前言
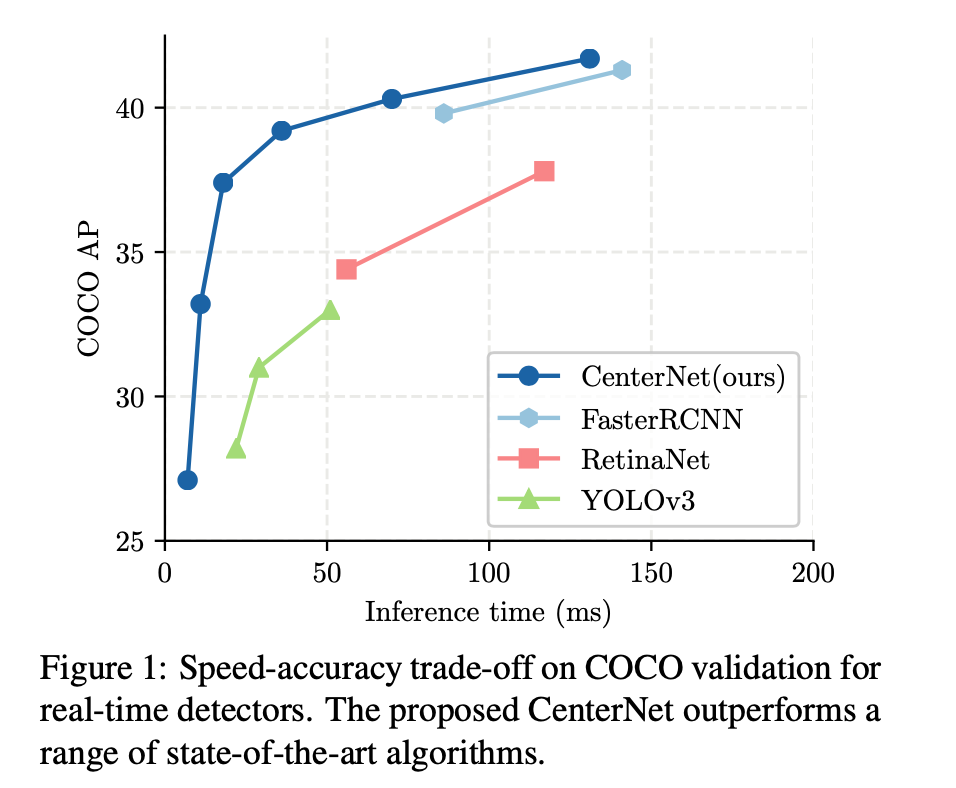
anchor-free目标检测属于anchor-free系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于one-stage和two-stage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。
CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。
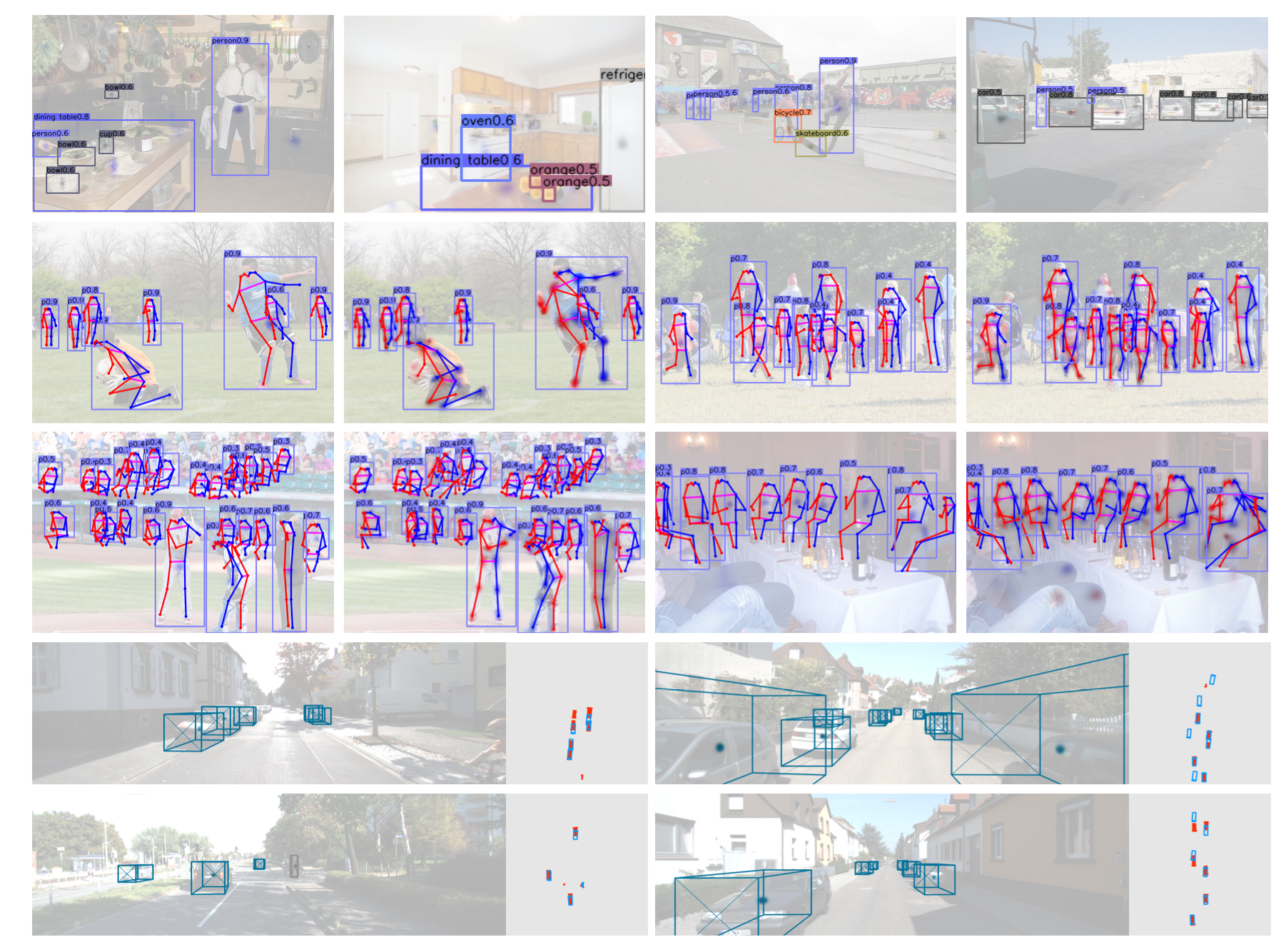
那CenterNet相比于之前的one-stage和two-stage的目标检测有什么特点?
- CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是背景 - 因为每个目标只对应一个“anchor”,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选
- CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是比较小的(Mask-Rcnn最小为16、SSD为最小为16)。
总体来说,CenterNet结构优雅简单,直接检测目标的中心点和大小,是真anchor-free。
PS:其实本篇所说的CenterNet的真实论文名称叫做 objects as points,因为也有一篇叫做CenterNet: Keypoint Triplets for Object Detection 的论文与这篇文章的网络名称冲突了,所以以下所说的CenterNet是指 objects as points。
网络结构与前提条件
接下来说一下正式进入篇章之前的一些前提知识。
使用的网络
论文中CenterNet提到了三种用于目标检测的网络,这三种网络都是编码解码(encoder-decoder)的结构:
- Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
- DLA-34 : 37.4% COCOAP and 52 FPS
- Hourglass-104 : 45.1% COCOAP and 1.4 FPS
每个网络内部的结构不同,但是在模型的最后都是加了三个网络构造来输出预测值,默认是80个类、2个预测的中心点坐标、2个中心点的偏置。
用官方的源码(使用Pytorch)来表示一下最后三层,其中hm为heatmap、wh为对应中心点的width和height、reg为偏置量,这些值在后文中会有讲述。
(hm): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
前提条件
附一张检测的效果图:

我们该如何检测呢?
首先假设输入图像为\(I\in R^{W\times H\times 3}\),其中 \(W\) 和 \(H\) 分别为图像的宽和高,然后在预测的时候,我们要产生出关键点的热点图(keypoint heatmap):\(\hat{Y}\in [0,1]^{\frac{W}{R}\times \frac{H}{R}\times C}\),其中\(R\) 为输出对应原图的步长,而\(C\)是在目标检测中对应着类别数,如在COCO目标检测任务中,这个\(C\)的值为80,代表当前有80个类别。
插一段官方代码,其中\(R\)就是self.opt.down_ratio也就是4,代表下采样的因子。
# 其中input_h和input_w为512,而self.opt.down_ratio为4,最终的output_h为128
# self.opt.down_ratio就是上述的R即输出对应原图的步长
output_h = input_h // self.opt.down_ratio
output_w = input_w // self.opt.down_ratio
这样,\(\hat{Y}_{x,y,c}=1\)就是一个检测到物体的预测值,对于\(\hat{Y}_{x,y,c}=1\),表示对于类别\(c\),在当前\((x,y)\)坐标中检测到了这种类别的物体,而\(\hat{Y}_{x,y,c}=0\)则表示当前当前这个坐标点不存在类别为\(c\)的物体。在整个训练的流程中,CenterNet学习了CornerNet的方法。对于每个标签图(ground truth)中的某一
\(C\)类,我们要将真实关键点(true keypoint)\(p\in R^2\) 计算出来用于训练。对于下采样后的坐标,我们设为

其中\(R\) 是上文中提到的下采样因子4。所以我们最终计算出来的中心点是对应低分辨率的中心点。
然后我们利用 \(Y\in [0,1]^{\frac{W}{R}\times\frac{H}{R}\times C}\) 来对图像进行标记,在下采样的[128,128]图像中将ground truth point以 \(Y\in [0,1]^{\frac{W}{R}\times\frac{H}{R}\times C}\)的形式,用一个高斯核
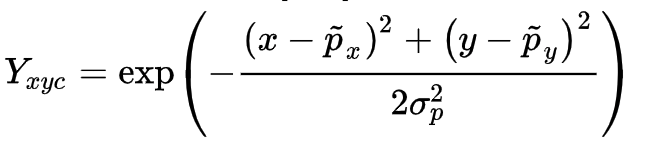
来将关键点分布到特征图上,其中 \(\sigma_p\)是一个与目标大小(也就是w和h)相关的标准差。如果某一个类的两个高斯分布发生了重叠,直接取元素间最大的就可以。
这么说可能不是很好理解,那么直接看一个官方源码中生成的一个高斯分布[9,9]:

每个点\(Y\in [0,1]^{\frac{W}{R}\times\frac{H}{R}\times C}\) 的范围是0-1,而1则代表这个目标的中心点,也就是我们要预测要学习的点。
损失函数
重点看一下中心点预测的损失函数
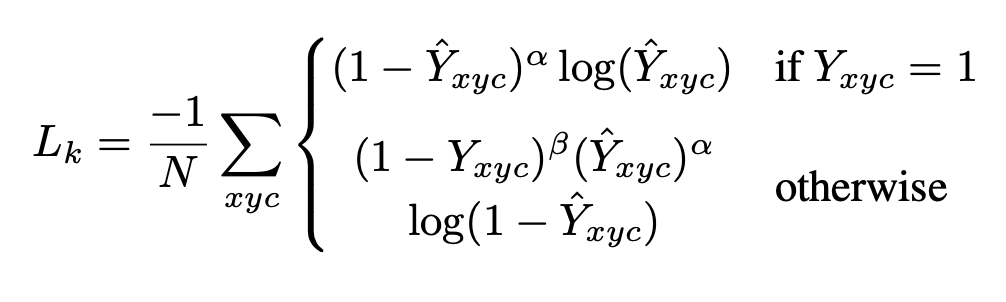
其中 \(\alpha\) 和 \(\beta\) 是Focal Loss的超参数, \(N\) 是图像 \(I\) 的的关键点数量,用于将所有的positive focal loss标准化为1。在这篇论文中 \(\alpha\) 和 \(\beta\) 分别是2和4。这个损失函数是Focal Loss的修改版,适用于CenterNet。
这个损失也比较关键,需要重点说一下。和Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值,当 \(Y_{xyc}=1\) 的时候, \((1-\hat{Y}_{xyc})^\alpha\) 就充当了矫正的作用,假如 \(\hat{Y}_{xyc}\)接近1 的话,说明这个是一个比较容易检测出来的点,那么 \((1-\hat{Y}_{xyc})^\alpha\) 就相应比较低了。而当 \(\hat{Y}_{xyc}\)接近0的时候,说明这个中心点还没有学习到,所以要加大其训练的比重,因此 \((1-\hat{Y}_{xyc})^\alpha\) 就会很大, \(\alpha\) 是超参数,这里取2。
再说下另一种情况,当 \(otherwise\) 的时候,这里对实际中心点的其他近邻点的训练比重(loss)也进行了调整,首先可以看到 \((\hat{Y}_{xyc})^\alpha\),因为当 \(otherwise\) 的时候 \((\hat{Y}_{xyc})^\alpha\) 的预测值理应是0,如果不为0的且越来越接近1的话,\((\hat{Y}_{xyc})^\alpha\) 的值就会变大从而使这个损失的训练比重也加大;而 \((1-Y_{xyc})^\beta\) 则对中心点周围的,和中心点靠得越近的点也做出了调整(因为与实际中心点靠的越近的点可能会影响干扰到实际中心点,造成误检测),因为 \(Y_{xyc}\) 在上文中已经提到,是一个高斯核生成的中心点,在中心点 \(Y_{xyc}=1\),但是在中心点周围扩散 \(Y_{xyc}\) 会由1慢慢变小但是并不是直接为0,类似于上图,因此 \((1-Y_{xyc})^\beta\),与中心点距离越近,\(Y_{xyc}\) 越接近1,这个值越小,相反则越大。那么 \((1-Y_{xyc})^\beta\) 和 \((1-\hat{Y}_{xyc})^\alpha\)是怎么协同工作的呢?
简单分为几种情况:
- 对于距离实际中心点近的点,\(Y_{xyc}\) 值接近于1 ,例如 \(Y_{xyc}=0.9\) ,但是预测出来这个点的值,\(\hat{Y}_{xyc}\) 比较接近1,这个显然是不对的,它应该检测到为0,因此用 \((\hat{Y}_{xyc})^\alpha\)惩罚一下,使其LOSS比重加大些;但是因为这个检测到的点距离实际的中心点很近了,检测到的 \(\hat{Y}_{xyc}\) 接近1也情有可原,那么我们就同情一下,用 \((1-Y_{xyc})^\beta\) 来安慰下,使其LOSS比重减少些。
- 对于距离实际中心点远的点,\(Y_{xyc}\) 值接近0,例如\(Y_{xyc}=0.1\) ,如果预测出来这个点的值 \(\hat{Y}_{xyc}\) 比较接近1,肯定不对,需要用 \((\hat{Y}_{xyc})^\alpha\) 惩罚(原理同上),如果预测出来的接近0,那么差不多了,拿 \((\hat{Y}_{xyc})^\alpha\) 来安慰下,使其损失比重小一点;至于 \((1-Y_{xyc})^\beta\) 的话,因为此时预测距离中心点较远的点,所以这一项使距离中心点越远的点的损失比重占的越大,而越近的点损失比重则越小,这相当于弱化了实际中心点周围的其他负样本的损失比重,相当于处理正负样本的不平衡了。
- 如果结合上面两种情况,那就是:\((1-\hat{Y}_{xyc})^\alpha\) 和 \((\hat{Y}_{xyc})^\alpha\) 来限制easy example导致的gradient被easy example dominant的问题,而 \((1-Y_{xyc})^\beta\) 则用来处理正负样本的不平衡问题(因为每一个物体只有一个实际中心点,其余的都是负样本,但是负样本相较于一个中心点显得有很多)。
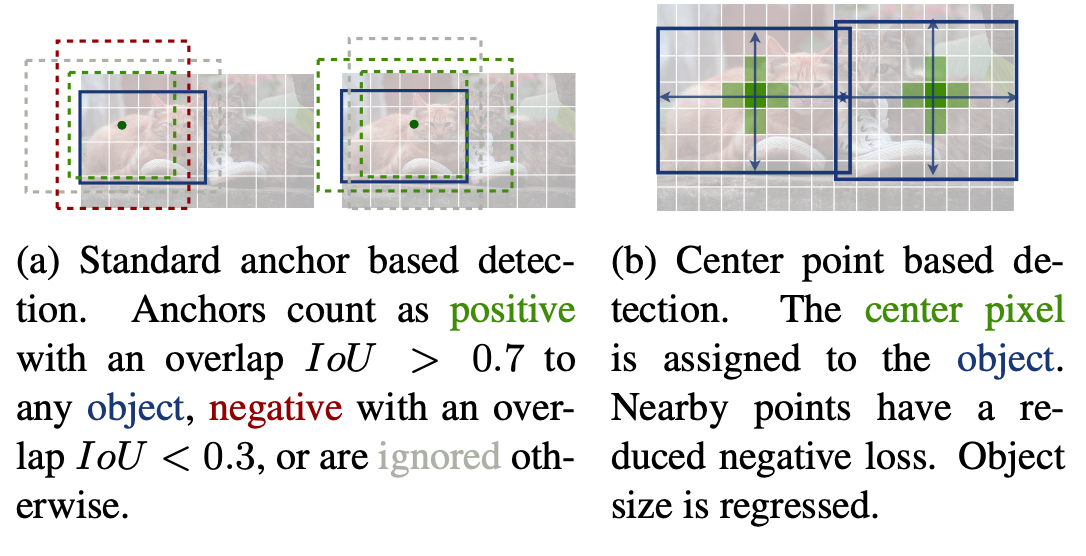
另外看一下官方的这张图可能有助于理解:传统的基于anchor的检测方法,通常选择与标记框IoU大于0.7的作为positive,相反,IoU小于0.3的则标记为negative,如下图a。这样设定好box之后,在训练过程中使positive和negative的box比例为1:3来减少negative box的比例(例如SSD没有使用focal loss)。
而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的:
目标中心的偏置损失
因为上文中对图像进行了\(R=4\) 的下采样,这样的特征图重新映射到原始图像上的时候会带来精度误差,因此对于每一个中心点,额外采用了一个 local offset:\(\hat{O}\in\mathcal{R}^{\frac{W}{R}\times\frac{H}{R}\times 2}\)去补偿它。所有类\(c\)
的中心点共享同一个 offset,这个偏置值(offset)用 L1 loss 来训练:
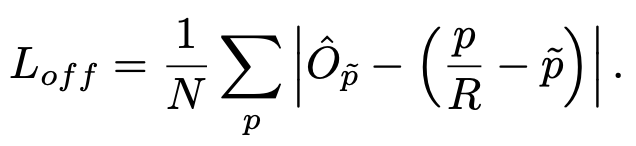
上述公式直接看可能不是特别容易懂,其实\(\frac{p}{R}\)是原始图像经过下采样得到的,对于[512,512]的图像如果\(R=4\)的话那么下采样后就是[128,128]的图像,下采样之后对标签图像用高斯分布来在图像上撒热点,怎么撒呢?首先将box坐标也转化为与[128,128]大小图像匹配的形式,但是因为我们原始的annotation是浮点数的形式(COCO数据集),使用转化后的box计算出来的中心点也是浮点型的,假设计算出来的中心点是[98.97667,2.3566666]。
但是在推断过程中,我们首先读入图像[640,320],然后变形成[512,512],然后下采样4倍成[128,128]。最终预测使用的图像大小是[128,128],而每个预测出来的热点中心(headmap center),假设我们预测出与实际标记的中心点[98.97667,2.3566666]对应的点是[98,2],坐标是\((x,y)\),对应的类别是\(c\),等同于这个点上\(\hat{Y}_{xyc}=1\),有物体存在,但是我们标记出的点是[98,2],直接映射为[512,512]的形式肯定会有精度损失,为了解决这个就引入了\(L_{off}\) 偏置损失。
式子中 \(\hat{O}_{\widetilde{p}}\) 是我们预测出来的偏置,而 \((\frac{p}{R}-\widetilde{p})\) 则是在训练过程中提前计算出来的数值,在官方代码中为:
# ct 即 center point reg是偏置回归数组,存放每个中心店的偏置值 k是当前图中第k个目标
reg[k] = ct - ct_int
# 实际例子为
# [98.97667 2.3566666] - [98 2] = [0.97667, 0.3566666]
reg[k]之后与预测出来的reg一并放入损失函数中进行计算。注意上述仅仅是对某一个关键点位置\(\widetilde{p}\) 来计算的,计算当前这个点的损失值的时候其余点都是被忽略掉的。
到了这里我们可以发现,这个偏置损失是可选的,我们不使用它也可以,只不过精度会下降一些。
目标大小的损失
我们假设\((x_1^{(k)},y_1^{(k)},x_2^{(k)},y_2^{(k)})\) 为目标 \(k\),所属类别为\(c_k\),它的中心点为
我们使用关键点预测\(\hat{Y}\) 去预测所有的中心点。然后对每个目标\(k\) 的 size 进行回归,最终回归到
这个值是在训练前提前计算出来的,是进行了下采样之后的长宽值。为了减少回归的难度,这里使用\(\hat{S}\in\mathcal{R}^{\frac{W^{'}}{R}\times\frac{H^{'}}{R}\times 2}\) 作为预测值,使用L1损失函数,与之前的\(L_{off}\) 损失一样:
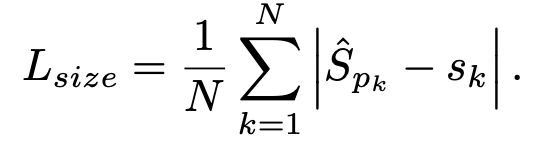
整体的损失函数为物体损失、大小损失与偏置损失的和,每个损失都有相应的权重。
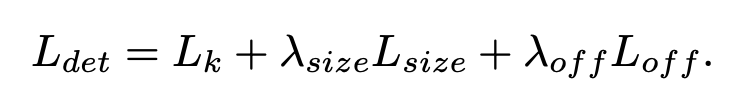
在论文中\(\lambda_{size}=0.1\),然后\(\lambda_{off}=1\),论文中所使用的backbone都有三个head layer,分别产生[1,80,128,128]、[1,2,128,128]、[1,2,128,128],也就是每个坐标点产生\(C+4\)个数据,分别是类别以及、长宽、以及偏置。
推断阶段
在预测阶段,首先针对一张图像进行下采样,随后对下采样后的图像进行预测,对于每个类在下采样的特征图中预测中心点,然后将输出图中的每个类的热点单独地提取出来。具体怎么提取呢?就是检测当前热点的值是否比周围的八个近邻点(八方位)都大(或者等于),然后取100个这样的点,采用的方式是一个3x3的MaxPool,类似于anchor-based检测中nms的效果。
这里假设\(\hat{p}_c\) 为检测到的点,
代表 \(c\) 类中检测到的一个点。每个关键点的位置用整型坐标表示 \((x_i,y_i)\) ,然后使用 \(\hat{Y}_{x_iy_ic}\) 表示当前点的confidence,随后使用坐标来产生标定框:
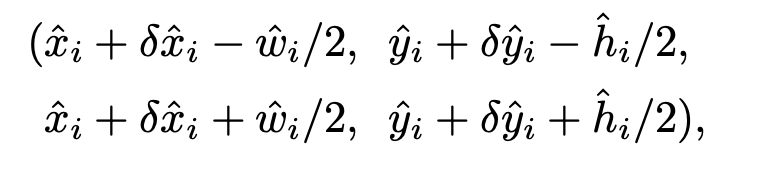
其中\((δ\hat{x}_i,δ\hat{y}_i) = \hat{O}_{\hat{x}_i,\hat{y}_i}\) 是当前点对应原始图像的偏置点,\((\hat{w}_i,\hat{h}_i)=\hat{S}\hat{x}_i,\hat{y}_i\) 代表预测出来当前点对应目标的长宽。
下图展示网络模型预测出来的中心点、中心点偏置以及该点对应目标的长宽:

那最终是怎么选择的,最终是根据模型预测出来的 \(\hat{Y}\) 值,也就是当前中心点存在物体的概率值,代码中设置的阈值为0.3,也就是从上面选出的100个结果中调出大于该阈值的中心点作为最终的结果。
四、Ground Truth(gt)是如何设计的
gt的编码基本与模型输出基本一致,就是将中心点坐标、检测框长宽、检测框坐标补偿均生成二维图像。但是里面有一些小细节,需要解释一下。
1. ground truth的维度
gt的维度大小不等于输入图像,而是等于输入图像除以下采样因子,也就是说,如果输入图像维度为640480,下采样因子为4,中心点坐标为(123,123),那么gt的维度即为160120,中心点坐标为(30,30),补偿值为(123-(30*4))/4=0.75。
2. 中心点heatmap的设计
我们应该如何设计中心点的heatmap?我们能想到的最平凡的方法就是生成一个二维矩阵,除了关键点坐标位置上的数值为1,其他均为0。但是这会出现一个问题,就是某些关键点附近的点,只要不是关键点本身,值都为0,那么在算loss的时候模型都会对他进行惩罚。这不是我们想看到的,因为即使他并不是恰好是关键点坐标,但只要离关键点足够近,依然是可以接受的。
因此我们想到了第二种方法,关键点附近的某个圆内,值均为1,其他均为0。这样做的目的是,我们将与关键点周围某个“可以接受的范围内”的点,均看作关键点的,在算loss的时候不进行惩罚。但是这样做依然会出现问题,比如距离关键点1个像素位的点,与距离关键点10个像素位的点,有可能数值均为1,那么均不会被惩罚,但是我们希望模型的输出尽可能地接近关键点。
最终我们采取的方法是在关键点周围生成高斯圆。也就是生成一个中心值为1,随着距离中心越来越远,数值越来越小的圆。这个圆的数值服从二维离散高斯分布。但是这里面牵扯到一个参数的选取,那就是方差/标准差,也可以认为是这个圆的半径大小,因为两者是等价的。具体公式可以参考[7]。原理简单来说就是遵从“检测框越大,圆半径越大”原则进行设计。
具体方法可以描述为,通过不断平移gt检测框,计算IoU,寻找IoU大于某个阈值的边界情况下的检测框顶点值,这些边界情况的顶点值距离原检测框对应顶点值的距离,就可以认为是该圆半径,从而计算出高斯圆所需要的方差值。
3. wh、offset heatmap的设计
对于wh、offset,在训练时并没有设计成heatmap,而是分别设计成了维度为(max_obj, 2)的张量,也可以看作是一个二元组列表,但列表最大长度被限制为了max_obj,其中第k个元素即为第k个物体中心点对应的长宽(或者是横纵坐标的offset)。这么做的目的主要是为了省内存,因为ground truth中只有关键点位置的(而非高斯圆内所有点)长宽、offset参与loss的计算,绝大部分区域不参与计算,因此不需要设计成heatmap来占用内存。
但这里有个问题,我们如何记住wh列表中第k个元素对应的中心点(i.e. 第k个物体的中心点)的坐标是什么呢?因此作者引入了另一个列表,代码中定义为ind,这个列表中的元素均为标量(i.e. 坐标编码),第k个元素的坐标是通过下式编码的:
其中 \(x_k, y_k\) 表示第k个物体的中心点坐标,input_w表示ground truth的宽度(如本节开头说的160)。这个公式其实非常简单,就是把160*120的特征图拉成一条线,上式就是求出了原图中的每个位置在拉成线后的index,因此保证了编码的唯一性,也就是说一旦得到这个编码,我们就可以知道第k个物体中心点的坐标,也就可以将第k个w、h、offset对应起来,从而计算损失。
有人可能会问,为什么要有max_obj这个超参数?这是为了训练的统一性,举例,如果没有这个超参数,一张图上5个物体,另一张图上12个物体,那么我们的wh张量的维度就会分别是(5,2)与(12,2),无法保证统一,也就无法合成batch。
另外,我们在对中心点坐标及补偿进行gt编码时,是除以了下采样因子,也就是这些值都是在“输出空间”(e.g. 160120)里的,但对w、h进行编码时,不需要除以下采样因子,只需要将“输入空间”(e.g. 640480)中的数值填入相应位置即可。