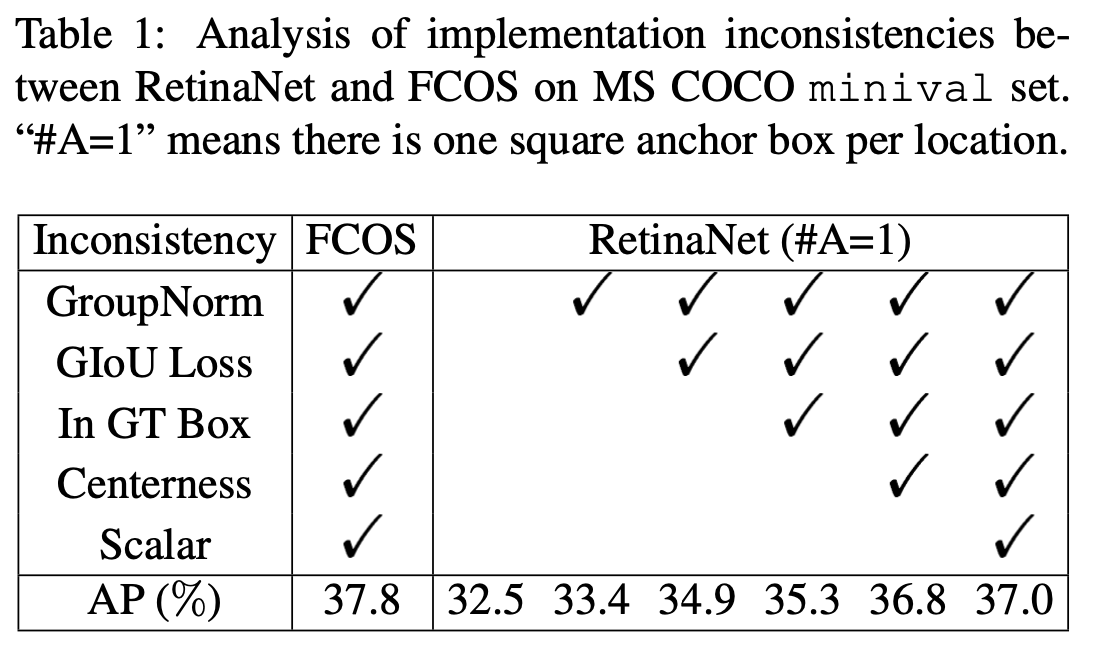
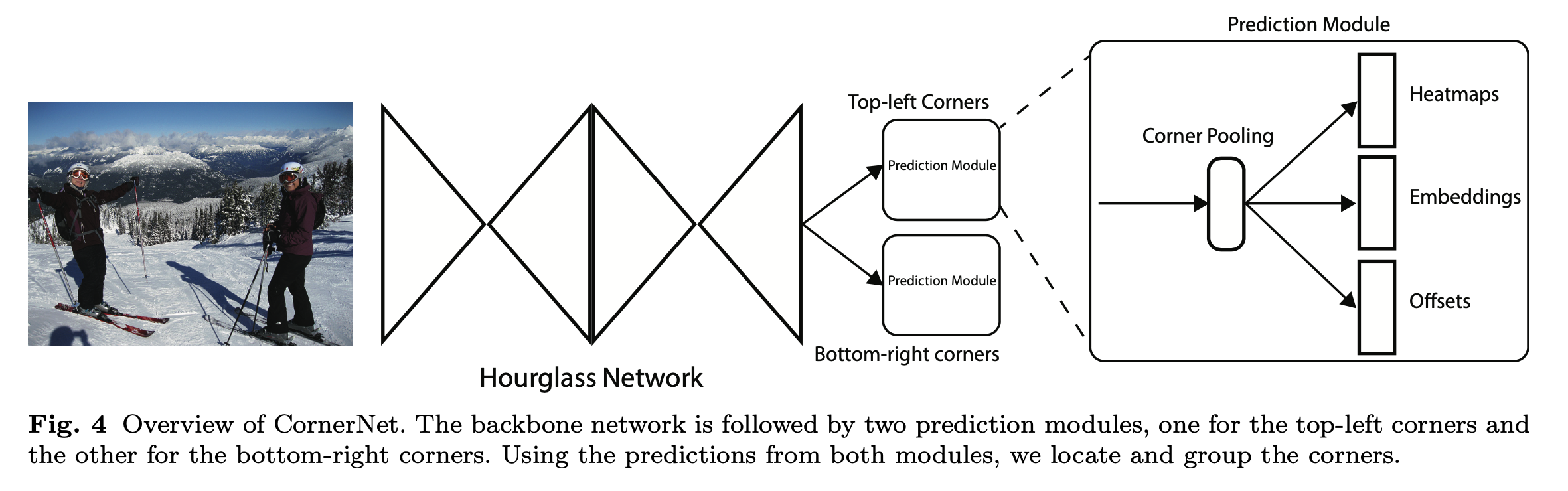
Computer Vision
2026-01-11

NMS 过程: 1. 根据分类概率从小到大排序ABCDEF 1. 从最大概率F开始,F与A~E的IOU是否大于阈值 1. 大于的扔掉,从剩下的当中继续重复2~3 [代码] SoftNMS NMS算法保留score最高的预测框,并将与当前预测框重叠较多的proposals视作冗余,显然,在实际的检测任务中,这种思路有明显的缺点,比如对于稠密物体检测,当同类的两个目标距离较近时,如果使用原生的nms,就会导致其中一个目标不能被召回,为了提高这种情况下目标检测的召回率,SoftNMS应运而生。对于FasterRCNN在MSCOCO数据集上的结果,将NMS改成SoftNMS,mAP提升了1.1%。 它认为重叠较多的proposals也有可能包含有效目标,只不过重叠区域越大可能性越小。参见下图,NMS...