动机
Faster R-CNN是首个利用CNN来完成proposals的预测的,之后的很多目标检测网络都是借助了Faster R-CNN的思想。而Faster R-CNN系列的网络都可以分成2个部分:
- Fully Convolutional subnetwork before RoI Layer
- RoI-wise subnetwork
第1部分就是直接用普通分类网络的卷积层,用其来提取共享特征,然后一个RoI Pooling Layer在第1部分的最后一张特征图上进行提取针对各个RoIs的特征向量(或者说是特征图,维度变换一下即可),然后将所有RoIs的特征向量都交由第2部分来处理(分类和回归),而第二部分一般都是一些全连接层,在最后有2个并行的loss函数:softmax和smoothL1,分别用来对每一个RoI进行分类和回归,这样就可以得到每个RoI的真实类别和较为精确的坐标和长宽了。
这里要注意的,第1部分都是像VGG、GoogleNet、ResNet之类的基础分类网络,这些网络的计算都是所有RoIs共享的,在一张图片测试的时候只需要进行一次前向计算即可。而对于第2部分的RoI-wise subnetwork,它却不是所有RoIs共享的,因为这一部分的作用就是“给每个RoI进行分类和回归”,所以当然不能共享计算。那么现在问题就处在这里,首先第1部分的网络具有“位置不敏感性”,而如果我们将一个分类网络比如ResNet的所有卷积层都放置在第1部分用来提取特征,而第2部分则只剩下全连接层,这样的目标检测网络是“位置不敏感的translation-invariance”,所以其检测精度会较低,并且也白白浪费了分类网络强大的分类能力(does not match the network's superior classification accuracy)。而ResNet论文中为了解决这样的位置不敏感的缺点,做出了一点让步,即将RoI Pooling Layer不再放置在ResNet-101网络的最后一层卷积层之后而是放置在了“卷积层之间”,这样RoI Pooling Layer之前和之后都有卷积层,并且RoI Pooling Layer之后的卷积层不是共享计算的,它们是针对每个RoI进行特征提取的,所以这种网络设计,其RoI Pooling Layer之后就具有了“位置敏感性translation-variance”,但是这样做牺牲了测试速度,因为所有RoIs都要经过若干层卷积计算,测试速度会很慢。
那么到底怎么办?要精度还是要速度?R-FCN的回答是:都要!!!
网络设计
position-sensitive score map
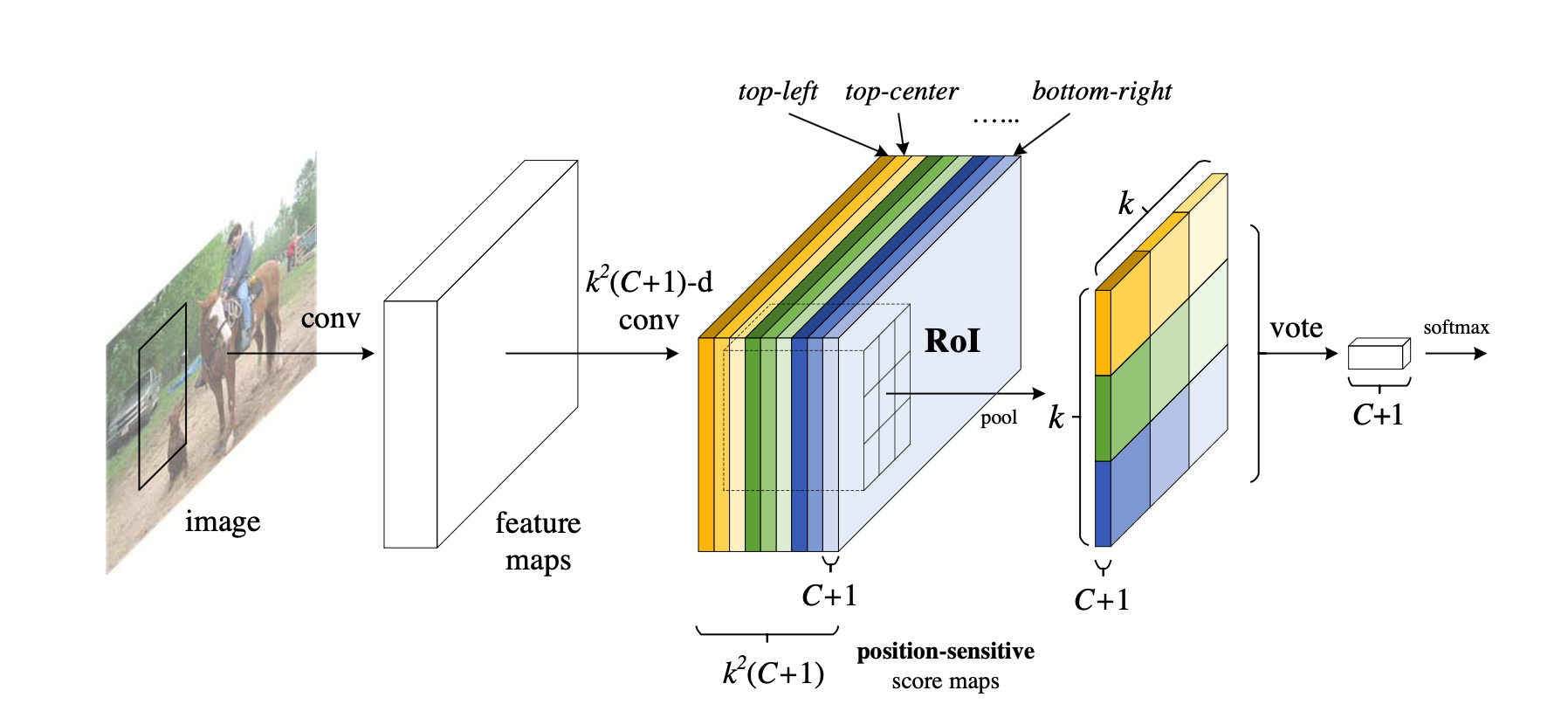
这张图就是R-FCN的网络结构图,其主要设计思想就是“位置敏感得分图position-sensitive score map”。现在就对着这张图来解释其设计思路。如果一个RoI含有一个类别c的物体,那么作者将该RoI划分为 \(k\times k\) 个区域,分别表示该物体的各个部位,比如假设该RoI中含有人这个物体,k=3,那么就将“人”划分为了9个子区域,top-center区域毫无疑问应该是人的头部,而bottom-center应该是人的脚部,而将RoI划分为\(3\times3\) 个区域是希望这个RoI在其中的每一个区域都应该含有该类别c的物体的各个部位,即如果是人,那么RoI的top-center区域就必须含有人的头部。而当这所有子区域都含有各自对应的该物体的相应部位后,那么分类器才会将该RoI判断为该类别。物体的各个部位和RoI的这些子区域是“一一映射”的对应关系。
现在我们知道了一个RoI必须是\(k\times k\)个子区域都含有该物体的相应部位,才能判断该RoI属于该物体,如果该物体的很多部位都没有出现在相应的子区域中,那么就判断该RoI为背景类别。那么现在的问题就是“网络如何判断一个RoI的\(k\times k\)个子区域都含有相应部位呢?就是“判断RoI子区域是否含有物体的相应部位”。这就是position-sensitive score map设计的核心思想了。R-FCN会在共享卷积层的最后再接上一层卷积层,而该卷积层就是“位置敏感得分图position-sensitive score map”,该score map是什么意义呢?首先它就是一层卷积层,它的height和width和共享卷积层的一样,但是它的channels=\(k^2(C+1)\),如上图所示。那么C表示物体类别种数再加上1个背景类别,每个类别都有\(k^2\)个score maps。现在我们先只针对其中的一个类别来讨论,假设是人这个类别,那么其有\(k^2\)个score maps,每一个score map表示“原图image中的哪些位置含有人的某个一个部位”,而该score map会在含有“该score map对应的人体的某个部位”的位置有“高响应值”,也就是说每一个score map都是用来“描述人体的其中一个部位出现在该score map的何处,而在出现的地方就有高响应值”。既然是这样,那么我们只要将RoI的各个子区域对应到“属于人的每一个score map”上然后获取它的响应值不就好了。但是要注意,由于各score map都是只属于“一个类别的一个部位”的,所以RoI的第\(i\)个子区域一定要到第\(i\)张score map上去找对应区域的响应值,因为RoI的第\(i\)的子区域需要的部位和第\(i\)张score map关注的部位是一样的。那么现在该RoI的\(k \times k\)个子区域都已经分别到“属于人的\(k^2\)个score maps”上找到其响应值了,那么如果这些响应值都很高,那么就证明该RoI是人呀~对吧。不过,当然这有点不严谨,因为我们只是在“属于人的\(k^2\)个score maps”上找响应值,我们还没有到属于其它类别的score maps上找响应值呢,万一该RoI的各个子区域在属于其它类别的上的score maps的响应值也很高,那么该RoI就也有可能属于其它类别呢?是吧,万一2个类别的物体本身就长的很像呢?所以呢,当然就是看那个类别的响应值更高了。
Position-sensitive RoI pooling
上一部分,我们只是简单的讲了下“RoI的\(k\times k\) 个子区域在各个类别的score maps上找到其每个子区域的响应值”,我们并没有详细讲这个“找到”是如何“找”的呢?这就是这一部分的“位置敏感RoI池化操作了(Position-sensitive RoI pooling)”,字面意思理解就是“池化操作是位置敏感的”,现在就来解释“池化操作是怎么个位置敏感法”。
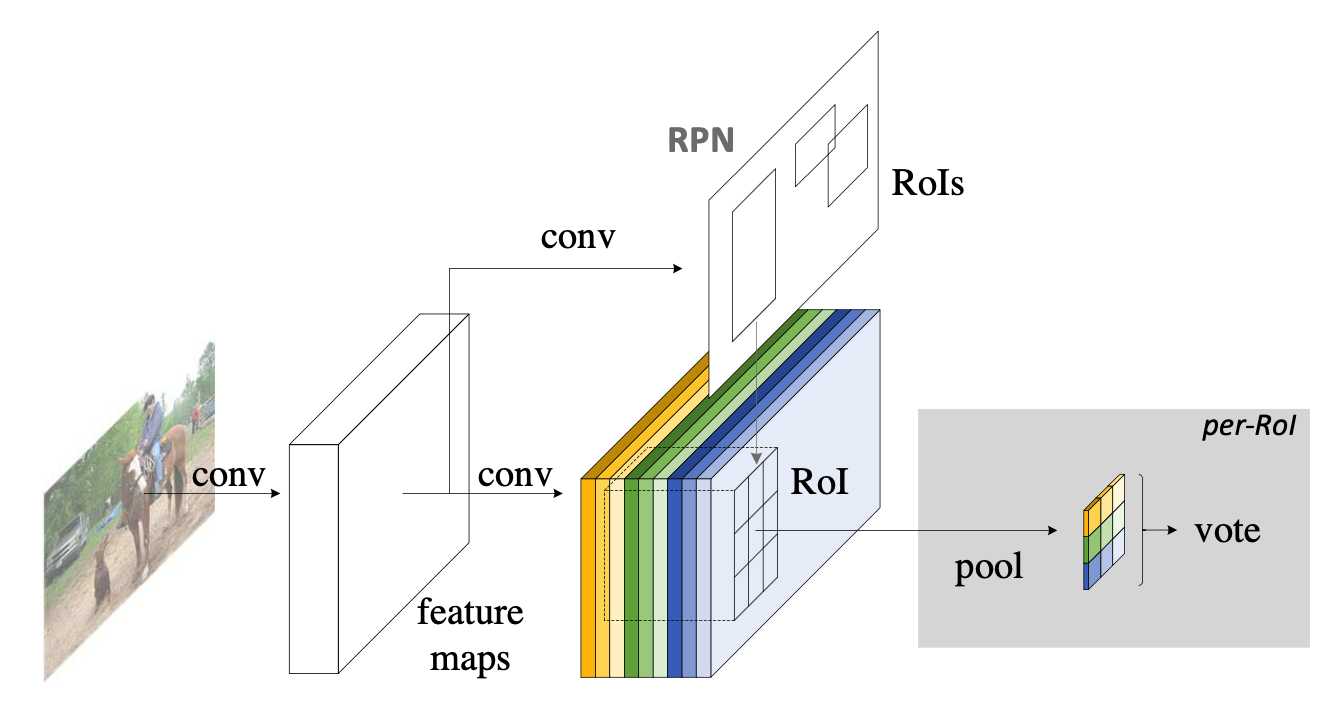
看这图,通过RPN提取出来的RoI区域,其是包含了“坐标、长宽”的4值属性的,也就是说不同的RoI区域能够对应到score map的不同位置上,而一个RoI会分成 \(k\times k\) 个bins(也就是子区域。每个子区域bin的长宽分别是 \(\frac{h}{k}\)和 \(\frac{w}{k}\) ),每个bin都对应到score map上的某一个区域(上图已经很明显的画出来了)。那么好既然该RoI的每个bin都对应到score map上的某一个子区域,那么池化操作就是在该bin对应的score map上的子区域执行,且执行的是平均池化。我们在上一部分已经讲了,第 \(i\) 个bin应对在第 \(i\) 个score map上找响应值,那么也就是在第 \(i\) 个score map上的“该第 \(i\) 个bin对应的位置”上进行池化操作,且池化是取“bin这个范围内的所有值的平均值”。并且由于有 \(C+1\)个类别,所以每个类别都要进行相同方式的池化。(下面的公式就是池化操作的计算方式)
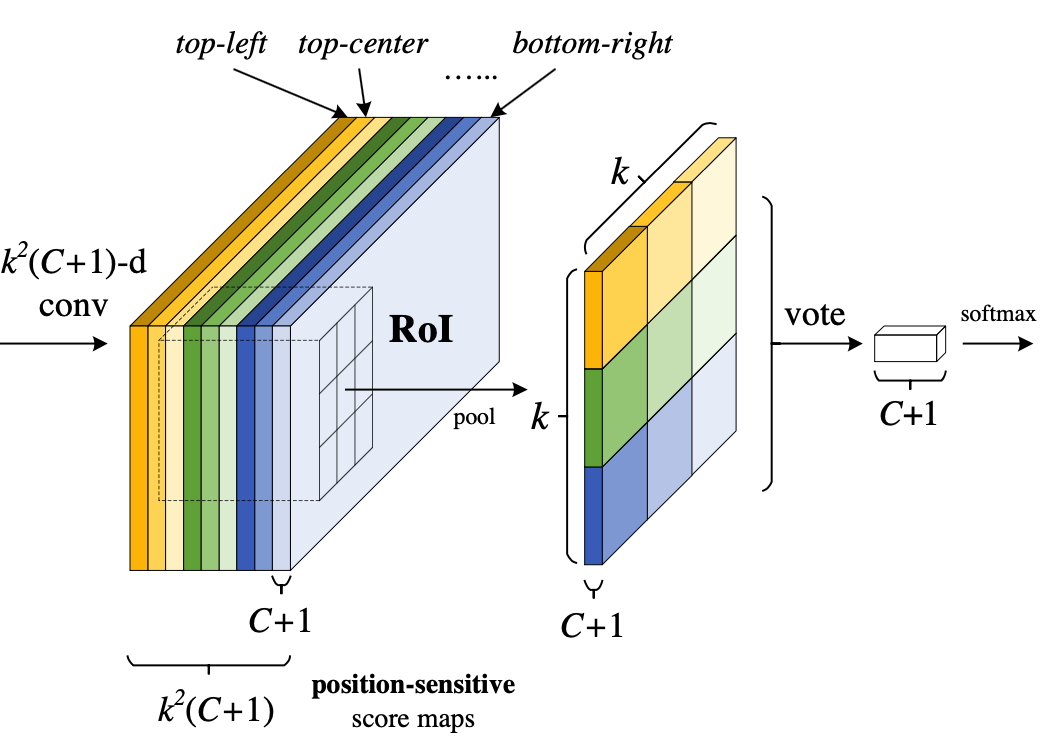
和Faster R-CNN中的ROI Pooling一样要对9个小区域分别进行pooling,要注意的是R-FCN中9个小区域并不是在所有\(k^2 * (C+1)\)维度上都做pooling,每个小区域只会在对应的(C+1)个维度上作pooling,比如ROI左上角的区域就在前C+1个维度上pooling,左中位置的区域就在\(C+2\)到\(2C+2\)间的维度上作pooling,以此类推。pooling后输出的是C+1维度的\(k*k\) 数据,每个维度上的\(k*k\)个数据再加到一起(上图的vote过程)形成C+1个单点数据,就代表了C+1个类别的分类概率。
那么一共有 \(C+1\) 个scores,那么将这 \(C+1\) 个数使用简单的softmax函数就可以得到属于各个类别的概率了(注意,这里不需要使softmax分类器了,只需要使用简单的softmax函数,因为这里就是通过简单的比大小来判断最终的类别的,下图的2个公式已经写的很清楚了)。
对于目标定位的输出和上面的分类输出过程类似,只是维度不再是\(k^2 * (C+1)\),而是\(k^2*4\),表示9个小区域的[dx,dy,dw,dh]4个偏移坐标。
理解难点1:平移不变性和平移可变性
作者在论文中提到了两个概念,平移不变性(translation invariance)和平移可变性(translation variance)。平移不变性比较好理解,在用基础的分类结构比如ResNet、Inception给一只猫分类时,无论猫怎么扭曲、平移,最终识别出来的都是猫,输入怎么变形输出都不变这就是平移不变性,网络的层次越深这个特性会越明显。平移可变性则是针对目标检测的,一只猫从图片左侧移到了右侧,检测出的猫的坐标会发生变化就称为平移可变性。当卷积网络变深后最后一层卷积输出的feature map变小,物体在输入上的小偏移,经过N多层pooling后在最后的小feature map上会感知不到,这就是为什么原文会说网络变深平移可变性变差。
再来看个Faster R-CNN + ResNet-101结构的例子。如果在Faster R-CNN中没有ROI层,直接对整个feature map进行分类和位置的回归,由于ResNet的结构较深,平移可变性较差,检测出来的坐标会极度不准确。如果在ResNet中间(图1 conv4与conv5间)加个ROI层结果就不一样了,ROI层提取出的proposal中,有的对应前景label,有的对应背景label,proposal位置的偏移就有可能造成label分类(前景和背景分类)的不同。偏移后原来的前景很有可能变成了背景,原来的背景很有可能变成了前景,换句话说分类loss对proposal的位置是敏感的,这种情况ROI层给深层网络带来了平移可变性。如果把ROI加到ResNet的最后一层(图1 conv5后)结果又是怎样呢?conv5的第一个卷积stride是2,造成conv5输出的feature map更小,这时proposal的一个小偏移在conv5输出上很有可能都感知不到,即proposal对应的label没有改变,所以conv5后虽然有ROI也对平移可变性没有什么帮助,识别出来的位置准确度会很差。
论文中作者给了测试的数据:ROI放在ResNet-101的conv5后,mAP是68.9%;ROI放到conv5前(就是标准的Faster R-CNN结构)的mAP是76.4%,差距是巨大的,这能证明平移可变性对目标检测的重要性。
理解难点2:Position-sensitive score map为什么会带来平移可变性
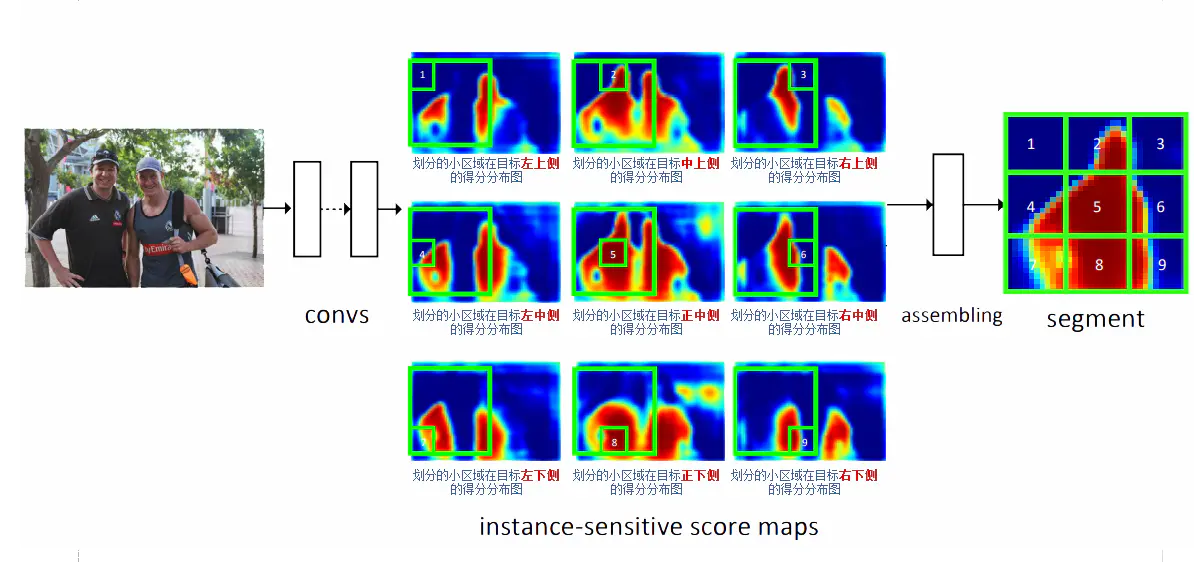
Position-sensitive score map的概念最早来自另一篇实例分割的论文Instance-sensitive Fully Convolutional Networks 。下图是示意图,中间的9张图对应Position-sensitive score map的9个维度的输出。拿左上角的图说明:它的每一个点代表该点正好出现在目标左上角的概率(更准确的说应该是得分,因为还没做softmax),也可以理解是该点右下方正好是目标的概率。要注意的是:“目标左上角的概率”的概念并不局限于图中画的绿色框范围,而是整张图上的每一个点,这是新学习者很容易引起误解的地方。同理其余8张图各自对应了目标正上侧、右上侧、左中侧、正中侧、右中侧、左下侧、正下侧、右下侧的概率。在训练时,一个ROI的9个小区域从每张图的对应区域去Pooling出一个结果,组成新的图(下图右侧的9宫格图),如果ROI刚好覆盖ground truth,这个新的区域就标记为前景(label=1)。
这里有个关键点要解释,为什么每张图都能携带相对位置信息?因为从图3提取1~9号小方格时,每个小方格在每张图上的位置并不相同,而是在上下左右方向上有偏移,当组合出来的9宫格对应ground truth时,小方格1就对应了 ground truth左上角的位置,小方格2对应了ground truth正上方的位置,依此类推,所以用这种9宫格训练目标时就有了相对目标位置的信息在里面 。