k1.5—CoT强化训练
概述
Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。
- 问题设定
给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\),其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\),目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\),每个 \(z_i\) 是解决问题的重要中间步骤。
当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\)。
- 强化学习目标
基于真实答案 \(y^*\),分配一个值 \(r(x, y, y^*) \in \{0, 1\}\), Kimi k1.5使用奖励模型 \(r\) 来评估给定问题 \(x\) 的提出答案 \(y\) 的正确性。
给定一个问题 \(x\),模型 \(\pi_\theta\) 生成CoT和最终答案:\(z \sim \pi_\theta(\cdot|x)\),\(y \sim \pi_\theta(\cdot|x, z)\)。生成的CoT质量通过它是否能导致正确的最终答案来评估。总结起来,考虑以下目标来优化策略:
策略优化方法
在线策略镜像下降(Online Policy Mirror Descent)
Kimi k1.5应用了在线策略镜像下降的变体作为训练算法。该算法迭代执行。在第 \(i\) 次迭代中,使用当前模型 \(\pi_{\theta_i}\) 作为参考模型,优化以下相对熵正则化的策略优化问题:
其中 \(\tau > 0\) 是控制正则化程度的参数.
这个目标有一个闭式解:
其中 \(Z = \sum_{y',z'} \pi_{\theta_i}(y', z'|x) \exp(r(x, y', y^*)/\tau)\) 是归一化因子。
对两边取对数,我们得到对于任何 \((y, z)\),以下约束成立,这允许我们在优化过程中利用off-policy数据:
这启发了以下代理损失:
为了近似 \(\tau \log Z\),使用样本 \((y_1, z_1), ..., (y_k, z_k) \sim \pi_{\theta_i}\):
研究发现,使用采样奖励的经验均值 \(\bar{r} = \text{mean}(r(x, y_1, y^*), ..., r(x, y_k, y^*))\) 可以产生有效的实际结果。最终,通过取代理损失的梯度来得出学习算法。对于每个问题 \(x\),使用参考策略 \(\pi_{\theta_i}\) 采样 \(k\) 个响应,梯度为:
与传统策略梯度方法的相似性与区别
对于熟悉策略梯度方法的人来说,Kimi k1.5的梯度公式看起来类似于使用采样奖励均值作为基线的策略梯度方法((2))。然而,存在两个主要区别:
- off-policy 采样:响应是从参考策略 \(\pi_{\theta_i}\) 采样的,而不是从当前策略(on-policy)采样。这是一个重要的区别,因为传统的策略梯度方法通常是on-policy,即使用当前策略生成样本。
- L2正则化:应用了L2正则化,这增加了优化的稳定性。
因此,Kimi k1.5 的方法可以被视为将常规的 on-policy 正则化策略梯度算法自然扩展到off-policy情况。他们从数据集D中采样一批问题,并将参数更新为 \(\theta_{i+1}\),该参数随后作为下一次迭代的参考策略。由于每次迭代由于参考策略的变化而考虑不同的优化问题,他们也在每次迭代开始时重置优化器。
另外,Kimi k1.5在训练系统中排除了价值网络,这一设计选择在之前的研究中也有应用。虽然这显著提高了训练效率,但研究人员也提出了一个假设:传统使用价值函数进行信用分配在经典强化学习中的方法可能不适合他们的上下文。
为了说明这一点,他们提供了一个具体场景:
- 假设模型已经生成了部分思维链(CoT) \((z_1, z_2, ..., z_t)\),现在面临两个潜在的下一步推理:\(z_{t+1}\) 和 \(z'_{t+1}\)。
- 假设 \(z_{t+1}\) 直接导致正确答案,而 \(z'_{t+1}\) 包含一些错误。
- 如果有一个理想的价值函数,它会指示 \(z_{t+1}\) 比 \(z'_{t+1}\) 具有更高的价值。
- 根据标准的信用分配原则,选择 \(z'_{t+1}\) 会受到惩罚,因为它相对于当前策略具有负面优势。
然而,研究人员认为,探索 \(z'_{t+1}\) 对于训练模型生成长CoT实际上非常有价值。通过使用从长CoT得出的最终答案的合理性作为奖励信号,只要模型成功恢复并达到正确答案,就可以从取 \(z'_{t+1}\)中学习试错模式。从这个例子中得出的关键是,我们应该鼓励模型探索不同的推理路径,以增强其解决复杂问题的能力。这种探索性方法产生了丰富的经验,支持关键规划技能的发展。我们的主要目标不仅限于在训练问题上获得高准确性,而是专注于为模型提供有效的问题解决策略,最终提高其在测试问题上的性能。
总结一下K1.5的强化框架:
- off-policy 学习框架:通过从参考策略采样并应用L2正则化,扩展了传统策略梯度方法。
- 无价值网络设计:不使用价值网络进行信用分配,而是鼓励探索多样化推理路径,即使这些路径可能包含错误。这种方法有助于模型学习更复杂的推理策略,包括试错和恢复能力。
这种设计理念反映了一个更广泛的哲学:在复杂推理任务中,探索和多样性比短期奖励最大化更重要,因为它们能够培养更强大的问题解决能力。
独特优势
- 长上下文扩展
Kimi k1.5将上下文窗口扩展到128k,观察到随着上下文长度的增加,性能持续提升。一个关键思想是使用部分展开(Partial Rollouts)来提高训练效率——通过重用大量以前的轨迹来对新轨迹进行采样,从而避免从头开始重新生成新轨迹的成本。
- 简化框架
长上下文扩展结合改进的策略优化方法,建立了一个简化的RL框架。由于能够扩展上下文长度,学习的CoT表现出规划、反思和修正的特性。增加上下文长度有增加搜索步骤数量的效果。因此,无需依赖更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型,就能实现强大的性能。
- 长度惩罚
Kimi k1.5引入了长度奖励来限制响应长度的快速增长,从而提高模型的token效率。给定问题 \(x\) 的 \(k\) 个采样响应 \((y_1, z_1), ..., (y_k, z_k)\),令 \(len(i)\) 为 \((y_i, z_i)\) 的长度,\(min\_len = \min_i len(i)\) 且 \(max\_len = \max_i len(i)\)。如果 \(max\_len = min\_len\),则所有响应的长度奖励设为零。否则,长度奖励为:
其中 \(\lambda = 0.5 - \frac{len(i) - min\_len}{max\_len - min\_len}\)。
从上面这个式子可以看出是提倡较短的回答,并在正确的回答中惩罚较长的回答,同时明确惩罚回答不正确的较长的回答。然后,这个基于长度的奖励会用一个 weighting 参数添加到原始奖励中。 在作者的初步实验中,长度惩罚可能会减慢初始阶段的训练速度。为了缓解这个问题,作者建议在训练期间逐渐预热长度惩罚。具体来说,采用标准策略优化,没有长度惩罚,然后对其余训练进行恒定长度惩罚。
Long2short
虽然长思维链(Long-CoT)模型能够实现强大的性能,但与标准的短思维链(Short-CoT)大语言模型相比,它在测试时消耗更多的令牌(tokens)。然而,通过将长思维链模型的思考先验知识转移到短思维链模型,即使在有限的测试时间令牌预算下,性能也可以得到改善。这就是所谓的"Long2Short"问题。
Kimi k1.5团队提出了几种解决Long2Short问题的方法,包括模型合并、最短拒绝采样、DPO和Long2Short强化学习。这些方法旨在保持长CoT模型的推理能力,同时提高令牌效率。
- 模型合并 (Model Merging)
模型合并被证明对维持泛化能力很有用。Kimi团队还发现,当合并长CoT模型和短CoT模型时,它在提高令牌效率方面也很有效。
具体实现方式:
优势:- 将长CoT模型与较短模型结合,无需训练即可获得新模型
- 具体来说,通过简单地平均两个模型的权重来合并它们
- 这种方法可以保留长CoT模型的推理能力,同时提高令牌效率
- 无需额外训练,实现简单
- 可以保留两种模型的优势
- 在不牺牲太多性能的情况下提高令牌效率
- 最短拒绝采样 (Shortest Rejection Sampling)
Kimi团队观察到,他们的模型对同一问题生成的响应长度变化很大。基于这一观察,他们设计了最短拒绝采样方法
具体实现方式:
优势:- 对同一问题进行n次采样(在他们的实验中,n=8)
- 从正确的响应中选择最短的一个用于监督微调
- 这种方法可以帮助模型学习更简洁的解决方案
- 保持解决问题的正确性
- 显著减少响应长度
- 提高模型在测试时的效率
- DPO (Direct Preference Optimization)
与最短拒绝采样类似,DPO方法也利用长CoT模型生成多个响应样本,但采用了偏好学习的框架。
具体实现方式:
优势:- 利用长CoT模型生成多个响应样本
- 将最短的正确解决方案选为正样本
- 将较长的响应作为负样本,包括错误的较长响应和正确的较长响应(长度为所选正样本的1.5倍)
- 这些正负样本对形成用于DPO训练的成对偏好数据
- 直接优化模型以偏好更短的正确响应
- 不需要显式的奖励模型
- 可以有效平衡正确性和简洁性
- Long2Short强化学习 (Long2Short RL)
在标准RL训练阶段之后,Kimi团队选择一个在性能和令牌效率之间提供最佳平衡的模型作为基础模型,并进行单独的long2short RL训练阶段。
具体实现方式:
优势:- 显著减少最大展开长度,进一步惩罚超过所需长度的响应,即使它们可能是正确的
- 这种方法强制模型学习更简洁的解决方案,同时保持正确性
- 直接优化令牌效率和性能之间的权衡
- 可以根据特定需求调整长度惩罚和最大展开长度
- 在保持高性能的同时实现显著的令牌节省
RL Infrastructure

Kimi k1.5系统采用了一个精心设计的迭代同步RL框架,旨在通过持续学习和适应来增强模型的推理能力。该系统的一个关键创新是引入了部分展开(Partial Rollout)技术,专门设计用于优化复杂推理轨迹的处理。
如图a所示,RL训练系统通过迭代同步方法运行,每次迭代包括展开阶段和训练阶段:
- 展开阶段:
- 由中央主控协调的展开工作器通过与模型交互生成展开轨迹
- 这些轨迹是对各种输入的响应序列
- 生成的轨迹存储在重放缓冲区中,确保训练数据的多样性和无偏性
- 重放缓冲区通过打破时间相关性来提高数据质量
- 训练阶段:
- 训练工作器访问这些经验来更新模型的权重
- 这个循环过程允许模型不断从其行动中学习,随着时间调整其策略以提高性能
- 中央主控:
- 作为中央指挥者,管理数据流和展开工作器、训练工作器、奖励模型评估和重放缓冲区之间的通信
- 确保系统和谐运行,平衡负载并促进高效的数据处理
- 训练工作流程:
- 训练工作器访问这些展开轨迹(无论是在单次迭代中完成还是跨多次迭代分割)
- 计算梯度更新以优化模型参数并提高性能
- 整个过程由奖励模型监督,评估模型输出的质量并提供必要的反馈
- 代码执行服务:
- 专门设计用于处理代码相关问题,是奖励模型的组成部分
- 在实际编程场景中评估模型的输出
- 通过验证模型的解决方案与实际代码执行对比,这个反馈循环对于优化模型的策略至关重要
- 确保模型的学习与现实世界的编程挑战紧密对齐
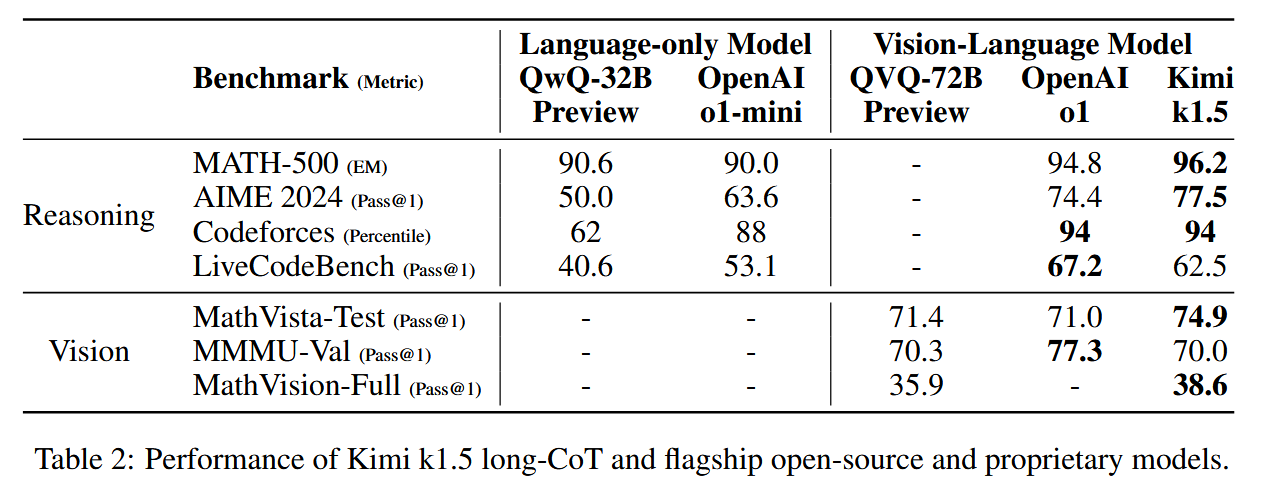
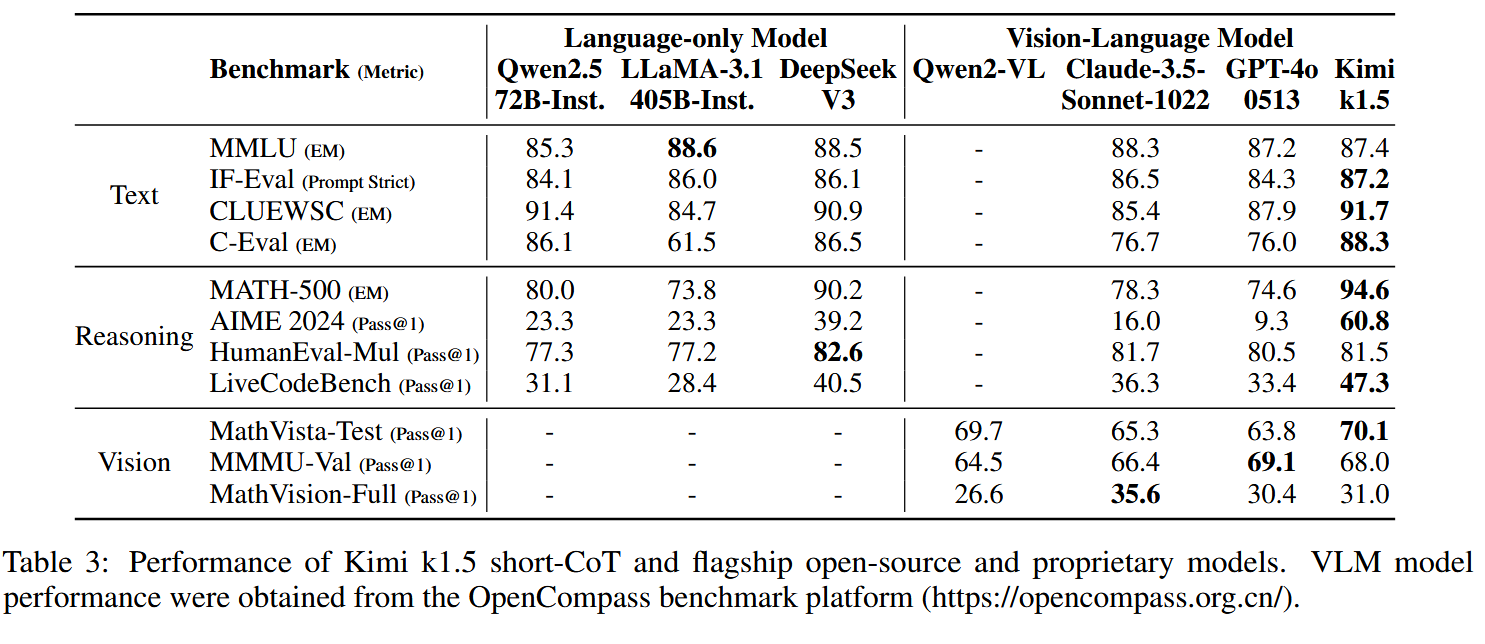
实验结果