Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce 和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。具体参考官方教程。
Hadoop架构

- HDFS: 分布式文件存储
- YARN: 分布式资源管理
- MapReduce: 分布式计算
- Others: 利用YARN的资源管理功能实现其他的数据处理方式
内部各个节点基本都是采用Master-Woker架构
Hadoop HDFS
架构
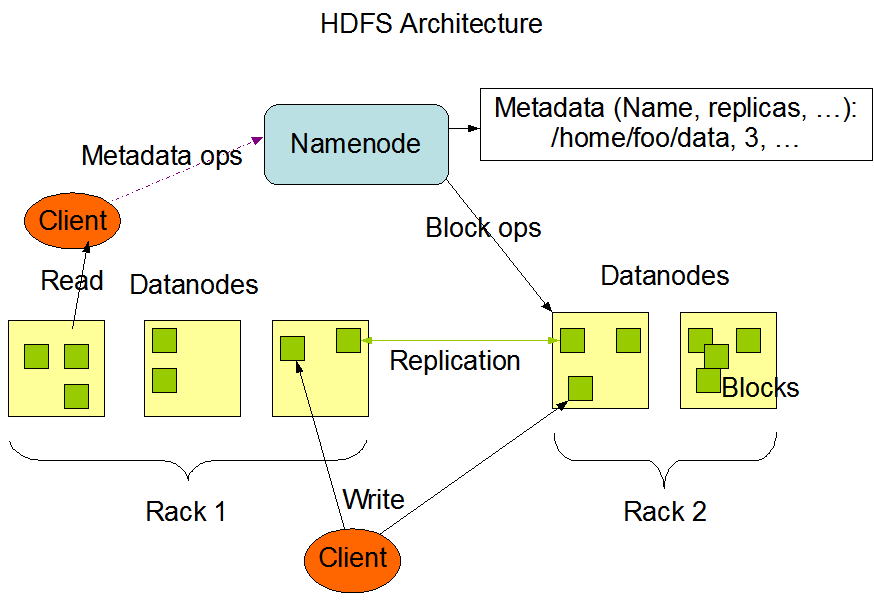
- Block数据块;
- NameNode
- Secondary NameNode
- DataNode
Hadoop YARN
旧的MapReduce架构
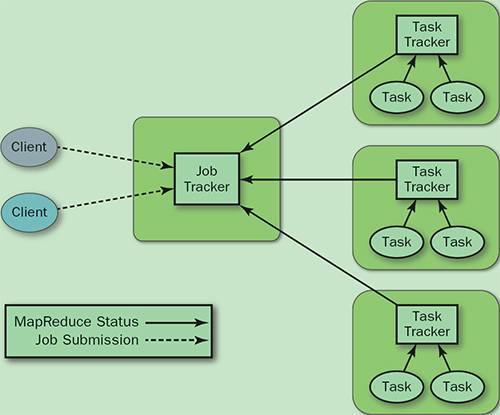
- JobTracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- TaskTracker: 加载或关闭任务,定时报告任务状态
此架构会有以下问题:
- JobTracker 是 MapReduce 的集中处理点,存在单点故障
- JobTracker 完成了太多的任务,造成了过多的资源消耗,当 MapReduce job 非常多的时候,会造成很大的内存开销。这也是业界普遍总结出老 Hadoop 的 MapReduce 只能支持 4000 节点主机的上限
- 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM
- 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot , 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就集群资源利用的问题
总的来说就是单点问题和资源利用率问题
YARN架构
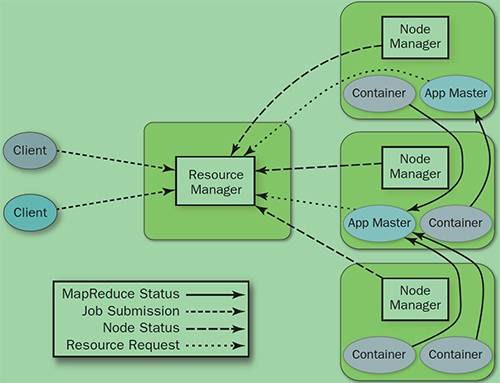
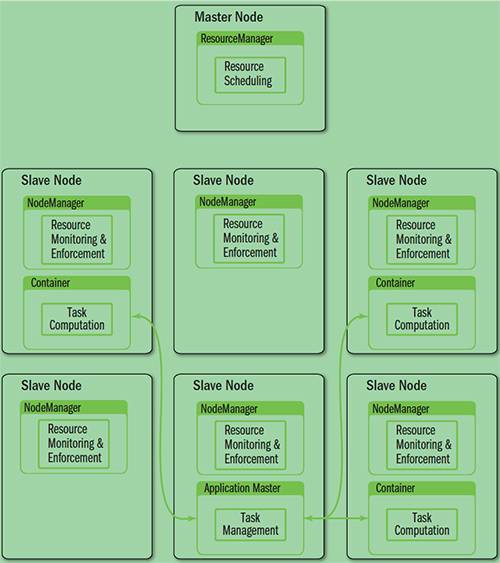
YARN就是将 JobTracker 的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:一个全局的资源管理和一个每个作业的管理(ApplicationMaster) ResourceManager 和 NodeManager 提供了计算资源的分配和管理,而 ApplicationMaster 则完成应用程序的运行
- ResourceManager: 全局资源管理和任务调度
- NodeManager: 单个节点的资源管理和监控
- ApplicationMaster: 单个作业的资源管理和任务监控
- Container: 资源申请的单位和任务运行的容器
Containner
容器(Container)这个东西是 Yarn 对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn 对资源的管理也是用到了这种思想。
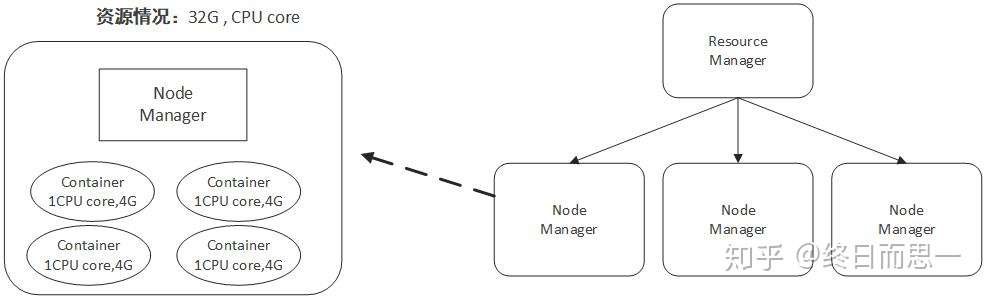
如上所示,Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器由 NodeManager 启动和管理,并被它所监控。
- 容器被 ResourceManager 进行调度。
NodeManager 和 ResourceManager 这两个组件会在下面讲到。
三个主要组件
再看最上面的图,我们能直观发现的两个主要的组件是 ResourceManager 和 NodeManager ,但其实还有一个 ApplicationMaster 在图中没有直观显示。我们分别来看这三个组件。
ResourceManager
我们先来说说上图中最中央的那个 ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,整个系统有且只有一个 RM ,来负责资源的调度。它也包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当 Client 提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
- 应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理 Client 用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
ApplicationMaster
每当 Client 提交一个 Application 时候,就会新建一个 ApplicationMaster 。由这个 ApplicationMaster 去与 ResourceManager 申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
NodeManager
NodeManager 是 ResourceManager 在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler 提供这些资源使用报告。
提交一个 Application 到 Yarn 的流程
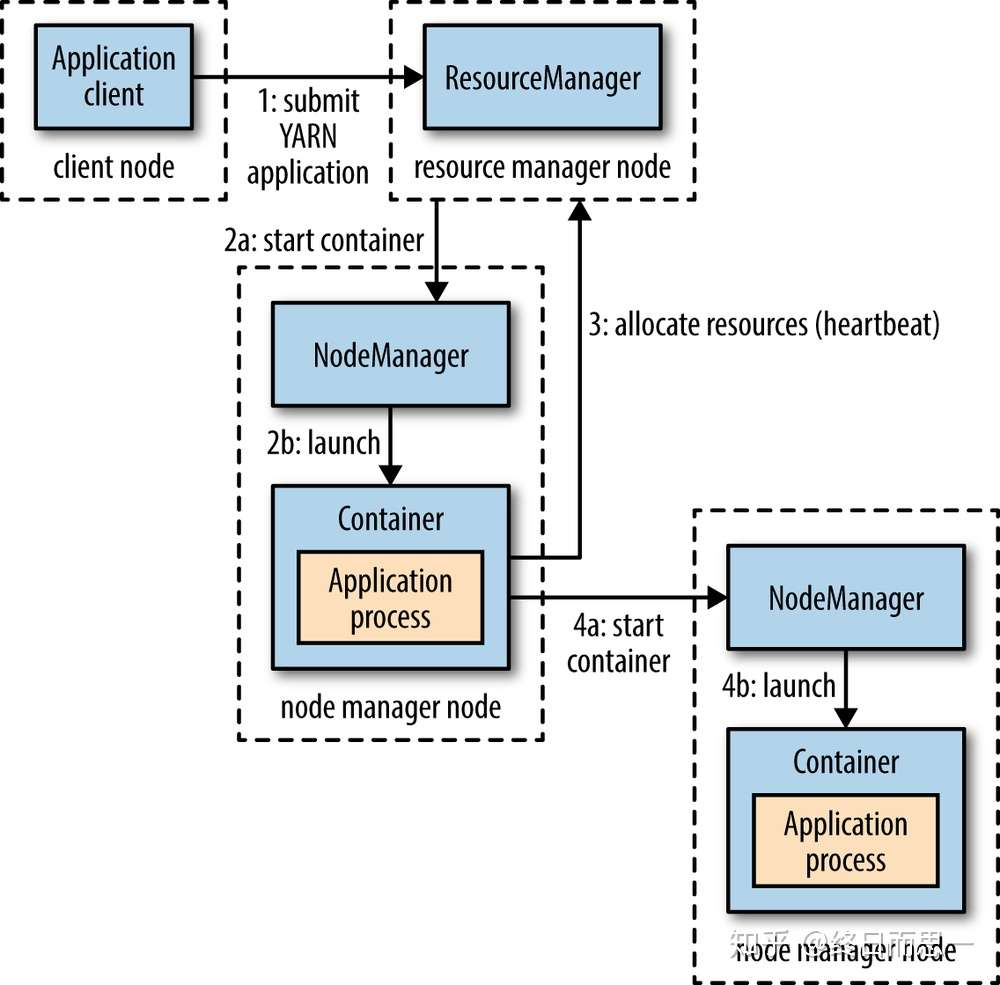
这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
- Client 向 Yarn 提交 Application,这里我们假设是一个 MapReduce 作业。
- ResourceManager 向 NodeManager 通信,为该 Application 分配第一个容器。并在这个容器中运行这个应用程序对应的 ApplicationMaster。
- ApplicationMaster 启动以后,对 作业(也就是 Application) 进行拆分,拆分 task 出来,这些 task 可以运行在一个或多个容器中。然后向 ResourceManager 申请要运行程序的容器,并定时向 ResourceManager 发送心跳。
- 申请到容器后,ApplicationMaster 会去和容器对应的 NodeManager 通信,而后将作业分发到对应的 NodeManager 中的容器去运行,这里会将拆分后的 MapReduce 进行分发,对应容器中运行的可能是 Map 任务,也可能是 Reduce 任务。
- 容器中运行的任务会向 ApplicationMaster 发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster 再向 ResourceManager 注销并释放容器资源。
以上就是一个作业的大体运行流程。
Hadoop Map/Reduce
概述
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统(HDFS)是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(job configuration)。然后,Hadoop的 job client提交作业(jar包/可执行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给job-client。
虽然Hadoop框架是用Java实现的,但Map/Reduce应用程序则不一定要用 Java来写。
什么是Map和什么是Reduce
Map的本质实际上是拆解,比如说有辆红色的小汽车,有一群工人,把它拆成零件了,这就是Map。
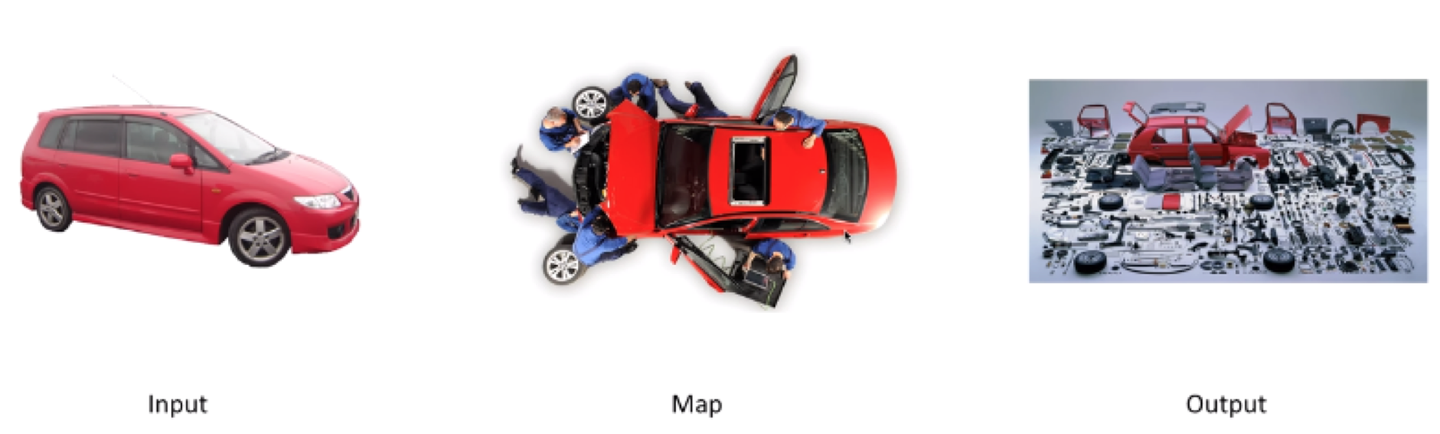
那什么是Reduce呢?Reduce就是组合,我们有很多汽车零件,还有很多其他各种装置零件,把他们一阵拼装,变成变形金刚,这就是Reduce。

什么是MapReduce
统合来看,MapReduce就是你有很多各种各样的蔬菜水果面包(Input),有很多厨师,不同的厨师分到了不同的蔬菜水果面包,自己主动去拿过来(Split),拿到手上以后切碎(Map),切碎以后给到不同的烤箱里,冷藏机里(Shuffle),冷藏机往往需要主动去拿,拿到这些东西存放好以后会根据不同的顾客需求拿不同的素材拼装成最终的结果,这就是Reduce,产生结果以后会放到顾客那边等待付费(Ticket),这个过程是Finalize。
所以MapReduce是六大过程,简单来说:Input, Split, Map, Shuffle, Reduce, Finalize。
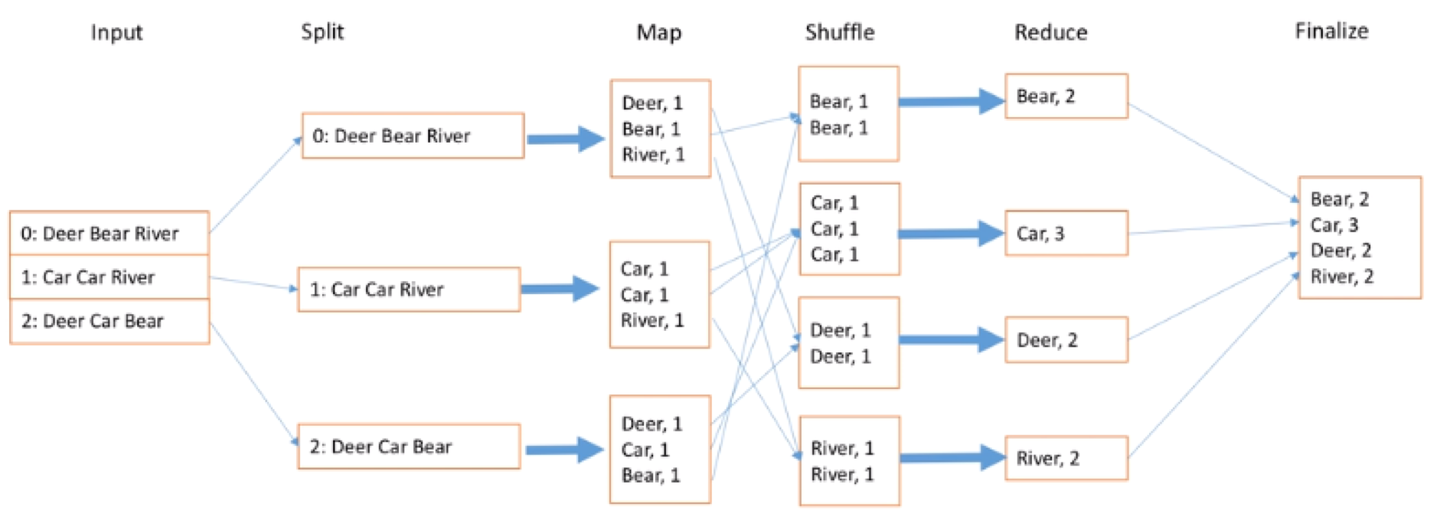
那如何统计1TB或1PB文件里的单词数呢?
我们输入很多文档,文档的每一行有很多不同的单词,我们找不同的worker拿到自己手上,就是Split过程,那怎么切分呢?每一行文档就切分成单词和它出现的次数,每次出现的次数是1,就写1。接下来Shuffle就是把不同的单词继续放到同样的盒子里面,Bear放一起,Car放一起,这可以由Shuffle写的时候算法来决定。当然现在很多智能都不用做了,有时候还需要随机采样的方式来实现。等到这个结果以后,最后一步Reduce,就是把相同的数据放一起,比如Car有3个就写3,River是2个就写2,最后再放到一起,这样便于提供服务,得到最终结果。大家可以看到最后箭头指过来是乱序的,也就是说这个执行过程实际上是高度并行的,也不用等待每个都完成,所以说这是一个很好的优化过程。
写一下代码是怎样的呢?

Map输入每一行的ID是key,value是这一行的单词。有这个结果以后就可以统计每个单词出现的次数。Reduce输入的还是各个单词,但后面跟的是一个串,是在里面出现的次数,1,1,1,我们把1加到一起就是sum的过程,这就是MapReduce的整个过程。输出我们的关键词和它的出现次数。
MapReduce怎么建立倒排索引?
首先输入很多的文档,这里面每一行不是文档编号了,我们要存它的文档编号。拆解的时候我们加入新的概念,Worker,这里有三个Worker,每个Worker负责1行,当然有很多数据时每个Worker可以负责多行,每个Worker就需要进行Map拆解,把每个单词都拆成单词和出现的文档ID。接着Shuffle有两个新Worker,他们把单词一拆,一部分交个Worker4,一部分交给Worker5,让他们去前面拿数据,拿到以后会排个序,这也是最基本的Shuffle过程。接着就是Reduce,把相同的东西合并到一起去,比如food出现在两个文档里,就是0和2。最终就是把这些结果放到一起去就可以让我们查找了。
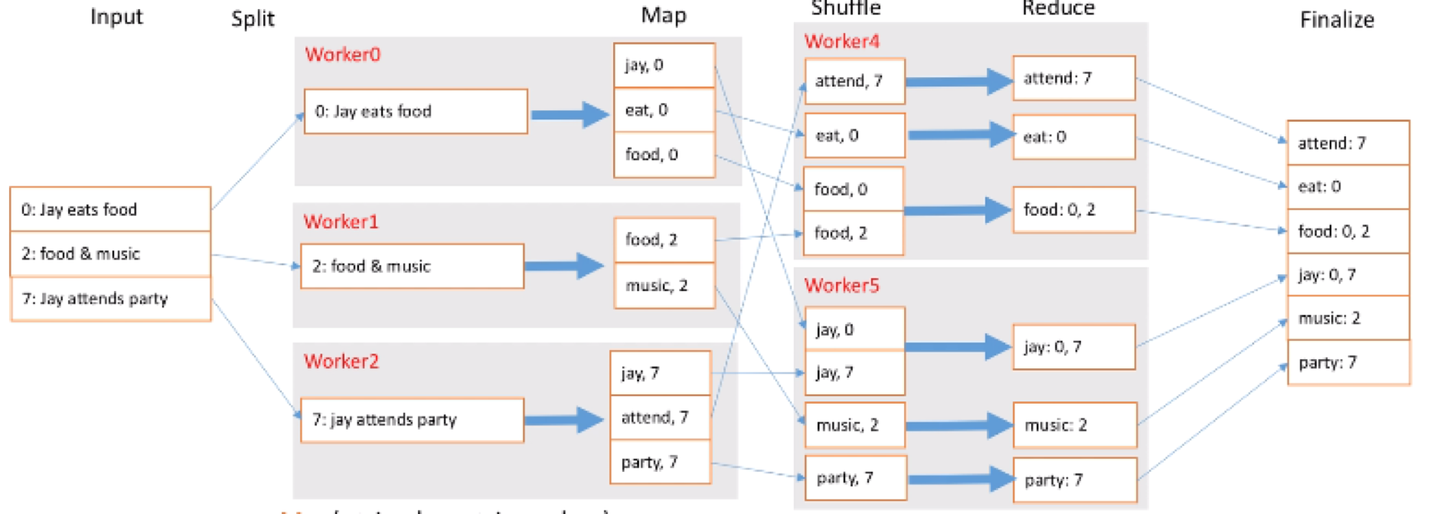
那什么是倒排索引?倒排索引就是每个单词出现在哪些文档里,这样就能快速检索。最终外部输入每行文档的ID及内容,我们可以把它拆解成单词出现在哪个文档里。Reduce过程输入是每个关键词key,输出是key出现在哪些文档里就放到一起。

MapReduce架构是什么呢?
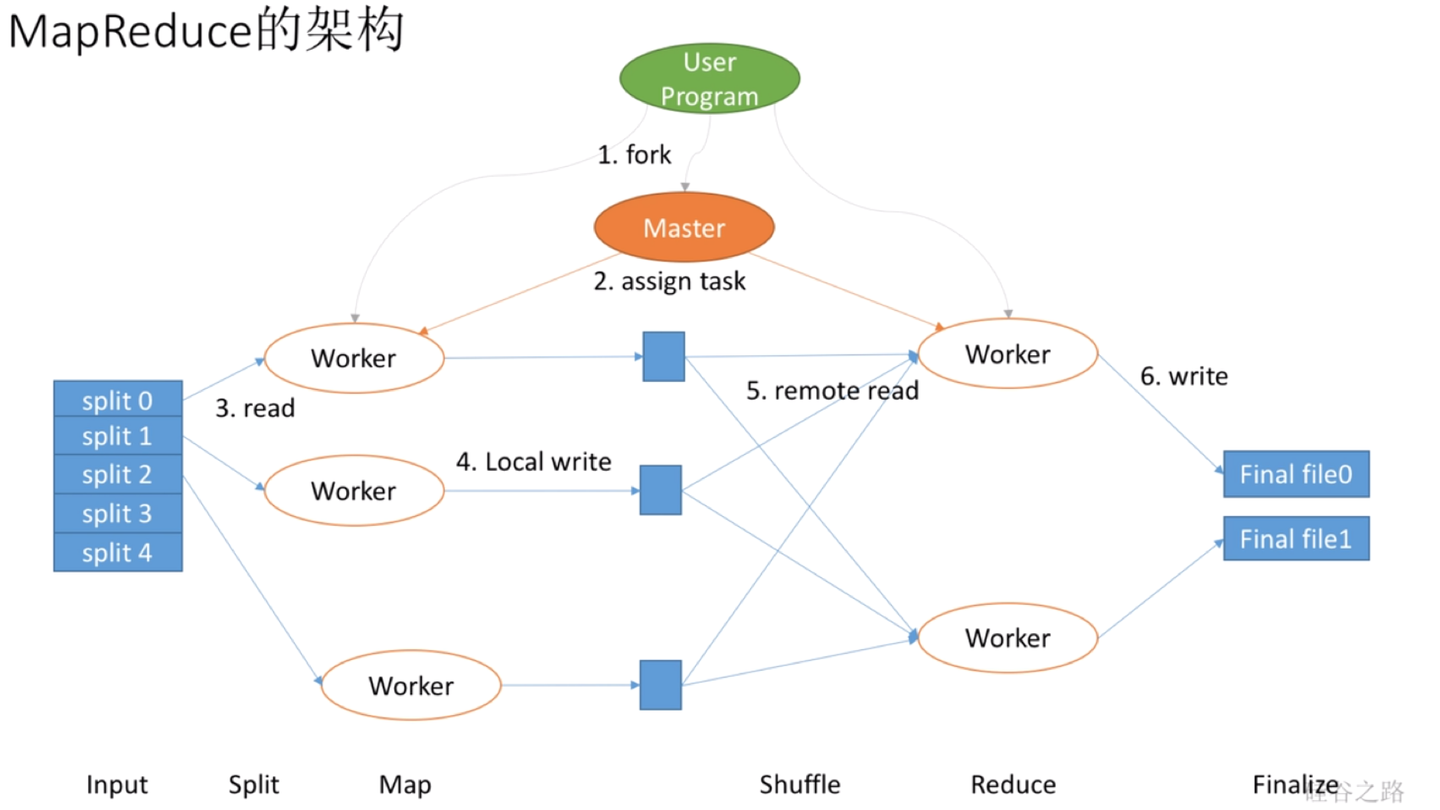
首先,我们有用户进程,它需要协调或者定义我们程序怎么运行,当然它不是自己运行,实际上它会先想数据有多少,需要拆解成多少个Mapper,多少个Reducer去做。比如要找5个Mapper去做,就会把数据拆成5份,这样会产生出很多很多Worker,会有Map Worker和Reduce Worker。但最重要的是还会产生一个Master Worker,这个和其他Worker等级是一样的,只不过会做一些特殊事情,它会作为用户的代理来协调整个过程,用户就可以做其他事情。Master Worker会让这个Worker去拿0号数据,一个Worker负责拿1号数据等等,这就是分配数据的过程。每个Worker会在本地把数据切分开吧,写到本地的缓存或者硬盘上行。前面Map Worker做完了,Master让Reduce Worker去拿数据,他们就会从各个Worker里拿到本地需要的数据,在本地做完Reduce以后将结果写到最终的文件里就是Finalize。实际上,这个过程可以看到第一步切数据是Input,第二步是Map拿数据Split,第三步自己切分就是Map,第四步Reduce去拿数据是Shuffle,第五步Reducer自己去做数据的整合是Reduce,第六步输出结果Finalize。
总结:
MapReduce本质就是分治法
会刷题也要学会解决生活中的真实问题,成为一个真正解决问题成长的人。
MapReduce六大过程:来洋葱、拿洋葱、切洋葱、放洋葱、拼洋葱、送洋葱