引言与背景
随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。
随机逼近的核心优势在于:
- 能够处理带有随机噪声的观测数据
- 不需要目标函数的解析表达式
- 可以在线学习,每获得一个新样本就更新估计值
均值估计问题
考虑一个随机变量\(X\),其取值来自有限集合\(\mathcal{X}\)。我们的目标是估计\(E[X]\)。假设我们有一个独立同分布的样本序列\(\{x_i\}_{i=1}^n\),那么\(X\)的期望值可以近似为:
非增量方法与增量方法
非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。
增量方法:定义
可以推导出递归公式:
这个算法可以增量式地计算平均值,每次收到新样本就立即更新估计值。可以验证:
更一般的形式是:
其中\(\alpha_k > 0\) 是步长参数。 \(\{\alpha_k\}\) 满足一定条件(后面会说),当 \(k \to \infty\) 时,\(w_k \to E[X]\)。
Robbins-Monro算法
假设我们想要找到方程\(g(w) = 0\) 的根,其中\(w \in \mathbb{R}\) 是未知变量,\(g: \mathbb{R} \to \mathbb{R}\) 是一个函数。但是我们面临的问题是:
- 函数 \(g\) 的表达式未知
- 我们只能获得 \(g(w)\) 的带噪声观测值:\(\tilde{g}(w, \eta) = g(w) + \eta\)
如下图所示,这是一个黑盒系统,只有输入\(w\) 和带噪声的输出 \(\tilde{g}\) 是已知的。

算法描述
Robbins-Monro算法的形式为:
其中 \(w_k\) 是第 \(k\) 次对根的估计,\(\tilde{g}(w_k, \eta_k)\) 是第 \(k\) 次带噪声的观测值,\(a_k\) 是正系数。
💡 Robbins-Monro算法示例:求解 \(g(w) = w^3 - 5\) 的根
个方程的真实根是 \(w^* = 5^{1/3} \approx 1.71\)。
在这个例子中,假设我们无法直接观察函数 \(g(w)\) 的值, 只能观察到带有噪声的输出:\(\tilde{g}(w) = g(w) + \eta\), 并且噪声 \(\eta\) 是独立同分布的,服从标准正态分布(均值为0,标准差为1)
我们使用RM算法来求解这个问题:\[w_{k+1} = w_k - a_k\tilde{g}(w_k, \eta_k)\]
其中:
- \(\tilde{g}(w_k, \eta_k) = w_k^3 - 5 + \eta_k\) 是带噪声的观测值
- \(a_k = 1/k\) 是步长系数
- 初始猜测值 \(w_1 = 0\)
初始状态:\(w_1 = 0\)
- 此时函数值 \(g(w_1) = 0^3 - 5 = -5\)
- 但我们观察到的是 \(\tilde{g}(w_1) = -5 + \eta_1\)
第一次更新:\[w_2 = w_1 - a_1\tilde{g}(w_1) = 0 - 1 \cdot (-5 + \eta_1) = 5 - \eta_1\]
- 如果没有噪声(\(\eta_1 = 0\)),\(w_2\) 将直接跳到5,远远超过真实根1.71
- 但由于噪声的存在,\(w_2\) 会在5附近波动
后续迭代:
- 当 \(w_k > w^*\) 时,\(g(w_k) > 0\),算法会减小 \(w_k\) 的值
- 当 \(w_k < w^*\) 时,\(g(w_k) < 0\),算法会增加 \(w_k\) 的值
- 随着 \(k\) 增大,步长 \(a_k = 1/k\) 变小,更新幅度减小
- 噪声的影响也随着步长减小而减弱
下图展示了RM算法对这个例子的模拟结果
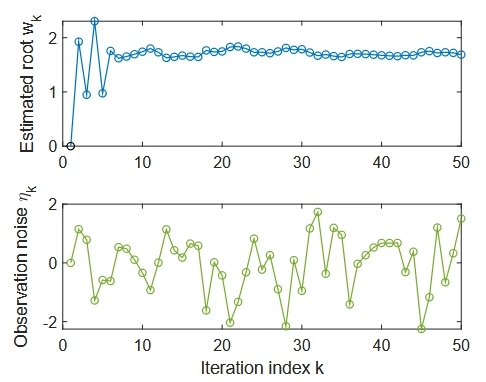
在这个例子中, 初始猜测值 \(w_1\) 必须适当选择以确保收敛, 后面的内容将会展示在不受约束的初始值下的RM算法
收敛性质
Robbins-Monro定理: 在Robbins-Monro算法中,如果满足以下条件:
- \(0 < c_1 \leq \nabla_w g(w) \leq c_2\) 对所有 \(w\) 成立;
- \(\sum_{k=1}^{\infty} a_k = \infty\) 且 \(\sum_{k=1}^{\infty} a_k^2 < \infty\);
- \(E[\eta_k|H_k] = 0\) 且 \(E[\eta_k^2|H_k] < \infty\);
其中\(H_k = \{w_k, w_{k-1}, ...\}\),则\(w_k\) 几乎必然收敛到满足 \(g(w^) = 0\)的根 \(w^*\)。
- 第一个条件:
- \(0 < c_1 \leq \nabla_w g(w)\) 表示 \(g(w)\) 是单调递增函数,确保 \(g(w) = 0\) 的根存在且唯一
- 如果 \(g(w)\) 是单调递减的,可以将 \(-g(w)\) 作为新函数
- \(\nabla_w g(w) \leq c_2\) 表示 \(g(w)\) 的梯度上界有限
- 在实际应用中我们可以将优化问题转化为寻根问题:假设我们要最小化目标函数 \(J(w)\),可以定义 \(g(w) = \nabla_w J(w)\),优化问题转化为求解 \(g(w) = 0\)(即寻找梯度为零的点),在这种情况下,条件 \(\nabla_w g(w) > 0\) 意味着 \(\nabla_w^2 J(w) > 0\),这表明 \(J(w)\) 是凸函数。凸函数是优化问题中常见的假设,因为凸函数有良好的性质(如局部最小值就是全局最小值)。
- 第二个条件:
- \(\sum_{k=1}^{\infty} a_k^2 < \infty\) 要求 \(a_k\) 收敛到零
- \(\sum_{k=1}^{\infty} a_k = \infty\) 要求 \(a_k\) 不能收敛得太快
- 典型的满足条件的序列是 \(a_k = \frac{1}{k}\)
- 在许多应用中,RM算法中的\(a_k\) 常常被选为一个足够小的常数, 虽然不满足条件2,但在一些场景下还是可以使算法收敛
- 第三个条件:
- 这是一个温和的条件,不要求观测误差 \(\eta_k\) 是高斯分布
- 如果\(\{\eta_k\}\)是独立同分布的随机序列且满足\(E[\eta_k] = 0\) 和 \(E[\eta_k^2] < \infty\),则该条件成立
应用于均值估计
将均值估计问题表述为寻根问题:
- 定义函数 \(g(w) = w - E[X]\)
- 原问题变为求解 \(g(w) = 0\)
- 给定 \(w\) 值,我们能获得的带噪声观测是 \(\tilde{g} = w - x\)
- 可以写成 \(\tilde{g}(w, \eta) = g(w) + \eta\),其中 \(\eta = E[X] - x\)
应用Robbins-Monro算法:
这正是之前的均值估计算法。根据Robbins-Monro定理,如果\(\sum_{k=1}^{\infty} \alpha_k = \infty\),\(\sum_{k=1}^{\infty} \alpha_k^2 < \infty\),且\(\{x_k\}\) 是独立同分布的,则 \(w_k\) 几乎必然收敛到 \(E[X]\)。
对于Robbins-Monro算法的证明可以用Dvoretzky收敛定理, 具体证明过程可以参阅 Mathematical Foundations of Reinforcement Learning
随机梯度下降(SGD)
考虑以下优化问题:
其中\(w\) 是待优化参数,\(X\) 是随机变量,期望是关于\(X\) 计算的。
梯度下降算法为:
但这需要计算期望\(E[\nabla_w f(w_k, X)]\),而这通常是未知的。
随机梯度下降算法
要解决这个问题,首先可以考虑用样本均值代替期望,即
将其带入到 (2), 可得,
上面的算法的一个问题是它需要每次迭代中的所有样本。 在实践中,如果样本是逐个采集的,那么每次采集样本时更新 \(w\) 是比较好处理的。为此,我们可以使用以下算法:
其中 \(x_k\) 是在时间步 \(k\) 收集的样本。该算法即为随机梯度下降法,因为它依赖于随机样本。随机梯度下降算法用随机梯度 \(\nabla_w f(w_k, x_k)\) 替代真实梯度 \(E[\nabla_w f(w_k, X)]\)。
收敛性分析
SGD有一个有趣的收敛模式:当估计值远离最优解时,收敛过程快速;当估计值接近最优解时,随机梯度的随机性变得显著,收敛速度减慢。
相对误差分析:
这表明相对误差 \(\delta_k\) 与 \(|w_k - w^*|\) 成反比。
SGD的收敛性定理: 对于SGD算法\(w_{k+1} = w_k - \alpha_k \nabla_w f(w_k, x_k)\),如果满足以下条件,则 \(w_k\)几乎必然收敛到\(\nabla_w E[f(w, X)] = 0\) 的根:
- \(0 < c_1 \leq \nabla_w^2 f(w, X) \leq c_2\);
- \(\sum_{k=1}^{\infty} a_k = \infty\) 且 \(\sum_{k=1}^{\infty} a_k^2 < \infty\);
- \(\{x_k\}_{k=1}^{\infty}\) 是独立同分布的。
SGD算法可以看作是特殊的Robbins-Monro算法:
SGD要解决的问题是最小化\(J(w) = E[f(w, X)]\),可以转化为寻根问题:找到\(\nabla_w J(w) = E[\nabla_w f(w, X)] = 0\) 的根。
令\(g(w) = \nabla_w J(w) = E[\nabla_w f(w, X)]\),我们要找到 \(g(w) = 0\) 的根。我们能测量的量是\(\tilde{g} = \nabla_w f(w, x)\),可以重写为:
应用Robbins-Monro算法:
这正是SGD算法。可以验证Robbins-Monro定理的三个条件都满足,因此SGD收敛
SGD与均值估计
均值估计问题可以表述为优化问题:
其中\(f(w, X) = \|w - X\|^2/2\),梯度为\(\nabla_w f(w, X) = w - X\)。可以验证最优解为\(w^* = E[X]\)(通过求解\(\nabla_w J(w) = 0\))。
应用SGD算法:
这正是之前的均值估计算法,表明均值估计算法是一个专门为解决均值估计问题设计的SGD算法。
BGD, SGD, and mini-batch GD
假设我们要最小化\(J(w) = E[f(w, X)]\),给定随机样本集\(\{x_i\}_{i=1}^n\):
- 批量梯度下降(BGD):
- 小批量梯度下降(MBGD):
其中\(I_k\) 是\(\{1,...,n\}\)的一个子集,大小为\(|I_k| = m\)
- 随机梯度下降(SGD):
MBGD可以看作是SGD和BGD之间的中间版本:
- 相比SGD,MBGD随机性更小,因为它使用更多样本
- 相比BGD,MBGD不需要在每次迭代中使用所有样本,更加灵活
- 如果\(m = 1\),MBGD变为SGD
- MBGD的收敛速度通常比SGD更快
对于均值估计问题,三种算法分别为:
- BGD:\(w_{k+1} = w_k - \alpha_k(w_k - \bar{x})\)
- MBGD:\(w_{k+1} = w_k - \alpha_k(w_k - \bar{x}_k^{(m)})\),其中\(\bar{x}_k^{(m)} = \frac{1}{m}\sum_{j \in I_k} x_j\)
- SGD:\(w_{k+1} = w_k - \alpha_k(w_k - x_k)\)
当\(\alpha_k = 1/k\)时,这些方程可以解为:
- BGD:\(w_{k+1} = \bar{x}\)
- MBGD:\(w_{k+1} = \frac{1}{k}\sum_{j=1}^k \bar{x}_j^{(m)}\)
- SGD:\(w_{k+1} = \frac{1}{k}\sum_{j=1}^k x_j\)
Reference
https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning