简介
对于标准的3D传感器来说,扫描透明物体一直是个难题,传统的双目,结构光或ToF RGB-D镜头都对透明物体束手无策,它们难以产生准确的深度估计,通常在许多情况下,透明物体会显示为一堆无效的噪点或失真的近似平面,如下图。谷歌+Synthesis AI+哥伦比亚大学的研究团队推出了ClearGrasp技术,通过深度学习的引入增强识别和估计透明物体。
为什么3D镜头无法对透明物体呈像,原因是传统3D传感器的算法会假定所以物体的表面都符合完全漫反射(Lambertian)。即所有方向上的反光都是均匀的,然而透明物体却不符合这个假设,不仅光存在反射,还存在折射。
三个关键点
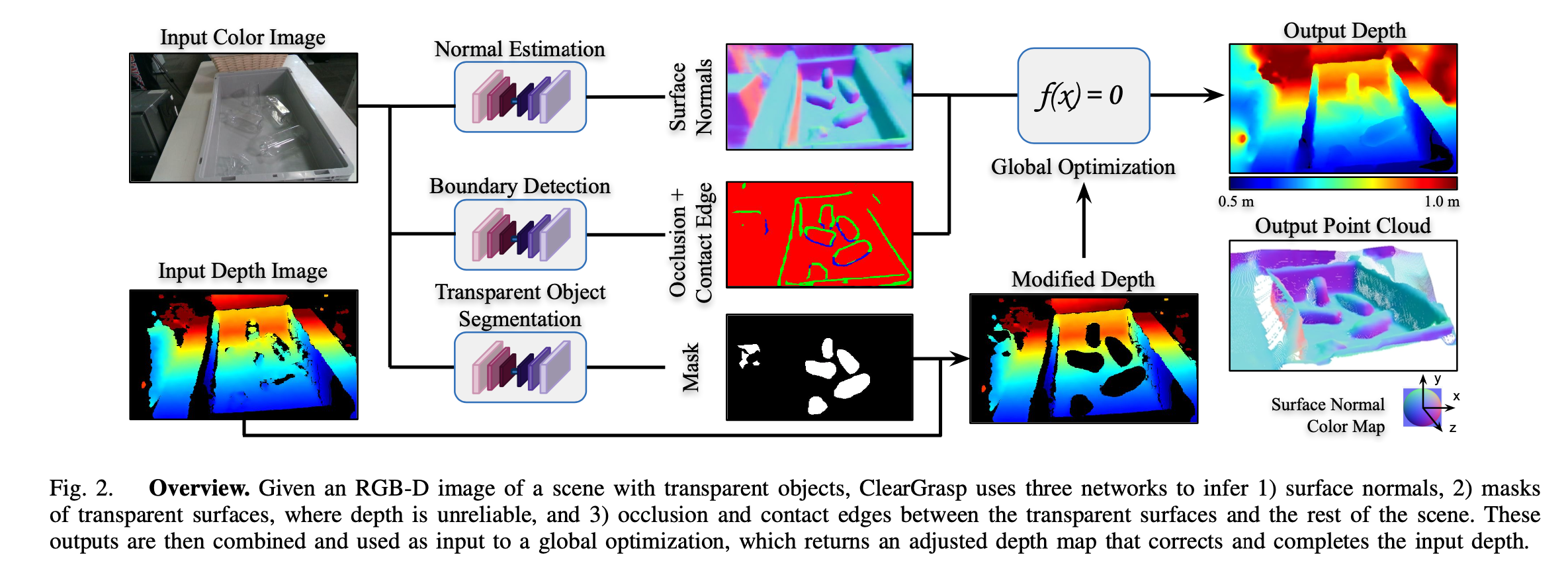
- RGB-D相机通常对于典型的非透明物体表面,可以提供良好的深度估计。 因此,我们推测不必要从头开始直接估算所有几何图形深度,而是从RGB-D相机校正初始深度估算值更为实际:使我们能够使用非透明表面的深度来推测透明表面的深度。 为了使此功能起作用,我们建议预测透明物体表面的像素mask(以检测并去除不可靠的深度),以及透明表面与背景之间的遮挡和接触边缘(以扩展可靠深度)。
- 出现在透明物体上的折射和镜面图案比其绝对深度为它们的曲率(例如表面法线)提供了更强的视觉提示。 这促使使用深度网络从RGB数据中推断出表面法线信息,与直接推断深度值相比,我们发现该信息要可靠得多。
- 用于透明物体的3D训练数据的ground-thuth很难获取,但我们可以将具有域随机化的高质量渲染合成图像用作训练数据,以在真实世界数据上获得合理的结果。
基本原理: 给定任意一个透明的RGB-D图像对象,ClearGrasp使用深度卷积网络来推断表面法线(Normal),透明物体的掩膜(Mask) ,遮挡边界(Occlusion Boundary, 深度上不连续)。然后使用这些输出来优化和完善初始深度估计场景中所有的透明表面。
网络框架
Estimating 3D Geometry of Transparent Object
- 为了移除原始深度图中的不可靠深度区域,即透明物体所占的像素区域,作者提出使用透明物体分割网络(Transparent Object Segmentation Network),输入单张RGB图片,输出场景中透明物体的像素Mask,即判断每个像素点是属于透明或者非透明物体,在后续优化中会去除被判定为透明物体的像素,得到修改后的深度图(Modified Depth)。
- 表面法向量估计(Surface Normal Estimation) 同样使用了RGB图片作为输入,输出做了L2正则化。
- 边缘识别网络(Boundary Detection Network) 对于单张RGB输出遮挡边缘(Occlusion Boundary)和相连边缘(Contact edge)信息,这帮助网络更好的分辨图片中不同的边缘,对深度不连续的边缘做出更准确的预测。
- 以上三个网络均采用了 Deeplabv3+ 和 DRN-D-54 作为骨干网络。
- 全局优化(Global Optimization): 全局优化集合了上述三个网络的输出,加上原始深度图(修改过的),输入能量方程: