状态价值(State values)
定义
状态价值是强化学习中的核心概念,用于衡量Agent从某个状态出发、遵循特定策略后所能获得的期望回报。
数学表达为:
\[
v_\pi(s) = \mathbb{E}[G_t | S_t = s]
\tag{1}\]
其中:
- \(v_\pi(s)\):状态 \(s\) 的状态价值函数(state-value function) 或者简称为 状态价值(state value);
- \(\pi\):智能体遵循的策略;
- \(G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots\):从当前时间步 \(t\) 开始的折扣回报;
- \(\gamma \in (0, 1)\):折扣因子,用于平衡即时奖励和未来奖励。
状态价值的特点
- 依赖于状态\(s\):状态价值是条件期望,条件是智能体从状态 \(s\) 开始。
- 依赖于策略 \(\pi\):不同策略会生成不同的轨迹,从而影响状态价值。
- 与时间步无关:状态价值是一个固定值,与当前时间步 \(t\) 无关。
- 代表一个状态的价值。如果一个状态的价值更高,那么策略就更好,因为可以获得更大的累积奖励。
💡 Return和State value的区别:return是一个轨迹带来的折扣奖励和,而state value 是在一个policy下所有的轨迹奖励和的期望也就是所有轨迹对应的return的期望
贝尔曼方程(Bellman Equation)
定义与核心思想
贝尔曼方程是一组线性方程,描述了所有状态价值之间的相互关系。通过求解贝尔曼方程,可以计算出所有状态的价值,从而实现策略评估(Policy Evaluation)
贝尔曼方程的基础形式为:
\[v_\pi(s) = \mathbb{E}[R_{t+1} + \gamma v_\pi(S_{t+1}) | S_t = s]\]
其中:
- \(R_{t+1}\):从状态 \(s\) 出发时获得的即时奖励;
- \(S_{t+1}\):下一时间步的状态;
- \(\gamma v_\pi(S_{t+1})\):对未来回报的折扣期望。
推导过程
通过分解回报 \(G_t\) 的形式:
\[G_t = R_{t+1} + \gamma G_{t+1}\]
带入 (1) 可以得到:
\[v_\pi(s) = \mathbb{E}[G_t | S_t = s] = \mathbb{E}[R_{t+1} + \gamma G_{t+1} | S_t = s]\]
进一步分解为:
\[v_\pi(s)=\color{teal}{\mathbb{E} [R_{t+1} \mid S_t=s]} \color{salmon}+\gamma{\mathbb{E}[G_{t+1} \mid S_t=s]}\]
可以看出上式存在两个部分,将在下面具体展开:
First term: 即时奖励期望
首先, 计算第一项 \(\mathbb{E}\left[R_{t+1} \mid S_t=s\right]\):
\[\begin{aligned}\color{teal}{\mathbb{E}\left[R_{t+1} \mid S_t=s\right]} & =\sum_{a \in \mathcal A(s)} \pi(a \mid s) \mathbb{E}\left[R_{t+1} \mid S_t=s, A_t=a\right] \\& = \color{teal}{\sum_{a \in \mathcal A(s)} \pi(a \mid s) \sum_{r\in\mathcal{R}} p(r \mid s, a) r} .\end{aligned}\]
其中,\(\mathcal{R}\) 依赖于 \((s,a)\)。
证明:
给定事件 \(R_{t+1} = r, S_t = s, A_t = a\),证明相当简单。
从全期望值定理(the law of total expectation):给定离散随机变量 \(X\) 和 \(Y\),则
\[\mathbb{E}(X)=\mathbb{E}(\mathbb{E}(X \mid Y))\]
如果 \(Y\) 是有限的,我们有
\[\mathbb{E}(X)=\sum_{y_i \in \mathcal{Y}} \mathbb{E}\left(X \mid Y=y_i\right) p\left(Y=y_i\right)\]
因此我们可以得到:
\[\mathbb{E}\left[R_{t+1} \mid S_t=s\right] =\sum_{a \in \mathcal A(s)} \pi(a \mid s) \mathbb{E}\left[R_{t+1} \mid S_t=s, A_t=a\right]\]
其中 \(A_t\) 是有限的。
从期望的定义 \(\mathbb{E}\left[R_{t+1} \mid S_t=s, A_t=a\right] = \sum_{r}p(r \mid s, a) r\), 可以推出:
\[\sum_{a \in \mathcal A(s)} \pi(a \mid s) \mathbb{E}\left[R_{t+1} \mid S_t=s, A_t=a\right] = \sum_{a \in \mathcal A(s)} \pi(a \mid s) \sum_r p(r \mid s, a) r\]
得证。具体证明可以参考《Mathematical Foundations of Reinforcement Learning》附录A
Second term:未来(折扣)回报期望
首先,我们计算未来奖励的均值,
\[\begin{aligned}\color{salmon}\mathbb{{E}\left[G_{t+1} \mid S_t=s\right] }& =\sum_{s^{\prime}} \mathbb{E}\left[G_{t+1} \mid S_t=s, S_{t+1}=s^{\prime}\right] p\left(s^{\prime} \mid s\right) \\& =\sum_{s^{\prime}} \mathbb{E}\left[G_{t+1} \mid S_{t+1}=s^{\prime}\right] p\left(s^{\prime} \mid s\right) \\& =\sum_{s^{\prime}} v_\pi\left(s^{\prime}\right) p\left(s^{\prime} \mid s\right) \\& =\color{salmon}\sum_{s^{\prime}} v_\pi\left(s^{\prime}\right) \sum_a p\left(s^{\prime} \mid s, a\right) \pi(a \mid s)\end{aligned}\]
然后我们将其与折扣因子 \(γ\) 相乘。为了简单起见,我们说第二个项 \(\gamma \mathbb{E}[G_{t+1} \mid S_t]\) 是“未来奖励的平均值”,它是折扣的。
上面推导过程中,第一行也来自 全期望值定理;
第二行的转换来源于马尔可夫性质。奖励 \(r_t \)被定义为仅依赖于 \(s_t\) 和 \(a_t\) :
\[p\left(r_{t+1} \mid s_t, a_t, s_{t-1}, a_{t-1}, \ldots, s_0, a_0\right)=p\left(r_{t+1} \mid s_t, a_t\right) .\]
合并到一起
将上面两个项合在一起就得到了贝尔曼方程的完整形式:
\[\begin{aligned}
v_\pi(s)
& =\mathbb{E}\left[R_{t+1} \mid S_t=s\right]+\gamma \mathbb{E}\left[G_{t+1} \mid S_t=s\right], \\
& = \underbrace{\color{teal}\sum_a \pi(a \mid s) \sum_r p(r \mid s, a) r}_{\text {mean of immediate rewards }}
+
\underbrace{\gamma \color{salmon} {\sum_{s^{\prime}} \pi(a \mid s) \sum_a p\left(s^{\prime} \mid s, a\right) v_\pi\left(s^{\prime}\right)},}_{\text {(discounted) mean of future rewards }} \\
& =\sum_a \pi(a \mid s)\left[\sum_r p(r \mid s, a) r+\gamma \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) v_\pi\left(s^{\prime}\right)\right], \quad \forall s \in \mathcal{S} .
\end{aligned}\tag{2}\]
- 贝尔曼方程是一组线性方程,描述了所有状态值之间的关系。
- 上述逐元素形式对每个状态 \(s \in \mathcal{S}\) 都有效。这意味着有 \(| \mathcal{S}|\) 个这样的方程!
- \(p(r \mid s, a)\) 和 \(p(s^{\prime} \mid s, a)\) 代表系统模型
Examples
还是以Grid-World为例。
确定性策略
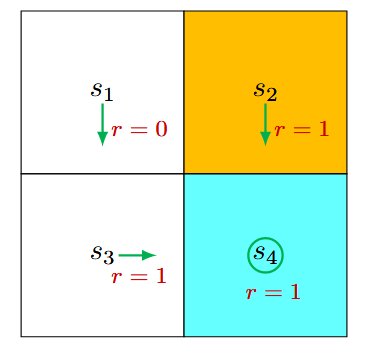
首先,考虑状态 \(s_1\)。在该策略下,采取行动的概率为
\[\pi\left(a=a_3 \mid s_1\right)=1 \quad \text{and} \quad \pi\left(a \neq a_3 \mid s_1\right)=0.\]
状态转移概率为
\[p\left(s^{\prime}=s_3 \mid s_1, a_3\right)=1 \quad \text{and} \quad p\left(s^{\prime} \neq s_3 \mid s_1, a_3\right)=0 .\]
奖励概率是:
\[p\left(r=0 \mid s_1, a_3\right)=1 \quad \text{and} \quad p\left(r \neq 0 \mid s_1, a_3\right)=0 .\]
将这些值代入之前提到的贝尔曼方程 式2 中,得到:
\[v_\pi\left(s_1\right)=0+\gamma v_\pi\left(s_3\right)\]
同理, 可以得到
\[\begin{aligned}& v_\pi\left(s_2\right)=1+\gamma v_\pi\left(s_4\right), \\& v_\pi\left(s_3\right)=1+\gamma v_\pi\left(s_4\right), \\& v_\pi\left(s_4\right)=1+\gamma v_\pi\left(s_4\right) .\end{aligned}\]
我们可以从这些方程中求解状态值。由于方程简单,我们可以手动求解。更复杂的方程可以通过后面提出的算法求解。在这里,状态值可以求解为
\[\begin{aligned}& v_\pi\left(s_4\right)=\frac{1}{1-\gamma}, \\& v_\pi\left(s_3\right)=\frac{1}{1-\gamma}, \\& v_\pi\left(s_2\right)=\frac{1}{1-\gamma}, \\& v_\pi\left(s_1\right)=\frac{\gamma}{1-\gamma} .\end{aligned}\]
如果设置 \(\gamma=0.9\), 则
\[\begin{aligned}& v_\pi\left(s_4\right)=\frac{1}{1-0.9}=10, \\& v_\pi\left(s_3\right)=\frac{1}{1-0.9}=10, \\& v_\pi\left(s_2\right)=\frac{1}{1-0.9}=10, \\& v_\pi\left(s_1\right)=\frac{0.9}{1-0.9}=9 .\end{aligned}\]
随机策略
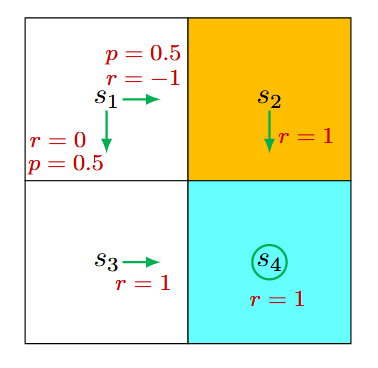
在状态 \(s_1\),向右和向下的概率均为 0.5。从数学上讲,我们有 \(\pi\left(a=a_2 \mid s_1\right)=0.5\) 和 \(\pi\left(a=a_3 \mid s_1\right)=0.5\)。状态转移概率是确定的,因为 \(p\left(s^{\prime}=s_3 \mid s_1, a_3\right)=1\) 和 \(p\left(s^{\prime}=s_2 \mid s_1, a_2\right)=1\)。奖励概率也是确定的,因为 \(p\left(r=0 \mid s_1, a_3\right)=1\) 和 \(p\left(r=-1 \mid s_1, a_2\right)=1\)。将这些值代入 式2 得到
\[v_\pi\left(s_1\right)=0.5\left[0+\gamma v_\pi\left(s_3\right)\right]+0.5\left[-1+\gamma v_\pi\left(s_2\right)\right]\]
同样,可以得到
\[\begin{aligned}& v_\pi\left(s_2\right)=1+\gamma v_\pi\left(s_4\right), \\& v_\pi\left(s_3\right)=1+\gamma v_\pi\left(s_4\right), \\& v_\pi\left(s_4\right)=1+\gamma v_\pi\left(s_4\right) .\end{aligned}\]
同样可以手动求解出上面方程组,得到
\[\begin{aligned}v_\pi\left(s_4\right) & =\frac{1}{1-\gamma}, \\v_\pi\left(s_3\right) & =\frac{1}{1-\gamma}, \\v_\pi\left(s_2\right) & =\frac{1}{1-\gamma}, \\v_\pi\left(s_1\right) & =0.5\left[0+\gamma v_\pi\left(s_3\right)\right]+0.5\left[-1+\gamma v_\pi\left(s_2\right)\right], \\& =-0.5+\frac{\gamma}{1-\gamma} .\end{aligned}\]
设置 \(\gamma=0.9\), 则
\[\begin{aligned}& v_\pi\left(s_4\right)=10, \\& v_\pi\left(s_3\right)=10, \\& v_\pi\left(s_2\right)=10, \\& v_\pi\left(s_1\right)=-0.5+9=8.5 .\end{aligned}\]
这表明第一个例子的策略更好,因为它具有更大的状态值。 这个数学结论与直觉是一致的,即第一个策略更好,因为当Agent从 \(s_1\) 移动时,它可以避免进入禁区。结论是,以上两个示例表明状态值可用于评估策略。
贝尔曼方程的计算方法
(2)中的贝尔曼方程是一种 element-wise的形式, 这意味着有像这样的 \(|\mathcal{S}|\) 个方程!如果我们把所有方程放在一起,我们得到一组线性方程,可以简洁地写成矩阵-向量 的形式。
矩阵-向量形式
首先, 我们对(2)进行重写,
\[v_\pi(s)=\color{teal}{r_\pi(s)} + \gamma \color{salmon}{\sum_{s^{\prime}} p_\pi\left(s^{\prime} \mid s\right) v_\pi\left(s^{\prime}\right)}\]
其中,
\[r_\pi(s) \triangleq \sum_a \pi(a \mid s) \sum_r p(r \mid s, a) r, \quad p_\pi\left(s^{\prime} \mid s\right) \triangleq \sum_a \pi(a \mid s) p\left(s^{\prime} \mid s, a\right)\]
假设状态可以按 \(s_i(i=1, \ldots, n)\) 索引。对于状态 \(s_i\),对应的贝尔曼方程是
\[v_\pi\left(s_i\right)=\color{teal}{r_\pi\left(s_i\right)}+\gamma \color{salmon} {\sum_{s_j} p_\pi\left(s_j \mid s_i\right) v_\pi\left(s_j\right)}\]
将所有这些状态方程合并并重写为矩阵-向量形式
\[
v_\pi=
\color{teal}{r_\pi}
+
\gamma \color{salmon}{P_\pi v_\pi}
\tag{3}\]
其中:
- \(v_\pi \in \mathbb{R}^n\):状态价值向量;
- \(r_\pi \in \mathbb{R}^n\):即时奖励向量;
- \(P_\pi \in \mathbb{R}^{n \times n}\):状态转移概率矩阵。
通过矩阵形式,可以更直观地理解状态间的依赖关系,并为求解提供便利。
矩阵-向量形式的解
闭式解法
利用矩阵求逆,直接求解:
\[v_\pi = (I - \gamma P_\pi)^{-1}r_\pi\]
特点:
迭代解法
通过迭代计算逐步逼近精确解:
\[v_{k+1} = r_\pi + \gamma P_\pi v_k\]
- \(v_0\) 是初始猜测值;
- 随着迭代次数 \(k \to \infty\),\(v_k \to v_\pi\)。
证明:
将误差定义为 \(\delta_{k}=v_{k}-v_{\pi}\)。我们只需要证明 \(\delta_{k} \rightarrow 0\)。将 \(v_{k+1}=\delta_{k+1}+v_{\pi}\) 和 \(v_{k}=\delta_{k}+v_{\pi}\) 代入 \(v_{k+1}=r_{\pi}+\gamma P_{\pi} v_{k}\) 得到
\[ \delta_{k+1}+v_{\pi}=r_{\pi}+\gamma P_{\pi}\left(\delta_{k}+v_{\pi}\right)\]
可以重写为
\[\begin{aligned} \delta_{k+1} & =-v_{\pi}+r_{\pi}+\gamma P_{\pi} \delta_{k}+\gamma P_{\pi} v_{\pi}, \\ & =\gamma P_{\pi} \delta_{k}-v_{\pi}+\left(r_{\pi}+\gamma P_{\pi} v_{\pi}\right), \\ & =\gamma P_{\pi} \delta_{k} . \end{aligned}\]
因此,
\[\delta_{k+1}=\gamma P_{\pi} \delta_{k}=\gamma^{2} P_{\pi}^{2} \delta_{k-1}=\cdots=\gamma^{k+1} P_{\pi}^{k+1} \delta_{0}\]
由于 \(P_{\pi}\) 的每个元素都是非负且不大于1的,对任意 \(k\) 我们有 \(0 \leq P_{\pi}^{k} \leq 1\)。也就是说,\(P_{\pi}^{k}\) 的每个元素都不大于 \(1\)。另一方面,由于 \(\gamma < 1\),我们知道 \(\gamma^{k} \rightarrow 0\),因此当 \(k \rightarrow \infty\) 时,\(\delta_{k+1}=\gamma^{k+1} P_{\pi}^{k+1} \delta_{0} \rightarrow 0\)。
动作价值(Action values)
定义
动作价值衡量在某状态采取某动作的价值,定义为从状态-动作对 \((s, a)\) 出发的期望回报:
\[q_\pi(s, a) = \mathbb{E}[G_t | S_t = s, A_t = a]\tag{4}\]
动作价值与状态价值的关系
根据全期望值定理(law of total expectation),
\[\begin{aligned}\underbrace{\mathbb{E}\left[G_t \mid S_t=s\right]}_{v_\pi(s)} = \sum_{a \in \mathcal{A}_t} \underbrace{\mathbb{E}\left[G_t \mid S_t=s, A_t=a\right]}_{q_\pi(s, a)} \pi(a \mid s)\end{aligned}\]
因此,
\[ \color{orange} {v_\pi(s)=\sum_{a\in\mathcal{A}} \pi(a \mid s) q_\pi(s, a)} .\tag{5}\]
回忆贝尔曼方程(2),状态值可以写成
\[v_\pi(s)=\sum_{a \in \mathcal{A}} \pi(a \mid s)[\underbrace{\sum_r p(r \mid s, a) r+\gamma \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) v_\pi\left(s^{\prime}\right)}{q\pi(s, a)}]\]
通过比较 (5)和此方程,我们得到动作值函数为
\[\color {brown}{q_\pi(s, a)=\sum_{r\in\mathcal{R}} p(r \mid s, a) r+\gamma \sum_{s^{\prime}\in\mathcal{S}} p\left(s^{\prime} \mid s, a\right) v_\pi\left(s^{\prime}\right)}\tag{6}\]
可以看出动作价值由两部分组成:
- 即时奖励:\(\sum_{r \in R} p(r|s, a)r\);
- 未来奖励:\(\gamma \sum_{s' \in S} p(s'|s, a)v_\pi(s')\)。
并且(6)可以看出是从状态价值计算动作价值, 两者相辅相成,是强化学习中策略评估和优化的基础。
示例
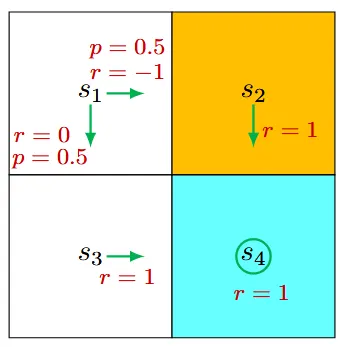
考虑上图所示的随机策略。
\[q_\pi\left(s_1, a_2\right)=-1+\gamma v_\pi\left(s_2\right)\]
请注意,即使一个动作不会被策略选中,它仍然具有动作值。因此,对于其他动作:
\[\begin{aligned}& q_\pi\left(s_1, a_1\right)=-1+\gamma v_\pi\left(s_1\right), \\& q_\pi\left(s_1, a_3\right)=0+\gamma v_\pi\left(s_3\right), \\& q_\pi\left(s_1, a_4\right)=-1+\gamma v_\pi\left(s_1\right), \\& q_\pi\left(s_1, a_5\right)=0+\gamma v_\pi\left(s_1\right) .\end{aligned}\]
💡为什么我们关心给定策略不会选择的动作? 尽管某些动作不能由给定的策略选择,但这并不意味着这些动作不好。给定的策略可能不好,因此无法选择最佳动作。强化学习的目的是找到最佳策略。为此,我们必须继续探索所有行动,以确定每个状态的更好动作。
动作价值形式的贝尔曼方程
贝尔曼方程不仅可以用状态价值(State Value)来描述,还可以用动作价值(Action Value)来表达。动作价值形式的贝尔曼方程进一步揭示了动作与状态之间的关系,是强化学习中不可或缺的工具。
将(5) 和 (6) 结合,可以得到动作价值形式的贝尔曼方程:
\[q_\pi(s, a) = \sum_{r \in R} p(r|s, a)r + \gamma \sum_{s' \in S} p(s'|s, a) \sum_{a' \in A} \pi(a'|s') q_\pi(s', a')\tag{7}\]
这一公式的含义是:
- 动作价值由即时奖励(第一项)和未来奖励(第二项)组成;
- 未来奖励部分依赖于下一状态 \(s'\) 的动作价值,以及策略 \(\pi\) 在 \(s'\) 选择动作的概率。
矩阵-向量形式
将上述方程转化为矩阵-向量形式:
\[q_\pi = \tilde{r} + \gamma P \Pi q_\pi\]
其中:
- \(q_\pi\):动作价值向量,按状态-动作对索引;
- \(\tilde{r}\):即时奖励向量,按状态-动作对索引;
- \(P\):状态转移概率矩阵,按状态-动作对到状态的转移概率;
- \(\Pi\):策略矩阵,表示每个状态选择动作的概率。
矩阵形式的特点:
- 即时奖励 \(\tilde{r}\) 和转移概率矩阵 \(P\) 仅由环境模型决定,与策略无关;
- 策略信息嵌入在矩阵 \(\Pi\) 中。
意义
动作价值形式的贝尔曼方程有以下重要意义:
- 策略评估
给定策略 \(\pi\),可以通过求解动作价值形式的贝尔曼方程,计算所有状态-动作对的动作价值,从而评估策略的优劣。 - 策略改进
动作价值直接反映了每个动作的价值,为策略改进提供了依据。例如,在策略优化中,智能体可以选择使动作价值最大的动作,从而逐步逼近最优策略。 - 模型依赖性
动作价值形式的贝尔曼方程中,\(\tilde{r}\) 和 \(P\) 是由环境模型决定的,适用于基于模型(Model-Based)的强化学习方法。在无模型(Model-Free)方法中,动作价值可以通过采样估计。
总结
- 状态价值与贝尔曼方程
- 状态价值用于评估策略优劣,是强化学习的核心概念。
- 贝尔曼方程通过描述状态间的关系,为求解状态价值提供了理论工具。
- 策略评估与优化
- 策略评估通过求解贝尔曼方程实现。
- 动作价值为策略优化提供了更直接的依据。
- 通用性
贝尔曼方程不仅在强化学习中广泛应用,还出现在控制理论、运筹学等领域.
Reference
3 - Chapter 2 State Values and Bellman Equation.pdf
Lu, Yukuan-Action Value
Lu, Yukuan-Bellman Equation: The Matrix-Vector Form
Lu, Yukuan-Bellman Equation