简介
"Anchor-free"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster R-CNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchor-free"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。
以下是对"anchor-free"方法的一些关键理解点:
无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchor-free"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。
直接位置和形状回归: "anchor-free"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目标的中心和形状。这些热图和偏移信息通常通过卷积神经网络预测。
适用于不规则目标: 传统的锚框在捕捉不规则形状的目标时可能会有困难,而"anchor-free"方法可以更好地适应不规则目标的检测。
减少计算复杂性: 由于不需要生成大量锚框,"anchor-free"方法可能减少了计算复杂性,这对于实时目标检测任务很有帮助。
端到端训练: 通常,"anchor-free"方法可以实现端到端训练,模型可以直接从原始数据中学习目标检测任务,而不需要额外的处理。
一些常见的"anchor-free"目标检测方法包括CenterNet、CornerNet和Center-KeypointNet等。这些方法在不同的场景和应用中都取得了很好的效果,特别是在需要高效目标检测的任务中。但需要注意,每种方法的性能和适用性会根据具体情况有所不同,因此在选择目标检测方法时需要考虑任务的要求。
另一方面,基于锚框的方法涉及生成一组预定义的锚框(例如R-CNN中的RPN或SSD中的prior box),并根据这些锚框与真实框之间的差异进行位置回归。
引入锚框的方法具有以下优点:
1)它显著减少了计算复杂性,并将提案的数量控制在可管理的范围内,以便进行后续的计算和筛选。
2)通过调整不同的锚框设置,可以覆盖尽可能多的物体,并为不同的任务设置不同的锚框尺度范围。
3)由于锚框的尺度是人工定义的,物体的定位是通过锚框的回归来实现的,仅计算偏移量而不是精确位置,大大降低了优化的难度。
然而,基于锚框的方法也有一些局限性:
1)许多在Faster R-CNN之后发表的论文表明,通过使用更多不同尺寸和长宽比的锚框以及采用各种训练技巧,可以获得更好的结果。然而,通过增加计算能力来改进网络的方法往往难以在实际应用中实施(模型速度和大小)。
2)锚框的设置需要手动调整大量参数,并且离散的锚框尺度设置可能导致某些物体无法与任何锚框匹配,导致遗漏检测。
相比之下,基于锚框的方法需要生成一组预定义的锚框,并通过锚框与真实框之间的差异进行位置回归。基于锚框的方法可以显著减少计算复杂性,并调整锚框设置以适应不同尺度的物体。然而,基于锚框的方法需要手动调整参数,并且可能遗漏检测某些物体。
以下是一些"anchor-free"目标检测方法的简介:
- DenseBox: 使用单个FCN进行目标检测,通过多任务引入landmark localization来提升性能。
- CornerNet: 基于关键点的目标检测方法,通过预测物体的角点来实现检测。
- CenterNet: 基于物体中心点的目标检测方法,通过预测物体的中心点来实现检测。
- FCOS: 一种自适应正负anchor选择的目标检测方法。
- ATSS: 另一种自适应正负anchor选择的目标检测方法。
每种方法在不同场景和应用中取得了良好的效果,但具体选择哪种方法需要根据任务需求进行考虑。
请注意,以上内容仅为简要介绍,具体细节和性能可能因具体方法和实验设置而有所不同。更多详细信息可以参考各个方法的论文和相关资料。
Anchor-free工作
DenseBox
两点贡献:
1.证明单个FCN可以检测出遮挡严重、不同尺度的目标。
2.通过多任务引入landmark localization,能进一步提升性能。
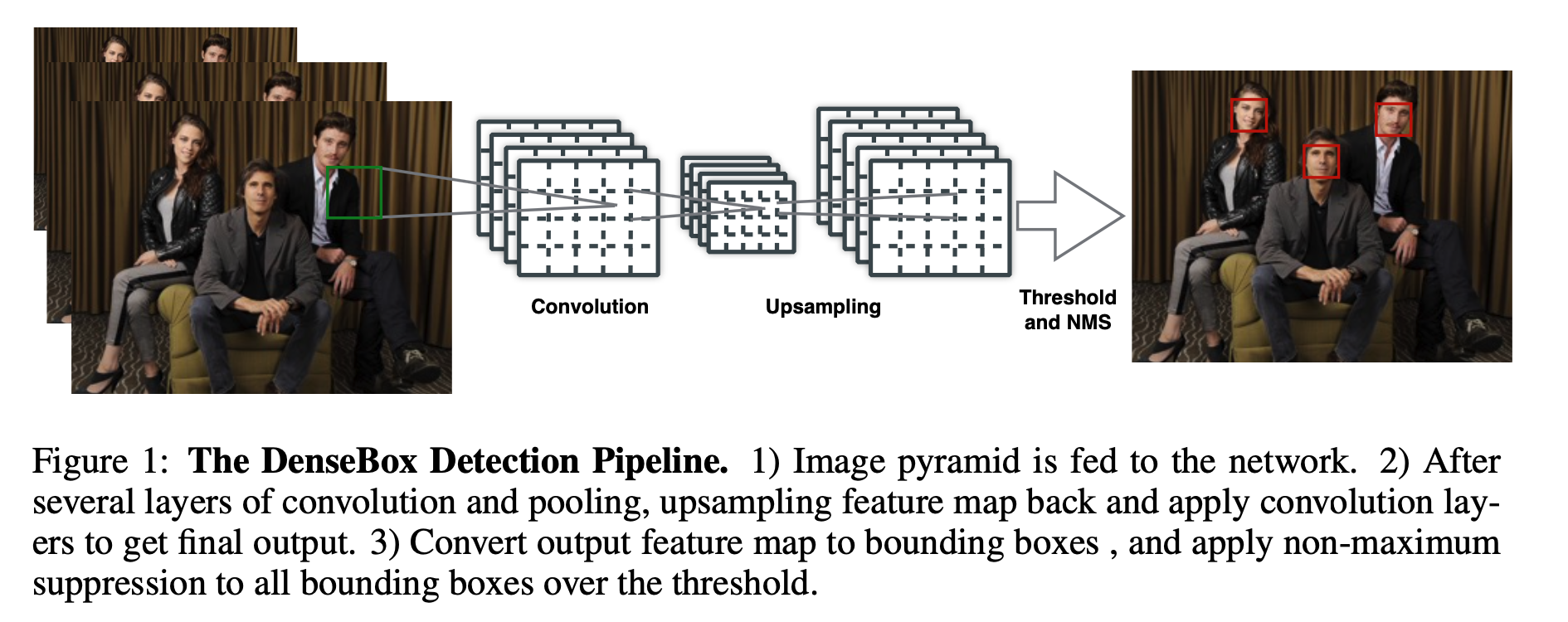
如图1所示,单个FCN同时产生多个预测bbox和置信分数的输出。测试时,整个系统将图片作为输入,输出5个通道的feature map。每个pixel的输出feature map得到5维的向量,包括一个置信分数和bbox边界到该pixel距离的4个值。最后输出feature map的每个pixel转化为带分数的bbox,然后经过NMS后处理。
Ground Truth Generation

如果直接使用整幅图片进行训练的话,会在反向传播时浪费大量时间,于是使用了一种策略,对输入图片进行裁剪包含人脸和丰富背景的patches(目标检测的数据增强),在训练阶段,这些patches被裁剪后resize到240x240,其中人脸区域大约50像素。因此最后的输出为60x60且5通道的张量,因此Ground Truth在构建时,也得是60x60x5的张量,其人脸区域由一个以人脸bounding box的中心为圆心且半径为0.3倍(paper setting)的bounding box size的圆形区域确定,这个东西与segmentation类似。现在看来思想很超前!
在GT的第一个通道,我们用0来进行初始化,如果包含在正样本区域,那么就设置为1。其他的4个通道由该像素点与box的左上角和右下角的距离来确定。对于多张人脸,如果他们落在patch center的一定范围内,那么这些人脸就是正样本,其余的均为负样本。
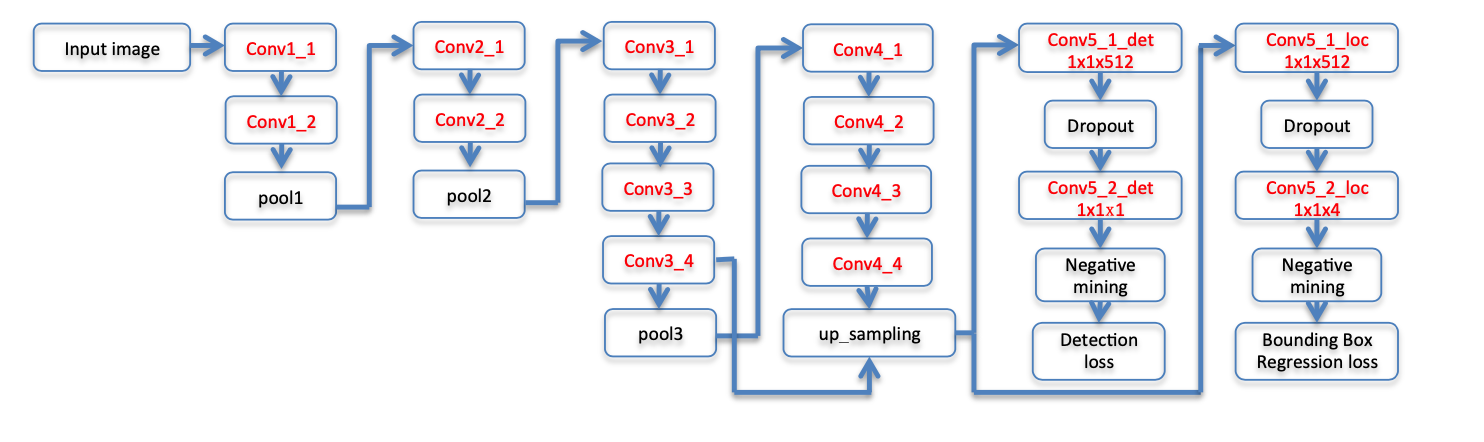
模型结构
使用了VGG19,由于进行了上采样,所以总体图像尺寸降了4倍!
Keypoint-based
FCOS
ATSS :
目标检测的自适应正负anchor选择