Quick Start
一个最简单的DDP Pytorch例子!
环境准备
PyTorch(gpu)>=1.5,python>=3.6
推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。
# Dockerfile# Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
# FROM nvcr.io/nvidia/pytorch:20.03-py3代码
单GPU代码
## main.py文件
import torch
# 构造模型
model = nn.Linear(10, 10).to(local_rank)
# 前向传播
outputs = model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
# 后向传播
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.step()
## Bash运行
python main.py加入DDP的代码
## main.py文件
import torch
# 新增:
import torch.distributed as dist
# 新增:从外面得到local_rank参数import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
# 新增:DDP backend初始化torch.cuda.set_device(local_rank)
dist.init_process_group(backend='nccl') # nccl是GPU设备上最快、最推荐的后端# 构造模型device = torch.device("cuda", local_rank)
model = nn.Linear(10, 10).to(device)
# 新增:构造DDP modelmodel = DDP(model, device_ids=[local_rank], output_device=local_rank)
# 前向传播outputs = model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
# 后向传播optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.step()
# Bash运行
# 改变:使用torch.distributed.launch启动DDP模式,
# 其会给main.py一个local_rank的参数。这就是之前需要"新增:从外面得到local_rank参数"的原因python -m torch.distributed.launch --nproc_per_node 4 main.pyDDP的基本原理
大白话原理
假如我们有N张显卡,
- (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。
- (Ring-Reduce加速)在模型训练时,各个进程通过一种叫Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度;
- (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
是不是很简单呢?
与DP模式的不同
那么,DDP对比Data Parallel(DP)模式有什么不同呢?
DP模式是很早就出现的、单机多卡的、参数服务器架构的多卡训练模式,在PyTorch,即是:
model = torch.nn.DataParallel(model)在DP模式中,总共只有一个进程(受到GIL很强限制)。master节点相当于参数服务器,其会向其他卡广播其参数;在梯度反向传播后,各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。这种参数更新方式,会导致master节点的计算任务、通讯量很重,从而导致网络阻塞,降低训练速度。
但是DP也有优点,优点就是代码实现简单。要速度还是要方便。
DDP为什么能加速?
本节对上面出现的几个概念进行一下介绍,看完了你就知道为什么DDP这么快啦!
Python GIL
GIL是个很捉急的东西,如果大家有被烦过的话,相信会相当清楚。如果不了解的同学,可以自行百度一下噢。这里简要介绍下其最大的特征(缺点):Python GIL的存在使得,一个python进程只能利用一个CPU核心,不适合用于计算密集型的任务。使用多进程,才能有效率利用多核的计算资源。
而DDP启动多进程训练,一定程度地突破了这个限制。
Ring-Reduce梯度合并
Ring-Reduce是一种分布式程序的通讯方法。
- 因为提高通讯效率,Ring-Reduce比DP的parameter server快。
- 详细的介绍:ring allreduce和tree allreduce的具体区别是什么?
简单说明

- 各进程独立计算梯度。
- 每个进程将梯度依次传递给下一个进程,之后再把从上一个进程拿到的梯度传递给下一个进程。循环n次(进程数量)之后,所有进程就可以得到全部的梯度了。
- 可以看到,每个进程只跟自己上下游两个进程进行通讯,极大地缓解了参数服务器的通讯阻塞现象!
并行计算
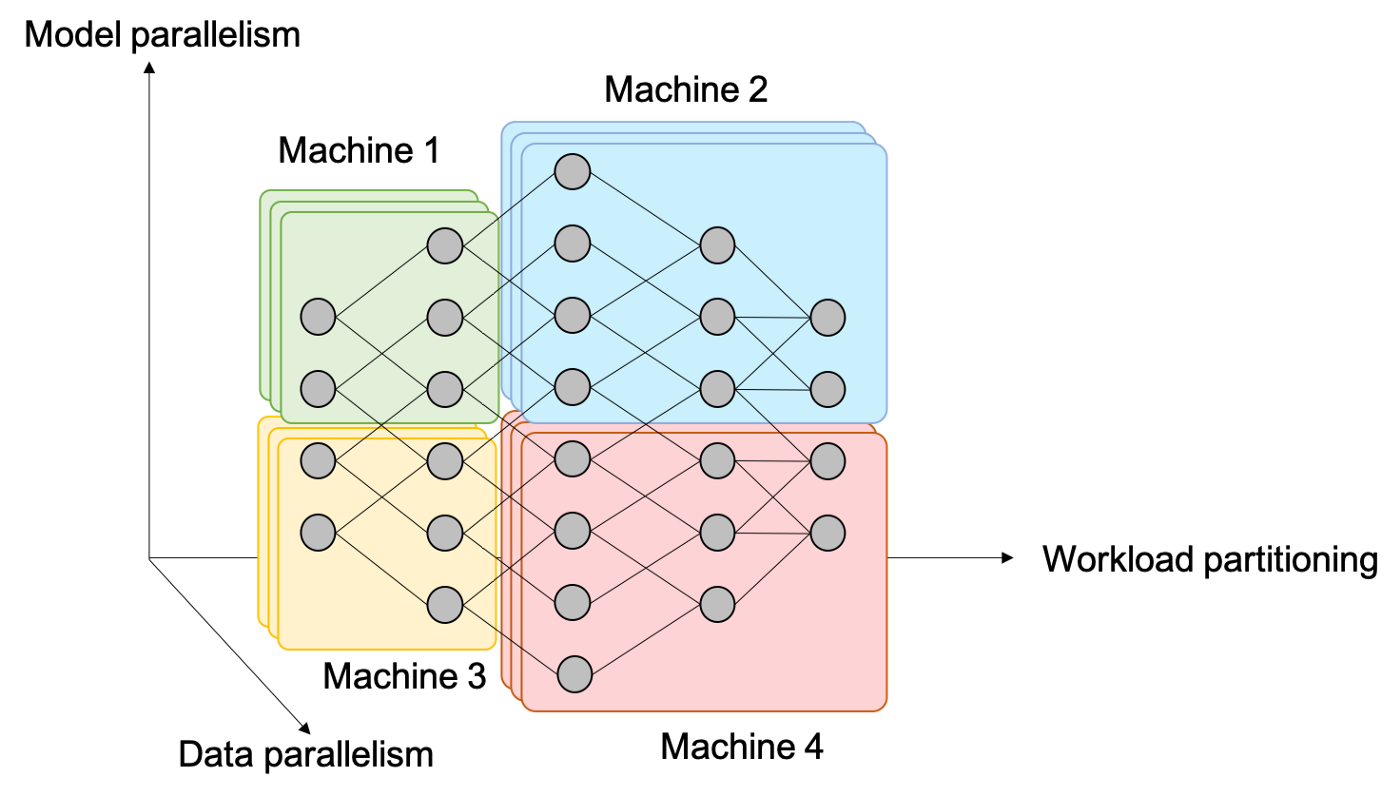
统一来讲,神经网络中的并行有以下三种形式:
- Data Parallelism
- 这是最常见的形式,通俗来讲,就是增大batch size。
- 平时我们看到的多卡并行就属于这种。比如DP、DDP都是。这能让我们方便地利用多卡计算资源。
- 能加速。
- 这是最常见的形式,通俗来讲,就是增大batch size。
- Model Parallelism
- 把模型放在不同GPU上,计算是并行的。
- 有可能是加速的,看通讯效率。
- Workload Partitioning
- 把模型放在不同GPU上,但计算是串行的。
- 不能加速。
如何在PyTorch中使用DDP
看到这里,你应该对DDP是怎么运作的,为什么能加速有了一定的了解,下面就让我们学习一下怎么使用DDP吧!
DDP模式
DDP有不同的使用模式。DDP的官方最佳实践是,每一张卡对应一个单独的GPU模型(也就是一个进程),在下面介绍中,都会默认遵循这个pattern。举个例子:我有两台机子,每台8张显卡,那就是2x8=16个进程,并行数是16。
但是,我们也是可以给每个进程分配多张卡的。总的来说,分为以下三种情况:
- 每个进程一张卡。这是DDP的最佳使用方法。
- 每个进程多张卡,复制模式。一个模型复制在不同卡上面,每个进程都实质等同于DP模式。这样做是能跑得通的,但是,速度不如上一种方法,一般不采用。
- 每个进程多张卡,并行模式。一个模型的不同部分分布在不同的卡上面。例如,网络的前半部分在0号卡上,后半部分在1号卡上。这种场景,一般是因为我们的模型非常大,大到一张卡都塞不下batch size = 1的一个模型。
在本文中,先不会讲每个进程多张卡要怎么操作,免得文章过于冗长。在这里,只是让你知道有这个东西,用的时候再查阅文档。
概念
下面介绍一些PyTorch分布式编程的基础概念。
基本概念
下面介绍一些PyTorch分布式编程的基础概念。
基本概念
在16张显卡,16的并行数下,DDP会同时启动16个进程。下面介绍一些分布式的概念。
- group 即进程组。默认情况下,只有一个组。这个可以先不管,一直用默认的就行。
- world size 表示全局的并行数,简单来讲,就是2x8=16。
# 获取world size,在不同进程里都是一样的,得到16
torch.distributed.get_world_size()- rank 表现当前进程的序号,用于进程间通讯。对于16的world sizel来说,就是0,1,2,…,15。注意:rank=0的进程就是master进程。
# 获取rank,每个进程都有自己的序号,各不相同
torch.distributed.get_rank()- local_rank 又一个序号。这是每台机子上的进程的序号。机器一上有0,1,2,3,4,5,6,7,机器二上也有0,1,2,3,4,5,6,7
# 获取local_rank。
# 一般情况下,你需要用这个local_rank来手动设置当前模型是跑在当前机器的哪块GPU上面的。
torch.distributed.local_rank()详细流程
精髓
DDP的使用非常简单,因为它不需要修改你网络的配置。其精髓只有一句话
model = DDP(model, device_ids=[local_rank], output_device=local_rank)原本的model就是你的PyTorch模型,新得到的model,就是你的DDP模型。最重要的是,后续的模型关于前向传播、后向传播的用法,和原来完全一致!DDP把分布式训练的细节都隐藏起来了,不需要暴露给用户,非常优雅!
准备工作
但是,在套model = DDP(model)之前,我们还是需要做一番准备功夫,把环境准备好的。这里需要注意的是,我们的程序虽然会在16个进程上跑起来,但是它们跑的是同一份代码,所以在写程序的时候要处理好不同进程的关系。
## main.py文件
import torch
import argparse
# 新增1:依赖
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# 新增2:从外面得到local_rank参数,在调用DDP的时候,其会自动给出这个参数,后面还会介绍。所以不用考虑太多,照着抄就是了。
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
# 新增3:DDP backend初始化
# a.根据local_rank来设定当前使用哪块GPU
torch.cuda.set_device(local_rank)
# b.初始化DDP,使用默认backend(nccl)就行。如果是CPU模型运行,需要选择其他后端。
dist.init_process_group(backend='nccl')
# 新增4:定义并把模型放置到单独的GPU上,需要在调用`model=DDP(model)`前做哦。
# 如果要加载模型,也必须在这里做哦。
device = torch.device("cuda", local_rank)
model = nn.Linear(10, 10).to(device)
# 可能的load模型...
# 新增5:之后才是初始化DDP模型
model = DDP(model, device_ids=[local_rank], output_device=local_rank)前向与后向传播
有一个很重要的概念,就是数据的并行化。我们知道,DDP同时起了很多个进程,但是他们用的是同一份数据,那么就会有数据上的冗余性。也就是说,你平时一个epoch如果是一万份数据,现在就要变成1*16=16万份数据了。那么,我们需要使用一个特殊的sampler,来使得各个进程上的数据各不相同,进而让一个epoch还是1万份数据。幸福的是,DDP也帮我们做好了!
my_trainset = torchvision.datasets.CIFAR10(root='./data', train=True)
# 新增1:使用DistributedSampler,DDP帮我们把细节都封装起来了。用,就完事儿!
# sampler的原理,后面也会介绍。
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
# 需要注意的是,这里的batch_size指的是每个进程下的batch_size。也就是说,总batch_size是这里的batch_size再乘以并行数(world_size)。
trainloader = torch.utils.data.DataLoader(my_trainset, batch_size=batch_size, sampler=train_sampler)
for epoch in range(num_epochs):
# 新增2:设置sampler的epoch,DistributedSampler需要这个来维持各个进程之间的相同随机数种子
trainloader.sampler.set_epoch(epoch)
# 后面这部分,则与原来完全一致了。
for data, label in trainloader:
prediction = model(data)
loss = loss_fn(prediction, label)
loss.backward()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.step()其他需要注意的地方
- 保存参数
# 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。
# 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。
# 2. 我只需要在进程0上保存一次就行了,避免多次保存重复的东西。if dist.get_rank() == 0:
torch.save(model.module, "saved_model.ckpt")- 理论上,在没有buffer参数(如BN)的情况下,DDP性能和单卡Gradient Accumulation性能是完全一致的。
- 并行度为8的DDP 等于 Gradient Accumulation Step为8的单卡
- 速度上,DDP当然比Graident Accumulation的单卡快;
- 但是还有加速空间。
- 如果要对齐性能,需要确保喂进去的数据,在DDP下和在单卡Gradient Accumulation下是一致的。
- 这个说起来简单,但对于复杂模型,可能是相当困难的。
调用方式
像我们在QuickStart里面看到的,DDP模型下,python源代码的调用方式和原来的不一样了。现在,需要用torch.distributed.launch来启动训练。
- 作用
- 在这里,我们给出分布式训练的重要参数:
- 有多少台机器?
- -nnodes
- 当前是哪台机器?
- -node_rank
- 每台机器有多少个进程?
- -nproc_per_node
- 高级参数(可以先不看,多机模式才会用到)
- 通讯的address
- 通讯的port
- 有多少台机器?
- 在这里,我们给出分布式训练的重要参数:
- 实现方式
- 我们需要在每一台机子(总共m台)上都运行一次
torch.distributed.launch - 每个
torch.distributed.launch会启动n个进程,并给每个进程一个-local_rank=i的参数- 这就是之前需要"新增:从外面得到local_rank参数"的原因
- 这样我们就得到\(n*m\)个进程,
world_size=n*m
- 我们需要在每一台机子(总共m台)上都运行一次
单机模式
## Bash运行# 假设我们只在一台机器上运行,可用卡数是8
python -m torch.distributed.launch --nproc_per_node 8 main.py多机模式
复习一下,master进程就是rank=0的进程。在使用多机模式前,需要介绍两个参数:
- 通讯的address
-master_address- 也就是master进程的网络地址
- 默认是:127.0.0.1,只能用于单机。
- 通讯的port
-master_port- 也就是master进程的一个端口,要先确认这个端口没有被其他程序占用了哦。一般情况下用默认的就行
- 默认是:29500
## Bash运行
# 假设我们在2台机器上运行,每台可用卡数是8
# 机器1:
python -m torch.distributed.launch --nnodes=2 --node_rank=0 --nproc_per_node 8 \
--master_adderss $my_address --master_port $my_port main.py
# 机器2:
python -m torch.distributed.launch --nnodes=2 --node_rank=1 --nproc_per_node 8 \
--master_adderss $my_address --master_port $my_port main.py小技巧
# 假设我们只用4,5,6,7号卡
CUDA_VISIBLE_DEVICES="4,5,6,7"
python -m torch.distributed.launch --nproc_per_node 4 main.py
# 假如我们还有另外一个实验要跑,也就是同时跑两个不同实验。
# 这时,为避免master_port冲突,我们需要指定一个新的。这里我随便敲了一个。
CUDA_VISIBLE_DEVICES="4,5,6,7" python -m torch.distributed.launch --nproc_per_node 4 \
--master_port 53453 main.pymp.spawn调用方式
PyTorch引入了torch.multiprocessing.spawn,可以使得单卡、DDP下的外部调用一致,即不用使用torch.distributed.launch。 python main.py一句话搞定DDP模式。
给一个mp.spawn的文档:代码文档
下面给一个简单的demo:
def demo_fn(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# lots of code....def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)mp.spawn与launch各有利弊,请按照自己的情况选用。按照笔者个人经验,如果算法程序是提供给别人用的,那么mp.spawn更方便,因为不用解释launch的用法;但是如果是自己使用,launch更有利,因为你的内部程序会更简单,支持单卡、多卡DDP模式也更简单。
在slurm集群上完成训练
如何在我们的slurm集群上完成这个初始化并进行训练,那么问题就变成了如何在slurm集群上把你分配到的ip写进程序里。两个办法:
- srun指定-n 进程总数以及 --ntasks-per-node 每个节点进程数,这样就可以通过
os.environ获得每个进程的节点ip信息,全局rank以及local rank,有了这些就可以很方便很方便的完成初始化。推荐使用该方法 - salloc,这个就相对霸道一些,直接指定几个节点自己拿来用,这样就很容易选出来通信用的节点,再随便给个端口,我们就能完成初始化。相比1还是麻烦不少。
关于获取节点信息的详细代码:
import os
os.environ['SLURM_NTASKS'] #可用作world size
os.environ['SLURM_NODEID'] #node id
os.environ['SLURM_PROCID'] #可用作全局rank
os.environ['SLURM_LOCALID'] #local_rank
os.environ['SLURM_STEP_NODELIST'] #从中取得一个ip作为通讯ip贴段差不多能跑的代码吧:
import torch
torch.multiprocessing.set_start_method('spawn')
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
import os
def dist_init(host_addr, rank, local_rank, world_size, port=23456):
host_addr_full = 'tcp://' + host_addr + ':' + str(port)
torch.distributed.init_process_group("nccl", init_method=host_addr_full,
rank=rank, world_size=world_size)
num_gpus = torch.cuda.device_count()
torch.cuda.set_device(local_rank)
assert torch.distributed.is_initialized()
rank = int(os.environ['SLURM_PROCID'])
local_rank = int(os.environ['SLURM_LOCALID'])
world_size = int(os.environ['SLURM_NTASKS'])
# get_ip函数自己写一下 不同服务器这个字符串形式不一样
# 保证所有task拿到的是同一个ip就成
ip = get_ip(os.environ['SLURM_STEP_NODELIST'])
dist_init(ip, rank, local_rank, world_size)
# 接下来是写dataset和dataloader,这个网上有很多教程
# 我这给的也只是个形式,按自己需求写好就ok
dataset = your_dataset() #主要是把这写好
datasampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size=batch_size_per_gpu, sampler=source_sampler)
model = your_model() #也是按自己的模型写
model = DistributedDataPrallel(model, device_ids=[local_rank], output_device=local_rank)
# 此后训练流程与普通模型无异照上面写好train.py之后(叫啥都行,这儿就叫train.py吧),slrum指令写这样:
# 这里是3台机器,每台机器8张卡的样子
srun -n24 --gres=gpu:8 --ntasks-per-node=8 python train.py