简介
BAGEL 模型原生支持统一的多模态理解和生成,是一个 decoder-only 的模型,BAGEL 在包含文本、图像、视频和网络数据的大量多模态数据上进行了预训练,包括数万亿 tokens。尽管有一些研究尝试扩展其统一模型,但它们主要仍然依赖于标准图像生成和理解任务中的图像-文本配对数据进行训练。
然而,最近的研究发现,学术模型与 GPT-4o 和 Gemini 2.0 等专有系统在统一多模态理解和生成方面存在显著差距,而这些专有系统的底层技术并未公开。作者认为,弥合这一差距的关键在于使用精心构建的多模态交错数据进行规模化训练。这种多模态交错数据整合了文本、图像、视频和网络来源。通过使用这种多样化的多模态交错数据进行扩展时,模型展现出复杂的、新兴的多模态推理能力。这种规模化不仅增强了核心的多模态理解和生成能力,还促进了复杂的组合能力,例如自由形式的视觉操作和需要长上下文推理的多模态生成。
论文主要贡献:
- 数据策略创新,融合多源数据。包含:
- 架构设计理念,采用 Mixture-of-Transformer-Experts (MoT) 架构:选择性激活模态特定参数,不同于以往方法的bottlenect连接器设计, bagel通过共享自注意力操作实现长上下文交互
- BAGEL模型特性, Bagel模型共有7B 激活参数(总计 14B 参数),并且开源了多模态基础模型, 模型同时俱有非常有竞争力的图像理解,图像生成以及图像编辑能力
- 能力涌现模式,随着交错多模态预训练的扩展,观察到清晰的能力涌现模式:
Model
BAGEL 采用了MoT 架构,包括两个 Transformer experts,一个负责理解,一个负责多模态生成。两个 experts 通过每层共享的 self-attn 处理相同的 token序列。对于预测不同模态的 token,模型采用了不同的方法:
两个视觉 Encoder:一个用于理解 (捕获语义信息),一个用于生成 (捕获像素信息)。
两个 Transformer Expert 通过每一层的共享 Self-attention 操作在相同的 token sequence 上运行。
- 预测文本 token 时:BAGEL 遵循 Next-Token-Prediction 范式。
- 预测视觉 token 时:BAGEL 采用 Rectified Flow 方法。

模型设计
在之前的多模态理解生成统一模型中,有这么几种设计选择:
- 离散自回归。代表:Chameleon,Emu3,Janus-Pro,Janus,TokenFlow,VILA-U,Liquid
Quantized Autoregressive Model 方法利用 Next-Token-Prediction 范式来生成文本和视觉 token。
优势:可以直接利用现有的 LLM 基础设施。
劣势:Quantized Autoregressive Model 的视觉生成质量,在经验上不如基于 Diffusion 的模型。而且,推理延迟由于 Autoregressive 方法的顺序性质而受到影响。
- 外部扩散模型。代表:MetaMorph,MetaQuery,Emu2,Seed-X
这种方法是:LLM Backbone 结合外部扩散模型。这种设计通过轻量级的 Adapter 将预训练的 LLM/VLM 与 Diffusion Model 连接起来。LLM Backbone 自回归生成一组 latent token 作为 "semantic condition" 信号,然后由 Diffusion Model 借助它来生成图像。
优势:可以以最小的数据消耗表现出快速收敛性,在一些多模态生成和理解 Benchmark 上得到有竞争力的性能。
劣势:将 LLM Context 压缩到相对较少的 latent token 中。这个做法在理解和生成模块之间引入了明确的 Bottleneck,会带来信息损失的风险,尤其是在长上下文多模态推理中。这样的约束可能与大型基础模型的 scaling philosophy 相矛盾。
- 集成 Transformer。代表:JanusFlow,LLamaFusion,TransFusion
LLM 和 Diffusion Model 集成在单个 Transformer 中。在 Autoregressive Transformer (强大的理解/推理能力) 和 Diffusion Transformer (强大的视觉生成能力) 的互补优势的驱动下,使用共同的模型架构来实现这两种范式之间的无缝切换。
优势:在所有 Transformer Block 都可以有 Context,没有外部扩散模型方法的 Bottleneck,从而实现生成和理解模块之间的无损交互,更适合 scaling。
劣势:与外部扩散模型解决方案相比,需要更多的训练的计算。
BAGEL 认为统一模型有能力从大规模交错多模态数据中学习更丰富的多模态能力。为此,BAGEL 选择了 "集成 Transformer" 的方案,认为它在大规模训练设置中具有更大的潜力,且可以更好地作为长上下文多模型推理和强化学习的基础模型。
模型架构
Backbone
BAGEL 的 Backbone 继承自 LLM,decoder-only 的 Transformer 架构。作者选择 Qwen2.5 LLM 作为初始化,因为其卓越的性能。采用 RMSNorm 进行归一化,SwiGLU 激活,RoPE 进行位置编码,GQA 用于降低 KV cache。此外,按照图像/视频生成模型的常见做法在每个 attention block 中添加 QK-Norm,这个做法在稳定训练过程方面有效。
视觉编码器
- 理解编码器:使用 ViT Encoder 将像素转换为 token。采用具有固定 384 分辨率的 SigLIP2-so400m/14 初始化 ViT Encoder。在此基础上,首先插值位置编码,设置 \(980×980\) 作为最大输入尺寸,然后集成 NaViT,使其能够以原生纵横比处理图像。采用两层 MLP connector 来匹配 ViT token 和 LLM hidden state 的特征维度。
- 生成编码器:使用来自 FLUX 的预训练 VAE 将图像从 pixel space 转换到 latent space。latent representation 的下采样比为 8,latent channel 为 16,然后由 \(2×2 \) patch embedding 层处理以减少空间大小并匹配 LLM Backbone 的隐藏维度。VAE 模型在训练期间被冻结。
位置编码:BAGEL 在 ViT 和 VAE token 集成到 LLM Backbone 之前,对其加上 2D 位置编码。
Diffusion timestep 编码:遵循 CausalFusion,直接对 VAE token 加上 timestep embedding,而不是像 SD3,DiT 那样使用 AdaLN 操作。这种修改保留了性能,同时产生了更清晰的架构。
LLM 内部:text token,ViT token,VAE token 根据输入的模态结构交错。对于属于同一样本的 token,采用了 causal attention 机制的广义版本。这些 token 首先被划分为多个连续的 split,每个 split 都包含来自单个模态的 token (比如 text、ViT 或 VAE)。split 之间:一个 split 中的 token 可能关注前面 split 中的所有 token。split 内部:对 text token 采用 causal attention,对 visual token 保持 bidirectional attention。
Generalized Causal Attention
如下图
在训练期间,交错的多模态生成样本可能包含多个图像。对于每个图像,准备了3组 visual token:
- Noised VAE tokens:被 diffusion noise 加噪的 VAE latents,Rectified-Flow 训练使用,计算 MSE Loss。
- Clean VAE tokens:原始的不包含噪声的 VAE latents,在生成后续图像或文本标记时充当 Condition。
- ViT tokens:从 SigLIP2 Encoder 获得,可以有助于统一生成和理解交织数据的输入格式。而且,可以实证性地提高交错生成的质量。
对于交错图像或文本生成,后续图像或文本 token 可能 attend to 先前图像的 clean VAE tokens 和 ViT tokens,但不关注它们的 Noised VAE tokens。
对于交错多图像生成,采用 diffusion forcing 策略,将独立的 noise level 添加到不同的图像中。此外,为了增强生成一致性,遵循 CausalFusion 的做法,随机分组连续的图像,并在每个组内应用 full attention。每组内的噪声水平相同。
使用 PyTorch FlexAttention 实现广义因果注意力,比 naive scaled-dot-product attention 实现了约 2× 加速。推理过程中,广义因果注意力允许缓存生成多模态上下文的 key-value (KV) pairs,从而加速多模态解码。只存储干净的 VAE tokens 和 ViT tokens 的 KV pair。一旦图像完全生成,上下文中相应的 Noised VAE tokens 被它们的 Clean VAE tokens 替换。为了在交错推理中实现 classifier-free guidance,分别随机丢弃 text,ViT 和 clean VAE tokens (概率为 0.1、0.5 和 0.1)。

Transformer Design
BAGEL 比较了几种 Transformer 变体:标准 Dense Transformer、Mixture-of-Experts (MoE) 和 Mixture-of-Transformers (MoT) 架构。
- MoE 变体:只复制每个 Qwen2.5 LLM block 中的 FFN 作为 generation expert 的初始化。
- MoT 变体:复制 Qwen2.5 LLM 的所有可训练参数,来创建 generation expert。
BAGEL 模型中的 MoE 和 MoT 都使用 hard routing:新复制的 generation expert 专门处理 VAE tokens,而原来的 understanding expert 处理 text 和 ViT tokens。尽管与密集基线相比,MoE 和 MoT 架构将总参数计数增加了大约两倍,但 3 个模型变体在训练和推理期间都具有相同的 FLOPs。
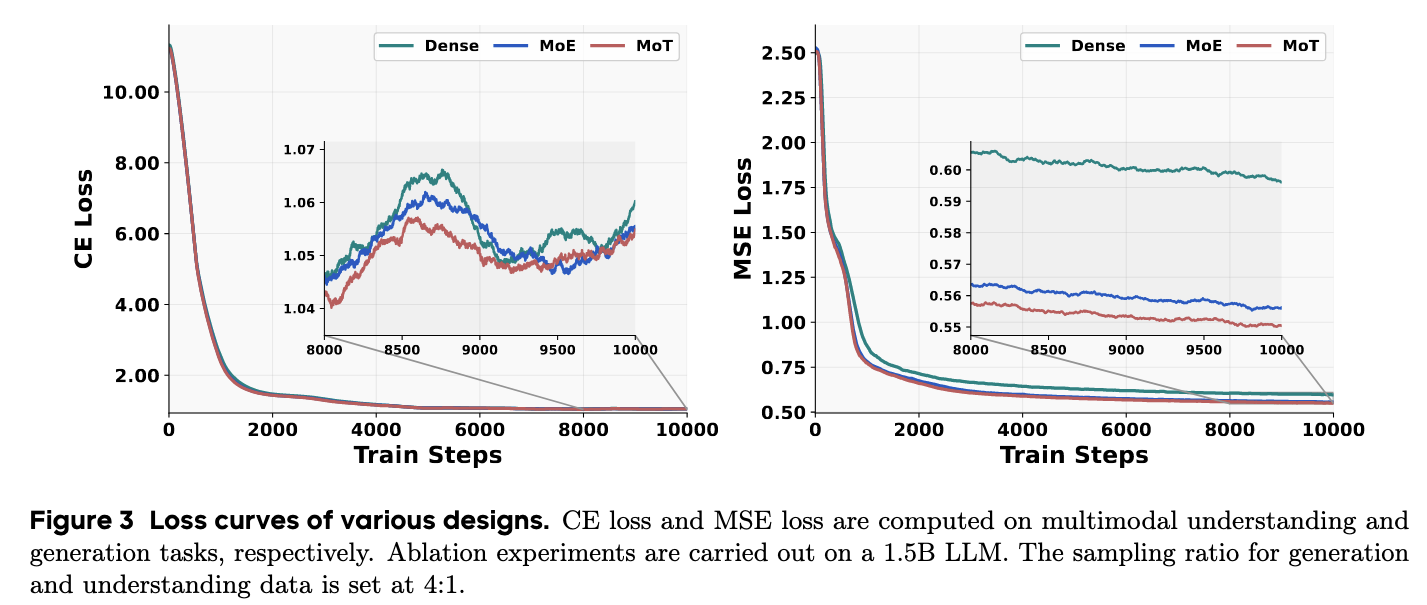
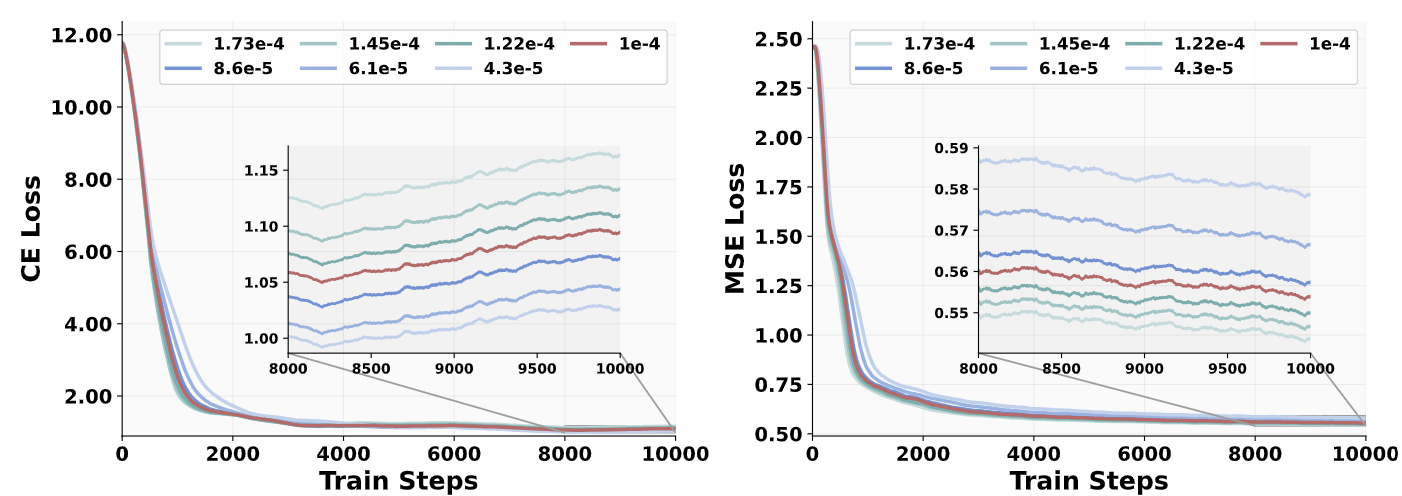
作者对 1.5B Qwen -2.5 LLM 进行了消融实验,将 Transformer 架构设定为唯一变量。如上图所示,MoT 始终优于 Dense 和 MoE,差距在多模态生成任务上最为明显。
对比左右图不难看出,MSE Loss (Generation) 表现出平滑单调递减的轨迹。其中,MoT 架构不仅收敛最快,而且最终损失最低。相比之下,CE Loss (Understanding) 表现出波动,这也是交错异构数据的预期结果。但 MoT 总体上仍然保持了最佳性能。
这些发现突出了将用于 Generation 和 Understanding 的参数解耦开的明显优势,两个目标可能会引导模型参数朝向不同的优化方向。
Data
数据定义了大模型的知识边界,BAGEL 在跨越多种模态 (包括语言、图像、视频和网络数据) 的多种数据集上进行训练,使其能够执行多模态推理、上下文预测、物理动力学建模和未来帧预测,所有这些都通过统一的多模态接口。除了标准的视觉语言 (VLM)、文生图 (T2I) 和语言模型 (LLM) 数据集之外,BAGEL 还从网络和视频源构建了新的视觉文本交错数据集,以进一步提高模型的顺序多模态推理能力。
下图总结了训练数据的规模和组成。
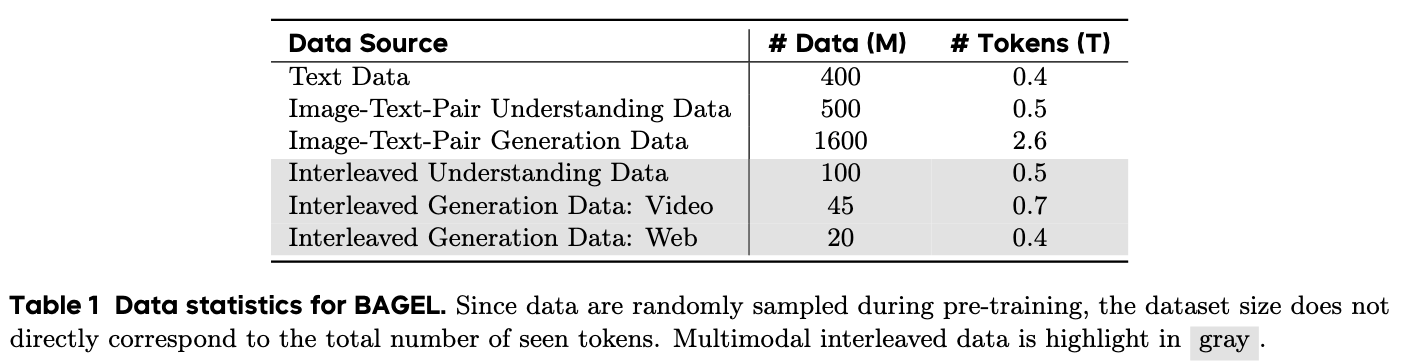
- 纯文本数据
为了保持 LLM 语言建模的能力,使用一组高质量的纯文本数据来补充训练语料库。这些数据语言覆盖广泛,在通用文本任务中实现强大的推理和生成能力。
- 图文对数据
图文对数据在多模态学习中起核心作用,为视觉语言模型和文生图提供了大规模的视觉监督。BAGEL 根据视觉-文本配对数据的下游使用将其组织成两个子集:一个用于 VLM 预训练,一个用于 T2I 生成。VLM 训练利用大规模的图文对,涵盖了广泛的视觉概念,主要来自 web 的替代文本和 caption。数据经历了基于 CLIP 的相似性过滤、分辨率和纵横比约束、文本长度检查和重复数据删除,以确保质量和多样性。文生图数据结合了高质量的图文对,以及一些来自现有 T2I 模型的合成数据。
- 图文交织数据
视觉-文本配对数据不能够支持涉及多个图像和中间文本的复杂上下文推理。在此类数据上训练的模型通常难以捕捉跨模态的视觉和语义关系,导致生成不太连贯。所以 BAGEL 在训练中引入了图文交织数据,以支持更丰富的多模态交互。
训练语料库集成了两个主要来源:视频数据和网络数据。
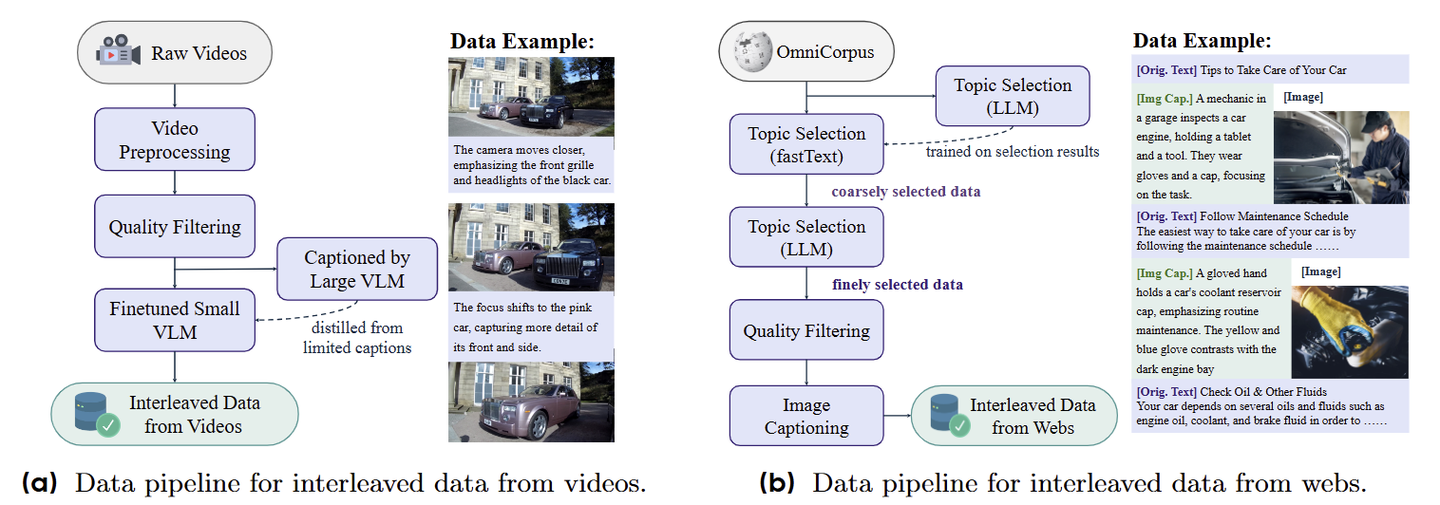
视频数据通过直接从现实世界中捕获时间和空间动态,提供丰富的世界知识。BAGEL 使用公开可用的在线视频资源以及两个开源数据集构建我们的视频数据集:Koala36M (提供大规模的教学和交互丰富的内容),MVImgNet2.0 (包含从不同相机视点捕获的对象以支持多视图空间理解)。
Web 数据捕获复杂的现实世界多模态结构,并提供跨越广泛领域的各种知识。它包括自然交错的资源,例如百科全书文章、逐步视觉教程和其他丰富的接地文档。这种交错格式为训练模型执行多模态推理提供了丰富的监督。BAGEL 基于 OmniCorpus (一个从 Common Crawl 预处理的大规模数据集,提供大量具有交错文本和图像的网络文档)。
图文交织数据的组成主要有两部分:从视频获得交错数据,以及从网站获得交错数据。BAGEL 通过这两个做法分别构造了 45M 和 20M 交错数据。如下图所示。
- 推理增强数据
BAGEL 假设在图像生成之前引入推理步骤可以有助于讲清楚视觉目标,并且构建了 500k 个推理增强的例子。
Training
BAGEL 使用多阶段训练策略:
- Alignment 阶段:把 SigLIP2 ViT encoder 和 Qwen2.5 LLM 对齐,只训练 MLP connector,把 vision encoder 和语言模型冻结。这个阶段仅使用图像-文本对数据,每个图像被调整为 378×378 的固定分辨率以匹配 SigLIP2 的输入大小。
- Pre-training 阶段:除了 VAE 之外,所有模型参数都打开训练。这个阶段的训练资料包括 2.5T tokens,涵盖了 text,image–text pairs,multimodal conversation,web-interleaved,video -interleaved 数据。这个阶段采用原生分辨率策略进行多模态理解和生成,对每张图像的最大长边和最小短边都有限制。
- Continued Training 阶段:这个阶段增加了视觉输入分辨率。进一步增加了交错数据的采样率,以强调学习跨模态推理,因为模型的核心理解和生成能力变得更加稳定可靠。CT 阶段消耗大约 2.6T tokens。
- Supervised Fine-tuning 阶段:对于多模态生成,从图像-文本对数据集和交错生成数据集中构建了一个高质量子集。对于多模态理解,从 LlaVA-OV 和 Mammoth-VL 的 SFT 数据中过滤一个子集。这个阶段训练 token 的总数是 72.7B。
与 VLM 或 T2I 模型的预训练不同,统一的多模态预训练需要仔细调整数据采样率和学习率,以平衡来自理解和生成任务的信号。
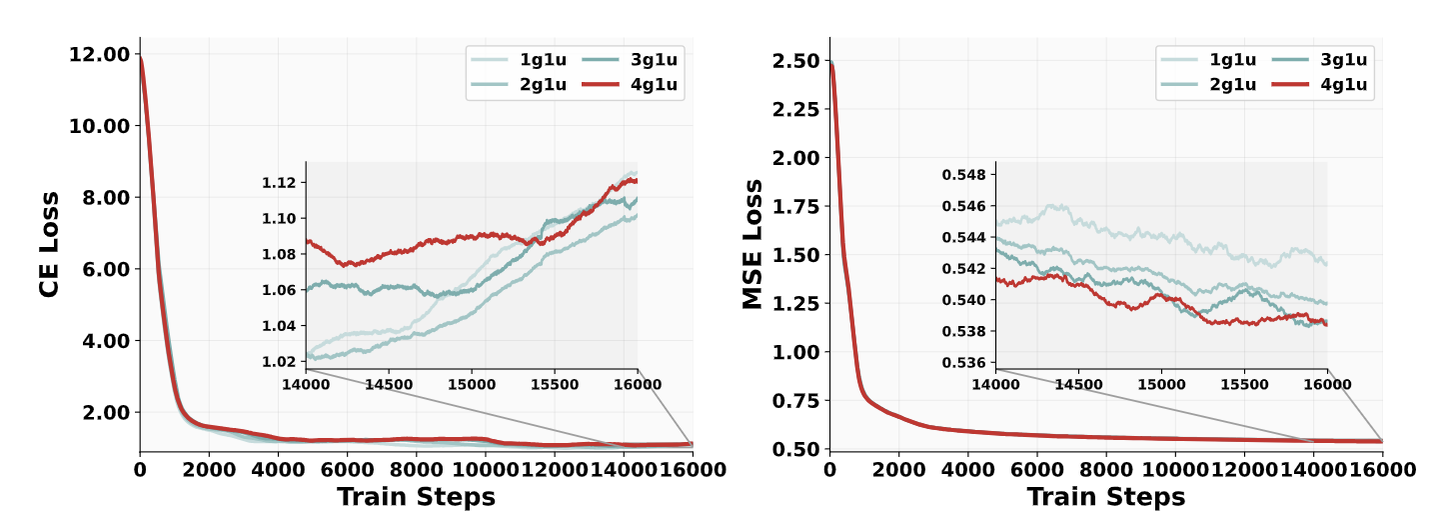
数据采样率
作者对 1.5B Qwen2.5 LLM 进行了一系列消融实验。如下图所示,将生成数据的采样率从 50% (1g1u) 增加到 80% (4g1u) 稳步降低 MSE Loss。相比之下,CE Loss 在采样率之间没有表现出一致的模式。在 4g1u 和 2g1u 之间,观察到的差距最大,在 14,000 step 处为 0.07,对下游任务的影响可以忽略不计。这些发现表明,生成示例应该比理解示例更频繁地采样。
学习率
如下图所示,这两种损失的行为相反:较大的学习率使 MSE Loss 收敛得更快,而较小的学习率有利于 CE Loss。为了调和这种权衡,将单独的权重因子分配给两个目标。
涌现能力
涌现能力 (Emerging ability) 指的是:如果某种能力在模型训练的早期没有出现,但在模型训练的后期出现了,那就可以说它是一种涌现能力。
这种定性转变通常被称为相变 (phase transition),表示模型行为发生了突然和戏剧性的变化,而且这种行为也无法通过训练损失曲线来预测。BAGEL 在统一模型中观察到类似的现象。因此,BAGEL 就通过评测一系列的历史 checkpoint 来检验模型能力的出现。具体来讲作者报告了 VLM benchmark (评测理解),GenEval 分数 (评测生成),GEdit 分数和 IntelligentBench 分数。这几个指标一起评估模型在简单和复杂的多模态推理方面的能力。
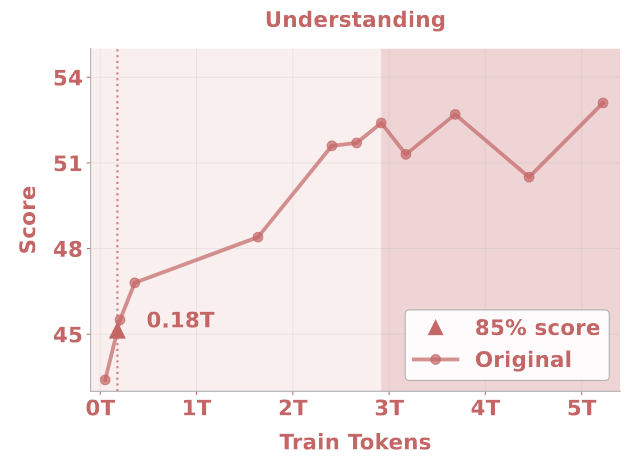
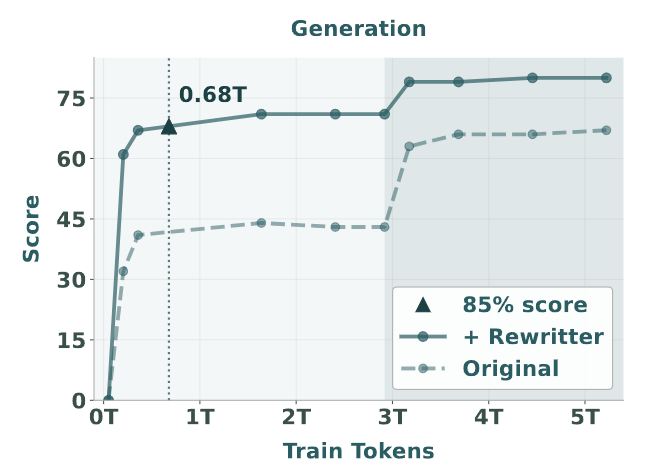
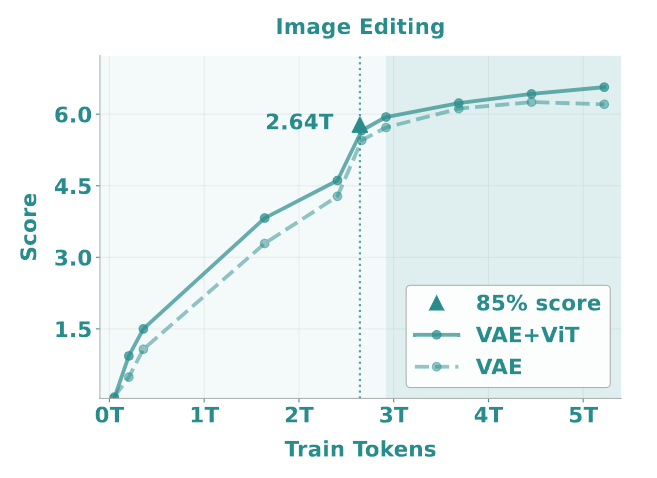
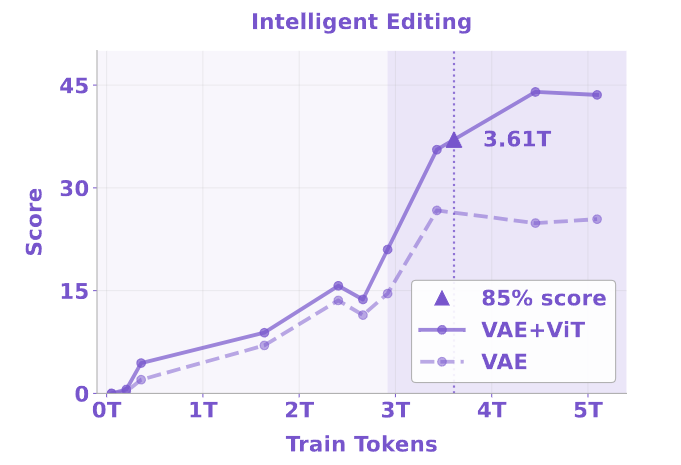
不同的任务表现出不同的学习动力学和饱和行为。如果选择达到 85% 峰值性能所需的可见 token 数量作为指标,如图 9-12 所示,发现传统的理解和生成任务达到饱和比较早:分别在大约 0.18T 和 0.68T token 处就达到了饱和。相比之下,既需要理解和生成能力的编辑任务表现出较慢的收敛,在 2.64T token 之后达到 85% 的性能。智能编辑任务 (消除了简单的编辑 case,强调复杂的多模态推理),需要 3.61T token 才能达到 85% 的性能。
下面的四张图 为 BAGEL 在不同任务上的预训练性能曲线。颜色较轻的区域代表低分辨率 Pre-training 阶段,颜色较暗的区域代表高分辨率 Continued Training 阶段。
随着 training token 数量的增加,BAGEL 表现出一致的改进。性能和训练规模之间的关系可总结如下:
- BAGEL 在各种任务中,随 training token 数量增加,性能持续改进。
- 不同的能力在不同的阶段涌现:理解和生成能力首先出现,然后是基本的编辑能力,最后才是更为智能的编辑能力。这些任务的复杂性也逐渐增加。
- 在图像编辑任务中,采用 VAE 和 ViT 特征,超过了单独使用 VAE 特征。尤其是在智能编辑中存在明显差距。这也支持了 ViT 提供重要的语义上下文来帮助生成的看法。
下图是对于涌现行为的定性研究结果。可以观察到与性能曲线一致的趋势:在看到 1.5T token 之前,生成质量已经很强,在看到 3.0T token 后质量略有提高,分辨率更高。对于文本渲染,生成正确拼写 "hello" 和 "BAGEL" 的能力在大约 1.5T 到 4.5T token 之间出现。
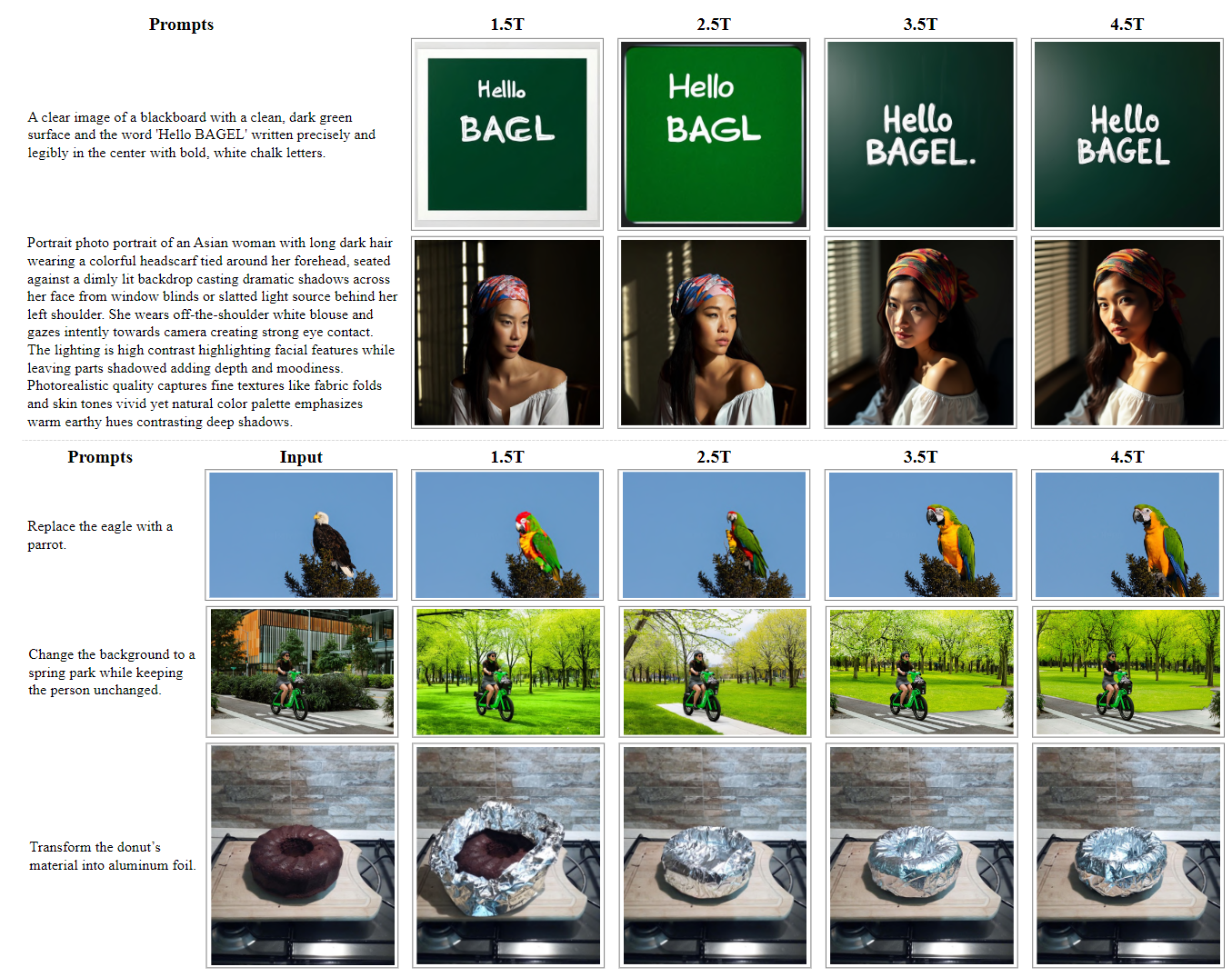
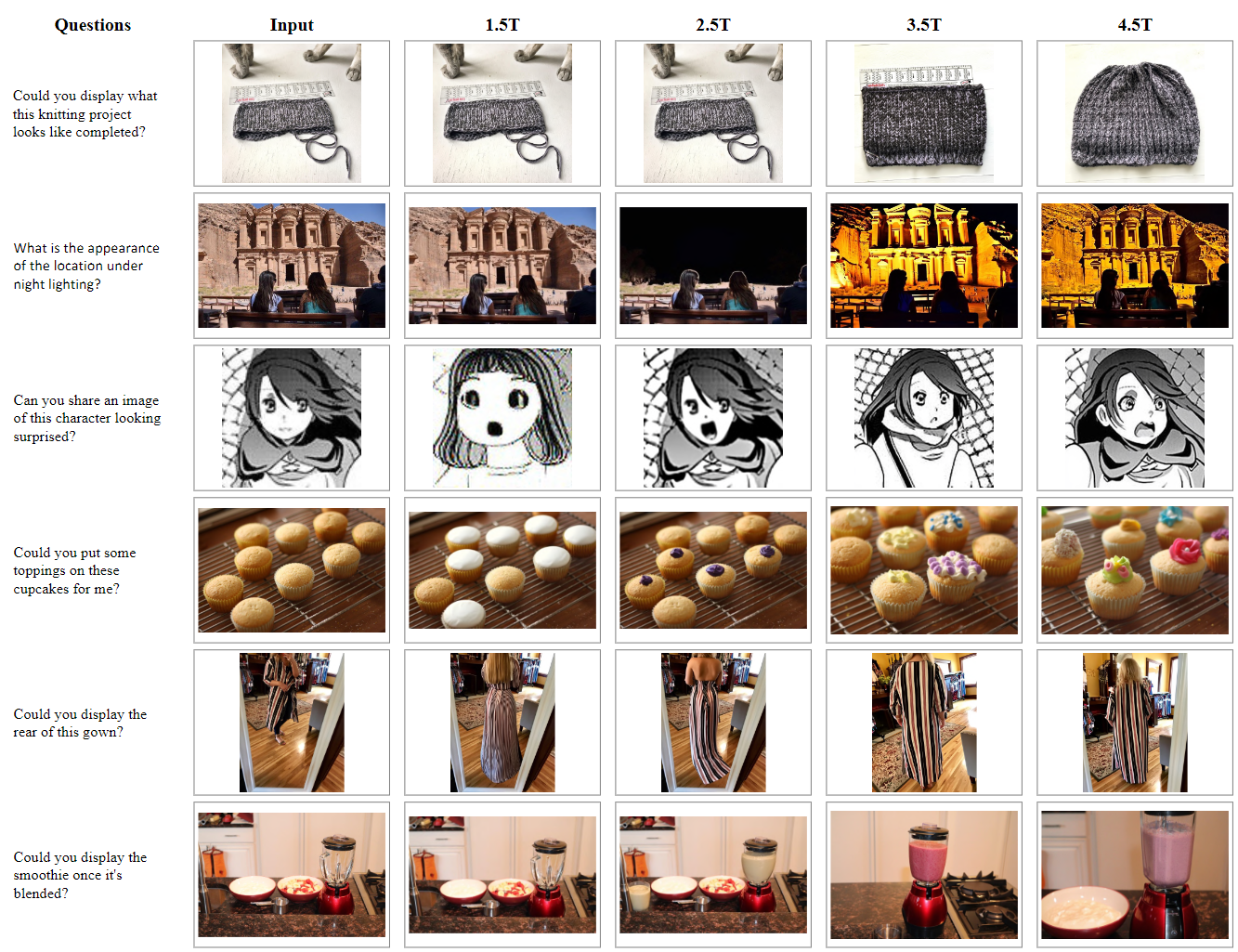
如下图所示是智能编辑任务的定性可视化,也可以观察到涌现行为。与图 13 的传统编辑 (只涉及对输入图像进行部分修改) 不同,智能编辑通常需要基于多模态推理生成全新的概念。在看到 3.5T token 之前,模型倾向于以最小的变化重现输入图像,这是一种任务没被完全理解的策略。在看到 3.5T token 后,模型开始展示清晰的推理,产生连贯且语义适当的编辑。
实验结果
作者在多模态理解、T2I 生成和经典图像编辑上评估了 BAGEL 模型。
视觉理解
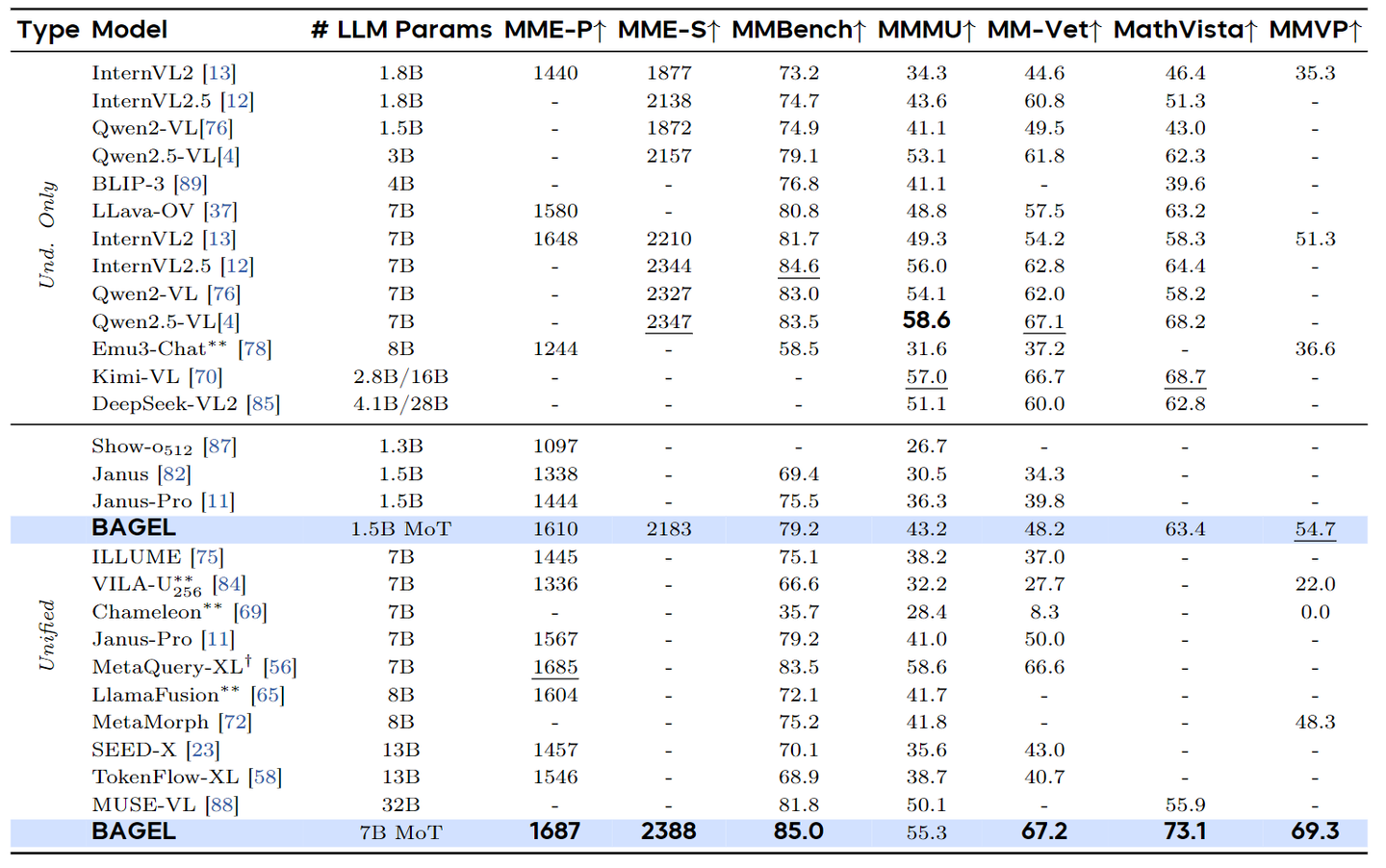
结果如下图所示。在 7B 的激活参数下,BAGEL 在理解任务上的表现优于现有的统一模型。比如,在 MMMU 和 MM-Vet 上分别比 Janus-Pro 实现了 14.3 和 17.1 个点的改进。值得注意的是,MetaQuery-XL 依赖于冻结的,预训练的 Qwen2.5-VL Backbone,限制了其适配度。此外,与 Qwen2.5-VL 和 InternVL2.5 等专门做理解的模型相比,BAGEL 在大多数这些基准上提供了卓越的性能。
视觉生成
BAGEL 在两个基准上评估视觉生成性能:GenEval 和 WISE。如下图所示,在与 MetaQuery-XL 相同的评估设置下,BAGEL 的总体得分为 88%,优于专门的生成模型 (FLUX-1-dev:82%、SD3-Medium:74%) 和统一模型 (Janus-Pro:80%,MetaQuery-XL:80%)。在 WISE 基准测试中,BAGEL 超过了除领先的私有模型 GPT-4o 之外的所有先前模型。这表明 BAGEL 具有很强的推理能力与世界知识。
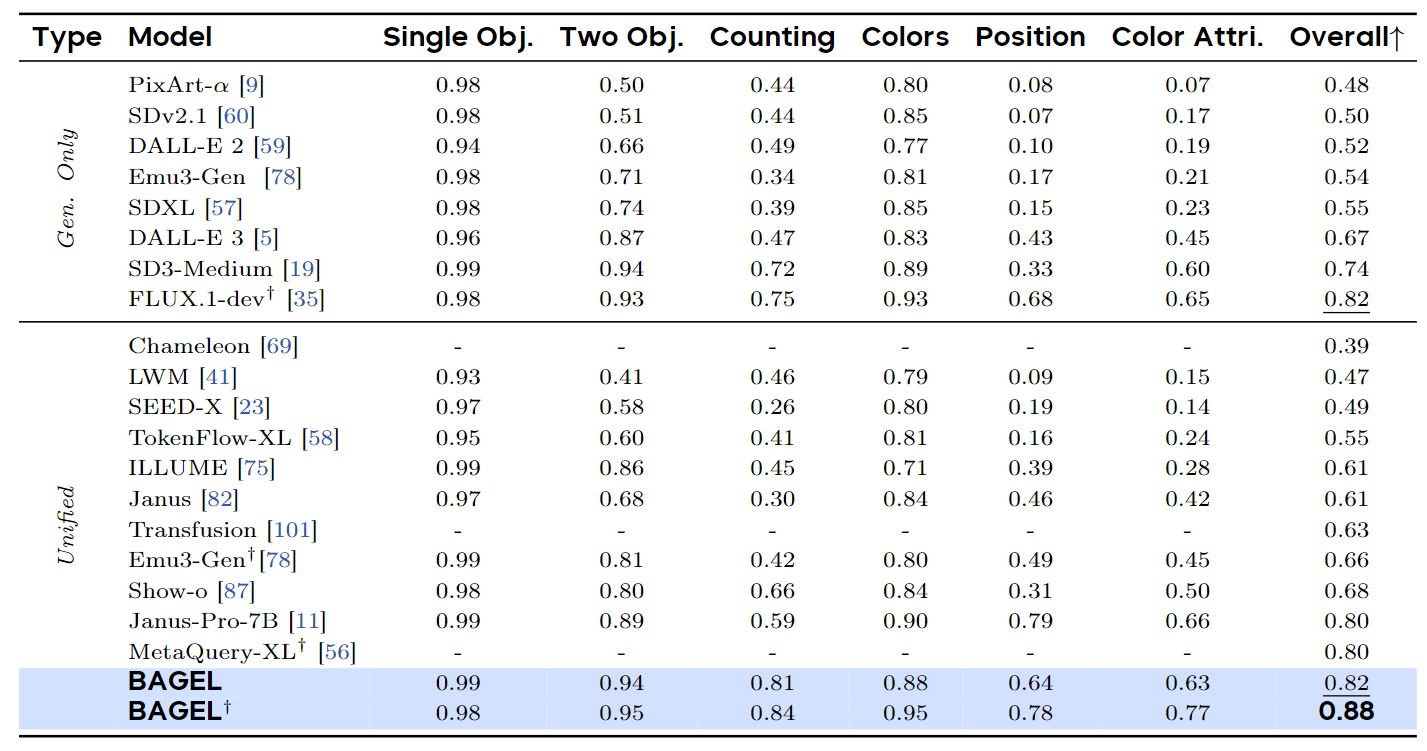
作者对 BAGEL 和 Janus -Pro 7B、SD3 -medium 和 GPT -4o 进行了定性比较。如下图所示,BAGEL 生成的图像明显好于 Janus -Pro 7B,并且还超越了广泛使用的文生图模型 SD3 -medium。

图像编辑
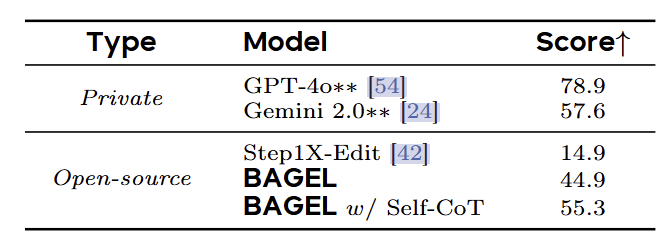
BAGEL 使用 GEdit-Bench 进一步评估了经典图像编辑能力。BAGEL 取得了与当前领先的专家图像编辑模型 Step1X-Edit 竞争的结果,也优于 Gemini 2.0。此外,作者报告了新提出的 IntelligentBench 的结果,其中 BAGEL 达到了 44.9 的性能,大大超过了现有的开源 Step1X-Edit 模型 30。如下两张图所示
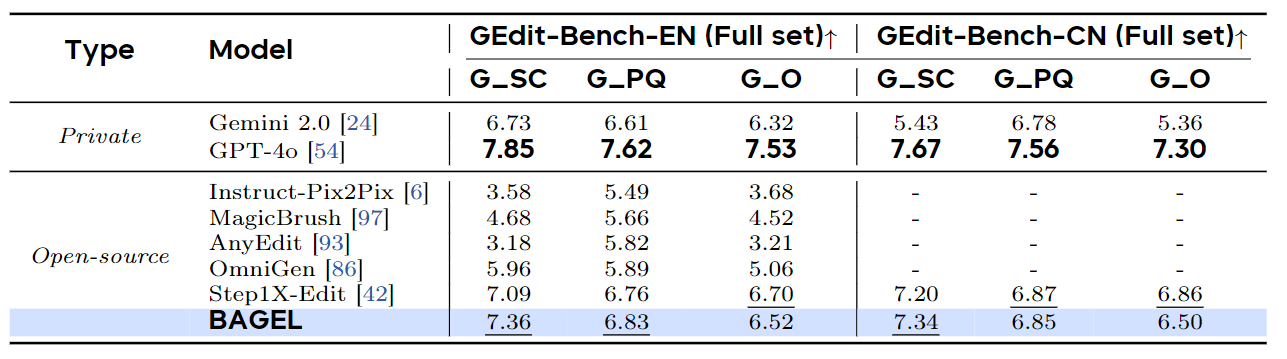
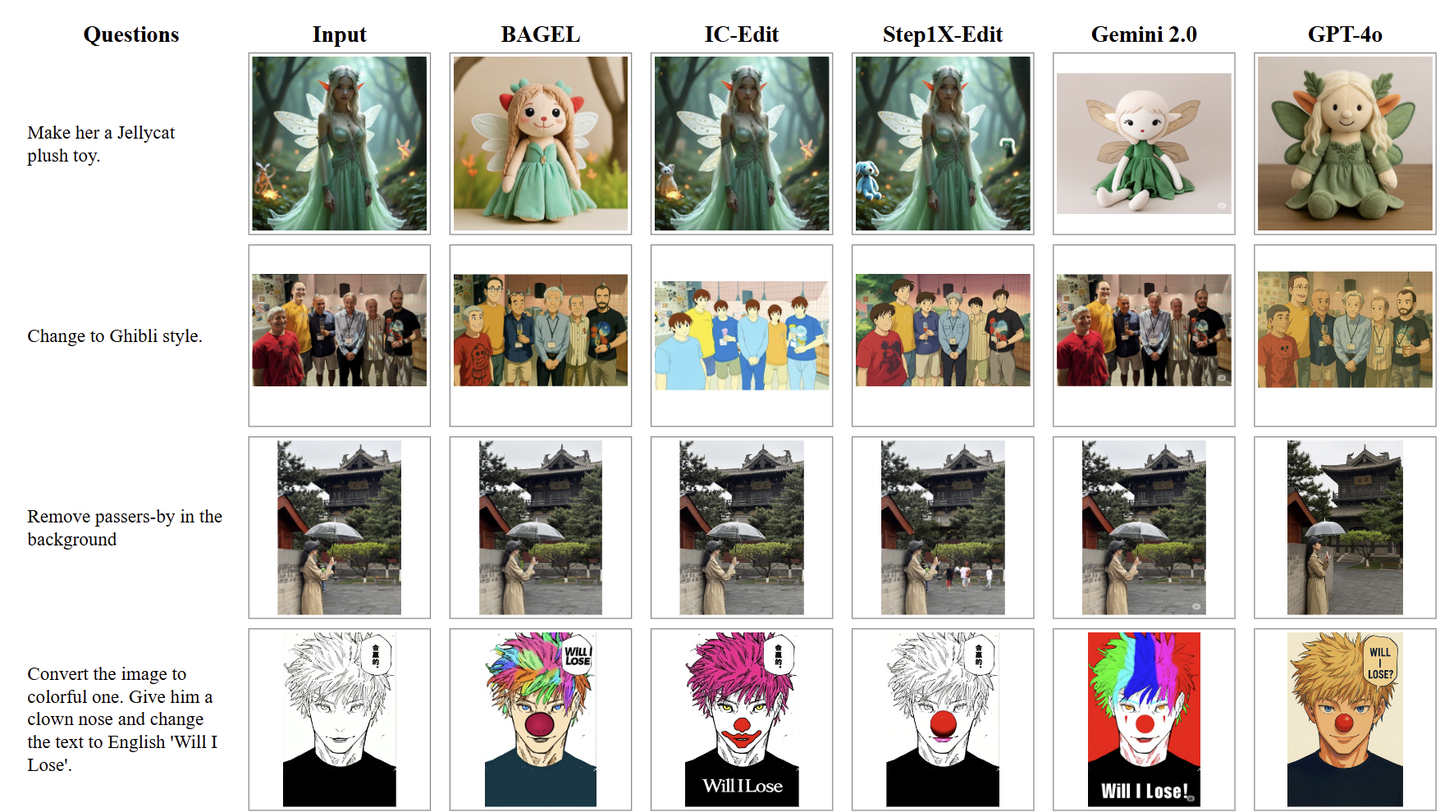
作者还在一组不同的图像编辑场景中提供了定性比较,将 BAGEL 与 Gemini 2.0、GPT-4o、Step1X-Edit 和 IC-Edit 进行基准测试。BAGEL 始终表现出比 Step1X-Edit 和 IC-Edit 更好的性能,并且还超过了 Gemini 2.0 的能力。虽然 GPT-4o 成功地处理了这些场景,但它往往会对源图像引入意想不到的修改,但 BAGEL 有效地避免了这个问题。

带有思考过程的生成和编辑
文生图
对于文生图任务,作者在 WISE 上评估 BAGEL,在生成之前使用 CoT 推理过程。如下图所示,具有 CoT 的 BAGEL 得分为 0.70,比其非 CoT 高出 0.18,并且还大大优于所有现有的开源模型 (之前的 SOTA: 0.55 的 MetaQuery-XL)。
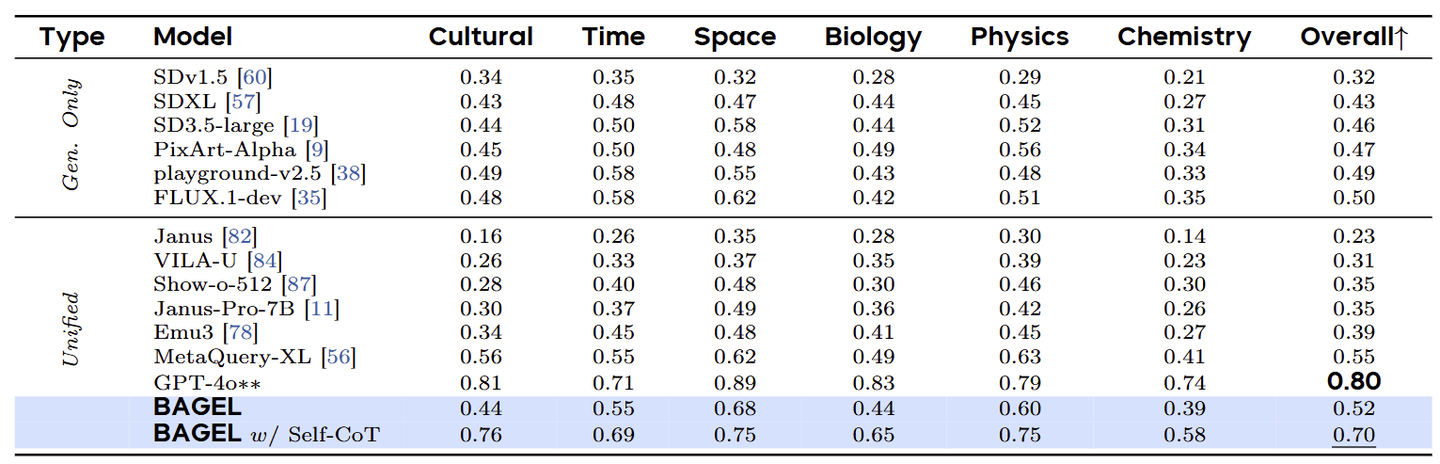
除了定量评估之外,下图中提供了可视化,BAGEL 在给出短提示时无法生成正确的图像,但在使用基于 CoT 的思维范式时成功了。

图像编辑
如下图所示,将 CoT 合并到 BAGEL 中将其 Intelligent Score 从 44.9 提高到 55.3。性能提升主要归因于推理的加入,使模型能够利用世界知识并提供详细的编辑指导。作者进一步说明了来自 IntelligentBench 的几个代表性案例,其中任务需要一般性的知识或者多步推理。在这些情况下,BAGEL 在表现出了显著改进的图像编辑能力。

失败案例
下图展示了 BAGEL 与其他先进模型相比的代表性失败案例。


涉及某些 IP、复杂文本、反事实场景、对象交换和去模糊的任务对 BAGEL 等模型提出了挑战。相比之下,GPT-4o 在这些场景中表现得最好。