Motivation
我们知道object detection的算法主要可以分为两大类:two-stage detector和one-stage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。
既然有了出发点,那么就要找one-stage detector的准确率不如two-stage detector的原因,作者认为原因是:样本的类别不均衡导致的。我们知道在object detection领域,一张图像可能生成成千上万的candidate locations,但是其中只有很少一部分是包含object的,这就带来了类别不均衡。那么类别不均衡会带来什么后果呢?引用原文讲的两个后果:
- training is inefficient as most locations are easy negatives that contribute no useful learning signal;
- en masse, the easy negatives can overwhelm training and lead to degenerate models.
什么意思呢?负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。其实先前也有一些算法来处理类别不均衡的问题,比如OHEM(online hard example mining),OHEM的主要思想可以用原文的一句话概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples。OHEM算法虽然增加了错分类样本的权重,但是OHEM算法忽略了容易分类的样本。
因此针对类别不均衡问题,作者提出一种新的损失函数:focal loss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。为了证明focal loss的有效性,作者设计了一个dense detector:RetinaNet,并且在训练时采用focal loss训练。实验证明RetinaNet不仅可以达到one-stage detector的速度,也能有two-stage detector的准确率。
Focal Loss
介绍focal loss,在介绍focal loss之前,先来看看交叉熵损失,这里以二分类为例,原来的分类loss是各个训练样本交叉熵的直接求和,也就是各个样本的权重是一样的。公式如下:
为了简化上式,定义 \(p_t\),
因此,\(CE(p,y)=CE(p_t)=-log(p_t)\)
接下来介绍一个最基本的对交叉熵的改进,也将作为本文实验的baseline,既然one-stage detector在训练的时候正负样本的数量差距很大,那么一种常见的做法就是给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定\(a\)的值来控制正负样本对总的loss的共享权重。“\(α ∈ [0, 1]\) for class 1 and 1 − α for class −1”.
显然前面的公式虽然可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重,于是就有了focal loss:
当正负例难以区分的时候,\(p_t\)较小,此时loss权重趋近于1;反之,当较好区分时,\(p_t\)较大,相对的权重就会趋近于0。 其中\(\gamma\)为调制系数(modulating factor)平滑地调整了易分类样本的权重。
绘制图看如下,横坐标是\(p_t\),纵坐标是loss。\(CE(p_t)\)表示标准的交叉熵公式,\(FL(p_t)\)表示focal loss中用到的改进的交叉熵。图中\(γ=0\)的蓝色曲线就是标准的交叉熵损失。
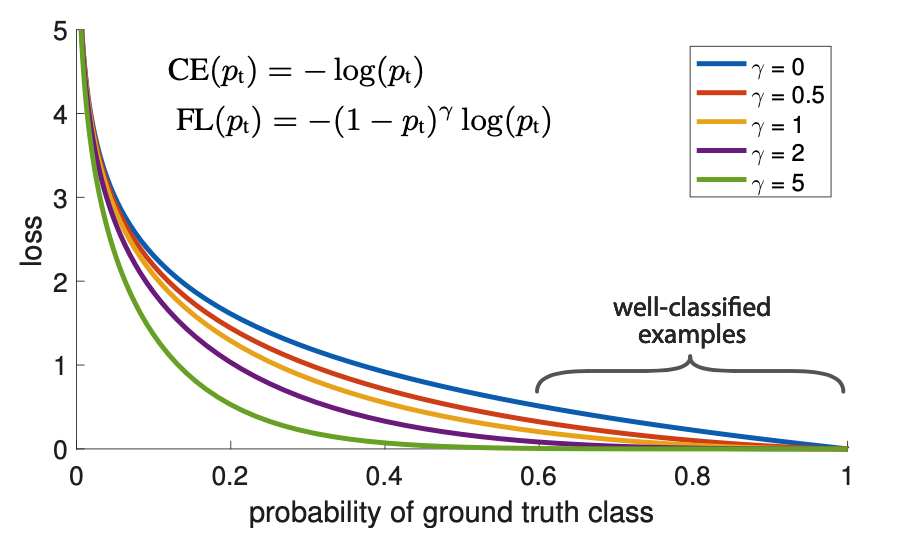
结合两个公式,最终的focal loss 形式如下
RetinaNet
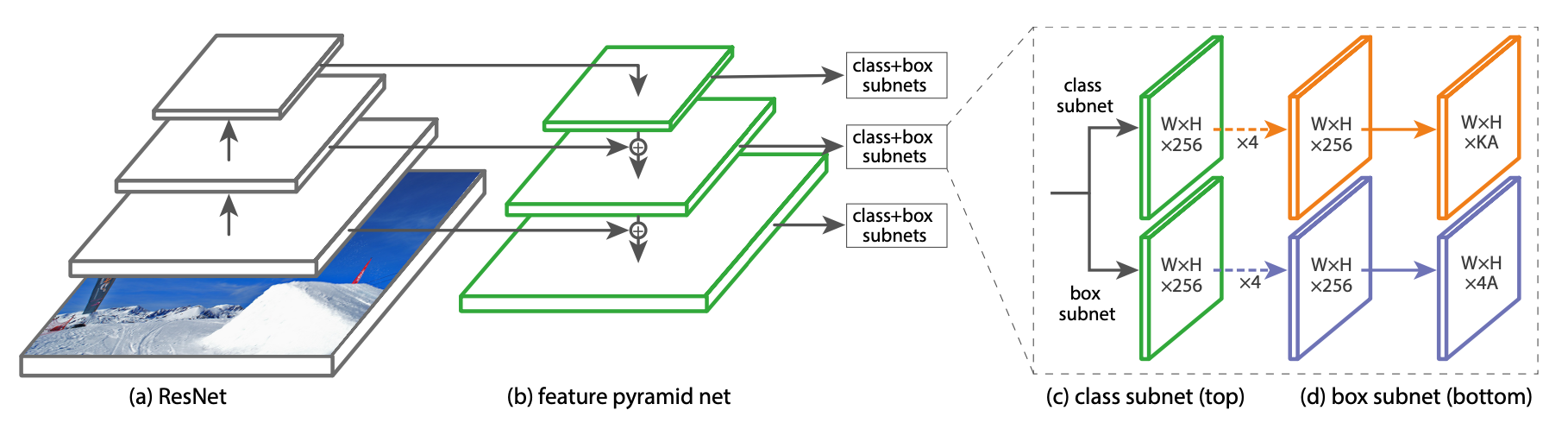
Feature Pyramid Network Backbone
采用的是Resnet+FPN作为backbone,如上图(a)和(b),自底向上分为P3到P7, (Pl 代表着比原图分辨率缩小 \(2^l\) )
Anchors
作者用了translation-invariant anchor boxes 平移不变锚与RPN的变体相似。设置anchor从P3到P7有相应的 \(32^2\) 到 \(512^2\) 的区域。对于每层,有A=9个anchor,穿过这些层,它们可以覆盖32-813个输入图片中的像素。每个Anchor最终学习一个K个分类目标的one-hot向量(K是目标类别数)和4维的box regression目标。作者设定:anchor与ground-truth 的IoU>0.5分配为该目标,IOU \(\in\)[0,0.4)的为背景 。每个anchor最多分配一个目标。
Classification Subnet:
分类子网络在每个空间位置的A个anchor和K个类别,预测object 存在的概率。整个子网络采用的是FCN(全卷积网络),与FPN中的每层相接,每层的网络参数共享。最后用sigmoid激活函数对于每个空间位置,输出 KA 个binary预测。与RPN对比,作者的object classification子网络更深,只用 3*3 卷积,且不和box regression子网络共享参数。作者发现这种higer-level设计决定比超参数的特定值要重要。
Box Regression Subnet:
与object classification子网络平行,作者在金字塔每层都接一个小的FCN上,意图回归每个anchor box对邻近ground truth object的偏移量。回归子网络的设计和分类相同,不同的是它为每个空间位置输出4A个线性输出。对于每个空间位置的A个anchor,4个输出预测anchor和ground-truth box的相对偏移。与现在大多数工作不同的是,作者用了一个class-agnostic bounding box regressor,这样能用更少的参数更高效。Object classification和bounding box regression两个网络共享一个网络结构,但是分别用不同的参数。
Initialization:
这里有点特殊。在RetinaNet子网中,除最后一层外,所有新的conv层均使用 \(b=0\) 的偏差初始化,并且使用 \(\sigma=0.01\) 的高斯权重填充。对于分类子网的最后一个conv层,我们将偏差初始化设置为 \(b=-log((1-\pi)/\pi)\) (偏置值的计算是配合最后的激活函数来推),使得训练初期的前景置信度输出为\(π=0.01\),即认为大概率都是背景。这样背景就会输出很小的loss,前景会输出很大的loss,从而阻止背景在训练前期产生巨大的干扰loss。
效果和结论
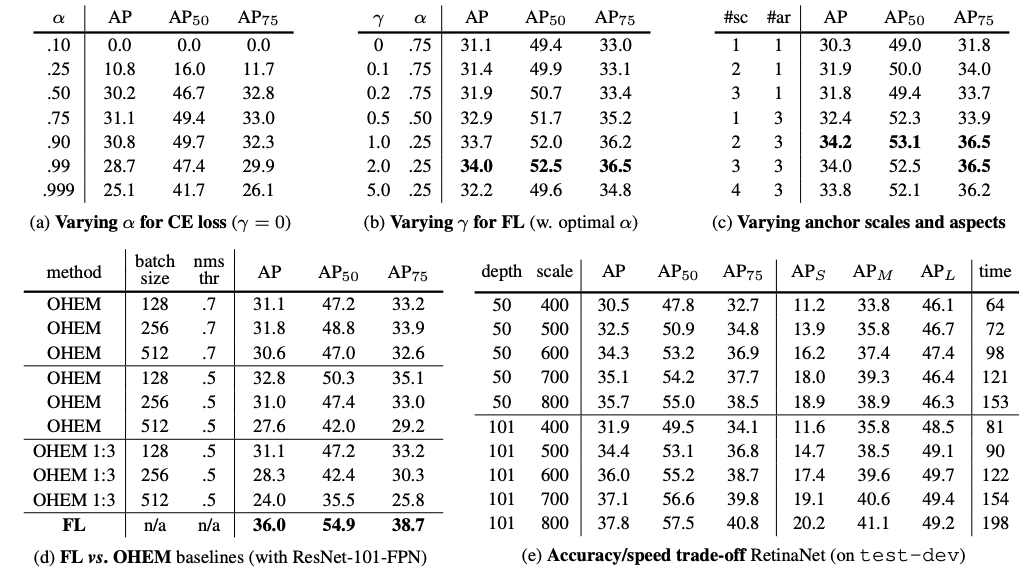
一些对比实验,总之就是效果很好。
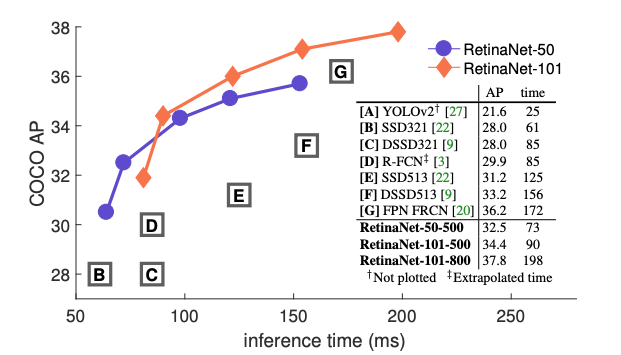
性能上的:
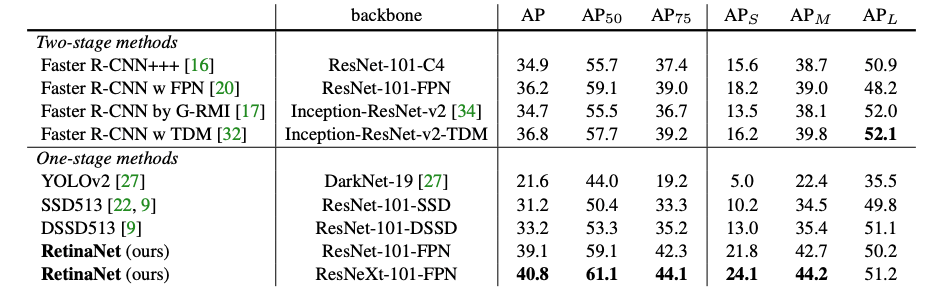
速度上的: