Preformer Performer的出发点还是标准的Attention,所以在它那里还是有 [Math] ,然后它希望将复杂度线性化,那就是需要找到新的 [Math] ,使得: [公式] 如果找到合理的从 [Math] 到 [Math] 的映射方案,便是该思路的最大难度了。 激活函数 线性Attention的常见形式如 式3,其中 [Math] 、 [Math] 是值域非负的激活函数。那么如何选取这个激活函数呢?Performer告诉我们,应该选择指数函数 [公式] 首先,我们来看它跟已有的结果有什么不一样。在 Transformers are RNNs 给出的选择是: [公式] 我们知道 1+x 正是 e^x 在 x=0 处的一阶泰勒展开,因此 [Math] 这个选择其实已经相当接近 ...
NLP
2026-01-11

简介 承接 Transformers are RNNs 这篇论文 目的: 为了分析之前linear transformer的效果为什么不好。发现主要是两个原因造成的: 1. 无界梯度(unbounded gradient),会导致模型在训练时不稳定,收敛不好; 1. 注意力稀释(attention dilution),transformer在lower level时应该更关注局部特征,而higher level更关注全局特征,但线性transformer中的attention往往weight 更均匀化,不能聚焦在local区域上,因此称为attention稀释。 解决方案: 1. 对linear attention算出来的output接着做个normalization,形成NormForme...
01背包 描述 有N件物品和一个容量为V的背包。 第i件物品的体积是vi,价值是wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包流量,且总价值最大。 二维动态规划 f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值最大是多少。 result = max(f[n][0V]) f[i][j]: 不选第i个物品:f[i][j] = f[i1][j]; 选第i个物品:f[i][j] = f[i1][jv[i]] + w[i](v[i]是第i个物品的体积) 两者之间取最大。 初始化:f[0][0] = 0 代码如下: [代码] 一维动态优化 从上面二维的情况来看,f[i] 只与f[i1]相关,因此只用使用一个一维数组[0v]来存储前一个状态。那么如何来实现呢? 第一个问题:状...
Algorithm
2026-01-11
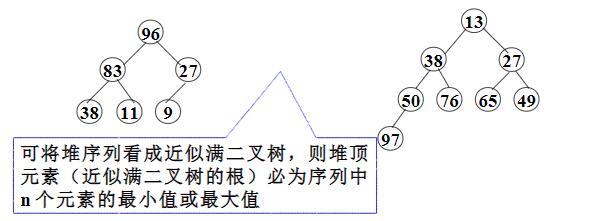
起步 heapq 模块实现了适用于Python列表的最小堆排序算法。 堆是一个树状的数据结构,其中的子节点都与父母排序顺序关系。因为堆排序中的树是满二叉树,因此可以用列表来表示树的结构,使得元素 N 的子元素位于 2N + 1 和 2N + 2 的位置(对于从零开始的索引)。 本文内容将分为三个部分,第一个部分简单介绍 heapq 模块的使用;第二部分回顾堆排序算法;第三部分分析heapq中的实现。 heapq 的使用 创建堆有两个基本的方法:heappush() 和 heapify(),取出堆顶元素用 heappop()。 heappush() 是用来向已有的堆中添加元素,一般从空列表开始构建: [代码] 如果数据已经在列表中,则使用 heapify() 进行重排: [代码] 回顾堆排序算...
计数排序、基数排序、桶排序则属于非比较排序,算法时间复杂度O(n),优于比较排序。但是也有弊端,会多占用一些空间,相当于是用空间换时间。 1. 计数排序: 计数排序的基本思想是:对每一个输入的元素a[i],确定小于 a[i] 的元素个数。所以可以直接把 a[i] 放到它输出数组中的位置上。假设有5个数小于 a[i],所以 a[i] 应该放在数组的第6个位置上。 实现代码如下: [代码] 2. 桶排序: 桶排序的基本思想是:把数组a划分为n个大小相同子区间(桶),每个子区间各自排序,最后合并。桶排序要求数据的分布必须均匀,不然可能会失效。计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。 [代码] 算法实现步骤 1. 根据待排序集合中最大元素和最小元素的差值范围和映...
Algorithm
2026-01-11
题目说明 在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 示例 1: 输入: [3,2,1,5,6,4] 和 k = 2 输出: 5 示例 2: 输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 输出: 4 题解 使用快排的思想 [代码]
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...
💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回left还是right; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid 1] 就对应 right = mid 1,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划...
Computer Vision
2026-01-11

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 One stage TwoStage Anchor Free Transformer Problems
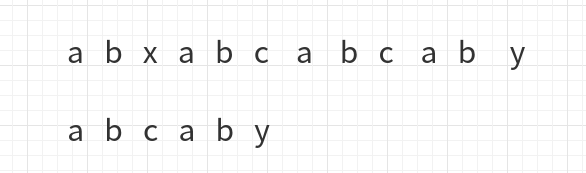
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如abababc那么bab在其位置1处,bc在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(mn)。kmp算法保证了时间复杂度为O(m+n)。 基本原理 举个例子: 发现x与c不同后,进行移动 a与x不同,再次移动 此时比较到了c与y, 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前,y与c对齐,但是y前边的ab是与自己的前缀ab一样,于是ab并不用再比较,直接从第三个位置开始比较,如图: 所以说kmp算法对于这种情况就直接使用当前比较字符之...