取代RNN——Transformer
在介绍Transformer前我们来回顾一下RNN的结构

对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题
- 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理
- 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题
为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了
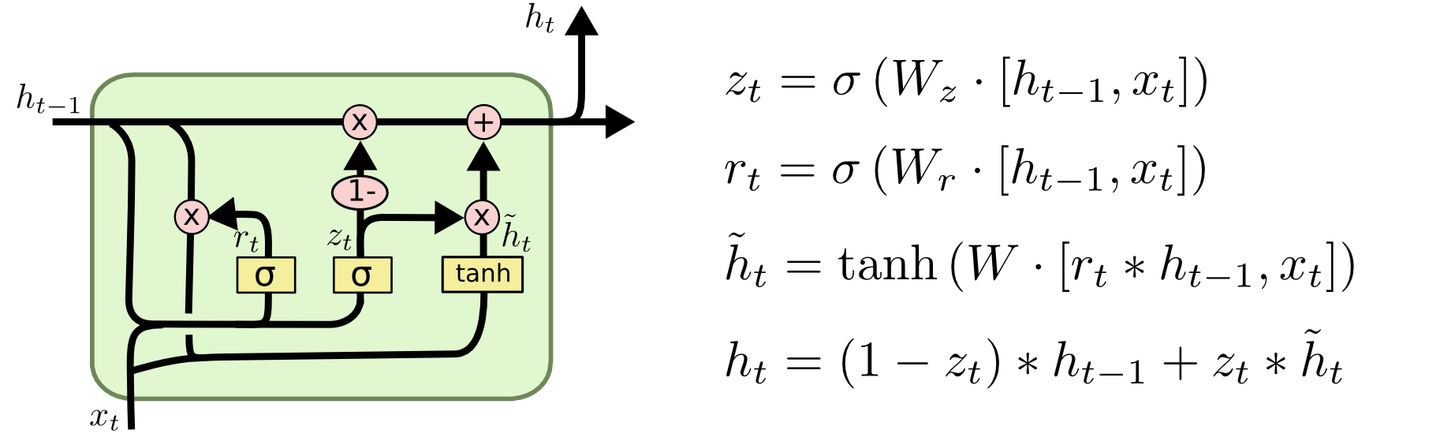
LSTM (Long Short Term Memory)

GRU (Gated Recurrent Unit)
但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢?
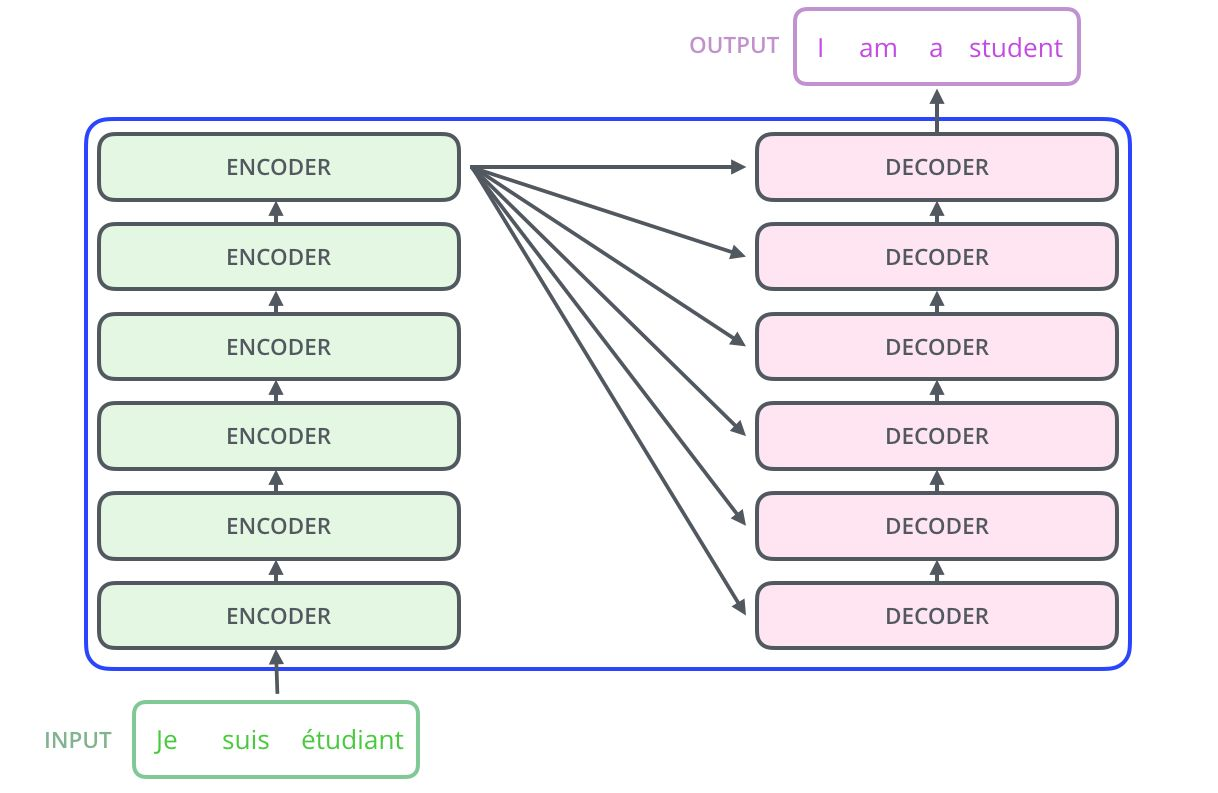
于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工作,它针对RNN的弱点进行重新设计,解决了RNN效率问题和传递中的缺陷等,在很多问题上都超过了RNN的表现。Transfromer的基本结构如下图所示,它是一个N进N出的结构,也就是说每个Transformer单元相当于一层的RNN层,接收一整个句子所有词作为输入,然后为句子中的每个词都做出一个输出。但是与RNN不同的是,Transformer能够同时处理句子中的所有词,并且任意两个词之间的操作距离都是1,这么一来就很好地解决了上面提到的RNN的效率问题和距离问题。

每个Transformer单元都有两个最重要的子层,分别是Self-Attention层与Feed Forward层,后面会对这两个层的详细结构做介绍。文章使用Transformer搭建了一个类似Seq2Seq的语言翻译模型,并为Encoder与Decoder设计了两种不同的Transformer结构。
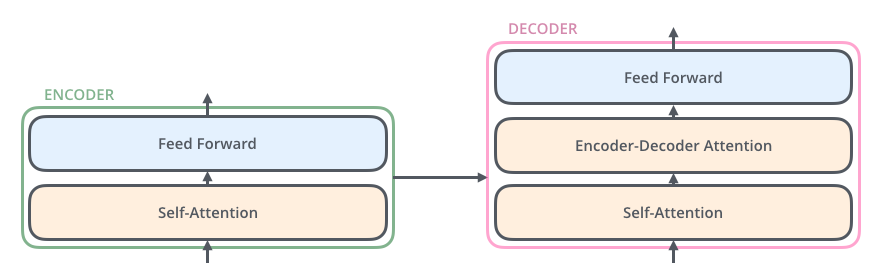
Decoder Transformer相对于Encoder Transformer多了一个Encoder-Decoder Attention层,用来接收来自于Encoder的输出作为参数。最终只要按照下图的方式堆叠,就可以完成Transformer Seq2Seq的结构搭建。
举个例子介绍下如何使用这个Transformer Seq2Seq做翻译
- 首先,Transformer对原语言的句子进行编码,得到memory。
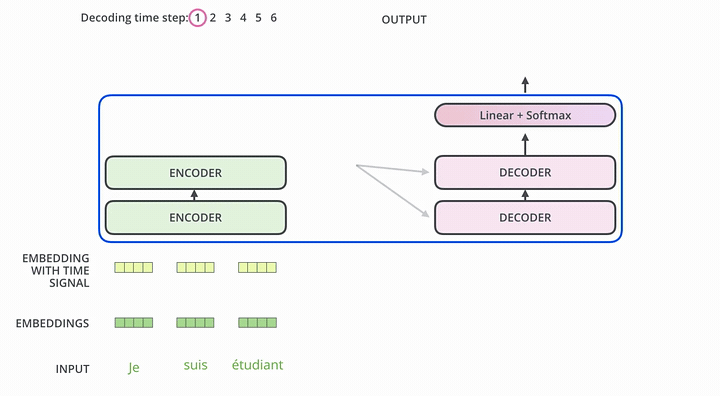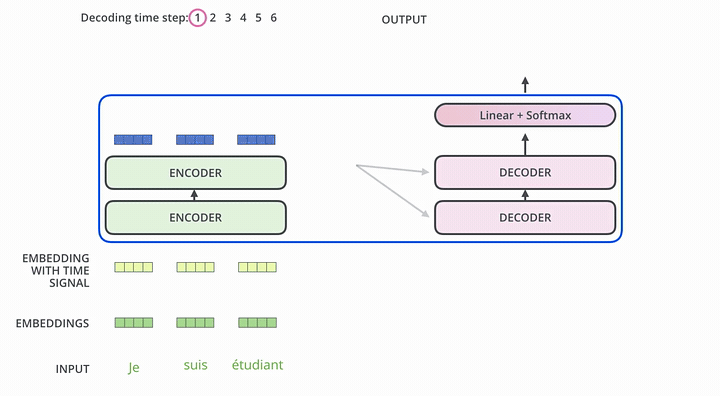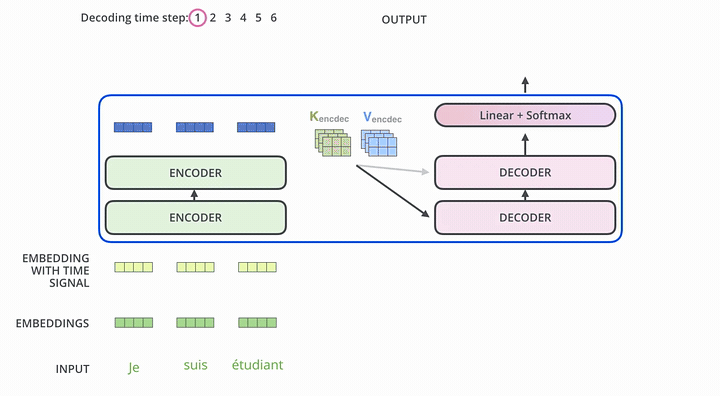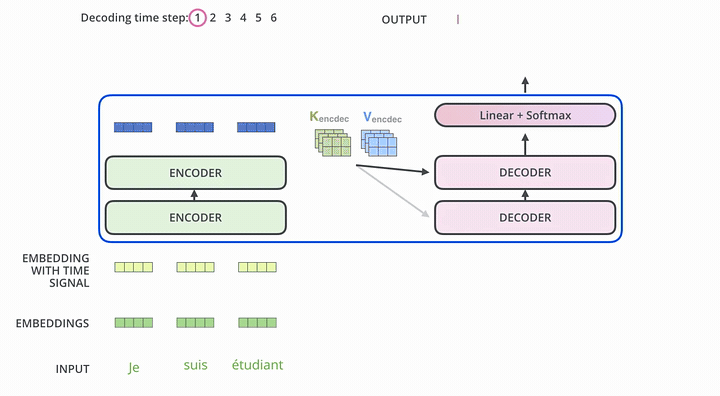
- 第一次解码时输入只有一个
<SOS>标志,表示句子的开始。 - 解码器通过这个唯一的输入得到的唯一的输出,用于预测句子的第一个词。
- 第二次解码,将第一次的输出Append到输入中,输入就变成了
<SOS>和句子的第一个词(ground truth或上一步的预测),解码生成的第二个输出用于预测句子的第二个词。以此类推(过程与Seq2Seq非常类似)
了解了Transformer的大致结构以及如何用它来完成翻译任务后,接下来就看看Transformer的详细结构:
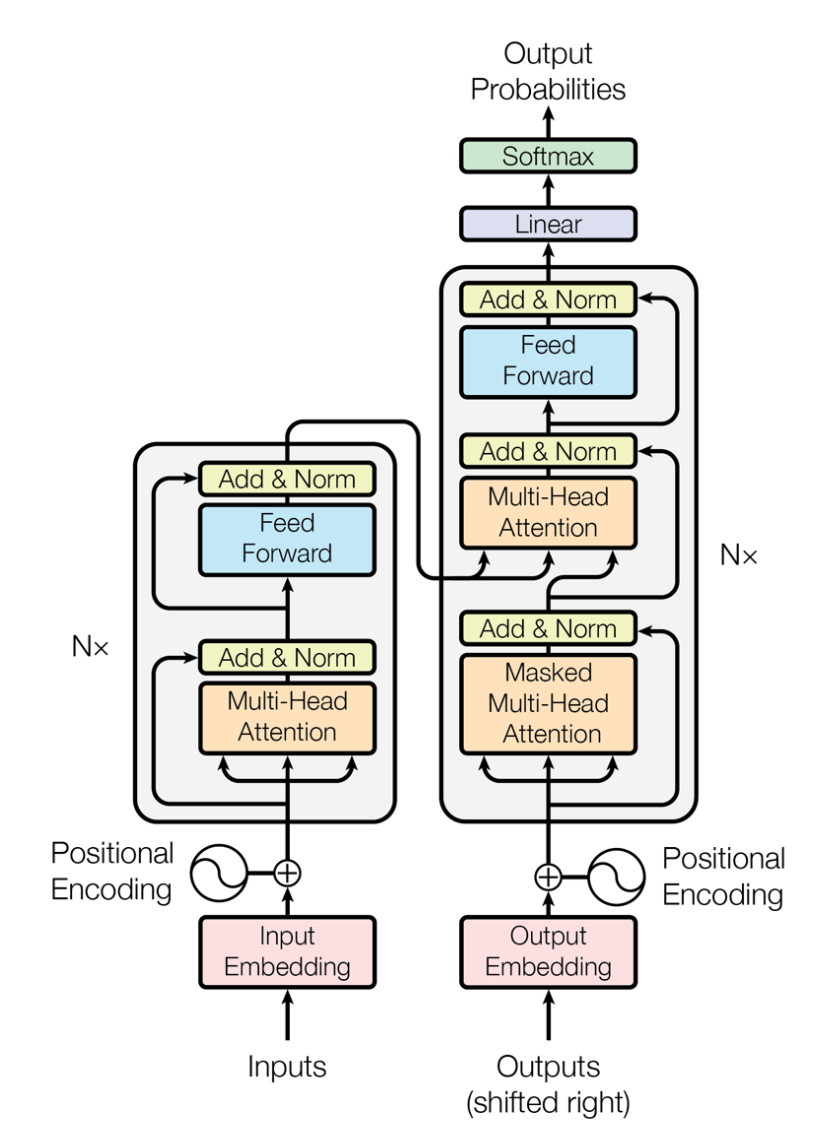
核心组件就是上面所提到的Self-Attention和Feed Forward Networks,但还有很多其他细节,接下来我们就开始逐个结构的来解读Transformer。
Self Attention
Self Attention就是句子中的某个词对于本身的所有词做一次Attention。算出每个词对于这个词的权重,然后将这个词表示为所有词的加权和。每一次的Self Attention操作,就像是为每个词做了一次Convolution操作或Aggregation操作。具体操作如下:
首先,每个词都要通过三个矩阵\(W_q, W_k, W_v\) 进行一次线性变化,一分为三,生成每个词自己的query, key, vector三个向量。以一个词为中心进行Self Attention时,都是用这个词的key向量与每个词的query向量做点积,再通过Softmax归一化出权重。然后通过这些权重算出所有词的vector的加权和,作为这个词的输出。具体过程如下图所示
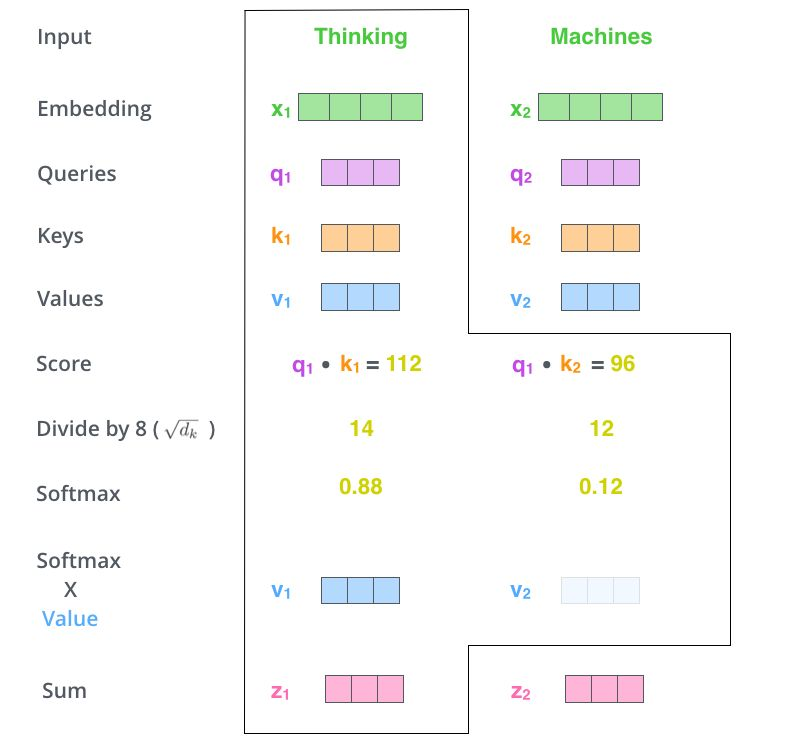
归一化之前需要通过除以向量的维度\(d_k\)来进行标准化,所以最终Self Attention用矩阵变换的方式可以表示为
最终每个Self Attention接受n个词向量的输入,输出n个Aggregated的向量。
上文提到Encoder中的Self Attention与Decoder中的有所不同,Encoder中的\(Q\)、\(K\)、\(V\)全部来自于上一层单元的输出,而Decoder只有Q来自于上一个Decoder单元的输出,K与V都来自于Encoder最后一层的输出。也就是说,Decoder是要通过当前状态与Encoder的输出算出权重后,将Encoder的编码加权得到下一层的状态。
Masked Attention
通过观察上面的结构图我们还可以发现Decoder与Encoder的另外一个不同,就是每个Decoder单元的输入层,要先经过一个Masked Attention层。那么Masked的与普通版本的Attention有什么区别呢?
Encoder因为要编码整个句子,所以每个词都需要考虑上下文的关系。所以每个词在计算的过程中都是可以看到句子中所有的词的。但是Decoder与Seq2Seq中的解码器类似,每个词都只能看到前面词的状态,所以是一个单向的Self-Attention结构。
Masked Attention的实现也非常简单,只要在普通的Self Attention的Softmax步骤之前,与(&)上一个下三角矩阵M就好了
Multi-Head Attention
Multi-Head Attention就是将上述的Attention做h遍,然后将h个输出进行concat得到最终的输出。这样做可以很好地提高算法的稳定性,在很多Attention相关的工作中都有相关的应用。Transformer的实现中,为了提高Multi-Head的效率,将W扩大了h倍,然后通过view(reshape)和transpose操作将相同词的不同head的k、q、v排列在一起进行同时计算,完成计算后再次通过reshape和transpose完成拼接,相当于对于所有的head进行了一个并行处理。
Position-wise Feed Forward Networks
Encoder中和Decoder中经过Attention之后输出的n个向量(这里n是词的个数)都分别的输入到一个全连接层中,完成一个逐个位置的前馈网络。
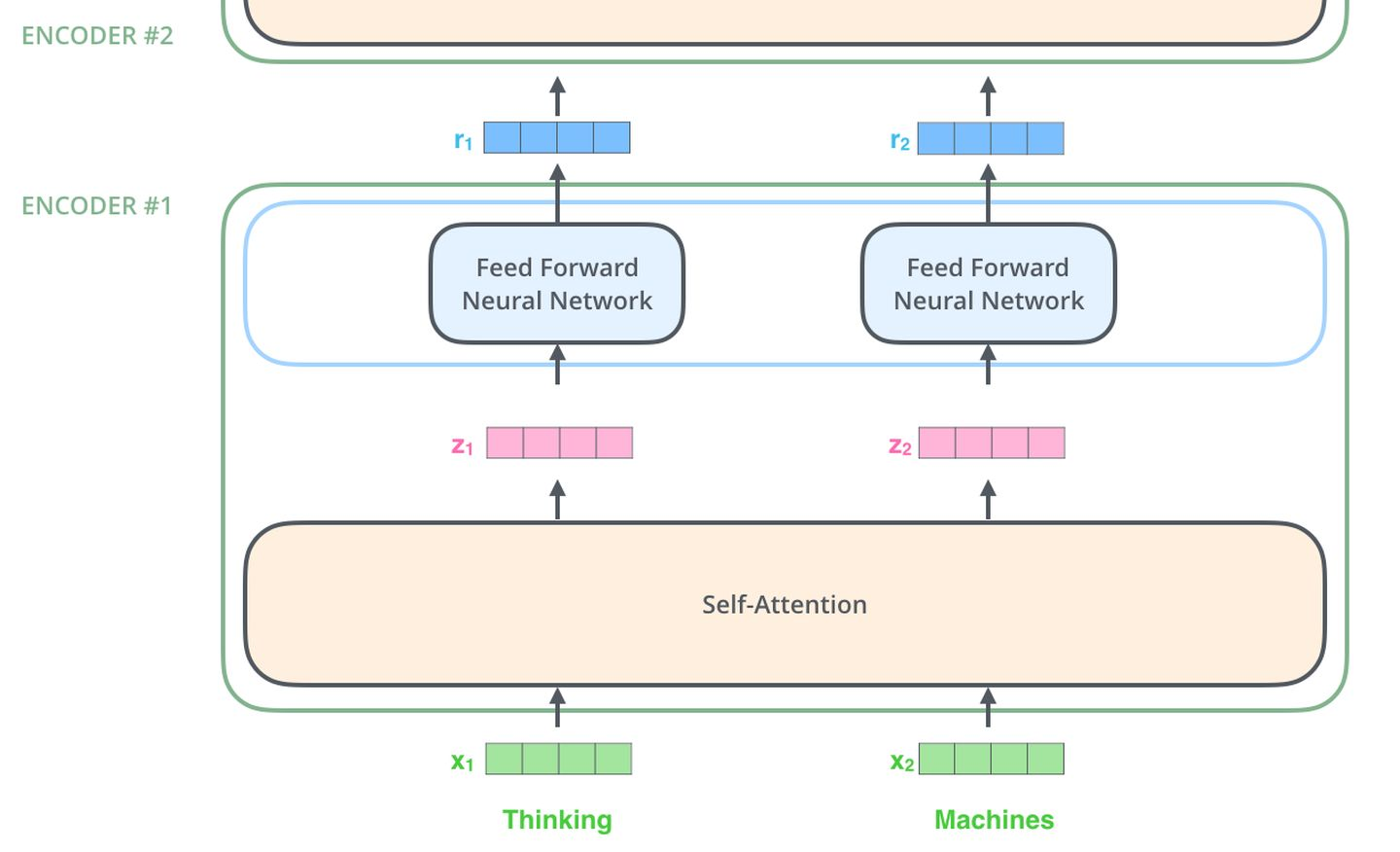
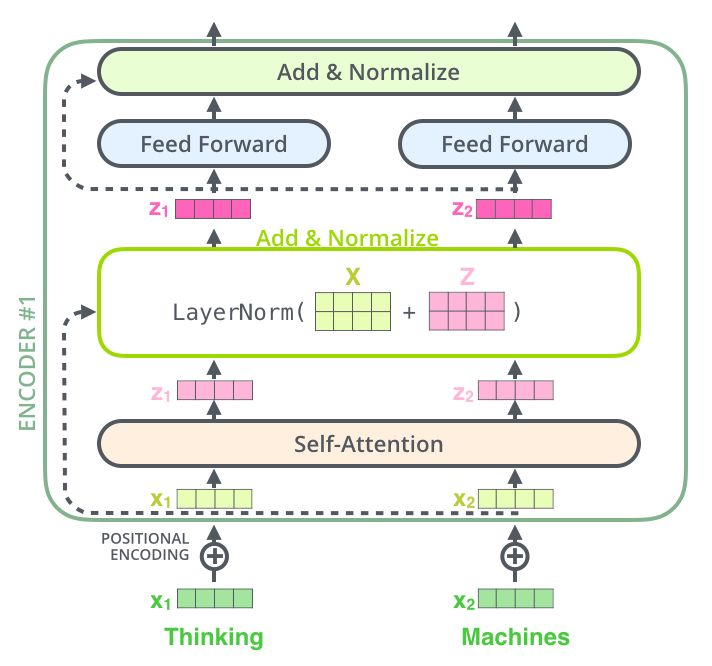
Add & Norm
是一个残差网络,将一层的输入与其标准化后的输出进行相加即可。Transformer中每一个Self Attention层与FFN层后面都会连一个Add & Norm层。
Positional Encoding
一种做法就是分配一个0到1之间的数值给每个时间步,其中,0表示第一个词,1表示最后一个词。这种方法虽然简单,但会带来很多问题。其中一个就是你无法知道在一个特定区间范围内到底存在多少个单词。换句话说,不同句子之间的时间步差值没有任何的意义。
另一种做法就是线性分配一个数值给每个时间步。也就是,1分配给第一个词,2分配给第二个词,以此类推。这种方法带来的问题是,不仅这些数值会变得非常大,而且模型也会遇到一些比训练中的所有句子都要长的句子。此外,数据集中不一定在所有数值上都会包含相对应长度的句子,也就是模型很有可能没有看到过任何一个这样的长度的样本句子,这会严重影响模型的泛化能力。
因此,一种好的位置编码方案需要满足以下几条要求:
- 它能为每个时间步输出一个独一无二的编码;
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致;
- 模型应该能毫不费力地泛化到更长的句子。它的值应该是有界的;
- 它必须是确定性的。
Transformer的作者们提出了一个简单但非常创新的位置编码方法,能够满足上述所有的要求。首先,这种编码不是单一的一个数值,而是包含句子中特定位置信息的d 维向量(非常像词向量)。第二,这种编码没有整合进模型,而是用这个向量让每个词具有它在句子中的位置的信息。换句话说,通过注入词的顺序信息来增强模型输入。
相对位置的线性关系:正弦曲线函数的位置编码的另一个特点是,它能让模型毫不费力地关注相对位置信息。这里引用原文的一段话:
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset \(k\), \(\text{PE}_{\text{pos}+k}\) can be represented as a linear function of \(\text{PE}_{\text{pos}}\)
我们选择正弦曲线函数,因为我们假设它能让模型很容易地学习关注相对位置,因为对于任何固定的偏移量 \(k\), \(\text{PE}_{\text{pos}+k}\) 可以表示成 \(\text{PE}_{\text{pos}} \)的线性函数。
由于Transformer中既不存在RNN,也不同于CNN,句子里的所有词都被同等的看待,所以词之间就没有了先后关系。换句话说,很可能会带上和词袋模型相同的不足。为了解决这个问题,Transformer提出了Positional Encoding的方案,就是给每个输入的词向量叠加一个固定的向量来表示它的位置。文中使用的Positional Encoding如下
其中\(pos\)是词在句子中的位置,\(i\) 是词向量中第i位,即将每个词的词向量为一行进行叠加,然后针对每一列都叠加上一个相位不同或波长逐渐增大的波,以此来唯一区分位置。
Transformer 工作流程
Transformer的工作流程就是上面介绍的每一个子流程的拼接
- 输入的词向量首先叠加上Positional Encoding,然后输入至Transformer内
- 每个Encoder Transformer会进行一次Multi-head self attention->Add & Normalize->FFN->Add & Normalize流程,然后将输出输入至下一个Encoder中
- 最后一个Encoder的输出将会作为memory保留
- 每个Decoder Transformer会进行一次Masked Multi-head self attention->Multi-head self attention->Add & Normalize->FFN->Add & Normalize流程,其中Multi-head self attention时的\(K\)、\(V\)至来自于Encoder的memory。根据任务要求输出需要的最后一层Embedding。
- Transformer的输出向量可以用来做各种下游任务
具体实现可以参考这里:The Annotated Transformer
Transformer机器翻译任务具体训练和推理过程
推理过程:
以“我爱你”到“I love you”为例,对于transformer来讲,在翻译“我爱你”这句话时,先将其进行embedding和encoding送入encoder(包含n层encoder layers),encoder layer之间完全是串联关系,最终在第n层encoder layer得到k,v。
对于decoder来讲,t0时刻先输入起始符(S),通过n层decoder layer(均计算masked自注意力与交互注意力(由decoder得到的q与encoder输出的k,v计算)),最终在第n层decoder layer得到当前的预测结果projection(可以理解成“I love you”中的“I”);在t1时刻,将t0时刻得到的输出“I”输入至decoder,重复t0的过程(计算masked自注意力与交互注意力),最终在第n层decoder layer得到输出“love”。最后经过多次计算,得到完整输出结果“I love you E”(E为终止符,由“you”输入decoder得到),是一个自回归的过程。
训练过程:
仍以“我爱你”到“I love you”为例,在训练过程中,encoder输入的是待翻译句子“我爱你”,得到k,v;decoder输入的是“S I love you”(S位起始符);最终计算loss的label是“I love you E”。
所谓的mask其实就是一个上斜为1的矩阵,如下图所示
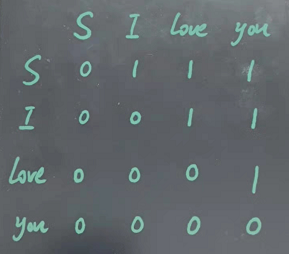
对于mask,0为可以看到的字,1为看不到的字。在此具体问题中,当计算自注意力的字是S时,就看不到后面的“I”,“love”,“you”;计算z自注意力的字时“I”时,就看不到后面的“love”,“you”,以此类推。
对于decoder中的交互注意力来讲,\(q\),\(k\),\(v\)(\(k\),\(v\)是encoder)均来自输入的一整段话。我们可以看到,在由q,k相乘结果再与v相乘前,先对\(qk^T\)进行了softmax计算,那么在进行softmax前,mask就发挥作用了,decoder会根据mask将对应位置的值设置为无穷小, 比如\(-1e^{10}\),这样在计算softmax时,会使其失去作用(趋近于0),进而在与v相乘时,也就忽略了v中对应的 “love” 和 “you” 的部分。
以“S I love you”为例,如果我们想对“I”求交互注意力,那么我们应该让此时的注意力机制看不到后面的“love”和“you”,此时对应了上文中mask矩阵的第二行,即让“love”和“you”在qkt中对应的值置为无穷小,这样在做softmax的时候,就可以忽略“love”和“you”的作用,也就是在一定程度上实现了“看不到”后面的“love”和“you”的作用
以上就是decoder在训练过程中,mask所起到的作用,最后decoder得到预测输出,与label的“I love you E”计算loss,使得其输出逼近label,最终得到训练好的模型。
单向二阶段训练模型——OpenAI GPT
GPT(Generative Pre-Training),是OpenAI在2018年提出的模型,利用Transformer模型来解决各种自然语言问题,例如分类、推理、问答、相似度等应用的模型。GPT采用了Pre-training + Fine-tuning的训练模式,使得大量无标记的数据得以利用,大大提高了这些问题的效果。
GPT就是利用Transformer进行自然语言各种任务的尝试之一,主要有以下三个要点
- Pre-Training的方式
- 单向Transformer模型
- Fine-Tuning与不同输入数据结构的变化
如果已经理解了Transformer的原理,那么只需要再搞懂上面的三个内容就能够对GPT有更深的认识。
Pre-Training 训练方式
很多机器学习任务都需要带标签的数据集作为输入完成。但是我们身边存在大量没有标注的数据,例如文本、图片、代码等等。标注这些数据需要花费大量的人力和时间,标注的速度远远不及数据产生的速度,所以带有标签的数据往往只占有总数据集很小的一部分。随着算力的不断提高,计算机能够处理的数据量逐渐增大。如果不能很好利用这些无标签的数据就显得很浪费。
所以半监督学习和预训练+微调的二阶段模式整变得越来越受欢迎。最常见的二阶段方法就是Word2Vec,使用大量无标记的文本训练出带有一定语义信息的词向量,然后将这些词向量作为下游机器学习任务的输入,就能够大大提高下游模型的泛化能力。
但是Word2Vec有一个问题,就是单个单词只能有一个Embedding。这样一来,一词多义就不能很好地进行表示。
单向Transformer结构
OpenAI GPT采用了单向Transformer完成了这项预训练任务。
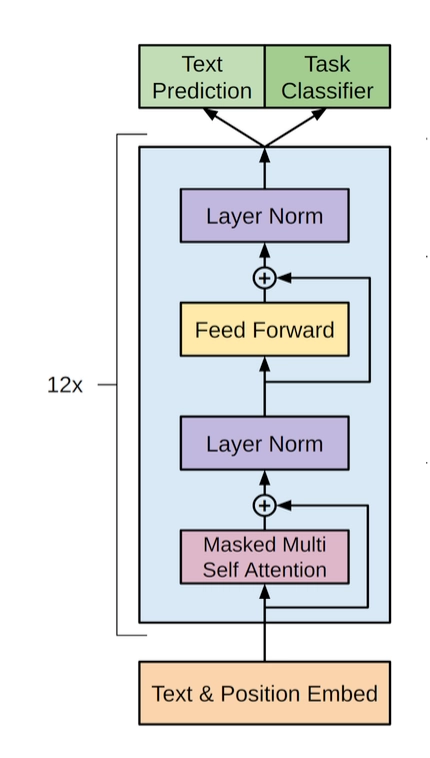
什么是单向Transformer?在Transformer的文章中,提到了Encoder与Decoder使用的Transformer Block是不同的。在Decoder Block中,使用了Masked Self-Attention,即句子中的每个词,都只能对包括自己在内的前面所有词进行Attention,这就是单向Transformer。GPT使用的Transformer结构就是将Encoder中的Self-Attention替换成了Masked Self-Attention,具体结构如下图所示:
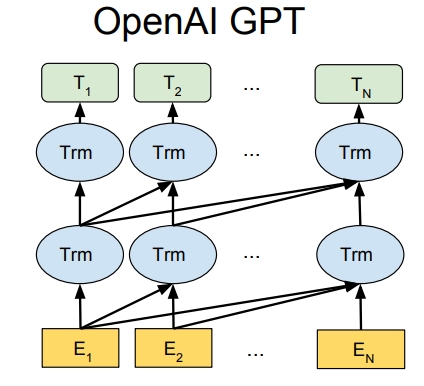
由于采用的是单向的Transformer,只能看到上文的词,所以语言模型为:
而训练的过程其实非常的简单,就是将句子n个词的词向量(第一个为<SOS>)加上Positional Encoding后输入到前面提到的Transfromer中,n个输出分别预测该位置的下一个词(<SOS>预测句子中的第一个词,最后一个词的预测结果不用于语言模型的训练)。
由于使用了Masked Self-Attention,所以每个位置的词都不会“看见”后面的词,也就是预测的时候是看不见“答案”的,保证了模型的合理性,这也是为什么OpenAI采用了单向Transformer的原因。
Fine-Tuning与不同输入数据结构的变化
接下来就进入模型训练的第二步,运用少量的带标签数据对模型参数进行微调。
上一步中最后一个词的输出我们没有用到,在这一步中就要使用这一个输出来作为下游监督学习的输入。
为避免Fine-Tuning使得模型陷入过拟合,文中还提到了辅助训练目标的方法,类似于一个多任务模型或者半监督学习。具体方法就是在使用最后一个词的预测结果进行监督学习的同时,前面的词继续上一步的无监督训练,使得最终的损失函数成为:
针对不同任务,需要修改输入数据的格式:
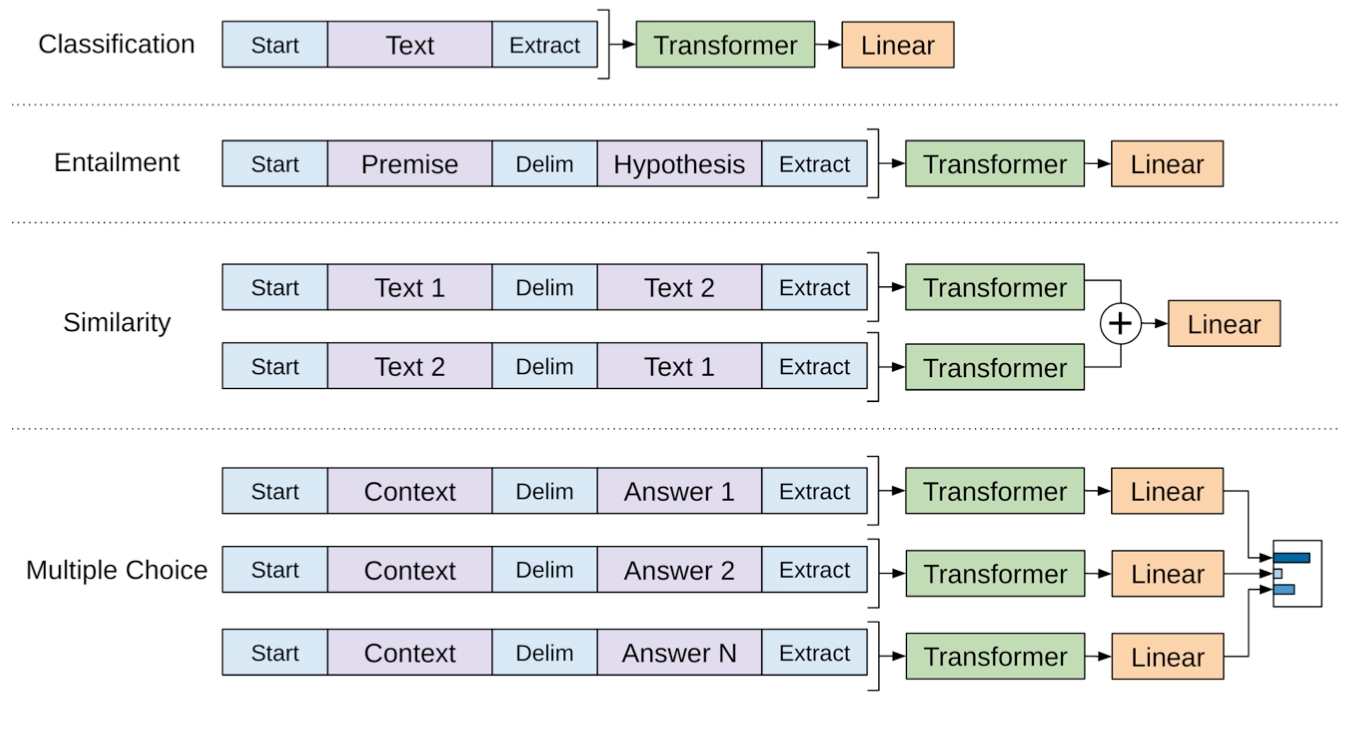
- Classification:对于分类问题,不需要做什么修改
- Entailment:对于推理问题,可以将先验与假设使用一个分隔符分开
- Similarity:对于相似度问题,由于模型是单向的,但相似度与顺序无关。所以需要将两个句子顺序颠倒后两次输入的结果相加来做最后的推测
- Multiple Choice:对于问答问题,则是将上下文、问题放在一起与答案分隔开,然后进行预测
双向二阶段训练模型——BERT
BERT(Bidirectional Encoder Representation from Transformer),是Google Brain在2018年提出的基于Transformer的自然语言表示框架。是一提出就大火的明星模型。BERT与GPT一样,采取了Pre-training + Fine-tuning的训练方式,在分类、标注等任务下都获得了更好的效果。
BERT与GPT非常的相似,都是基于Transformer的二阶段训练模型,都分为Pre-Training与Fine-Tuning两个阶段,都在Pre-Training阶段无监督地训练出一个可通用的Transformer模型,然后在Fine-Tuning阶段对这个模型中的参数进行微调,使之能够适应不同的下游任务。
虽然BERT与GPT看上去非常的相似,但是它们的训练目标和模型结构和使用上还是有着些许的不同:
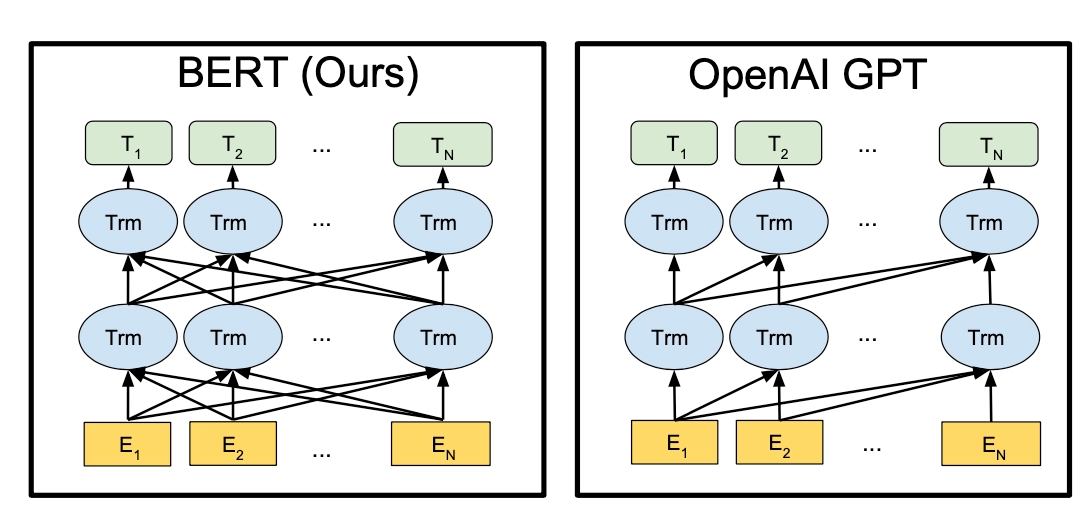
- GPT采用的是单向的Transformer,而BERT采用的是双向的Transformer,也就是不用进行Mask操作;
- 使用的结构的不同,直接导致了它们在Pre-Training阶段训练目标的不同;
双向Transformer
BERT采用的是不经过Mask的Transformer,也就是与Transformer文章中的Encoder Transformer结构完全一样:
GPT中因为要完成语言模型的训练,也就要求Pre-Training预测下一个词的时候只能够看见当前以及之前的词,这也是GPT放弃原本Transformer的双向结构转而采用单向结构的原因。
BERT为了能够同时得到上下文的信息,而不是像GPT一样完全放弃下文信息,采用了双向的Transformer。但是这样一来,就无法再像GPT一样采用正常的语言模型来预训练了,因为BERT的结构导致每个Transformer的输出都可以看见整个句子的,无论你用这个输出去预测什么,都会“看见”参考答案,也就是“see itself”的问题。ELMo中虽然采用的是双向RNN,但是两个RNN之间是独立的,所以可以避免see itself的问题。
Pre-Training阶段
那么BERT想用双向的Transformer模型,就不得不放弃GPT中所采用的语言模型来作为预训练的目标函数。取而代之的,BERT提出了一种完全不同的预训练方法。
Masked Language Model (MLM)
在Transformer中,我们即想要知道上文的信息,又想要知道下文的信息,但同时要保证整个模型不知道要预测词的信息,那么就干脆不要告诉模型这个词的信息就可以了。也就是说,BERT在输入的句子中,挖掉一些需要预测的词,然后通过上下文来分析句子,最终使用其相应位置的输出来预测被挖掉的词。这其实就像是在做完形填空 (Cloze)一样。
但是,直接将大量的词替换为<MASK>标签可能会造成一些问题,模型可能会认为只需要预测<MASK>相应的输出就行,其他位置的输出就无所谓。同时Fine-Tuning阶段的输入数据中并没有<MASK>标签,也有数据分布不同的问题。为了减轻这样训练带来的影响,BERT采用了如下的方式:
- 输入数据中随机选择15%的词用于预测,这15%的词中,
- 80%的词向量输入时被替换为
<MASK> - 10%的词的词向量在输入时被替换为其他词的词向量
- 另外10%保持不动
这样一来就相当于告诉模型,我可能给你答案,也可能不给你答案,也可能给你错误的答案,有<MASK>的地方我会检查你的答案,没<MASK>的地方我也可能检查你的答案,所以<MASK>标签对你来说没有什么特殊意义,所以无论如何,你都要好好预测所有位置的输出。
Next Sentence Prediction (NSP)
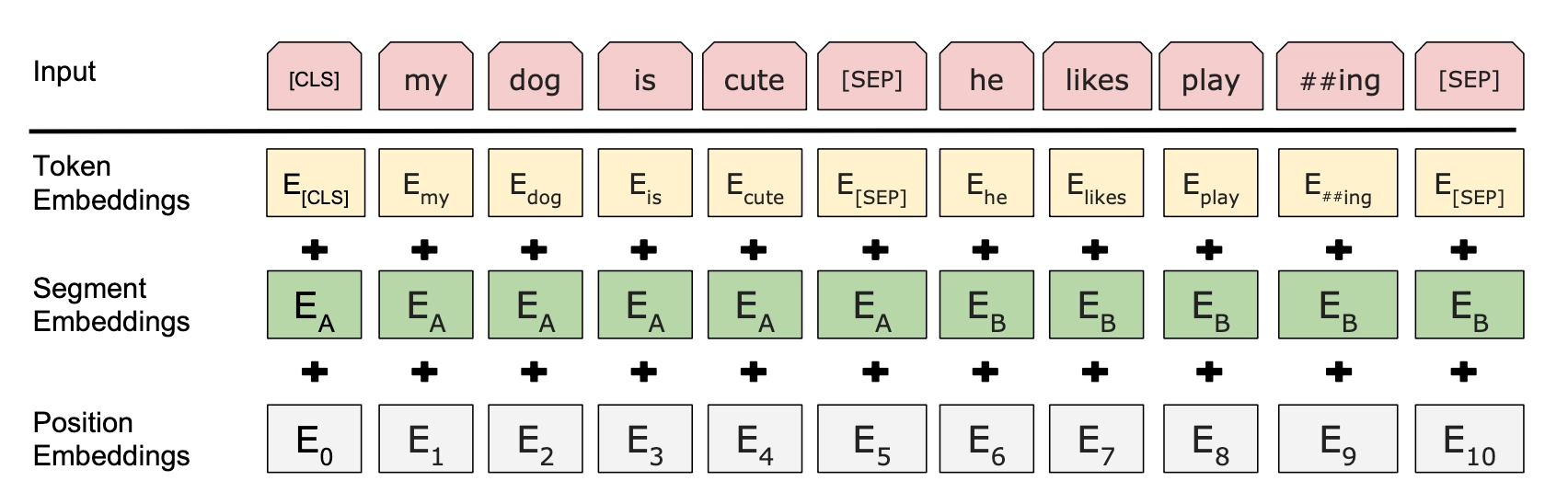
BERT还提出了另外一种预训练方式NSP,与MLM同时进行,组成多任务预训练。这种预训练的方式就是往Transformer中输入连续的两个句子,左边的句子前面加上一个<CLS>标签,它的输出被用来判断两个句子之间是否是连续上下文关系。采用负采样的方法,正负样本各占50%。
为了区分两个句子的前后关系,BERT除了加入了Positional Encoding之外,还两外加入了一个在预训练时需要学习的Segment Embedding来区分两个句子。这样一来,BERT的输入就由词向量、位置向量、段向量三个部分相加组成。此外,两个句子之间使用<SEP>标签予以区分。
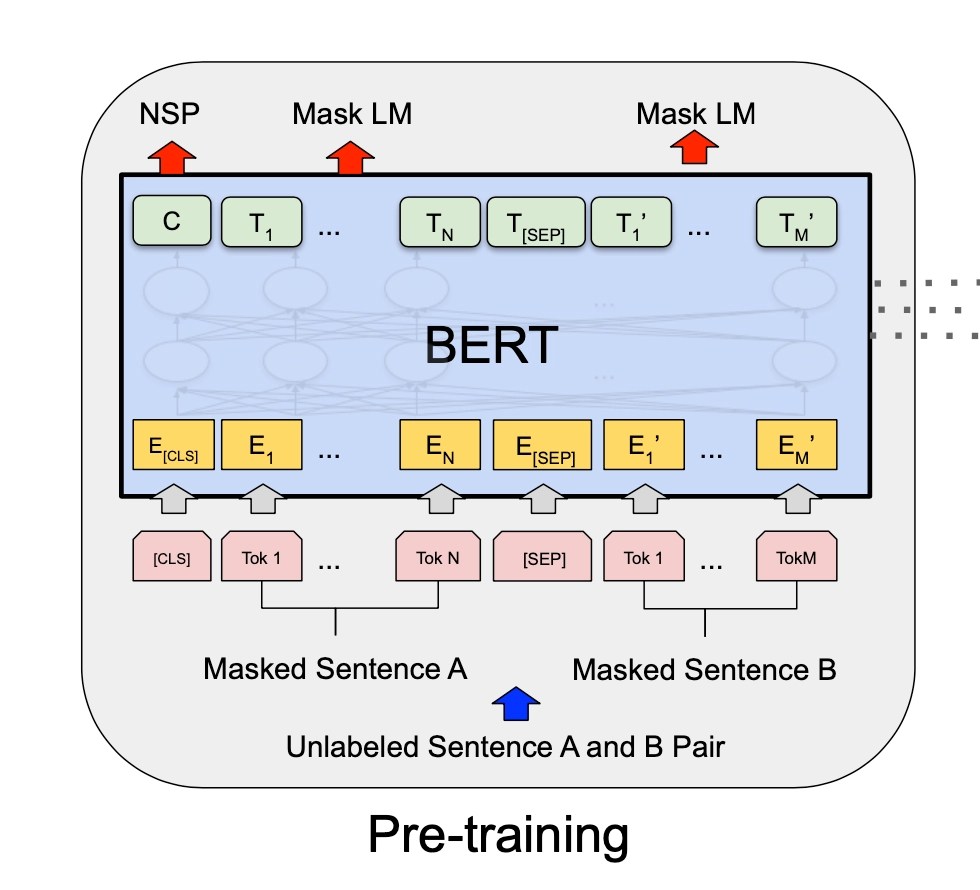
整体Pre-Training的示意图如下:
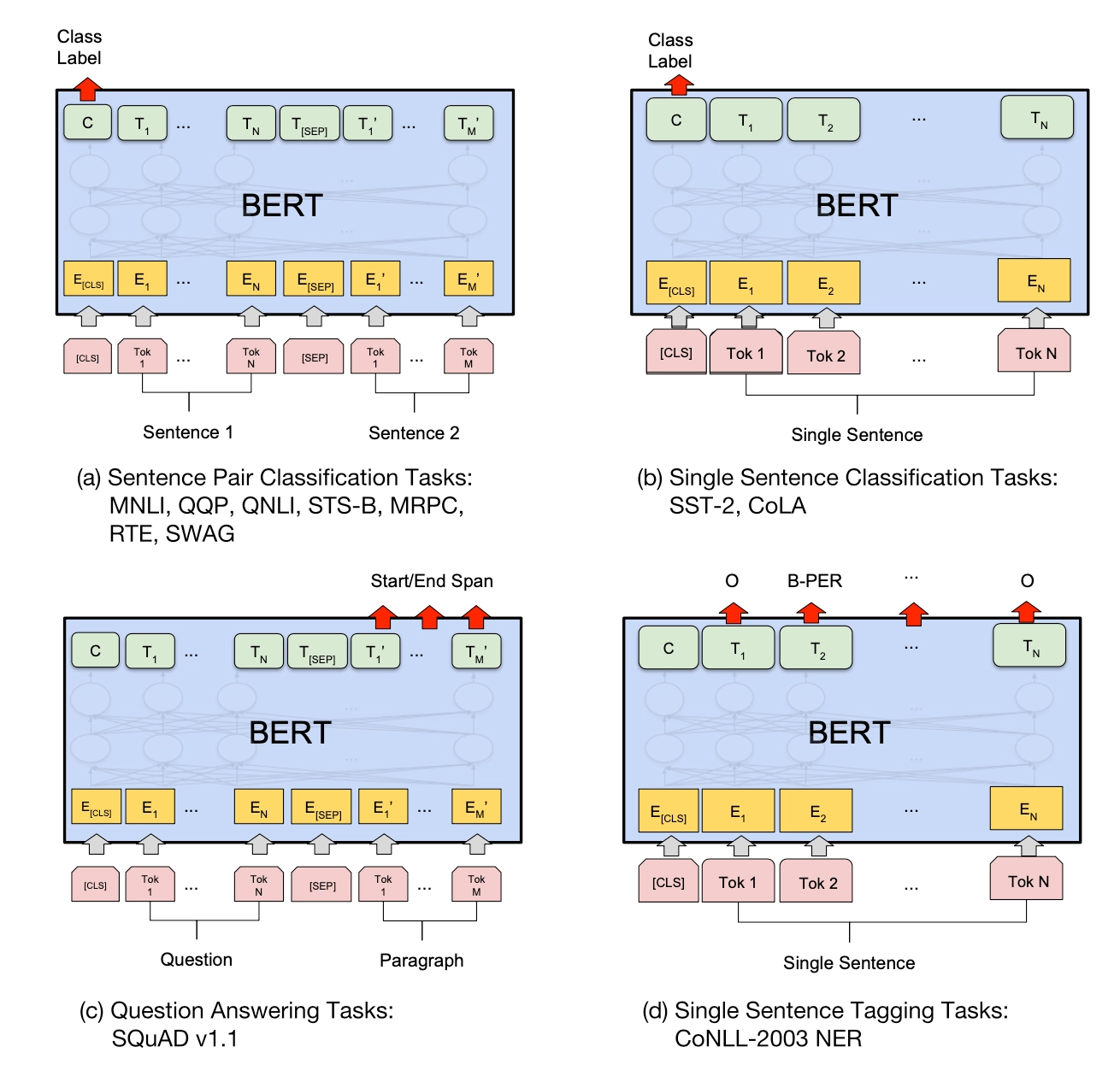
Fine-Tuning阶段
BERT的Fine-Tuning阶段和GPT没有太大区别。因为采用了双向的Transformer所以放弃了GPT在Fine-Tuning阶段使用的辅助训练目标,也就是语言模型。此外就是将分类预测用的输出向量从GPT的最后一个词的输出位置改为了句子开头<CLS>的位置了。不同的任务Fine-Tuning的示意图如下:
Post Scriptum
个人认为,BERT只是GPT模型的一种trade-off,为了在两个阶段都能够同时获得句子上下文的信息,使用了双向Transformer模型。但是为此却要付出失去传统语言模型的代价,转而采用MLM+NSP这种更加复杂的方式进行预训练。
多任务模型——MT-DNN
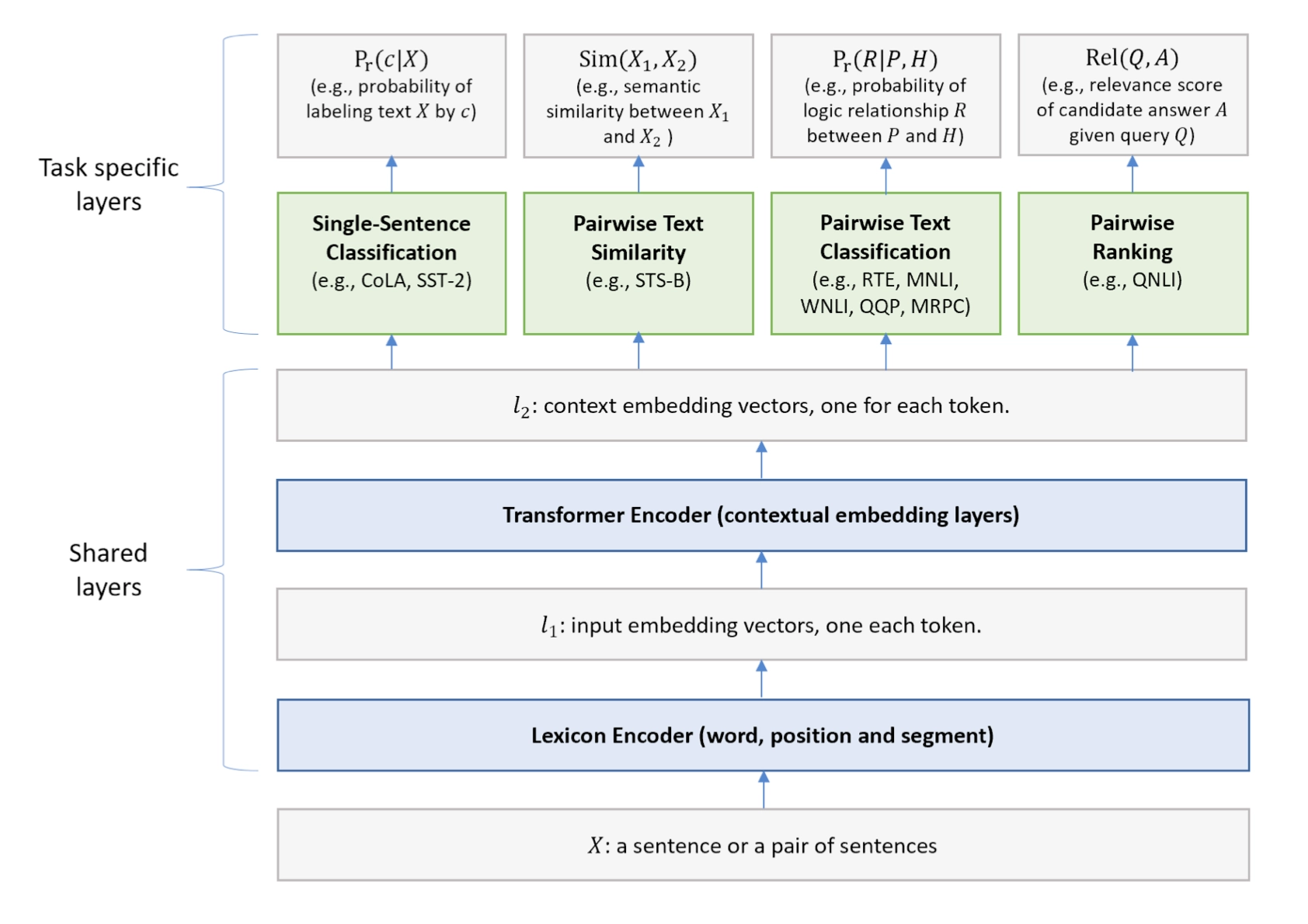
MT-DNN (Multi-Task Deep Neural Networks) 依然采用了BERT的二阶段训练方法以及双向Transformer。在Pre-Training阶段,MT-DNN与BERT几乎完全一样,但是在Fine-Tuning阶段,MT-DNN采用了多任务的微调方式。同时采用Transformer输出的上下文Embedding进行单句分类、文本对相似度、文本对分类以及问答等任务的训练。整个结构如下图所示:
单向通用模型——GPT-2
GPT-2继续沿用了原来在GPT中使用的单向Transformer模型,而这篇文章的目的就是尽可能利用单向Transformer的优势,做一些BERT使用的双向Transformer所做不到的事。那就是通过上文生成下文文本。
GPT-2的想法就是完全舍弃Fine-Tuning过程,转而使用一个容量更大、无监督训练、更加通用的语言模型来完成各种各样的任务。我们完全不需要去定义这个模型应该做什么任务,因为很多标签所蕴含的信息,就存在于语料当中。就像一个人如果博览群书,自然可以根据看过的内容轻松的做到自动摘要、问答、续写文章这些事。
严格来说GPT-2可能不算是一个多任务模型,但是它确实使用相同的模型、相同的参数完成了不同的任务。那么GPT-2是怎么使用语言模型完成多种任务的呢?
通常我们针对特定任务训练的专用模型,给定输入,就可以返回这个任务相应的输出,也就是
那么如果我们希望设计一个通用的模型,这个模型在给定输入的同时还需要给定任务类型,然后根据给定输入与任务来做出相应的输出,那么模型就可以表示成下面这个样子
就好像原来我需要翻译一个句子,需要专门设计一个翻译模型,想要问答系统需要专门设计一个问答模型。但是如果一个模型足够聪明,并且能够根据你的上文生成下文,那我们就可以通过在输入中加入一些标识符就可以区分各种问题。比如可以直接问他:(‘自然语言处理', 中文翻译)来得到我们需要的结果Nature Language Processing。在我的理解中GPT-2更像是一个无所不知的问答系统,通过告知一个给定任务的标识符,就可以对多种领域的问答、多种任务做出合适的回答。GPT-2满足零样本设置 (zero-shot setting), 在训练的过程中不需要告诉他应该完成什么样的任务,预测是也能给出较为合理的回答。
那么GPT-2为了做到上面这些要求,做了哪些工作呢?
- 拓宽并加大数据集
首先就是要让模型博览群书,如果训练样本都不够多,那还怎么进行推理?前面的工作都是针对某一个特定问题的,所以数据集都比较片面。GPT-2收集了一个规模更大、范围更广的数据集。同时呢,要保证这个数据集的质量,保留那些拥有高质量内容的网页。最终组成了一个800万个文本,40G的数据集WebText。 - 扩大网络容量
书多了脑袋容量也得带一些要不然记不住书里的东西。为了提高网络的容量,使其拥有更强的学习潜力,GPT-2将Transformer堆叠的层数增加到48层,隐层的维度为1600,参数量达到了15亿。 - 调整网络结构
GPT-2将词汇表提升到50257,最大的上下文大小 (context size) 从GPT的512提升到了1024,batchsize从512提升为1024。此外还对Transformer做出了小调整,标准化层放到没每个sub-block之前,最后一个Self-attention后又增加了一个标准化层;改变了残差层的初始化方法等等。
Post Scriptum
GPT-2其实最惊人的是其极强的生成能力,而如此强大的生成能力主要还是要归功于其数据质量以及惊人参数量和数据规模。GPT-2的参数量大到用于实验的模型都还处于欠拟合状态,如果接着训练,效果还能进一步提升。