Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
本文主要介绍 Self-Supervised Learning 在 NLP领域的经典工作:BERT模型的原理及其变体。本文来自台湾大学李宏毅老师PPT:
https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/bert_v8.pdf
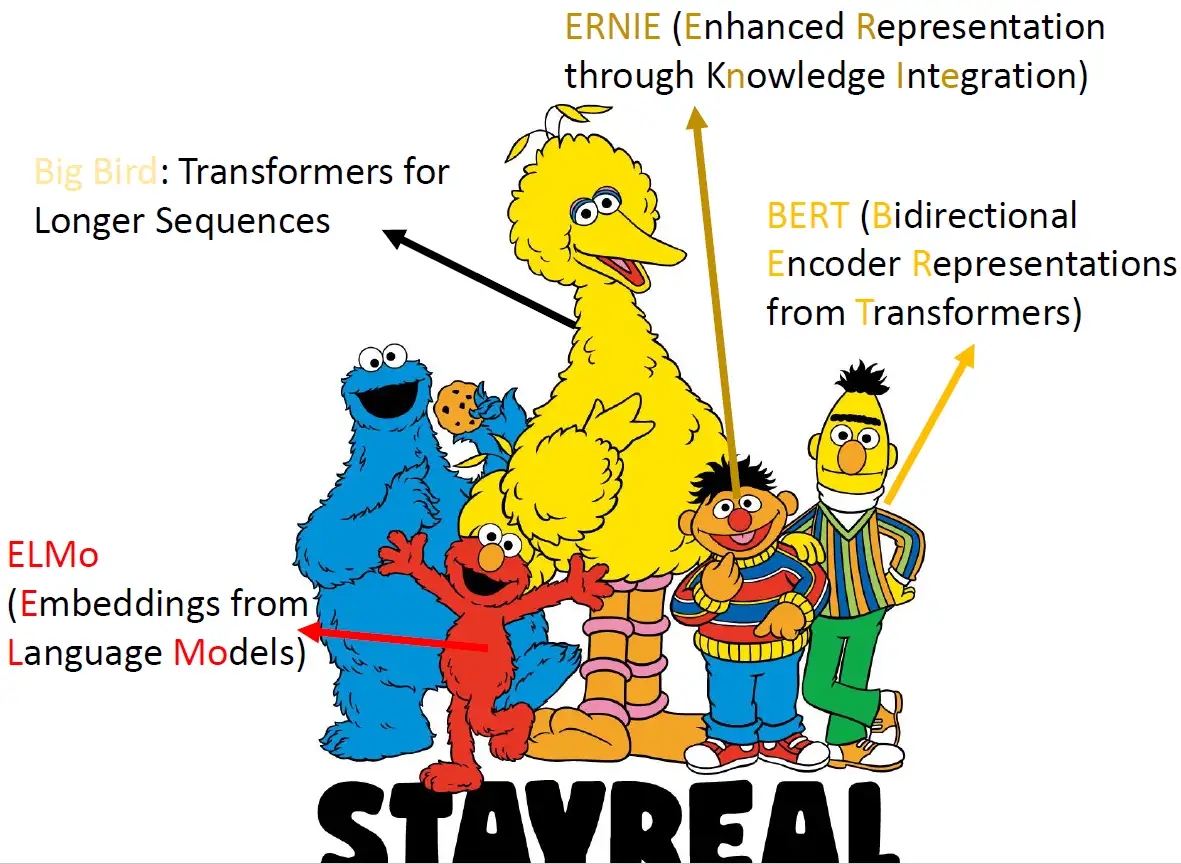
芝麻街
在介绍 Self-Supervised Learning 之前就不得不先介绍下 芝麻街。因为不知道为什么,Self-Supervised Learning的模型都是以芝麻街的人物来命名的。那么这些芝麻街的角色都是什么样的模型呢?在我们实际了解他们做的事情之前,我们先来看看他们的名字:
ELMo代表的是红色怪物,是Embedding from Language Models的缩写,它是最早的 Self-Supervised Learning的模型。后来又有了BERT (Bidirectional Encoder Representations from Transformers),是我们最耳熟能详的的 Self-Supervised Learning model。然后BERT最好的朋友是ERNIE (Enhanced Representation through Knowledge Integration),是紧接着BERT出现的模型。后来又出现了一个叫做大鸟 (Big Bird: Transformers for Longer Sequences) 的模型。
BERT这个模型的最大特点是比较大,它有340 M的参数量 (parameters),这个数值究竟有多大呢?我们可以横向对比几个数据:
最近很火的 视觉 Transformer 模型 ViT 及其变体 DeiT 模型的参数量如下表所示。但其实除了BERT之外,还有一些更大的模型,如GPT-2, GPT-3, T5等等。最近出的Switch Transformer的参数量甚至达到了1.6T,是GPT-3的近10倍,而GPT-3的参数量又是Turing NLG的10多倍。
BERT 与 Self-Supervised Learning
接下来就正式介绍什么是 Self-Supervised Learning。
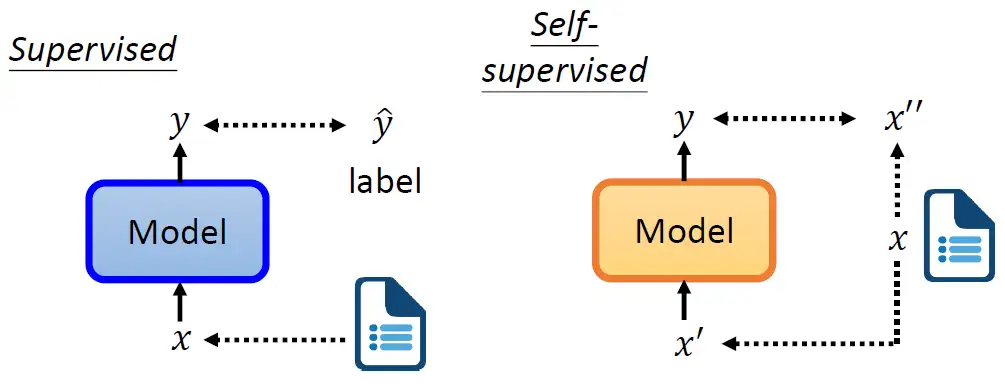
如下图所示,我们之前在做 Supervised Learning的时候,如何让model输出我们想要的 \(y\) 呢?你得要有label的资料。假设今天要做情感分析,让机器看一段文字,输出对应的情感是正面的还是负面的。那你要有一大堆文章和对应的label,才能够训练model。
那 Self-Supervised 就是在没有label的情况下自己想办法监督自己。还是同样的一堆资料 \(x\) ,我们现在把它分成2部分:\(x^{'}\) 和 \(x^{''}\) 。然后把 \(x^{'}\)输入到模型里面,让它输出 \(y\),然后我们让 \(y\) 与 \(x^{''}\) 越接近越好,这个就是Self-Supervised Learning。换言之在 Self-Supervised Learning里面输入的一部分作为了监督信号,一部分仍作为输入。
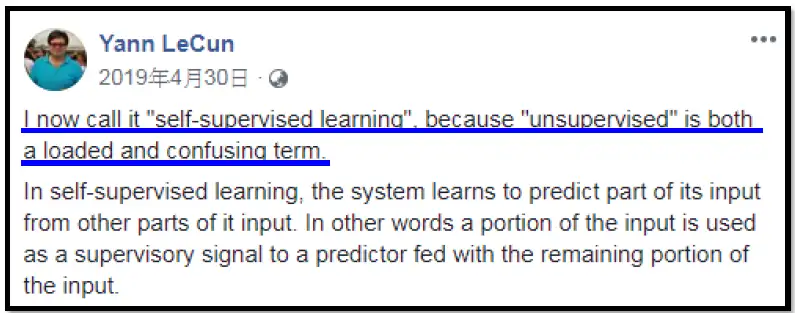
Self-Supervised Learning 这个词汇最早是Yann LeCun说的,下图是Yann LeCun于19年4月30日在Facebook上的贴文。为什么不直接叫做Unsupervised Learning呢?因为Unsupervised Learning是一个比较大的family,里面有很多不同的方法,为了突出方法的专门化,所以就叫做 Self-Supervised Learning。
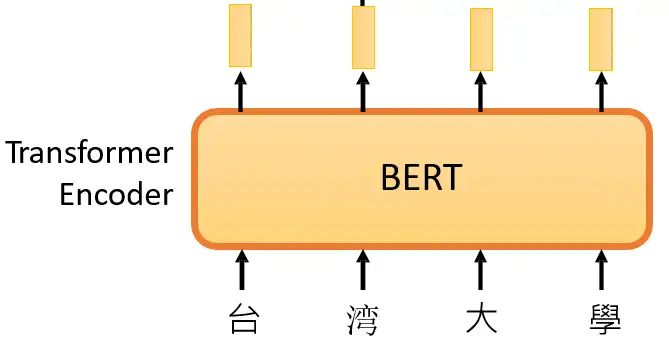
下面的问题是怎么把输入的 \(x\) 分成2部分: \(x\)′ 和 \(x\)″ 呢?我们看下面的BERT模型,它的架构就是Transformer 的 Encoder,里面有很多Self-attention,MLP,Normalization等等。
BERT可以做的事情也就是Transformer 的 Encoder 可以做的事情,就是输入一排向量,输出另外一排向量,输入和输出的维度是一致的。那么不仅仅是一句话可以看做是一个sequence,一段语音也可以看做是一个sequence,甚至一个image也可以看做是一个sequence。所以BERT其实不仅可以用在NLP上,还可以用在CV里面。所以BERT其实输入的是一段文字,如下图所示。
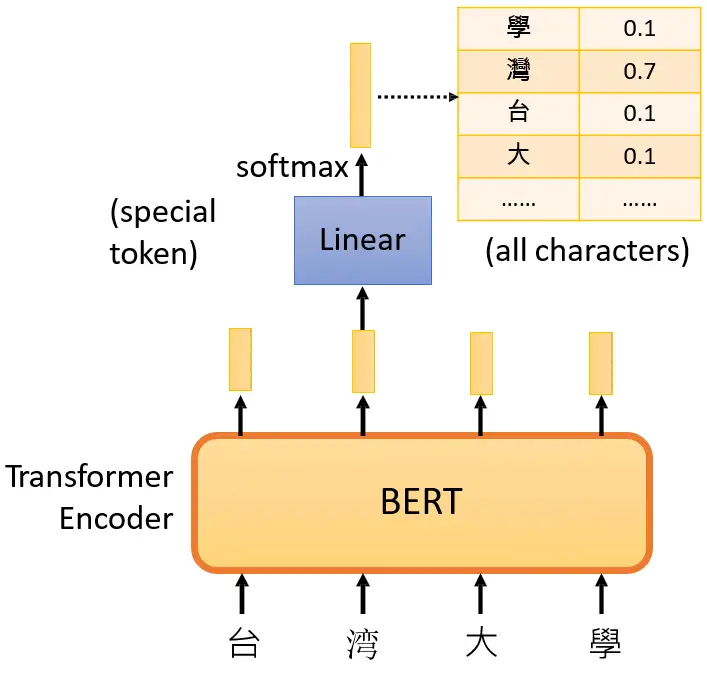
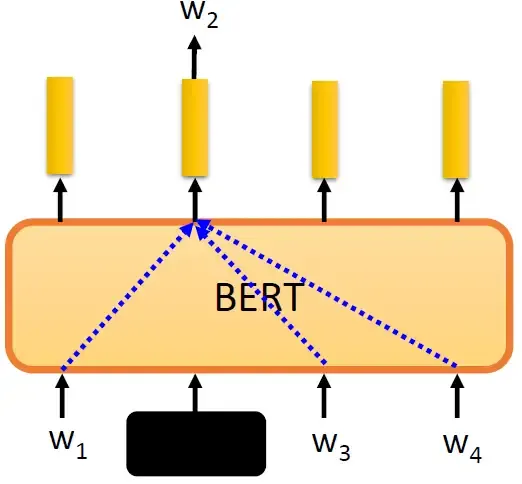
接下来要做的事情是把这段输入文字里面的一部分随机盖住。随机盖住有2种,一种是直接用一个Mask把要盖住的token (对中文来说就是一个字)给Mask掉,具体是换成一个特殊的字符。另一种做法是把这个token替换成一个随机的token。

接下来把这个盖住的token对应位置输出的向量做一个Linear Transformation,再做softmax输出一个分布,这个分布是每一个字的概率,如下图所示。
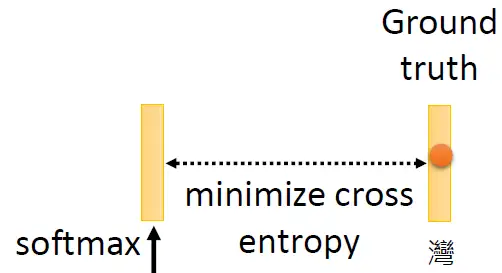
那接下来要怎么训练BERT呢?因为这时候BERT并不知道被 Mask 住的字是 "湾" ,但是我们知道啊,所以损失就是让这个输出和被盖住的 "湾" 越接近越好,如下图所示。
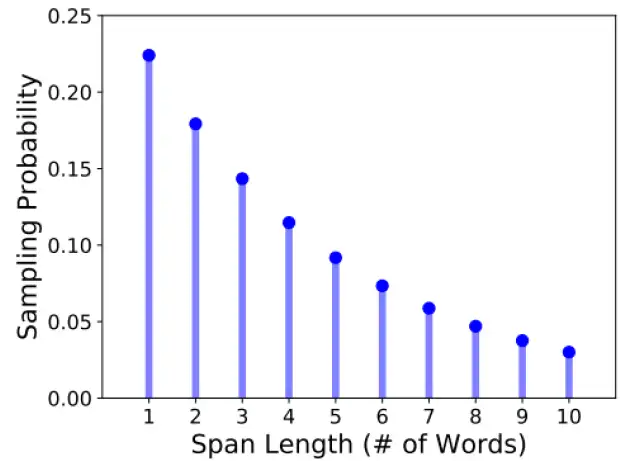
其实BERT在训练的时候可以不止是选取一个token,我们可以选取一排的token都盖住,这就是 SpanBERT 的做法,至于要盖住多长的token呢?SpanBERT定了一个概率的分布,如下图所示。有0.22的概率只盖住一个token等等。
除此之外,SpanBERT还提出了一种叫做Span Boundary Objective (SBO) 的训练方法,意思是说:
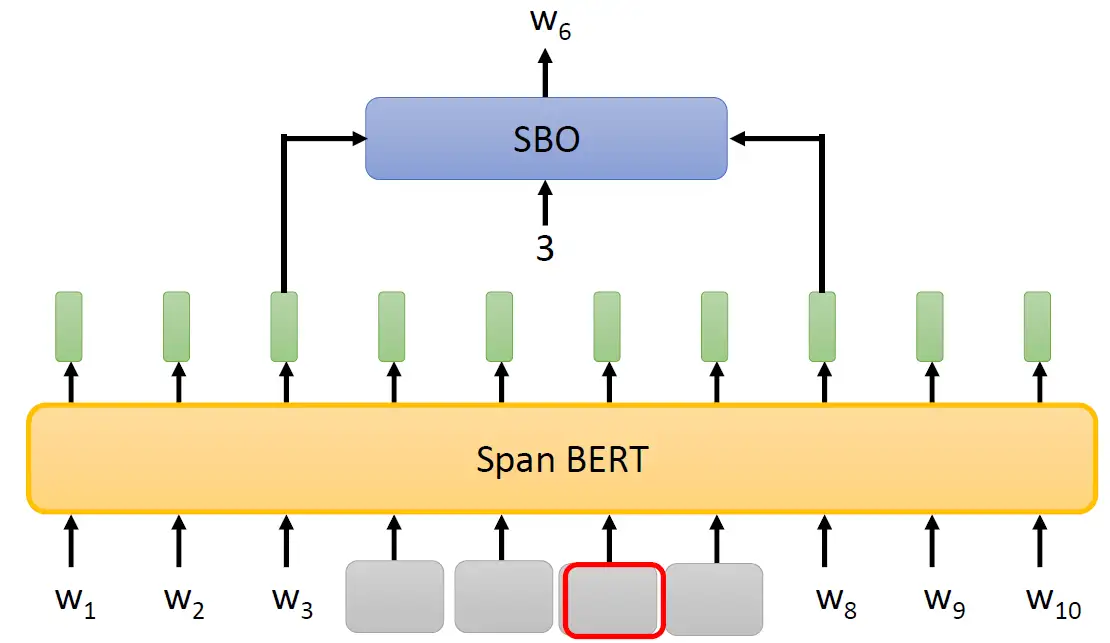
盖住一串token以后,用这段被盖住的token的左右2个Embedding去预测被盖住的token是什么。SBO把盖住的部分的左右两边的Embedding吃进来,同时还输入一个数字,比如说3,就代表我们要还原被盖住的这些token里面的第3个token。
其实BERT在训练的时候不只是要做Masking Input,还要做的一件事情是Next Sentence Prediction。那我们会先爬取很多的sentence,然后随机地找两个sentence,给他俩中间加上一个分隔符号 [SEP],代表前后是2个不同的句子;然后在最前面加上1个分类符号 [CLS],这个东西相当于是 ViT 里面的 class token。把这些拼在一起以后输入到BERT里面,当然输出也会是一个Sequence,但是我们只看 [CLS] 的输出,并把这个输出通过一个 Linear Transformation,得到二元的分类 "Yes/No"。在这里它代表的意义是:"Sentence 1 和Sentence 2 是不是相接的?"如下图10所示。
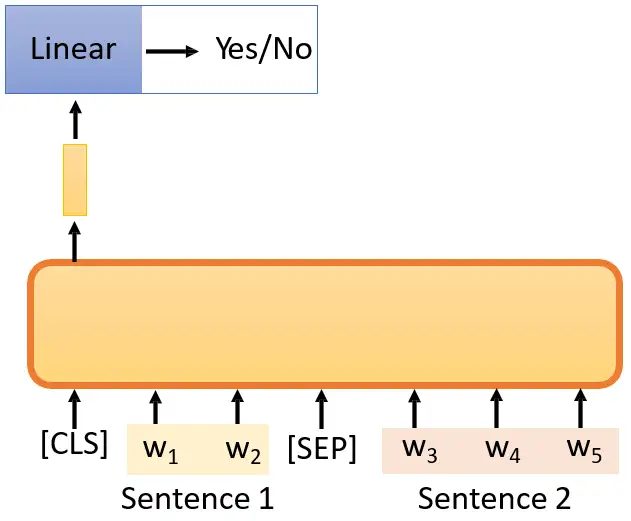
但是后续有文章,比如Robustly optimized BERT approach (RoBERTa) 就说明Next Sentence Prediction是对训练没有什么特别的帮助的,一种可能的原因是判断前后两个句子是不是相接的这个任务太简单了,要知道两个句子是不是应该接在一起也许不是一个特别难的任务。所以BERT可能没有借助Next Sentence Prediction这个任务学到太多的有用的东西。后续的 ALBERT中又提出了sentence order prediction的办法,被认为是有作用的,就是判断连续的两个sentence的先后顺序。
下面的问题是:BERT到底应该怎么用呢?
我们现在训练的BERT模型其实只会做2件事情:
- Masked token prediction:预测盖住的词是什么。
- Next sentence prediction:预测两个句子是不是前后接起来的。
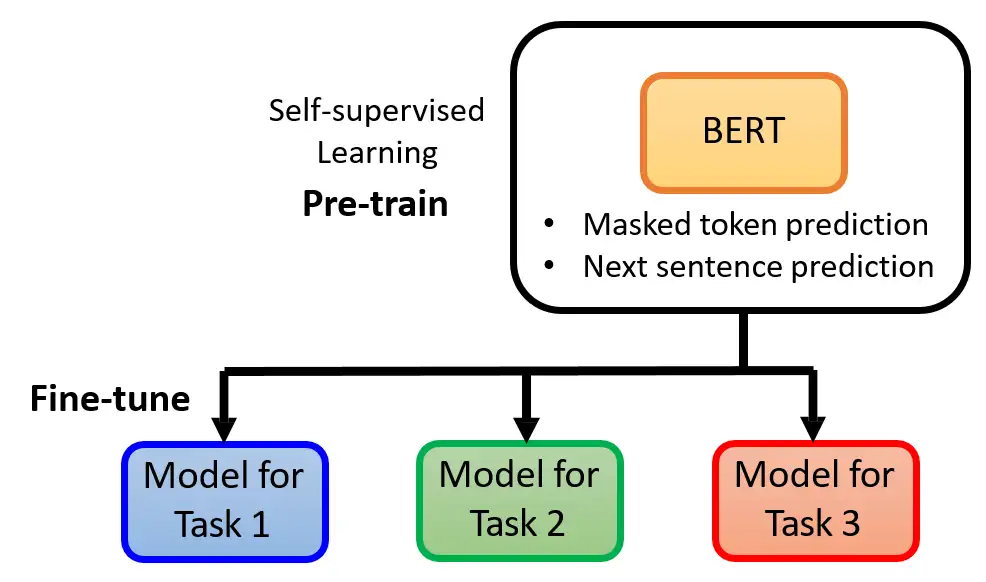
那么接下来神奇的地方是:BERT可以被用在很多下游任务 (Downstream Tasks) 上,这些下游任务可能和Masked token prediction,Next sentence prediction毫无关联,但是BERT可以作为预训练模型被用在它们上面。
那接下来训练好BERT以后,就要测试一下它的能力如何。通常你需要把它在多个任务上进行测试,刚才我们说BERT相当于是胚胎干细胞,那你需要让它分化成多种专门的细胞,在每个任务上进行测试。这个任务集最知名的标杆就叫做:General Language Understanding Evaluation (GLUE),GLUE Benchmark
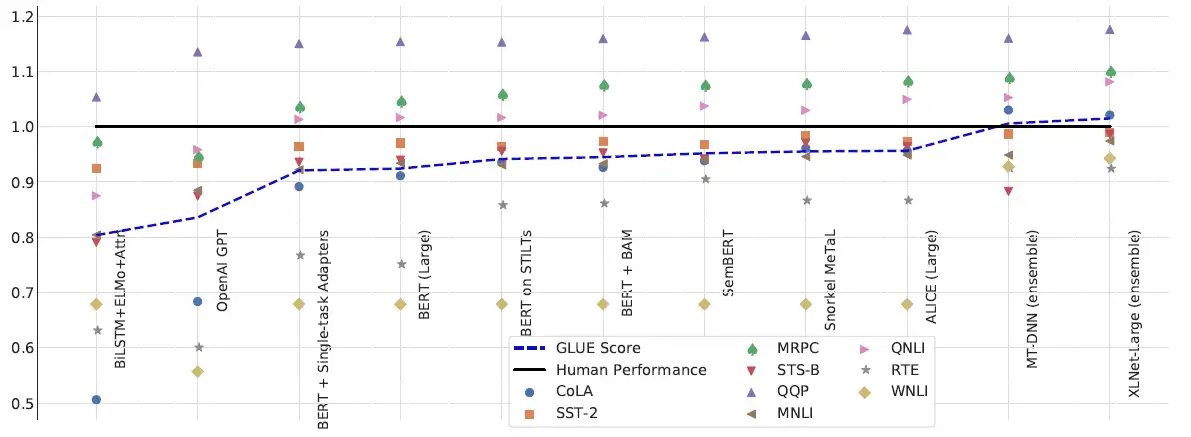
GLUE里面的9个任务如下图所示。我们要把预训练模型在这9个任务上面分别微调,所以其实会得到9个模型,分别做在9个任务上,看看这9个任务上正确率的平均是多少,这个平均数值就代表了Self-Supervised-Learning模型的好坏。

下图代表的是近年来的模型的GLUE得分,黑色的线代表的是人类的得分,最新的XLNet就在这个任务上超越了人类水平,说明GLUE 这个任务已经被玩坏了,所以后续有了更难的自然语言任务:SuperGLUE让机器来解。
接下来的问题是:如何使用BERT呢?
- Case1:情感分析:输入一个句子,输出对应的情感类别。
BERT是怎么解Sentiment Analysis的问题呢?给它一个句子,在这个句子前面放上 class token,这步和 ViT 是一模一样的。同样地,我们只取输出的Sequence里面的class token对应的那个vector,并将它做Linear Transformation+Softmax,得到类别class,就代表这个句子的预测的情感,如下图所示。
值得注意的是,对于这种下游任务你需要有labelled data,也就是说BERT其实没办法凭空解Sentiment Analysis的问题,也是需要一部分有监督数据的。我们此时的情感分析模型包括BERT部分和Linear Transformation部分,只是BERT部分的初始化来自Self-Supervised Learning,而Linear Transformation部分采样的是随机初始化。这两部分的参数都用Gradient Descent来更新。
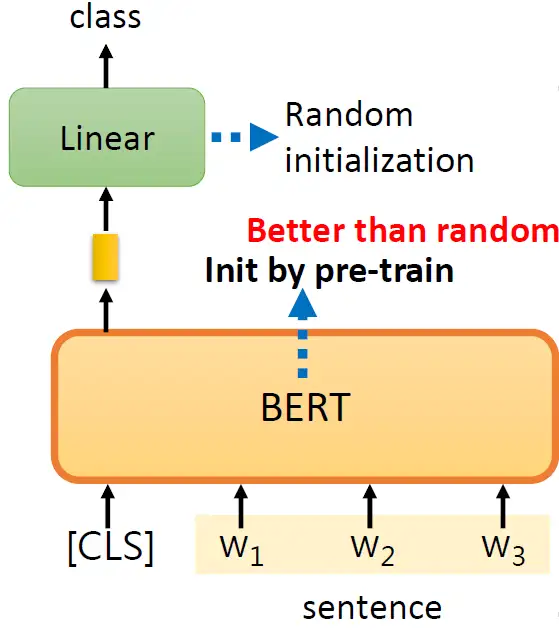
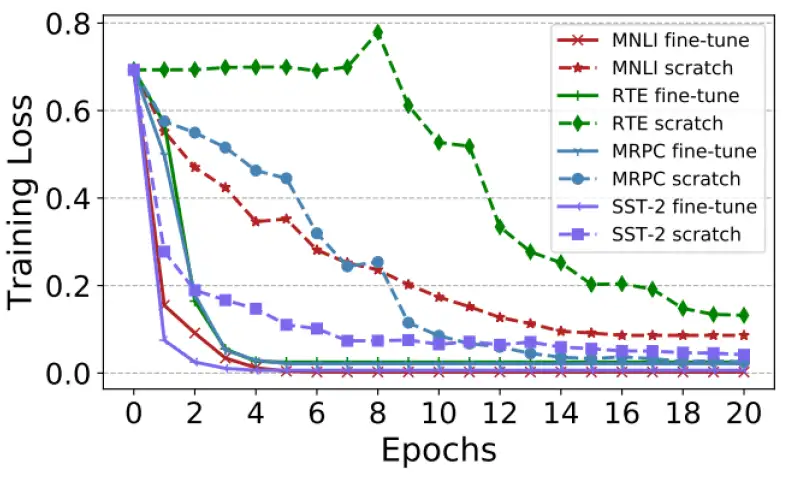
下图其实是个对比,就是BERT部分不用预训练模型的初始化 (scratch) 和用了预训练模型的初始化 (fine-tune) 的不同结果,不同颜色的线代表GLUE中的不同任务。 不用预训练模型的初始化会导致收敛很慢而且loss较高,说明预训练模型的初始化的作用。
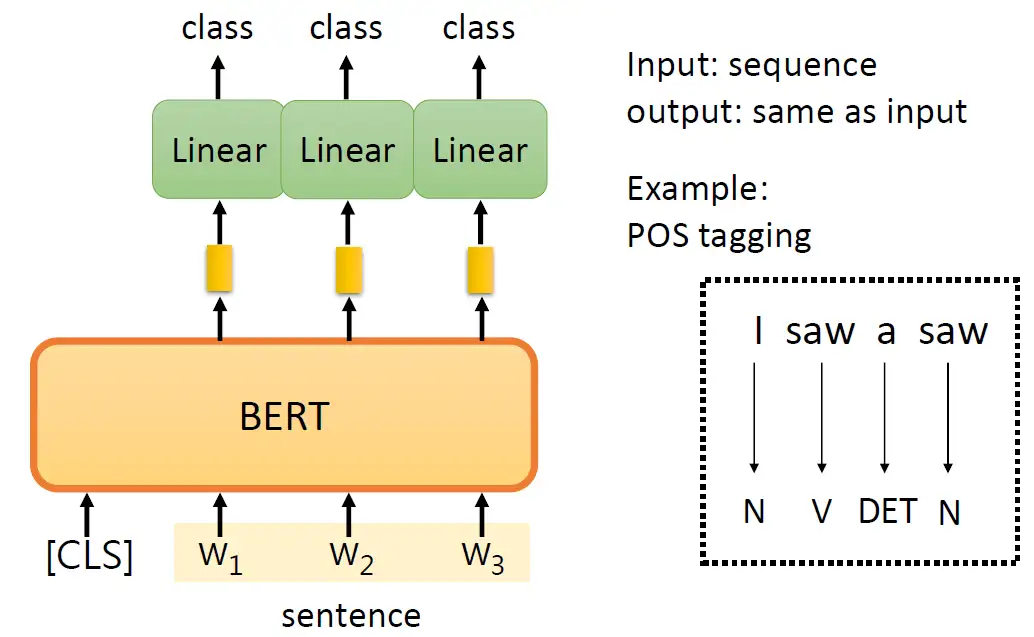
- Case2:词性标注:输入一个句子,输出每个词对应的词性。
与 Case1 不一样的是,此时输出的每个token都会做Linear Transformation+Softmax,得到类别class,就代表这个token的词性,如下图16所示。
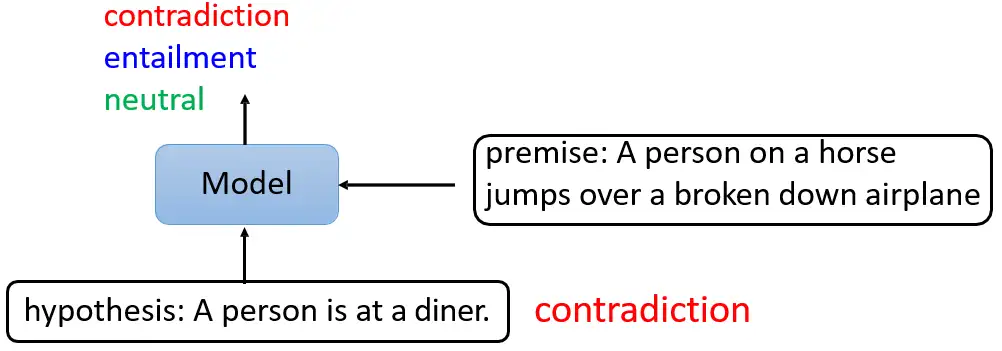
- Case3:Natural Language Inference (NLI):输入两个句子,输出一个类别。
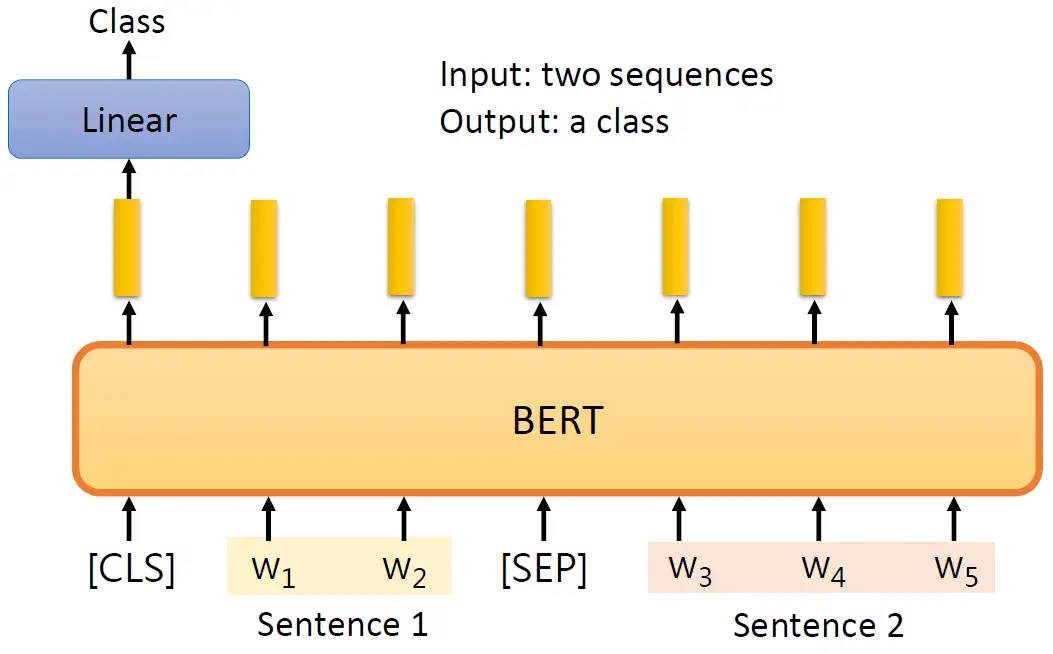
比如下图中所举的例子,其中一个句子是:A person on a horsejumps over a broken down airplane。另一个假设是:hypothesis: A person is at a diner。很明显是矛盾的,所以此时模型要输出contradiction。这个应用场景其实也是很多,比如输入一篇文章和一个留言,来让模型看看留言到底是赞成文章,还是反对文章的。把2个句子输入以后,在最前面加上1个分类符号 [CLS],把这些拼在一起以后输入到BERT里面,当然输出也会是一个Sequence,但是我们只看 [CLS] 的输出,并把这个输出通过一个 Linear Transformation,得到分类 "赞成/反对/中性"。当然此时我们也同样需要少量的监督信息。
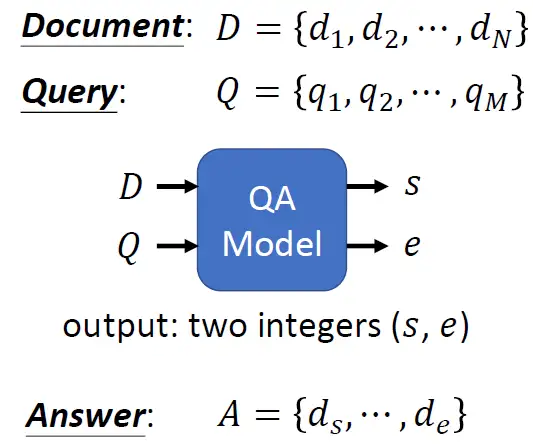
- Case4:Extraction based Question Answering (QA):输入一篇文章和问题,输出问题答案。
如下图所示,输入是文章 \(D\) 和问题 \(Q\) ,输出是两个正整数 \(s\) 和 \(e\) 。代表index,我们把文章截取从 \(s\) 到 \(e\) 的片段之后就是问题的答案 \(A=\{d_s,...,d_e\}\)。

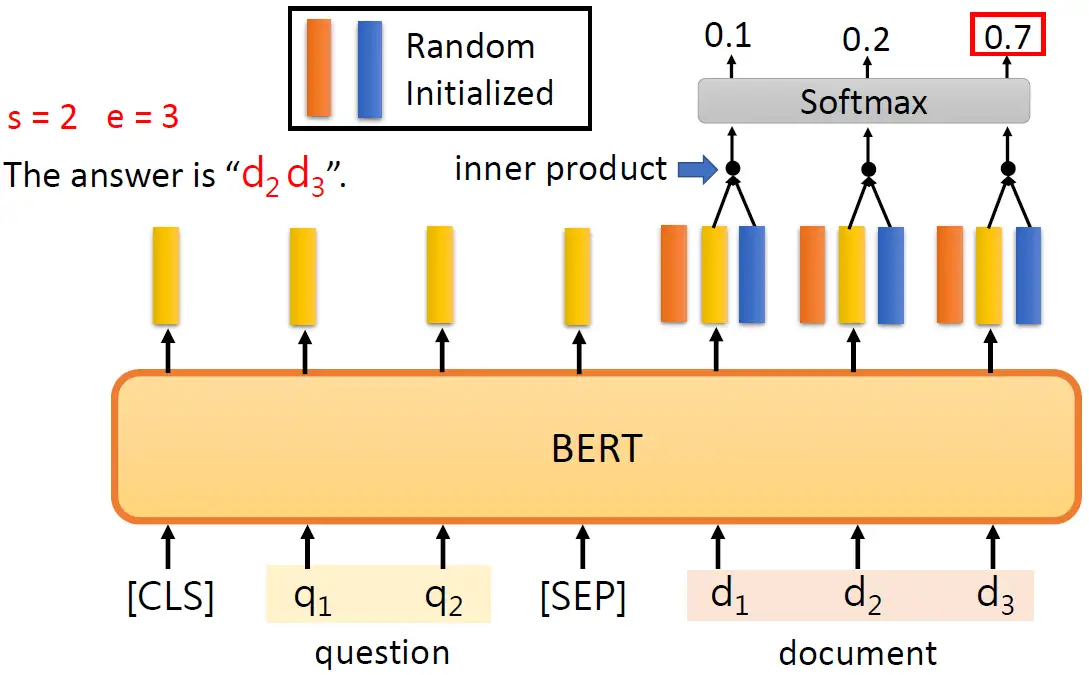
针对这种情况训练BERT的方法如下图所示,输入有一个question和一个document,那么它们之间要用分隔符号 [SEP] 分开。接下来我们从输出的Sequence里面挑出document对应的输出。我们除了BERT部分之外唯一需要训练的是2个vector,分别是图中橙色和蓝色的vector,这两个vector的维度和BERT的embedding dimension的维度是一致的,比如BERT的嵌入维度是768维,那这2个向量也是768维的。
接下来要做的是:把橙色向量和document对应的输出的每个向量做内积以后再做softmax操作,得到的最大值的索引就是document的起始位置,比如第2个0.5最大,那么这里的 \(s\) 就等于2。然后,把蓝色向量和document对应的输出的每个向量做内积以后再做softmax操作,得到的最大值的索引就是document的终止位置,比如第3个0.7最大,那么这里的 \(e\) 就等于3。再强调一遍,橙色向量和蓝色向量是随机初始化的,而BERT部分是使用Self-Supervised Learning 预训练好的。

- Case5:General Sequence 输出一般的句子
下一个问题是如何让预训练的模型输出一般的句子呢?或者,如何把Pre-trained model用在这种seq2seq的model里面?
一种做法是如下图所示,我们把这个Pre-trained model作为一个Encoder,输入一个sequence以后得到输出,我们再把这个得到的输出送到一个Decoder中,这个Decoder是task-specific的,然后Decoder会输出一串token sequence,这样就结束了。但这样的坏处是:我们有的这个Encoder是经过了预训练的Pre-trained model,但是Decoder不是,它没有经过预训练,不是Pre-trained model。一般来讲我们的Task-specific的data会很少,所以这个Decoder如果很大的话会训不好,我们希望整个模型里面多数的参数都是Pre-trained的。
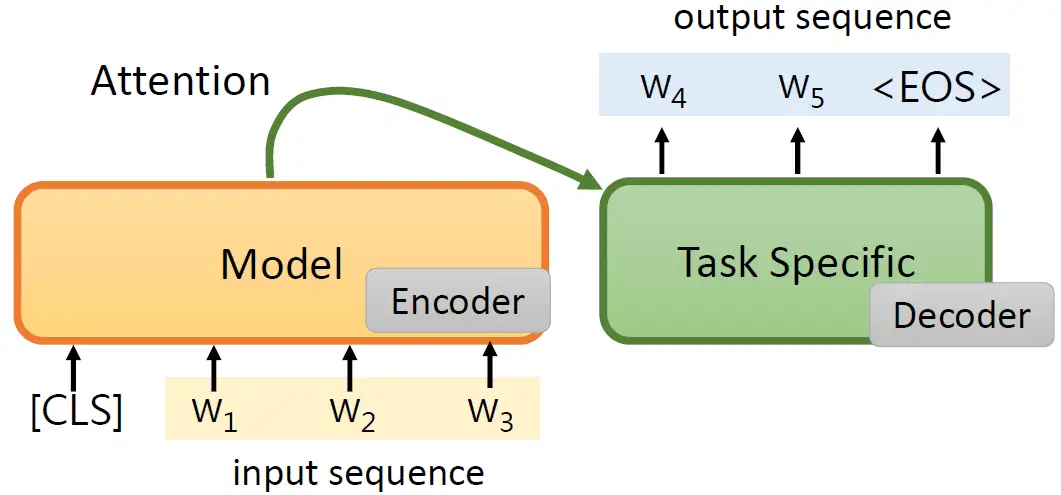
所以现在我们采取另外一种做法,如下图所示。我们把输入序列 \(w_1\),\(w_2\) 丢进模型之后呢,给模型一个特别的符号 [SEP],模型看到这个分隔符号之后知道输入已经完成,该输出sequence了。于是在输入 [SEP]之后模型经过一个Task-specific的层之后输出 \(w_3\) ,再输入 \(w_3\) 之后模型经过一个Task-specific的层之后输出 \(w_4\) ,再输入 \(w_4\) 之后模型经过一个Task-specific的层之后输出 \(w_5\) ,以此类推。

BART, MASS 和 ELECTRA 模型
BART 和 MASS提出的问题是说:可以直接Pre-train一个seq2seq的模型吗,如下图所示。那怎么用这种Self-Supervised Learning的办法去Pre-train一个seq2seq的模型呢?
我们输入一个sequence \(w_1,w_2,w_3,w_4\) ,经过Encoder和Decoder,输出的目标是要reconstruct原来的这个sequence \(w_1,w_2,w_3,w_4\) 。但有件事需要注意:就是我们要把输入的 \(w_1,w_2,w_3,w_4\) 做某种程度的破坏 (corrupted),如果你没有做任何的破坏,那么seq2seq model 其实没有学到任何的东西。为了增加学习的难度,我们需要对输入做某种程度的破坏,那都有什么破坏的方法呢?
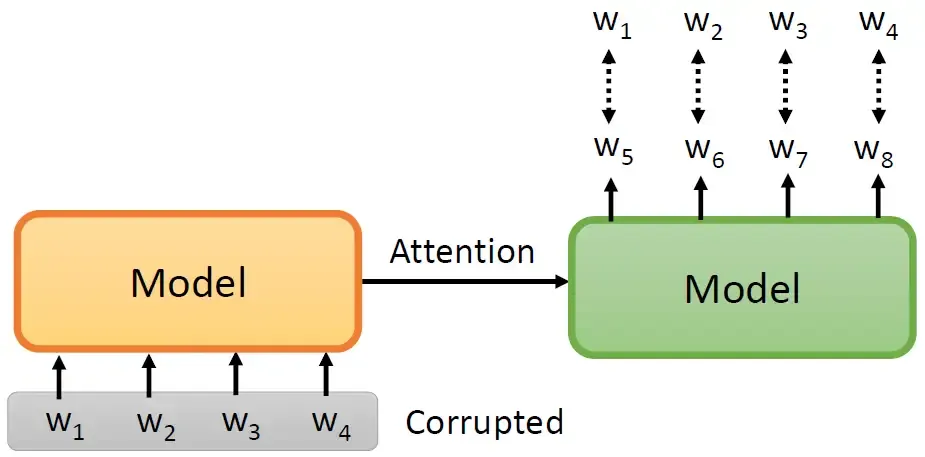
MASS的想法就是下图的第1行,和BERT很像,就是把一些部分随机的盖住。和BERT不一样的地方是:BERT是不要求还原完整的sequence的,只要求填出被mask的部分即可。
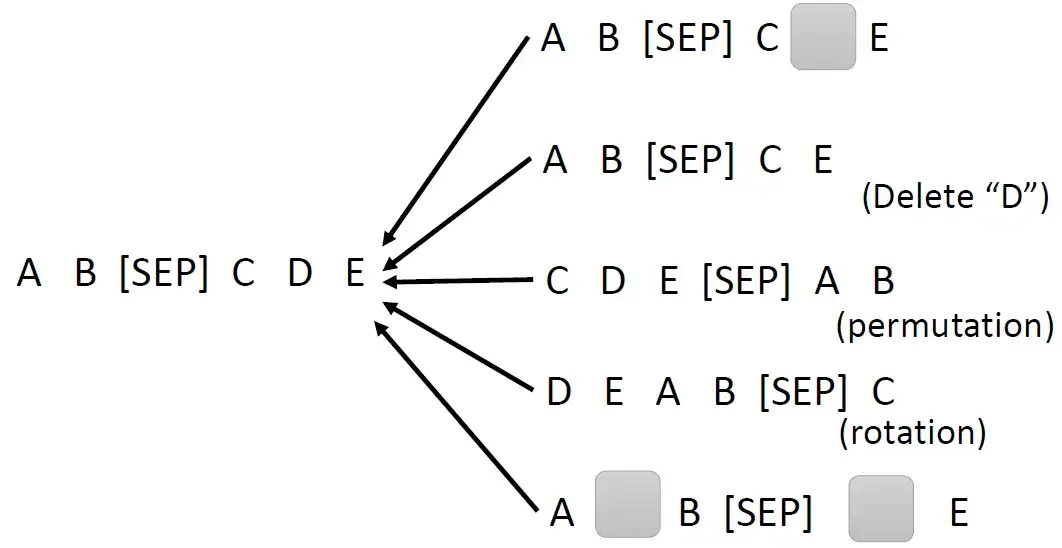
在BART论文里面就提出了各式各样的方法,是下图的后面几行。除了mask住以外,还有直接删除token (delete)。或者,把前后的句子顺序给打乱 (permutation),或者把原本某些在尾部的东西拿到前面来 (rotation)。还有一种方法是Text infilling ,对应下图最后一行。我们会在这个句子里面加入mask,但是加入的情况有2种:一种是随机插入,我们并没有把原来的句子盖住任何东西,比如A, B中间原本是没有任何东西的,我们插入一个mask。另一种是不管mask有多长,都只放一个mask,比如今天把C, D这2个token都盖住,但却只放1个mask。最后的结论是:permutation和rotation的结果不太好,而Text infilling的结果一直很好。
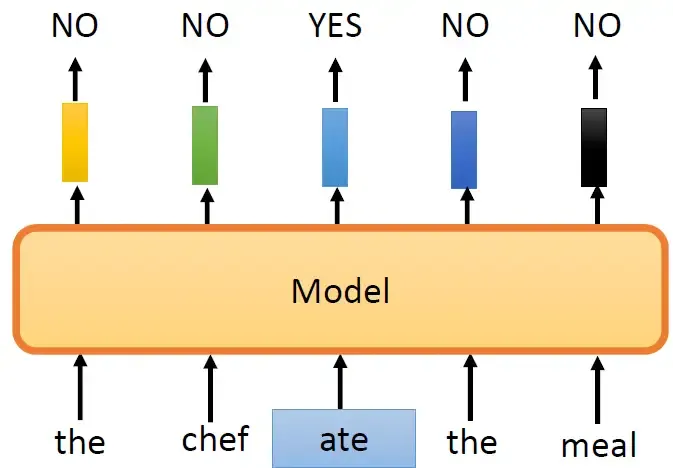
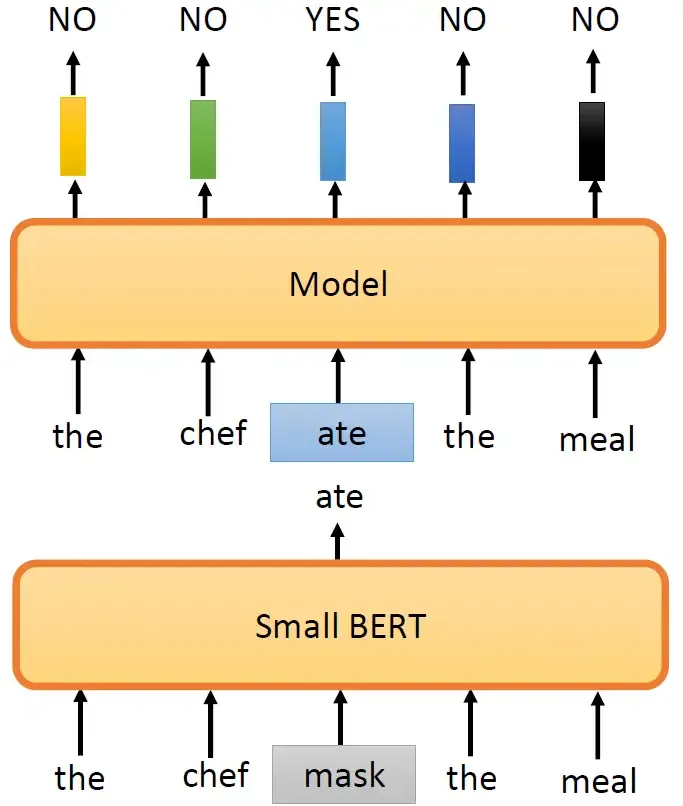
到目前为止的Pre-training的方法都是要预测一些信息,预测下一个token或者被盖住的token长什么样子。但是,有没有其他的做法呢?其实预测一个东西需要的训练的强度是很大的,所以ELECTRA就是为了避开需要预测这个任务。ELECTRA不做预测这件事,只回答Binary的问题。ELECTRA的模型就是吃一个句子进来,然后把这个句子里面的一些地方置换成其他词汇,如下图所示,比如说把原来的第3个词置换成了ate,ELECTRA就负责输出这个句子的5个token是否有被置换:NO, NO, YES, NO, NO。这样做有什么好处呢?第1个好处就是预测YES/NO更容易。那现在的问题是:我要把随机的一个token置换成什么呢?如果随机置换一个奇奇怪怪的词汇就会很容易被发现,所以办法如图所示,用了另外一个比较小的BERT模型产生被置换的词汇。比如这个小的BERT模型这个位置先mask起来,输出一个ate,那么ELECTRA模型的这个位置就被替换成ate。
这个方法其实有点像GAN,一个模型 Small BERT生成被替换的词汇,一个模型ELECTRA判别YES/NO。但是作者没有按照GAN的方法训练,所以不能说是GAN。这个小的BERT模型是事先训练好的。那么之所以不把它当做GAN来训练是因为BERT模型太大,GAN本身很难训练,那这样大的模型无法保证稳定训练。
FAQ
- BERT输入序列的长度有限制吗?
答1:因为BERT模型的架构本质是Transformer的Encoder,而Transformer架构主要靠Self-attention,它的运算量是 \(O(N^{2}d)\) ,其中 \(N\) 是Sequence的长度,而 \(d\) 是模型的Embedding dimension,所以理论上BERT输入序列的长度不能太长,一般是512左右。
- BERT预训练通常是做填空题,下游任务各种各样,二者有什么关系呢?
答2:这两件事情怎么会有关系呢?请看下一节。
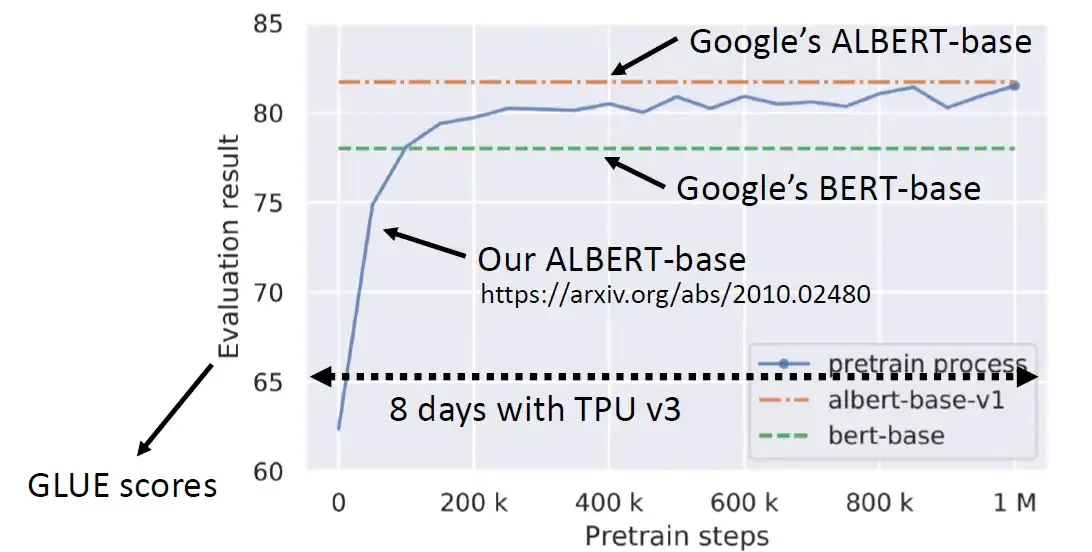
BERT其实是很难训练的,它使用的资料量是3个billion的词汇,相当于哈利波特系列词汇量总和的3000倍。如下图26所示,参数更新了1000000次,TPU跑了8天,也无法复现Google的结果。
为什么 BERT 有用呢?
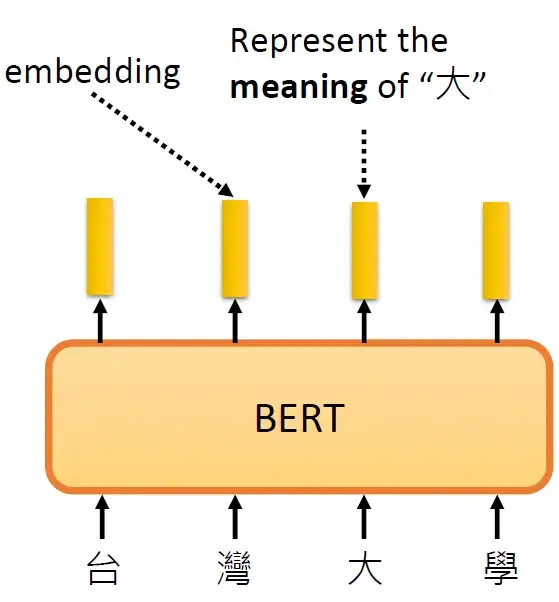
那什么叫代表它们的意思呢?假设把这些字对应的向量画出来,或算它们之间的距离,你会发现意思越相近的字它们的向量越接近。那你可能会问:语言都有一字多意的问题,那应该怎么表示呢?其实 BERT 它可以考虑上下文,比如都是 "果" 这个字,上下文不同,它的向量也会不一样。比如吃苹果的 "果" 和苹果手机的 "果" 向量就不一样,如下图所示。
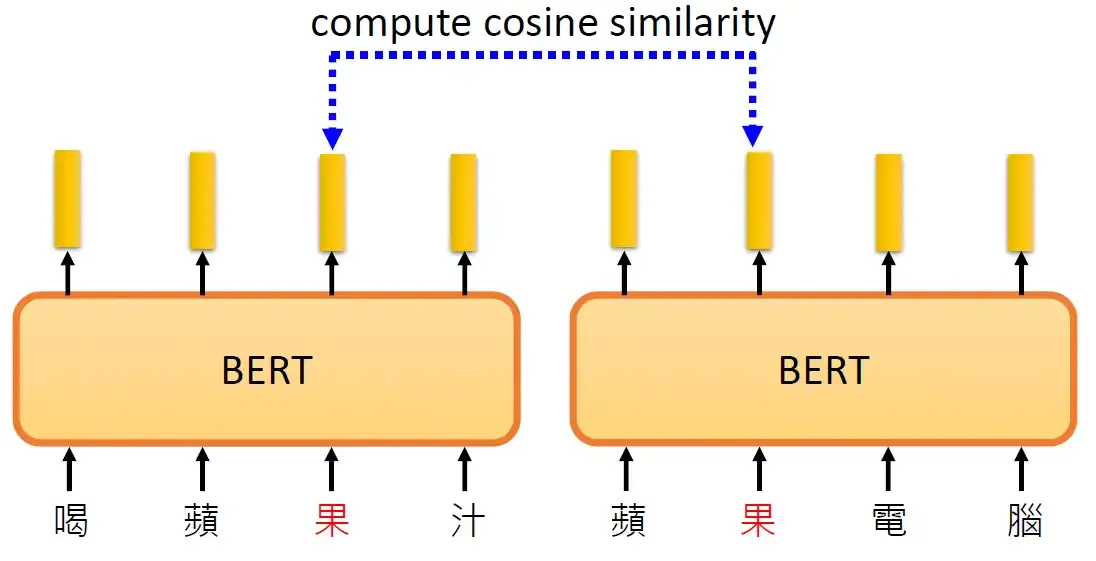
BERT真的可以做到这件事吗?我们把 "喝苹果汁" 和 "苹果电脑" 都丢到BERT模型里面去,计算这2个果的余弦相似度,这两个向量不会一样,因为BERT本质是Encoder,编码内容信息,而这两个果的上下文不同,如下图所示。
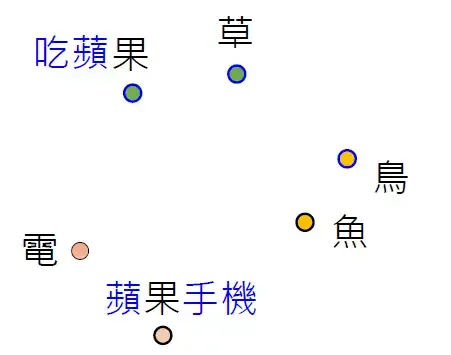
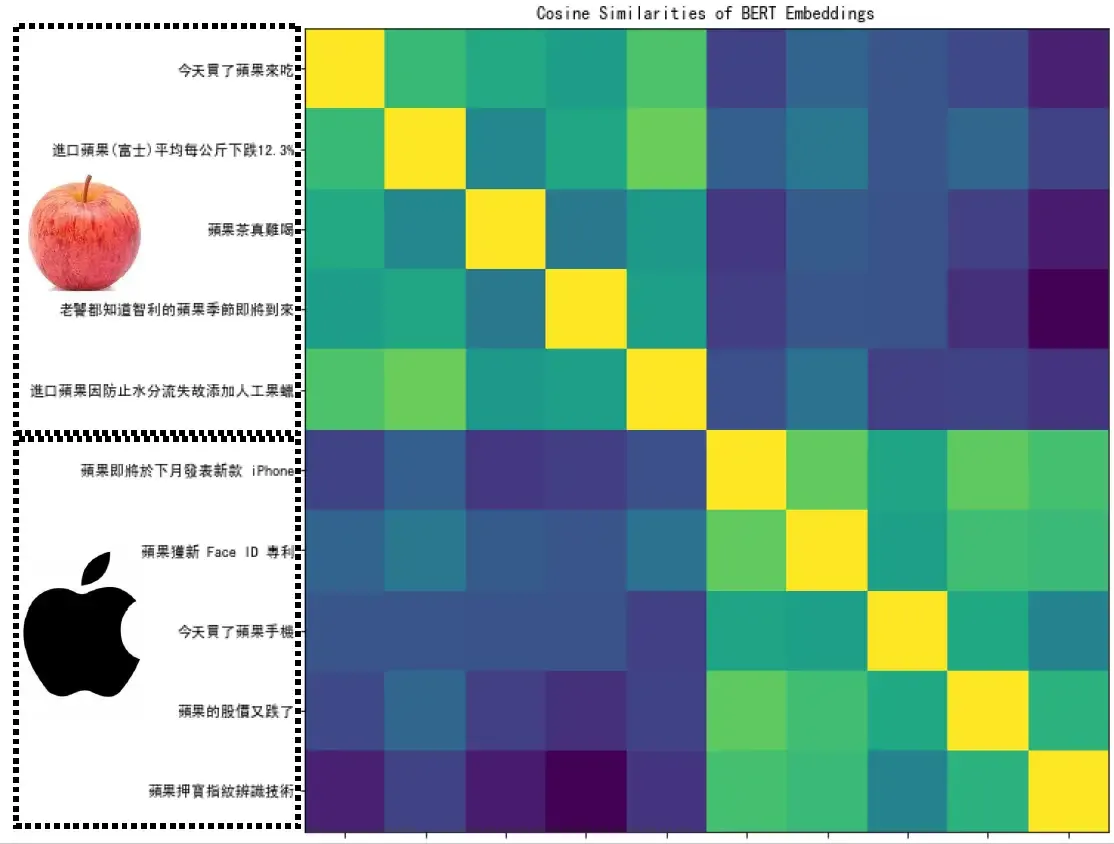
下面图30选了10个句子,前5个句子里面的 "果" 是苹果的果,后5个句子里面的 "果" 是苹果电脑的果。这10个果两两之间去计算相似度,得到一个10×10的矩阵。可以发现前五个果两两之间相似度高,后五个果两两之间相似度高,但前后的果相似度低。这说明BERT是可以根据上下文信息学到这个词的意思。著名语言大师John Rupert Firth曾说过:"You shall know a word by the company it keeps."意思是我们是通过一个词的上下文含义来了解这个词的意思的。今天如果一个 "果" 后面跟的是树,斤这类词汇,很容易理解成苹果的果;而如果后面跟的是股价,公司这类词汇,很容易理解成苹果电脑的果。
多语言学习
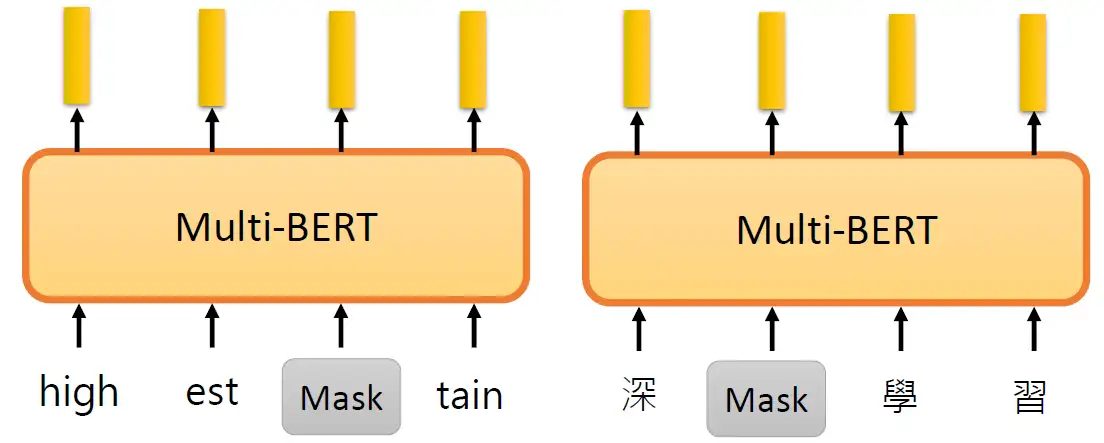
下面要介绍的是多语言的BERT (Multi lingual BERT),让模型对于不同的语言都去做填空题。但是真正神奇的地方如下图所示,拿英文训练的Multi lingual BERT模型竟然能够学习到会做中文的QA问题。
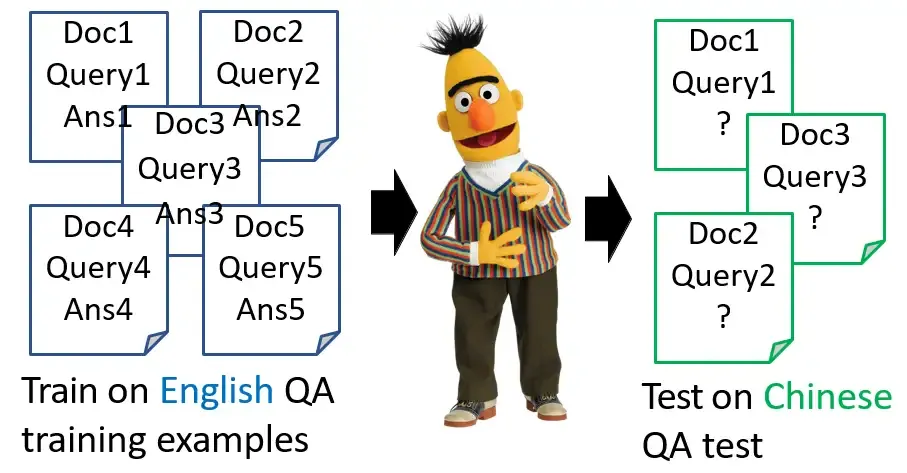
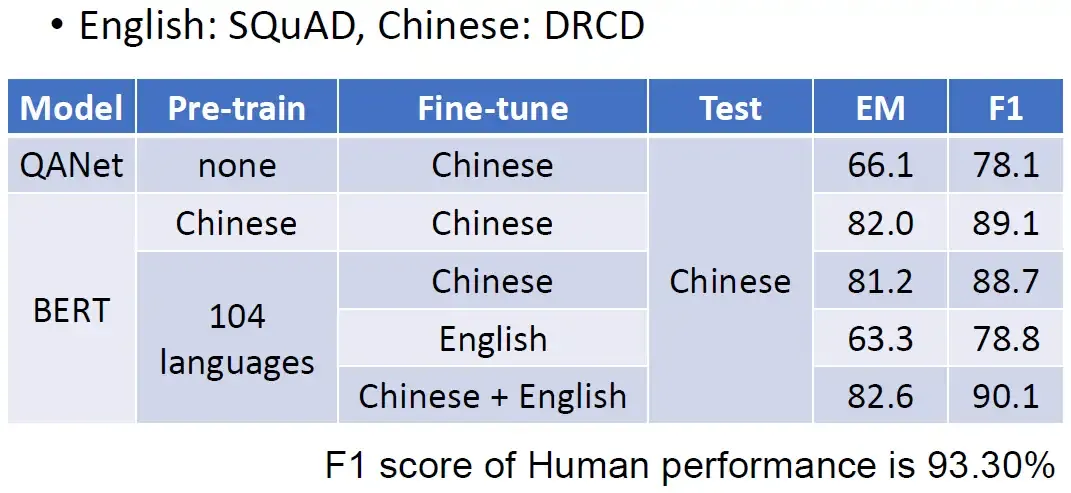
下图是一个真实的结果给大家参考,这边的训练的资料英文是SQuAD,中文的是DRCD。在还没有用BERT的时候是问答模型QANet的结果,它是很差的。
BERT我们首先在中文上做Pre-train,然后假设在中文上Fine-tune,在中文的QA问题上测试,F1 score可以达到89.1之高。
如果是在104种语言上做Pre-train,然后假设在中文上Fine-tune,在中文的QA问题上测试,F1 score可以达到88.7之高。
甚至是在104种语言上做Pre-train,然后假设在English上Fine-tune,在中文的QA问题上测试,F1 score仍可以达到78.7。注意这种情况模型从来没有看过中文的问答的资料集。仅凭在包含中文的训练集上做填空题学到的东西,它接触的唯一关于中文的东西就是填空而已。我们拿英文QA问答教它,竟然就可以自动地学会中文的QA问答。
为什么会这样呢?也许不同语言的词汇的Embedding是很接近的,如下图所示。也许模型在看过了大量语言以后,自动学会了这件事情。对模型来说不同语言对它都是一样的,它只看意思。但这一切的前提是你得有巨大的多语言数据集 (每种语言1000k snetences以上)才能够把模型训起来。

到这里,我们知道了BERT是一个能做句子填空的模型,你给它输入一个带有Mask的英文句子,它能够填英文的空;给它输入一个带有Mask的中文句子,它能够填中文的空。但是有哪里怪怪的。BERT可以把不同语言,同样意思的符号的vector很接近,可是BERT不会把中文和英文混在一起吗?给它输入一个带有Mask的英文句子,它会填空时在空格填入中文吗?
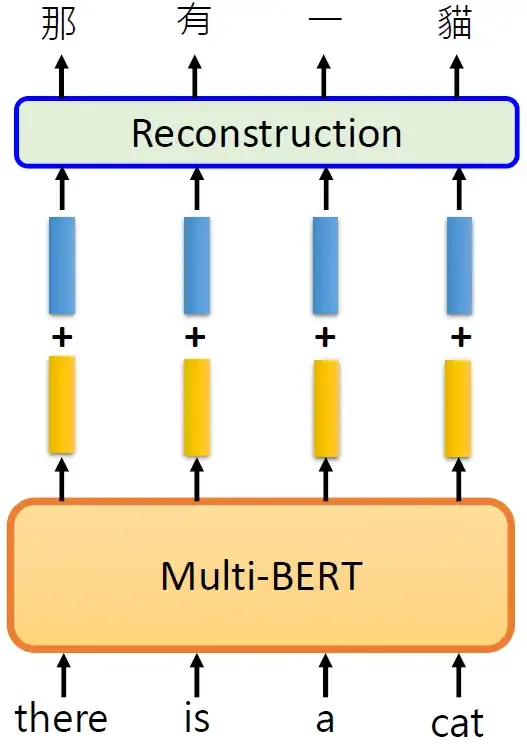
它没有这么做,说明它知道不同语言的信息,它并没有完全抹掉语言的资讯。下面的实验中,我们把所有英文词汇的Embedding取平均,把所有中文词汇的Embedding取平均,作差得到蓝色的向量,如图所示。

得到蓝色的向量以后,给BERT输入一个英文的句子there is a cat,得到输出的黄色向量,给黄色的向量上面加上蓝色的向量,再去做填空题,就能填中文的答案了,如图所示。
GPT系列模型
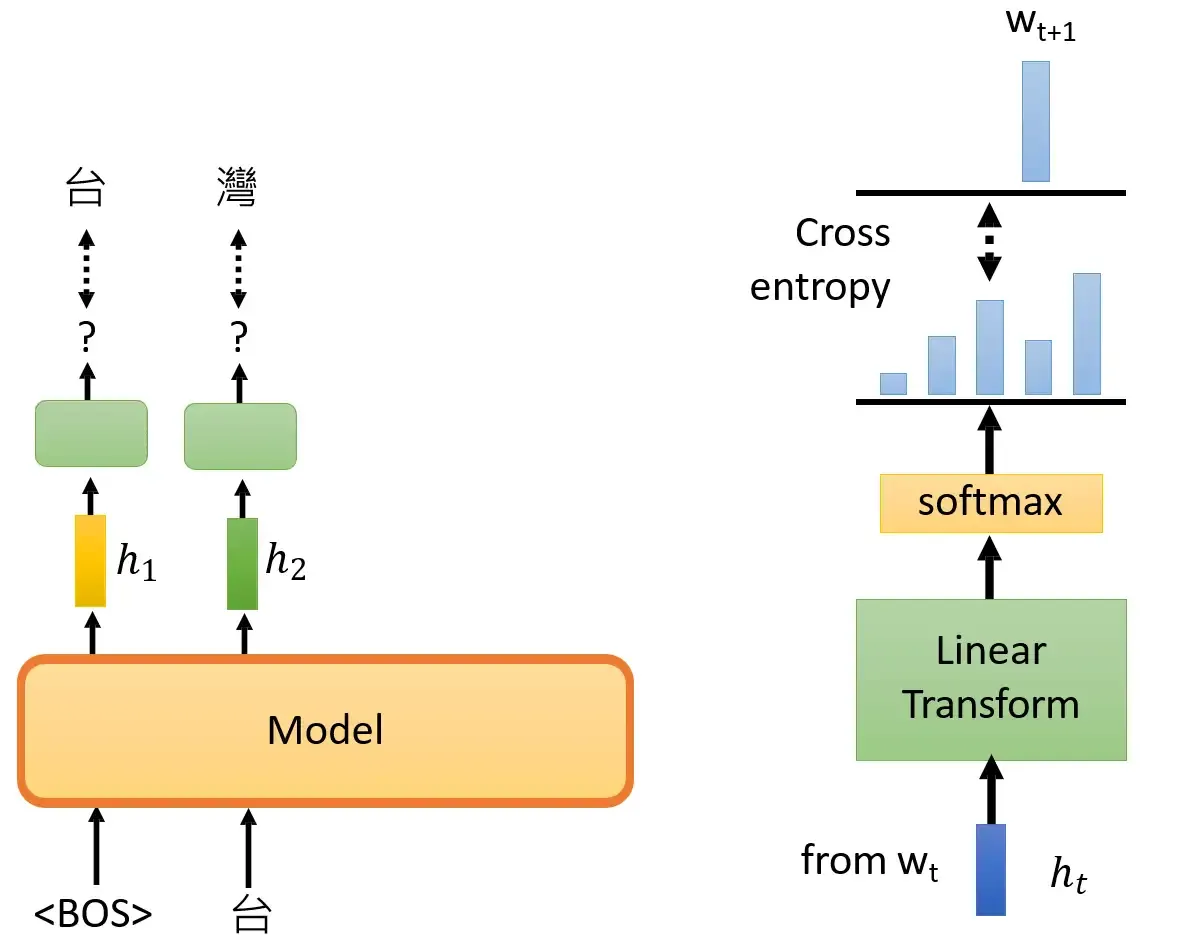
那么GPT可以把一句话补完,怎么把它用在下游任务上面呢?比如下图,怎么把它用在翻译的任务或者其他自然语言处理的任务上呢?GPT并没有使用和BERT一样的做法:在下游任务的小数据集上做Fine-tune,可能是因为GPT的模型真的太大了,达到连Fine-tune都很有困难。望这个向量与 "台" 越接近越好。再输入 "台",模型输出绿色的Embedding,这个Embedding经过右侧的Linear Transformation+Softmax操作得到一个向量,希望这个向量与 "湾" 越接近越好。以此类推。这就是GPT模型,它厉害的地方是用了很多训练数据训练了一个异常巨大的模型,参数量可以达到175000M。注意GPT的模型有点像Transformer的Decoder,也就是说输入开始符号<BOS>预测 "台" 的时候模型不会看到后面的 "湾大学",输入开始符号<BOS>和"台",预测 "湾" 的时候模型不会看到后面的 "大学",以此类推。
既然GPT有预测下一个token的能力,那它自然也就有生成文章的能力,你可以让它不断预测下一个token,产生完整的文章。最著名的是GPT曾经写了一篇和发现了独角兽 (horn) 有关的,一个活灵活现的假新闻,如下图所示。

那么GPT可以把一句话补完,怎么把它用在下游任务上面呢?比如下图,怎么把它用在翻译的任务或者其他自然语言处理的任务上呢?GPT并没有使用和BERT一样的做法:在下游任务的小数据集上做Fine-tune,可能是因为GPT的模型真的太大了,达到连Fine-tune都很有困难。

GPT的做法是:
先打问题的描述:Translate English to French。
然后给它几个范例,比如:sea otter → loutre de mer 等等。
接下来输入要翻译的文本:cheese → ?
利用 GPT 文本生成的能力,自动地把后面给补完,希望它就可以产生翻译的结果。
值得注意的是GPT并没有学去做翻译,它唯一学到的就是给一段文字的前半段然后把后半段补完。现在我们只是给它几个例子和一个命令 Translate English to French,就期望它给出翻译的结果,这个叫Few-shot Learning。但是我们完全没有进行训练啊,没有任何 Gradient Descent 的这个意思,但是你一定要取个名字,文献里面就叫做 "In-context" Learning。
其他领域的 Self-Supervised Learning
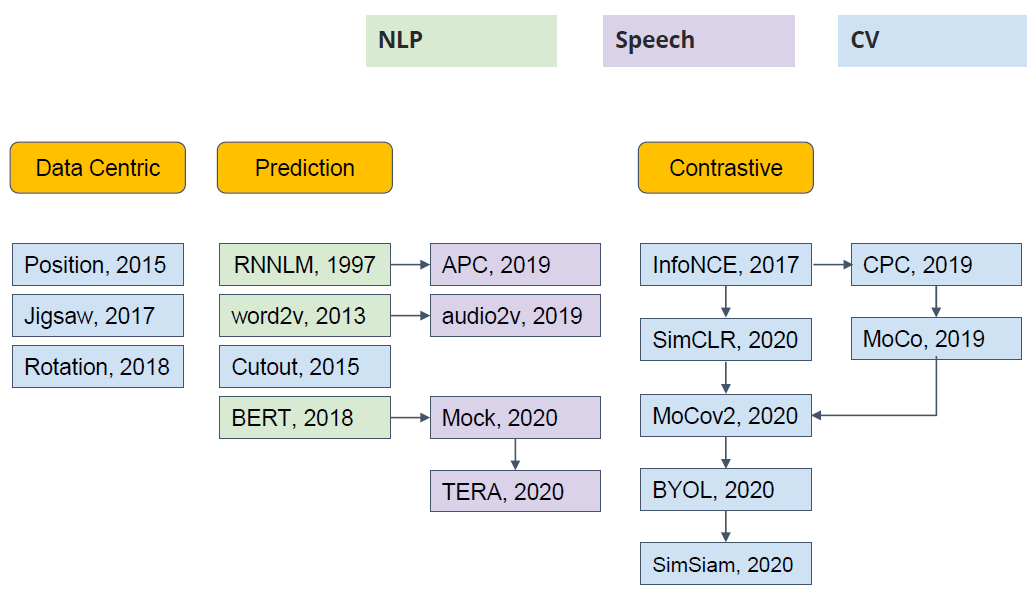
Self-Supervised Learning 不仅是在NLP领域,在CV, 语音领域也有很多经典的工作,如下图40所示。它可以分成3类:Data Centric, Prediction 和 Constractive,我们今天介绍的BERT, GPT都是属于Prediction的类别。
总结
本文介绍了 NLP 领域的 Self-Supervised Learning 的经典工作 BERT 和 GPT 模型,对于BERT来讲,其自监督训练的部分就是训练 BERT 做简单的填空题,这一过程需要巨大的数据集,但是令人欣慰的是这些数据集都是没有标签的资料,只是一些简单的句子,用于训练 BERT 做填空题。训练好之后的BERT具有了 Word Embedding 的能力,且这里的 Word Embedding 是可以自动地考虑上下文的,使得BERT得到的 Word Embedding 自动覆盖了上下文的信息。这样的预训练好的 BERT 模型,只需要少量的带标签数据集,就可以在无数下游任务 (Downstream Tasks) 中完成微调 (Fine-tune),得到一个个不同的适用于下游任务的性能卓著的model。这就是 Self-Supervised Learning 的步骤和优势。