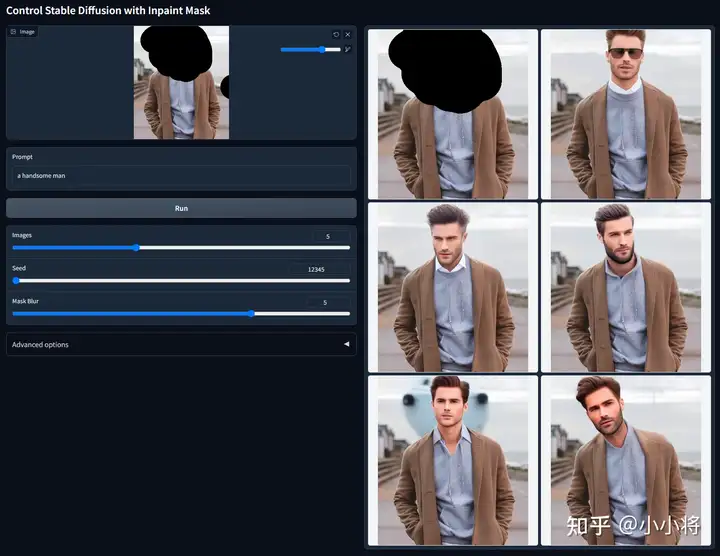
ControlNet 1.1 Inpaint:这个模型可以看成SD inpainting模型的ControlNet实现,此时condition是masked image(实际上Inpainting模型我们往往还输入mask图,但是这里ControlNet默认输入RGB图像,所以没有包含mask图)。它的一个效果如下所示:
ControlNet 1.1 Tile:这个ControlNet模型可以看成是一个细化模型,按照官方说法,Tile模型可以实现以下用处:
- it can do 2x, 4x, or 8x super resolution
这里边表述的核心点就是Tile模型可以忽略图像中原有的细节而生成新的细节,而且当文本prompt和图像中的语义不匹配时它会忽略prompt。这里举几个例子,第一个例子是对一张64x64的图像进行8倍放大,可以看到这不仅仅是超分,图像中的细节也发生了变化: