1. 检测任务的困难
图像分类算法,比如ResNeXt-101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 \(AP_{50}\)为62%,显然,总体上来看,准确率差了20个点左右,那么问题来了,为什么检测算法比识别算法的效果低这么多呢?
1.1 尺度差异
作者认为原因在于,检测任务中的目标存在较大的尺度变化(large scale variation)。作者统计了Imagenet和COCO数据集的特点,如下图,
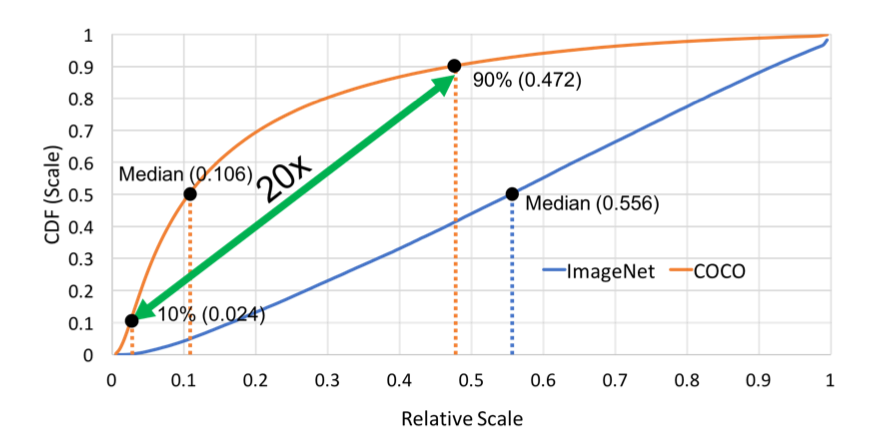
其中,横坐标表示目标相对于原图的比例,纵坐标表示累计分布(cumulation distribution function)。显然,由图中可以看出,COCO数据集中50%的目标相对原图的比例小于0.106,而Imagenet数据集中相对原图的比例小于0.106的目标的比例不足10%,因此,COCO数据集中的目标尺寸明显小于Imagenet数据集中的目标。
而且,COCO数据集中,最小的10%的目标尺寸小于0.024,最大的10%的目标尺寸大于0.472,显然,对于待检测的所有目标,它们的尺寸差异是很大的,那么如何把所有尺寸的目标都召回来呢?
文章中总结的目前尺度变化的方案:
- 使用FPN这种把浅层特征和深层特征融合的,或者最后在预测的时候,使用浅层特征和深层特征一起预测;
- 也有比较直接地在浅层和深层的feature map上直接各自独立做预测的 (e.g. SSD);
- 使用dilated或者deformable这类特殊的卷积来提高检测器对分辨率的敏感度(提高感受野)
- 最常用的,upsample来rezie网络输入图像的大小
1.2 domain-shift
通常,对于目标检测任务,我们会使用imagenet预训练的模型,然后做finetune。但是,上面提到了分类数据集中目标的尺寸比检测数据集中的大,所以直接finetune会引入“domain-shift” 问题,那么如何保证finetune用的数据集中目标尺寸和检测数据集中保持一致呢?
2 图像分辨率对分类任务的影响
在分类任务中,我们常常遇到训练集或者测试集中包含了不同分辨率的图片。根据经验这时候会有很多种选择,(1) 把所有的图片缩放到相同尺寸,然后训练和推理;(2) 训练大网络和小网络,分别用来处理大分辨率和小分辨率的图片。在论文中,作者用数据说话,证明了这两种方案都是次优的。
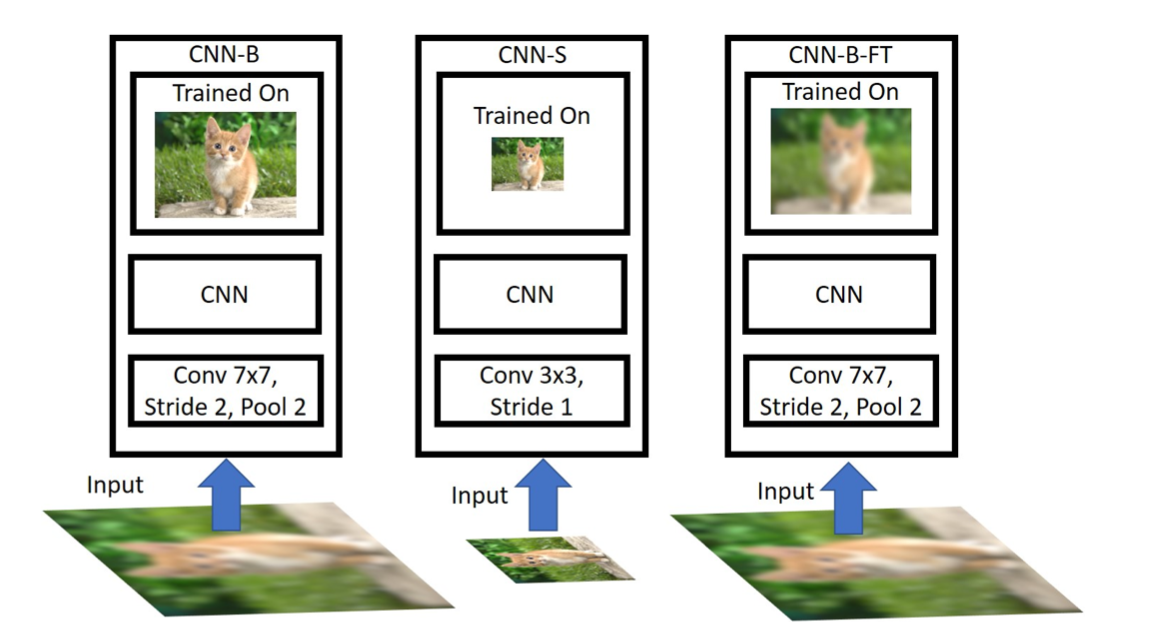
(a)CNN-B方案:在224x224尺度上训练的模型, 其stride=2. 我们将测试图片降采样到 [48x48, 64x64, 80x80, 96x96,128x128], 然后再放大回224x224用于测试;
(b)CNN-S方案:训练集将图像下采样到48 × 48 , 64 × 64 , 80 × 80 , 96 × 96 , 128 × 128 ,模拟出低分辨率图片,作为网络的输入,测试集将所有图像resize到相同分辨率,低清训练/低清测试;
(c)CNN-B-FT:先使用224 × 224 的高分辨率图像对网络做预训练,然后将图像下采样到48 × 48 , 64 × 64 , 80 × 80 , 96 × 96 , 128 × 128 ,模拟出低分辨率图片,接着将低分辨率图像resize到224×224,然后用这些上采样的模糊图片finetune模型参数。
它们的对比结果如下,

结论1:由图(a)可以看出,训练集和测试集的图像分辨率差异越大,测试集的效果越低;因此,至少在图像分类方面,对未经网络训练的分辨率进行测试显然不是最佳选择。
解释:因为先下采样然后resize,相当于训练集图片变模糊了,也即模型学习的是模糊图像的特征,且采样率越低,图片越模糊,对应的测试集(非模糊图像)效果就越差。
结论2:从图(b)可以看出,模型效果 CNN-B-FT > CNN-S > CNN-B;
解释:CNN-B-FT的效果优于CNN-S,作者认为原因是,从高分辨率图像中学习到的知识有助于识别低分辨率的图像。
可以这样理解作者的三个实验:ImageNet物体大、分辨率高,而COCO目标都很小,直接迁移会有问题,作者在试图探究如何进行迁移。降采样后的小图像数据集其实对应的是COCO数据集普遍存在的小目标的情况,试图模仿COCO数据集。因此三个网络的含义应该是:CNN-B,ImageNet预训练后的参数直接用来给COCO这种分辨率低的数据集用;CNN-S,不用ImageNet这种高分辨率的数据集做训练,我把网络就设置成适合COCO这类数据集的,训练和测试都用分辨率低的数据集;CNN-B-FT,ImageNet人家都训练好了,不用白不用,但是用之前,先用低分辨率数据集做一下fine-tune改良效果。
从CNN-B-FT的实验可以得出:在高清训练集学出来的模型依然有办法在低清晰度的图片上做预测. 直接用低清晰度图片微调好过将stride降低重新训练一个网络推广到目标检测上, 当尺度不同时, 我们可以选择更换在ImageNet上pre-trained网络架构.
3 目标检测的影响因素
3.1 图像分辨率
这里研究了训练集和测试集的分辨率对结果的影响,做了如下对比实验
实验1(简写为\(800_{all}\)):训练集分辨率设置为800 × 1400,学习训练集中的所有目标,测试集分辨率设置为1400 × 2000 ;
实验2(简写为\(1400_{all}\)):训练集分辨率设置为1400 × 2000,学习训练集中的所有目标,测试集分辨率设置为1400 × 2000 ;
对比结果:实验2的效果略微优于实验1;
解释:(1)为什么实验2的效果更好呢?因为实验2的训练集和测试集图像分辨率相同;(2)为什么效果提升不明显呢?因为实验2训练集图片分辨率大,那么其中的medium-to-large目标会变得太大导致分类出错。也就是说,高分辨率的训练集图片提升了小目标的识别效果,但是降低了medium-to-large目标的识别效果。
思考:怎么在提升小目标的识别效果的同时,也提升medium-to-large目标的识别效果呢?
3.2 图像中目标的尺寸
实验3(简写为\(1400_{<80px}\)):训练集分辨率设置为1400 × 2000,只学习训练集中的小目标,忽略掉medium-to-large目标,测试集分辨率设置为1400 × 2000;
对比结果:实验3的效果明显低于实验1;
解释:medium-to-large目标在所有目标中的比例为30%左右,完全忽略掉会导致模型对目标的差异性的学习不够充分,比如形状、姿态的变化。相反地,保留这一部分目标的话,虽然模型学的不好,但还是能学到一些信息的,好处>坏处。
3.3 数据增强
多尺度训练(Multi-Scale Training)的方法,简称为MST,通常使用全卷积网络,然后用不同分辨率的图像batch来优化模型参数,因此网络可以学习到目标在不同分辨率下的特征,但是对于特别小或者特别大的目标效果也不好。
3.4 结果与结论
3.4.1 结果
论文中给出了不同实验的结果,如下图,

3.4.2 结论
为了使检测器的效果更好,要满足两点要求,(1)检测器要学习合理尺寸的目标;(2)检测器要学习目标的差异化,比如目标本身形状、姿态的变化。
4 SNIP
4.1 网络结构
SNIP,全称为“Scale Normalization for Image Pyramids”,它的结构和MST很相似,但是算是MST的改进版本。与MST类似,它也是把输入图像缩放到不同的尺寸,论文中取了3个尺寸,480 × 800 , 800 × 1200 , 1400 × 2000,对于尺寸为1400 × 2000 的高分辨率图像,作者意识到大目标很难分类,所以只学习small目标(改进点);对于尺寸为480 × 800的低分辨率图像,作者意识到小目标很难分类,所以只学习big目标(改进点);对于尺寸为800 × 1200 800的中等分辨率图像,只学习middle目标(改进点),SNIP整个的网络结构如下图,
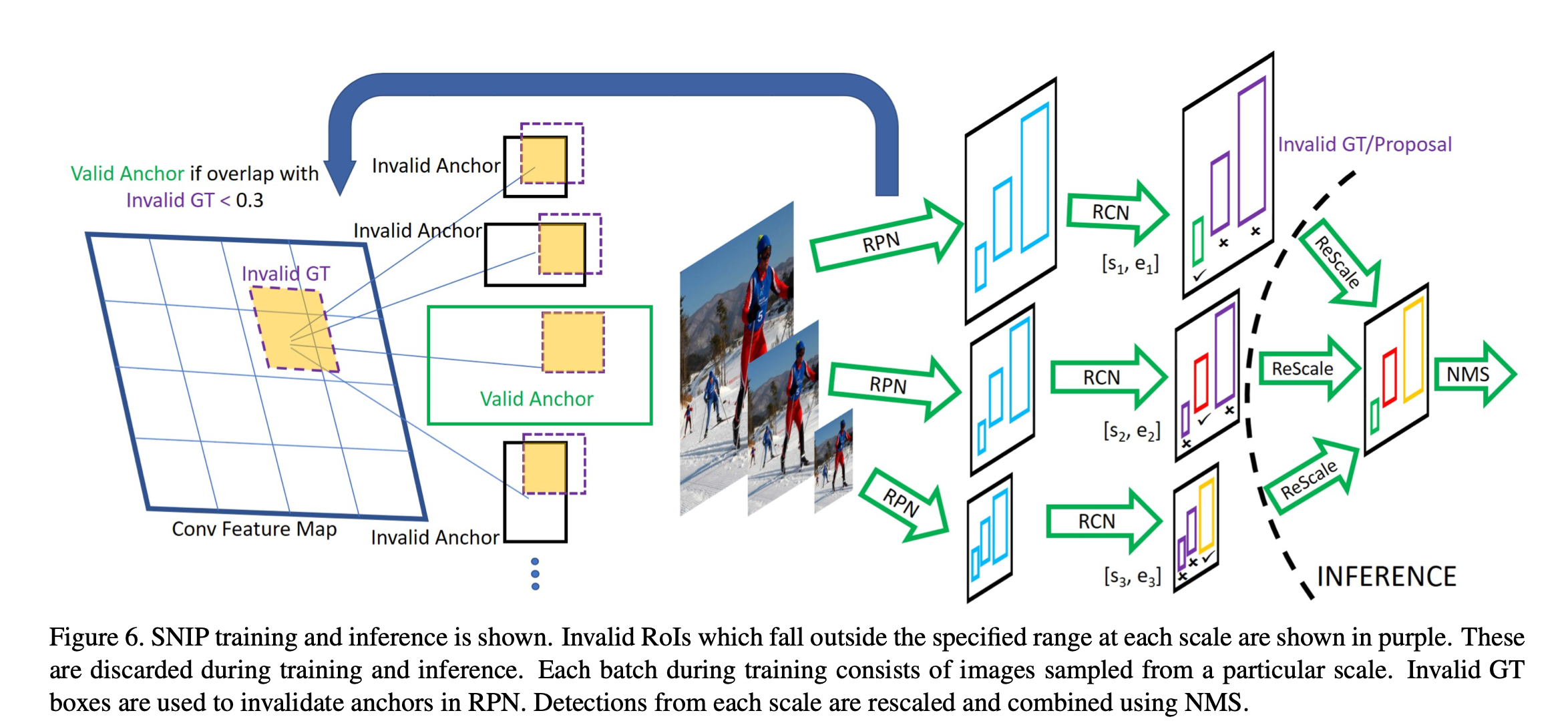
从单一分支维度来看,该分支能够学习合理尺度的目标。从目标尺度的维度来看,SNIP框架能够学习所有尺度的目标,因此保证了3.4.2中提到的两点要求。
4.2 Q&A
(1)SNIP结构中的三个分支,是否存在参数共享?
回答:上图中的三个分支的参数是共享的,在训练的时候,每个batch中的数据会缩放到某一个尺寸,比如480 × 800,然后学习该分辨率下的big目标。当训练过程完成时,网络能够学习到所有目标(small、middle、big)的特征了。
(2)Invalid GT和Invalid Anchor怎么定义?
回答:仍然以480 × 800 的训练batch为例,使用阈值 \([s_{3}, e_{3}]\)可以筛选出所有的big目标,这些big目标即为valid GT,其余的middle和small目标为Invalid GT。在RPN网络中,若当前Anchor与所有Invalid GT的IoU小于0.3,则被认为valid anchor(positive sample),否则被认为Invalid anchor(negative sample)。
- 训练与测试分辨率从不一致的时候性能会下降;
- 大分辨率输入图像虽然能提升小目标检测性能,但同时使得大目标过大导致其很难分类,此消彼长,最终精度提升并不明显;
- 多尺度训练(Mutil-Scale training),采样到的图像分辨率很大(1400x2000),导致大目标更大,而图像分辨率过小时(480x640),导致小目标更小,这些均产生了非最优的结果;
- SNIP针对不同分辨率挑选不同的proposal进行梯度传播,然后将其他的设置为0。即针对每一个图像金字塔的每一个尺度进行正则化表示;
总体来说,SNIP让模型更专注于物体本身的检测,剥离了多尺度的学习难题。在网络搭建时,SNIP也使用了类似于MST的多尺度训练方法,构建了3个尺度的图像金字塔,但在训练时,只对指定范围内的Proposal进行反向传播,而忽略掉过大或者过小的Proposal。
SNIP方法虽然实现简单,但其背后却蕴藏深意,更深入地分析了当前检测算法在多尺度检测上的问题所在,在训练时只选择在一定尺度范围内的物体进行学习,在COCO数据集上有3%的检测精度提升,可谓是大道至简。