kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如abababc那么bab在其位置1处,bc在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(mn)。kmp算法保证了时间复杂度为O(m+n)。 基本原理 举个例子: 发现x与c不同后,进行移动 a与x不同,再次移动 此时比较到了c与y, 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前,y与c对齐,但是y前边的ab是与自己的前缀ab一样,于是ab并不用再比较,直接从第三个位置开始比较,如图: 所以说kmp算法对于这种情况就直接使用当前比较字符之...
Deep Learning
2026-01-11

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址:https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮...
Algorithm
2026-01-11
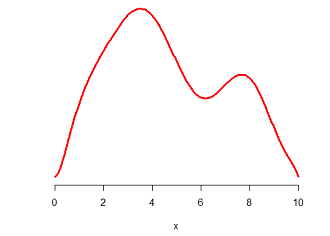
题意 给定平面上一个圆的圆心位置和半径,从圆中以均匀的概率随机选取点。 分析 拒绝取样 其实我的第一反应是用拒绝取样(Rejection Sampling)的思路来做:首先从这个圆的与坐标轴平行的外切正方形中均匀随机选取点,然后判断点是否位于圆中;如果不在,重新生成一个新的点,再次进行判断;否则直接返回。 直觉上来说,拒绝取样显然是正确的;不过我们可以用一种稍微更加形式化的方法来描述。(以下内容参考了拒绝采样(reject sampling)的简单认识,非常直观形象。) 下图是一个随机变量的密度函数曲线,试问如何获得这个随机变量的样本呢? 如果你像我一样,已经把概率论与数理统计统统还给数学老师了,那么提示一下,概率密度函数(PDF)是累积分布函数(CDF)的导数,反映的是概率的“密集程度”。...
Algorithm
2026-01-11
根据一棵树的先序遍历和中序遍历,或者后序遍历和中序遍历序列,都可以唯一地确定一棵树。 树中的节点,分为度为0,1,2的结点。如果树中只有一个节点,那么可以唯一确定一棵树,即只有一个节点的树。 当树中结点个数大于等于2的情况,树中的叶子结点和它的父亲结点中,至少有一种存在如下的情况。(为方便起见,我们先从叶子节点入手) case 1: case2: case 3: A D F / \ / \ B C E G 即,叶子结点的父亲有两个孩子,只有左孩子,只有右孩子的情况。我们只需要证明,如果树存在这三种结构中的哪一种,可以唯一确定一棵树,什么情况下又不能唯一确定一棵树呢? 1. case 1: A / \ B C 前序遍历: ABC, 后序遍历: BCA 现在,我们根据遍历序列,看看能否得到另一种...
Computer Vision
2026-01-11
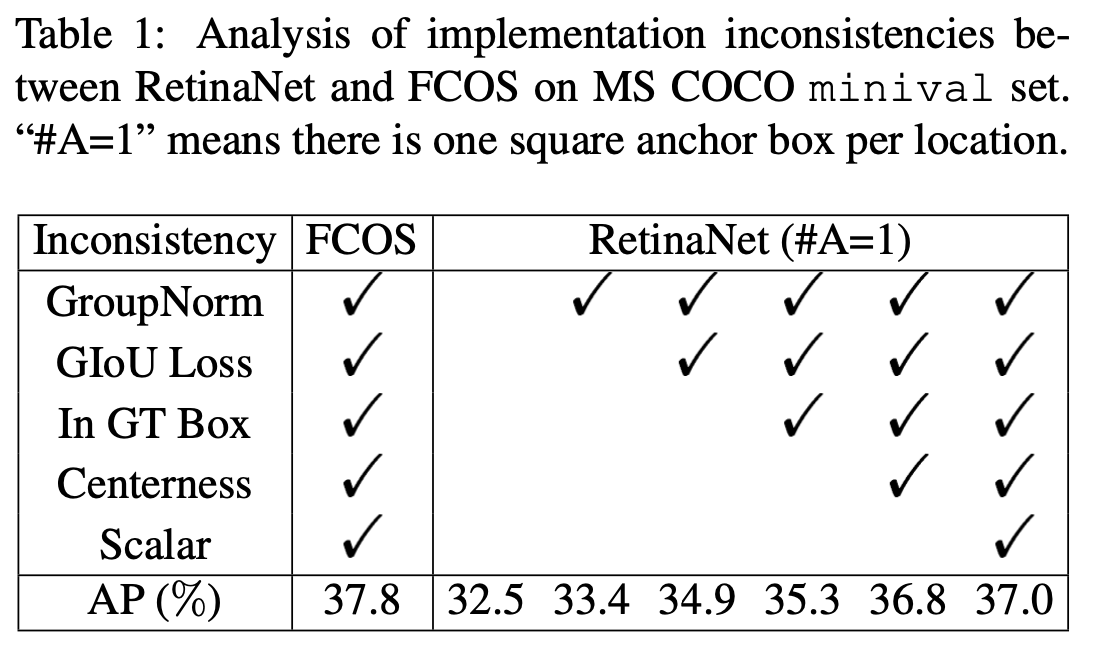
Introduction 由于FPN和Focal loss 的加入,anchorfree模型变得越来越多。在仔细比对了anchorbased和anchorfree目标检测方法后,结合实验结果,论文认为两者的性能差异主要来源于正负样本的定义,假如训练过程中使用相同的正负样本,两者的最终性能将会相差无几。 作者将目前的Anchorfree分为两个大类: 1. keypointbased methods:以CornerNet和ExtremeNet为代表,首先定位几个预定义或自学习的关键点,然后限制物体的空间范围; 1. centerbased methods:以FCOS和Foveabox为代表,使用物体的中心点或区域定义基准点,然后预测从该点到物体边界的四个距离。 为此,论文提出ATSS( Ada...
Computer Vision
2026-01-11
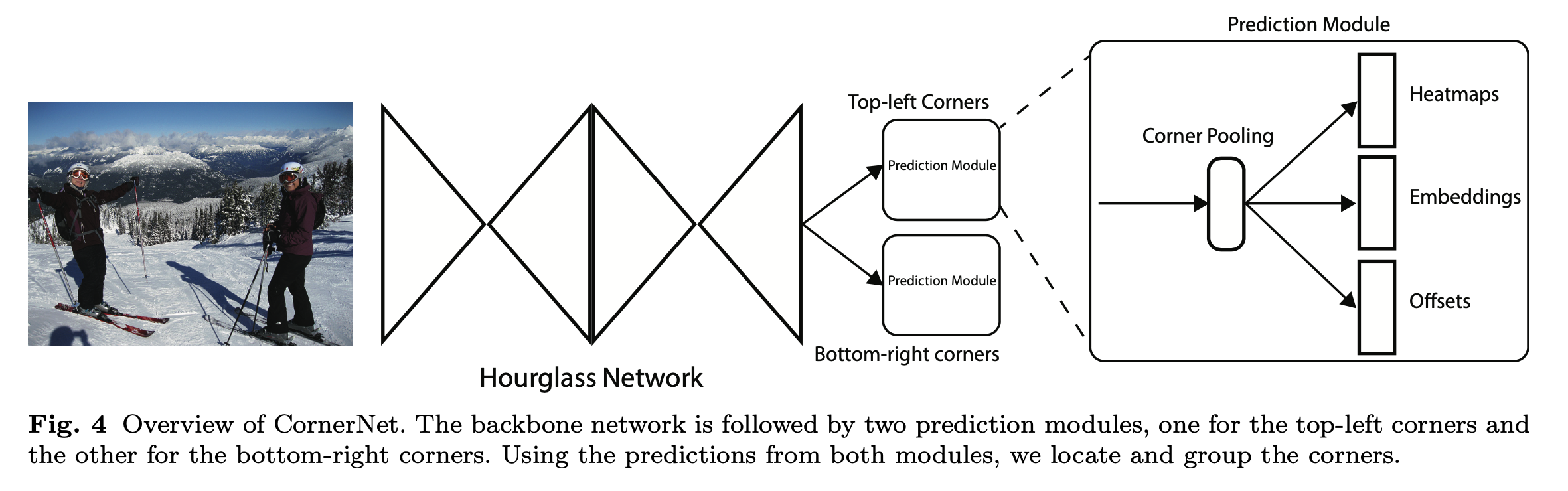
简介 CornerNet是密歇根大学Hei Law等人在发表ECCV2018的一篇论文,作者总结目前anchorbased方法存在两个缺点: 1. 提取的anchor boxes数量较多,比如DSSD使用40k, RetinaNet使用100k,anchor boxes众多造成anchor boxes正负样本的不均衡; 1. anchor boxes需要调整很多超参数,比如anchor boxes数量、尺寸、比率,影响模型的训练和推断速率。 作者的思路其实来源于一篇多人姿态估计的论文"Endtoend learning for joint detection and grouping"。基于CNN的2D多人姿态估计方法,通常有2个思路(BottomUp Approaches和TopDown ...
Computer Vision
2026-01-11
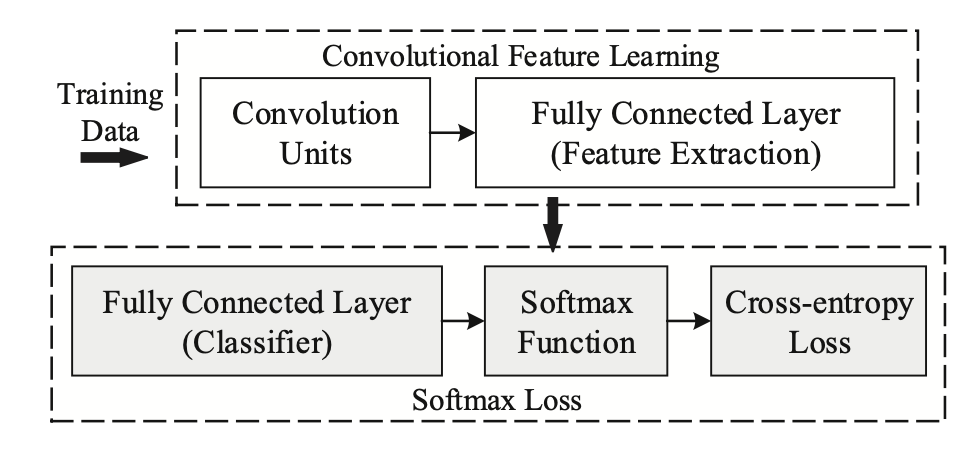
近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上;本文从两种主要的改进方式——做归一化以及增加类间 margin——展开梳理,介绍了近年来基于 Softmax 的 Loss 的研究进展。 Softmax简介 Softmax Loss 因为其易于优化,收敛快等特性被广泛应用于图像分类领域。然而,直接使用 softmax loss 训练得到的 feature 拿到 retrieval,verification 等“需要设阈值”的任务时,往往并不够好。 这其中的原因还得从 Softmax 的本身的定义说起,Softmax loss 在形式上是 softmax 函数加上交叉熵损失,它的目的是让所有的类别在概率空间具有最大的对数似然,也就是保证所有的类别都能分类正确,...
Computer Vision
2026-01-11

Motivation 我们知道object detection的算法主要可以分为两大类:twostage detector和onestage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。作者提出focal loss的出发点也是希望onestage detector可以达到twostage detector的准确率,同时不影响原有的速度。 既然有了出发点,那么...
Computer Vision
2026-01-11
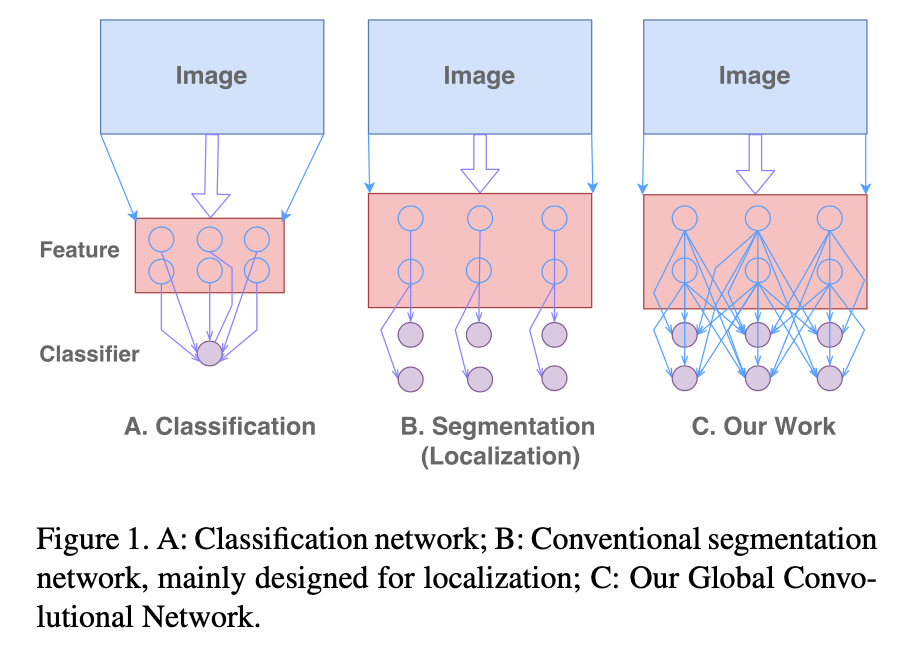
CVPR2017 算法 Global Convolutional Network(GCN),江湖人送外号“Large Kernel”。 Motivation GCN 主要将 Semantic Segmentation分解为:Classification 和 Localization两个问题。但是,这两个任务本质对特征的需求是矛盾的,Classification需要特征对多种Transformation具有不变性,而 Localization需要对 Transformation比较敏感。但是,普通的 Segmentation Model大多针对 Localization Issue设计,正如图(b)所示,而这不利于 Classification。 所以,为了兼顾这两个 Task,本文提出了两个...
Computer Vision
2026-01-11
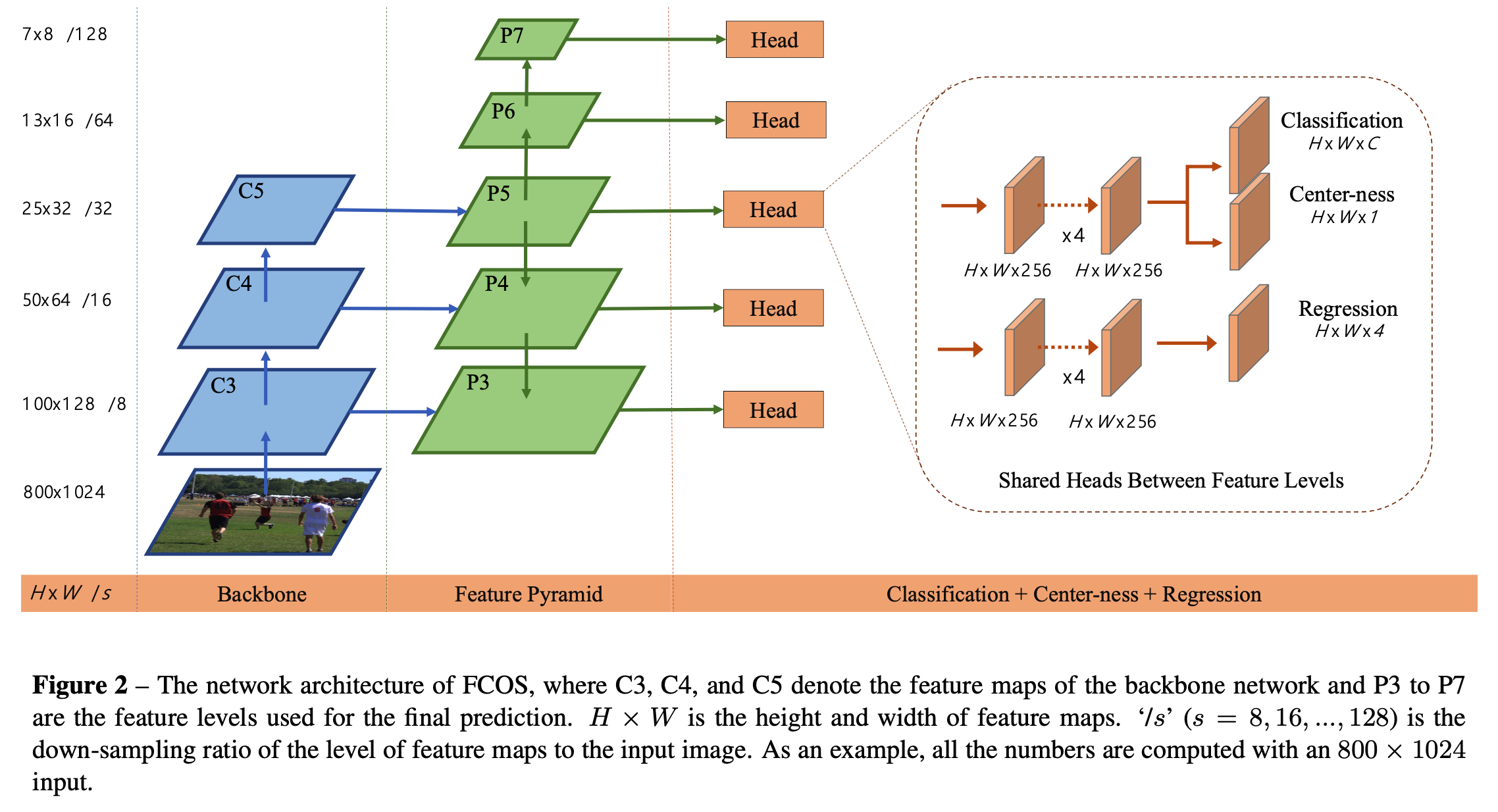
先要明确的知道,FCOS是一个基于FCN(全卷积网络用于目标检测)、一阶段(one stage)、anchor free、proposal free、参考语义分割思想 实现的逐像素目标检测的模型。 简要介绍下FCOS几个核心点: (1)FCOS方法借鉴了FCN的思想,对 feature map 上每个特征点做回归操作,预测四个值 , 分别代表特征点到Ground Truth Bounding box上、下、左、右边界的距离。 (2)特征点映射会原图后对应多个GT Bounding box,无法准确判断原图像素所属类别,因此模型引入 FPN 结构,利用不同的层来处理不同尺寸的目标框。 (3)远离目标中心点可能会产生劣质预测结果,为了增强中心点选取的准确性,模型引入了Centerness lay...
Computer Vision
2026-01-11
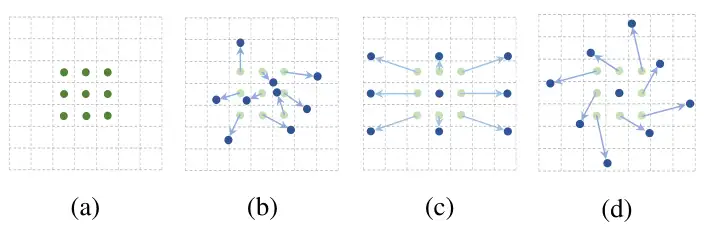
Deformable Convolution 在正式介绍这个工作之前很有必要先了解什么是 Deformable Convolution 。 Deformable Convolution 是MSRA的代季峰老师以及实习生在2017年提出的一种全新的卷积结构。这种方法将固定形状的卷积过程改造成了能适应物体形状的可变的卷积过程,从而使结构适应物体形变的能力更强。 传统的CNN只能靠一些简单的方法(比如max pooling)来适应物体的形变,如果形变的太厉害就无能为力了。因为CNN的卷积核的geometric structure是fixed的,也就是固定住的。卷积核总是在固定位置对输入特征特征进行采样。 为了改变这种情况专家们想了很多方法,最常见的有两种: 1. 使用大量的数据进行训练。比如用Im...
Deep Learning
2026-01-11

DropBlock 论文题目:DropBlock: A regularization method for convolutional networks 论文地址:https://arxiv.org/abs/1810.12890 由于dropBlock其实是dropout在卷积层上的推广,故很有必须先说明下dropout操作。 dropout,训练阶段在每个minibatch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参数与更新。而测试阶段则又让所有神经元都参与计算。 dropout操作流程:参数是丢弃率p 1)在训练阶段,每个minibatch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元...